

Влияет ли размер приложения и команды на то, как мы его релизим? Давайте представим себе стартап с небольшой командой. В этом случае обычно не задумываешься о процессе релизов: сделал фичу — зарелизил.
А теперь представим большой проект, например, какое-нибудь банковское приложение, над которым работает много команд. Тут мы понимаем, что наверняка есть процесс, релизные циклы, «бюрократия». Без этого будет хаос. Но где то место, когда становится ясно, что пора такой процесс настраивать и у себя?
В этой статье расскажу, что при росте приложения Додо Пиццы стало отправной точкой и заставило внедрить Release Train. В конце поделюсь результатами, помогло ли это.
Если ваш проект растёт или вы часто спотыкаетесь в работе при релизе приложения, то надеюсь, что рассказ про наш опыт поможет эти проблемы решить.
Как было: кто готов, тот и катит
За начальную точку возьмём начало 2021 года. К этому моменту приложение Додо Пиццы разрабатывали 6 фича-команд плюс core-команда. Мы развивали в командах подход Trunk-based Development (TBD), покрывали фичи-тогглами, фича-ветки жили недолго, декомпозировали задачи, работал CI, гоняли юнит и UI-тесты.
Было достаточно много регресс-кейсов, потому что приложение работало в 12 странах. Мы покрывали их e2e-тестами (покрыто примерно 40-50% кейсов), из-за этого каждый регресс длился примерно 3-4 дня.
Релиз происходил очень просто: кто готов катить свою фичу, тот и катил. Мелкие фишечки не катили специально, а просто подливали в основную ветку и ждали, когда кто-то другой покатит релиз.
Идеальный сценарий
Вот как примерно выглядел наш процесс работы с ветками. Есть несколько команд (серые, синие, оранжевые и зеленые), которые работают над разными фичами. Так как мы работаем по TBD, то каждая фича может прожить несколько последовательных веток. Например, серая команда сделала свою фичу за 4 шага, синяя и оранжевая — за 1 шаг, а зеленая — за 2.

Когда какая-то команда заканчивала свою фичу, она могла покатить релиз. Например, синяя команда закончила фичу и покатила релиз. Потом оранжевая команда закончила фичу — покатила релиз.
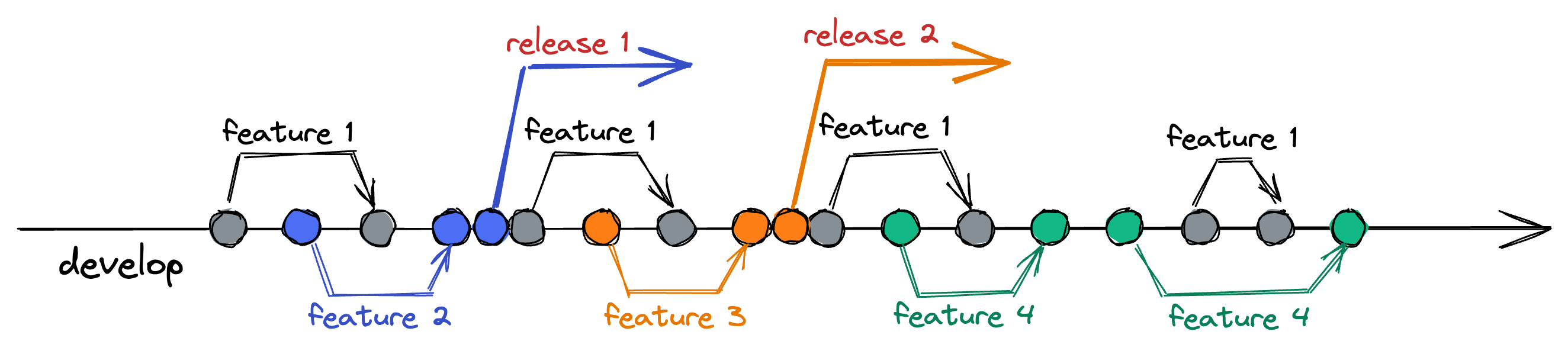
Это работало отлично до поры до времени: у нас был идеальный сценарий. Но всё хорошее когда-то заканчивается.
Что-то пошло не так: тяжело, тесно и непрогнозируемо
Конь
Первая проблема — накопилось много фич и релиз стал слишком большим.
Не всегда команды хотят релизить свои фичи сразу. Как я писал выше, процесс релиза и регресса довольно трудоёмкий и занимал 3-4 дня. Поэтому если твоя фича небольшая и не срочная, то ты можешь сам её не релизить. Потому что наверняка скоро какая-то другая команда покатит релиз и она войдёт в него. Примерно это выглядит так:

Но эта конструкция очень хрупкая, особенно, когда количество команд растёт. Много команд может написать много не больших фич, но в сумме получается очень много нового кода. Потом в итоге кто-то покатит свою большую фичу и прицепом он покатит «коня».
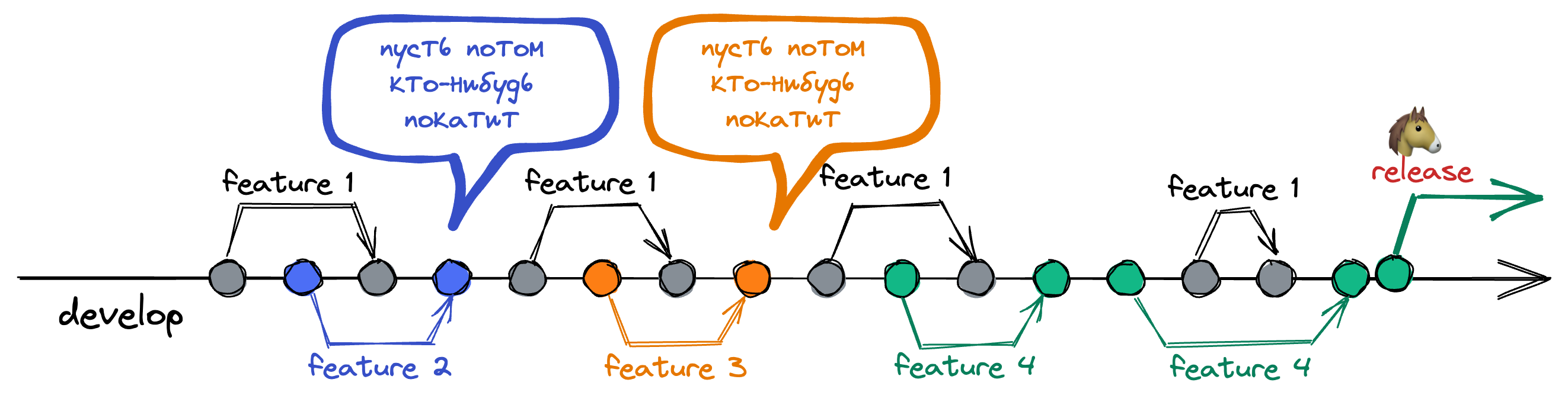
В итоге релиз-конь приводит к тому, что:
затягивается регресс;
выше риск появления регрессионных багов;
выше риск получить ошибку на проде.
Нужно сделать так, чтобы даже если синие и оранжевые явно не хотят катить релиз, релиз всё равно как-то покатился.
Толкучка
Все команды разные, и фичи все разные. Иногда всё происходит таким образом, что сразу все команды доделывают свои фичи примерно в один срок. В этом случае возникает толкучка, или «подожди меня, завтра утром всё солью, обещаю!».

В итоге толкучка приводит к тому, что:
релиз тоже получается «конь»;
если пойти всем навстречу, то твой релиз задержится, а это негативно повлияет на планы команды.
Нужно сделать так, чтобы, с одной стороны, синие никого не ждали. Но с другой стороны, если синие будут релизить, то остальные знали, когда именно.
Нет прогнозируемости
Синие сделали небольшую фичу, и ожидают, что оранжевые скоро покатят релиз. Но что-то пошло не так, и оранжевые тоже не покатили релиз из-за каких-то своих проблем. В итоге синие сказали бизнесу, что скоро фича будет на проде, а оказалось, что нескоро. В итоге невозможно спрогнозировать, когда фича будет на проде.
Это не говорит о том, что синяя команда безответственная. Если у неё будет суперважная или срочная фича, то, конечно же, команда покатит релиз сама. Но в остальных случаях неприятно, если ты не можешь точно сказать, когда твоя фича окажется у клиентов.

Нужно сделать так, чтобы независимо от размера и срочности фичи ты точно мог сказать, когда она будет у клиентов на проде.
Все 3 проблемы (конь, толкучка и отсутствие прогнозируемости) тесно взаимосвязаны и дополняют друг друга. Но, пожалуй, базовая и главная из них — это отсутствие прогнозируемости. Именно она порождает остальные проблемы.
Release Train
Мы решили, что хватит терпеть, пора что-то менять. И нам в этом поможет Release Train. Термином Release Train называют разные вещи: и процесс релизов по расписанию, и выделенную большую команду, которая управляет процессом релизов.
Мы будем говорить про процесс релизов по расписанию. Мне нравится, как Release Train описывает Martin Fowler в статье Patterns for Managing Source Code Branches, и определение, которое даёт компания Thoughtworks в своем тех радаре (может быть, Мартин его же и писал).
А вот так мы сформулировали Release Train для себя:
Release Train — это процесс координации релизов между командами. Все релизы происходят по фиксированному графику, независимо от того, готовы фичи или нет. Поезд не ждёт вас. Если вы опоздали, то ждите следующего.
Разберём Release Train на паре примеров с нашими разноцветными командами.
Решаем проблему коня
Release Train происходит по расписанию и не зависит от того, кто что успел влить в основную ветку. На примере ниже фичи от синей и оранжевой команды поедут в релиз. Остальные будут ждать следующего поезда. Мы могли бы подождать немного, но тогда получился бы конь.

Решаем проблему толкучки
В то же самое время Release Train помогает более эффективно спланировать работу. Допустим, что изначально синяя команда планировала закончить фичу позже. Но так как все знают дату релизов, то можно немного перестроить свои планы так, чтобы доделать фичу пораньше. Или, наоборот, понять, что к следующему поезду ты точно не успеваешь и можно спокойно доделывать фичу, ведь ты знаешь всё расписание.
На примере ниже синяя команда захотела попасть в релиз и влила все свои изменения перед поездом. Если бы всё было по-старому, то могла бы возникнуть толкучка.
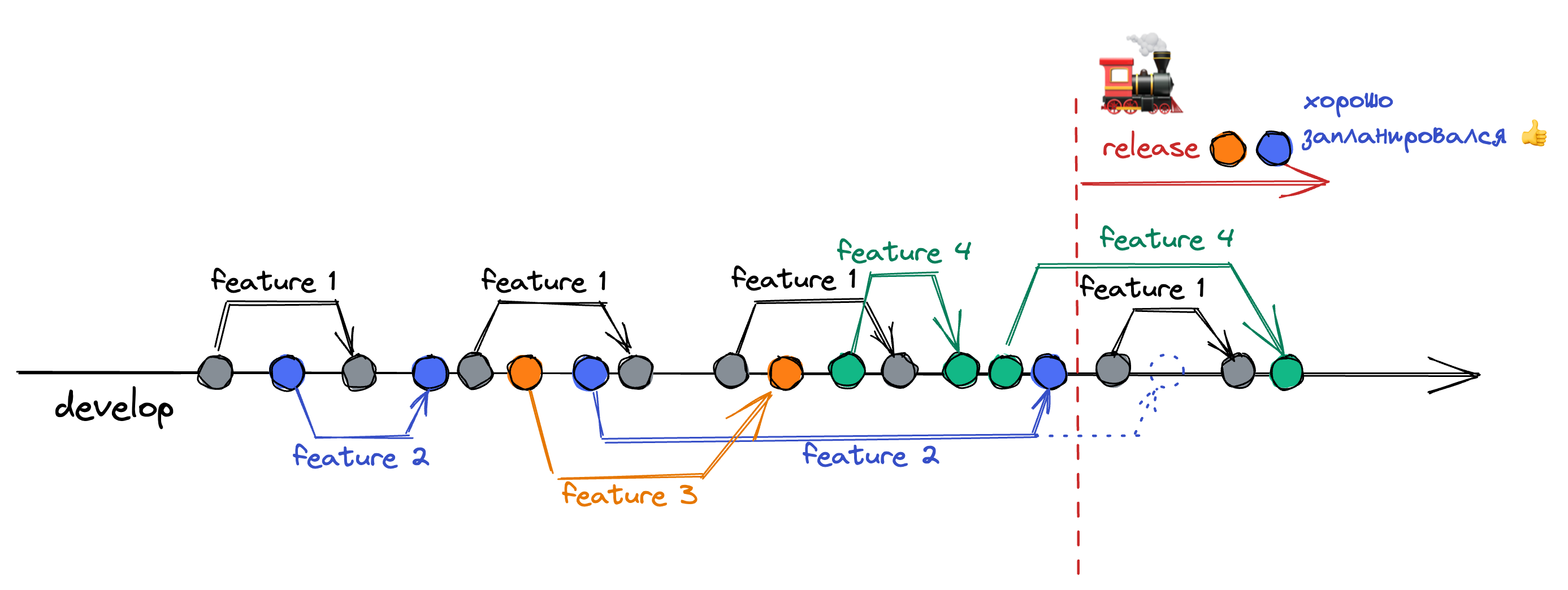
Ну и главное: Release Train даёт нам прогнозируемость by design.
Кому-то эти примеры могут показаться очевидными, но мы решаем проблемы по мере их появления. Когда проблем с релизами не было, то мы не городили никакого Release Train. Когда проблем накопилось, поняли, что пора.
Как мы внедряли Release Train
Первым делом мы написали RFC. Под RFC понимают как сам процесс, так и дизайн-документ, который используют многие компании перед началом работы над проектом. Некоторые используют именно RFC, некоторые ADR, кто-то называет их просто более общим термином Design Doc. В Dodo Engineering мы используем и RFC, и ADR.
Наш процесс RFC выглядел так:
составить RFC-документ;
обсудить его в узком кругу, собрать комментарии и внести корректировки;
рассказать про RFC широкому кругу;
воплотить в жизнь;
собрать обратную связь, трекать метрики, оценить результаты.
Структура RFC документа по нашему Release Train была такая:
описание процесса релиз трейна;
какие команды участвуют, что именно делают;
какое будет расписание;
метрики.
В составлении RFC мы опирались на опыт других компаний и их статьи:
Первое решение
В итоге мы пришли к такому процессу:
релизим каждую неделю;
отводим релизную ветку в среду утром;
проводим регресс до пятницы, в пятницу отправляем на ревью;
в понедельник начинаем раскатку релиза;
-
в среду отводим новую релизную ветку;
Релиз-команда:
iOS и Android-разработчик из одной из фичевых команд
2 QA-инженера
составляем график на квартал вперёд — когда какая команда катит релиз. Через квартал собираемся и продлеваем график.
Схематично наш Release Train выглядел вот так:
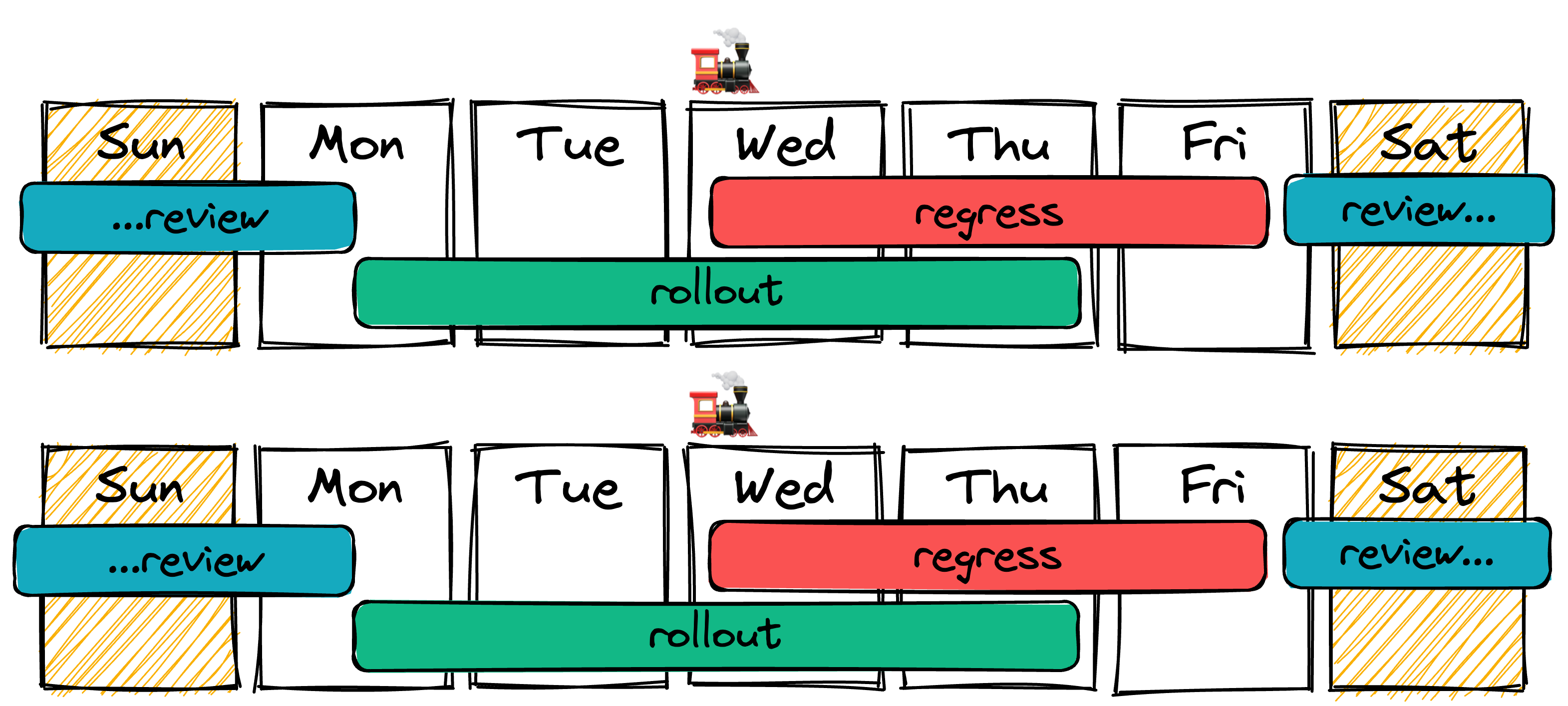
Не всё пошло гладко
Спустя месяц стало понятно, что всё классно, но:
очень тяжело каждую неделю проводить регресс и укладываться к пятнице;
совсем не остаётся времени на хотфиксы, а они бывают.
Как я писал выше, в 2021 году регресс у нас проходил в среднем 3-4 дня. Сейчас он проходит 2-3 дня. Но иногда может выбиваться и из этих рамок. Мы продолжаем работать над покрытием регресс-кейсов e2e-тестами, но 100% покрытия пока нет. У нас покрыто примерно 70% и 60% регресс кейсов на каждой платформе соответственно.
Отсюда вывод такой, что пока у нас регресс занимает несколько дней, то, скорее всего, будет некомфортно проводить релизные циклы каждую неделю.
Итоговое решение — двухнедельные релизы
В итоге мы перешли на двухнедельные релизные циклы и Release Train теперь выглядит так:
релизим каждые 2 недели;
отводим релизную ветку в среду утром;
проводим регресс до пятницы, в пятницу отправляем на ревью;
-
по плану в понедельник начинаем раскатку (если была задержка, то можно позже);
Релиз-команда:
iOS и Android разработчик из одной из фичевых команд
2 QA-инженера
составляем график на квартал вперёд, кто и когда катит релиз. Через квартал собираемся и продлеваем график;
раскатываем постепенно;
есть время на хотфиксы;
через неделю в среду отводим новую релизную ветку.
Вот так схематично можно изобразить процесс, если всё идет по плану.

Всё похоже на еженедельный цикл, только остаётся достаточно времени на потенциальные хотфиксы. А вот так будет выглядеть, если регресс затянулся:

Тоже ничего страшного, даже на хотификсы всё равно осталось время.
Как новый процесс повлиял на прогнозируемость
Главная цель, которую мы преследовали — это повышение прогнозируемости. Её можно разбить на две составляющие: когда будет релиз приложения и в каком релизе поедет моя фича.
На вопрос «когда будет релиз» мы ответили by design процессом Release Train.
На вопрос «в каком релизе поедет моя фича» теперь каждая команда сможет самостоятельно ответить в момент, когда будет планировать и оценивать фичу. Ведь раньше нельзя было точно сказать, потому что другая команда могла покатить релиз, а могла и не покатить. А теперь всё зависит только от собственного планирования.

Чтобы это дополнительно подтвердить, мы провели опросы среди мобильных разработчиков, QA и продактов, где среди прочего были вопросы:
Когда следующий релиз? (На этот вопрос ответили 100%)
Помог ли Release Train планировать работу в команде? (На этот вопрос положительно ответили 75%, кто-то и без релиз трейнов отлично предсказывал свою работу).
Также Release Train помог нам работать с код-фризами и релиз-фризами. У нас их несколько, помимо новогодних есть еще другие (например, 1 сентября и некоторые другие праздники). Теперь с Release Train нам не нужно подстраиваться под эти даты с отведением веток, регрессом и всем прочим. Релизы работают по расписанию, просто открываем их в сторах попозже.
Влияние на метрики
Помимо просто решения проблем, мы ещё замеряли метрики. Давайте посмотрим на основные.
Lead time
Первая важная метрика, которую мы замеряли — это Lead Time коммита в релиз.
Вот такой получился график. Стрелочкой я обозначил, когда мы начали процесс Release Train.
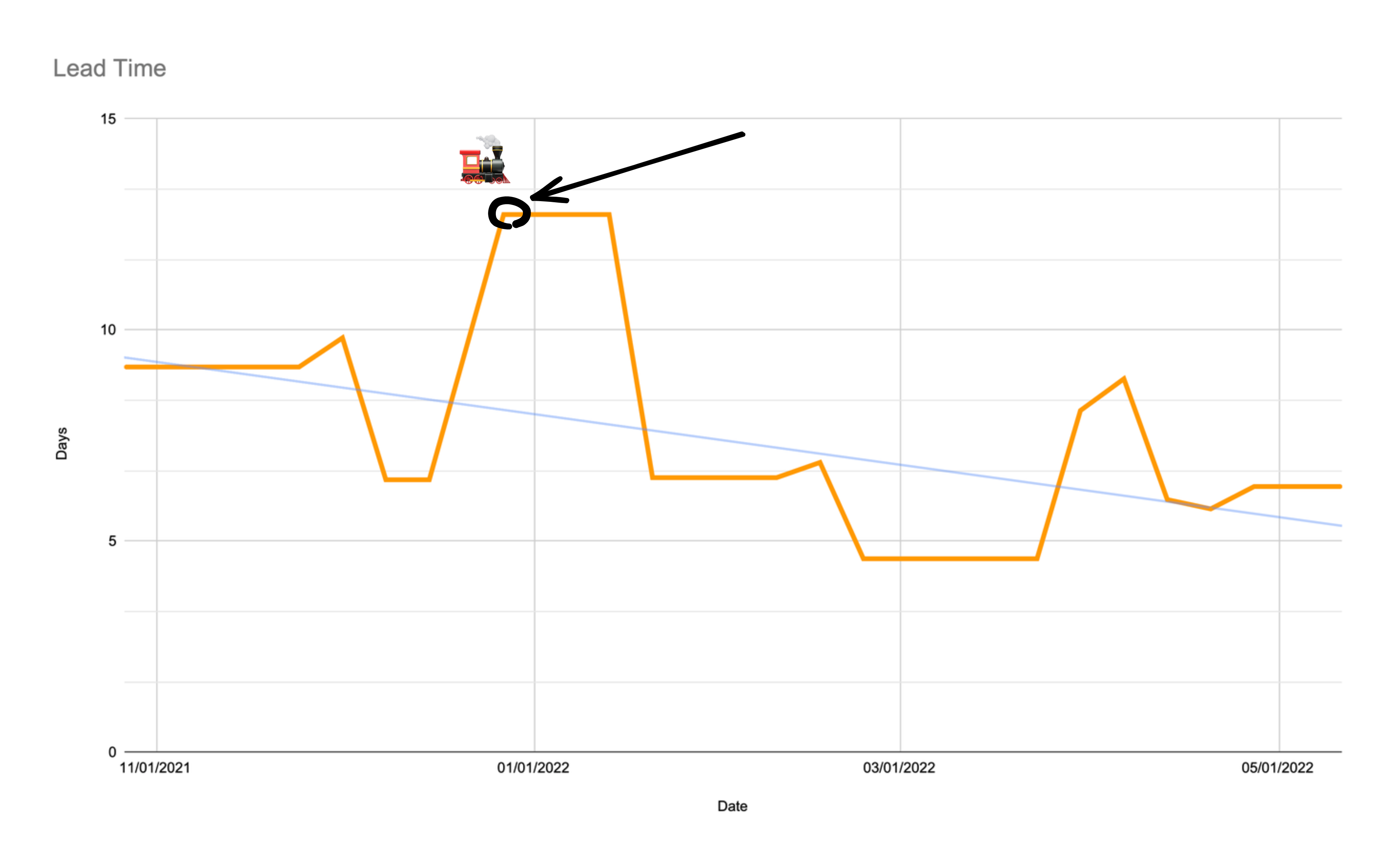
По графику видно, что Lead Time стал где-то на уровне 6 дней. 6 дней это много или мало?
Бенчмарки от Google
Есть бенчмарки от Google для этой метрики, но в основном она для бэкенда. По своей шкале они выделяют следующие группы:
Elite: меньше часа
High: от 1 часа до 1 недели
Medium: от 1 недели до 6 месяцев
Low: от 6 месяцев и выше
Я считаю, что для стандартных продуктовых мобильных приложений, таких как приложение Додо Пиццы, Lead time должен стремиться в идеале к половине длительности релизного цикла. Это равносильно тому, что каждый день задача сливается в основную ветку. То есть, если релизный цикл 14 дней, то Lead Time должен стремиться к 7 дням.
Bugs per regress
Ещё одна метрика, которую мы трекаем — количество багов за регресс. Она описывает, насколько стабильный релизный кандидат мы готовим к релизу. Если предыдущий релиз выходил давно, то, скорее всего, много нового кода, много фич — и количество багов будет высоким, больше потратим время на регресс и фикс.
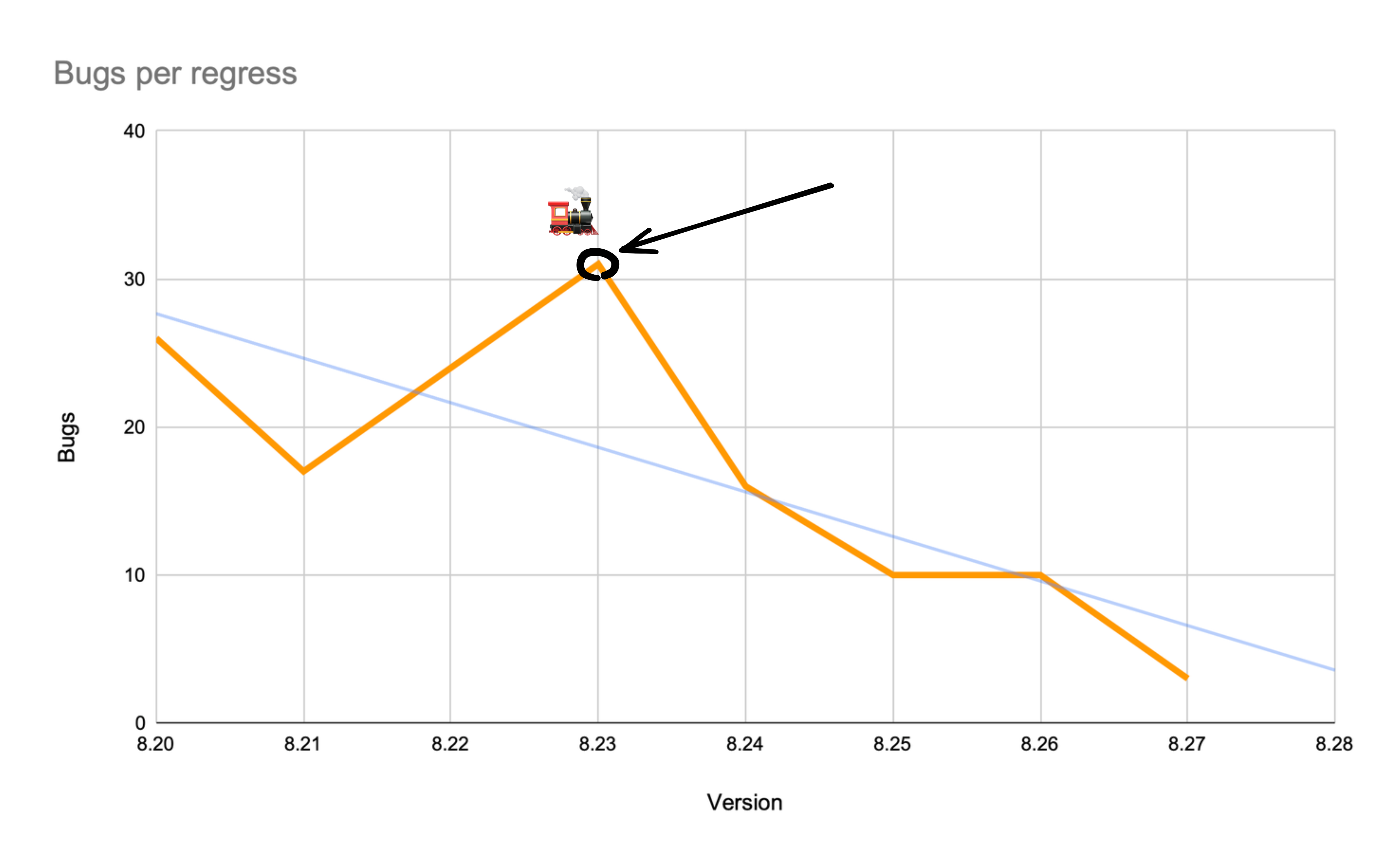
В моменте эта метрика опустилась до 3 багов. Конкретные цифры не так принципиальны, но в целом видно, что тенденция пошла на снижение.
Ещё метрики
Кратко расскажу, за какими метриками также следили в рамках релиз трейна.
Crash-free. Всегда следим за этой метрикой. Была гипотеза, что она просядет из-за того, что старались уложить регресс в более сжатые и строгие сроки. Просадки не было.
Было интересно, повлияют ли частые релизы (каждую неделю) на отток клиентов, на удаление приложения. В результате никак не повлияло.
Внедряй, улучшай
Текущий процесс нам нравится —считаем, что он решил свои задачи. И знаем, как его дальше улучшать.
Продолжаем работать над автоматизацией регресса, чтобы он стал более простым и быстрым
Пока за рамками осталась часть по автоматизации работы (скрипты по отведению веток).
Работа с переводами. Сейчас у нас 16 стран, надо переводить приложение на все языки. Для этого есть внутренний сервис, но разработчикам всё равно пока приходится участвовать в этом процессе вручную перед релизом.
Пока мы были относительно маленькими, Release Train нам был не нужен. А когда столкнулись с тем, что не можем прогнозировать релизы, их размер и количество, решили внедрить Release Train. Сначала попробовали еженедельные релизные циклы, но из-за трудоёмких регрессов пришлось перейти на двухнедельные. Живём так до сих пор.
Сейчас у нас появилась предсказуемость релизов и раскатки фич, метрики показывают положительную динамику. В планах повысить покрытие регресс-кейсов е2е-тестами, автоматизировать процесс работы с ветками и оптимизировать процесс переводов на другие языки.
Надеюсь, что эта статья и наш опыт поможет командам и проектам, которые начали задумываться о процессе релизов или столкнулись с похожими проблемами. Буду рад почитать в комментариях о подходах, которые вы используете для релизов.
Подписывайтесь на канал Dodo Mobile, там мы коротко рассказываем о том, как разрабатываем мобильные приложения для нашей сети ресторанов быстрого питания.
Комментарии (4)

thyratr0n
23.12.2022 09:41Т.е. сквозь боль и страдания вы пришли к двухнедельным спринтам?

maxkachinkin Автор
23.12.2022 09:41Нет, не 2-х недельным спринтам. Спринты у каждой команды любые на усмотрение команда. 2-х недельные именно релизные циклы приложения.
Смысл релиз трейна в том, чтобы отделить релиз билда от релиза фич. Релиз билдов идет строго по расписанию. Релиз фич идет так, как напланируют команды. Может быть так, что в новом релизе не будет ни одной новой фичи, а только фиксы какие-то. Хотя по факту, когда 6 команд работает параллельно, такого ни разу не было.
murkin-kot
Правильно ли я понял, что на самом деле бизнесу просто был нужен график ввода в эксплуатацию, а всё остальное - местный фольклор и эмоциональное восприятие (лошади с толкучками)?
И почему время ввода в эксплуатацию большое? Каков процент ручных тестов?
maxkachinkin Автор
Бизнесу нужна прогнозируемость. Чтобы он мог четко понимать, когда та или иная фича окажется у клиентов. Когда приложение и команда были небольшими, то и график, который синхронизирует команды, никакой не нужен. Оценили фичу и делаем. Как сделали — покатили. А когда несколько команд работают параллельно так просто уже не получается. Нужен какой-то специальный процесс, который это всё синхронизирует.
Сейчас 60% и 70% регресс кейсов автоматизировано на каждой платформе соответственно. Остальное пока ручное.