
Особо амбициозные разработчики любят заявлять о том, что используемый ими язык программирования или фреймворк будет жить лет сто. Дерзкое заявление, учитывая, что разработке программного обеспечения, как таковой, всего около 65 лет. А фреймворки ещё моложе.
Можно почитать Пола Грэма и его разглагольствования о столетнем языке. Но он имеет в виду немного другое: язык, потомки которого будут с нами и через 100 лет в более или менее узнаваемом виде. То есть, если язык C заменит Algol, это нормально. Пола интересует другое, а именно, какие функции Algol достаточно хороши, чтобы выжить при переходе на новый язык.
А мне интересно, какие языки все ещё будут использоваться через 100 лет.

Есть такое популярное мнение: «чтобы язык можно было использовать и через сто лет, он должен иметь хорошую производительность». Как бы вы оценили подобное заявление? По каким критериям проводили оценку?
Это не риторический вопрос. Приступаем к оценке.
Что могут рассказать нам древнейшие языки?
Раз уж языкам программирования всего 65 лет, у нас попросту нет примеров столетнего языка. Зато есть несколько языков программирования, которым 60 и более лет. Что мы можем о них сказать?
Как только язык становится популярным, он обычно не умирает, но часто мутирует. Версия Fortran 2008 года не совсем похожа на Fortran77 или оригинальный Fortran (1957 год). Но у них много общего. Язык остаётся узнаваемым, у него есть стабильное сообщество программистов. Фортран всегда был популярен в научном и математическом сообществах и остаётся таковым до сих пор. Например, Fortran является основным языком программирования для суперкомпьютеров, для которых в приоритете высокая производительность, а значит, нужен максимально быстрый язык. Fortran значительно быстрее, чем, к примеру, C. Именно потребность в высокой скорости и преданное сообщество разработчиков дают Фортрану дыхание жизни.

Получается, когда мы говорим про столетний язык, мы на самом деле не имеем в виду преемственность синтаксиса или функций. Мы ищем сообщество непрерывного программирования. Интересным примером является Perl: версия Perl 6 (теперь называемая Raku) должна была внести значительные изменения в язык, что и произошло. Но процесс занял много лет. В итоге Perl 5 оформился как отдельное сообщество, а Perl 6 пришлось пробиваться, как новому языку. Если бы изменения Perl 6 случились быстро, мы бы, конечно, до сих пор имели единое Perl-сообщество. Perl 1 и 2 сильно отличались от Perl 5, но никто и не думал считать их разными языками. То есть именно раскол среди разработчиков превратил Perl 6 в другой язык.
Ещё одним старым языком является LISP, у которого множество потомков, включая Guile, Scheme, Clojure и Racket. Они никогда не были особо популярны, но исчезать не собираются. LISP не умер, хотя умерли многие его небольшие диалекты. У более крупных диалектов (например, CommonLISP) есть свой собственный импульс, и они тоже никуда не делись. Итак: речь не всегда идёт именно об одноязычном сообществе программистов. Вы можете возразить, что даже если Clojure разрастётся до огромных размеров, сам LISP останется мёртвым. Но речь идёт об очень конкретном, оригинальном LISP. Как и в случае с Perl 1, его потомки сильно изменились, но в них по-прежнему легко узнаётся один и тот же базовый язык. Что еще более важно, вы можете легко выучить новый диалект LISP, если знаете старый. У них много общего.
Как могут умереть языки?
Я говорю "язык мёртв" в том же смысле, в каком мертва латынь. Существуют небольшие изолированные сообщества академических и религиозных носителей латыни. Но это не повседневный язык для значительного числа людей.
Если вы этого ещё не сделали, советую прочитать статью об истории языков программирования.
Алгол (1958) мёртв. У него есть потомки, но они мало похожи на Алгол. Итак: это один из вариантов того, как может умереть язык. Его могут полностью “съесть” более совершенные потомки, которые заберут всю его пользовательскую базу. «Семейство алголов» включает в себя таких дальних родственников, как Perl, и менее используемые ответвления вроде Delphi. А ещё туда входят C, C++, Visual BASIC и Java. Это чрезвычайно популярные языки, которые давно поглотили всё сообщество разработчиков Алгола. В частности С был молодым и чрезвычайно популярным, поэтому не было никаких причин продолжать использовать Алгол.
Некоторые языки так и не прижились. FLOW-MATIC был первым языком Грейс Хоппер до того, как она написала COBOL. Да, он оказал влияние на COBOL, но сам по себе никогда особо не использовался. И многие ныне мёртвые языки были такими: мало пользователей, маленькие коммюнити.
Сюда также можно включить множество «протоязыков». Это языки, которые по большей части мутировали во что-то другое. FLOW-MATIC превратился в COBOL, поэтому его крошечное сообщество пользователей перетекло в сообщество COBOL. Именно так многие языки умирают: они присоединяются к другому языку, и их сообщество становится частью сообщества этого нового языка.
«Предшественники» и протоязыки не обязательно должны разрабатываться одними и теми же людьми. FACT (1959) сейчас считается предшественником COBOL, поскольку он повлиял на дизайн, и его пользователи стали частью сообщества COBOL. Но FACT не был проектом Грейс Хоппер. Точно так же C был назван в честь BCPL. Пользователи BCPL (их было не так много) стали пользователями C. Но BCPL был написан Мартином Ричардсом, который не входил в число авторов C. Так что дело даже не в том, кто написал язык. Речь идёт о том, куда переходит сообщество его пользователей.
Что значит мёртвый?
Прежде чем идти дальше, остановимся на очевидном и несколько глупом использовании слова «мёртвый» в отношении языков программирования.
Языки программирования пишутся людьми для людей. Это человеческий язык и человеческая культура. Они точно так же создают функциональные компьютерные программы. Они точно так же восприимчивы к тенденциям, как и любой другой человеческий язык или культура.
Когда вы слышите, что «Rails мертв», это вовсе не означает, что «ни одна программа больше не использует Rails», «ни одна компания больше не использует Rails», или «никакие новые проекты не написаны на Rails». Они означает лишь, что «Rails больше не популярен, и вместо него вы должны изучить что-то другое».
Это также может означать, что для программистов на Rails меньше рабочих мест, чем для тех, кто владеет другими языками, меньше фреймворков или технологий. Может означать, что основатели стартапов предпочитают что-то другое. Но совершенно не означает, что Rails в принципе больше не используется или вообще непригоден.
Так что определение “мёртвый” в смысле потери популярности можно спокойно игнорировать для любого языка, которому более 25 лет. Он в любом случае не является новым, популярным или сильно раскрученным. Абсолютное, 100%-е требование к 100-летнему языку — быть, по этому определению, мертвым.
Что ослабляет языки
Языки не умирают сразу. Они медленно угасают, пока последний пользователь не перейдёт на другой язык.
Кое-что серьёзно раскалывает сообщество. Perl 5 и Raku стали намного слабее после разделения. Переход Python от версии 2 к версии 3 был трудным и стоил ему части аудитории. Переход Ruby с 1.8 на 1.9 был схожим, хотя и не таким медленным и драматичным. Когда вы делаете что-то, что раскалывает сообщество, оно естественным образом становится слабее. В крайних случаях, таких как с Perl, сообщество становится настолько маленьким, что может вымереть.
Это одна из причин, по которой языки уничтожаются их собственными потомками. Зачем оставаться с Algol, когда существует C? Зачем оставаться с FLOW-MATIC, если автор перешёл на COBOL? Потомок языка часто более привлекателен для сообщества, чем сам язык.
Что ещё более важно, языковые сообщества, как правило, переходят на тот инструмент, который решает те же проблемы. Разработчики переходят с Perl на Ruby или Python — языки, решающие схожие задачи аналогичным образом. Между Python и R существует постоянное противостояние, потому что оба решают задачи для статистического анализа данных. То есть языком пользуются не ради самого языка, а ради решения вполне конкретных проблем.
Проблема обычно не только в том, что у языка появляется новый конкурент, а в том, что старое решение перестаёт работать. Ruby и Rails имели репутацию феноменально простого стека для разработки веб-приложений по сравнению со старыми средами Java, такими как JBoss. Но в более поздних версиях Rails пришлось всё больше и больше укреплять инфраструктуру из-за угроз безопасности, что усложнило развёртывание. В свою очередь облачная PaaS-платформа Heroku перестала предлагать бесплатный тарифный план, а очевидной замены для неё не оказалось. Следовательно, Rails сейчас сложнее развёртывать, чем раньше. А значит, она хуже решает проблемы пользователей. Это ослабляет фреймворк и сам язык Ruby, который подпитывался от сообщества пользователей Rails.

Итак, языки начинают угасать, если они перестают решать проблему так же хорошо, как раньше, или если появляется конкурент, который решает проблему лучше.
Что укрепляет язык?
Если язык должен решать проблемы пользователей, это означает, что проблема имеет первостепенное значение.
Нишевость укрепляет язык. Язык R отлично подходит для статистического анализа данных и занимает важное место в этом сообществе. Никто не станет писать на нём операционную систему, с этим согласны все участники, но оно и не требуется.
Java — самый популярный в последнее время язык общего назначения. Все последующие являются нишевыми: Python хорош в математике, научном программировании и программировании искусственного интеллекта, а Ruby отлично обрабатывает динамические веб-приложения. JavaScript доминирует в браузерном программировании и нескольких связанных с ним ниш на стороне сервера. Fortran, когда-то универсальный, теперь используется в суперкомпьютерах и некоторых математических приложениях. C отступает в нишу операционных систем и драйверов, поэтому теперь он исключён из общего программирования приложений.
Ниши — это сила.
Я не утверждаю, что «Java — это последний язык общего назначения». Учитывая 65-летнюю историю языков программирования, заявлять такое было бы странно. 27 лет существования Java не означают, что не будет другого популярного языка общего назначения. Но, действительно, скорее всего такие языки будут появляться редко.
Чтобы язык действительно мог претендовать на универсальность, следует избегать нишевости. Даже у Java есть некоторые существенные ограничения на сферы применения, например, большой объем памяти делает его сомнительным для небольших встроенных процессоров. Может быть, «универсальность» вообще сойдёт на нет, размывшись многими и разными нишами.
С другой стороны, ниша означает, что у языка есть фокус и цель. Нишевость сильна, потому что она сообщает своему сообществу, для кого предназначен язык и какие задачи решает.
Нужна ли производительность столетнему языку?
Fortran, один из старейших процветающих языков, который продолжает жить благодаря производительности. Это серьёзный аргумент “за”.
LISP, ещё один из старейших, совершенно не заботится о производительности, но процветает благодаря гибкости и простоте реализации. Это аргумент “против”.
Впрочем, у нас тут не голосование. На деле цель Fortran — производительность, а LISP уделяет основное внимание гибкости и удобству. Так что мы опять возвращаемся к цели использования. Нужна ли производительность? Смотря какие задачи решает язык.
Производительность — это неплохо. Но если вы спросите сообщество Fortran: «Нужно ли вам больше простоты в реализации вашего компилятора?» они скажут «Без разницы». Сообщество LISP не может сказать, что их вообще не волнует производительность, но им интересны и гибкие варианты с низкой производительностью. Вопрос не в том, «хороша ли высокая производительность?» Вопрос в том, «какое место она занимает в вашем списке приоритетов?»
BASH, оболочка командной строки, имеет довольно низкую производительность и всегда была таковой. Но не этим он притягивает пользователей. Сообществу требуется совместимость, стабильность и простота использования. Если бы вы сделали массовую высокопроизводительную версию BASH, её использовало бы всего несколько человек. Точнее его бы использовали, если бы это не было не в ущерб одной из основных целей. Таким образом, наш гипотетический высокопроизводительный BASH уже мертворожденный, потому что «универсальная доступность» и «100% совместимость» слишком важны для его сообщества.
Меняются ли приоритеты?
Если что-то не было приоритетом на заре появления языка, это не означает, что сейчас оно таковым не является. Первые версии Ruby или Python могли быть очень медленными, но часть их нынешних пользователей может заботиться о производительности гораздо больше, чем о выразительности. Возможно, PHP изначально был ориентирован на простоту развертывания, но нынешняя база пользователей фреймворка Laravel может захотеть более чистого, более выразительного основного языка, ради которого готова пожертвовать совместимостью и доступностью.
Тут нет ничего невозможного.
Проблема в преемственности сообщества. Очень сложно отогнать одно сообщество, а потом привлечь другое. Слишком много старой информации о языке теперь неактуально. Неверная информация привлекает людей, которые вам не нужны, и отталкивает тех, которым нужно ваше текущее предложение. Итак: изменение того, что было фишкой приложения, — одна из самых опасных вещей, которые могут произойти с языком. Это может стать причиной раскола сообщества, о котором говорилось ранее.
Вы можете внести небольшие изменения. Немного дополнительной производительности никого не оттолкнет. Но в какой-то момент вам придётся идти на компромисс.
Ruby стал использоваться более крупными компаниями. В целом это хорошо. Но это также было и переломным моментом. Стоит ли снижать выразительность из-за того, что неограниченная выразительность вызывает проблемы с большими командами? Может быть. А если внести это изменение, увеличит ли оно размер сообщества Ruby и продолжительность его жизни? Подобные изменения несут в себе самые большие риски смерти языка.
Между прочим, это одна из причин, по которой проекты по оптимизации Ruby, такие как YJIT и TruffleRuby, не стремятся ограничивать возможности Ruby. Дополнительная производительность — это хорошо, но именно благодаря выразительности Ruby получил своих фанатов. Производительность — это круто, если она не ставит под угрозу выразительность. Да, это касается не всех языков, но для Ruby оно работает именно так.
Быстрее, медленнее
Беспокойство по поводу приоритетов стало причиной того, что переход с Python 2 на Python 3 занял так много времени и мучений. Python делает очень медленные, преднамеренные изменения с отличной обратной совместимостью. В тех редких случаях, когда он нарушает обратную совместимость, пользователи воспринимают это как предательство.
С Ruby было легче, потому что Ruby не обещает такой большой обратной совместимости. Их философия скорее такая: «в основном мы сохраняем некоторую обратную совместимость, но иногда, когда мы хотим сделать язык лучше, что-то ломается, так что вам придётся подстроиться». В результате Python рулит в математическом/научном сообществе, которому нужны программы, способные работать и 20 лет спустя, а Ruby завоевал сообщество веб-программистов, где стандарты меняются каждые 5 лет.
Между прочим, это не означает, что Ruby прав, а Python нет, или наоборот. Это снова к вопросу о нишах. Можно быть настолько крутым в чём-то одном, что вы обойдёте язык общего назначения, который вроде бы подходит для всего, но уступает в конкретных параметрах нишевым языкам.
Язык, завоевавший веб-нишу, быстро меняется, как Ruby. Язык, завоевавший нишу математики/науки, медленно меняется, как Python.
Не исключено, что один язык может быть НАСТОЛЬКО хорош, что завоюет сразу оба сообщества. Но в конце концов ему придётся конкурировать с потомками, которые снова будут превосходить его по тому или иному критерию.
Кстати, именно так и вышло с Perl. Давным-давно Perl был единственным языком сценариев. И он всё ещё неплох для объединения больших кусков текстовых файлов. Но теперь он конкурирует с Ruby, который быстро меняется, и с Python, который меняется медленно. Ruby занял веб-нишу, которую Perl, соответственно, потерял.
Это не ограничивается языками сценариев. C++ меняется намного быстрее, чем C, по разным причинам. C получил преимущество в некоторых областях за счёт медленных изменений. Как часто разработчики драйверов меняют языки? Им нравится стабильность. C++, который меняется быстрее, получил популярность в других областях, таких как программирование приложений. Это далеко не единственная разница между C и C++. Но она важна.
Слон в посудной лавке
Мы ещё не успели толком поговорить про COBOL. Программистов на COBOL немного, и практически все они обслуживают старый код. Многие миллионы строк COBOL поддерживают работу огромного количества банковской инфраструктуры. Он оставался на своём месте, практически без изменений, в течение десятилетий. Там, где от COBOL избавлялись, обычно делали механический перевод с COBOL на другой язык (в основном Java).
С точки зрения количества строк кода, COBOL ещё жив и бодр. Если завтра весь код COBOL испарится, вся международная банковская система мгновенно рухнет.
С точки зрения людей, которые используют его для новых проектов, COBOL почти мертв. На COBOL написано очень, очень мало новых проектов.
Так он жив или мёртв? Скорее мёртв, чем жив.
Не существует большого сообщества разработчиков COBOL. COBOL — это то, что происходит, если вы никогда не вносите изменений в язык, в конечном итоге, ваше сообщество уже не заботится о том, что именно вы предоставляете. Меняться — значит рисковать. Язык может умереть немного или насовсем. Никогда не меняться — значит умереть абсолютно точно.
Может, дело в том, что COBOL устарел? Не совсем. COBOL немного моложе Fortran, а Fortran на удивление здоров и энергичен в своей нише.
Это напоминает нам о том, что фраза «этот язык никуда не исчезнет, его использует компания X» не совсем верна. Google широко использует C++, но это не должно быть единственной причиной его выживания. Ruby используется Shopify, но это только одна из причин его долговечности.
Вам нужны новые пользователи, новые обещания, новая кровь.
Как устаревают обещания?
Одним из старых обещаний (особенностей) C было вести себя как компьютер PDP-11. Он по-прежнему делает это, но это больше не является приоритетом. Как ни странно, ранний LISP делал то же самое. Это старые языки. Эти функции можно рассматривать как старые обещания.
Первоначально LISP требовалось совсем немного производительности — ровно столько, чтобы сделать его математическую выразительность работоспособной. Со временем процессоры стали быстрее, и от этого отказались — car и cdr определённо не дают простой доступ к регистрам в современных реализациях LISP, и никого это не волнует. Если производительность приемлемая, остальное не так важно. И планка «приемлемости» на тот момент была довольно низкой. CommonLISP, например, был намного медленнее, чем C, и в основном это считалось нормальным.
Вы можете подумать, что для C такие изменения будут проходить сложнее. Если C обещает быть похожим на процессор, то что он делает, когда процессор меняется? Новые процессоры используют инструкции SIMD, например, инструкции Intel SSE. Они выполняют операции с большими массивами, и это очень важно для быстрого выполнения объёмных задач. C никогда не добавлял для них никакой абстракции. Он по-прежнему выглядит в основном как PDP-11, в котором такого не было.
Но часто мы не понимаем, какие особенности важны для нашего сообщества разработчиков. C не должен быть самым быстрым языком. В противном случае такие проблемы, как перекрытие указателей, заставили бы его первых пользователей обратиться к Фортрану, более быстрому языку без этой проблемы.
C всегда был достаточно быстрым, приятным языком, который обеспечивал хороший баланс между мощностью и производительностью. И, честно говоря, в период расцвета у него было меньше конкурентов, поэтому он мог особо не беспокоиться о своих особенностях и своей нише. Современный C в его современной нише (операционные системы, драйверы устройств, низкоуровневое системное программирование) больше ориентирован на управление, чем на производительность. Его производительность должна быть приемлемой, но, в первую очередь, речь идёт о точных побитовых макетах. Если тут и там сбрасывается несколько циклов процессора, остаётся ещё много свободного времени. Поэтому драйверы устройств всё ещё пишутся не на Фортране.
Особенности меняются с годами. Они должны. Не нужно избегать любых изменений. Нужно правильно управлять ими.
Как сильно меняются обещания языков программирования? Язык C родом из 1972 года, он появился 50 лет назад. Благодаря всем изменениям, которые он претерпел за эти годы, он находится на полпути к тому, чтобы стать столетним языком. Он всё ещё крепок и полон сил. Думаю, у него получится.
Итак, как продержаться 100 лет?
Что, если вы хотите, чтобы ваш язык просуществовал 100 лет? Что, если вы состоите в языковом сообществе, которое вам нравится, или вы языковой дизайнер? Что бы вы сделали, чтобы создать столетний язык?
Вы не можете просто сосредоточиться на особенностях языка и синтаксисе. Чтобы сохранить язык живым, нужно знать, что вы обещаете своему сообществу. Почему они здесь? Это бывает непросто: конкретная новая функция — это хорошо или плохо? Иногда вы попадаете в конфликт с основной причиной, по которой аудитория пользуется языком. В Fortran пользователи не оценят выразительность в ущерб скорости. В Руби наоборот. В Rust безопасность памяти занимает одно из первых мест в списке приоритетов. В C возможность возиться с памятью всякими странными способами ценится больше, чем безопасность.
Ни один из приоритетов не является неправильным. Они определяются нишей.
Это также означает, что нужно быть осторожным, «вырываясь из своей ниши». Ваша ниша — ваша сила. Есть все признаки того, что в будущем языки будут больше ориентированы на ниши, а не меньше.
Это также означает, что следовать различным известным советам Генри Форда стоит очень осторожно. «Если бы я спросил людей, чего они хотят, они бы попросили более быструю лошадь.». «Автомобиль может быть любого цвета, если этот цвет – черный». Иногда вы можете проявить дальновидность и дать своему сообществу то, о чем они и не думали просить. Но если они говорят, что им что-то не нужно, стоит прислушаться. На каждого Генри Форда в мире приходится очень много людей, которые совсем не Генри Форды и угадывают хреново.
Спросите себя: «Каковы ваши обещания и особенности?» Подумайте о том, как они устаревают. Будут ли люди нуждаться в том, что вы предлагаете, через 100 лет? Что им было нужно 100 лет назад?
Да, это сложно. Но стоит понимать, что 100 лет – это на самом деле очень долго.
А как вы считаете, какой язык программирования в ближайшее время умрёт?
Комментарии (338)

MentalBlood
00.00.0000 00:00+24Между Python и R существует постоянное противостояние, потому что оба решают задачи для статистического анализа данных
Python в отличие от R не специализирован для анализа данных. Его особенность — развитая экосистема и низкий порог входа, который хорошо синергировал со скачком популярности ML и DS
P.S. А, там дальше Python уже "нишевый язык". Это как называть компьютеры нишевыми устройствами потому что большинство использует их для просмотра веб-страниц, например

leotsarev
00.00.0000 00:00+8Питон нишевый язык, но не для анализа данных. Он для задач, где требуется с минимум логики склеивать готовые компоненты. Анализ данных — это подмножество этого.

MaratCdek
00.00.0000 00:00+37Fortran значительно быстрее, чем, к примеру, C.
Как это? Как это понимать?

serg_meus
00.00.0000 00:00+45Перефразируя старый анекдот.
Встретились как-то два программиста, один писал на Фортране, другой на Си.
-- Фортран значительно быстрее, чем Си, -- сказал первый.
-- Интересно, чем?
-- Чем Си.

unclejocker
00.00.0000 00:00+15Я по диагонали глянул, судя по всему, дело в том, что там очень много встроенных операций для матриц, например, оптимизацией компиляции которых под разные архитектуры занимались последние 50 лет.
Т.к. и C и Fortran компилируются в машинный код, то наверняка на C можно так же эффективно написать, но это потребует гораздо большего навыка и усилий (а может и вставок на ассемблере), а пользователи фортрана получают все это готовое.
Aldrog
00.00.0000 00:00+2На C вместо них обычно используются различные реализации blas, которые также очень тщательно вылизаны, так что сомнительный аргумент.

IvaYan
00.00.0000 00:00+16И по иронии судьбы, BLAS может оказаться написан на... Fortran. Как например OpenBLAS и ATLAS.

JustMoose
00.00.0000 00:00+2Может быть. А может быть и нет. Я полистал вики. Там действительно упоминается Netlib BLAS - The official reference implementation on Netlib, written in Fortran 77.[39]
Плюс, там же про BLAS пишут, что "It originated as a Fortran library in 1979[1] and its interface was standardized by the BLAS Technical (BLAST) Forum, whose latest BLAS report can be found on the netlib website.[2] This Fortran library is known as the reference implementation (sometimes confusingly referred to as the BLAS library) and is not optimized for speed but is in the public domain.[3][4]"
То есть, эталонная реализация действительно была написана на фортране в 1979.
Однако про ATLAS пишут уже "It provides a mature open source implementation of BLAS APIs for C and Fortran77." - кажется, что ключевое слово здесь "for". То есть, этот самый ATLAS можно использовать ДЛЯ фортрана. Но сам ATLAS написан на вполне себе Си. Я скачал исходники с гитхаба, там внутри от фортрана - только тесты (видимо библиотеке на вход подаются файлики фортрана и проверяется, правильно ли они интерпретируются).
OpenBLAS я тоже скачал, так же как и его прародителя GotoBLAS2. Да, там есть исходники на фортране. В папке test. И в папке lapack. Во всех остальных местах лежит чистый Си.

vadimr
00.00.0000 00:00Но сам ATLAS написан на вполне себе Си.
Вообще-то на ассемблере (собственно вычислительное ядро). На Си это (работу с SSE и другими векторными процессорами) написать невозможно.
JustMoose
00.00.0000 00:00Дело не в Си. Дело в компиляторах. Если верить вот этой статье аж от 2015 года (7 лет прошло!), то обычная студия может генерировать SSE из циклов без какого-либо участия программиста.
Там первой строчкой в статье ссылка на зипарь с результирующим ассемблером. И там действительно внутри SSE!
Ну а вообще, в 21 веке оптимизирующие компиляторы стали вполне умными. Можно открыть Голову Дракона (ниже) и полистать. Там, имхо, половина книжки про оптимизацию.
Ахо, Лам, Сети, Ульман. Компиляторы: принципы, технологии и инструментарий, 2-е изд.
vadimr
00.00.0000 00:00Компиляторы-то умные, но сам язык Си не имеет для этого выразительных средств. Попробуйте на Си написать функцию, перемножающую матрицы, и вы получите сначала проблему с чисто формальным определением параметров, а потом невекторизуемый код.
JustMoose
00.00.0000 00:00Ну так не надо использовать Си. Есть же С++. Можно слепить класс для хранения матрицы с интерфейсом на любой вкус, переопределить оператор умножения и радоваться. Про невекторизуемый код - не верю. Если компилятор из статьи смог заоптимизировать один цикл, то что ему мешает оптимизировать вложенный цикл, который нужен для перемножения матриц?
vadimr
00.00.0000 00:00+1Вопрос в том, как эта матрица будет представлена в оперативной памяти. Если как массив указателей на массивы, то не будет регулярности адресов по второму измерению, что сделает невозможной векторизацию. Если руками намастырить монолитную область памяти и явно прописывать адресную арифметику, то оптимизатору будет непросто в этом разобраться, да и чем это лучше ассемблера.
В Фортране массив A (M, N) представляет собой непрерывную область памяти размером M*N элементов. A (*, 1) – первый столбец, непрерывная область памяти. A (1, *) – первая строка, интервал между адресами всех элементов строго равен M. То же самое с текстовыми строками, которые являются массивами символов фиксированной длины. Ну и т.д. Векторизовать это очень просто.

eptr
00.00.0000 00:00+3Если руками намастырить монолитную область памяти и явно прописывать адресную арифметику, то оптимизатору будет непросто в этом разобраться, да и чем это лучше ассемблера.
А если использовать массив массивов, то правильная адресная арифметика уже будет неявно "встроена", и оптимизатору будет в этом "разобраться" куда проще.
vadimr
00.00.0000 00:00+2В Си массив массивов понимается как массив указателей на массивы, а не как двухмерный массив. Там не будет регулярности адресов элементов, вследствие чего невозможны векторные операции над столбцами. Только над строками.
eptr
00.00.0000 00:00Вы проверять пробовали?
#define M 2 #define N 3 #define ELEMS(a) (sizeof (a) / sizeof *(a)) void fun(void) { char const a[M][N] = {0}; printf("sizeof a: %zu\n", sizeof a); printf("&a: %p\n", (void const *)&a); for (size_t m = 0; m < ELEMS(a); ++ m) { printf("\tsizeof a[%zu]: %zu\n", m, sizeof a[m]); printf("\t&a[%zu]: %p\n", m, (void const *)&a[m]); for (size_t n = 0; n < ELEMS(a[m]); ++ n) { printf("\t\t&a[%zu][%zu]: %p\n", m, n, (void const *)&a[m][n]); } } }Результат будет выглядеть примерно так:
sizeof a: 6 &a: 0x7fffc4b8de7a sizeof a[0]: 3 &a[0]: 0x7fffc4b8de7a &a[0][0]: 0x7fffc4b8de7a &a[0][1]: 0x7fffc4b8de7b &a[0][2]: 0x7fffc4b8de7c sizeof a[1]: 3 &a[1]: 0x7fffc4b8de7d &a[1][0]: 0x7fffc4b8de7d &a[1][1]: 0x7fffc4b8de7e &a[1][2]: 0x7fffc4b8de7fВ C массив массивов понимается как массив массивов.
vadimr
00.00.0000 00:00+3Теперь сделайте M и N переменными.
Попробуйте на Си написать функцию, перемножающую матрицы, и вы получите сначала проблему с чисто формальным определением параметров, а потом невекторизуемый код.
eptr
00.00.0000 00:00+2Теперь сделайте M и N переменными.
Сделал:
#define ELEMS(a) (sizeof (a) / sizeof *(a)) void fun(size_t const M, size_t const N) { char a[M][N]; memset(&a, 0, sizeof a); printf("sizeof a: %zu\n", sizeof a); printf("&a: %p\n", (void const *)&a); for (size_t m = 0; m < ELEMS(a); ++ m) { printf("\tsizeof a[%zu]: %zu\n", m, sizeof a[m]); printf("\t&a[%zu]: %p\n", m, (void const *)&a[m]); for (size_t n = 0; n < ELEMS(a[m]); ++ n) { printf("\t\t&a[%zu][%zu]: %p\n", m, n, (void const *)&a[m][n]); } } } #define M 2 #define N 3 int main(void) { fun(M, N); return EXIT_SUCCESS; }Результат:
sizeof a: 6 &a: 0x7ffc19160190 sizeof a[0]: 3 &a[0]: 0x7ffc19160190 &a[0][0]: 0x7ffc19160190 &a[0][1]: 0x7ffc19160191 &a[0][2]: 0x7ffc19160192 sizeof a[1]: 3 &a[1]: 0x7ffc19160193 &a[1][0]: 0x7ffc19160193 &a[1][1]: 0x7ffc19160194 &a[1][2]: 0x7ffc19160195Предвосхищая возможное дальнейшее предложение поработать в таком же стиле с динамически выделенной памятью, сделаю и это:
#define ELEMS(a) (sizeof (a) / sizeof *(a)) void fun(void const *const p, size_t const M, size_t const N) { char const (*const a)[M][N] = p; printf("sizeof a: %zu\n", sizeof *a); printf("&a: %p\n", (void const *)a); for (size_t m = 0; m < ELEMS(*a); ++ m) { printf("\tsizeof a[%zu]: %zu\n", m, sizeof (*a)[m]); printf("\t&a[%zu]: %p\n", m, (void const *)&(*a)[m]); for (size_t n = 0; n < ELEMS((*a)[m]); ++ n) { printf("\t\t&a[%zu][%zu]: %p\n", m, n, (void const *)&(*a)[m][n]); } } } #define M 2 #define N 3 int main(void) { void *const p = calloc(M, N); if (p) { fun(p, M, N); free(p); } return EXIT_SUCCESS; }Результат:
sizeof a: 6 &a: 0x45e2a0 sizeof a[0]: 3 &a[0]: 0x45e2a0 &a[0][0]: 0x45e2a0 &a[0][1]: 0x45e2a1 &a[0][2]: 0x45e2a2 sizeof a[1]: 3 &a[1]: 0x45e2a3 &a[1][0]: 0x45e2a3 &a[1][1]: 0x45e2a4 &a[1][2]: 0x45e2a5В C массив массивов понимается как массив массивов.
vadimr
00.00.0000 00:00+2Переменными сделайте M и N, а не подставляйте вместо них препроцессором константы 2 и 3.
eptr
00.00.0000 00:00+3Переменными сделайте M и N, а не подставляйте вместо них препроцессором константы 2 и 3.
Да, давайте ещё и константность везде поубираем, чтобы она вас не смущала.
И чтобы компилятор не смог ничего лишнего соптимизировать, запутаем способ получения
MиN, да так, чтобы в выражениях для их вычисления ещё и ни единой константы не было.Вариант с VLA:
#define ELEMS(a) (sizeof (a) / sizeof *(a)) void fun(size_t M, size_t N) { char a[M][N]; memset(&a, 0, sizeof a); printf("sizeof a: %zu\n", sizeof a); printf("&a: %p\n", (void *)&a); for (size_t m = 0; m < ELEMS(a); ++ m) { printf("\tsizeof a[%zu]: %zu\n", m, sizeof a[m]); printf("\t&a[%zu]: %p\n", m, (void *)&a[m]); for (size_t n = 0; n < ELEMS(a[m]); ++ n) { printf("\t\t&a[%zu][%zu]: %p\n", m, n, (void *)&a[m][n]); } } } int main(int argc, char **argv) { (void)argv; size_t M = argc + argc; size_t N = argc * (argc + argc) + argc; fun(M, N); return EXIT_SUCCESS; }Это я знаю, что программа будет запускаться без параметров, и
argcбудет равен1.Но компилятор из этого не может исходить, тем более, что я же могу второй раз ту же уже скомпилированную программу и с параметром запустить.
Результат:
sizeof a: 6 &a: 0x7ffca25fa910 sizeof a[0]: 3 &a[0]: 0x7ffca25fa910 &a[0][0]: 0x7ffca25fa910 &a[0][1]: 0x7ffca25fa911 &a[0][2]: 0x7ffca25fa912 sizeof a[1]: 3 &a[1]: 0x7ffca25fa913 &a[1][0]: 0x7ffca25fa913 &a[1][1]: 0x7ffca25fa914 &a[1][2]: 0x7ffca25fa915Вариант с динамически выделяемой памятью:
#define ELEMS(a) (sizeof (a) / sizeof *(a)) void fun(void *p, size_t M, size_t N) { char (*a)[M][N] = p; printf("sizeof a: %zu\n", sizeof *a); printf("&a: %p\n", (void *)a); for (size_t m = 0; m < ELEMS(*a); ++ m) { printf("\tsizeof a[%zu]: %zu\n", m, sizeof (*a)[m]); printf("\t&a[%zu]: %p\n", m, (void *)&(*a)[m]); for (size_t n = 0; n < ELEMS((*a)[m]); ++ n) { printf("\t\t&a[%zu][%zu]: %p\n", m, n, (void *)&(*a)[m][n]); } } } int main(int argc, char **argv) { (void)argv; size_t M = argc + argc; size_t N = argc * (argc + argc) + argc; void *p = calloc(M, N); if (p) { fun(p, M, N); free(p); } return EXIT_SUCCESS; }Результат:
sizeof a: 6 &a: 0x119f2a0 sizeof a[0]: 3 &a[0]: 0x119f2a0 &a[0][0]: 0x119f2a0 &a[0][1]: 0x119f2a1 &a[0][2]: 0x119f2a2 sizeof a[1]: 3 &a[1]: 0x119f2a3 &a[1][0]: 0x119f2a3 &a[1][1]: 0x119f2a4 &a[1][2]: 0x119f2a5Есть ещё идеи?
В C массив массивов понимается как массив массивов, причём независимо от того, какой это массив, обычный или VLA.
Более того, в этом стиле доступна работа и с динамически выделенной памятью, причём даже в этом случае размерности каждого массива не обязаны быть константами времени компиляции.
В этом смысле Fortran не имеет преимуществ перед C.
vadimr
00.00.0000 00:00+2Видите как, уже пришлось перейти к void*, передаче отдельно от массива его размеров и адресной арифметике полувручную. А когда вы ещё учтёте возможность выравнивания, будет совсем вручную.
Причём компилятор-то не знает, что значение M - это длина строки массива, и не может им воспользоваться при загрузке вектора в векторный процессор.
eptr
00.00.0000 00:00+5Видите как, уже пришлось перейти к void*
Почему вы решили, что именно "пришлось"?
Смотрите, как можно совсем без `void *`:
#define ELEMS(a) (sizeof (a) / sizeof *(a)) void fun(size_t M, size_t N, char (*a)[M][N]) { printf("sizeof a: %zu\n", sizeof *a); printf("&a: %p\n", (void *)a); for (size_t m = 0; m < ELEMS(*a); ++ m) { printf("\tsizeof a[%zu]: %zu\n", m, sizeof (*a)[m]); printf("\t&a[%zu]: %p\n", m, (void *)&(*a)[m]); for (size_t n = 0; n < ELEMS((*a)[m]); ++ n) { printf("\t\t&a[%zu][%zu]: %p\n", m, n, (void *)&(*a)[m][n]); } } } int main(int argc, char **argv) { (void)argv; size_t M = argc + argc; size_t N = argc * (argc + argc) + argc; char (*a)[M][N] = calloc(M, N); if (a) { fun(M, N, a); free(a); } return EXIT_SUCCESS; }Результат:
sizeof a: 6 &a: 0x19fb2a0 sizeof a[0]: 3 &a[0]: 0x19fb2a0 &a[0][0]: 0x19fb2a0 &a[0][1]: 0x19fb2a1 &a[0][2]: 0x19fb2a2 sizeof a[1]: 3 &a[1]: 0x19fb2a3 &a[1][0]: 0x19fb2a3 &a[1][1]: 0x19fb2a4 &a[1][2]: 0x19fb2a5передаче отдельно от массива его размеров
Верно, это же C, и вы сами выбрали случай, когда размерности становятся известны только в run-time'е.
Их в любом случае необходимо передавать, только в других языках это происходит "под капотом", и отменить это нельзя, а здесь, хоть и требуется выполнять явную передачу, но, зато этим можно управлять (передавать или не передавать, если не требуется).
и адресной арифметике полувручную
Где здесь, особенно в последнем варианте, адресная арифметика? (1)
Что значит, "полувручную"? (2)
А когда вы ещё учтёте возможность выравнивания, будет совсем вручную.
Функции
malloc/calloc/reallocвозвращают адрес с выравниванием, достаточным для хранения любого стандартного объекта.Если же передаётся адрес настоящего массива, то он, по определению, выровнен.
Зачем вы пытаетесь найти изъяны там, где их нет?
Причём компилятор-то не знает, что значение M - это длина строки массива, и не может им воспользоваться при загрузке вектора в векторный процессор.
Возьмём следующий код (ссылка на godbolt):
#include <stdlib.h> #include <stdio.h> #include <string.h> #define K 1000 #define ELEMS(a) (sizeof (a) / sizeof *(a)) typedef int type; void add(size_t M, size_t N, type (*a)[M][N], type (*b)[M][N], type (*c)[M][N]) { for (size_t m = 0; m < ELEMS(*a); ++m) { for (size_t n = 0; n < ELEMS((*a)[m]); ++n) { (*a)[m][n] = (*b)[m][n] + (*c)[m][n]; } } } void fill(size_t M, size_t N, type (*x)[M][N], type y) { for (size_t i = 0; i < ELEMS(*x); ++i) { for (size_t j = 0; j < ELEMS((*x)[i]); ++j) { (*x)[i][j] = y; } } } int main(int argc, char **argv) { (void)argv; int m = argc + argc; int n = m + argc * argc; size_t M = m * K; size_t N = n * K; type (*a)[M][N] = malloc(sizeof *a); if (a) { type (*b)[M][N] = malloc(sizeof *b); if (b) { fill(M, N, b, m); type (*c)[M][N] = malloc(sizeof *c); if (c) { fill(M, N, c, n); add(M, N, a, b, c); printf("a[0][0]: %i\n", (*a)[0][0]); free(c); } free(b); } free(a); } return EXIT_SUCCESS; }и посмотрим, векторизуется ли он в функциях
addиfill.Функция
fillзаполняет массив одним и тем же значением.Функция
addскладывает поэлементно два массива и поэлементно же кладёт результат в третий.В данном коде во все элементы массива
bкладётся 2, во все элементы массиваcкладётся 3, затем они суммируются, а результат кладётся в массивa.Первый элемент массива
aраспечатывается, чтобы icc не "думал", что, раз массивaпосле заполнения никак не используется, то можно ничего и не вычислять, и не выбрасывал вызов функцииadd.В функции
addвидим в ассемблерном коде gcc следующее:.L5: vmovdqu ymm1, YMMWORD PTR [r15+rdx] vpaddd ymm0, ymm1, YMMWORD PTR [rax+rdx] vmovdqu YMMWORD PTR [r9+rdx], ymm0 add rdx, 32 cmp rdx, r14 jne .L5Видите векторизацию?
Компилятор смог.В функции
fillвидим в ассемблерном коде gcc следующее:vpbroadcastd ymm0, ebx ... .L36: vmovdqu YMMWORD PTR [rdx], ymm0 add rdx, 32 cmp rcx, rdx jne .L36А здесь видите векторизацию?
Компилятор опять смог.Для clang'а и icc от Intel'а всё аналогично.
Если прогнать perf'ом, то получается следующее (у меня локально установлена другая версия gcc, поэтому используемые регистры в ассемблерном коде слегка другие):
14.99 │118: vmovdqu ymm1,YMMWORD PTR [r14+r12*1] 15.00 │ vpaddd ymm0,ymm1,YMMWORD PTR [rax+r12*1] 65.00 │ vmovdqu YMMWORD PTR [rdx+r12*1],ymm0 │ add r12,0x20 │ cmp r12,rdi 5.00 │ ↑ jne 118Видно, что эти инструкции на самом деле работают, а не просто "валяются в коде рядом".
Это означает, что компилятор смог.
Более того, смогли все опробованные мной компиляторы.Вы можете ответить на вопросы, помеченные мной как (1) и (2)?
Итак:
В C массив массивов понимается как массив массивов, причём независимо от того, какой это массив, обычный или VLA.
В этом стиле доступна работа и с динамически выделенной памятью, причём даже в этом случае размерности каждого массива не обязаны быть константами времени компиляции.
Никакой дополнительной адресной арифметики при этом не требуется.
Никаких прочих накладных расходов, связанных с использованием указателей на
void, нет.Передача размерностей массива в рассматриваемом случае не зависит от языка и будет присутствовать в том или ином виде в любом языке.
Не существует никаких проблем с выравниванием, специфичных для применяемой техники.
При этом все широко используемые современные компиляторы прекрасно векторизуют код.
В этом смысле Fortran не имеет преимуществ перед C.
Если ещё учесть, что strict aliasing'ом можно управлять с помощью ключевого слова
restrict, то станет очевидно, что в этом смысле Fortran вообще не имеет преимуществ перед C.Напоминаю, что первый пункт в списке выше есть прямое возражение на ваше утверждение:
В Си массив массивов понимается как массив указателей на массивы, а не как двухмерный массив.
vadimr
00.00.0000 00:00+2Хорошо, что Вы тратите своё время и пытаетесь доказательно разобраться в вопросе (поставил бы Вам плюсик в карму, да нельзя дальше увеличивать без статей), но плохо, что при этом игнорируете часть смысла сказанного.
Когда вы в своей функции add обходите массив по строкам, то вы никак не используете его двухмерность. Фактически это проход по одномерному массиву, расписанный в два индекса, и компилятор понимает, что происходит обращение к последовательным ячейкам памяти. Если вы заметите, я изначально писал про перемножение матриц, потому что там таким трюком не обойтись. Если вы в своей функции add переставите местами индексы, например, у массива c (т.е. c[n,m] вместо c[m,n]), то компилятор начинает выдавать уже такую хтонь, которую я затрудняюсь проинтерпретировать.
Далее, вы же сами должны хорошо понимать, что ваш макрос ELEMS работает только по совпадению из-за невыровненности элементов массива на границу, большую их длины. Такое поведение не гарантируется языком Си (уже на той же самой PDP-11 нечётные адреса зачастую были запрещены). Конечно, никакого принципиального значения этот макрос не имеет, можно перейти просто к M и N, но это ещё затруднит работу векторизатора. В том числе на некоторых векторных архитектурах размеры самих векторов должны выравниваться на длину векторных регистров.
Что касается массива указателей, то я был неправ, высказав своё утверждение в таком виде, оно неверно. В целом я думал о том, что написано ниже, и неудачно выразил свою мысль.
Теперь, о практике программирования в целом. Думаю, вы согласитесь, что по целому ряду причин мало кто в реальной жизни будет писать функции так, как это сделано в вашем демонстрационном коде. Программист на С и особенно С++ будет выбирать решение, более соответсвующее принципу инкапсуляции и более совместимое со стандартной библиотекой. А это значит, что все эти трюки с массивами в С крайне малоприменимы, на практике там будет другая структура данных. В отличие от Фортрана, где податься некуда, и сложные структуры данных, как правило, представляются в виде набора массивов.
Наконец, как тут уже отмечалось в комментариях выше, не будем забывать, что фортрановскую программу можно простой перекомпиляцией перевести с SSE на CUDA.
eptr
00.00.0000 00:00Хорошо, что Вы тратите своё время и пытаетесь доказательно разобраться в вопросе
А как ещё иначе?
Авторитетов же не существует.К тому же, чтобы навыки не "загнивали", их необходимо тренировать, а на это так и так уходит время.
но плохо, что при этом игнорируете часть смысла сказанного.
Это, видимо, потому, что я возражал по конкретному пункту о необходимости явно прописывать адресную арифметику, а потом по конкретному другому пункту касательно "устройства" массива массивов.
Когда вы в своей функции add обходите массив по строкам, то вы никак не используете его двухмерность. Фактически это проход по одномерному массиву, расписанный в два индекса, и компилятор понимает, что происходит обращение к последовательным ячейкам памяти.
Ну, то есть, не требуется прописывать адресную арифметику, и компилятор может соптимизировать, поскольку "понимает", с чем работает.
Если вы заметите, я изначально писал про перемножение матриц, потому что там таким трюком не обойтись.
Во-первых, это никакой не трюк, а штатная возможность, абсолютно переносимая и обязанная одинаковым образом быть поддержанной всеми компиляторами, претендующими на соблюдение стандарта.
А, во-вторых, основной фоновый контекст у нас здесь – преимущество (или отсутствие такового) Fortran'а перед C в рассматриваемой части.Если вы в своей функции add переставите местами индексы, например, у массива c (т.е. c[n,m] вместо c[m,n]), то компилятор начинает выдавать уже такую хтонь, которую я затрудняюсь проинтерпретировать.
Вы хотите сказать, что компилятор Fortran'а аналогичный код в тех же условиях сумеет векторизовать?
Далее, вы же сами должны хорошо понимать, что ваш макрос ELEMS работает только по совпадению из-за невыровненности элементов массива на границу, большую их длины.
Макрос
ELEMSработает для любых случаев.Элементы массива (и сам массив, а также массив массивов и далее рекурсивно) выровнены согласно требованию к выравниванию для типа элемента массива.
Между элементами массива нет "пропусков", они расположены "вплотную" друг к другу, и sizeof массива строго равен количеству его элементов, умноженному на sizeof его элемента.Такое поведение не гарантируется языком Си (уже на той же самой PDP-11 нечётные адреса зачастую были запрещены).
Расположение элементов массива "влотную", без "пропусков" гарантируется стандартом, и это необходимое условие для того, чтобы адресная арифметика была в принципе работоспособной.
Макрос
ELEMSпрямо опирается на гарантии стандарта и именно поэтому работает для любых случаев.В структурах между полями могут быть пропуски, но там и типы у полей могут быть разными, и, соответственно, у них могут быть разные размеры и требования по выравниванию, что и может приводить к подобным эффектам.
Конечно, никакого принципиального значения этот макрос не имеет, можно перейти просто к M и N, но это ещё затруднит работу векторизатора.
Нет необходимости переходить к
MиN, отказываясь от данного макроса по надуманной причине, поэтому у "векторизатора" затруднений, связанных с этим, не появится.В том числе на некоторых векторных архитектурах размеры самих векторов должны выравниваться на длину векторных регистров.
Язык C предоставляет средства для реализации повышенных требований к выравниванию, поэтому здесь также нет никаких проблем.
Короткий пример (ссылка на godbolt):
#include <stdlib.h> #include <stdio.h> #include <stdalign.h> int main(void) { int a0[16]; alignas(sizeof a0) int a1[16]; printf("&a0: %p, sizeof a0: %zu, alignof a0: %zu\n", (void *)&a0, sizeof a0, alignof a0); printf("&a1: %p, sizeof a1: %zu, alignof a1: %zu\n", (void *)&a1, sizeof a1, alignof a1); return EXIT_SUCCESS; }Результат (взятый у clang'а, потому что у gcc он не интересный):
&a0: 0x7ffe2b64b2b0, sizeof a0: 64, alignof a0: 4 &a1: 0x7ffe2b64b240, sizeof a1: 64, alignof a1: 64По адресу видно, что
a0реально выровнен на границу 16, аa1– уже на границу 64.
Явный код для выравнивания на 64 для массиваa1можно также увидеть в ассемблере у каждого из компиляторов.Что касается массива указателей, то я был неправ, высказав своё утверждение в таком виде, оно неверно. В целом я думал о том, что написано ниже, и неудачно выразил свою мысль.
Но доказательств для этого потребовалось больше, чем, я думал, будет достаточно.
Теперь, о практике программирования в целом. Думаю, вы согласитесь, что по целому ряду причин мало кто в реальной жизни будет писать функции так, как это сделано в вашем демонстрационном коде.
Я не могу судить о реальной жизни в широком смысле, ибо недостаточно информации, поэтому не могу согласиться или не согласиться.
Да, junior'ы не смогут такое написать, и даже, наверное, часть middle'ов не сможет, особенно вариант с VLA, но достаточно им по-настоящему объяснить, как устроены типы в языке, и на чём базируется адресная арифметика, а не как это часто делают современные преподаватели, и, после некоторого времени, потраченного на практику, такое даже junior'ы смогут, здесь нет чего-то заумного.
Программист на С и особенно С++ будет выбирать решение, более соответсвующее принципу инкапсуляции и более совместимое со стандартной библиотекой.
Использование указателя на массив никак не ограничивает инкапсуляцию, а у программиста на C++, кроме указателей, ещё наличествуют в активе и ссылки, он может использовать ссылку на массив.
Поскольку речь идёт об инкапсуляции, то реализация может быть любой.
Если кто-то ничего не знает, кроме как о
std::vector, (как ещё понять "более совместимое со стандартной библиотекой", но при этом не дающее возможности применить указатель на массив?) это не повод огульно обобщать на большинство (как ещё понять "программист на С и особенно С++ будет выбирать"?).К тому же, сейчас активно используется такая процедура как review, что нивелирует огрехи, которые могут допустить не слишком искушённые программисты.
А это значит, что все эти трюки с массивами в С крайне малоприменимы, на практике там будет другая структура данных.
Повторюсь, это никакой не трюк, это совершенно штатная и абсолютно переносимая возможность языка.
Там будет та структура данных, которую выберет программист.
Если программист слабо владеет языком, он легко может выбрать неподходящее решение.
Для этого обычно в компаниях бывают программисты, кототрые хорошо владеют используемым языком, и которые на review укажут, как следует изменить решение, чтобы оно стало эффективным.И уже после этого там будет та структура данных, которую выберет грамотный программист, и которая эффективна для используемого языка.
В отличие от Фортрана, где податься некуда, и сложные структуры данных, как правило, представляются в виде набора массивов.
То есть, получается, что в этом месте C имеет преимущество перед Fortran'ом, поскольку даёт больше возможностей и более гибок.
Наконец, как тут уже отмечалось в комментариях выше, не будем забывать, что фортрановскую программу можно простой перекомпиляцией перевести с SSE на CUDA.
Выходит, это единственное преимущество Fortran'а в данной части.
vadimr
00.00.0000 00:00Между элементами массива нет "пропусков", они расположены "вплотную" друг к другу, и sizeof массива строго равен количеству его элементов, умноженному на sizeof его элемента.
Расположение элементов массива "влотную", без "пропусков" гарантируется стандартом,
Из какого места стандарта вы делаете такой вывод?
и это необходимое условие для того, чтобы адресная арифметика была в принципе работоспособной.
Чтобы была работоспособной адресная арифметика, достаточно того, чтобы инкремент указателя на элемент массива давал следующий элемент.
Как вы вообще представляете себе char [] на машине с невозможностью обращения по нечётному адресу (как, например, некоторые модели PDP, хорошо известные разработчикам Си)?
В близнеце Си Паскале – так там специально даже есть синтаксис packed array.
eptr
00.00.0000 00:00+1Из какого места стандарта вы делаете такой вывод?
6.2.5 Types
...
20 Any number of derived types can be constructed from the object and function types, as follows:
— An array type describes a contiguously allocated nonempty set of objects with a particular member object type, called the element type.
...На всякий случай, ссылка на перевод слова contiguous.
Чтобы была работоспособной адресная арифметика, достаточно того, чтобы инкремент указателя на элемент массива давал следующий элемент.
Тогда все массивы, а также области памяти, интерпретируемые как массивы, будут "дырявыми".
Но в C они не могут быть "дырявыми".
Как вы вообще представляете себе char [] на машине с невозможностью обращения по нечётному адресу (как, например, некоторые модели PDP, хорошо известные разработчикам Си)?
Невозможность обратиться по нечетному адресу характерна лишь для регистров R6 (PC) и R7 (SP).
Для остальных регистров проблемы обратиться к байту, в том числе, по нечётному адресу, нет.Очень просто представляю: байтовые инструкции.
В близнеце Си Паскале – так там специально даже есть синтаксис packed array.
Pascal – очень условный "близнец" C.
vadimr
00.00.0000 00:00Это ваша вольная интерпретация стандарта.
20 Any number of derived types can be constructed from the object and function types, as follows:
— An array type describes a contiguously allocated nonempty set of objects with a particular member object type, called the element type.
Обратите внимание, что contiguously allocated относится к objects, а element type – к member object. Отсюда никак не следует, что тип элемента, т.е. тип объекта-члена – это то же самое, что непрерывно размещённые в памяти объекты. Буквально: размещённый набор объектов с определёнными типами объектов-членов.
Да и по сути, машин с адресацией памяти словами – вагон и маленькая тележка.
В том, что на практике бывают массивы с дырками между элементами, я совершенно уверен, хотя лично с языком Си на таких машинах не работал. Более интересный вопрос другой: бывают ли в Си многомерные массивы с дополнительными дырками между строками? В принципе, это не запрещено, и компилятор мог бы увеличивать длину строк до длины векторного регистра для более эффективной векторизации в какой-нибудь архитектуре, но я о такой автоматической оптимизации нигде не читал, хотя советы вручную увеличивать размеры массивов встречал.
eptr
00.00.0000 00:00Это ваша вольная интерпретация стандарта.
Точно моя?
Обратите внимание, что contiguously allocated относится к objects, а element type – к member object. Отсюда никак не следует, что тип элемента, т.е. тип объекта-члена – это то же самое, что непрерывно размещённые в памяти объекты. Буквально: размещённый набор объектов с определёнными типами объектов-членов.
Здесь имеется ввиду, что тип у всех объектов должен быть одинаковый.
И объекты не просто размещённые, а смежно или непрерывно размещённые.Переводчик №1 (ссылка): "Тип массива описывает смежно выделенный непустой набор объектов с определенным типом объекта-члена, называемым типом элемента".
Переводчик №2 (ссылка): "Тип массива описывает непрерывно выделенный непустой набор объектов с определенным типом объекта-члена, называемым типом элемента".
"Смежно/непрерывно выделенный непустой набор объектов".
В отличие от структур, о которых можно прочесть в следующем предложении стандарта:
— A structure type describes a sequentially allocated nonempty set of member objects (and, in certain ircumstances, an incomplete array), each of which has an optionally specified name and possibly distinct type.
Переводчик №1 (ссылка): "Тип структуры описывает последовательно выделенный непустой набор объектов-членов (и, при определенных обстоятельствах, неполный массив), каждый из которых имеет опционально заданное имя и, возможно, отдельный тип".
Переводчик №2 (ссылка): "Тип структуры описывает последовательно размещенный непустой набор объектов-членов (и, в некоторых случаях, неполный массив), каждый из которых имеет необязательно указанное имя и, возможно, отдельный тип".
Для массивов размещение смежное/непрерывное, а для структур – лишь последовательное (упорядоченное по порядку объявления полей) без требования непрерывности размещения.
И тип элементов – для массивов один и тот же, для структур – нет.
Да и по сути, машин с адресацией памяти словами – вагон и маленькая тележка.
Вы уже приводили пример PDP-11, и выяснилось, что никакой проблемы нет, ибо наличествует и адресация байтами, и в этом случае доступны и нечётные адреса.
В том, что на практике бывают массивы с дырками между элементами, я совершенно уверен, хотя лично с языком Си на таких машинах не работал.
Чья-либо уверенность в данном случае ничего не проясняет.
Тем более, если человек не работал с языком C.Более интересный вопрос другой: бывают ли в Си многомерные массивы с дополнительными дырками между строками?
Нет, не бывают.
В принципе, там и многомерных не бывает, бывают массивы массивов.
vadimr
00.00.0000 00:00К переводам претензий нет, правильные переводы. Претензия к тому, почему вы думаете, что object и member object – это одна и та же сущность. Это же не ведический санскрит, чтобы при каждом упоминании предмет описывать новыми словами. Если б было по-вашему, написали бы “contiguously allocated member objects”.
Здесь структура примерно такая же, как в предложении “ящик доверху заполнен пирожками с ароматными яблоками”. Это не то же самое, что “ящик заполнен яблоками”. Contiguously allocated objects относится к ячейкам памяти (или, говоря наиболее корректно, к единицам размещения в памяти), а member objects – к содержащимся в них элементам массива.
eptr
00.00.0000 00:00К переводам претензий нет, правильные переводы. Претензия к тому, почему вы думаете, что object и member object – это одна и та же сущность. Это же не ведический санскрит, чтобы при каждом упоминании предмет описывать новыми словами. Если б было по-вашему, написали бы “contiguously allocated member objects”.
Рассмотрение набора смежных объектов определённым образом концептуально вводит новую сущность – массив – с новыми терминами.
Если рассматривать этот набор как массив, то теперь это не просто объекты, а элементы массива, но несмотря на то, что с разных точек зрения они называются по-разному, – то объекты, то элементы массива, – от этого они не становятся чем-то другим.

zkutch
00.00.0000 00:00Еще один аргумент в пользу непрерывности расположения элементов массива это (С2011) 6.5.2.1 Array subscripting, где читаем "E1[E2] is identical to (*((E1)+(E2)))". Учитывая однотипность это и есть гарантия непрерывности.
vadimr
00.00.0000 00:00+1Это говорит только о том, что элементы массива находятся друг от друга на расстоянии одного инкремента указателя на массив. Это и есть адресная арифметика. Но она никак не говорит о том, что единичный инкремент строго равен размеру элемента, и, как следствие - не о том, что нет дырок.
Дырки образуются как раз от участков памяти, на которые невозможно (или нежелательно по соображениям эффективности) указать самостоятельным адресом. Нигде в стандарте не указано, что дискретность адреса не может превышать минимальный размер переменной.
eptr
00.00.0000 00:00Дырки образуются как раз от участков памяти, на которые невозможно (или нежелательно по соображениям эффективности) указать самостоятельным адресом. Нигде в стандарте не указано, что дискретность адреса не может превышать минимальный размер переменной.
Однако, сказано, что массив представляет из себя "смежно/непрерывно выделенный непустой набор объектов".
В качестве переменной с нежелательными участками памяти можно привести переменную следующего типа:
struct S { int i; char c; }Если
sizeof(int)есть 4, то размер переменной такого типа можно считать равным 5.В силу невозможности или нежелательности нарушения выравнивания для элементов такого типа в массиве, необходимо добавить ещё 3 байта, и тогда в массиве таких переменных между ними будет 8 байт.
И вот здесь возникает два возможных вИдения происходящего:
Размер переменной данного типа есть 5, адресная арифметика "щёлкает" на 8 байт, и имеет место наличие "дырок" между элементами массива.
Размер переменной данного типа есть 8, то есть, "дырка" входит в состав переменой данного типа, адресная арифметика "щёлкает" на 8 байт, имеет место отсутствие "дырок" между элементами массива.
В силу требования для массивов смежности/непрерывности размещения элементов, в C единственно возможно только второе вИдение.
Зачастую возможно указать компилятору для такой структуры нарушать выравнивание, и тогда размер структуры будет равен 5.
Но и адресная арифметика в массиве с таким типом элемента начнёт "щёлкать" на 5 байт, а не на 8.
Таким образом, даже в тех случаях, когда возникают "дырки", в массиве этих "дырок" все равно нет за счёт вхождения этих "дырок" в состав переменных такого типа (и элементов массива, если они находятся в составе массива) и, как следствие, увеличивающих
sizeofтаких переменных на размер "дырки".
vadimr
00.00.0000 00:00В силу требования для массивов смежности/непрерывности размещения элементов, в C единственно возможно только второе вИдение.
Никто нигде не обещал, что элементом массива является сам тот объект, который хранится в элементе массива. Элемент массива – это адресуемая область памяти, предназначенная для хранения объекта указанного типа, не более того. Поэтому возможны оба варианта.
eptr
00.00.0000 00:00Хорошо, попробуем на этот момент взглянуть ещё с такой стороны.
Вы говорите, что хранящийся в массиве объект может не являться элементом массива, имея ввиду, что у них, вследствие этого, могут быть разные размеры (у элемента массива, очевидно, – больше), из-за чего в массиве между элементами и могут возникнуть "дырки", когда мы рассматриваем элементы массива, верно?
В стандарте сказано, что "тип массива описывает непрерывно выделенный непустой набор объектов с определенным типом объекта-члена, называемым типом элемента".
А именно, что элемент массива имеет тип, и что он совпадает с типом объекта-члена.
Вы же не считаете, что если тип, имеющийся у объекта-члена, назвать типом элемента, то тип у элемента может "в процессе называния" стать другим, отличным от типа объекта-члена?
Для всех типов данных определена операция
sizeof.Результат этой операции зависит исключительно от типа.
Он не зависит от "происхождения" типа, то есть, в результате какой операции у выражения получился такой тип, или в состав какой объемлющей структуры данных входит объект, размер типа которого мы вычисляем.
Соответственно, если типы объектов-членов и элементов массива совпадают, то операция
sizeofдаст для них строго идентичный результат, и, соответственно, выходит, что у объектов-членов и элементов массива строго одинаковый размер.Если объекты-члены выделены смежно/непрерывно (по определению массива), то и элементы массива будут расположены смежно/непрерывно в силу одинаковости размеров объектов-членов и элементов массива.
Или, по-другому: раз у объектов-членов и элементов массива одинаковый размер, то они вынуждены являться друг другом, то есть, быть одной и той же сущностью.
vadimr
00.00.0000 00:00Вы делаете подмену одного понятия другим в самом начале, и дальше уже производите логический вывод из неверной предпосылки.
тип массива описывает непрерывно выделенный непустой набор объектов с определенным типом объекта-члена, называемым типом элемента
не означает, что
элемент массива имеет тип, и что он совпадает с типом объекта-члена
Элементом массива является объект, который представляет собой адресуемую область памяти. Эта область памяти сама по себе не имеет никакого типа, однако содержит объект-член определённого типа. По сути, массив – это контейнер, и когда мы говорим об элементах массива, то имеем в виду ячейки этого контейнера. В которые уложены значения того типа, от которого произведён массив.
Ячейка массива, как таковая, не является частью системы типов языка Си, у неё нет ни типа, ни размера в смысле sizeof. Также как в Си нет типа и размера, например, у функции, хотя мы понимаем, что она в конечном итоге может быть представлена каким-то вполне конкретным набором байтов в машинном коде, имеющим размер с точки зрения машины. Или у оператора присваивания.
Когда мы выясняем тип и размер элемента массива в смысле семантики языка Си, то в действительности получаем тип и размер значения, хранящегося в этом элементе.
eptr
00.00.0000 00:00Элементом массива является объект, который представляет собой адресуемую область памяти. Эта область памяти сама по себе не имеет никакого типа, однако содержит объект-член определённого типа.
Не объект, а объекты, которые "уложены" в этой памяти смежно/непрерывно, и между ними нет промежутков.
То есть, сначала объекты смежно/непрерывно уложены в памяти, а потом это рассматривается как массив.
Если аппаратная архитектура не позволяет смежно/непрерывно уложить значащие биты значения, значит, те незначащие, которые необходимо добавить, чтобы "упереться" в памяти в начало значащих битов следующего значения, и которые мы здесь называем "дыркой", придётся, с точки зрения уже языка C, а не аппаратной архитектуры, "включить" в состав объекта, чтобы получить смежную/непрерывную "укладку".
Без такой "укладки" объектов массива быть не может, ибо это – необходимое условие в его определении.
И выход здесь один – включить незначащие биты в состав объекта.
По сути, массив – это контейнер, и когда мы говорим об элементах массива, то имеем в виду ячейки этого контейнера. В которые уложены значения того типа, от которого произведён массив.
В определении сначала – "плотная" укладка объектов.
Ячейка массива, как таковая, не является частью системы типов языка Си, у неё нет ни типа, ни размера в смысле sizeof. Также как в Си нет типа и размера, например, у функции, хотя мы понимаем, что она в конечном итоге может быть представлена каким-то вполне конкретным набором байтов в машинном коде, имеющим размер с точки зрения машины. Или у оператора присваивания.
Функция не является типом данных, она является "типом исполнения".
Для неё не определена операция
sizeof, поэтому не может быть определено ещё множество операций, включая присваивание и адресную арифметику.Более того, функция может состоять из множества не смежных между собой частей, поэтому принципиально не может быть описана как тип данных с адресом и размером.
Лучше вернуться к типам данных.
Когда мы выясняем тип и размер элемента массива в смысле семантики языка Си, то в действительности получаем тип и размер значения, хранящегося в этом элементе.
Здесь, исходя из определения массива, первично смежное/непрерывное размещение объектов и только потом уже их рассмотрение в качестве массива.
Артефакты аппаратной архитектуры, не позволяющие разместить значения какого-то архитектурного (а не C-шного) типа смежно/непрерывно, решаются включением уже в C-шный тип тех незначащих бит, которые мы называем "дыркой" и которые необходимо добавить, чтобы достигнуть по памяти начала значащих бит следующего значения, лежащего в памяти.
Таким образом, с точки зрения некоторой аппаратной архитектуры, "дырки" есть, но изнутри C их нет, потому что они, с точки зрения C, включены в каждый объект, даже в тех случаях, когда объект является отдельной переменной и не является элементом массива.
Вы смотрите на вещи с точки зрения аппаратной архитектуры, и тогда "дырки", несомненно, есть.
Но изнутри C эта же аппаратная архитектура пропущена сквозь призму абстрактной машины C, которая "обходит" подобные артефакты аппаратной архитектуры путём включения её "дырок" в состав объекта.
Если бы мы "смотрели" на мир из ассемблерного кода, тогда мы бы "сняли с себя очки абстрактной машины C", и "дырки" бы существовали или отсутствовали в зависимости от точки зрения, рассматриваем мы элементы массива в C-шном стиле или в том стиле, в котором их рассматриваете вы.
Но, коль скоро мы смотрим на это изнутри C, "открывающийся вид" становится однозначным, "бездырочным", несмотря на то, что "под капотом" "дырки" есть.
Вот такой получается парадокс, как с тем сусликом:
Видишь изнутри C дырки?
Нет.
И я нет, а они – есть.
zkutch
00.00.0000 00:00Но также не говорится, что единичный инкремент не равен размеру типа. Кстати, как вы сами согласны, если они равны, то и дырок нет.
С другой стороны фразу "set of objects with a particular member object type" (6.2.5, 20) я понимаю как "набор объектов с определенным типом объекта-члена" т.е. декларируемая вами выше разница между object и member object как разница размером ячеек и размером расположенных в них объектах не обязательна. Эта фраза просто и только говорит о том, что у всех членов набора тип один и тот же.
И, как пример, возьмем например массив char-ов т.е. каждый член массива занимает байт. И пусть баит же есть минимальное адресуемое пространство. Думаю да, но все равно спрошу: согласны ли вы с тем, что в этом случае дырок нет?
p.s. я ограничен одним часом на один коментарий, так, что запоздалость ответа не сочтите за невнимательность.
vadimr
00.00.0000 00:00Конечно, эта разница не обязательна. Более того, в подавляющем большинстве случаев её и нет, иначе бы и никаких дискуссий не возникало. Если на машине универсальная байтовая адресация, то дырок не будет.
zkutch
00.00.0000 00:00Ну тогда выход получается очень простым. Стандарт не требует точного размера байта, есть только ограничение снизу, чтобы байт содержал "any member of the basic character set" (3.6). Поэтому достаточно минимальное адресуемое пространство в данной среде объявить байтом. Все остальные основные типы кратны ему, так, что дырок не будет. Зачем делать их различными и заранее обрекать ситуации на дырки? И, не могли бы ли вы привести конкретный пример среды и имплементации массива с дырками для хотя бы одного из основных типов?
p.s. Кстати сам байт тоже "is composed of a contiguous sequence of bits". Следуя вашему предположению можно и бит теперь разделить на два понятия и имет дырки на битовом уровне.
eptr
00.00.0000 00:00;
Так "дырявые" же структуры, а не массив.
А массив состоит из структур, а не из элементов структур.Вот пример (ссылка на godbolt):
#include <stdlib.h> #include <stdio.h> struct S { int i; char c; }; int main(void) { struct S s = {0}; printf("sizeof s: %zu\n", sizeof s); printf("sizeof s.i: %zu\n", sizeof s.i); printf("sizeof s.c: %zu\n", sizeof s.c); struct S a[3] = {0}; puts(""); printf("sizeof a: %zu\n", sizeof a); printf("sizeof a[0]: %zu\n", sizeof a[0]); return EXIT_SUCCESS; }Результат:
sizeof s: 8 sizeof s.i: 4 sizeof s.c: 1 sizeof a: 24 sizeof a[0]: 8Видно, что сумма размеров полей структуры на 3 байта меньше размера структуры.
В структуре – дыра, причём, с краю, а не в середине, но она принадлежит структуре, входит в неё, является её неотъемлемой частью.
Именно поэтому размер структуры равен 8.Массив структур в качестве элементов имеет объекты типа
struct Sразмером 8 байт.
Количество элементов – 3.
Размер массива – 24.Между элементами массива, каждый из которых имеет размер 8 байт, нет никаких дыр.
Они есть внутри каждого элемента, но это – внутреннее свойство типа элемента, а не свойство самого массива.Адресная арифметика "щёлкает" на размер элемента и абстрагируется от его внутренних свойств.
Поэтому ей все равно, есть дыры в каждом из элементов, нет, сколько их и какого они размера.Единственное, что её "заботит" – размер элемента.
vadimr
00.00.0000 00:00Соглашусь с вами в том, что вы убедительно показали, что данный пример ничего не доказывает по сути обсуждения.
Что касается адресной арифметики, то ей наплевать и на размер элемента тоже. Ей важны собственно адреса элементов.
eptr
00.00.0000 00:00+1Соглашусь с вами в том, что вы убедительно показали, что данный пример ничего не доказывает по сути обсуждения.
Это потому, что вы не связываете адресную арифметику с размером элемента.
Что касается адресной арифметики, то ей наплевать и на размер элемента тоже. Ей важны собственно адреса элементов.
Размер элемента является фундаментальнейшей и определяющей сущностью для адресной арифметики, для неё нет ничего важнее.
struct S { int i; char c; }; struct S * fun(struct S *p) { return p + 1; }Если посмотреть, во что транслируется
fun, то мы увидим следующее (ссылка на godbolt):fun: lea rax, [rdi+8] retОткуда компилятор знает, что надо на 8 "шагнуть"?
Он совсем не знает, откуда вообще взялся этот указатель: на элемент массива он изначально указывает, на поле структуры или вообще, на отдельную переменную.Более того, могут быть различные вызовы этой, одной и той же, функции с указателями на различные, в смысле предыдущего абзаца, объекты, а обработка-то должна быть какой-то одной: указатель не несёт в себе информации о том, в составе чего находится объект.
Поэтому на что адресной арифметике точно плевать, так это – на происхождение указателя.
Но ей точно не плевать на размер типа данных, на который указывает указатель.
Именно потому, что размерstruct Sсоставляет 8 байт, и только поэтому, численное значение указателя увеличивается на 8.
В состав чего входит объект, а также то, как он устроен внутри, имеют для адресной арифметики строго нулевое значение.
Для неё важен исключительно размер элемента и только он.Вот пример (ссылка на godbolt):
#include <stdlib.h> #include <stdio.h> struct S; void fun0(struct S *p) { printf("p: %p\n", (void *)p); #if 0 printf("sizeof *p: %zu\n", sizeof *p); p++; #endif printf("p: %p\n", (void *)p); } struct S { int i; char c; }; void fun1(struct S *p) { printf("p: %p\n", (void *)p); printf("sizeof *p: %zu\n", sizeof *p); p++; printf("p: %p\n", (void *)p); } int main(void) { struct S s; fun1(&s); return EXIT_SUCCESS; }Если раскомментировать закомментированный код, то, несмотря на то, что функции
fun0иfun1станут идентичными, сразу же возникнет ошибка:<source>: In function 'fun0': <source>:9:43: error: invalid application of 'sizeof' to incomplete type 'struct S' 9 | printf("sizeof *p: %zu\n", sizeof *p); | ^ <source>:10:10: error: increment of pointer to an incomplete type 'struct S' 10 | p++; | ^~Во время определения функции
fun0структураstruct Sещё не определена, она только объявлена, а это значит, кроме прочего, что неизвестен её размер.Именно потому, что адресная арифметика не существует без размера элемента, ругань относится не только к операции
sizeof, но и к операции инкремента указателя.Но как только структура определена, и становится известен её размер, у компилятора, при компиляции функции
fun1, претензии пропадают не только к операцииsizeof, но и к инкременту указателя.А что изменилось-то?
Стал известен размерstruct S.
И этого оказалось совершенно достаточно.То есть:
Для работы адресной арифметики строго необходим размер типа, на который указывает указатель.
Кроме размера типа, адресной арифметике больше ничего не нужно, будь то происхождение объекта или его внутренняя структура, – это никак не влияет на адресную арифметику.
vadimr
00.00.0000 00:00+2Вы путаете две вещи: размер типа, на который указывает указатель, и размер ячейки памяти, в которой размещено значение этого типа. Они чаще всего совпадают (в x86 всегда), но это не значит, что они одно и то же.
Если вспомнить, например, машину, на которой Вирт реализовывал Паскаль – CDC 6000 – то там память состояла из 60-битовых слов, к частям которых адресоваться было невозможно. Поэтому там отдельно рассматривался тип array of char, где каждый символ записывался по своему адресу, и packed array of char, где несколько символов (видимо, 10 6-битных) упаковывались в одно слово и имели общий адрес памяти. Также там могли целые упихиваться в 30-битные полуслова и 15-битные четвертьслова. А адрес был 18-разрядным, указывая на 60-битовые слова и адресуя таким образом чуть менее 2 мегабайт памяти. Я не думаю, что для CDC 6000 был реализован компилятор Си, но это, тем не менее, пример реальной архитектуры.
Отсюда видно, что инкременты указателей и значения, возвращаемые функцией sizeof, в общем случае не обязаны как-либо соотноситься между собой.
eptr
00.00.0000 00:00+2Вы путаете две вещи: размер типа, на который указывает указатель, и размер ячейки памяти, в которой размещено значение этого типа. Они чаще всего совпадают (в x86 всегда), но это не значит, что они одно и то же.
Речь о языке C, поэтому не путаю.
Программа на языке C исполняется в абстрактной машине.
Чем сильнее свойства железа отличаются от требований к абстрактной машине, тем больше требуется программной поддержки от реализации, чтобы "изнутри языка" всё выглядело так, как будто исполнение происходит в абстрактной машине.Если вспомнить, например, машину, на которой Вирт реализовывал Паскаль – CDC 6000 – то там память состояла из 60-битовых слов, к частям которых адресоваться было невозможно. Поэтому там отдельно рассматривался тип array of char, где каждый символ записывался по своему адресу, и packed array of char, где несколько символов (видимо, 10 6-битных) упаковывались в одно слово и имели общий адрес памяти. Также там могли целые упихиваться в 30-битные полуслова и 15-битные четвертьслова.
Все объекты в программе на C должны иметь уникальные адреса. Элементы массива – тоже объекты, и поэтому тоже должны иметь уникальные адреса. В результате, реализации языка C с таким упакованным массивом невозможны на данном железе.
Я не думаю, что для CDC 6000 был реализован компилятор Си, но это, тем не менее, пример реальной архитектуры.
Это – возможно, но будет выглядеть достаточно уродливо и несколько не эффективно.
Если минимально адресуемая единица – 60 бит, значит,charна этой платформе будет 60-битным, и препроцессорная константаCHAR_BITбудет иметь значение 60.Отсюда видно, что инкременты указателей и значения, возвращаемые функцией sizeof, в общем случае не обязаны как-либо соотноситься между собой.
Из того, что программа на языке C исполняется в абстрактной машине, следует, что любые попытки сослаться на особые свойства железа не состоятельны.
5.1.2.3 Program execution
1 The semantic descriptions in this International Standard describe the behavior of an abstract machine in which issues of optimization are irrelevant.
vadimr
00.00.0000 00:00Если сделать 60-битный char (и остальные типы), то будет невозможно описать упакованную структуру, и расположенные в памяти символы и целые числа вообще будут недоступны программе на Си, за исключением младших частей слов.
eptr
00.00.0000 00:00Если сделать 60-битный char (и остальные типы), то будет невозможно описать упакованную структуру
Видимо, невозможно.
и расположенные в памяти символы и целые числа вообще будут недоступны программе на Си, за исключением младших частей слов.
Половинки и четвертинки могут быть доступны за счёт использования битовых полей струткур.
Для конкретных длин полей (15 и 30) компилятор мог бы задействовать соответствующие инструкции.Но, конечно, эта архитектура – не для C.
vadimr
00.00.0000 00:00Повторюсь, это никакой не трюк
Вы не забывайте, что всеми этими макросами, sizeof'ами, циклами, преобразованиями пойнтеров туда и обратно вы расписываете аналог следующего фортрановского кода:
allocate (a (M, N), b (M, N), c (M, N))b = mmc = nna = b + c
vadimr
00.00.0000 00:00Посмотрел, кстати – gfortran это сложение массивов транслирует в ОДНУ векторную команду paddb.
Тут поинтересней сделал, чтобы случайные числа были. Но результат тот же:
program main integer*1, allocatable :: a (:,:), b (:,:), c (:,:) integer :: m, n, mm, nn, i, j real :: u call random_number (u) m = floor (u * 100) call random_number (u) n = floor (u * 100) allocate (a (m,n), b (m, n), c (m, n)) do j=1, N do i=1, M call random_number (u) b (i, j) = floor (u * 100) end do end do nn = 3 c = nn a = b + c print *, a end program maingfortran -O3 -ftree-vectorize -fopt-info-vec -Wall -std=gnu -fimplicit-none -Wno-maybe-uninitialized -static-libgfortran -flto -S test.f90
eptr
00.00.0000 00:00+1Посмотрел, кстати – gfortran это сложение массивов транслирует в ОДНУ векторную команду paddb.
Нет, он транслирует сложение массивов ровно в те же векторные инструкции (в количестве 3-х), в которые транслируется и та программа на C, которую я приводил:
.L18: vmovdqu ymm4, YMMWORD PTR [r12+rax] vpaddb ymm0, ymm4, YMMWORD PTR [r14+rax] vmovdqu YMMWORD PTR [r9+rax], ymm0 add rax, 32 cmp rax, r10 jne .L18Ссылка на godbolt с вашим кодом, я оттуда достал этот фрагмент из ассемблерного листинга для компилятора gfortran (добавил опцию
-march=native, чтобы более эффективные векторные инструкции использовались).Однако, и flang, и ifort (в последнем надо как следует поискать нужное место), выдают для сложения матриц ровно такой же код с точностью до конкретных используемых регистров.
Видите, выясняется, что Fortran не имеет преимуществ в производительности перед C.
eptr
00.00.0000 00:00+1Видимо, процессоры разные у меня и на сайте, вот и инструкции другие.
Процессор там такой (ссылка на godbolt):
Intel(R) Xeon(R) Platinum 8375C CPU @ 2.90GHz
или такой:
AMD EPYC 7R32Но, в любом случае, чудес не бывает, одной инструкцией
paddbобойтись не получится.
vadimr
00.00.0000 00:00Да, всё верно, такой же цикл, просто paddb вместо vpaddb. Я ж не на сервере это делал.
vadimr
00.00.0000 00:00А теперь вернёмся к тому, о чём я писал с самого начала – к обработке двухмерного массива. Подставим в сложение c[n][m] вместо c[m][n]. И то же самое в фортране – вместо простого сложения массивов напишем цикл (наружный цикл по j, так как в фортране массивы хранятся по столбцам):
program main integer*1, allocatable :: a (:,:), b (:,:), c (:,:) integer :: m, n, mm, nn, i, j real :: u call random_number (u) m = floor (u * 100) call random_number (u) n = floor (u * 100) allocate (a (m,n), b (m, n), c (n, m)) do j=1, N do i=1, M call random_number (u) b (i, j) = floor (u * 100) end do end do nn = 3 c = nn do j=1, N do i=1, M a (i,j) = b (i,j) + c (j,i) end do end do print *, a end program mainАссемблерный код в фортране не сильно изменился, там такая же команда paddb / vpaddb в чуть более сложном окружении. А сишный кодогенератор пошёл вразнос (я уже писал, что не могу проинтерпретировать увиденное).

Refridgerator
00.00.0000 00:00С интересом смотрю на ваши баттлы. Но почему примеры такие примитивные? Нет проблем в оптимизации и векторизации банального сложения. Возьмите хотя бы свёртку что ли или преобразование какое-нибудь интегральное небанальное.
vadimr
00.00.0000 00:00Замечание, по большому счёту, справедливое. Но тут уже на этапе сложения от чтения ассемблерного кода иногда ум заходит за разум, а небанальное преобразование в ассемблерном виде оценить будет совсем затруднительно. Разве что непосредственно измерением времени. Но надо сначала закончить со сложением.
Refridgerator
00.00.0000 00:00Здесь есть очень немалая вероятность того, что векторизация сложения массивов попросту «захардкожена», а не является результатом универсального алгоритма оптимизации. К тому же вы этот массив ещё и линейно обходите. Сделайте его знакочередующим хотя бы (типа 4-5-3-6-2-7-1 (или 5-6-3-4-1-2, чтобы возможность для векторизации была более очевидной)).
vadimr
00.00.0000 00:00В знакочередующем варианте как раз возможность векторизации неочевидна, и непонятно, что это должно доказывать. Всё-таки мы рассчитываем на то, что программист сам по себе пишет мало-мальски эффективный код.
Тем временем, я задался значениями M = 10000 и N = 1000000 для Си и, соответственно, M = 1000000 и N = 10000 для Фортрана, построил таким образом сложение двух сорокагигабайтных массивов, один из которых проходится подряд, а другой в неестественном порядке, и замерил время. Для Си при нескольких запусках получилось 4m59.1s с точностью до 0.1 сек, для Фортрана – 4m57.0s с точностью до 0.7 сек (затрудняюсь объяснить, почему у Фортрана дисперсия больше). Разница есть, но очень небольшая.
eptr
00.00.0000 00:00+1А теперь вернёмся к тому, о чём я писал с самого начала – к обработке двухмерного массива. Подставим в сложение c[n][m] вместо c[m][n]. И то же самое в фортране – вместо простого сложения массивов напишем цикл (наружный цикл по j, так как в фортране массивы хранятся по столбцам)
Да, давайте вернёмся (ссылка на godbolt):
program main integer*1, allocatable :: a (:,:), b (:,:), c (:,:) integer :: m, n, mm, nn, i, j real :: u call random_init (.true., .true.) call random_number (u) m = floor (u * 102) call random_number (u) n = floor (u * 205) allocate (a (m,n), b (m, n), c (n, m)) do j=1, N do i=1, M call random_number (u) b (i, j) = floor (u * 100) end do end do nn = 3 c = nn do j=1, N do i=1, M a (i,j) = b (i,j) + c (j,i) end do end do print *, m, n print *, a end program mainПрограмма слегка подрихтована, чтобы M и N всегда были одинаковыми и равными таковым в последующем коде на C, но чтобы выглядели как настоящие достаточно случайные.
gfortran:
.L17: movzx eax, BYTE PTR [rdx+r11] movzx r8d, BYTE PTR [rdx+rsi*2] vmovd xmm0, DWORD PTR [r12+rcx] sal eax, 8 or eax, r8d movzx r8d, BYTE PTR [rdx+rsi] sal eax, 8 or eax, r8d movzx r8d, BYTE PTR [rdx] add rdx, rbp sal eax, 8 or eax, r8d vmovd xmm4, eax vpaddb xmm0, xmm4, xmm0 vmovd DWORD PTR [r10+rcx], xmm0 add rcx, 4 cmp rbx, rcx jne .L17Уже известная тройка инструкций и затем
add rcx, 4.В сообщении компилятора написано:
app/example.f90:28:7: optimized: loop vectorized using 4 byte vectors
И в этом отрывке, если проследить, то видно, что обращения, действительно, 4-х байтовые (
DWORD PTR).Это – не векторизация, компилятора только вид сделал, что векторизовал.
У flang-trunk код идентичен.
У ifort – простыня:
Простыню под спойлер убрал
..B1.52: # Preds ..B1.52 ..B1.51 mov r14, rsi #29.25 lea r8, QWORD PTR [rsi+rsi*2] #29.23 imul r14, r10 #29.25 lea r13, QWORD PTR [rax+r14] #29.23 movzx r15d, BYTE PTR [r13] #29.23 lea r12, QWORD PTR [rsi+rsi*4] #29.23 lea rdi, QWORD PTR [rsi*8] #29.23 sub rdi, rsi #29.23 vmovd xmm0, r15d #29.23 vpinsrb xmm1, xmm0, BYTE PTR [rsi+r13], 1 #29.23 vpinsrb xmm2, xmm1, BYTE PTR [r13+rsi*2], 2 #29.23 vpinsrb xmm3, xmm2, BYTE PTR [r8+r13], 3 #29.23 vpinsrb xmm4, xmm3, BYTE PTR [r13+rsi*4], 4 #29.23 vpinsrb xmm5, xmm4, BYTE PTR [r12+r13], 5 #29.23 vpinsrb xmm6, xmm5, BYTE PTR [r13+r8*2], 6 #29.23 vpinsrb xmm7, xmm6, BYTE PTR [rdi+r13], 7 #29.23 lea rdi, QWORD PTR [rsi+rsi*8] #29.23 vpinsrb xmm8, xmm7, BYTE PTR [r13+rsi*8], 8 #29.23 lea rbx, QWORD PTR [rdi+rsi*2] #29.23 vpinsrb xmm9, xmm8, BYTE PTR [rdi+r13], 9 #29.23 lea r14, QWORD PTR [rdi+rsi*4] #29.23 vpinsrb xmm10, xmm9, BYTE PTR [r13+r12*2], 10 #29.23 vpinsrb xmm11, xmm10, BYTE PTR [rbx+r13], 11 #29.23 mov rbx, rsi #29.23 vpinsrb xmm12, xmm11, BYTE PTR [r13+r8*4], 12 #29.23 shl rbx, 4 #29.23 vpinsrb xmm13, xmm12, BYTE PTR [r14+r13], 13 #29.23 mov r14, rbx #29.23 sub r14, rsi #29.23 mov r15, r14 #29.23 sub r15, rsi #29.23 vpinsrb xmm14, xmm13, BYTE PTR [r15+r13], 14 #29.23 movzx r15d, BYTE PTR [rbx+r13] #29.23 add rbx, rsi #29.23 vpinsrb xmm15, xmm14, BYTE PTR [r14+r13], 15 #29.23 vmovd xmm16, r15d #29.23 vpinsrb xmm17, xmm16, BYTE PTR [rbx+r13], 17 #29.23 imul rbx, rsi, 19 #29.23 vpinsrb xmm18, xmm17, BYTE PTR [r13+rdi*2], 18 #29.23 imul rdi, rsi, 23 #29.23 vpinsrb xmm19, xmm18, BYTE PTR [rbx+r13], 19 #29.23 imul rbx, rsi, 22 #29.23 vpinsrb xmm20, xmm19, BYTE PTR [r13+r12*4], 20 #29.23 imul r12, rsi, 21 #29.23 vpinsrb xmm21, xmm20, BYTE PTR [r12+r13], 21 #29.23 lea r12, QWORD PTR [rsi*4] #29.23 vpinsrb xmm22, xmm21, BYTE PTR [rbx+r13], 22 #29.23 mov r15, rsi #29.23 imul rbx, rsi, 26 #29.23 vpinsrb xmm23, xmm22, BYTE PTR [rdi+r13], 23 #29.23 imul rdi, rsi, 27 #29.23 vpinsrb xmm24, xmm23, BYTE PTR [r13+r8*8], 24 #29.23 imul r8, rsi, 25 #29.23 vpinsrb xmm25, xmm24, BYTE PTR [r8+r13], 25 #29.23 neg r12 #29.23 imul r8, rsi, 29 #29.23 vpinsrb xmm26, xmm25, BYTE PTR [rbx+r13], 26 #29.23 vpinsrb xmm27, xmm26, BYTE PTR [rdi+r13], 27 #29.23 shl r15, 5 #29.23 add r12, r15 #29.23 sub r15, rsi #29.23 mov r14, r15 #29.23 sub r14, rsi #29.23 vpinsrb xmm28, xmm27, BYTE PTR [r12+r13], 28 #29.23 vpinsrb xmm29, xmm28, BYTE PTR [r8+r13], 29 #29.23 vpinsrb xmm30, xmm29, BYTE PTR [r14+r13], 30 #29.23 vpinsrb xmm31, xmm30, BYTE PTR [r15+r13], 31 #29.23 vinserti32x4 ymm0, ymm15, xmm31, 1 #29.23 vpaddb ymm1, ymm0, YMMWORD PTR [rdx+r10] #29.23 vmovdqu YMMWORD PTR [r10+rcx], ymm1 #29.5 add r10, 32 #28.3 cmp r10, r9 #28.3 jb ..B1.52 # Prob 82% #28.3Зато здесь шаг, как видно из инструкции
addr 10, 32, – 32, и обращения – 32-байтовые (YMMWORD PTR).Да, это уже – векторизация, причём, довольно мощная.
Ассемблерный код в фортране не сильно изменился, там такая же команда paddb / vpaddb в чуть более сложном окружении. А сишный кодогенератор пошёл вразнос (я уже писал, что не могу проинтерпретировать увиденное).
Как видно, gfortran не справился, 4-байтный "вектор" – это не векторизация.
Теперь посмотрим C-шный код, максимально близкий к рассматриваемому Frotran'овскому (ссылка на godbolt):
#include <stdlib.h> #include <stdio.h> #include <string.h> #include <time.h> #define ELEMS(a) (sizeof (a) / sizeof *(a)) typedef int type; void fun(size_t M, size_t N) { type (*a)[M][N] = malloc(sizeof *a); if (a) { type (*b)[M][N] = malloc(sizeof *b); if (b) { type (*c)[N][M] = malloc(sizeof *c); if (c) { for (size_t i = 0; i < ELEMS(*b); ++i) { for (size_t j = 0; j < ELEMS((*b)[i]); ++j) { (*b)[i][j] = rand(); } } for (size_t i = 0; i < ELEMS(*c); ++i) { for (size_t j = 0; j < ELEMS((*c)[i]); ++j) { (*c)[i][j] = 3; } } for (size_t i = 0; i < ELEMS(*a); ++i) { for (size_t j = 0; j < ELEMS((*a)[i]); ++j) { (*a)[i][j] = (*b)[i][j] + (*c)[j][i]; } } printf("a[0][0]: %i\n", (*a)[0][0]); free(c); } free(b); } free(a); } } int main(void) { //srand(time(NULL)); srand(0); size_t M = 100. * rand() / RAND_MAX; size_t N = 100. * rand() / RAND_MAX; printf("M: %zu, N: %zu\n", M, N); fun(M, N); return EXIT_SUCCESS; }gcc:
.L22: vmovd xmm2, DWORD PTR [rax+rbx*2] vmovd xmm3, DWORD PTR [rax] vpinsrd xmm0, xmm2, DWORD PTR [rax+rcx], 1 vpinsrd xmm1, xmm3, DWORD PTR [rax+rbx], 1 add rax, rdi vpunpcklqdq xmm0, xmm1, xmm0 vpaddd xmm0, xmm0, XMMWORD PTR [r11+r8] vmovdqu XMMWORD PTR [r10+r8], xmm0 add r8, 16 cmp r8, rsi jne .L22gcc справился, шаг равен 16, что также подтверждается 16-байтовыми обращениями (
XMMWORD PTR).clang:
.LBB0_36: # Parent Loop BB0_31 Depth=1 vmovdqu ymm0, ymmword ptr [rcx - 96] vmovdqu ymm1, ymmword ptr [rcx - 64] vmovdqu ymm2, ymmword ptr [rcx - 32] vmovdqu ymm3, ymmword ptr [rcx] vpaddd ymm0, ymm0, ymmword ptr [rsi + 4*rdx - 224] vpaddd ymm1, ymm1, ymmword ptr [rsi + 4*rdx - 192] vpaddd ymm2, ymm2, ymmword ptr [rsi + 4*rdx - 160] vpaddd ymm3, ymm3, ymmword ptr [rsi + 4*rdx - 128] vmovdqu ymmword ptr [r8 + 4*rdx - 224], ymm0 vmovdqu ymmword ptr [r8 + 4*rdx - 192], ymm1 vmovdqu ymmword ptr [r8 + 4*rdx - 160], ymm2 vmovdqu ymmword ptr [r8 + 4*rdx - 128], ymm3 vmovdqu ymm0, ymmword ptr [rcx + r9 - 96] vmovdqu ymm1, ymmword ptr [rcx + r9 - 64] vmovdqu ymm2, ymmword ptr [rcx + r9 - 32] vmovdqu ymm3, ymmword ptr [rcx + r9] vpaddd ymm0, ymm0, ymmword ptr [rsi + 4*rdx - 96] vpaddd ymm1, ymm1, ymmword ptr [rsi + 4*rdx - 64] vpaddd ymm2, ymm2, ymmword ptr [rsi + 4*rdx - 32] vpaddd ymm3, ymm3, ymmword ptr [rsi + 4*rdx] vmovdqu ymmword ptr [r8 + 4*rdx - 96], ymm0 vmovdqu ymmword ptr [r8 + 4*rdx - 64], ymm1 vmovdqu ymmword ptr [r8 + 4*rdx - 32], ymm2 vmovdqu ymmword ptr [r8 + 4*rdx], ymm3 add rdx, 64clang справился лучше всех: шаг 64 байта.
icc:
..B1.58: # Preds ..B1.58 ..B1.57 mov rcx, r13 #34.35 imul rcx, rdi #34.35 lea rcx, QWORD PTR [r14+rcx*4] #34.35 vmovd xmm0, DWORD PTR [rcx+r9] #34.35 vmovd xmm1, DWORD PTR [rcx] #34.35 vpinsrd xmm17, xmm0, DWORD PTR [rdx+rcx], 1 #34.35 vpinsrd xmm16, xmm1, DWORD PTR [rcx+r13*8], 1 #34.35 add rcx, rbx #34.35 vpunpckldq xmm6, xmm16, xmm17 #34.35 vmovd xmm2, DWORD PTR [rcx+r9] #34.35 vmovd xmm3, DWORD PTR [rcx] #34.35 vpinsrd xmm5, xmm2, DWORD PTR [rdx+rcx], 1 #34.35 vpinsrd xmm4, xmm3, DWORD PTR [rcx+r13*8], 1 #34.35 vpunpckldq xmm7, xmm4, xmm5 #34.35 vinserti128 ymm8, ymm6, xmm7, 1 #34.35 vpaddd ymm9, ymm8, YMMWORD PTR [r12+rdi*4] #34.35 vmovdqu YMMWORD PTR [rsi+rdi*4], ymm9 #34.9 add rdi, 8 #33.6 cmp rdi, rax #33.6 jb ..B1.58 # Prob 82% #33.6icc – хуже всех, но 8 – это, всё-таки, не 4.
Итак, что мы видим?
C ни в какой разнос не пошёл.
C-шный код векторизуется лучше, чем Fortran'овский.
C-шный код ещё и транслируется в более понятный ассемблер.Выходит, нет у Fortran'а преимуществ перед C в смысле векторизуемости.
vadimr
00.00.0000 00:00Программы не эквивалентны. Вы в Си перешли для использования в массиве от типа char к int, а в Фортране оставили integer*1. Поменяйте integer*1 на integer, и получите длинный конвейер (для моего процессора конвейер имеет длину 16 байт).
Также надо заметить, что GNU Fortran сильно прибавил в оптимизации за последнее время. Версия 12 в смысле векторизации более хороша, чем, например, версия 7, которой до сих пор комплектуются из коробки некоторые дистрибутивы вроде openSUSE.
eptr
00.00.0000 00:00+1Программы не эквивалентны. Вы в Си перешли для использования в массиве от типа char к int, а в Фортране оставили integer1. Поменяйте integer1 на integer, и получите длинный конвейер (для моего процессора конвейер имеет длину 16 байт).
Я Fortran'а не знаю, особенно современного, поэтому не догадался, что значит эта 1.
В программе на C я этот тип за'typedef'ил, и, получается, совсем не зря.C-щный код с
char'ом (ссылка на godbolt):#include <stdlib.h> #include <stdio.h> #include <string.h> #include <time.h> #define ELEMS(a) (sizeof (a) / sizeof *(a)) typedef char type; void fun(size_t M, size_t N) { type (*a)[M][N] = malloc(sizeof *a); if (a) { type (*b)[M][N] = malloc(sizeof *b); if (b) { type (*c)[N][M] = malloc(sizeof *c); if (c) { for (size_t i = 0; i < ELEMS(*b); ++i) { for (size_t j = 0; j < ELEMS((*b)[i]); ++j) { (*b)[i][j] = rand(); } } for (size_t i = 0; i < ELEMS(*c); ++i) { for (size_t j = 0; j < ELEMS((*c)[i]); ++j) { (*c)[i][j] = 3; } } for (size_t i = 0; i < ELEMS(*a); ++i) { for (size_t j = 0; j < ELEMS((*a)[i]); ++j) { (*a)[i][j] = (*b)[i][j] + (*c)[j][i]; } } printf("a[0][0]: %i\n", (*a)[0][0]); free(c); } free(b); } free(a); } } int main(void) { //srand(time(NULL)); srand(0); size_t M = 100. * rand() / RAND_MAX; size_t N = 100. * rand() / RAND_MAX; printf("M: %zu, N: %zu\n", M, N); fun(M, N); return EXIT_SUCCESS; }gcc:
.L14: movzx eax, BYTE PTR [r10+rdi] movzx r13d, BYTE PTR [r10+rbx*2] vmovd xmm0, DWORD PTR [rcx+r11] sal eax, 8 or eax, r13d movzx r13d, BYTE PTR [r10+rbx] sal eax, 8 or eax, r13d movzx r13d, BYTE PTR [r10] add r10, r9 sal eax, 8 or eax, r13d vmovd xmm1, eax vpaddb xmm0, xmm1, xmm0 vmovd DWORD PTR [rdx+r11], xmm0 add r11, 4 cmp r11, r8 jne .L14Похоже, код идентичен с Fortran'овским, с точностью до используемых регистров.
clang:
Первичный цикл у clang'а очень большой
.LBB0_20: # Parent Loop BB0_13 Depth=1 vmovdqu ymm0, ymmword ptr [rsi] vmovdqu ymm1, ymmword ptr [rsi + 32] vmovdqu ymm2, ymmword ptr [rsi + 64] vmovdqu ymm3, ymmword ptr [rsi + 96] lea rdx, [rsi + rbx] vpaddb ymm0, ymm0, ymmword ptr [rcx + r10 - 992] vpaddb ymm1, ymm1, ymmword ptr [rcx + r10 - 960] vpaddb ymm2, ymm2, ymmword ptr [rcx + r10 - 928] vpaddb ymm3, ymm3, ymmword ptr [rcx + r10 - 896] lea rbp, [rdx + rbx] vmovdqu ymmword ptr [rdi + r10 - 992], ymm0 vmovdqu ymmword ptr [rdi + r10 - 960], ymm1 vmovdqu ymmword ptr [rdi + r10 - 928], ymm2 vmovdqu ymm0, ymmword ptr [rsi + rbx] vmovdqu ymm1, ymmword ptr [rsi + rbx + 32] vmovdqu ymm2, ymmword ptr [rsi + rbx + 64] vmovdqu ymmword ptr [rdi + r10 - 896], ymm3 vmovdqu ymm3, ymmword ptr [rsi + rbx + 96] add rsi, rax vpaddb ymm0, ymm0, ymmword ptr [rcx + r10 - 864] vpaddb ymm1, ymm1, ymmword ptr [rcx + r10 - 832] vpaddb ymm2, ymm2, ymmword ptr [rcx + r10 - 800] vpaddb ymm3, ymm3, ymmword ptr [rcx + r10 - 768] vmovdqu ymmword ptr [rdi + r10 - 864], ymm0 vmovdqu ymmword ptr [rdi + r10 - 832], ymm1 vmovdqu ymmword ptr [rdi + r10 - 800], ymm2 vmovdqu ymm0, ymmword ptr [rbx + rdx] vmovdqu ymm1, ymmword ptr [rbx + rdx + 32] vmovdqu ymm2, ymmword ptr [rbx + rdx + 64] vmovdqu ymmword ptr [rdi + r10 - 768], ymm3 vmovdqu ymm3, ymmword ptr [rbx + rdx + 96] lea rdx, [rbp + rbx] vpaddb ymm0, ymm0, ymmword ptr [rcx + r10 - 736] vpaddb ymm1, ymm1, ymmword ptr [rcx + r10 - 704] vpaddb ymm2, ymm2, ymmword ptr [rcx + r10 - 672] vpaddb ymm3, ymm3, ymmword ptr [rcx + r10 - 640] vmovdqu ymmword ptr [rdi + r10 - 736], ymm0 vmovdqu ymmword ptr [rdi + r10 - 704], ymm1 vmovdqu ymmword ptr [rdi + r10 - 672], ymm2 vmovdqu ymm0, ymmword ptr [rbx + rbp] vmovdqu ymm1, ymmword ptr [rbx + rbp + 32] vmovdqu ymm2, ymmword ptr [rbx + rbp + 64] vmovdqu ymmword ptr [rdi + r10 - 640], ymm3 vmovdqu ymm3, ymmword ptr [rbx + rbp + 96] lea rbp, [rdx + rbx] vpaddb ymm0, ymm0, ymmword ptr [rcx + r10 - 608] vpaddb ymm1, ymm1, ymmword ptr [rcx + r10 - 576] vpaddb ymm2, ymm2, ymmword ptr [rcx + r10 - 544] vpaddb ymm3, ymm3, ymmword ptr [rcx + r10 - 512] vmovdqu ymmword ptr [rdi + r10 - 608], ymm0 vmovdqu ymmword ptr [rdi + r10 - 576], ymm1 vmovdqu ymmword ptr [rdi + r10 - 544], ymm2 vmovdqu ymm0, ymmword ptr [rbx + rdx] vmovdqu ymm1, ymmword ptr [rbx + rdx + 32] vmovdqu ymm2, ymmword ptr [rbx + rdx + 64] vmovdqu ymmword ptr [rdi + r10 - 512], ymm3 vmovdqu ymm3, ymmword ptr [rbx + rdx + 96] lea rdx, [rbp + rbx] vpaddb ymm0, ymm0, ymmword ptr [rcx + r10 - 480] vpaddb ymm1, ymm1, ymmword ptr [rcx + r10 - 448] vpaddb ymm2, ymm2, ymmword ptr [rcx + r10 - 416] vpaddb ymm3, ymm3, ymmword ptr [rcx + r10 - 384] vmovdqu ymmword ptr [rdi + r10 - 480], ymm0 vmovdqu ymmword ptr [rdi + r10 - 448], ymm1 vmovdqu ymmword ptr [rdi + r10 - 416], ymm2 vmovdqu ymm0, ymmword ptr [rbx + rbp] vmovdqu ymm1, ymmword ptr [rbx + rbp + 32] vmovdqu ymm2, ymmword ptr [rbx + rbp + 64] vmovdqu ymmword ptr [rdi + r10 - 384], ymm3 vmovdqu ymm3, ymmword ptr [rbx + rbp + 96] lea rbp, [rdx + rbx] vpaddb ymm0, ymm0, ymmword ptr [rcx + r10 - 352] vpaddb ymm1, ymm1, ymmword ptr [rcx + r10 - 320] vpaddb ymm2, ymm2, ymmword ptr [rcx + r10 - 288] vpaddb ymm3, ymm3, ymmword ptr [rcx + r10 - 256] vmovdqu ymmword ptr [rdi + r10 - 352], ymm0 vmovdqu ymmword ptr [rdi + r10 - 320], ymm1 vmovdqu ymmword ptr [rdi + r10 - 288], ymm2 vmovdqu ymmword ptr [rdi + r10 - 256], ymm3 vmovdqu ymm0, ymmword ptr [rbx + rdx] vmovdqu ymm1, ymmword ptr [rbx + rdx + 32] vmovdqu ymm2, ymmword ptr [rbx + rdx + 64] vmovdqu ymm3, ymmword ptr [rbx + rdx + 96] vpaddb ymm0, ymm0, ymmword ptr [rcx + r10 - 224] vpaddb ymm1, ymm1, ymmword ptr [rcx + r10 - 192] vpaddb ymm2, ymm2, ymmword ptr [rcx + r10 - 160] vpaddb ymm3, ymm3, ymmword ptr [rcx + r10 - 128] vmovdqu ymmword ptr [rdi + r10 - 224], ymm0 vmovdqu ymmword ptr [rdi + r10 - 192], ymm1 vmovdqu ymmword ptr [rdi + r10 - 160], ymm2 vmovdqu ymmword ptr [rdi + r10 - 128], ymm3 vmovdqu ymm0, ymmword ptr [rbx + rbp] vmovdqu ymm1, ymmword ptr [rbx + rbp + 32] vmovdqu ymm2, ymmword ptr [rbx + rbp + 64] vmovdqu ymm3, ymmword ptr [rbx + rbp + 96] vpaddb ymm0, ymm0, ymmword ptr [rcx + r10 - 96] vpaddb ymm1, ymm1, ymmword ptr [rcx + r10 - 64] vpaddb ymm2, ymm2, ymmword ptr [rcx + r10 - 32] vpaddb ymm3, ymm3, ymmword ptr [rcx + r10] vmovdqu ymmword ptr [rdi + r10 - 96], ymm0 vmovdqu ymmword ptr [rdi + r10 - 64], ymm1 vmovdqu ymmword ptr [rdi + r10 - 32], ymm2 vmovdqu ymmword ptr [rdi + r10], ymm3 add r10, 1024 add r15, -8 jne .LBB0_20Шаг равен 1024, не постеснялись они так развернуть.
Вторичный цикл сильно меньше:
.LBB0_23: # Parent Loop BB0_13 Depth=1 vmovdqu ymm0, ymmword ptr [r10] vmovdqu ymm1, ymmword ptr [r10 + 32] vmovdqu ymm2, ymmword ptr [r10 + 64] vmovdqu ymm3, ymmword ptr [r10 + 96] add r10, rbx vpaddb ymm0, ymm0, ymmword ptr [rsi + rbp - 96] vpaddb ymm1, ymm1, ymmword ptr [rsi + rbp - 64] vpaddb ymm2, ymm2, ymmword ptr [rsi + rbp - 32] vpaddb ymm3, ymm3, ymmword ptr [rsi + rbp] vmovdqu ymmword ptr [rdx + rbp - 96], ymm0 vmovdqu ymmword ptr [rdx + rbp - 64], ymm1 vmovdqu ymmword ptr [rdx + rbp - 32], ymm2 vmovdqu ymmword ptr [rdx + rbp], ymm3 sub rbp, -128 cmp rax, rbp jne .LBB0_23Шаг, насколько я понимаю, 128.
Есть и третичный, совсем маленький:
.LBB0_27: # Parent Loop BB0_13 Depth=1 vmovdqu xmm0, xmmword ptr [rsi] add rsi, rax vpaddb xmm0, xmm0, xmmword ptr [r9 + rdx] vmovdqu xmmword ptr [r14 + rdx], xmm0 add rdx, 16 cmp r8, rdx jne .LBB0_27Шаг – 16.
Не знаю, насколько это эффективно для относительно небольших массивов, но clang здесь отличлся.
icc (если я правильно нашёл место):
..B1.28: # Preds ..B1.28 ..B1.27 mov bl, BYTE PTR [rdi+rax*2] #34.22 add bl, BYTE PTR [r15+r11*2] #34.35 mov BYTE PTR [rsi+rax*2], bl #34.9 mov bl, BYTE PTR [1+rdi+rax*2] #34.22 add bl, BYTE PTR [rdx+r11*2] #34.35 add r11, r12 #33.6 mov BYTE PTR [1+rsi+rax*2], bl #34.9 inc rax #33.6 cmp rax, r8 #33.6 jb ..B1.28 # Prob 63% #33.6Похоже, icc не справился.
Итак, если взять GNU, то результат одинаковый, что для Fortran'а, что для C.
Опять получается так, что у Fortran'а нет преимуществ перед C в смысле быстродействия.
vadimr
00.00.0000 00:00+2Я бы резюмировал результат так: применив усилия опытного программиста и написав довольно много неочевидного и нетипичного кода, можно на Си получить по эффективности аналог простых для написания и восприятия матричных операторов Фортрана.
Возможно, что у gfortran и gcc вообще целиком буквально один и тот же оптимизатор.
Refridgerator
00.00.0000 00:00А где вы там увидели неочевидный и нетипичный код? Обычный вложенный цикл. Если взять компилятор не си, а си++ от Microsoft или Intel, то они такие вещи векторизуют вообще без подсказок, достаточно просто в опциях компилятора включить оптимизацию с поддержкой AVX и выбрать floating model=fast.
Я потому и намекал уже неоднократно, что на таких примитивных операциях нет смысла что-либо сравнивать. Сложение матриц это вообще не то, что занимает хоть какие-то ресурсы, по сравнению с их умножением. Вы же тут вроде о языке для научных вычислений говорите? Медленное преобразование Фурье на 10000 элементов будет выполняться достаточно долго, чтобы замерить производительность кода таймером, без вникания в ассемблерный код.
vadimr
00.00.0000 00:00+1Если говорить о производительности реальных тяжёлых вычислений, то правомерен будет вопрос об оптимизированном под них железе (хотя бы для начала той же самой Nvidia) и коммерческом компиляторе. А там и до суперкомпьютеров дорожка доведёт. Тут сложно будет объявить окончательный результат на полпути.
Даже на маленьком одночиповом микроконтроллере PIC32 коммерческая версия компилятора Си оптимизирует лучше, чем бесплатная.
Refridgerator
00.00.0000 00:00Раньше не замечал, но у Интела, оказывается, есть компилятор и для Фортрана. Поэтому уверен, что компиляторы из oneAPI Toolkit одной версии будут выдавать идентичную производительность. Что значит следующее:
а) преимуществу скорости Фортрана взяться неоткуда, разве что делать сравнение на компиляторах разного времени и уровня;
б) Фортран всё ещё достаточно популярен и востребован, чтобы поддерживать для него оптимизирующий компилятор (а компиляторы от Интела как раз и претендуют на звание самых быстрых на Западе);
в) Фортран вполне сможет первым преодолеть 100-летний рубеж только потому, что старше.
eptr
00.00.0000 00:00+1Я бы резюмировал результат так: применив усилия опытного программиста и написав довольно много неочевидного и нетипичного кода, можно на Си получить по эффективности аналог простых для написания и восприятия матричных операторов Фортрана.
Код – очевидный.
Нетипичный он, видимо, в связи с качеством преподавания.
Действительно, редко встретишь указатели на массивы.Кода – не много.
Не можно получить, а штатно получается аналог, без трюков.
Возможно, что у gfortran и gcc вообще целиком буквально один и тот же оптимизатор.
Почти наверняка.
Идентичность получающегося кода, а также разумность такого подхода практически не оставляют шансов другому исходу.
Поэтому говорить о превосходстве Fortran'а перед C в смысле эффективности бессмысленно.
vadimr
00.00.0000 00:00Я в Фортране-то тоже не настоящий сварщик, поэтому пришлось поднять кое-какие справочники. Вот вам версия программы, которая работает в несколько раз быстрее за счёт автоматического распараллеливания (я пробовал так делать раньше, но не преуспел, а оказывается, что надо указывать при компиляции ключ -fopenmp, чтобы это работало).
program main integer, allocatable :: a (:,:), b (:,:), c (:,:) integer :: m, n, mm, nn, i, j real :: u m = 100000 n = 10000 allocate (a (m,n), b (m,n), c (n,m)) mm = 2 nn = 3 b = mm c = nn !$omp parallel do private (i, j) do j=1, n do i=1, m a (i,j) = b (i,j) + c (j,i) end do end do !$omp end parallel do call random_number (u) i = floor (u * m) call random_number (u) print *, a (i,j) end program mainПравда, сразу скажу, что тут неудобство в том, что в таком виде вычисления будут ускоряться на параллельных и массово-параллельных архитектурах, а на массовых векторно-конвейерных (как Nvidia) надо писать цикл do concurrent, который компилируется на обычном x86, но не ускоряет там код.
eptr
00.00.0000 00:00+1Я в Фортране-то тоже не настоящий сварщик, поэтому пришлось поднять кое-какие справочники. Вот вам версия программы, которая работает в несколько раз быстрее за счёт автоматического распараллеливания (я пробовал так делать раньше, но не преуспел, а оказывается, что надо указывать при компиляции ключ -fopenmp, чтобы это работало).
Вы использовали OpenMP.
Однако, OpenMP – он же не только для Fortran'а разработан.В Википедии всё написано.
Fortran не имеет преимуществ по быстродействию по сравнению с C.
eptr
00.00.0000 00:00-1Вы не забывайте, что всеми этими макросами, sizeof'ами, циклами, преобразованиями пойнтеров туда и обратно вы расписываете аналог следующего фортрановского кода
И что?
Язык C – общего назначения, в него не тащат, что не попадя.Если перейти на C++, Fortran проиграет, ибо C++ позволяет создать себе инструмент, причём такой, какой надо, и пользоваться им.
В Fortran'е же, насколько я понимаю, есть только то, что есть.
vadimr
00.00.0000 00:00+1Логически-то можно создать инструмент, а в смысле эффективности это будет затратно, с чего мы и начали.
Так что – или извращаться с адресной арифметикой для эффективной эмуляции фортрановских операторов, или написать на объектах, но тогда будет менее эффективно.

Aleshonne
00.00.0000 00:00Перегрузка операторов в Фортране есть, ООП есть, по сравнению с C++ только шаблонов нет. Но можно писать код, общий относительно вариантов типа (real(4), real(8), real(16)). Небольшое расширение вполне себе реализуется.
eptr
00.00.0000 00:00+1Перегрузка операторов в Фортране есть, ООП есть, по сравнению с C++ только шаблонов нет. Но можно писать код, общий относительно вариантов типа (real(4), real(8), real(16)). Небольшое расширение вполне себе реализуется.
Получается, это немного лучше, чем C-шный
_Generic, но явно слабее чем C++. Но если этого хватает, то – и ладно.В статье утверждалось, что Fortran значительно быстрее C/C++, но увидеть этого мне пока не удалось.
По эффективности я не вижу преимуществ Fortran'а перед C.
Aleshonne
00.00.0000 00:00+2В статье утверждалось, что Fortran значительно быстрее C/C++, но увидеть этого мне пока не удалось. По эффективности я не вижу преимуществ Fortran'а перед C.
Преимущества в плане качества кода у компиляторов Фортрана перед C нет, как, впрочем, нет и особого отставания.
Но у него есть очень хорошая стандартная библиотека, которая прекрасно документирована и весьма оптимально реализована, а общепринятая практика программирования (учебники, примеры из документации, вообще пул доступных публично программ) содержит примеры довольно производительного кода. Например, фортрановкий move_alloc я в примерах видел гораздо чаще, чем плюсовый std::move. Да и в целом самый простой способ сделать что-то на Фортране обычно очень производительный, его синтаксис склоняет к написанию быстрого кода.
За счёт этого программа, написанная неопытным программистом на Фортране будет гораздо производительнее программы, написанной неопытным программистом на C++. Какой-нибудь физик перепишет алгоритм на Фортран почти 1-в-1 из статьи и получит результат за приемлемое время, не имея при этом вообще никакого представления о том, как матрицы размещены в памяти и какие инструкции выполняет процессор при их умножении. На Питоне он напишет программу несколько быстрее, но выполнятся она будет в несколько раз дольше. А на C++ физик, вероятно, правильно работающую программу с первой попытки просто не напишет. Это (плюс большая база уже написанных программ и хорошая совместимость современных компиляторов со старым кодом) и делает Фортран популярным в научной среде.
eptr
00.00.0000 00:00+1Преимущества в плане качества кода у компиляторов Фортрана перед C нет, как, впрочем, нет и особого отставания.
Вот бы ещё и в статье бы было так сказано...
За счёт этого программа, написанная неопытным программистом на Фортране будет гораздо производительнее программы, написанной неопытным программистом на C++. Какой-нибудь физик перепишет алгоритм на Фортран почти 1-в-1 из статьи и получит результат за приемлемое время, не имея при этом вообще никакого представления о том, как матрицы размещены в памяти и какие инструкции выполняет процессор при их умножении.
Вот в это уже вполне верится.
К тому же, C, и особенно C++, – не для использования новичками.
eptr
00.00.0000 00:00А
__restrict?Вынести, при необходимости, если нужна абсолютная совместимость, в C тот код, в котором это требуется, – тоже никак?
eptr
00.00.0000 00:00Вы отбросили часть контекста, а также дополнили его своим содержимым, в результате чего отвечаете не на ту мысль, которая имелась мной ввиду.
Поэтому ваше неявное указание на то, что строго в рамках C++ без расширений или без выноса части кода в C это не решается, не состоятельно.

0xd34df00d
00.00.0000 00:00+1Вы отбросили часть контекста, а также дополнили его своим содержимым, в результате чего отвечаете не на ту мысль, которая имелась мной ввиду.
Если здесь был потерян контекст (кстати, я так и не понял, какой), то, возможно, вам стоит лучше его очёрчивать. На публичных площадках это вообще полезная идея, потому что читателей больше, чем писателей, поэтому вы сэкономите много времени другим людям, если не будете заставлять их играть в угадайку.
Отвечать же на «C++ позволяет создать себе инструмент» вообще не очень конструктивно, потому что из плюсов так себе язык для написания eDSL'ей. Как и из фортрана, впрочем. Да, в фортране едва ли применимы паттерны вроде expression templates, но, с одной стороны, ваш средний программист не умеет в expression templates, а, с другой — это ерунда по сравнению с тем, что можно в ещё более других языках.
eptr
00.00.0000 00:00Если здесь был потерян контекст (кстати, я так и не понял, какой), то, возможно, вам стоит лучше его очёрчивать. На публичных площадках это вообще полезная идея, потому что читателей больше, чем писателей, поэтому вы сэкономите много времени другим людям, если не будете заставлять их играть в угадайку.
Вы правда думаете, что я будут следовать вашим указаниям, как мне вести дискуссию и что включать в каждый пост?
Я вас никоим образом не заставлял отвечать мне и не заставлял играть в вашу "угадайку".
Отвечать же на «C++ позволяет создать себе инструмент» вообще не очень конструктивно, потому что из плюсов так себе язык для написания eDSL'ей. Как и из фортрана, впрочем. Да, в фортране едва ли применимы паттерны вроде expression templates, но, с одной стороны, ваш средний программист не умеет в expression templates, а, с другой — это ерунда по сравнению с тем, что можно в ещё более других языках.
Нет никакого желания расшифровывать обрывки ваших мыслей, в существенной части лишённые контекста, да ещё и зачем-то уводящие в сторону каких-то более других языков.
0xd34df00d
00.00.0000 00:00Вы как-то близко к сердцу это всё воспринимаете. Я всего лишь описал внешнее впечатление, интерпретировать их как указания — пожалуй, не стоит.
Похоже, конструктивной беседы не выйдет, увы.
0xd34df00d
00.00.0000 00:00Компиляторы это делают из рук вон хреново. Руками дергать интрисики (а не ассемблер, кстати, так что вы оба не совсем правы) — зачастую даёт существенный профит.
Aleshonne
00.00.0000 00:00+7У Фортрана много преимуществ для научной разработки. По моему мнению (5 лет активно пишу на Фортране), важнейшие его плюсы это полноценные многомерные массивы из коробки (Фортран даёт некоторые гарантии по размещению массивов в памяти, что позволяет более агрессивно оптимизировать программу как в плане отсутствия лишних проверок, так и в плане попадания нужных данных в кэш) и синтаксис, способствующий высокой производительности (самый простой способ написать что-то на Фортране обычно очень производительный, в то время как на других языках приходится заморачиваться).
Кроме того, авторы компиляторов поддерживают просто эпическую совместимость со старым кодом. Не так давно я компилировал код, созданный 35 лет назад под БЭСМ-6, и он просто взял и скомпилировался, после чего успешно выполнился, выдав результат, точно совпадающий со старым.
Но не стоит идеализировать Фортран, проблем в нём куча. Особенно вы будете страдать, пытаясь работать со строками. Есть большая вероятность, что у каждого опытного программиста на Фортране есть собственная библиотека, реализующая строковые операции адекватным образом, а не так, как это сделано в языке. И никогда не пытайтесь писать на Фортране GUI, иначе есть шанс повеситься в процессе.

Jianke
00.00.0000 00:00важнейшие его плюсы это полноценные многомерные массивы из коробки
А как обстоит с эффективностью у APL, у которое матрицы тоже из коробки?
Aleshonne
00.00.0000 00:00+1У APL нет настолько продвинутых компиляторов, как у Фортрана. Тот же ifort выдаёт очень качественные бинарники, которые способны выжать из процессора всю возможную производительность. А теоретически, там тоже простор для оптимизаций немеряный.

Tzimie
00.00.0000 00:00А что скажете о Julia как современном конкуренте Фортран?
Aleshonne
00.00.0000 00:00+1Юля хороша и перспективна, но у меня к ней есть большой список претензий.
Невозможность работы на компьютерах, не подключённых к интернету. Многие пакеты после установки лезут в сеть и что-то оттуда докачивают, иногда по несколько сотен мегабайт. И, при этом, пакеты сильно друг от друга зависят. Мне, например, интересна решалка дифуров Gridap, которая, однако, имеет 95 зависимостей, в том числе LightXML, TimeZones и Conda (которая, вообще говоря, скачивает из сети и устанавливает на машину питон).
Захардкоженые пути в установленной системе (продолжение проблемы 1). Перенос установленной Юли на другой компьютер теоретически возможен, но куча пакетов при этом перестаёт нормально работать.
Отсутствие нормальной возможности создать бинарник. Функции вроде eval(), что очевидно, не работают в скомпилированном виде, но первые две проблемы распространение программ затрудняют.
Так себе поддержка пакетов сторонними разработчиками. Комьюнити маленькое, много хороших вещей просто забрасывают, например, пакет JuliaFEM не обновлялся уже 3 года и на новых версиях Юли просто не компилируется.
Но в целом язык интересный, периодически использую для решения задач линейно алгебры и анализа данных, он показывает себя в этом лучше питона.
Tzimie
00.00.0000 00:00А векторные операции и параллелизм... Или современный Фортран это может делать сам?
Aleshonne
00.00.0000 00:00Даже не особо современный Фортран умеет делать автопараллелизацию, векторизацию и разворачивание циклов. А ещё есть конструкции вроде do concurrent или forall, которые по умолчанию параллельные:
do concurrent (i = 1:n) res(i) = a(i) + k * b(i) end doPS Ознакомьтесь, например, вот с этим, будет интересно: https://developer.nvidia.com/blog/accelerating-fortran-do-concurrent-with-gpus-and-the-nvidia-hpc-sdk/
Tzimie
00.00.0000 00:00А вот интересно, если бы в таком цикле мы бы суммировали все элементы в одну переменную?
Юля позволяет такое и не ругается, но результат из-за конкуренции оказывается неправильным. Надо создавать массив шириной в число потоков, суммировать по номеру потока, а потом суммировать этот маленький массив
Aleshonne
00.00.0000 00:00Фортран на такое вроде бы ругается, но я не уверен. Если нужна сумма, то потом можно написать res_scalar = sum(res), реализация суммирования массивов из стандартной библиотеки параллельная и работает быстро. Ну или параллелить цикл вручную с использованием !$OMP PARALLEL REDUCTION или !$OMP DO REDUCTION.

TitovVN1974
00.00.0000 00:00В Julia ,бывает, что внезапно что-то меняется после обновления и перестает работать.

Crocodilus
00.00.0000 00:00А чем там хуже работа со строками, чем у С? Я реализую значительную часть строковых операций через массивы, однажды по заказу писал на F'95 программу, сортирующую строки текста по длине, с учётом типа шрифта, и выстраивающую строки в виде нижней треугольной матрицы (не спрашивайте, зачем: я ответить не в состоянии). Программа писалась быстро, а работала ещё быстрее. Мне понравилось.
Aleshonne
00.00.0000 00:00Попробуйте на Фортране поработать с юникодом. Вам не понравится. Кроме того, преобразование число → строка и строка → число там довольно своеобразно реализовано, пробелы имеют специальное значение, с динамическими строками беда (приходится писать самому), нет некоторых привычных современным разбалованным программистам мелочей (функции вроде split и join).
Crocodilus
00.00.0000 00:00Преимущества Питона и ему подобных здесь ясны и очевидны (хотя у современных реализаций Ф вроде есть динамические строки как расширение над стандартом, емнип, а сечения массивов Питон позаимствовал у HPF), но обычно недостатки Фортрана почему-то сравнивают с Си.

Rio
00.00.0000 00:00+15У Фортрана правило strict aliasing работает всегда, поэтому он всегда применяет оптимизации, недоступные по умолчанию старому доброму C89, компилятор которого предполагает, что массивы, переданные через указатели, могут перекрываться. Это вроде бы единственное, из-за чего он действительно может генерировать более быстрый код. Но у нового Си-кода, написанного с учётом strict aliasing, он скорее всего уже не будет так выигрывать (но нужно тестировать, всё может отличаться на разных платформах и компиляторах).
leotsarev
00.00.0000 00:00+3Кажется, правила strict aliasing спасают только если тип разный. А если тип одинаковый, то в С они всегда потенциально пересекаются.
В Fortran (как и в Rust) два мутабельных указателя никогда не пересекаются.
Rio
00.00.0000 00:00если тип одинаковый, то в С они всегда потенциально пересекаются.
В С99 добавили ключевое слово restrict для ручного управления этим делом. Если им параметры одного типа явно пометить, то компилятор будет считать их непересекающимися. В стандарт С++ вроде ещё не добавили пока (могу ошибаться), но некоторые компиляторы поддерживают нестандартные расширения вроде _ _restrict_ _
Tzimie
00.00.0000 00:00Массивы в Фортране могли пересекаться, оператор equivalence позволял их расположить с перекрытием
Aleshonne
00.00.0000 00:00+1Equivalence может только статические массивы пересечь, что определяется на этапе компиляции и не замедляет работу программы (компилятор создаёт один супермассив, в который влезают оба пересекающихся, и работает с ним, соответствующим образом сдвинув индексы). Для allocatable массивов этот оператор применить не получится. Есть, правда, ещё массивы через указатели (real, pointer :: x(:)), которые работают так же как в C и пересечь их можно без проблем, но я видел их использование только для интеропераблельности с тем самым C.
vadimr
00.00.0000 00:00+1В программах на Си очень много ресурсов тратится на управление памятью в куче, как непосредственно за счёт использования динамических структур вместо статических, так и из-за невозможности использовать в связи с этим глубокие оптимизации кода. Для Фортрана использование кучи и структур данных, элементы которых не являются регулярно размещёнными в памяти – это экзотика. Поэтому фортрановский код очень хорошо транслируется в векторные инструкции, когда то же самое на Си требует циклов (или векторизации вручную через явное обращение к векторным библиотекам, чем в реальной жизни мало кто занимается).
Несколько утрируя, можно сказать, что каждая звёздочка в программе на Си – визуально маркированный оверхед по сравнению с Фортраном. Конечно, у процессора существует непосредственно реализованная машинная инструкция выборки по указателю, но она с каждым годом всё более небесплатная по сравнению с эпохой PDP-11 из-за более сложной организации физической памяти.

maxwolf
00.00.0000 00:00+13В программах на C на управление памятью в куче тратится ровно столько ресурсов, сколько захотел программист, ни больше, ни меньше. Именно поэтому у него, как языка программирования, никаких имманентных различий по производительности с Фортраном нет, а технический уровень автора статьи вызывает сомнения (у меня, по крайней мере).
vadimr
00.00.0000 00:00+1Ну, вообще любая программа делает ровно то, что захотел программист, с этим сложно спорить. Но тем не менее, мало кто захочет отказаться от использования стандартной библиотеки Си ради повышения эффективности кода (да и то оптимизатор у компилятора всё равно хуже). Тогда уж проще на ассемблере налабать.
В статье много залепух, но то, что Си не является оптимальным с точки зрения эффективности языком программирования для современных компьютеров – это точно.
maxwolf
00.00.0000 00:00Во-первых, вы заявили, что «В программах на Си очень много ресурсов тратится на управление памятью в куче», что не соответствует действительности, и я вам именно на этот тезис возразил. Во-вторых, в ответе, вы пустились в более общие рассуждения, о том, что «вообще любая программа делает ровно то, что захотел программист», и это тоже не вполне верно (вспомните, или прочитайте, про императивное и декларативное программирование), в-третьих, вы написали «мало кто захочет отказаться от использования стандартной библиотеки Си ради повышения эффективности кода», при том, что именно библиотечные функции сильно оптимизированы, зачастую написаны на ассемблере и, как правило, работают эффективнее самописанных «велосипедов». Ну и в-четвёртых (особенно в свете первых трёх пунктов), ваше утверждение «Си не является оптимальным с точки зрения эффективности языком программирования для современных компьютеров – это точно» — выглядит, по крайней мере, спорно.
P.S. Ни в коей мере не имею намерения вас задеть. Только лишь показать, что окружающая нас Действительность зачастую оказывается гораздо обширнее наших представлений о ней, и для сколько-нибудь значимых категорических утверждений по любой теме нужно чётко представлять себе как область определения правоты высказывания, так и пределы собственной компетентности в этой области.vadimr
00.00.0000 00:00+1Во-первых, вы заявили, что «В программах на Си очень много ресурсов тратится на управление памятью в куче», что не соответствует действительности, и я вам именно на этот тезис возразил.
Правильно, а возразили вы тем, что программисты имеют возможность отказаться от кучи. На что я вам возразил, что возможность действительно имеют, но в подавляющем большинстве случаев не хотят.
Воспринимайте моё утверждение в статистическом смысле, который оно и несёт, а не как категорический императив.

tyomitch
00.00.0000 00:00+9а технический уровень автора статьи вызывает сомнения (у меня, по крайней мере).
Судя по его профилю на linkedin -- это опытный вебдев, никогда в жизни не притрагивавшийся к Фортрану.

Rigidus
00.00.0000 00:00+1то что он пишет о лиспах вызывает гомерический хохот - уровень знакомства на уровне мемчиков и статьи на лурке

zuek
00.00.0000 00:00+1Ну, я, например, на лиспе только а автокаде писал - курсач рисовал, а т.к. пользоваться автокадом меня никто не учил, а справочник по автолиспу уже был в наличии, то я просто "написал на автолиспе чертёж редуктора"... понятно, что это - как зубной щёткой плац подметать, но на кульмане я бы это вычерчивал бы ещё дольше. Так что лиспы - они очень разные бывают, и могут очень по-разному использоваться.

Ndochp
00.00.0000 00:00Ну я вот недавно конструктор из 300 с фигом одинаковых компонентов собирал в Fusion 360. Много бы отдал за то, чтобы таймлайн можно было бы как текст редактировать (даже с ограничениями) а не мышедрыгством заниматься.

adeshere
00.00.0000 00:00+11Fortran значительно быстрее, чем, к примеру, C.
Я всю жизнь пишу на фортране именно потому, что это довольно быстрый язык. А про C знаю гораздо меньше. Но известные мне тесты говорят, что оба эти языка позволяют писать высокоэффективные "перемалыватели чисел". И хотя для конкретных задач многое зависит от компилятора (насколько хорошо он оптимизировал код), я не вижу глобальных причин, почему между этими языками должна быть существенная разница в производительности.
А вот в чем разница, на мой взгляд, действительно есть - так это в том, что для кодирования вычислений от программиста на фортране не требуется такая же высокая квалификация, как от от программиста на C. Язык сам подталкивает программиста использовать такие конструкции, которые легко поддаются оптимизации. Как следствие, порог входа в высокопроизводительные расчеты намного ниже. И это одна из важнейших причин, по которой ученые (для которых программа - лишь инструмент, а не цель) до сих пор выбирают для работы фортран.
Но вот что будет еще лет через 100 - это очень большой вопрос. Сейчас у любого ученого есть тьма задач, для которых нет нет готовых решений. Поэтому приходится
брать в руки палку и чертить на пескеоткрывать среду разработки и что-то там кодить. Но тенденция явно идет к тому, что вскоре (лет через 100) мы (ученые) будем вместо этого собирать решения из готовых блоков, написанных профессионалами, а то и нейросетями?
SpiderEkb
00.00.0000 00:00+1Но тенденция явно идет к тому, что вскоре (лет через 100) мы (ученые) будем собирать решения из готовых блоков, написанных профессионалами, а то и нейросетями?
Не боитесь, что и ученых при таком подходе тоже нейросетями заменят?
В том и дело, что в любой области всегда есть задачи, которые не имеют готового решения. И решение таковых задач и есть прогресс.
Ну мне так кажется...

DistortNeo
00.00.0000 00:00+1Как следствие, порог входа в высокопроизводительные расчеты намного ниже. И это одна из важнейших причин, по которой ученые (для которых программа — лишь инструмент, а не цель) до сих пор выбирают для работы фортран.
Да, так и есть. Хороший учёный редко бывает одновременно хорошим программистом, способным писать высокоэффективный код. Фокусируясь на чём-то одном, второе неизбежно начинает проседать. Это я прямо по своему опыту себе могу сказать.
Но тенденция явно идет к тому, что вскоре (лет через 100) мы (ученые) будем вместо этого собирать решения из готовых блоков, написанных профессионалами, а то и нейросетями?
Сейчас прогнозируется, что уже через 10 лет вычислительная мощность компьютеров достигнет вычислительных возможностей человеческого мозга. Угадайте, что будет дальше?

Hemml
00.00.0000 00:00+1Фортран очень простой и "приземленный" язык, в том смысле, что все вещи в фортране делаются практически всегда так, как они делаются процессором. Это позволяет делать очень хорошие оптимизирующие компиляторы, так как компилятору не нужно предусматривать хитровыдуманные способы взаимодействия с памятью, как в других языках. Фортран примитивен, он просто не позволит тебе использовать конструкции, которые нельзя эффективно скомпилировать. Это не отменяет возможности "грязных хаков", конечно, но если ты применил то, что применять не стоило и это не сработало -- ты сам себе буратино. К тому же компиляторы фортрана (а их много!) разрабатываются и конкурируют между собой уже более полувека, они прошли большой путь эволюции и нагнать их другим языкам будет непросто. К тому же, в наш век опенсорса, конкуренция компиляторов уже мало возможна. Много ли конкурирующих компиляторов питона, например? Если какой-то фирме захочется создать такой, сможет ли она на нем зарабатывать? Вряд ли. По этой причине Фортран так и останется самым быстрым языком для научных вычислений)
vadimr
00.00.0000 00:00Си тоже приземлённый язык, только он к другому процессору был приземлён.
Hemml
00.00.0000 00:00+1Скорее, не к процессору, а просто для других вещей был предназначен. Самое вопиющее различие -- многомерные массивы. В фортране для доступа к произвольному элементу требуется одно обращение к памяти (чаще всего). В Си -- столько, сколько измерений у массива. На эти грабли, как правило, наступает каждый аспирант, загоревшийся идеей переписать код с фортрана на Си и потом недоумевающий, почему его версия работает в несколько раз медленнее)
eptr
00.00.0000 00:00+2Самое вопиющее различие -- многомерные массивы. В фортране для доступа к произвольному элементу требуется одно обращение к памяти (чаще всего). В Си -- столько, сколько измерений у массива.
"5-мерный" массив (передаётся указатель на массив):
int fun(size_t i, size_t j, size_t k, size_t l, size_t m, int (*a)[5][6][7][8][9]) { return (*a)[i][j][k][l][m]; }Результирующий ассемблерный код (ссылка на godbolt):
fun: imul rdi, rdi, 3024 lea rax, [rcx+rcx*8] lea rdx, [rdx+rdx*8] imul rsi, rsi, 504 add rax, rdi add rax, rsi lea rax, [rax+rdx*8] add rax, r8 mov eax, DWORD PTR [r9+rax*4] retСколько обращений к памяти?
Я вижу одно, в предпоследней инструкции.На эти грабли, как правило, наступает каждый аспирант, загоревшийся идеей переписать код с фортрана на Си и потом недоумевающий, почему его версия работает в несколько раз медленнее)
Наверное, у того аспиранта массивы неправильные.
Грабли как правило заключаются в отсутствии владении языком, неэффективным его использованием, а не недостатком языка.
Hemml
00.00.0000 00:00Отличный пример! Тут компилятор явно нарушает стандарт, используя массивы в "фортрановском стиле", например, интеловский компилятор так делает. Проблема в том, что делает он так не всегда)
eptr
00.00.0000 00:00Отличный пример! Тут компилятор явно нарушает стандарт, используя массивы в "фортрановском стиле", например, интеловский компилятор так делает.
И какой пункт стандарта он нарушает?
Все компиляторы так делают.
Добавил MSVC (ссылка на godbolt).clang:
fun: # @fun imul rax, rdi, 12096 imul rsi, rsi, 2016 lea rdi, [rdx + 8*rdx] lea rcx, [rcx + 8*rcx] shl rdi, 5 add rax, r9 add rsi, rax add rdi, rsi lea rax, [rdi + 4*rcx] mov eax, dword ptr [rax + 4*r8] retIntel:
fun: lea rax, QWORD PTR [rdx+rdx*8] #6.11 imul rdx, rdi, 12096 #6.11 shl rcx, 2 #6.11 mov r10, rsi #6.11 shl r10, 5 #6.11 lea r8, QWORD PTR [r9+r8*4] #6.11 shl rsi, 11 #6.11 shl rax, 5 #6.11 sub rsi, r10 #6.11 add rdx, rsi #6.11 lea r11, QWORD PTR [rcx+rcx*8] #6.11 add rax, r11 #6.11 add rdx, rax #6.11 mov eax, DWORD PTR [r8+rdx] #6.11 retMSVC:
fun PROC lea rax, QWORD PTR [rcx+rcx*2] lea rcx, QWORD PTR [rdx+rax*2] imul rax, rcx, 7 mov rcx, QWORD PTR m$[rsp] add rax, r8 lea r8, QWORD PTR [r9+rax*8] mov rax, QWORD PTR a$[rsp] lea rdx, QWORD PTR [rcx+r8*8] add r8, rdx mov eax, DWORD PTR [rax+r8*4] ret 0 fun ENDPСмотрите, — все компиляторы так делают, у всех одно-единственное обращение к памяти.
Может, всё-таки, дело не в нарушении стандарта?
Вообще-то, сообщество настолько огромно, и у него такое количество глубоко разбирающихся в вопросе людей, что подобное "нарушение" было бы вскрыто в короткие сроки и давно исправлено.
В C нет многомерных массивов, зато есть массивы массивов.
Hemml
00.00.0000 00:00Именно, в стандарте С написано, что многомерный массив -- это массив ссылок на одномерные массивы. Если компилятор хранит массив иным образом -- это нарушение. И, да, вполне возможно, что все (современные) компиляторы этим грешат для оптимизации. Компилятор знает, что программист не использует эту фишку (в ваших примерах это можно определить) и хранит массивы так. А теперь представьте, что этот массив надо экспортировать -- вызвать внешнюю функцию и передать ссылку на массив. Если у компилятора нет возможности делать межобъектную оптимизацию (у Intel C/C++ для этого нужно использовать специальный ключ, например), он вынужден будет хранить массив в соответствии со стандартом, в внешняя функция -- обращаться к нему в соответствии со стандартом. И, здравствуйте, вот вам и лишние обращения к памяти!
eptr
00.00.0000 00:00+3Именно, в стандарте С написано, что многомерный массив -- это массив ссылок на одномерные массивы.
А почему я не могу обнаружить этого в стандарте?
Вот, где определяется, что такое массив (ссылка на draft C11):
6.2.5 Types
...
20 Any number of derived types can be constructed from the object and function types, as follows:
— An array type describes a contiguously allocated nonempty set of objects with a particular member object type, called the element type. The element type shall be complete whenever the array type is specified. Array types are characterized by their element type and by the number of elements in the array. An array type is said to be derived from its element type, and if its element type is T, the array type is sometimes called ‘‘array of T’’. The construction of an array type from an element type is called ‘‘array type derivation’’.Всё.
Где здесь сказано, что массивы бывают многомерные, и, тем более, что тогда они должны быть массивами ссылок?
В C нет многомерных массивов.
Зато там есть массивы массивов.
Это можно продолжать рекурсивно.У меня в изначальном примере не 5-мерный массив, а "5-мерный".
Это значит, что, на самом деле, там массив массивов массивов массивов массивовint'ов.Hemml
00.00.0000 00:00в 90-х у меня был бумажный справочник стандарта C и в нем было написано, что это должен быть массив ссылок. За ссылку на дафт спасибо, очень забавный документ, триграфы, значит, они сохранили, лол.
Но, возвращаясь к многомерным массивам. Вы совершенно правильно заметили, что их в C нет. Давайте же разберем, что значит [] в C. С одномерным массивом всё понятно:
char x[10];Тип переменной
xтут -- указательchar*, с этим не будете спорить? Пойдем далее, какой тип уxв этом коде:char x[10][10];? Возьму на себя смелость утверждать, что это будет
char**, то есть указатель на массив указателей. Какие действия нужно произвести, чтобы получить доступ к элементуx[3][3]? Начнем с простого -- в результате будет определенноchar. Как мы могли бы получитьcharизchar*? Нам нужно разыменование указателя, то есть мы берем адрес изchar*, обращаемся к памяти по этому адресу и получаем искомыйchar. Но у нас неchar*, у насchar**. Разыменованием мы получимchar*, то естьchar**это указатель на массив (в нашем случае) указателей. Чтобы получить искомый char, нам нужно разыменовывать указатель дважды. В соответствии со стандартом.Фактически, код:
char c=x[3][3];эквивалентен коду:
char c=*(*(x+3)+3);То, что компилятор делает оптимизацию, превращая массив в фортрановский (да, массивы такого типа так называются), нарушает стандарты. Если я в другом месте (а лучше всего, в другом объектном файле или библиотеке) попытаюсь дважды разыменовать указатель
char **x, то получу в лучшем случаеSIGSEGV, в худшем -- рандомное значение.Фактически, компилятор может хранить массив по-фортрановски, а для внешних вызовов сделать массив указателей, чтобы сохранить совместимость. Отлично. Но функция, получившая этот указатель, будет обязана разыменовывать указатели как положено, делая по нескольку лишних запросов в память, с этим ничего не поделаешь. И именно на эти грабли обычно наступают студенты и аспиранты)
eptr
00.00.0000 00:00+6в 90-х у меня был бумажный справочник стандарта C и в нем было написано, что это должен быть массив ссылок.
Каждые 5 лет в IT сменяется эпоха.
За 30 лет сменилось 6 эпох.
Также тот справочник мог быть низкого качества.С одномерным массивом всё понятно:
char x[10];Тип переменной
xтут -- указательchar*, с этим не будете спорить?Ещё как буду (ссылка на godbolt):
#include <stdlib.h> #include <stdio.h> int main(void) { char x[10]; char *p; printf("sizeof x: %zu\n", sizeof x); printf("sizeof p: %zu\n", sizeof p); return EXIT_SUCCESS; }Результат:
sizeof x: 10 sizeof p: 8Заметьте, все компиляторы единодушны.
Размеры указателя и массиваxотличаются.Это потому, что массив есть "смежно выделенное непустое множество объектов с определенным типом объекта-члена, называемым типом элемента", а никакой не указатель.
10 смежных
char' ов – вот вам иsizeof, равный 10.Пойдем далее, какой тип у
xв этом коде:char x[10][10];Возьму на себя смелость утверждать, что это будет
char**, то есть указатель на массив указателей.Если применить определение из стандарта, то никакой это не указатель на указатель.
Лучше взять
char x[10][20];, чтобы проще отличать было.x – это 10 смежно выделенных элементов, каждый из которых есть
char y[20];.
Аy– (условный, конечно,y) – это 20 смежно выделенных элементов, каждый из которых естьchar.То, что существует неявное преобразование от массива к указателю на его первый элемент, не делает массив указателем.
Фактически, код:
char c=x[3][3];эквивалентен коду:
char c=*(*(x+3)+3);Да, эквивалентно, и поэтому можно написать так:
char c = 3[3[x]];И ни один компилятор даже не пикнет (я не шучу).
Но это тоже никоим образом не превращает массив в указатель на его первый элемент.
То, что компилятор делает оптимизацию, превращая массив в фортрановский (да, массивы такого типа так называются), нарушает стандарты.
Вот странно.
Вроде и место в стандарте показал, где массив определяется, а до сих пор слышу, про какое-то нарушение.
Если я в другом месте (а лучше всего, в другом объектном файле или библиотеке) попытаюсь дважды разыменовать указатель
char **x, то получу в лучшем случаеSIGSEGV, в худшем -- рандомное значение.Смотрите, а внаглую 10-кратно разыменовал 10-мерный массив (ссылка godbolt):
#include <stdlib.h> #include <stdio.h> int main(void) { char x[1][2][3][4][5][6][7][8][9][10] = {{{{{{{{{{'!'}}}}}}}}}}; printf("sizeof x: %zu\n", sizeof x); printf("**********x: %c\n", **********x); return EXIT_SUCCESS; }и ничего не упало ни в каком из компиляторов.
Никаких, понимаете ли,SIGSEGV:sizeof x: 3628800 **********x: !Оптимизацию специально отключил, чтобы в ассемблерном коде видно было, что в массив кладётся 33 ('!') при инициализации и потом читается при разыменовании, а также распечатал размер массива, чтобы было видно, что он и правда, 10-мерный.
Да, интересный способ вычислить факториал 10...
Но функция, получившая этот указатель, будет обязана разыменовывать указатели как положено, делая по нескольку лишних запросов в память, с этим ничего не поделаешь.
Массив – не указатель.
Видите, я следую стандарту, и у меня ничего не падает.
И никаких лишних обращений к памяти у меня нет.Неужели вы продолжите утверждать, что массив массивов - это массив указателей?
Hemml
00.00.0000 00:00-3Ну вот не надо передергивать. При чем тут sizeof? Как одинаковость или разность значений, возвращаемых sizeof, определяет тип переменной? Вы вообще в курсе, что такое типы? Справочник, кстати, был отличный, перевод канонического стандарта, кажется, K&R, но я не уверен. Чай, не википедия какая. И про типы там всё было хорошо написано.
Все ваши примеры отлично работают в пределах одного исходинка. Попробуйте передать ссылку на ваш "массив массивов" во внешнюю процедуру, определенную в прилинкованной библиотеке и посмотрите, как там будет осуществляться доступ. Hint: подумайте о том, как та процедура узнает о размерности массива, по одному указателю. А передача указателя -- легитимный способ сослаться на массив.
Ну и про типы почитайте что-нибудь, очень полезно, рекомендую.
eptr
00.00.0000 00:00+3При чем тут sizeof?
Если то – указатель, и это – указатель, да ещё и на один и тот же тип, то у них размеры должны быть одинаковые, я из этого исходил.
Как одинаковость или разность значений, возвращаемых sizeof, определяет тип переменной?
Не в эту сторону, а в обратную.
Не типы одинаковые, потому что
sizeofодинаковый, а – раз одинаковые типы, то иsizeofу них должен быть одинаковый.Вы вообще в курсе, что такое типы?
Конечно, это же основополагающее начало языка C.
Справочник, кстати, был отличный, перевод канонического стандарта, кажется, K&R, но я не уверен. Чай, не википедия какая. И про типы там всё было хорошо написано.
Возможно, и отличный, правда, из ваших слов следует, что, похоже, местами, неправильный.
Все ваши примеры отлично работают в пределах одного исходинка.
Согласен, в пределах одного работают.
Попробуйте передать ссылку на ваш "массив массивов" во внешнюю процедуру, определенную в прилинкованной библиотеке и посмотрите, как там будет осуществляться доступ.
Обязательно попробую, прямо сейчас и попробую, только функцию размещу вместо библиотеки в отдельно компилирующемся файле.
Ведь это не меняет сути?
Hint: подумайте о том, как та процедура узнает о размерности массива, по одному указателю.
Я прямо расскажу об этом этой самой процедуре путём описания соответствующего типа её параметра.
Ну и про типы почитайте что-нибудь, очень полезно, рекомендую.
Лучше я тогда сразу и продемонстрирую своё понимание типов, чтобы у вас не оставалось сомнений, что я про типы не только читал, но и как следует в них разобрался.
Функция, в числе прочего, будет принимать константный указатель на "4-мерный массив".
На самом деле, это будет константный указатель на массив массивов массивов массивов
int'ов.Две функции: одна читает, другая пишет.
Файл
main.c:#include <stdlib.h> #include <stdio.h> #include "array.h" void fun(int const value) { int array[10][10][10][10] = {0}; printf("value: %i\n", value); puts(""); printf("array[1][2][3][4] before: %i\n", get_array_element(1, 2, 3, 4, &array)); array[1][2][3][4] = value; printf("array[1][2][3][4] after : %i\n", get_array_element(1, 2, 3, 4, &array)); puts(""); printf("array[4][3][2][1] before: %i\n", array[4][3][2][1]); set_array_element(4, 3, 2, 1, &array, value); printf("array[4][3][2][1] after : %i\n", array[4][3][2][1]); } int main(void) { fun(777); return EXIT_SUCCESS; }В функции
funзаводится "4-мерный" массив, по 10 элементов в каждом "измерении", и инициализируется 0-ми.Далее, сначала распечатывается значение из массива по индексам 1, 2, 3 и 4 с использованием функции
get_array_element, скомпилированной в другом файле, затем это же место модифицируется путём прямого обращения к массиву, затем опять читается функциейget_array_element, чтобы убедиться, что функция "видит" массив, и видит его правильно.После этого распечатывается значение из массива по индексам 4, 3, 2 и 1 с помощью прямого обращения к массиву, затем это же место модифицируется функцией
set_array_element, и опять распечатывается с помощью прямого обращения к массиву, чтобы увидеть, что функция записала значение в массив, и записала его туда, куда нужно.Файл
array.c:#include "array.h" int get_array_element( size_t const x0, size_t const x1, size_t const x2, size_t const x3, int (*const array)[10][10][10][10] ) { return (*array)[x0][x1][x2][x3]; } void set_array_element( size_t const x0, size_t const x1, size_t const x2, size_t const x3, int (*const array)[10][10][10][10], int const value) { (*array)[x0][x1][x2][x3] = value; }Реализации функций
get_array_elementиset_array_element.В числе прочего, функции принимают указатель на массив.
Видите, как я передал информацию о размерностях массива по одному указателю?
Файл
array.h:#ifndef ARRAY_H__ #define ARRAY_H__ #include <stddef.h> int get_array_element(size_t x0, size_t x1, size_t x2, size_t x3, int (*array)[10][10][10][10]); void set_array_element(size_t x0, size_t x1, size_t x2, size_t x3, int (*array)[10][10][10][10], int value); #endif // ARRAY_H__Здесь – декларации функций
get_array_elementиset_array_element, чтобы изmain.cих можно было правильно вызвать.Поскольку godbolt теперь поддерживает cmake с возможностью компиляции множества файлов, предоставляя примитивную IDE, то – вот ссылка на микро-проект с этим кодом.
Теперь самое интересное: в ассемблерном коде для функции
mainвидно, что функцияfunвызывается, а не inline'ится:main: sub rsp,0x8 mov edi,0x309 call 401170 <fun> xor eax,eax add rsp,0x8 retВ ассемблерном коде функции
funтакже видно, что функцииget_array_elementиset_array_elementвызываются, а не inline'ятся (компилятору здесь некуда деться, потому что компиляция – раздельная):fun: push rbx mov edx,0x9c40 mov ebx,edi xor esi,esi sub rsp,0x9c40 mov rdi,rsp call 401050 <memset@plt> mov esi,ebx mov edi,0x402004 xor eax,eax call 401040 <printf@plt> mov edi,0x402086 call 401030 <puts@plt> mov r8,rsp mov ecx,0x4 mov edx,0x3 mov esi,0x2 mov edi,0x1 call 401260 <get_array_element> mov edi,0x40200f mov esi,eax xor eax,eax call 401040 <printf@plt> mov r8,rsp mov ecx,0x4 mov edx,0x3 mov esi,0x2 mov edi,0x1 mov DWORD PTR [rsp+0x1348],ebx call 401260 <get_array_element> mov edi,0x40202d mov esi,eax xor eax,eax call 401040 <printf@plt> mov edi,0x402086 call 401030 <puts@plt> mov esi,DWORD PTR [rsp+0x4384] mov edi,0x40204b xor eax,eax call 401040 <printf@plt> mov r9d,ebx mov r8,rsp mov ecx,0x1 mov edx,0x2 mov esi,0x3 mov edi,0x4 call 401280 <set_array_element> mov esi,DWORD PTR [rsp+0x4384] mov edi,0x402069 xor eax,eax call 401040 <printf@plt> add rsp,0x9c40 pop rbx retДолгожданный ассемблерный код функции
get_array_element:get_array_element: imul rdi,rdi,0x3e8 lea rax,[rdx+rdx*4] imul rsi,rsi,0x64 lea rax,[rdi+rax*2] add rax,rsi add rax,rcx mov eax,DWORD PTR [r8+rax*4] retВидите, сколько там обращений к памяти?
Я вижу только одно, в предпоследней инструкции.Долгожданный ассемблерный код функции
set_array_element:set_array_element: imul rdi,rdi,0x3e8 lea rax,[rdx+rdx*4] imul rsi,rsi,0x64 lea rax,[rdi+rax*2] add rax,rsi add rax,rcx mov DWORD PTR [r8+rax*4],r9d retВидите, сколько в этой функции обращений к памяти?
Я опять вижу только одно, в предпоследней инструкции.А, да, результат исполнения программы:
value: 777 array[1][2][3][4] before: 0 array[1][2][3][4] after : 777 array[4][3][2][1] before: 0 array[4][3][2][1] after : 777Я нигде не ошибся в рассуждениях и в предоставленном коде?
Hemml
00.00.0000 00:00Вы с удивительным упорством пытаетесь доказать ошибочное утверждение, прибегая при этом к уловкам, не надо так. Давайте проведем чистый эксперимент: передача массива по ссылке, процедуры get/set_element не знают размерность массива. Чистый C.
eptr
00.00.0000 00:00Вы с удивительным упорством пытаетесь доказать ошибочное утверждение, прибегая при этом к уловкам, не надо так.
Ошибочное оно или верное, думаю, выяснится по результатам.
В чём заключаются уловки, что не так?
Давайте проведем чистый эксперимент: передача массива по ссылке, процедуры get/set_element не знают размерность массива. Чистый C.
Что вы имеете ввиду под передачей массива по ссылке (в C нет ссылок, только указатели)?
Можете прототип (декларацию, объявление) функции написать, как она должна массив принимать?
Сейчас у меня прототип написан так:
int get_array_element(size_t x0, size_t x1, size_t x2, size_t x3, int (*array)[10][10][10][10]);А как надо, если не так?
Hemml
00.00.0000 00:00-2Изначально мое утверждение было -- фортрановские массивы быстрее, чем массивы с C, так как требуют меньше обращений к памяти. Это так, по стандарту. Тут выходите вы и начинаете опровергать, приводя примеры. Я понимаю, как вы к этому пришли -- попробовали, о, доступ к массиву не через массив ссылок, а напрямую. Из этого вы сразу же делаете вывод о том, что в C массивы работают так всегда и начинаете защищать этот вывод опять же при помощи примеров.
Я тоже люблю экспериментировать, в этом мы с вами близки. Но у меня хватает жизненного опыта, чтобы не делать далеко идущих обобщений из частных случаев. Конкретно, в вашем случае, компилятор нарушает (ради оптимизации) канонический (описанный в стандарте) способ работы с массивами по двум причинам: 1) он точно знает размерность массива; 2) он точно знает, что с этим массивом не будет работать никакой внешний код. Внешний, в данном случае, не контроллируемый этим же компилятором. Тогда и только тогда работа с массивом будет происходить так, как вы предполагаете. Стоит одному из этих условий нарушиться и вы получите очень медленный код в лучшем случае. В худшем -- неопределенное поведение.
Когда K&R проектировали C, они сознательно пошли на такой способ работы с массивами. Это дает возможность определять адрес любого элемента, не зная размерности массива. Скорость, вероятно, для них не была приоритетом в то время. В принципе, массивы в фортрановском стиле в С реализовать можно и так, через макросы, например. В фортране же работа с многомерными массивами зашита прямо в язык и в нем с ними работать удобнее.
Upd: во времена создания C процессоры просто не имели многоуровневых кэшей и скорость доступа к массивам была, наверное, даже быстрее, чем в фортране, так как фортрану нужно подгрузить из памяти размерности, потом провести сложения и умножения, тогда как C достаточно было всего лишь подгрузить значения. Но в современных процессорах доступ к памяти стоит много дороже, чем в PDP11 и фортран выигрывает)
eptr
00.00.0000 00:00+3Изначально мое утверждение было -- фортрановские массивы быстрее, чем массивы с C, так как требуют меньше обращений к памяти.
Да, и я возражал по этому пункту.
Это так, по стандарту.
Я вам приводил выдержку из стандарта, из которой не следует, что массивы требуют множества обращений к памяти.
Тут выходите вы и начинаете опровергать, приводя примеры.
Да, но не только примеры, но и ссылки на стандарт.
Я понимаю, как вы к этому пришли -- попробовали, о, доступ к массиву не через массив ссылок, а напрямую.
Нет, я пришёл к этому выводу, исходя не из практики, а из теории.
Из этого вы сразу же делаете вывод о том, что в C массивы работают так всегда и начинаете защищать этот вывод опять же при помощи примеров.
Не только примеры, но и ссылки на стандарт.
Примеры – только как косвенное подтверждение, поскольку компиляторы реализуют стандарт.
Я тоже люблю экспериментировать, в этом мы с вами близки. Но у меня хватает жизненного опыта, чтобы не делать далеко идущих обобщений из частных случаев.
Здесь вы опять исходите из того, что я пришёл к своим выводам, исходя из практики, но это – не так, я пришел к ним, исходя из теории, поэтому это – не обобщение.
Конкретно, в вашем случае, компилятор нарушает (ради оптимизации) канонический (описанный в стандарте) способ работы с массивами
Компилятор может выполнять некоторые оптимизации "как бы" "нарушающие стандарт", пока изнутри языка C этого не видно.
Например, он может не помещать переменную в память, держа её в регистре, если адрес этой переменной не берётся: изнутри этого кода нельзя узнать, лежит переменная в памяти или нет, поэтому можно "как бы" "нарушать стандарт", ведь каждый lvalue-объект должен иметь адрес.
Например, для данной функции:
void f0() { for (int x = 0; x < 5; ++x) { printf("x: %i\n", x); } }Генерируется код, который держит переменную не в памяти и не обращается к ней:
.LC7: .string "x: %i\n" f0: push rbx xor ebx, ebx .L7: mov esi, ebx mov edi, OFFSET FLAT:.LC7 xor eax, eax inc ebx call printf cmp ebx, 5 jne .L7 pop rbx retНо стоит изменить код, взяв адрес этой переменной:
void f1() { for (int x = 0; x < 5; ++x) { printf("x: %i, &x: %p\n", x, (void *)&x); } }Как переменная сразу же оказывается в памяти:
.LC8: .string "x: %i, &x: %p\n" f1: sub rsp, 24 mov DWORD PTR [rsp+12], 0 xor esi, esi .L11: lea rdx, [rsp+12] mov edi, OFFSET FLAT:.LC8 xor eax, eax call printf mov eax, DWORD PTR [rsp+12] lea esi, [rax+1] mov DWORD PTR [rsp+12], esi cmp esi, 4 jle .L11 add rsp, 24 retПоэтому компилятор можно "простимулировать" прекратить "как бы" "нарушать стандарт".
Конкретно, в вашем случае, компилятор нарушает (ради оптимизации) канонический (описанный в стандарте) способ работы с массивами по двум причинам: 1) он точно знает размерность массива;
Хорошо, уберём, во время компиляции он не будет знать, и 1-ая причина исчезнет.
2) он точно знает, что с этим массивом не будет работать никакой внешний код. Внешний, в данном случае, не контроллируемый этим же компилятором.
Сейчас происходит раздельная компиляция.
Когда компилятор компилирует
main.cи видит передачу массива в функциюget_array_elementилиset_array_element, он не только не видит реализации этих функций, но и не знает, каким компилятором будет скомпилирован тот файл, где они определены.Поэтому 2-ой причины при раздельной компиляции файлов просто нет.
Тогда и только тогда работа с массивом будет происходить так, как вы предполагаете. Стоит одному из этих условий нарушиться и вы получите очень медленный код в лучшем случае. В худшем -- неопределенное поведение.
Вот и проверим (ссылка на godbolt).
Я указал cmake'у показывать строки компиляции, и теперь хорошо видно, что файлы сначала компилируются раздельно, а затем получившиеся объектные файлы линкуются.
Также добавил ещё один компилятор, для верности.
Однако, теперь мне требуется передавать не только индексы, по которым требуется обратиться к массиву, но и величины его размерностей.
Компиляторы держат не более 6-и параметров на регистрах, остальные начинают помещать в память, и может быть трудно понять в ассемблерном коде, где обращения к памяти, связанные с работой с массивом, а где – с параметрами, а мне уже нужно передавать до 10.
Поэтому я воспользовался битовыми полями в структуре, чтобы в одном параметре передать сразу все индексы, а в другом – сразу все величины его размерностей, поэтому прототипы этих функций выглядят так:
typedef struct { size_t const x0:5; size_t const x1:5; size_t const x2:5; size_t const x3:5; } dimensions, indices; int get_array_element(dimensions const dim, int (*array)[dim.x0][dim.x1][dim.x2][dim.x3], indices idx); void set_array_element(dimensions const dim, int (*array)[dim.x0][dim.x1][dim.x2][dim.x3], indices idx, int value);Реализации – так:
int get_array_element( dimensions const dim, int (*const array)[dim.x0][dim.x1][dim.x2][dim.x3], indices const idx ) { return (*array)[idx.x0][idx.x1][idx.x2][idx.x3]; } void set_array_element( dimensions const dim, int (*const array)[dim.x0][dim.x1][dim.x2][dim.x3], indices const idx, int const value) { (*array)[idx.x0][idx.x1][idx.x2][idx.x3] = value; }В параметре
dimсодержатся величины размерностей переданного массива, в параметреidx– индексы, по которым следует обратиться к массивуТеперь компилятор при компиляции файла
array.cне будет знать размерностей массивов, которые будут передаваться в эти функции.В основном же файле я специально сначала передам и проверю работу массива с одними величинами размерностей, а потом с другими, и при этом с этими разными массивами будут работать одни и те же функции
get_array_elementиset_array_element:void fun(dimensions const dim, indices const get_idx, indices const set_idx, int const value) { int array[dim.x0][dim.x1][dim.x2][dim.x3]; memset(&array, 0, sizeof array); printf("dimensions: %u, %u, %u, %u\n", dim.x0, dim.x1, dim.x2, dim.x3); printf("indices for get: %u, %u, %u, %u\n", get_idx.x0, get_idx.x1, get_idx.x2, get_idx.x3); printf("indices for set: %u, %u, %u, %u\n", set_idx.x0, set_idx.x1, set_idx.x2, set_idx.x3); printf("value: %i\n", value); puts(""); printf("array[%u][%u][%u][%u] before: %i\n", get_idx.x0, get_idx.x1, get_idx.x2, get_idx.x3, get_array_element(dim, &array, get_idx)); array[get_idx.x0][get_idx.x1][get_idx.x2][get_idx.x3] = value; printf("array[%u][%u][%u][%u] after : %i\n", get_idx.x0, get_idx.x1, get_idx.x2, get_idx.x3, get_array_element(dim, &array, get_idx)); puts(""); printf("array[%u][%u][%u][%u] before: %i\n", set_idx.x0, set_idx.x1, set_idx.x2, set_idx.x3, array[set_idx.x0][set_idx.x1][set_idx.x2][set_idx.x3]); set_array_element(dim, &array, set_idx, value); printf("array[%u][%u][%u][%u] after : %i\n", set_idx.x0, set_idx.x1, set_idx.x2, set_idx.x3, array[set_idx.x0][set_idx.x1][set_idx.x2][set_idx.x3]); } int main(void) { puts("Test1:\n-----"); fun((dimensions){10, 10, 10, 10}, (indices){1, 2, 3, 4}, (indices){4, 3, 2, 1}, 777); puts("\nTest2:\n-----"); fun((dimensions){5, 15, 7, 21}, (indices){3, 12, 6, 19}, (indices){4, 9, 0, 20}, 333); return EXIT_SUCCESS; }Первый раз массив получает размерности 10, 10, 10 и 10, а второй раз – 5, 15, 7, 21.
Если что, при вызове функции
funиз функцииmainв качестве параметров используются составные литералы.Ассемблерный код функции
get_array_element, скомпилированный gcc:get_array_element: mov r10,rsi mov r9,rdi mov rsi,rdi shr r9,0xf shr rsi,0xa and r9d,0x1f and esi,0x1f imul rsi,r9 mov rax,rdi mov r8,rdx shr rax,0x5 shr r8,0x5 mov rdi,rdx and eax,0x1f imul rax,rsi and r8d,0x1f shr rdi,0xa imul r8,rsi mov rcx,rdx and edi,0x1f imul rdi,r9 shr rcx,0xf and edx,0x1f imul rdx,rax and ecx,0x1f lea rax,[rcx+r8*1] add rax,rdi add rax,rdx mov eax,DWORD PTR [r10+rax*4] retТо же для функции
set_array_element:set_array_element: mov r10,rsi mov r8,rdi mov rsi,rdi shr r8,0xf shr rsi,0xa and r8d,0x1f and esi,0x1f imul rsi,r8 mov rax,rdi mov rdi,rdx shr rdi,0x5 and edi,0x1f imul rdi,rsi shr rax,0x5 and eax,0x1f mov r9,rdi mov rdi,rdx imul rax,rsi shr rdi,0xa mov r11d,ecx and edi,0x1f mov rcx,rdx imul rdi,r8 shr rcx,0xf and edx,0x1f imul rdx,rax and ecx,0x1f lea rax,[rcx+r9*1] add rax,rdi add rax,rdx mov DWORD PTR [r10+rax*4],r11d retВ каждой из функций я вижу только одно обращение к памяти, в предпоследней инструкции.
Теперь для clang'а,
get_array_element:get_array_element: mov ecx,edx mov eax,0x50f mov r9d,0x505 mov r8d,0x50a bextr r10d,edi,r9d and ecx,0x1f bextr r11d,edi,r8d bextr eax,edi,eax bextr r9d,edx,r9d bextr r8d,edx,r8d mov edi,0x50f imul r11,rax imul rcx,r10 imul r8,rax bextr rdx,rdx,rdi imul rcx,r11 imul r9,r11 lea rcx,[rsi+rcx*4] lea rax,[rcx+r9*4] lea rax,[rax+r8*4] mov eax,DWORD PTR [rax+rdx*4] retИ
set_array_element:set_array_element: push r14 push rbx mov ebx,0x50f mov r8d,0x505 mov r9d,0x50a mov eax,0x50f bextr r14d,edi,eax bextr r11d,edi,r9d bextr eax,edx,r9d bextr r10d,edi,r8d bextr edi,edx,r8d bextr rbx,rdx,rbx and edx,0x1f imul r11,r14 imul rdx,r10 imul rax,r14 imul rdx,r11 imul rdi,r11 lea rdx,[rsi+rdx*4] lea rdx,[rdx+rdi*4] lea rax,[rdx+rax*4] mov DWORD PTR [rax+rbx*4],ecx pop rbx pop r14 retВ коде clang'а для этих функций я также вижу по одному обращению к памяти.
Итак:
При компиляции
array.cкомпилятор не только не знает размера массива, передающегося в функции, но теперь туда передаются массивы с разными величинами размерностей.Раздельная компиляция не позволяет компилятору при компиляции файла
main.cсчитать, что с передаваемым массивом не будет работать внешний код, потому что в этот момент он не знает даже, каким компилятором будет собран тот файл (в нашем случае –array.c), в котором будут находиться реализации функцийget_array_elementиset_array_element.Fortran не выигрывает.
Hemml
00.00.0000 00:00-1Зачем такие сложности? Вот более простой пример, полностью соответствующий стандарту:
void test(char ***x) { x[5][5][5]=100; }Не в курсе, что такое godbolt, потому скомпилирую простым gcc:
$ gcc -c -save-temps test.c $ ls test.c test.i test.o test.sСодержимое test.s:
.text .globl _test _test: LFB0: pushq %rbp LCFI0: movq %rsp, %rbp LCFI1: movq %rdi, -8(%rbp) movq -8(%rbp), %rax addq $40, %rax movq (%rax), %rax addq $40, %rax movq (%rax), %rax addq $5, %rax movb $100, (%rax) nop popq %rbp LCFI2: ret LFE0: .section __TEXT,__eh_frame,coalesced,no_toc+strip_static_syms+live_support EH_frame1: .set L$set$0,LECIE1-LSCIE1 .long L$set$0 LSCIE1: .long 0 .byte 0x1 .ascii "zR\0" .byte 0x1 .byte 0x78 .byte 0x10 .byte 0x1 .byte 0x10 .byte 0xc .byte 0x7 .byte 0x8 .byte 0x90 .byte 0x1 .align 3 LECIE1: LSFDE1: .set L$set$1,LEFDE1-LASFDE1 .long L$set$1 LASFDE1: .long LASFDE1-EH_frame1 .quad LFB0-. .set L$set$2,LFE0-LFB0 .quad L$set$2 .byte 0 .byte 0x4 .set L$set$3,LCFI0-LFB0 .long L$set$3 .byte 0xe .byte 0x10 .byte 0x86 .byte 0x2 .byte 0x4 .set L$set$4,LCFI1-LCFI0 .long L$set$4 .byte 0xd .byte 0x6 .byte 0x4 .set L$set$5,LCFI2-LCFI1 .long L$set$5 .byte 0xc .byte 0x7 .byte 0x8 .align 3 LEFDE1: .ident "GCC: (MacPorts gcc8 8.4.0_0) 8.4.0" .subsections_via_symbolsДавайте вместе подсчитаем обращения к памяти?
eptr
00.00.0000 00:00+3Зачем такие сложности? Вот более простой пример, полностью соответствующий стандарту:
void test(char ***x) { x[5][5][5]=100; }Замечательно, только вы здесь работаете не с массивами массивов, а с массивами указателей на элементы другого массива.
То, что вы индексируете указатель, не делает из него массива.Не в курсе, что такое godbolt, потому скомпилирую простым gcc:
Там у меня ссылка есть, можно ознакомиться.
Кстати, ваша функция выглядит там замечательно, особенно если включить оптимизацию:
test: mov rax, QWORD PTR [rdi+40] mov rax, QWORD PTR [rax+40] mov BYTE PTR [rax+5], 100 retДавайте вместе подсчитаем обращения к памяти?
Здесь прекрасно видно, что сначала идут два чтения, а потом одна запись, причём чтения индексируются на 40, а запись на 5.
Это – потому, что эти два чтения соответствуют разыменованиям указателей.
Что необходимо передать в вашу функцию?
void test(char ***x) { x[5][5][5]=100; } void fun(void) { char a[6] = {0}; char *b[6] = {a, a, a, a, a, a}; char **c[6] = {b, b, b, b, b, b}; test(c); printf("с[5][5][5]: %i\n", c[5][5][5]); } int main(void) { fun(); return EXIT_SUCCESS; }В вашу функцию можно передать массив указателей на указатель на
char, что представлено у меня в функцииfunв виде переменнойc.Инициализирован этот массив
cдолжен быть указателями на первые элементы массивов указателей наchar, возможно, даже одинаковыми, что представлено у меня в функцииfunв виде переменойb.Массив
bдолжен быть инициализирован указателями на первые элементы массиваchar'ов, возможно, одинаковыми, что представлено у меня в функцииfunв виде переменнойa.У вас функция
testдля формирования ей параметра требует создания, кроме основного массиваchar'ов, ещё не менее двух вспомогательных, из которых сначала необходимо выполнить два чтения, прежде чем будет получен адрес, по которому следует записать в массивchar'ов.Если вы проверите, то увидите, что выражение
c[5][5][5]в коде выше "увидит" значение, записанное вашей функциейtest.Как вы думаете, что получится, если попробовать передать вашей функции "3-мерный" массив?
Примерно, так:
void test(char ***x) { x[5][5][5]=100; } void fun(void) { char a[6][6][6] = {0}; test(a); printf("a[5][5][5]: %i\n", a[5][5][5]); } int main(void) { fun(); return EXIT_SUCCESS; }Каков должен быть тип параметра
xу функцииtestв этом коде, чтобы всё заработало правильно?
Hemml
00.00.0000 00:00-1Хм. То есть одна и та же конструкция x[1][2][3] теперь в C может работать совершенно по-разному? Хотя выглядит одинаково? И это уже даже вошло в стандарт? Лол.
Возвращаясь к теме поста -- вот как раз пример того, как умирают языки. В попытке догнать Фортран (еще раз лол) ребята придумали новый язык, похожий внешне на C, но программы в нем теперь работают по-другому. По странному недоразумению они тоже назвали его C. Молодцы, что уж тут. Почему было не использовать сразу Фортран?
eptr
00.00.0000 00:00+2Хм. То есть одна и та же конструкция x[1][2][3] теперь в C может работать совершенно по-разному? Хотя выглядит одинаково?
Да, и это зависит от типа, поскольку адресная арифметика зависит от размера типа, на который указывает указатель.
И это уже даже вошло в стандарт?
Это вошло ещё в самый первый стандарт, в 89-ый.
Лол.
Ну, какой же это лол?
Здесь лол может быть только один.Чтобы полноценно использовать вашу функцию по всему исходному массиву, необходимо два дополнительных массива (я дополнил вашу функцию, чтобы она могла присваивать любые значения по любым индексам):
#include <stdlib.h> #include <stdio.h> #define ELEMS(a) (sizeof (a) / sizeof *(a)) void test(char ***x, size_t idx0, size_t idx1, size_t idx2, char value) { x[idx0][idx1][idx2] = value; } void fun(void) { char a[6][6][6] = {0}; char *b[6][6] = { {a[0][0], a[0][1], a[0][2], a[0][3], a[0][4], a[0][5]}, {a[1][0], a[1][1], a[1][2], a[1][3], a[1][4], a[1][5]}, {a[2][0], a[2][1], a[2][2], a[2][3], a[2][4], a[2][5]}, {a[3][0], a[3][1], a[3][2], a[3][3], a[3][4], a[3][5]}, {a[4][0], a[4][1], a[4][2], a[4][3], a[4][4], a[4][5]}, {a[5][0], a[5][1], a[5][2], a[5][3], a[5][4], a[5][5]} }; char **c[6] = {b[0], b[1], b[2], b[3], b[4], b[5]}; test(c, 5, 5, 5, 100); printf("c[5][5][5]: %i\n", c[5][5][5]); char x = 0; for (size_t idx0 = 0; idx0 < ELEMS(c); ++idx0) { for (size_t idx1 = 0; idx1 < ELEMS(*b); ++idx1) { for (size_t idx2 = 0; idx2 < ELEMS(**a); ++idx2) { test(c, idx0, idx1, idx2, ++x); } } } x = 0; for (size_t idx0 = 0; idx0 < ELEMS(a); ++idx0) { for (size_t idx1 = 0; idx1 < ELEMS(*a); ++idx1) { for (size_t idx2 = 0; idx2 < ELEMS(**a); ++idx2) { if (a[idx0][idx1][idx2] != ++x) { printf("Check failed for idx0: %zu, idx1: %zu, idx2: %zu\n", idx0, idx1, idx2); } } } } } int main(void) { fun(); return EXIT_SUCCESS; }Массивы
bиcявляются дополнительными, без них вашу функцию использовать невозможно.В первом цикле для заполнения массива
aиспользуется ваша функция, которая работает через дополнительные массивыbиc, чтобы получить доступ к элементам массиваa, а во втором цикле, уже путём прямого обращения к массивуa, проверяется, что массивaзаполнен правильно вашей функцией.Попробуйте в инициализации массива
bпоменять какой-нибудь инициализатор, например, вa[3][1]замените 1 на 0, чтобы получилосьa[3][0], и второй цикл сразу определит, что "массив-то не настоящий".Но даже в этом варианте ваша функция практически никак не усложнилась:
test: mov rax, QWORD PTR [rdi+rsi*8] mov rax, QWORD PTR [rax+rdx*8] mov BYTE PTR [rax+rcx], r8b retДва чтения из вспомогательных массивов – из одного, а потом из другого, и только затем одна запись.
Если же использовать массив массивов массивов, то всё становится значительно проще:
void test(char (*x)[6][6], size_t idx0, size_t idx1, size_t idx2, char value) { x[idx0][idx1][idx2] = value; } void fun(void) { char a[6][6][6] = {0}; test(a, 5, 5, 5, 100); printf("c[5][5][5]: %i\n", a[5][5][5]); char x = 0; for (size_t idx0 = 0; idx0 < ELEMS(a); ++idx0) { for (size_t idx1 = 0; idx1 < ELEMS(*a); ++idx1) { for (size_t idx2 = 0; idx2 < ELEMS(**a); ++idx2) { test(a, idx0, idx1, idx2, ++x); } } } x = 0; for (size_t idx0 = 0; idx0 < ELEMS(a); ++idx0) { for (size_t idx1 = 0; idx1 < ELEMS(*a); ++idx1) { for (size_t idx2 = 0; idx2 < ELEMS(**a); ++idx2) { if (a[idx0][idx1][idx2] != ++x) { printf("Check failed for idx0: %zu, idx1: %zu, idx2: %zu\n", idx0, idx1, idx2); } } } } }При этом функция
testкомпилируется в следующее:test: lea rax, [rsi+rsi*8] lea rax, [rdi+rax*4] lea rdx, [rdx+rdx*2] lea rax, [rax+rdx*2] mov BYTE PTR [rax+rcx], r8b retКак видите, только одно обращение к памяти.
Массив
aможно передать более красивым образом:test(&a, idx0, idx1, idx2, ++x);А функция
testтогда будет выглядеть так:void test(char (*x)[6][6][6], size_t idx0, size_t idx1, size_t idx2, char value) { (*x)[idx0][idx1][idx2] = value; }И транслируется она в следующее:
test: lea rax, [rsi+rsi*8] lea rdx, [rdx+rdx*2] sal rax, 2 lea rax, [rax+rdx*2] add rdi, rax mov BYTE PTR [rdi+rcx], r8b retТоже одно обращение к памяти.
Возвращаясь к теме поста -- вот как раз пример того, как умирают языки.
Вы рейтинги использования языков смотрели?
В попытке догнать Фортран (еще раз лол) ребята придумали новый язык, похожий внешне на C, но программы в нем теперь работают по-другому.
Они так всегда работали, да и язык – тот же.
Никому не требовалось догонять Fortran: в языке C эффективность, то есть, быстродействие, всегда стояла во главе угла.
Помните, вы советовали мне почитать про типы?
Теперь вы убедились, что я действительно разобрался в типах, и как раз мне про них читать, чтобы грамотно ими воспользоваться, не требуется?
Вот вам и весь лол.
По странному недоразумению они тоже назвали его C. Молодцы, что уж тут.
Этого не было, потому что поведение с тех пор не изменилось.
Не хотите ли вы сказать, что это они – дураки, а не вы не разобрались?
Помните, я заметил, что справочник, на который вы сослались, может, и замечательный, но, местами, неправильный?
Так и вышло.
Несколько постов назад вы писали:
Вы с удивительным упорством пытаетесь доказать ошибочное утверждение, прибегая при этом к уловкам, не надо так.
Теперь вы видите, что я доказывал верное, а не ошибочное утверждение?
Видите, что никаких уловок нет и в помине?
Я подозреваю, что ваши утверждения об умирании языков, имея ввиду C, а также попытки насмехаться над теми, кто развивал язык C, настолько же несостоятельны.
Почему было не использовать сразу Фортран?
Наверное, тому есть причины, раз Fortran не настолько распространён, несмотря на то, что он – более ранний, чем другие языки.
Итак:
Массивы массивов в языке C не являются массивами указателей и требуют ровно одного обращения в память.
Fortran в смысле быстродействия не имеет преимуществ перед C.
Hemml
00.00.0000 00:00-2С89, это же ANSI C, тот самый стандарт, который много лет никто не хотел поддерживать? Ну, тогда понятно. Мы просто говорим о разных языках, хотя они, по недоразумению, называются одинаково)
eptr
00.00.0000 00:00+3С89, это же ANSI C, тот самый стандарт, который много лет никто не хотел поддерживать? Ну, тогда понятно. Мы просто говорим о разных языках, хотя они, по недоразумению, называются одинаково)
Нет, язык – тот же.
Та же программа с минимальными модификациями, убирающими использование возможностей новых стандартов, в режиме компиляции C89:
#include <stdlib.h> #include <stdio.h> #define ELEMS(a) (sizeof (a) / sizeof *(a)) void test(char (*x)[6][6], size_t idx0, size_t idx1, size_t idx2, char value) { x[idx0][idx1][idx2] = value; } void fun(void) { char a[6][6][6] = {0}; char x; size_t idx0, idx1, idx2; test(a, 5, 5, 5, 100); printf("c[5][5][5]: %i\n", a[5][5][5]); for (x = 0, idx0 = 0; idx0 < ELEMS(a); ++idx0) { for (idx1 = 0; idx1 < ELEMS(*a); ++idx1) { for (idx2 = 0; idx2 < ELEMS(**a); ++idx2) { test(a, idx0, idx1, idx2, ++x); } } } for (x = 0, idx0 = 0; idx0 < ELEMS(a); ++idx0) { for (idx1 = 0; idx1 < ELEMS(*a); ++idx1) { for (idx2 = 0; idx2 < ELEMS(**a); ++idx2) { if (a[idx0][idx1][idx2] != ++x) { printf("Check failed for idx0: %lu, idx1: %lu, idx2: %lu\n", idx0, idx1, idx2); } } } } } int main(void) { fun(); return EXIT_SUCCESS; }Вот ссылка туда, где это посмотреть можно online (в строках опций компиляции везде прописано
-std=c89).И указатель на массив массивов прекрасно передаётся, и всё вместе не менее прекрасно работает, что является дополнительным косвенным подтверждением, что массивы и раньше такими были.
Так что язык – тот же, и мы говорим об одном и том же языке.
Hemml
00.00.0000 00:00-2Нет, язык не тот же, несмотря на схожесть названий) В момент, когда ANSI решили придумать свой стандарт, язык C уже уществовал лет 20. Поскольку ANSI C был несовместим с C (на C уже было много чего написано, в том числе UNIX), а также, подозреваю, по причине нелюбви разработчиков к бюрократам из ANSI, стандарт очень долго существовал "на бумаге", но мало кем поддерживался и использовался. Потом всё изменилось, конечно, Linux пришел на смену UNIX, а в разработку пришло много вчерашних студентов, изучавших программирование на курсах, так что ANSI всё же стал использоваться.
eptr
00.00.0000 00:00+5Нет, язык не тот же, несмотря на схожесть названий) В момент, когда ANSI решили придумать свой стандарт, язык C уже уществовал лет 20. Поскольку ANSI C был несовместим с C (на C уже было много чего написано, в том числе UNIX), а также, подозреваю, по причине нелюбви разработчиков к бюрократам из ANSI, стандарт очень долго существовал "на бумаге", но мало кем поддерживался и использовался.
Хорошо, вернёмся в 1979 год и посмотрим.
Вот по этой ссылке выложен iso-образ загрузочного CD-ROM'а, с которого запускается симулятор PDP-11 с образом UNIX V7.
Правда, чтобы набрать и, главное, отредактировать там текст программы, необходимо было освоить строчный редактор
ed, потому что там нет дажеvi, но я справился.
Исходные файлы двух версий функции test В файле
1.cнаходится мой вариант реализации функцииtest, а в файле2.c– ваш.Как видно, параметры объявлены в старом стиле, потому что компилятор там настолько древний, что не поддерживает современного способа указания типов параметров.

Исходный файл с функцией main В файле
main.cнаходится функцияmain, которая вызывает функциюtest.Сначала массив
aобнуляется (не удалось найти, в какой библиотеке находится функцияmemset, поэтому пришлось обнулить вручную), затем распечатывается элементa[5][5][5]до вызова функцииtest, а потом ещё раз после, чтобы определить, удалось ли функцииtestправильно записать переданное ей значение по тем же самым индексам.Переменная
vоказалась по недосмотру лишней, но она не мешает процессу.
Компиляция, линковка и список получившихся файлов Все 3 исходных файла были раздельно скомпилированы в ассемблер.
Затем
main.sи1.sбыли скомпилированы до объектных файлов и слинкованы в исполняемый файл с именем1, а тот жеmain.sи2.sскомпилированы и слинкованы в исполняемый файл с именем2.Теперь исполняемый файл с именем
1использует мою версию функции test, а с именем2– вашу версию.Функции
mainв обоих исполняемых файлах идентичны.Теперь посмотрим, в какой ассемблерный код скомпилировались обе версии функции
test.Сначала моя версия:

Ассемблерный код моей версии функции test Интересующая часть кода находится между метками
L2иL3.:L2:mov 4(r5),r0 movb 6(r5),327(r0) L3:jmp cretРегистр
r5, очевидно, играет роль указателя frame'а стека.В первой строке в
r0из первого параметра4(r5)(который берётся по адресуr5 + 4) загружается указатель на массив массивов (char (*a)[6][6]).Во второй строке второй параметр
6(r5)(который берётся по адресуr5 + 6) в той же инструкции записывается в327(r0)(по адресуr0 + 327).Здесь используются 8-ричная система счисления, 327 в 8-ричной системе есть 215 в десятичной (в массиве 216 элементов, запись идёт в последний элемент).
Итого – одна запись в память, если не считать обращений к frame'у стека.
Теперь – ваша версия:

Ассемблерный код вашей версии функции test Интересующая часть также находится между метками
L2иL3:L2:mov 4(r5),r0 mov 12(r0),r0 mov 12(r0),r0 movb 6(r5),5(r0) L3:jmp cretВ первой строке в
r0из первого параметра4(r5)(который берётся по адресуr5 + 4) загружается указатель на указатель на указатель (char ***a).Далее, во второй и третьей строках происходят подряд два разыменования указателей, когда из
12(r0)(по адресуr0 + 12) происходит чтение. 12 в 8-ричной системе есть 10 (индекс 5 умножить на размер указателя, равный 2).В четвёртой строке второй параметр
6(r5)(который берётся по адресуr5 + 6) в той же инструкции записывается в5(r0)(по адресуr0 + 5).Итого – два чтения из памяти и одна запись в память, если не считать обращений к frame'у стека..
Как видно, – ничего не изменилось: в моей версии функции
testпо-прежнему происходит одно обращение к памяти на запись, в вашей – сначала два обращения на чтение, затем одно на запись.
Ассемблерный код функции main Здесь вызов функции
testпроисходит в следующих строках:mov $144,(sp) mov r5,-(sp) add $-336,(sp) jsr pc,*$_test144 в 8-ричной системе есть 100 – это второй параметр.
Далее, в стек кладётся адрес frame'а, уменьшаемый затем на 222 – это адрес массива (222 = 216 (длина массива) + 6 (очевидно, место под переменные
i0,i1иi2)).После этого происходит вызов функции
test.Настало время посмотреть на результаты:

Результаты исполнения файлов 1 и 2 и дата файла cc Программа с моей версией функции
testкорректно завершилась, и видно, что функцияtestзаписала число 100 туда, куда надо.Программа же с вашей версией функции
testне только оказалась не способной записать 100 туда, куда надо, но и вызвала Memory fault.Видно, что исполняемый файл компилятора имеет дату 1979-го года.
Потом всё изменилось, конечно, Linux пришел на смену UNIX, а в разработку пришло много вчерашних студентов, изучавших программирование на курсах, так что ANSI всё же стал использоваться.
Я думаю, что теперь, после предоставленного мной материала, можно уже не пытаться утверждать, что раньше при передаче "многомерного" массива всё было не так, как сейчас.
Как видите, всегда было так, как сейчас.
Всегда.
И язык – он тот же.
Повторюсь, в одном из предыдущих сообщений вы написали мне:
Вы с удивительным упорством пытаетесь доказать ошибочное утверждение, прибегая при этом к уловкам, не надо так.
Создаётся ощущение, что сейчас вы "зеркалите" себя, то есть, "с удивительным упорством пытаетесь доказать ошибочное утверждение, прибегая при этом к уловкам".
Считаете ли вы в отношении себя, что "не надо так"?
Aldrog
00.00.0000 00:00+2Вот я открыл оригинальный K&R C (как я понимаю, та книга, на которой основывался ваш справочник), и там неожиданно многомерные массивы описываются примерно так же, хоть и менее формально, чем в ANSI/ISO C.
C provides for rectangular multi-dimensional arrays
In C, by definition a two-dimensional array is really a one-dimensional array, each of whose elements is an array.
Other than this, a two-dimensional array can be treated in much the same way as in other languages. Elements are stored by rows, that is, the rightmost subscript varies fastest as elements are accessed in storage order.Разве что в начале зачем-то отмечается
although in practice they tend to be much less used than arrays of pointers.
Hemml
00.00.0000 00:00-2Скорее всего этого не было в справочнике. А не было, вероятно, потому, что это либо не поддерживалось в компиляторах, либо поддерживалось, но не работало как должно было)
eptr
00.00.0000 00:00+1Это работало всегда таким же образом, как и сейчас.
Доказательство – в посте выше.
Hemml
00.00.0000 00:00-3У меня создается впечатление, что вы на меня за что-то сердитесь. Совершенно напрасно. Очень хорошо, что вы выучили систему типов в языке C и (тут повторюсь) это действительно вам пригодится в будущем. Давайте вернемся к началу нашей беседы. Я утверждал, что все попытки аспирантов переписать код с фортрана на C, которые я наблюдал, кончались неудачей -- они получали код, работающий существенно медленнее и, практически всегда, выдающий неправильные результаты. Особенности языка этому способствуют. При этом я даже не считаю, что это плохо, аспирант тратит кучу времени, но лучше узнает устройство кода, повторяет численные методы и, в итоге, начинает больше ценить фортран, одни плюсы. При этом у меня и в мыслях не было как-то унижать C, это хороший язык, пусть и предназначенный для других вещей. У меня коллега написал код не просто на С, а даже на C++ и это хороший код. Работает он, правда, все равно медленнее фортрановского, но их нельзя так прямо сравнивать, внутри они сильно отличаются. Так что и на C можно написать код, но возможностей выстрелить себе в ногу там неизмеримо больше, чем в фортране, да и сам он менее удобен для этой цели.
Вообще, я давно перерос все эти споры в стиле "X" круче "Y", перерастете и вы :)
eptr
00.00.0000 00:00+2У меня создается впечатление, что вы на меня за что-то сердитесь.
Дело не в этом.
Вы просто вы упорно не признаёте очевидное, продолжая искать оправдания.
Я утверждал, что все попытки аспирантов переписать код с фортрана на C, которые я наблюдал, кончались неудачей -- они получали код, работающий существенно медленнее и, практически всегда, выдающий неправильные результаты.
Это – ожидаемо, в это вполне верится.
Особенности языка этому способствуют.
Это – верно.
При этом я даже не считаю, что это плохо, аспирант тратит кучу времени, но лучше узнает устройство кода, повторяет численные методы и, в итоге, начинает больше ценить фортран, одни плюсы.
Самый большой плюс был бы, если бы он понимал, почему это так, и что, на самом деле, можно получать правильные результаты и иметь аналогичную эффективность и на C.
А также, если бы он также понимал, что для этого требуется, скольких усилий это будет стоить, надо ли это будет потом специально поддерживать, чтобы в будущем не потерять, и имеет ли после всего этого смысл переходить на C.
При этом у меня и в мыслях не было как-то унижать C, это хороший язык, пусть и предназначенный для других вещей.
Дело не в унижении C.
У меня коллега написал код не просто на С, а даже на C++ и это хороший код. Работает он, правда, все равно медленнее фортрановского, но их нельзя так прямо сравнивать, внутри они сильно отличаются.
С++ ощутимо жёстче в смысле требований к программисту по его квалификации, чем C, поэтому здесь ситуация может быть ещё хуже.
Так что и на C можно написать код, но возможностей выстрелить себе в ногу там неизмеримо больше, чем в фортране, да и сам он менее удобен для этой цели.
Верно.
Вообще, я давно перерос все эти споры в стиле "X" круче "Y", перерастете и вы :)
Нет такого спора.
На самом деле, по эффективности оба языка, примерно, равны.
Очевидно, что если за полвека в этом отношении ничего не изменилось, то логично ожидать, что и дальше так же будет.
У Fortran'а есть свои недостатки и свои преимущества, также, как они есть и у C.
В тех применениях, где недостатки Fortran'а имеют малое значение, а преимущества – большое, разумно использовать Fortran, то же самое верно и в отношении C.
В некоторых ситуациях недостатки становятся достоинствами.
Меньшая гибкость Fortran'а и его "заточенность" под определённые задачи в некоторых ситуациях являются достоинствами, а не недостатками, особенно, если необходимо решать как раз те задачи, под которые "заточен" Fortran, а квалификация как программиста человека, пишущего программу, невелика.
В таких ситуациях C – неправильный выбор.
Что же касается "спора".
Всё началось с того, что я возражал по следующему вопросу:
Самое вопиющее различие -- многомерные массивы. В фортране для доступа к произвольному элементу требуется одно обращение к памяти (чаще всего). В Си -- столько, сколько измерений у массива.
И, в основном, именно этот вопрос и обсуждался.
Приведено было довольно много доказательств, что это не – так, а потом, после того, как вы попытались апеллировать к тому, что когда-то давно было так, – доказательства, что всегда было не так, то есть, что так никогда не было, но вы так и не согласились с тем, что данное утверждение – неверное.
Поэтому я и перенаправил вашу же фразу вам.




SpiderEkb
00.00.0000 00:00+14COBOL уже стал притчей во языцех. Но при этом никто (ну или почти никто) не упоминает альтернативу ему - RPG который, строго говоря, является ровесником кобола. Даже тут про него писали.
Язык программирования, синтаксис которого был изначально сходен с командным языком механических табуляторов компании IBM. Был разработан для облегчения перехода инженеров, обслуживавших эти табуляторы, на новую технику и переноса данных, первоначально был реализован для IBM 1401. Широко использовался в 1960-х и 1970-х годов.
Равно как и COBOL, RPG предназначен для коммерческих расчетов. Т.е. там есть типы данных с фиксированной точкой, операции присвоения с округлением, поддерживается множество форматов дат и времени (и встроенная конвертация между форматами). Есть как встроенные функции работы с БД (позиционирование, чтение, запись, изменение, удаление
При этом это реально быстрый (в своей предметной области) язык. Как фортран для математиков. И что важно - это язык эволюционирует и развивается. Даже синтаксис изменился. Первые версии имитировали табуляторы, так называемый FIXED style

где каждый элемент должен был занимать свою позицию. И там не было поддержки процедур, были "сабрутины" (subruotines) которые располагались в общей области видимости (как в ранних версиях Basic - помните GOSUB? В RPG аналог - EXSR).
Современная версия RPG - это уже нормальный процедурный язык.



В последних версиях появляются новые фичи - динамические массивы, overload процедур, много удобных фич типа функции %split (разбивка строки на слова по заданному разделителю), %list (список элементов - полезен для инициализации массивов, для проверок типа if ... in %list(...)) конструкции типа for-each и т.п.
При этом по прежнему поддерживается старый синтаксис (т.е. старый fixed код по-прежнему собирается современным компилятором), по прежнему поддерживаются сабрутины (на самом деле это достаточно удобная вещь когда нужно несколько раз выполнить один и тот же набор операций с одними и теми же переменными или просто организовать логическое структурирование кода).
Да, это нишевый специфический язык ориентированный на решение определенного класса задач. Но в своей области он хорош. И кода на нем написано предостаточно. И на SO есть теги (rpg, rpgle) и в LinkedIn есть группы (вполне живые и активные - RPG Programmers, ILE - RPG Developers).
Поддерживается главным образом на платформах от IBM (хотя были реализации и для других платформ, например, VisualRPG - RPG компилятор для .NET).
Понятно, что по популярности нишевые языки не сравнятся с языками общего назначения. Но не стоит их списывать со счетов.

PuerteMuerte
00.00.0000 00:00Но в своей области он хорош
Я на нём писал ещё в нулевые. Я не могу понять этого вашего выражения, если честно. В своей области — это какой? Если в общем, как язык для работы с бизнесовыми данными и формирования какой-то отчётности, то это старый и неудобный, кхм, артефакт, даже в то время. Да, если под «областью» подразумевать разработку экранов для терминала 5250, то да, в этой области он вполне себе неплох. Но тут и вся эта «область» вместе с ним — старый и неудобный артефакт.SpiderEkb
00.00.0000 00:00Я на нём писал ещё в нулевые
С нулевых он очень сильно изменился. Даже за последние 5 лет (я начинал на версии 7.2, сейчас 7.5 актуальная) появилось очень много чего.
Никто уже не пишет на fixed, никто не использует cycle mode. Только full-free и только linear. Нормальный процедурный язык.
Как, например, на С++ или джаве реализовать вот такую структуру:dcl-ds dsMyDS qualified; str1 char(20); str2 char(20); str3 char(20) pos(10); end-ds;а необходимость в подобном при работе с бизнесовыми данными сплошь и рядом.
Или вот подобное:
dcl-s strDateISO char(10); dcl-s zDateCYMD zoned(7: 0); zDateCYMD = 1230210; // Дата 10-е февраля 2023 года test(de) zDateCYMD *cymd; // Проверка корректности даты if not %error; strDateISO = %char(%date(zDateCYMD: *cymd): *iso); // Та же дата, но в виде строки '2023-02-10' endif;На других языках вам придется сначала библиотеки писать для работы с датами и временем.
В последних версиях появились overload процедуры
// Получение сообщения из queLIFO/queFIFO очереди // Возвращает количество полученных байт (размер полученного сообщения) // 0 если в очереди нет сообщений // в случае ошибки -1 dcl-pr USRQ_RecvMsg int(10) overload(USRQ_Recieve: USRQ_RecieveKey); dcl-pr USRQ_Recieve int(10) extproc(*CWIDEN : 'USRQ_Recieve') ; hQueue int(10) value; // handle объекта (возвращается USRQ_Connect) pBuffer char(64000) options(*varsize); // Буфер для приема nBuffLen int(10) value; // Размер приемного буфера dsSndrJob likeds(t_dsJobID) options(*omit); // Идентификатор задания-отправителя tsMsg timestamp options(*omit); // Таймштамп отправки сообщения Error char(37) options(*omit); // Ошибка end-pr; // Получение сообщения из queKeyd очереди // Возвращает количество полученных байт (размер полученного сообщения) // 0 если в очереди нет сообщений // в случае ошибки -1 dcl-pr USRQ_RecieveKey int(10) extproc(*CWIDEN : 'USRQ_RecieveKey') ; hQueue int(10) value; // handle объекта (возвращается USRQ_Connect) pBuffer char(64000) options(*varsize); // Буфер для приема nBuffLen int(10) value; // Размер приемного буфера pKey char(256) const; // Значение ключа сообщения nKeyLen int(10) value; // Фактический размер ключа nKeqSeq int(10) value; // Правило использования ключа // queKeySeqGT - ключ сообщения должен быть больше заданного // queKeySeqLT - ключ сообщения должен быть меньше заданного // queKeySeqNE - ключ сообщения должен быть не равен заданному // queKeySeqEQ - ключ сообщения должен быть равен заданному // queKeySeqGE - ключ сообщения должен быть больше или равен заданному // queKeySeqLE - ключ сообщения должен быть меньше или равне заданному dsSndrJob likeds(t_dsJobID) options(*omit); // Идентификатор задания-отправителя tsMsg timestamp options(*omit); // Таймштамп отправки сообщения Error char(37) options(*omit); // Ошибка end-pr;Используем универсальную USRQ_RecvMsg, в зависимости от набора параметров подставляется нужный вариант - USRQ_Recieve или USRQ_RecieveKey. Кстати, сами функции написаны на С++ и содержатся в SRVPGM с моделью памяти TRASPACE с 64-bit указателями, но вызываются из RPG программ с SINGLE LEVEL моделью и 128-bit указателями. Тут нет проблем с тем, чтобы то, что удобнее на С/С++ писать, писать на С/С++. Более того, нет проблем использовать С-шные функции - только правильно описать прототип на RPG, компилятор сам подтянет. Например: Working with the IFS in RPG
Появились динамические массивы (dim(*auto)), разные полезные конструкции типа:
for-each word in %split(str: ' '); ... endfor;Разбивка строки str на слова и обработкой каждого слова (word) в цикле.
Есть возможность вставлять SQL код в программу:
dow not done; // Читаем блоками по items2Read строк в массив sqlData EXEC SQL FETCH currACY FOR :items2Read ROWS INTO :sqlData; // Сколько реально прочитали itemsRead = SQLERRD(3); if itemsRead > 0; // если что-то прочитано exsr ProcDataBlock; else; // Если по текущему запросу больше нет данных done = *on; endif; enddo;Так что в плане бизнес-логики на RPG писать проще. Уж на что я на С/С++ писал более 20-ти лет и поначалу достаточно скептически относился к RPG, но в процессе работы убедился что в современном варианте это вполне годный язык для логики верхнего уровня, а низкоуровневые вещи не проблема на С/С++ реализовать.
PuerteMuerte
00.00.0000 00:00Уж на что я на С/С++ писал более 20-ти лет и поначалу достаточно скептически относился к RPG
Ну вот в этом и корни вашего заблуждения. С/С++, это языки немного из другой сферы. Конкуренты RPG — это всякие там джавы/сишарпы.
Я могу сделать, например в сишарпе, вот так:public class dsMyDS { [Display(Name = "First Param")] [Required] [StringLength(20)] public string str1 { get; set;} [Display(Name = "Second Param")] [StringLength(20)] public string str2 { get; set;} [Range(0, 150)] public decimal dec3 { get; set;} }Или вот подобное:
Подобное я просто не буду писать, конкретно подобное преобразование не существует за пределами AS/400. Потому что на других языках у меня не может быть даты в формате целого числа 1230210. С пользовательского интерфейса я получу дату как строку в локали текущего пользователя, и преобразую её в формат даты-времени. Точнее, я сам даже не буду ничего преобразовывать, фреймворк за меня это сделает автоматически, я в своём коде на входе получу уже обработанную и валидированную модель.
И с СУБД я получу дату тоже собственно как дату. А вычисления с датами проводятся в формате даты-времени.На других языках вам придется сначала библиотеки писать для работы с датами и временем
Сейчас «из коробки» там куча готовой функциональности. Перегрузка, это вообще 1980-е годы, динамические массивы — 1990-е.Разбивка строки str на слова и обработкой каждого слова (word) в цикле.
String.split()
Кстати, а чтобы обратно собрать одной операцией в строку после обработки — это в RPG тоже завезли? ;)Есть возможность вставлять SQL код в программу:
Это и в мои годы в RPG было. В коде Java или C# прямо SQL вставить нельзя, но зато есть функциональные аналоги этого, Hibernate + Stream или EF + Linq соответственно. Ну как аналоги? Более мощные аналоги. Вы можете манипулировать не только данными из внешнего источника, но и данными внутри вашего приложения. Вы можете синхронизировать схему данных внешнего источника со схемой данных вашего приложения, и так далее. Поэтому нет, я повторюсь, новый RPG гораздо лучше старого RPG, но он существенно отстал от мира за пределами своей экосистемы.SpiderEkb
00.00.0000 00:00Ну вот в этом и корни вашего заблуждения. С/С++, это языки немного из другой сферы.
А я не говорю что они из одной сферы. Наоборот, я постоянно говорю что когда мне надо, например, поработать с *usrq через системные указатели и mi, я сделаю это на С, когда мне надо расписать бизнеслогику - я сделаю это на RPG. И все это вместе прекрасно сосуществует.
Я могу сделать, например в сишарпе, вот так
И во что это превратится в итоге? Куча кода которое будет при каждо обращении процессор грузить? Или это просто способ описания как переменные в памяти лежат (как в RPG)?
Подобное я просто не буду писать, конкретно подобное преобразование не существует за пределами AS/400. Потому что на других языках у меня не может быть даты в формате целого числа 1230210.
Кто вам такое сказал? Дата может существовать в любом формате. Точнее, в том, в котором ее удобнее хранить и сравнивать (например). А ее визуальное представление - дело десятое.
Целое число 20230210 - это тоже дата.
Кстати, а чтобы обратно собрать одной операцией в строку после обработки — это в RPG тоже завезли? ;)
Да. В 7.4 TR7 / 7.5 TR1
Result = %concat(<separator character(s)> : <string or variable> : <string or variable> : <string or variable> ... ) ; String = %concat(';' : 'ANT' : 'BEAR' : 'CAT' : 'DOG' : 'EEL') ; // ANT;BEAR;CAT;DOG;EEL String = %concat(', ' : 'ANT' : 'BEAR' : 'CAT' : 'DOG' : 'EEL') ; // ANT, BEAR, CAT, DOG, EEL String = %concat(*none : 'ANT' : 'BEAR' : 'CAT' : 'DOG' : 'EEL') ; // ANTBEARCATDOGEELВ том числе и для массивов
dcl-s VarArray varchar(10) dim(*auto:100) ; VarArray = %list('Amy' : 'Beth' : 'Carol' : 'Dawn' : 'Enid') ; String = %concatarr(', ' : VarArray) ; // Amy, Beth, Carol, Dawn, Enidновый RPG гораздо лучше старого RPG, но он существенно отстал от мира за пределами своей экосистемы.
Ну так он существует в пределах своей экосистемы. Как быстрый и эффективный инструмент для написания бизнес-логики. Да, это специфическая экосистема, но в плане эффективности, устойчивости и надежности она хороша, если уметь ей пользоваться.
Просто далеко не везде она нужна (во многих вещах ее возможности избыточны и не окупят вложений)
PuerteMuerte
00.00.0000 00:00Наоборот, я постоянно говорю что когда мне надо, например, поработать с *usrq через системные указатели и mi
Так о том и речь — вы при разработке бизнес-приложения для обработки ввода лезете в очередь через указатели. Это само по себе странно звучит в современном мире. Вы ведь должны получать на входе готовые, проверенные и структурированные бизнес-данные, а не сырой ввод. И вообще не думать о том, как переменные в памяти лежат, потому что как они там лежат — штука аппаратно-зависимая, а ваш код — нет. Да, вы грубо говоря можете описать в RPG структуру и положить её как есть в табличку DB2… но какую задачу это решает в бизнес-приложении? Да никакую.И во что это превратится в итоге? Куча кода которое будет при каждо обращении процессор грузить?
Это превратится в структуру данных, которую сможет автоматически преобразовать в форму UI, которую на входе сможет отвалидировать сервер приложений, которую можно сериализовать/десериализовать при необходимости передачи между различными приложениями на разных машинах, и которую EF сможет положить в СУБД, также выполнив валидацию, и при необходимости — синхронизировав её по структуре с таблицей.Кто вам такое сказал? Дата может существовать в любом формате.
Эм… я сам такое сказал, это так и есть. Если мы говорим про теоретическую возможность, то да, вы сами себе можете придумать любой формат хранения даты. Если мы говорим про практическую разработку, то нет, формат хранения даты у вас стандартизован, в джаве это целое число, кол-во миллисекунд с 1.1.1970, в дотнете это целое число, кол-во 100нс тиков с 1.1.0001, и ничего другого в вашей программе быть не может. Ну, по крайней мере, не должно, если вы сами себе не хотите придумать проблему на пустом месте. Потому что именно в этом формате она удобно хранится, в этом формате работают вычисления с датами, и в этом формате с ней работает бесчисленное количество системных библиотек/конверторов.
Если у вас на вход попадают даты в виде 20230210, то это никоим образом не целое число, это строка, и превратится она внутри в количество тиков до 10.02.2023 стандартными средствами языка.Да. В 7.4 TR7 / 7.5 TR1
Понял, спасибо. Уже не застал :)Да, это специфическая экосистема, но в плане эффективности, устойчивости и надежности она хороша, если уметь ей пользоваться.
Она плоха как минимум, в плане продуктивности разработчика. Да и в плане продуктивности самого софта есть сложности. Если у вас не хватает ресурсов вашего iSeries, и там уже не осталось ядер, которые этак за $200K вам активирует инженер IBM, вам нужно будет покупать новый. Если вам не хватает ресурсов какого-нибудь сервиса на сишарпе, вы доставите ещё пару копеечных узлов (в сравнении с iSeries), и горизонтально его отмасштабируете.SpiderEkb
00.00.0000 00:00Так о том и речь — вы при разработке бизнес-приложения для обработки ввода лезете в очередь через указатели. Это само по себе странно звучит в современном мире. Вы ведь должны получать на входе готовые, проверенные и структурированные бизнес-данные, а не сырой ввод.
А откуда я должен получить "готовые бизнес-данные"?
Вот вам задача (одна из многих) - ежегодная актуализация клиентов. Суть в том, что нужно выбрать по определенным критериям клиентов из таблицы и для каждого из них провести определенные проверки и процедуры.
На прошлый год речь шла о выборках порядка 22млн. Дабы выполнить задачу в разумный срок (а есть некоторое временное окно в течении которого она должна быть завершена), делается это путем распараллеливания обработки. Условно говоря, есть головное задание, есть обработчик, есть конвейер - очередь, куда головное задание выкладывает пакеты на обработку и откуда они разбираются обработчиками. Т.е. головное задание запускает нужное количество обработчиков (5-10 штук) и затем отбирает данные, выкладывает их на конвейер, разработчики их оттуда берут и обрабатывают.
Так вот в качеств конвейера удобно использовать *USRQ. Но чтобы ее использовать, нужен удобный API к ней. На уровне "подключиться к очереди", "послать сообщение", получить сообщение"... Вот эти API я пишу на С/С++ - есть SRVPGM где все это лежит. Дополнтельно есть средства администрирования - CL команды (CRTUSRQ, DLTUSRQ, DSPUSRQ, CLRUSRQ). Есть SQL функции (например, посмотреть что лежит в очереди не извлекая оттуда сообщения - peek, или view позволяющая смотреть все ини некотрые очереди - их свойства). Наример
select * from USRQ_INFO where USER_QUEUE_NAME = 'TSTQUE'или
select * from table(USER_QUEUE_ENTRIES('TSTQUE', '', 'ALL')) as tТак что для решения некоторых бизнес-задач еще и инструменты нужны дополнительные.
С распараллеливанием, кстати, очень много разных задач связано. Есть загрузка проводок из внешних систем (когда там приделают пакеты из 5-10млн проводок и их надо быстро ввести в систему), сверка клиентов после загрузки очередного списка росфина (поиск совпадений со всякими злодеями-бармалеями - там каждого клиента нужно проверить на совпадение по ряду параметров типа наименования, ИНН, для ФЛ это еще ДУЛ, ДР - нет ли его в росфиновском списке).
PuerteMuerte
00.00.0000 00:00На уровне «подключиться к очереди», «послать сообщение», получить сообщение"… Вот эти API я пишу на С/С++ — есть SRVPGM где все это лежит.
А у меня подобное выглядит вот так: один воркер выбирает кусок данных из базы, получая сразу массив «клиентов» (у меня это на самом деле не клиенты, а документы, но не суть важно) и кладёт их в очередь SQS, просто одной высокоуровневой командой, целиком как есть. С другой стороны освободившийся обработчик опрашивает очередь, когда увидел новый пакет, забирает и обрабатывает. При этом воркеров и обработчиков много, и они в общем-то вертятся на нескольких серверах там в облаке, которые я могу при необходимости просто добавлять.
Я прекрасно понимаю, о чём вы говорите, я в банке семь с половиной лет проработал (там же и на AS/400), но… за пределами банковской сферы HighLoad встречается часто, но решается иначе, и в общем-то проще и дешевле.SpiderEkb
00.00.0000 00:00А у меня подобное выглядит вот так: один воркер выбирает кусок данных из базы, получая сразу массив «клиентов» (у меня это на самом деле не клиенты, а документы, но не суть важно)
Ну аналогично. Просто у нас обычно еще какой-то отбор есть. Та же актуализация - 5 SQL запросов "на разные темы" и отбор примерно половины от всех существующих клиентов.
кладёт их в очередь SQS, просто одной высокоуровневой командой, целиком как есть
Можно использовать *DTAQ - там "одна высокоуровневая команда". Но *USRQ по сравнению с *DTAQ - это в 3-4 раза выигрыш как по скорости, так и по потреблению ресурсов.
А по факту - разработанное API как раз и сводит все к трем командам - подключиться и положить/взять.
А так сейчас идет разработка готового фреймворка где от конечного разработчика потребуется только две callback функции - одна для отбора данных и формированию пакетов, вторая - для обработки пакета. Все остальное (послать, получить, отслеживание за состоянием обработчиков и прочее) - все это будет зашито внутрь фреймворка и вмешательства разработчика не потребует.
они в общем-то вертятся на нескольких серверах там в облаке
Ну облачные решения это не для банка...
я в банке семь с половиной лет проработал (там же и на AS/400)
"В каком полку служили?" (с)
Я в EQ.Core формально, фактически - комплаенс (усиленно пихают в архитектора, но не сказать чтобы очень хочется).
за пределами банковской сферы HighLoad встречается часто, но решается иначе, и в общем-то проще и дешевле
Везде своя специфика. Я до банка занимался разработкой системы мониторинга инженерного оборудования зданий. Там местами и реалтайм был и все такое. Тоже своя специфика и свои решения.
zuek
00.00.0000 00:00формат хранения даты у вас стандартизован, в джаве это целое число, кол-во миллисекунд с 1.1.1970, в дотнете это целое число, кол-во 100нс тиков с 1.1.0001
Задумчиво: - "...а не жирно для даты полный таймстамп выделять?"
Видимо, как раз по причине выделения "длинного целого" для столь компактной сущности, как "дата", у меня в телефоне калькулятор занимает десятки мегабайт, в то время, как в "семёрке" его аналог "весил" менее мегабайта.
Сколько помню, даже в SQL'ах типы "дата" и "дата+время" - разные типы, разной длины.
PuerteMuerte
00.00.0000 00:00+1Видимо, как раз по причине выделения «длинного целого» для столь компактной сущности, как «дата», у меня в телефоне калькулятор занимает десятки мегабайт
Нет, вообще не жирно. Ваш калькулятор занимает десятки мегабайт, потому что у него там менеджер скинов встроен, поддержка разных dpi, а работает всё это через библиотечку, которая интерфейс калькулятора изXAML, пардон, это ж телефон, из Layout'а тянет, а под ней ещё DOM XML-парсер лежит и так далее.
В случае же даты куда дешевле иметь один тип данных на всё про всё, чем иметь отдельно тип «дата» и библиотеки для операций с ним, тип «дата-время» и библиотеки для операций с ним, тип «время» (ну вы поняли), и ещё набор конвертеров между этими тремя.zuek
00.00.0000 00:00Вполне допускаю, что проигрыш в объёме будет не катастрофическим (ну, вместо трёх-четырёх байт некогда стандартного "упакованного десятичного представления", когда 21.02.2023 представлялось в виде 0x20230221 или, до эпохи "бага 2000", вообще 0x230221, будет 8 байт), но всё же любая избыточность мне представляется вредной. Особенно, если учитывать "високосные секунды" при пересчёте таймстампов в дату - это же целый огород городить надо, чтобы последняя секунда 30 июня или 31 декабря не сконвертировалась случайно в 1 июля и 1 января, соответственно. В данном случае универсальность хранения тащит за собой очень серьёзное усложнение библиотек представления, более того, необходимо поддержание этих библиотек в актуальном состоянии (чтобы корректно учитывать все "високосные секунды").
PuerteMuerte
00.00.0000 00:00В данном случае универсальность хранения тащит за собой очень серьёзное усложнение библиотек представления
Универсальность хранения наоборот, в данном случае упрощает библиотеки представления. Ведь у нас не стоит выбор между «поддержка типа Дата» и поддержка типа «ДатаВремя». У нас стоит выбор между «поддержка только типа ДатаВремя» и «поддержка обоих типов, и Дата, и ДатаВремя». Ну потому что тип «Дата» — это лишь частное подмножество требуемых операций со временем, и он покрывает лишь некоторые потребности софта, и без типа «ДатаВремя» мы не обойдёмся.Особенно, если учитывать «високосные секунды» при пересчёте таймстампов в дату
Эта задача очень просто решена в стандартных библиотеках популярных платформ, будь-то дотнет, джава и иже с ними. Они не учитывают високосные секунды :)
SpiderEkb
00.00.0000 00:00формат хранения даты у вас стандартизован, в джаве это целое число, кол-во миллисекунд с 1.1.1970, в дотнете это целое число, кол-во 100нс тиков с 1.1.0001, и ничего другого в вашей программе быть не может
Да ладно?
А как же IBM Standart Time (он же MI_Time)? Который описан в хидерах как char[8], но по факту есть uint64. Младшие 12 бит - биты уникальности (когда вам нужно получать уникальное значение - вызываете MATMDATA с флагом _MDATA_CLOCK и получаете уникальное uint64 даже в рамках одной микросекунды, если не нужны - флаг _MDATA_CLOCK_NOT_UNIQUE). А старшие 52 бита - количество микросекунд (именно микро) с 08/23/1928 12:03:06.314752.
Странное на первый взгляд начало эпохи связано с тем, что они привязываются не к началу, а к середине эпохи. А за середину у них взято 01/01/2000 00:00:00.000000
Расковыряв (документация достаточно туманна - вроде бы все есть, но пришлось по разным местам собирать) этот формат сделал функции замера интервалов с точностью до мкс, а также функции конвертации MI_Time в стандартный UnixTime (+микросекунды) и быструю конвертацию в RPG timestamp (который на самом деле есть просто строка в заданном формате и посему все операции с ним достаточно медленные и ресурсозатратные)
PuerteMuerte
00.00.0000 00:00А как же IBM Standart Time (он же MI_Time)?
Вы же его не встретите в окружающем мире. Это просто одна из частных реализаций таймстампа.SpiderEkb
00.00.0000 00:00Именно так. Более того, я с разными платформами сталкивался - внутреннее представление времени никак не стандартизируется. А уж как оно будет представлено внутри используемого вами языка определяется разработчиками этого языка. Ну или каким-то общепринятыми стандартами типа UnixTime.

saipr
00.00.0000 00:00+3То есть, если язык C заменит Algol, это нормально.
Надо сказать, что язык C не только заменит Algol, он заменит и непоколебимый в 80-годах в Советском Союзе язык ПЛ/1 (PL/1):
Персональные компьютеры поставлялись с транслятором программ с языка Си. Это привело к тому, что практически сразу все забыли про язык программирования ПЛ/1.

jobless
00.00.0000 00:00+2И тем не менее жизнь продолжается
1 Feb, 2023 (nominal date) due to a bug in handling self-defining structures, version 1.0.1 replaces 1.0.0. The new version contains a fix for this and one other minor issue. The documentation has not been updated from 1.0.0, only the executables have been changed.
1 Feb, 2023: Iron Spring PL/I compiler 1.0.0 released The major new feature in this release is support for self-defining structures (REFER attribute).
jobless
00.00.0000 00:00+1Сразу не обратил внимания на то, что kt тоже крайнее обновление от 1 - го февраля :)

piuzziconezz
00.00.0000 00:00+4Быть может, что через 100 лет языков программирования как таковых и не останется, будет подробное ТЗ в свободной форме на человеческом языке, а ChatGPT42 будет создавать по нему сразу машинный код. Ну или какой-нибудь стандартный байт-код. Процесс программирования будет напоминать устный диалог человека с машиной.
IvaYan
00.00.0000 00:00+2То есть от языка программирования все равно отказаться не получится. Поверх машинного кода запилят текстовые мнемоники, назвут языком ассемблера и пойдут на второй круг.
piuzziconezz
00.00.0000 00:00ну ассемблер может и останется, только люди программировать на нем не будут (хотя и сейчас очень редко кому это надо)

LordDarklight
00.00.0000 00:00В ближайшие 100 лет всё как раз можно с ног на голову перевернуться языках программирования. Уже сейчас ChatGPT умеет эффективно конвертировать код между разными ЯП. Это в итоге приведёт к тому, что количество используемых ЯП будет сокращаться. При этом будут приходить новые ЯП, и старая кодовая база будет транслироваться на новые ЯП. А те же умные ИИ алгоритмы начнут не просо транслировать - а ещё и очень эффективно оптимизировать и выявлять баги. И в итоге ЯП начнут смещаться сторону более декларативных - только формализовано описывающих что нужно делать, а уже ИИ будут выполнять когенерацию сначала на каком-то промежуточном ЯП (автоматически подбираемом под задачу, или универсальном, но не удобным для человека - тот же WebAssrmbly, например), а затем и сразу в инструкции для процессора. А далее уже и сам формализованный депкларативный ЯП станет менее формализованным - и уже вполне эффективно можно будет просить ИИ сделать то то и то то - и не будет уже как такового программирования вовсе. Но это всё будет ещё развиваться столетия, хотя же сейчас ChatGPT вполне может выдавать вполне осмысленные результаты не прибегая к очень высокой формализации постановки задачи - что говорит о том, что это возможно и возможно всё это довести до ума в разумные (столетия) сроки.
Да, сейчас ChatGPT программируют классическим путём - но сколько уйдёт лет его развития, когда его начнут программировать через него же, а затем он начнёт это делать сам - сначала слушая указания людей, а потом принимая решения самостоятельно?
Но у классических ЯП ещё много времени - и у того же Фортрана, как у одного из наиболее доревних вполне себе живых ЯП, на данный момент, ещё шансов стать первым столетним живым языком программирования ОЧЕНЬ много! Но всё-таки ,формально, таковым будет языка ассемблера (классического, хотя это не совсем верно так говорить т.к. у него много диалектов и они активно развиваются - но в рамках постановки данной статьи - это не мешает их всех считать тем самым классическим ассемблером, зародившимся в 1949 году - то есть, за 8 лет до Фортрана); WebAssembler НЕ СТОИТ ОТНОСИТЬ к тому классическому ассемблеру, при определённой схожести - это совсем не его отдельный диалект - тут идеология использования заметно различная!
А так, я думаю, у всех живых ЯП из статьи есть почти 100% шанс стать столетними языками! Даже у COBOL - хотя я не понимаю, что с ним так долго возятся - да, проблема большая, во второй половине прошлого века на нём умудрились написать слишком много серьёзного программного кода (который был очень хорошо отлажен и требует высокой надёжности) и ему долго не было достойной альтернативы по ряду показателей. Но сейчас я бы просто создал бы новый коболоподобный (но современный) ЯП - и попросту конвертировал в него старый программный код через системы ИИ. А затем уже конвертировал с этого ЯП далее - на любой подходящий ЯП и фреймворк. Просто этот промежуточный ЯП нужно таким создавать - чтобы он подходил и уходил сразу всем
SpiderEkb
00.00.0000 00:00+3Уже сейчас ChatGPT умеет эффективно конвертировать код между разными ЯП. Это в итоге приведёт к тому, что количество используемых ЯП будет сокращаться
Интересно, как он будет конвертировать типы данных, которые есть в одном языке и нет в других?
Например, те же форматы данных с фиксированной точкой, которые на уровне языка поддерживаются в языках для коммерческой разработки, но практически отсутствуют (ну или присутствуют в виде реализации дополнительными библиотеками) в языках общего назначения.
Или различные специфические особенности - например, в том же RPG очень большая свобода при работе со структурами данных - создать структуру, в которой два поля частично перекрываются третьим (например, есть две строки по 20 символов и третье поле, тоже 20 символов, но первые 10 есть символы с 11-го по 20-й первой строки, вторые 10 - с 1-го по 10-й второй). Как такие вещи сконвертировать в С или джаву?
А если еще языки разные парадигмы используют? Один - функциональную, второй объектную?
Я уж не говорю о том, чтобы сконвертировать код, написанный на каком-нибудь Prolog в джаву...
И, на минуточку, еще не потерять в эффективности. По скорости, ресурсам...
Но сейчас я бы просто создал бы новый коболоподобный (но современный) ЯП - и попросту конвертировал в него старый программный код через системы ИИ. А затем уже конвертировал с этого ЯП далее - на любой подходящий ЯП и фреймворк
План, конечно, замечательный. За одним "но". Любое изменение кода в подобных системах требует полного ретеста.
Для примера - как это делается у нас.
Компонентное тестирование (соответствие кода ТЗ)
Бизнес-тестирование (соответствие кода + ТЗ бизнес-требованиям)
Интеграционное тестирование (отсутствие отрицательного влияния доработки на то, что уже внедрено и работает)
Нагрузочное тестирование (эффективность потребления ресурсов)
Тут ведь речь идет не об одной большой программе, а об огромном количестве различных модулей, каждый из которых выполняет какое-то определенное действие, решает какую-то бизнес-задачу. В тех же банках параллельно работают десятки тысяч различных процессов и обычное с точки зрения клиента действие вызывает длинную цепочку различных операций.
И тут переход с одной системы на другую удовольствие очень дороге и очень небыстрое. Хрестоматийный пример - Банк Содружества Австралии и Океании. Они так переходили с "легаси" на "современные технологический стек". Потратили на это 5 лет (2012-2017) и $750млн. Других энтузиастов не нашлось. Не говоря уже о том, что "современный технологический стек" к окончанию перехода уже становится если не легаси, то близком к нему.
Ну и есть еще один момент. Вот эти "старые языки" как правило работают на очень специфических платформах и глубоко в них интегрированы. И в значительной степени за счет этого эффективны. И там возникнет куча проблем (прежде всего с эффективностью) при переходе на "современный язык", который не настолько интегрирован в платформу. Т.е. потратите кучу времени и денег, а потом выяснится, что оно требует больше ресурсов и работает медленнее. И с вас сразу спросят - ради чего вот это все было?
Короче говоря, снаружи все это кажется намного проще, чем когда в этом всем поваришься и хоть немного начнешь понимать масштабы того, что там крутится.
LordDarklight
00.00.0000 00:00Интересно, как он будет конвертировать типы данных, которые есть в одном языке и нет в других?
Например, те же форматы данных с фиксированной точкой, которые на уровне языка поддерживаются в языках для коммерческой разработки, но практически отсутствуют (ну или присутствуют в виде реализации дополнительными библиотеками) в языках общего назначения.
Думаю Вы сами ответили на свой вопрос. Если чего-то нет в базе - на то есть библиотеки. Если они это не могут сделать на данном ЯП - он умрёт.
Другое дело, что такая конверсия может где-то немного в производительности или в ресурсах проиграть - но это не так уж страшно - ресурсов много, а производительность с оптимизируется в других местах. Куда важнее надёжность, переносимость и простота сопровождения. Ну и я всё-таки написал о конверсии не откуда угодно куда угодно - а о конверсии старого в новое - но этого нового может быть целый набор, из которого ЯП выбирается под конкретную задачу.
План, конечно, замечательный. За одним "но". Любое изменение кода в подобных системах требует полного ретеста.
Этим могут заняться ИИ системы - прогнав миллионы тестов на консолидированной гигантской кодовой базе - пока будет отлаживаться конвертере. Ну а потом, уже генерировать автотесты под каждую практическую конверсию по-отдельности. И я не зря сказал - что будет использоваться коболоподобный ЯП - тут логика кобола хорошо должна ложиться на новый ЯП - в основном меняется лишь обёртка - так что багов конверсии, что пропустят продвинутые ИИ анализаторы, должно быть не много!
SpiderEkb
00.00.0000 00:00+2Другое дело, что такая конверсия может где-то немного в производительности или в ресурсах проиграть - но это не так уж страшно - ресурсов много, а производительность с оптимизируется в других местах.
Т.е. кроме затрат на конвертацию, еще тратится на новые сервера? Кто вам столько денег даст? Бизнес - он деньги считать любит. И для него не аргумент что вы не знаете того языка, на котором у них там все написано и стабильно работает. Для них аргумент - конкретные цифры затрат и срок их окупаемости.
Этим могут заняться ИИ системы - прогнав миллионы тестов на консолидированной гигантской кодовой базе - пока будет отлаживаться конвертере. Ну а потом, уже генерировать автотесты под каждую практическую конверсию по-отдельности.
Увы, когда речь идет о миллионах (если не миллиардах) клиентских денег, деловой репутации банка и потенциальных претензиях со стороны регулятора, одному ИИ никто не доверится. От вас потребуют 146% гарантии того, что новая версия будет работать не хуже старой и на 146% будет давать тот же результат что и старая в любых условиях. Увы, но так это работает в реальной жизни. И именно поэтому никто не занимается переписыванием старого на новое просто так.
И я не зря сказал - что будет использоваться коболоподобный ЯП - тут логика кобола хорошо должна ложиться на новый ЯП - в основном меняется лишь обёртка
А. То есть сначала пишем новый ЯП. Такой же, но новый. Потом доказываем что он лучше старого. Потом конвертируем. Потом тесты... Это на несколько десятков лет развлекуха. А там придет "свежая кровь" и "на колу мочало, начинай сначала"?
Ndochp
00.00.0000 00:00. И для него не аргумент что вы не знаете того языка, на котором у них там все написано и стабильно работает.
Кажется Яху с лиспа переписывали именно связи с этим. "у нас кончились люди, которые могут писать на лиспе, а если не писать, то система помрет, так как не будет отвечать изменяющимся требованиям."
0xd34df00d
00.00.0000 00:00+1Да не, переходят, переходят. Я не так давно общался с людьми, переписывающими с мейнфреймов (и этих всех коболов-rpg) на современный хаскель. Вполне успешно делают это небольшой командой в крупном ретейлере, где операций и истории может быть побольше, чем в среднем банке.

WASD1
00.00.0000 00:00+1В ближайшие 100 лет всё как раз можно с ног на голову перевернуться языках программирования. Уже сейчас ChatGPT умеет эффективно конвертировать код между разными ЯП. Это в итоге приведёт к тому, что количество используемых ЯП будет сокращаться. При этом будут приходить новые ЯП, и старая кодовая база будет транслироваться на новые ЯП. А те же умные ИИ алгоритмы начнут не просо транслировать - а ещё и очень эффективно оптимизировать и выявлять баги.
Вы собственно описали два мешающих друг-другу процесса:
- трансляцию на другой язык
- оптимизацию после трансляции
Суть в том, что для хорошей оптимизации надо оставить как можно больше исходной семантики и внести как можно меньше паразитной (той, которая не нужна в исходной задаче, но появилась в технической реализации из-за особенностей инструментария, например ЯП, или SQL или ещё чего).То есть с тем, что подход к написанию ПО будет меняться - я не спорю, но вот переписывание старого ПО будет происходить как-то кардинально по-другому.
SpiderEkb
00.00.0000 00:00+1Вы собственно описали два мешающих друг-другу процесса:
- трансляцию на другой язык
- оптимизацию после трансляции
И полное тестирование все переписанного, которое займет кратно больше времени и ресурсов чем трансляция и оптимизация.
А еще забыли что все это переписывание невозможно без тотального понимания что и как оно делает. И хорошо, если есть актуальные версии документации по всему этому. А если нет?
То есть с тем, что подход к написанию ПО будет меняться - я не спорю, но вот переписывание старого ПО будет происходить как-то кардинально по-другому.
А не будет такого вот "тотального переписывания". Все новое будет писаться на новом, а старое... Что работает будет работать. Что не работает (или требует оптимизации) - будет заменяться новым и выводиться из эксплуатации.
Благо, там системы обычно построены на модели, близкой к модели акторов - много относительно небольших модулей, вызываемых друг из друга, каждый из которых выполняет конкретную задачу.
Но из любви к искусству, просто так, никто ничего переписывать не станет, поверьте. Это слишком дорого.
SpiderEkb
00.00.0000 00:00+1А кто и на чем будет писать ChatGPT?
И по ТЗ "в свободной форме на человеческом языке" не так просто создать эффективно работающий код даже для опытного разработчика.
Да NoCode будет развиваться и для достаточно большого класса рутинных задач вытеснит разработчиков. Но не думаю, что вытеснит совсем - чтобы робот что-то за тебя делал нужно сначала создать робота :-)
piuzziconezz
00.00.0000 00:00+3А кто и на чем будет писать ChatGPT?
Предыдущая версия ChatGPT, очевидно же) Ну и люди немного помогут.
...не так просто создать ...
Это пока что
Но не думаю, что вытеснит совсем
Я тоже не думаю, насовсем мало что исчезает.

Valehavl
00.00.0000 00:00Будут маленькое количество крутых программистов, пишущих оптимальные библиотеки, которым нужно будет хорошее знание тонкостей реализации кода на довольно низком уровне. А остальные будут пользоваться их наработками как вы указали.

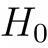


iliasam
00.00.0000 00:00+14По названию решил, что речь пойдет про какие-нибудь табуляторы, автоматоны, ткацкие станки с перфокартами и подобные вещи, которым реально сто лет.

Hidanio
00.00.0000 00:00+6Показалось достаточно странным что автор упомянул Java, но не упомянул .NET и то как они пытаются занять своё место под солнце путём расширения платформ и интеграции в неё различных ниш, что, в свою очередь, очень сильно подпиливает ножки стула у Java, но это всё равно затянется на десятилетия... (при условии что Oracle не будет предпринимать попыток сделать то же самое)
По мне так отличный пример конкуренции двух очень близких языков программирования.
Было бы интересно услышать мнение других по этому вопросу тоже :)vadimr
00.00.0000 00:00-5.Net крайне мало распространена вне Windows.

navferty
00.00.0000 00:00+4Это утверждение могло быть справедливым лет 10 назад, но сейчас, я уверен, программы на C# намного чаще запускаются на Linux, чем на Windows (если смотреть по соотношению вакансий, чаще всего C# используется для разработки веб-приложений, которые удобнее запускать на линукс машине, зачастую в контейнере).
Старый фреймворк объявлен deprecated уже почти 4 года назад, а современные версии ․NET кроссплатформенные.
vadimr
00.00.0000 00:00-3Лично я в своей практике ни разу не встречал под Linux программу, написанную на C#. Хотя, наверное, они существуют.

taishi-sama
00.00.0000 00:00+4Если играете в игры, то игры на Unity используют C#, и они зачастую кроссплатформенны. Ещё есть неплохой по размерам пласт игр, написанных на чисто C#-фреймворках (Terraria и Stardew Walley, например, кроссплатформенны и сделаны на прямых потомках XNA, Space Station 14 и Osu!Lazer вообще используют самописные игровые движки на чистом, последнем C# под самый актуальный рантайм — .NET 7, где максимум используется SDL для работы со всем зоопарком графики).
Ну а проблема с C# для простых десктопных приложений под Linux в том, что не существует настолько простого способа разрабатывать GUI в приложении на C#, как это существует под Windows, а в более сложных вариантах существует огромное количество конкурентов, от Qt до парочки фреймворков для кроссплатформенного интерфейса для Java. Ну и рантайм .NET — зависимость довольно специфична для Linux(.NET рантайм в стандартном репозитории есть вообще только в Ubuntu, и то там скорее всего будет устаревшим на одну мажорную версию), а лишние 70 МБ автономного рантайма игре простят, зависимости для бэкэнд проекта на C# будут задачей не конечного пользователя, а девопса, а вот в других задачах, особенно для простого консольного или графического приложения, могут задуматься.
Ну и есть огромный пласт бэкэнда, написанного на C#, который просто так не увидишь, если не будешь работать непосредственно в самой организации, использующего его
DistortNeo
00.00.0000 00:00В кровавом энтерпрайзе, где легаси на легаси и легаси погоняет — да.
А вот в стартапах часто выбирают уже не Java.

Rinsewind
00.00.0000 00:00При этом статус deprecated ничуть не мешает софту N-летней давности крутиться в debian контейнере
box0547
00.00.0000 00:00+2Из интересных фич .NET можно упомянуть intrinsics, memory and spans, AOT. Не знаю, как там с этим у Java.

dph
00.00.0000 00:00-1Да, все это есть в Javа, в том или ином виде.
DistortNeo
00.00.0000 00:00+2А можете пояснить? Потому что беглый гуглёж показал, что в Java ничего из этого нет и, скорее всего, никогда не будет из-за особенностей самой JVM.
dbf
00.00.0000 00:00https://openjdk.org/jeps/426
https://openjdk.org/jeps/383
https://www.graalvm.org/22.0/examples/java-kotlin-aot/DistortNeo
00.00.0000 00:00По вашим же ссылкам: и Vector API, и Foreign-Memory Access API находятся в состоянии Incubating API. Это экспериментальные фичи, которые монут быть изменены или вообще убраны в будущих релизах. Это явно не те вещи, которые можно было бы использовать в проде.
Надо понимать, что платформа .NET разрабатывалась как альтернатива экосистеме Java с учётом её опыта и решением накопленых проблем. В отличие от JVM, в .NET изначально были и указатели, и структуры, и почти сразу завезли нормальные дженерики (18 лет назад!). А вот в JVM до сих пор ничего из этого нет, и весь функционал представляет собой костыль на костыле, который, в принципе, работает благодаря многочисленным оптимизациям в конкретных реализациях JVM.
dbf
00.00.0000 00:00В исходном комментарии было написано "что в Java ничего из этого нет и, скорее всего, никогда не будет из-за особенностей самой JVM". Как видно, особенности jvm тут ничему не мешают, да и "скорее всего, никогда не будет" звучит необоснованно. Долгое время, например, хитрая работа с памятью делалась через misc.Unsafe, который задепрекейтили и делают замену.
Что касается дженериков, то их реализация в Java (видимо, она имеется ввиду) — не самая удачная, но имеющая свои обоснования — это вообще вопрос не jvm, а дизайна языка java. Kotlin работает на jvm и имеет другую реализацию. Так что " вот в JVM до сих пор ничего из этого нет" опять не применимо.
DistortNeo
00.00.0000 00:00Как видно, особенности jvm тут ничему не мешают
Особенности JVM приводят к тому, что приходится реализовывать всё это через костыли.
да и "скорее всего, никогда не будет" звучит необоснованно.
Я вполне допускаю, что эти фичи так и останутся экспериментальными.
Что касается дженериков, то их реализация в Java (видимо, она имеется ввиду) — не самая удачная, но имеющая свои обоснования — это вообще вопрос не jvm, а дизайна языка java. Kotlin работает на jvm и имеет другую реализацию.
Не соглашусь. Именно JVM накладывает ограничения на реализацию дженериков. И под капотом что в Java, что в Kotlin всё выглядит одинаково.
dbf
00.00.0000 00:00+1Тогда, похоже, вся разница в понимании фразы "никогда не будет из-за особенностей самой JVM" - для меня это звучит как невозможность технически это реализовать (что опровергается указанными jep), а для тебя - что из-за того, что это не заложили с самого начала платформы это маловероятно сделать организационно. В таком виде противоречия нет, последим за новыми версиями.
DistortNeo
00.00.0000 00:00из-за того, что это не заложили с самого начала платформы это маловероятно сделать организационно
Именно так.
dph
00.00.0000 00:00Как-то странно гуглили.
1) https://www.baeldung.com/jvm-intrinsics, https://vksegfault.github.io/posts/java-simd/#fn:1
2) Реализуется через Unsafe, есть целые библиотеки реализации примитивов через unsafe, например https://github.com/alexkasko/unsafe-tools
3) https://www.baeldung.com/ahead-of-time-compilation и кроме Graal были и другие решения для AOT для Java.
Все нагуглено за 3 минуты.


belch84
00.00.0000 00:00+10FORTRAN пока и есть главный претендент на то, чтобы сохраниться к своему столетнему юбилею. Его сила — в наличии огромного количества качественно отлаженных программ (и библиотек), реализующих численные алгоритмы. Если возможно использовать эти программы на уровне объектного кода (т.е. обращаясь к ним из других языков), то нет никакого смысла переписывать их на какие-либо иные языки, поскольку переписанные программа практически наверняка будут медленнее, также при переписывании обязательно будут внесены ошибки. Следует помнить, что уровень программистов, создававших и отлаживавших численные алгоритмы на FORTRANе, был в среднем выше, чем у нынешних. Конечно, численные алгоритмы — это не все, что нужно человечеству, но их доля среди прочих весьма значительна. Новые же численные алгоритмы появляются крайне редко.
Все это не отменяет недостатков FORTRANа, но главное его достоинство, что он был практически первым языком высокого уровня, и позволил создать нечто почти незыблемое, которое можно использовать и сейчасJustMoose
00.00.0000 00:00+1"Следует помнить, что уровень программистов, создававших и отлаживавших численные алгоритмы на FORTRANе, был в среднем выше, чем у нынешних." - А что есть "уровень программиста"? Я вполне допускаю, что программисты, которые писали под фортран, действительно знают математику получше. Но не уверен, что это верно в части программирования. Просто потому, что за последние лет 30 придумали много чего интересного. ООП хорошо так развился, паттерны всякие, да и железо на месте не стоит. Оптимизаторы получше стали. В общем, айти - одна из самых быстро развивающихся областей и наверняка найдётся многое, чего во времена Фортрана просто не существовало, и о чём тогдашние программисты просто не знали.

avacha
00.00.0000 00:00+4Так вот кому мы обязаны говноподелиями на электроне, страницами сайтов на десятки мегабайт и иже с ним. Да, б..., лучше стали. Да им до программистов даже времен расцвета борландского С, не то что эпохи фортрана - как до луны раком. Без содрогания на современные поделия ремесленников смотреть невозможно.
JustMoose
00.00.0000 00:00Я не спорю, что и говнокодеры тоже встречаются в природе ;)
Однако приведу небольшой пример: вот прям сейчас мы переписываемся на хабре, и используем для этого... браузер! Который, внезапно, имеет "трудоёмкость" в десятки тысяч человеко-лет. И который написан на чистейшем С++ и питоне с использованием паттернов. И который содержит десятки тысяч плюсовых файлов с исходниками.
Могли ли его написать те крутые программисты на Фортране? Да, конечно. Но! Это заняло бы, условно, в десять раз больше времени, просто потому что С++ поудобнее будет. (А если учесть, что браузер пишут последние четверть века... то x10 превращает задачу в практически невыполнимую).
belch84
00.00.0000 00:00Здесь же речь не о том, что FORTRAN в чем-либо превосходит современные ЯП. В начале своей трудовой деятельности мне довелось попрограммировать на FORTRANе (кстати, задачи были не совсем на численные методы), могу ответственно заявить, что он ужасен, особенно общие области COMMON — это настоящий кошмар (тем более, что во время учебы в университете мы тренировались на ALGOL-68, с тех поря я тепло отношусь ко всем алголоподобным языкам). Вместе с тем необходимо признать, что условное расстояние от программирования в машинных кодах до FORTRANа намного больше расстояния от FORTRANа до более современных языков, не говоря уже о расстоянии между самими современными языками. Поэтому дожить до столетия нынешним языкам будет сложно. А так — конечно, очень многие ЯП намного лучше, чем FORTRAN
Refridgerator
00.00.0000 00:00+2Переносил пару раз программы с фортрана на си. Это делается не вручную, а специальным конвертером, которых написано уже навалом. Главная сложность — это последующая чистка кода, поскольку авторы кода на фортране любят злоупотреблять goto и однобуквенными глобальными именами переменных (а ещё нумерация массивов не с нуля). О существовании многопоточности с разделением доступа, гонкой данных, деадлоками и прочими плюшками на фортране не подозревают примерно лишь все (привет от глобальных переменных). Ну а новое поколение учёных, по моим наблюдениям, выбирают питон, матлаб, маткад и иже с ними. И это логично — язык для учёных должен быть простым и удобным, чтобы и программировать легко, и в ноги не стрелять, и другой сторонний программист смог бы разобраться в их коде.
belch84
00.00.0000 00:00Пока есть необходимость в чистке конвертированного кода, нужны будут люди, способные сравнить исходные тексты, а также компиляторы с FORTRANа для окончательного тестирования результатов переноса. Все это будет продлевать существование древнего языка.
Refridgerator
00.00.0000 00:00+2Уже сам факт, что код из фортрана переписывается на си, а не наоборот, уже как бы намекает, какой именно из языков собирается на упокой. Точно так же, как и патефонные пластинки оцифровывают, чтобы музыка не потерялась. Содержание первично, носитель вторичен. Язык программирования это именно носитель, а первичны алгоритмы. Ну и правильная постановка вопроса — это не уже существующие компиляторы для каких-то языков на уже существующих платформах, а для каких языков в первую очередь пишут компиляторы на новых платформах.
Ну и что фортран, что си — это же всё-таки исторически первые языки, когда ещё не было понятно, что хорошо, а что плохо. Даже сейчас это не совсем ещё понятно, и новые языки чуть ли не каждый день появляются. Рано или поздно революция случится.belch84
00.00.0000 00:00-1Уже сам факт, что код из фортрана переписывается на си, а не наоборот, уже как бы намекает, какой именно из языков собирается на упокой
Аргумент странный, ничего не доказывающий. Вполне себе могу представить ситуацию, когда начнут переписывать программы с FORTRANа на другой какой-нибудь язык, потом на третий, и будут продолжать переписывать до его столетия. Необходимость переписывания может диктоваться соображениями совместимости, но иногда все равно дешевле будет обеспечить взаимодействие языков на уровне объектных модулей. Повторюсь, никто не спорит с тем, что C удобнее FORTRANа, но удастся ли первому полностью вытеснить второй — это вопросДаже сейчас это не совсем ещё понятно, и новые языки чуть ли не каждый день появляются. Рано или поздно революция случится
И как эта революция будет выглядеть? Появится универсальный язык, который вытеснит все остальные, а потом еще и будет существовать столетие? У меня на этот счет сильные сомнения. Скорее языки будут развиваться в направлении специализации, чем далее — тем более узкой (например, ЯП для стоматологов или генетиков). И (могу себе представить) — под оберткой у них может снова оказаться FORTRANRefridgerator
00.00.0000 00:00+1Фортран по природе — это процедурный язык, в одном семействе с бейсиком и паскалем. Причём заточенный под ограниченный набор конкретных задач. Ну есть там встроенная поддержка комплексных чисел — это плюс конечно. А поддержки дуальных чисел нет. И даже поддержки просто рациональных чисел нет. И можно ли их туда добавить используя стандартные возможности языка, без костылей — я не уверен. И чем больше фич в него будет добавлено по принципу «смотрите, мы тоже так можем», тем более уродливым он будет становиться. Как собственно, и любой другой язык.
Революция — это когда появится язык, отходящий от устоявшихся традиций и синтаксис со встроенными типами которого будет яснее и прозрачнее. Навскидку я даже могу накидать несколько революционных идей, которые лично мне бы хотелось бы видеть.
В частности, одна из проблем при работе с массивами — это доступ по индексу за пределами его объявления. Это приводит либо к исключению, либо к повреждению других данных, либо ко всяким уязвимостям. Решение: при определении массива требовать явно задавать реакцию на подобный сценарий — либо возвращать ноль, либо возвращать значение по модулю от индекса (зацикленный массив), либо сразу явным образом задавать callback-функцию, вызываемую при выходе за пределы.
Заодно можно отделить тип «целочисленный индекс» от типа «целое число», что позволит явно определять, какие переменные могут изменяться внутри цикла, а какие нет.
Можно задать возможность явно определять индексацию в массивах с нуля или единицы.
Основная проблема циклов в том, что они могут стать бесконечными, особенно когда количество циклов получено извне. В этом случае на уровне языка можно требовать или явного определения допустимых границ значений, или явного ограничения времени выполнения.
Можно ввести уровни доверия, неявно привязанных к переменным. Это позволит на уровне компиляции определять, была ли произведена проверка на корректность входных данных или нет, и выдавать соответствующие предупреждения.
Можно запретить неявное приведении типов при сравнении, например unsigned int с double (потому что UB, doublе может принимать значение «не число»).
Можно избавиться от отдельных символов для boolean типов и использовать их для других целей. Можно добавить операции для некоммутативного сложения/умножения, позволяющих компилятору точно понимать, что можно оптимизировать, а что нет.
Можно легализовать синтаксис типа 1.2.3 и 4:5:6, что позволит записывать рациональные числа, даты и ip-адреса без скобочек и строковых типов c их последующим парсингом.
Можно на уровне языка добавить поддержку постфиксной записи математических выражений и композиции функций (что сделано, например, в Mathematica).
Можно добавить поддержку любых гиперкомплексных чисел, включая те, которые ещё никто не исследовал.
Можно добавить поддержку конечных автоматов, избавляющих от мешанины из case, if и else. Это заодно позволит на уровне компилятора определять, все ли переходы и состояния корректно определены.vadimr
00.00.0000 00:00В частности, одна из проблем при работе с массивами — это доступ по индексу за пределами его объявления. Это приводит либо к исключению, либо к повреждению других данных, либо ко всяким уязвимостям. Решение: при определении массива требовать явно задавать реакцию на подобный сценарий — либо возвращать ноль, либо возвращать значение по модулю от индекса (зацикленный массив), либо сразу явным образом задавать callback-функцию, вызываемую при выходе за пределы.
Это сделает невозможной векторизацию.
Основная проблема циклов в том, что они могут стать бесконечными, особенно когда количество циклов получено извне. В этом случае на уровне языка можно требовать или явного определения допустимых границ значений, или явного ограничения времени выполнения.
Любой управляющий процессом цикл фактически бесконечен. Представьте, что у вас в домофоне количество итераций кончилось.
А так вообще язык, собравший все полезные фичи, которые могли придумать, уже был, это PL/I. Основная его проблема оказалась в том, что почти никто не мог его выучить целиком. Не говоря про написание совместимых между собой реализаций компиляторов.
Refridgerator
00.00.0000 00:00Это сделает невозможной векторизацию.
«Преждевременная оптимизация — корень всех зол»©. Автоматическая векторизация возможна далеко не во всех сценариях обращения с массивами. Экстремальная оптимизация всегда пишется вручную. Что опять же сильно легче сделать, когда в языке встроена поддержка многомерных типов, например (про ассемблер очевидно упоминать нет смысла).А так вообще язык, собравший все полезные фичи, которые могли придумать, уже был, это PL/I
Посмотрел я этот PL/I. До современного С++ не дотягивает даже близко. Вероятно, причина его непопулярности оказалась не во во множестве фич, а в неудачном дизайне, при котором множество фич усложнило написание программ, а не облегчило.vadimr
00.00.0000 00:00Посмотрел я этот PL/I
%-)
До современного С++ не дотягивает даже близко.
C++ развивается в совершенно другом направлении, чем PL/I. Во многом в противоположном. Например, во времена PL/I повсеместно считалось, что строгая типизация – зло.
vadimr
00.00.0000 00:00Раскрепощающие воображение задачи для программирования из арсенала PL/I:
Опишите вещественную переменную, которая на машине любой архитектуры будет обеспечивать представление не менее 10 (или другого конкретного значения) десятичных разрядов после запятой.
Напишите оператор ввода, который принимает данные в виде присваивания любой имеющейся в программе переменной значения и присваивает это значение. Например, ввод в виде A = 3 присвоит значение 3 переменной A, если такая переменная описана в области видимости оператора ввода.
Распечатайте значение произвольной структуры данных.
Напишите функцию, внутри которой будет несколько различных областей видимости.
Прочитайте задом-наперёд данные с магнитной ленты, движущейся в обратном направлении.
Напишите цикл, управляющая переменная в котором имеет тип файл.
Обработайте ситуацию антипереполнения в вычислениях с вещественными числами.
Напишите программу, делающую запрос на языке SQL таким образом, чтобы у программы были права на базу данных, которых нет у запускающего её пользователя.
Напишите вашу любимую программу целиком на языке препроцессора.
Запустите программу, содержащую синтаксические ошибки в своём исходном коде.
Refridgerator
00.00.0000 00:002,3,10 — C# c рефлексией не видит проблем в этих задачах. 4-ю не понял, 1 — типы decimal, BigInteger, Rational. 6 —
foreach(var file in dir.GetFiles()). 7 — #define double DOUBLE, где в классе DOUBLE переопределены математические операции с дополнительной проверкой. 8 — нужно просто перенести часть логики в хранимые процедуры или вьюшки. 9 — IOCCC знает как.vadimr
00.00.0000 00:002, 3, 10 - речь про любую структуру данных, а не про объект, который сам себе реализует рефлексию. Хотя это движение в верном направлении.
1 - это не вещественные типы.
6 - это цикл по именам файлов, а не по файлам. Хотя тоже движение в верном направлении.
7 - речь шла об обработке исключительных ситуаций, а не о проверке.
8 - тогда пользователь может сам вызвать эту процедуру или вьюшку.
Refridgerator
00.00.0000 00:00+11. истинно вещественных чисел в программировании не бывает, потому как они предполагают бесконечное количество цифр после запятой. Double это лишь подмножество целых чисел с логарифмической интерпретацией.
6. Всегда можно написать свой Enumerator, возвращающий конкретно необходимый тип, если тот не предусмотрен из коробки.
7. Не уверен, что SSE/AVX в таких случаях будут генерить исключительные ситуации, которые можно перехватить и обработать даже на уровне ассемблера.
8. Возможно, я не правильно понял суть задачи, но в SQL считается хорошим тоном ограничивать права пользователя на уровне СУБД, а не приложения.
vadimr
00.00.0000 00:001 - тем не менее, логарифмические типы наиболее широко используются, и проблема актуальна. Отчасти она решена по бедности введением стандарта IEEE. Но не на всех даже современных машинах арифметика IEEE-совместима.
7 - есть такие. Аппаратно регулируется флажком.
8- в СУБД так делают как раз именно по той причине, что в современных средствах разработки невозможно отделить права приложения от прав запускающего его пользователя, и поэтому ограничивающее приложение ничего на самом деле не ограничивает, так как можно зайти в обход. Но задумывалось изначально всё не так. Исходно хранимые процедуры компилировались на клиентской стороне.
Refridgerator
00.00.0000 00:007. Ну тогда я сразу на асме в FPU напишу, если это критично. А вообще, если до такого может дойти дело — ну значит программист изначально выбрал неподходящий тип данных. Устранять нужно причину, а не следствие.
8. Нет, так делают из-за риска SQL-инъекций. Достучаться к СУБД можно со стороны без приложения в принципе, просто перехватив tcp-пакет со строкой подключения.
vadimr
00.00.0000 00:00+1SQL инъекции невозможны, если операторы SQL обрабатываются на стадии компиляции.
TCP пакет со строкой подключения никак вам не поможет исполнять свой собственный код, не относящийся к пакету программы. Речь ведь не идёт о том, что программа работает из-под своего собственного пользователя.
Почитайте про статический SQL.
Refridgerator
00.00.0000 00:00Оператор SQL не может быть обработан на стадии компиляции, если тот отправляется на удалённый сервер по сети. А вот на самой СУБД — да, хранимая процедура может быть откомпилирована, оптимизирована и ограничена в правах вызова для конкретных пользователей.
vadimr
00.00.0000 00:00Я ж вам говорю, изучите матчасть (статический SQL). Тем более это основы SQL, то, как он изначально задумывался, и от неполной реализации чего сейчас происходит всякая фигня типа инъекций.
Refridgerator
00.00.0000 00:00-1Спасибо, но матчасть я знаю достаточно из подтверждённого дипломом высшего образования. Заодно, проектирование и сопровождение СУБД, вместе с сопутствующей фронт- и бэк-логикой, включая системы автоматизации металлургическим производством - это и есть моя основная работа.
vadimr
00.00.0000 00:00Высшее образование – это хорошо, но это только доля необходимой для изучения матчасти. А вот то, что вы, имея своей основной работой проектирование СУБД, пишете вещи типа:
Достучаться к СУБД можно со стороны без приложения в принципе, просто перехватив tcp-пакет со строкой подключения.
и
Оператор SQL не может быть обработан на стадии компиляции, если тот отправляется на удалённый сервер по сети.
– вот это очень печально.
PuerteMuerte
00.00.0000 00:00+2– вот это очень печально.
Почему? Первое в целом корректно, если не брать во внимание современные детали, что из https-соединения параметры подключения к СУБД вы в общем случае не получите, но тем не менее, по умолчанию следует полагать, что строка подключения — не секрет, и клиент-серверное приложение, это лишь один из возможных клиентов, которыми пользователь может подключиться к СУБД. Естественно, это правило не работает для трехзвёнок, частный случай которых — веб-приложение.
Про компиляцию, полагаю, ваш оппонент имел в виду компиляцию приложения, а не собственно оператора SQL
Refridgerator
00.00.0000 00:00Не, я имел ввиду именно то, что и сказал. Неважно, в каком виде SQL-запрос добирается до сервера с СУБД — в чисто текстовом или скомпилированном неважно в каком байт-коде. Всё это может скомпрометировано, как и строка подключения, так и отдельно взятый запрос. Поэтому, даже если бизнес-логика требует, чтобы пользователь смог выполнить DROP DATABASE — он не должен смочь её выполнить явным образом. Он должен смочь её выполнить только опосредованным образом — чтобы заодно выполнилось DUMP DATABASE и запись в журнал событий, кто и с какого IP эту операцию запросил. А гарантировать такое можно только на уровне СУБД.
PuerteMuerte
00.00.0000 00:00А гарантировать такое можно только на уровне СУБД.
Или в трёхзвенке. Они для того и придуманы были, чтобы убрать все уровни бизнес-логики, в том числе и контроль прав доступа, с централизованного нижнего звена на горизонтально масштабируемое среднее.
vadimr
00.00.0000 00:00Теоретически всё может быть скомпроментировано, в том числе и работа самого сервера СУБД.
На практике команда DROP DATABASE не относится к DML и, совсем строго говоря, вообще к SQL, поэтому пример некорректен, но неважно. Путь будет DELETE FROM T.
Когда вы говорите, что пользователь должен выполнять команду опосредованным образом, то это верно. Неверно то, что вы себе представляете это только как хранимую процедуру. А ведь код хранимой процедуры точно так же набирает программист за рабочей станцией, как и код клиентского приложения. И разницы здесь нет вообще, кроме оформления инструментария программирования.
Изначально, в IBM DB2 (SQL/DS), весь SQL был статическим, и операторы SQL записывались в тексте клиентской программы и обрабатывались препроцессором, который, упрощённо говоря, их обрабатывал примерно так же, как хранимые процедуры, помещая откомпилированный план выполнения на сервер. При этом программист имет право выполнять DELETE FROM T, и это право наследует выполняемый пакет в базе, а пользователь, работающий с программой, имеет право только запускать этот пакет (GRANT EXECUTE).
В дальнейшем людям из Oracle, которые, в отличие от IBM, не контролировали компиляторы с языков высокого уровня, пришло в голову сделать отдельный язык PL/SQL и поместить его компилятор на сервер. Так возникли хранимые процедуры. Но в сущности мало что поменялось.
Сейчас статический SQL мало распространён, но доступен для ряда СУБД и языков.
В DB2 вообще можно практически одну и ту же программу на языке высокого уровня со статическим SQL откомпилировать в исполняемый файл для рабочей станции, и тогда она будет клиентским приложением, или в динамическую библиотеку для сервера, и тогда она будет хранимой процедурой. Но в том и другом случае сам откомпилированный план выполнения запросов в пакете хранится в системной таблице на сервере.
Refridgerator
00.00.0000 00:007. Обработайте ситуацию антипереполнения в вычислениях с вещественными числами
У меня встречный вопрос. Организуйте вычислительный процесс так, чтобы чтобы переполнение/антипереполнение не приводило к ошибкам, без использования условных операторов и перехвата исключений.Refridgerator
00.00.0000 00:00Ну допустим написали вы допустим программу на PL/I для управления марсоходом, где корректность вычислений гарантирована перехватом исключений и возвратом заранее посчитанных значений. А затем эту программу перенесли на платформу, где вместо исключений NaN или Infinity — и всё, встанет марсоход в самом неожиданном месте.
А ещё есть платформы, где ветвления и циклы отсутствуют в принципе — DSP-процессоры, там время обработки строго ограничена. Перефразируя известный мем «программа не сможет впасть в бесконечный цикл, если в ней не будет циклов в принципе».
vadimr
00.00.0000 00:00Когда речь идёт о марсоходах и прочем встраиваемом ПО, то здесь вспоминается в известной степени противоположный пример. Ракета Ariane как-то упала из-за того, что возникла исключительная ситуация при обработке данных не используемого на данном участке полёта датчика, выдававшего мусор. Робастные алгоритмы обработки никто не отменял.
Refridgerator
00.00.0000 00:00Вот например нужно написать программу для вычисления значения рационального многочлена с заранее неизвестными коэффициентами. И вот получаем такой:

Как его вычислить в нуле без привлечения аналитических методов и символьных преобразований?
vadimr
00.00.0000 00:00Не надо вообще злоупотреблять операцией деления на марсоходе, я бы такой совет дал.
Делишь в управляющей программе – убедись в том, что знаменатель ограничен по модулю снизу. И, независимо от этого, продумай, что будет в случае переполнения.
Refridgerator
00.00.0000 00:00Так в том-то и дело, что приведённая функция всюду определена, больше нуля и меньше трёх. В нуле имеет значение 1, в частности. С функцией всё в порядке. Не в порядке программа, которая не может её вычислить.
vadimr
00.00.0000 00:00А раскрытие неопределённости – это не аналитический метод, который вы не хотите использовать?
Вы тут несколько переусложняете простой вопрос. Для того, чтобы ваша программа не падала, не нужно владеть алгебраическими преобразованиями. Вот для того, чтобы получить правильный результат вычислений – уже неплохо бы.
Refridgerator
00.00.0000 00:00Раз вопрос простой — вам же не составит труда написать программку, считающих подобные функции? Может, в Фортране даже готовый функционал для этого есть, чтобы не владеть алгебраическими преобразованиями.
vadimr
00.00.0000 00:00Простой вопрос не в том, чтобы сосчитать верный результат, а в том, чтобы не падать. Полином, записанный прямо в таком виде, никогда не должен появиться в управляющей программе, так как его знаменатель может обращаться в ноль, что очень легко понять. Независимо от того, можно или нельзя раскрыть неопределённость.
Refridgerator
00.00.0000 00:00Нет, не очень легко понять, когда его коэффициенты вычисляются, а не задаются явным образом. Но я так понимаю, ваш ответ — «нет, я не могу написать такую программу».
vadimr
00.00.0000 00:00Понять абсолютно легко: если есть полином, он потенциально может быть нулём.
Я не понимаю смысла вашей задачи. В реальной управляющей программе марсохода никогда не будет кубических форм, там будут линейные приближения в цикле обратной связи. Ну максимум квадратичные. А если уж понадобится посчитать зачем-то вашу дробь, напишут примерно так:
t = знаменатель;
if (abs (t) < 1)) t = sign (t);
функция = числитель / t;
Неточно численно, но не упадёт.
Refridgerator
00.00.0000 00:00Смысл задачи в ТАУ/ЦОС и конструировании функций с заданными характеристиками, включающих ограничение значений на бесконечном интервале и прохождение через явно заданные точки. Марсоходами пока не занимаюсь, это был пример ситуации, когда нельзя просто так взять и отбуксировать его на станцию тех.обслуживания, чтобы исправить ошибку.
Ну а ваше решение неправильное, неопределённость оно не раскрывает, просто подсовывает по сути случайное значение. Из-за таких «решений» ракеты и падают.
vadimr
00.00.0000 00:00Причём здесь ТАУ? Вы понимаете, как работает пид-регулятор? Он управляется своей собственной обратной связью, через реальные физические параметры.
Когда вы говорите про ТАУ, то это синтез системы управления, а не её использование.
Refridgerator
00.00.0000 00:00Пид-регулятор — это всё, что вы знаете из ТАУ? Начните с передаточной функции, чтобы узнать больше. Задайтесь вопросом, почему он имеет вид рационального многочлена, а не обычного. Задайтесь вопросом, какой смысл его вычисления, причём тут билинейное преобразование, и как решаются прямо противоположные задачи.
Но это если интересен источник возникновения задачи. Если интересует, как численно разрешать неопределённости в рациональных функциях без всяких там Лопиталей — ответ ищется в численных методах.
vadimr
00.00.0000 00:00Тут такое дело. Марсоход не считает свои передаточные функции. Это инженер делает, в КБ. И он не падает.
Refridgerator
00.00.0000 00:00Марсоход не считает, другие считают, «цифровая фильтрация» это называется. А марсоход как-минимум обсчитывает данные с датчиков.
Refridgerator
00.00.0000 00:00При том что Автоматизированное Управление может осуществляться множеством способов, включая нелинейные функции и вычислительную технику. При чём тут вопросы про ТАУ? Мы вроде бы как обсуждали преимущества применения Фортрана и PL/I для решения задач чуть посложнее сложения двух массивов, а мой вопрос был о том что — недостаточно перехватить событие антипереполнения и нужно его ещё корректно обработать — что вы опять же продемонстрировать пока не смогли.
vadimr
00.00.0000 00:00Потому что вы напихали в одну кучу четыре разных вопроса: ТАУ, Фортран, PL/I и марсоход.
Refridgerator
00.00.0000 00:00Если например сделать замену
x->x-1(то бишь просто линейный сдвиг) и пересчитать коэффициенты, то проблем с вычислением ни этой, ни каких-либо других точек уже не возникнет. Конечно, тут можно начать дискуссию на тему «но это же будет уже другая функция!», но так я и не это решение и имел ввиду, сразу оговорив, что оно должно быть численным.
Да и вообще дискуссия не об этом. Оппонент в качестве «задач на воображение» привёл сборник плохих практик программирования. А плохие практики потому и плохие, что их практиковать не надо, и думать в эту сторону тоже. Думать надо в сторону хороших практик. Хорошая практика — это когда ловить исключение не надо, потому что оно никогда не возникнет. Более простой пример — угадайте, как избежать NaN при вычислении sqrt(-1).
0xd34df00d
00.00.0000 00:00Если например сделать замену x->x-1 (то бишь просто линейный сдвиг) и пересчитать коэффициенты, то проблем с вычислением ни этой, ни каких-либо других точек уже не возникнет.
Совершенно очевидно, что от линейного сдвига по горизонтали пересечения с нулём не исчезнут. Магии не бывает.
Конечно, тут можно начать дискуссию на тему «но это же будет уже другая функция!»
Я не очень понимаю, какие нужны дискуссии вокруг, упрощая, вопроса о том, является ли y(x) = x и y(x) = x — 1 одинаковой функцией или нет.
Более простой пример — угадайте, как избежать NaN при вычислении sqrt(-1).
Спрашиваете! Типами, конечно.
Refridgerator
00.00.0000 00:00Совершенно очевидно, что от линейного сдвига по горизонтали пересечения с нулём не исчезнут. Магии не бывает.
Как насчёт того, чтобы взять и проверить? Я проверил, прежде писать это, Mathematica у меня не закрывается никогда. Насчёт магии — математика для меня и есть магия, вся целиком.
0xd34df00d
00.00.0000 00:00Проверить что именно? Инвариантность поведения функции относительно смены имён (и замены везде
xнаэ, например) вам случайно проверять не надо?Но если очень хочется что-нибудь проверить, то возьмите
f(x) = (x - 1)³ + (x - 1)² + (x - 1)(это ваш знаменатель после сдвига) и попробуйте решить уравнение f(x) = 0 (можно попробовать даже без Mathematica, а если сходу не получится, то подсказка: x = 1 подходит). Попробуйте сделать выводы о проблемах вычисления всей дроби после сдвига в точке x = 1.
Refridgerator
00.00.0000 00:00Я же сказал — надо пересчитать коэффициенты, то есть раскрыть скобки и упростить.
0xd34df00d
00.00.0000 00:00Вы в итоге всё равно «сократили на x» и получили неэквивалентную функцию. Сдвигать для этого было совершенно не обязательно.
Refridgerator
00.00.0000 00:00Да, именно так, сдвиг был потому что «сократить на x» численно значит «поделить на ноль». Осталось только научиться делить на ноль и задача решена.
0xd34df00d
00.00.0000 00:00Сокращение на x-1 не отличается с точки зрения деления на ноль. Просто оно теперь происходит в другой точке.
Refridgerator
00.00.0000 00:00+1Неудачный пример взял, не туда разговор зашёл, разрешите попробовать ещё раз. Вот такой, чуть более сложный пример возьмём:

То, при каких x знаменатель обращается в ноль видеть легко, а вот является ли эта неопределённость устранимой — уже нет. Равно как и на что именно тут нужно поделить, чтобы её устранить. Ну а поскольку речь идёт о численных вычислениях, то вместо корня из пяти фигурирует число ≈2.236068, то есть вопрос обращения знаменателя в ноль есть случайность, зависящий от накопленной погрешности и порядка вычислений.
Задача на развитие воображения: написать программу, численно решающую рациональные многочлены и выдающую корректный результат в устранимых особых точках не зная заранее, где те находятся.
Crocodilus
00.00.0000 00:00Методом интерполяции по точкам, где знаменатель отличен от нуля, в окрестности нуля. То есть фактически методом доопределения по непрерывности. Ошибка при шаге 0,1 (точки -0,1 и 0,1) даже при линейной интерполяции по двум точкам составит 1%. Две точки - это практически мгновенное вычисление. Ошибка порядка ~
 , что более чем достаточно. Разумеется, точного ответа, "целочисленной" единицы, строго получить нельзя, но можно округлить.
, что более чем достаточно. Разумеется, точного ответа, "целочисленной" единицы, строго получить нельзя, но можно округлить.
Refridgerator
00.00.0000 00:00Да, это наиболее простой (но не единственный) метод. Если двигаться в этом направлении, то можно заметить, что нет никакой сложности вычислить производные числителя и знаменателя, а через них и производную самой функции. Таким образом можно увеличить точность кубической интерполяцией, построенной по двум точкам и производным в них. Хотя, имея возможность вычислять производные в произвольной точке, можно применить правило Лопиталя напрямую и единицу получить вполне точно.

beeruser
00.00.0000 00:00«Преждевременная оптимизация — корень всех зол»
Вырванная из контекста фраза, не более.
Под векторизацию нужно дизайнить с самого начала, начиная с форматов данных (в С++). При желании, конечно, компилятор может развернуть AoS в SoA, но это очень хрупко. К примеру так Интелом был "взломан" тест libquantum в SPEC2006. Теперь LLVM так тоже умеет, но это достигнуто ценой героических усилий.
"на 429.mcf, 462.libquantum и 179.art дает 50-70% "
В частности, одна из проблем при работе с массивами — это доступ по индексу за пределами его объявления
Это всё пытаются решить в железе (и многое другое). Например зашищённый режим в Эльбрусе или CHERI Morello.
https://developer.arm.com/documentation/den0133/0100/Morello-prototype-architecture
А в GPU оно так и работает с контролем индекса. Но жирные 128-битные дескрипторы буферов в GPU это данность, а на CPU люди нос воротят от такого, хотя от голых указателей постепенно отказываются.
Refridgerator
00.00.0000 00:00Вырванная из контекста фраза, не более.
Вполне в контексте фраза я щитаю. Если мы разрабатываем элемент языка с точки зрения безопасности — то и думать надо в первую очередь о безопасности, а не о векторизации. О векторизации нужно думать разрабатывая встроенные типы, о чём я тоже уже упоминал ссылкой на HLSL.Это всё пытаются решить в железе (и многое другое)
Тут вопрос не в том, чтобы предотвратить доступ к памяти за пределами массива. Тут вопрос в том, чтобы программа не вываливалась с сообщением «Out of Range», особенно когда возврат нуля в таком случае вполне корректен. Ну например если мы складываем элементы массива, то пара лишних «плюс ноль» результата не испортят. Или когда запрашиваем коэффициент многочлена. Или когда делаем свёртку. Мне тут сложнее придумать обратный сценарий, когда вывалиться с исключением единственно правильное поведение.
0xd34df00d
00.00.0000 00:00Любой управляющий процессом цикл фактически бесконечен. Представьте, что у вас в домофоне количество итераций кончилось.
Это коданные, там другое определение продуктивности и завершаемости.
0xd34df00d
00.00.0000 00:00Все, описываемое вами, уже решается уже существующими системами типов.
Refridgerator
00.00.0000 00:00В каком языке? В шарпе вроде всё нормально с типами, но писать там
var dt=2020.01.02 12:00:00;илиt=sin^2(x)+x(1+x);или(a,b)=(a+b,a-b);пока не получается.0xd34df00d
00.00.0000 00:00В идрисе, например. Особенно когда в идрис2 вернут кастомный синтаксис из первого идриса.
но писать там var dt=2020.01.02 12:00:00; или t=sin^2(x)+x(1+x); или (a,b)=(a+b,a-b); пока не получается.
В агде можно определять произвольные миксфиксные операторы с очень слабыми ограничениями — там, разве что, нельзя пробелы, точки и двоеточия, потому что это часть базового синтаксиса. Сделать что-то вроде
dt = 2020•01•02-12⦂00⦂00(или любую уникодную точку, отличную от ascii
.) вы там вполне можете.Refridgerator
00.00.0000 00:00Я хочу стандартные ascii-символы, Rebol же смог. Для уникодных точек революционные идеи тоже имеются, не пропадут.
0xd34df00d
00.00.0000 00:00Странное желание. Позволю себе сказать, что это вам не нужно, настройте в редакторе уникод и радуйтесь жизни. Жизнь становится тогда очень красочной.
Refridgerator
00.00.0000 00:00Вполне понятное желание. В этом и интерес, чтобы писать так же, как и привык, но не оборачивать всё это в кавычки постоянно и не писать каждый раз парсеры. (Хаскел смотрел, мужества не хватило).
Aleshonne
00.00.0000 00:00О существовании многопоточности с разделением доступа, гонкой данных, деадлоками и прочими плюшками на фортране не подозревают примерно лишь все (привет от глобальных переменных).
Комассивы и инструкции вроде sync images или event wait смотрят на это утверждение с удивлением. С не меньшим удивлением на него смотрят директивы !$omp и !$acc, обеспечивающие поддержку OpenMP и OpenAAC соответственно.
Refridgerator
00.00.0000 00:00Ну много чего в современный фортран добавили. Только программы ещё 10-летней давности от этого не станут ни быстрее, ни thread-safety. Может, уже даже «фортран с классами» появился, не изучал глубоко этот вопрос.
Aleshonne
00.00.0000 00:00+1OpenMP — это Fortran95. Это вообще не современный, а очень даже древний стандарт, старше половины пользователей хабра. Комассивы помоложе, появились в Fortran2008. Нет, я не спорю, что какой-нибудь дедушка-профессор может и сейчас писать на FORTRAN-IV образца 70-го года, но подавляющее количество программистов при выходе нового стандарта Фортрана в течении пары лет переходят на него, потому что совместимость со старым кодом стопроцентная, а новые фичи полезные.
PS «Фортран с классами» — Fortran2003, в этом году 20 лет исполняется стандарту.
Refridgerator
00.00.0000 00:00«Си с классами» — 1979 год, 4-ый десяток перевалил, хотя Фортран вроде бы как старше. Ещё пару десятков лет — глядишь, и полноценный Фортран++ появится.
P.S. ничего против Фортрана не имею, если что. Вопрос исключительно в том, что познакомившись с Фортраном уже после Си/С++ желания писать на нём не возникло. В то время как познакомившись с C# Дельфи (вариация Object Pascal) был забыт как страшный сон, а необходимость писать на Джаве вызывала боль и страдания.


staticmain
00.00.0000 00:00+4У меня есть большой вопрос к автору статьи. Он заявляет, что разработке 65 лет, приводит в пример языки Алгол, Фортран.
Ассемблер появился 74 года назад. На нем до сих пор пишут, в том числе я.

Keeper9
00.00.0000 00:00+6Языков ассемблера много. Для каждого процессора он свой, а часто и не один.
Какой из ассемблеров вы имеете в виду?

Sau
00.00.0000 00:00+2Возможно, тут понятия-омонимы (одинаково звучат, но разные по смыслу):
Ассемблер как язык низкого уровня в целом. И тогда ответ да - 74 года.
И ассемблер как язык конкретного процессора. И тогда ответ нет.
Я бы сказал что языки низкого уровня принципиально другие, и применять мерки языков выского уровня для них неправильно. Да, у них нет особой совместимости, они всегда привязаны к конкретному железу. Но при этом имеется общий дух и принципы работы.
staticmain
00.00.0000 00:00В статье нет указания на "низкие" или "высокие". Статья про "язык программирования".
tyomitch
00.00.0000 00:00+1Ассемблер как язык низкого уровня в целом. И тогда ответ да - 74 года.
Почему именно 74?
Z3 -- это 1941
staticmain
00.00.0000 00:00+1Так ви таки будете смеяться - я ничтоже сумняшеся открыл википедию, где в русской версии написано 1949, а в английской 1947
tyomitch
00.00.0000 00:00+2Енвики объясняет, что неясно, что именно считать первым "языком ассемблера".
Для Z3 (1941) был свой символьный язык, но не было автоматического переводчика из символьной записи в машкод, т.е. собственно ассемблера. Что важнее для определения языка ассемблера -- чтобы был язык, или чтобы был ассемблер?
В 1947 вышла статья об автоматическом переводе символьных программ в машкод; но компьютер ARC2, частью работы над которым была та статья, так и не был достроен. Что важнее для определения первого ассемблера -- идея или воплощение?
Для EDSAC (1949) был создан первый автоматический ассемблер. Для IBM 650 (1954) был создан первый ассемблер, который назывался словом "ассемблер". Что важнее для определения первого ассемблера -- функциональность или название?
staticmain
00.00.0000 00:00Какой бы я не использовал (мои - это х86 и 6502) - это всё равно одно семейство языков с общими правилами и различиями только в названии команд (a -> b, b <- a, знаки препинания и всё остальное - это скорее различия компиляторов)
tyomitch
00.00.0000 00:00+2Даже классический 8087 уже в другой парадигме; а посмотрите на что-нибудь современное с VLIW
vadimr
00.00.0000 00:00+1Мне не хочется спорить с человеком, частью души которого является постындексная косвенная адресация с индексацией по Y, но тем не менее. Так рассуждая, можно зайти в тупик, потому что, например, ассемблеры лисп- и форт-машин – это языки лисп и форт.


18741878
00.00.0000 00:00+3Fortran
Lisp
Basic
IMHO, разумеется :)
Fortran превосходен для расчетов (напомню, что обсчитывать надо много чего - аэрогидродинамика, теплопередача, ядерная физика, ...)
Lisp - просто красавчик. Равной по красоте и влиянию идеи, сдается мне, так больше и не появилось.
Basic - всеядный монстр, переваривающий и мимикрирующий под все, к чему только ни прикоснется.
Воспринимайте, конечно, как шутку. Лет через 50 (кто доживет) - посмотрим как все будет на самом деле.

klimkinMD
00.00.0000 00:00+1Дельфи есть, а Паскаля (Модулы, Оберона, Компонентного П.), Ады нет

omxela
00.00.0000 00:00Консольное приложение на Дельфи и есть, по сути, программа на Паскале, не более. Так что хитрец жив.

HemulGM
00.00.0000 00:00Я бы так не сказал. Во-первых, в консольном приложении тоже можно использовать ООП, во-вторых, спецификация Делфи далеко ушла от старого доброго Паскаля и теперь код наполнился инлайн переменными, выводом типов, анонимными функциями, рефлексией, дженериками ну и так далее.
Не говоря уже о том, что консольное приложение по сути ни чем не отличается от "оконного" приложения, кроме как наличия кода для создания окон.



avshkol
00.00.0000 00:00+2Лучшая поддержка языку, на мой взгляд - это быстрота входа и наличие множества бесплатных библиотек. В этом случае я бы поставил прежде всего на python. К тому же он специализируется в перспективной нише - ML и обработка разнообразных данных.
Более того, я бы считал языками отдельные широко используемые библиотеки, имеющие множество классов и функций. Вот pandas - чем не язык, совместимый с python?
Hemml
00.00.0000 00:00+1Собственно, BASIC был как раз таким языком в свое время. Все начинали с него. И где теперь BASIC? Вот и питон там же будет)

idamir
00.00.0000 00:00Замечание к переводу: to solve a problem - решить задачу, а не проблему. Проблемы создают, а решают задачи.

Ahuromazdie
00.00.0000 00:00+3Perl первый скриптовый? Ну это несерьезно. В этой вашей вики пописано "Перл унаследовал много свойств от языков Си, AWK, скриптовых языков командных оболочек UNIX. " awk, bourneshell не скриптовые языки? Да и разные васики чем не скриптовые?

olku
00.00.0000 00:00Про COBOL не совсем верно. Есть спека языка, реализации в виде компиляторов, все немного разные, и бизнес модель их авторов. Так IBM его сама и уничтожила.

aborouhin
00.00.0000 00:00+1IMHO, весь прошлый опыт прогнозирования развития технологий показывает:
Ни один прогноз на десятки лет вперёд не сбывается и по прошествии этих самых лет прогнозы из прошлого можно рассматривать только как анекдоты. А если кто-то случайно что-то и угадывает - это остаётся совершенно незамеченным современниками и вытаскивают этого "провидца" на свет Божий уже только по факту, вот мол, смотрите, какое удивительное совпадение.
То, что, по мнению большинства, взлетит и станет главным трендом вот-вот уже скоро - никогда таковым не становится.
Так что какой ЯП доживёт до 100 лет и будут ли тогда вообще ЯП - никто не знает и вряд ли кто угадает. ChatGPT и её потомки весь код за программистов писать точно не будут. Но, вероятно, весь ландшафт IT изменится каким-то иным, не менее кардинальным образом, который нам ныне неведом.
DistortNeo
00.00.0000 00:00ChatGPT и её потомки весь код за программистов писать точно не будут
А почему вы так уверены? Рано или поздно вычислительная мощность компьютера превысит возможности мозга. И это случится уже лет через 10. Останется только задача обучить нейросеть, а дальше нейросетевых джунов можно просто клонировать.
omxela
00.00.0000 00:00+2Зачем оставаться с Algol, когда существует C?
Автор два раза задвинул эту мысль. Но ещё живы свидетели процесса. Я начинал с Алгола в середине 70-х. Он был очень популярен в нашей стране. Но на БЭСМ-6, скажем, была ужЕ дубнинская версия фортрана. Научные расчеты в мире проводились к тому времени на фортране IBM и PDP. К концу 70-х клоны этих машин стали доступны. И если диплом я писал на Алголе, то на работе просто вынужден был перейти на фортран. Понравился язык только через год-два. И нравится сейчас. Но первая любовь не ржавеет, и как только появился борландовский компилятор Паскаля, я с удовольствием освоил этот язык. Да, так вот, Алгол был убит фортраном на моих глазах. До Си (в моей среде обитания) было ещё относительно далеко. Как и до бейсика, ассемблера, и много чего ещё.
vadimr
00.00.0000 00:00Алгол продвигали в Европе, а Фортран в США. Экономика США победила.
Jianke
00.00.0000 00:00Вроде, нишу Алгола занял Паскаль, который был создан как чисто учебный язык, изучив который можно легко перейти на Алгол.
vadimr
00.00.0000 00:00Это уже позже было. Причём Паскаль до UCSD тоже не имел популярности в США.
В 1960-е годы джентльменским набором в коммерческом программировании были Фортран и Кобол, а затем также PL/I. При этом алгоритмы было чаще всего принято публиковать на Алголе.

I_Love_Misato
00.00.0000 00:00+5Python хорош в математике, научном программировании и программировании искусственного интеллекта
Нет, не хорош)) К тому же значительная часть самих библиотек для машинного обучения (PyTorch, TensorFlow) всё равно написана на C++.
Преимущество Python только в простом синтаксисе, который с ходу освоит любой научный работник, не являющийся программистом. На этом его плюсы заканчиваются. В Питоне нет статической проверки типов, что полезно в любой задаче, в том числе и научной. Нет проверки единиц измерения, как в F# - где нельзя сложить километры с секундами, например (что реально очень круто).
Можно объявлять глобальные переменные со всеми вытекающими последствиями. Можно, конечно, разрабатывать аккуратно, но человеческий фактор никто не отменял, особенно если код пишет не программист. А ноутбуки типа Jupyter очень плохо способствуют написанию качественного кода.
Написание более-менее сложных нейросетей (особенно с рекуррентными компонентами) - это настоящий ад, потому что нужно помнить, чему соответствует каждая размерность тензора, и не дай б-г в каком-то месте формат тензора изменяется. Документирование в комментариях, конечно, немного спасает ситуацию, но язык тут не помогает совершенно.
Ну и последний гвоздь в крышку гроба Питона, точнее два гвоздя. Отсутствие механизма перегрузки функций - раз, громоздкий синтаксис ООП (а в том же PyTorch без классов - никуда) - два.
В общем, идеальный язык для научных целей - это язык с большими возможностями для статического анализа - причём не только типов и величин, а ещё и размерностей. То есть, на примере машинного обучения - чтобы на этапе написания программы компилятор мог подсказать, согласуются ли между собой два последовательных слоя. Второе желательное свойство - запрет глобальных переменных. Третье - опциональная иммутабельность. Ну и почему бы не добавить в идеальный язык операторы дифференцирования и интегрирования. Можно добавить возможность вбивать в программу уравнения - и пусть компилятор сам их решает.
В общем, вырисовывается что-то похожее на Mathcad, только заточенное под разработку реальных программ))) Через сто лет проверяйте - выживет ли Питон, или его заменит такой вот монстр))
JustMoose
00.00.0000 00:00+1"Преимущество Python только в простом синтаксисе" - это не совсем так.
Вики говорит, что "While 3GLs like C, C++, C#, Java, and JavaScript remain popular for a wide variety of uses, 4GLs as originally defined found uses focused on databases, reports, and websites.[3] Some advanced 3GLs like Python, Ruby, and Perl combine some 4GL abilities within a general-purpose 3GL environment,[4] and libraries with 4GL-like features have been developed as add-ons for most popular 3GLs, producing languages that are a mix of 3GL and 4GL, blurring the distinction.[5]" (отсюда https://en.wikipedia.org/wiki/Fourth-generation_programming_language)
Ну и чисто интуитивно - питон позволяет писать код на уровне выше, чем С++, просто потому, что больше не надо думать про "мелочи" вроде выделения памяти, практически ручную обработку строк, сетевые библиотеки и т.п. Написать какую-нибудь парсилку сайта на питоне можно за пару дней. На плюсах это займёт... бесконечность. Я вот ассемблер написал на питоне за выходные ;) На плюсах я бы до сих пор его пилил. (нет, не для intel-а, увы).
DistortNeo
00.00.0000 00:00+3А ноутбуки типа Jupyter очень плохо способствуют написанию качественного кода.
И, собственно, что? Конечным продуктом в науке является не код, а результаты экспериментов. Методология, принятая в среде программистов, совсем не подходит для научной среды. Поэтому именно среди учёных Jupyter набрал высокую популярность. Наличие глобального мутабельного состояния и возможность исполнения произвольных кусков кода в интерактивном режиме — это именно то, что нужно для экспериментирования. И только потом уже можно взять PyCharm и переписать код нормально.
Ну а то, что доминирующим языком в науке стал именно Python — это следствие того, что более подходящих языков попросту не было. До Python был популярен MatLab, но он проиграл из-за ценовой политики.
I_Love_Misato
00.00.0000 00:00Если бы с этим не было проблем в реальной практике, я бы об этом не писал))) Периодически возникают ситуации, когда из-за плохого кода возникают труднообнаруживаемые баги. И что хуже всего в таких случаях, программа-то работает, нейросети учатся, эксперимент идёт, а исследователи могут несколько дней сидеть и играться с параметрами. И терять время из-за одного незаметного бага.
Всё зависит от размеров и сложности экспериментальной программы. И когда кодовая база достигает определённого уровня сложности, в бой вступает стандартные методы программирования, основная цель которых - именно борьба со сложностью.

flashmozzg
00.00.0000 00:00Уже возникали курьёзы, когда результаты кучи научных работ оказывались невалилными из-за "особенностей" языков и инструментов для анализа (вспоминается экселт, который некоторые числа как даты интерпретировал или наоборот).
Jianke
00.00.0000 00:00Преимущество Python только в простом синтаксисе
Преимущество Питона в том, что сейчас он очень широко используется для обучения.
Как показывает опыт Паскаля, который был создан как чисто учебный язык, после которого нужно перейти на Алгол, если задачу можно решить на учебном языке, то он и дальше продолжает широко использоваться для решения задач.
vadimr
00.00.0000 00:00Паскаль широко использовался только в эпоху Borland, когда ни о каком Алголе речи уже не было. До того он был нишевым языком. Если на то пошло, многие необходимые для коммерческого использования конструкции языка вроде типа string и нетипизированных файлов окончательно придумали только в UCSD, на котором базировался Borland.
Что касается Питона, то основу его современной аудитории составляют люди, обучавшиеся программированию до его появления. Это просто удобный универсальный язык, который отчасти напоминает мне PL/I: множество возможностей, бессистемно придуманных для удобства программиста.
0xd34df00d
00.00.0000 00:00Ну вон для хаскеля запилили нейросети аж с проверкой размерностей слоёв в компилтайме, но почему-то это никому не нужно.


silent_net
00.00.0000 00:00Кто может скинуть рабочую ссылку на игру Colobot, просто все версии которые нашёл были с троянами.
vaniacer