
Привет! На связи Олег Казаков из Spectr. Мы занимаемся разработкой цифровых сервисов, в том числе высоконагруженных систем с микросервисной архитектурой и большим количеством различных интеграций. И в этой статье расскажем об одном из кейсов при работе над проектом с микросервисной архитектурой — реализации единой системы авторизации и аутентификации.
Теория. Виды архитектуры
Начнем с теории и рассмотрим наиболее популярные виды архитектур.
Монолитная архитектура
В нулевых годах появились первые языки веб-разработки (например, PHP), различные CMS и фреймворки (например, jQuery, который сейчас уже все ненавидят). И большинство проектов реализовывались именно в виде монолита.
Основная особенность монолитной архитектуры в том, что все, грубо говоря, находится «в куче»: интерфейс, бизнес-логика и слой доступа к данным.
Разберем признаки монолитной архитектуры подробнее и поговорим о ее преимуществах и недостатках.
Преимущества монолитной архитектуры
Быстрый старт. У CMS и фреймворков есть готовые решения, благодаря которым можно развернуть окружение буквально в пару минут и начать писать код.
Простота сопровождения. Нет необходимости администрировать инфраструктуру для большого количества микросервисов, т.к. все находится в одном месте.
Высокая производительность на старте разработки. По сравнению с производительностью микросервисной архитектуры, в которой большое количество микросервисов общается между собой, генерируя большую нагрузку на сеть и понижая общую производительность.
Недостатки монолитной архитектуры
Big ball of mud (или «большой комок грязи»). Казалось бы, в начале работы над проектом проблем нет: мы разворачиваем окружение и начинаем работать, но спустя время проект перерождается в большой комок грязи. Из-за чего это происходит? Такое происходит из-за давления бизнеса, текучки кадров, ограничений выбранного решения. Представим ситуацию: разработчик долго работает над проектом, бизнес-требования к которому очень высокие, поэтому он начинает работать быстрее, при этом какие-то моменты он упускает — например, документацию уже не пишет. Далее этот разработчик в какой-то момент увольняется, а на проекте к этому времени накопился технический долг. Приходит новый разработчик, который не понимает, что происходит на проекте, поэтому начинает писать свою логику. В результате — большой комок грязи.
Нет гибкости. Этот недостаток заключается в том, что со временем сложно обновлять стек. Допустим, если мы изначально развернули проект на какой-то определенной CMS или фреймворке, впоследствии его будет сложно поменять, так как с ним остается много зависимостей. Если нужно обновить что-то одно — придется обновлять все.
Большая связанность бэкенда и фронтенда. Когда jQuery еще был довольно популярным фреймворком, схема работы между бэкендом и фронтендом была примерно такой: верстальщик сверстал — бэкендеру нужно это интегрировать. И это все в одной куче. Далее пришли правки по фронту, фронтендер наверстал что-то еще и нужно это все интегрировать. И так каждый раз. То есть каждый раз новая итерация — бэкендер снова интегрирует, интегрирует, интегрирует...
И логика и представление на стороне бэкендера. Бэкендер вынужден сам отвечать за представление данных на фронтенде. Как следствие, бэкендерам приходится разбираться во фронте, а это им не нравится.
Сложность масштабирования. Если нужно что-то масштабировать, когда не хватает ресурсов, приходится масштабировать весь проект.
Для реализации проектов с монолитной архитектуры есть много популярных решений:
CMS (Bitrix, WordPress, Drupal, Django CMS)
Фреймворки (Laravel, Symfony, Django).
SPA (Single Page Application)
Вернемся к истории. В начале 10-х годов появились реактивные фреймворки, что, в свою очередь, подтолкнуло к развитию бэкенд-фреймворков. Бэкенд-фреймворки начали поставлять реактивные движки внутри себя, прямо «из коробки». А это дало возможность разрабатывать фронтенд независимо от бэкенда и отделять интерфейсы от бизнес-логики.

Преимущества SPA
Изоляция фронтенда и бэкенда. Т.к. фронтенд связан с бэкендом только по API, мы получаем возможность более гибко выстраивать процесс разработки: бэкендер занимается бэкендом, фротендер — фронтом и работа одного не блокирует работу другого.
Больше логики на фронтенде. Бэкенд не решает, какие блоки выводятся, он отвечает только за поставку необходимых данных.
Больше гибкости. Теперь можно, например, улучшить отдельную часть проекта, какую-то версию накатить на фронт, при этом бэк не будет страдать. К тому же, если говорить про развитие проекта, мы можем в какой-то момент начать разрабатывать новый фронт, пока работает старый, а потом переключить его. В то время как в монолите придется его заново интегрировать, а это вызывает сложности.
Микросервисная архитектура
Микросервисная архитектура — это некое развитие сервис-ориентированной архитектуры (SOA), направленное на взаимодействие небольших, слабо связанных и легко заменяемых модулей — микросервисов. Микросервис — это изолированная, слабосвязанная единица разработки, работающая над одной задачей.
Микросервисная архитектура получила развитие благодаря тому, что появились реактивные фреймворки, практики гибкой разработки и направление DevOps.
Разберем плюсы и минусы микросервисов.
Преимущества микросервисной архитектуры
Гибкость. Каждый микросервис можно развивать по отдельности, улучшать его и накатывать новые изменения. Главное — гарантировать, что при всех этих изменениях остается тот же самый интерфейс, что и был при общении с этим микросервисом. Либо, если он меняется, нужно согласовать это изменение с другими микросервисами.
Простота кода. У нас есть множество микросервисов, каждый из которых выполняет свою отдельную задачу, у них меньше кода, а соответственно, меньше зависимостей и легче с ними работать. Если разделить написание кода на команду разработки, каждый может заниматься отдельным микросервисом.
Свобода в выборе стека. Для реализации каждого микросервиса можно выбрать стек, который ему больше подходит.
Масштабируемость. Можно масштабировать не все сразу (как это было с монолитом), а каждый отдельный микросервис. Допустим, самые высоконагруженные микросервисы можно отдельно масштабировать от другой системы.
Независимость моделей данных. Часто в микросервисной архитектуре у каждого микросервиса своя база данных. БД независимы, мы можем их обновлять в любой момент — например, добавлять новые поля.
Недостаток микросервисной архитектуры
Медленный старт и сложность проектирования. Микросервисы, в отличие от монолита, нужно сначала развернуть, спроектировать, настроить, а это довольно сложно. Если не обдумать решение и, как с монолитом, пойти напролом, есть вероятность, что мы спроектируем неправильно. По итогу получится не микросервис, а распределенный монолит (когда есть много сервисов, но они между собой сильно связаны).

Увеличение времени отклика. Это связано с тем, что запросов в системе довольно много, так как микросервисы между собой общаются через HTTP.
Сложность сопровождения. Чем больше проект, тем больше его операционная сложность. Увеличивается роль CI/CD и DevOps. А если культура DevOps в компании развита плохо, то однозначно будут проблемы с микросервисной архитектурой.
Проблемы при взаимодействии между микросервисами. У нас есть общение клиента с микросервисами и есть общение между микросервисами (внутренняя API). За ней нужно следить, соблюдать интерфейс, обновлять его.
Необходимость поддержания согласованности. В случае с монолитом, если в нем нужно обновить сразу две сущности, мы пишем транзакцию, обновляем одну, обновляем другую, завершаем транзакцию. Если что-то получилось не так — откатываем транзакцию (при этом сохраняется консистентность и целостность БД). А в случае с микросервисом, если эти сущности раскиданы по двум сервисам, нам нужно обновить и тут, и там. А если что-то из этого не обновится, получится неконсистентность данных. Поэтому приходится придумывать какое-то решение, чтобы это обойти.
Один из частных случаев проблемы взаимодействия между микросервисами мы сегодня как раз и рассмотрим. Для этого погрузимся в один пример.
Аутентификация и авторизация в проекте с микросервисной архитектурой
Рассмотрим частный случай проблемы с авторизацией и аутентификацией на примере реализации проекта с видеокурсами.
Контекст. Проект, реализованный с использованием микросервисной архитектуры. Пользователи могут загружать свои курсы и уроки, а внутри уроков загружать видео; другие пользователи, в зависимости от их уровня доступа, могут их смотреть. Проект разбили на три микросервиса:
storage — хранилище видеоуроков. Отвечает за загрузку и хранение видео, их обработку, уменьшение битрейта видео;
courses — центральный микросервис. Отвечает за хранение самих курсов, их описание и ссылки на видео в storage;
subscription — микросервис, который управляет доступом по оплате. Например: пользователь оплатил подписку и теперь имеет неограниченный доступ ко всем видео, подписка заканчивается — пользователь видит только первые два урока.

Теперь нужно понять, как фронту взаимодействовать с этими тремя микросервисами. Начинается все с аутентификации — на этом этапе нужно понять, как и где ее делать. Есть несколько способов реализации.
Вариант 1. Аутентификация на каждом микросервисе
Аутентификация на каждом микросервисе. Реализация 1

Каждый микросервис имеет свою информацию про Users: пользователи, роли пользователей — копия одних и тех же данных. При том что в storage нет никакой базы данных, нам приходится реализовывать эту базу данных здесь, ожидая получения доступа к данным.
Проблемы этого решения
Синхронизация данных. При изменении пользователя на одном их микросервисов нам нужно дублировать изменения на все. Если сервисов будет много — это существенно усложнит весь процесс.
Storage — прикладной микросервис с отличным от courses и subscription, стеком. В этом случае бессмысленно реализовывать работу с БД. Мы не сможем переиспользовать наработки с других сервисов и придется разрабатывать с нуля.
Аутентификация на каждом микросервисе. Реализация 2
Выделение пользователей в отдельную БД.
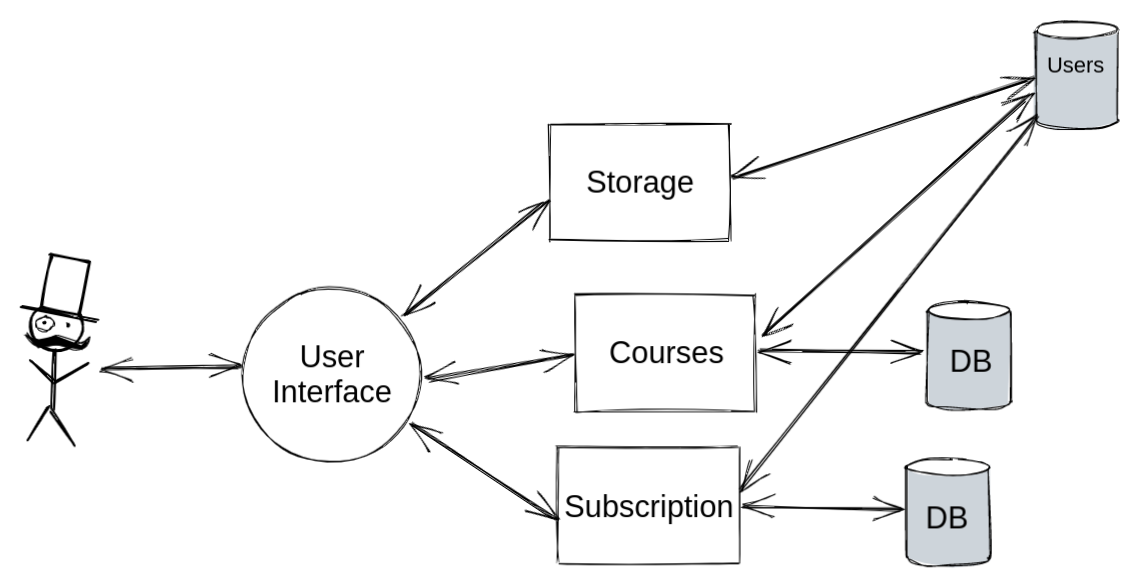
Так мы решаем проблему с синхронизацией — ее делать не нужно. Но в этом случае есть другие проблемы.
Проблемы этого решения
Нарушается принцип слабой связанности, т. к. все сервисы имеют доступ к одной БД Users. В итоге получается уже не очень микросервисно.
Проблема со storage никуда не уходит, нам все равно нужно работать с БД, что не очень удобно.
Вариант 2. Работа с пользователями в отдельном микросервисе
Добавляется новый микросервис Auth, который работает с таблицей Users, а другие микросервисы взаимодействуют с ним. По сути нам нужно каждый запрос (где требуется аутентификация) прогонять через данный сервис. В данном случае также есть несколько вариантов реализации взаимодействия с микросервисом Auth.
Работа с пользователями в отдельном микросервисе. Реализация 1

Делать дополнительные запросы к микросервису Auth.
Проблемы этого решения
Микросервисы не знают, какие роуты требуют аутентификации, а какие нет, и на каждый запрос нужно делать отдельный запрос в Auth, чтобы определить, есть ли доступ.
Нужно реализовывать логику взаимодействия с микросервисом Auth на все три микросервиса, при том, что стек разный.
Работа с пользователями в отдельном микросервисе. Реализация 2
Все запросы отправлять через Auth. В этом случае фронту станет легче, так как ему не нужно будет думать, на какой сервис отправить запрос. Есть документация API и все запросы идут на один и тот же домен.

Проблемы этого решения
Тратится лишнее время. Теперь все запросы проходят через Auth — и те, что требуют аутентификацию, и те, что не требуют, то есть на каждый запрос к бэку у нас дополнительный запрос. В целом это нормально, но т. к. это отдельный сервис со своей БД и неким ядром сервиса (например, какой-либо фреймворк), то при каждом запросе, не требующем аутентификации, происходит инициализация ядра, делаются какие-то проверки, а это все требует времени.
Вариант 3. Паттерн API Gateway
Это, пожалуй, самый правильный вариант реализации аутентификации в проекте с микросервисной архитектурой.
Что такое API Gateway?
Это микросервис, который является шлюзом между клиентом и другими микросервисами, он принимает запросы и проксирует их дальше. Бывают разные вариации API Gateway, нас интересует Gateway Routes — шлюз, который используется как обратный прокси, перенаправляющий запросы клиента на соответствующий сервис.
Каким должен быть API Gateway?
Во-первых, у него должна быть единая точка для работы фронта.
Во-вторых, за счет того, что это единая точка, мы скрываем реализацию бэкенда. Никто уже не знает, какая у нас структура микросервисов, а это плюс к безопасности.
В-третьих, API Gateway должен быть максимально быстрым, потому что все запросы идут через него.

В качестве API Gateway выберем Nginx — из-за его быстроты, доступности и многофункциональности. Теперь получается, что все запросы идут через него, а он их отправляет в нужные микросервисы. В конфигурации прописываем, на какие ресурсы нужен доступ пользователям, на каких не нужно проверять аутентификацию, какие запросы идут через Auth, а какие нет.
Как происходит аутентификация в этом случае?
Пользователь вводит логин и пароль → информация приходит на Nginx → Nginx видит путь api/v1/auth → отправляет эти же данные на Auth сервис → он проверяет пользователя, выдает токен → токен возвращается обратно.

Далее с этим токеном пользователь обращается к защищенным роутам → каждый запрос, который требует этого, мы прогоняем через Auth → проверяем токен → если все успешно — перенаправляем на любой из микросервисов.

Авторизация
Аутентификация учетных данных клиентов — важная задача, но этого недостаточно. Приложение должно также реализовать механизм авторизации, который проверяет, позволено ли клиенту выполнить запрошенную операцию. Как нам действовать в этом случае? Есть несколько вариантов.
Вариант 1. Авторизация на MS Auth
В этом случае микросервис сам решает, кому можно отправлять запрос, а кому нельзя. Вариантов здесь тоже два:
Авторизация на MS Auth. Реализация 1
Делаем от каждого MS запрос к MS Auth, чтобы проверить, есть ли доступ. Но здесь является проблемой то, что появляется еще один запрос.

Авторизация на MS Auth. Реализация 2
Определять на самом MS, можно ли обращаться к роуту. В этом случае у нас нет лишнего запроса, к тому же если у пользователя нет доступа, мы сразу можем реджектить — не отправлять MS. Но есть проблемы:
В этом случае нам нужно поддерживать логику авторизации на MS Auth. Иными словами, если что-то поменялось на одном MS, нужно это продублировать и на второй.
Если доступ к данным что-то разрешает или запрещает по определенному списку допусков, то возникнут проблемы, т. к. MS Auth может определить только по роуту, давать доступ или нет.

Вариант 2. Авторизация на ресурсных микросервисах
В этом случае ресурсные микросервисы сами решают, кому можно, а кому нельзя выдавать права. Как это можно сделать?
Использование JWT
JWT-токены позволяют передавать полезную нагрузку — некие данные от одного микросервиса к другому. И мы можем передать информацию: про роль, про самого пользователя и нам не нужно будет каждый раз делать запрос к микросервису авторизации, чтобы узнать, есть доступ или нет. Таким образом, информацию про роли мы можем хранить на каждом микросервисе. И мы получаем от микросервиса авторизации информацию по пользователю и его роли. Как устроен сам токен? Мы передаем, в данном случае:
заголовок — информация про алгоритм шифрования;
полезную нагрузку — данные, которые хотим передать от одного MS к другому;
сигнатуру — то, за счет чего обеспечивается безопасность (информация шифруется через секретный ключ, который известен всем MS, которые участвуют в этой цепочке).

Главный минус JWT-токена заключается в том, что он автономен, если мы выдали JWT, мы его не можем отозвать, а это влияет на безопасность. Чтобы эту проблему обойти, обычно занижают время жизни токена до минимального. Тогда злоумышленникам сложнее будет использовать этот токен, но при этом пользователям будет не очень удобно пользоваться.
OAuth 2.0
OAuth 2.0 выдает два вида токенов: access (тот же самый токен) и refresh (используется для обновления access). Access имеет короткий период жизни, а refresh — длинный (допустим, месяц), в этом случае через refresh можно обновлять access.

Итоги
Простой пример реализации аутентификации и авторизации представлен на GitLab: https://gitlab.com/devtalks-api-gateway. В репозитории:
Проект с тремя микросервисами: MS Courses, Auth-сервис и API Gateway.
Работа реализована на Docker. Можно развернуть один из репозиториев: API Gateway и следовать инструкции в Readme (в корне есть Makefile).
Config на Nginx, который проверяет нужные роуты на доступ, а другие роуты пропускает напрямую. То есть если нам нужна проверка аутентификации, происходит подзапрос к MS-авторизации, далее поступает ответ, и если он успешный, происходит запрос прокси на нужный MS.
Для микросервиса авторизации и микросервиса Courses используется Laravel.
Для MS Auth использован Laravel Passport (для работы c AUTH-сервисом).
Статья подготовлена по мотивам доклада Олега Казакова (CTO в Spectr) на митапе #DevTalks. Ссылка на запись доклада.
Комментарии (7)

anador
00.00.0000 00:00+1По данной теме могу порекомендовать следующую статью: https://cheatsheetseries.owasp.org/cheatsheets/Microservices_security.html (не смотрите, что OWASP, там не только про безопасность)

mozg3000tm
00.00.0000 00:00По моему, чтобы проверить подпись jwt достаточно публичного ключа, в случае асимметричной подписи. Тогда на все сервисах можно хранить только публичный ключ, а не приватный. Если же подпись симметричная, то да везде нужно хранить секретный ключ.

mark_ablov
00.00.0000 00:00+1Норм. Сложности появляются когда у вас несколько auth провайдеров и JWT может содержать разные identity.
PS: у нас в качестве api gateway используется простой прокси на node.js, что позволяет более гибко работать с маршрутизацией (в частности, храним маршруты в базе, а не перезаливаем конфиги nginx'a).

tempart
00.00.0000 00:00Треть статьи - введение в различия между двумя основными архитектурными стилями. Наверное, автор хочет плавно подвести нас к теме статьи? Но нет, в 100501 изложении монолита не видно ни слова про тему статьи. Подразумевается, но не сказано.
Описание AA в каждом пункте. "Мы", "нам" - кто эти загадочные звери?
Что мешает указывать конкретные сущности (группы сущностей), которые выполняют это действие?И самый интересный пункт, OAuth 2.0, внезапно всего три строчки. И это всё?!
Только собрался спросить, раз "через refresh можно", значит, необязательно?, и кто решает, можно или нет и т.п., как статья резко закончилась.
В общем, я не понял ни смысл статьи, ни части её содержания. И даже завидую тем, кому она показалась лучшей
PolkovnikovNikita
Лучшая статья по теме из тех что я видел
mozg3000tm
А мне нравится эта статья.