
Скачать (загрузить) с сервера блог-платформы «LiveJournal» (по-русски «ЖЖ» или «Живой Журнал») посты своего журнала (блога) на свой компьютер можно разными способами. В этой статье я буду рассматривать только способ загрузки постов с помощью клиент-серверного протокола ЖЖ (по-английски «Client/Server Protocol» или сокращенно «CSP»), посредством отправки HTTP(S)-запросов и получения HTTP(S)-ответов. Клиент-серверный протокол ЖЖ предусматривает несколько разных интерфейсов, я использую интерфейс «flat». Для практической реализации клиентской части (скрипта) я использую язык «PowerShell» в одноименной программе-оболочке версии 7. Скрипт будет описан ближе к концу статьи, там же будет ссылка на его исходный код.
Меня интересовала именно задача скачивания всех постов определенного журнала, постов, которые есть в указанном журнале на момент запуска скрипта. Но, думаю, информация, изложенная в данной статье, будет полезна и тем, кто решает задачу скачивания отдельных постов журнала или задачу синхронизации локальной копии журнала на своем компьютере с оригиналом журнала на сервере ЖЖ.
Удалённая функция «getevents»
Для скачивания постов журнала в наборе удалённых функций ЖЖ предназначена функция «getevents». (В документации клиент-серверного протокола ЖЖ вместо слова «function» используется слово «mode», но мне привычнее называть эту сущность «функцией».)
Удалённая функция «getevents» может работать четырьмя разными способами, которые отличаются друг от друга типом отбора (входной параметр «selecttype») скачиваемых постов. Во входном параметре «selecttype» вы можете указать одно из четырех значений: «day», «lastn», «one» или «syncitems». При этом каждый из этих четырех способов требует разных дополнительных входных параметров с нужной для этих способов дополнительной информацией.
Когда я только начал читать документацию клиент-серверного протокола ЖЖ, то не мог понять, где же простой способ скачивания всех постов, где же удалённая функция, которой можно всего лишь указать название журнала и получить в ответ все посты этого журнала? В итоге выяснилось, что такого простого способа скачать сразу все посты нужного журнала в клиент-серверном протоколе ЖЖ нет. Я думаю, что так это и задумывалось разработчиками. Удалённая функция «getevents» может вернуть все посты журнала, но только не за один раз, а несколькими порциями (если в журнале небольшое количество постов, то их таки можно получить одной порцией).
Предполагаю, что такое решение (порционная выдача постов журнала) даёт возможность администратору ЖЖ регулировать нагрузку на сервер ЖЖ: размер порции можно уменьшить или увеличить вручную, либо можно создать механизм автоматической регулировки размера порции в зависимости от нагрузки на сервер ЖЖ.
Итак, значение «day» входного параметра «selecttype» позволяет скачать все посты журнала, опубликованные в определенный день (информация о дате при этом указывается в дополнительных входных параметрах «year», «month» и «day»).
Значение «lastn» входного параметра «selecttype» позволяет скачать указанное в дополнительном входном параметре «howmany» количество самых последних (самых свежих) постов в журнале. По умолчанию (если дополнительный параметр «howmany» не указан) будет скачано 20 самых последних постов. Максимально возможное число постов, которое можно скачать этим способом — 50 самых последних постов. Это ограничение указано в документации. Предполагается, что этот способ будет использоваться, если пользователь хочет поработать в своем веб-клиенте с самыми свежими постами своего журнала (просмотреть их или отредактировать).
Впрочем, с помощью дополнительного входного параметра «beforedate» можно регулировать, какую именно группу постов вы получите этим способом: указав во входном параметре «beforedate» дату и время, вы получите указанное количество постов до этих даты и времени (тут имеются в виду дата и время, указываемые пользователем при создании или редактировании поста в журнале).
Значение «one» входного параметра «selecttype» позволяет скачать один пост журнала, идентификатор которого указан в дополнительном входном параметре «itemid». (Я демонстрировал этот способ на практическом примере в отдельной статье про способы аутентификации при использовании клиент-серверного протокола ЖЖ.)
Значение «syncitems» параметра «selecttype»
Значение «syncitems» входного параметра «selecttype» удалённой функции «getevents» позволяет скачать некоторое количество постов журнала (порцию), созданных или измененных после определенной даты, указанной в дополнительном входном параметре «lastsync». Предполагается, что этот способ будет использоваться для выполнения синхронизации оригинала журнала на сервере ЖЖ с копией журнала на компьютере пользователя. Если дополнительный входной параметр «lastsync» не указывать, то будут возвращены посты, начиная с самых старых. Количество возвращаемых при этом способе постов определяется сервером ЖЖ (вероятно, это количество могут менять). На данный момент это количество равно 100 постам.
Этот способ самый эффективный из четырех перечисленных для решения задачи скачивания всех постов нужного журнала. Скажем, если имеется журнал, содержащий 100 постов, и автор журнала писал один пост ежедневно, то при способе «day» для скачивания всех постов нужно будет выполнить 100 HTTP(S)-запросов, при способе «lastn» понадобится 2 HTTP(S)-запроса, при способе «one» тоже понадобится 100 HTTP(S)-запросов, а вот при способе «syncitems» понадобится только один HTTP(S)-запрос (без учета HTTP(S)-запросов для аутентификации).
Из-за эффективности именно способ «syncitems» рекомендуется в документации для решения задачи скачивания всех постов определенного журнала. Это логично, ведь задачу скачивания всех постов журнала можно считать крайним частным случаем синхронизации оригинала журнала на сервере ЖЖ с копией журнала на компьютере клиента (пользователя).
Конкретно этот способ рекомендуется, в том числе, в главе «Downloading Entries» (по-русски «Скачивание постов») документации. Эта глава была одним из главных источников информации при написании данной статьи, но далеко не единственным. Кстати, по указанной ссылке не сказано, но текст этой главы практически без изменений был взят из поста в ЖЖ 2004 года пользователя Марка Смита. При написании своего скрипта для скачивания всех постов нужного журнала я ориентировался на псевдокод, предложенный Марком Смитом, в который внес некоторые изменения.
Как устроена выдача постов и синхронизация в ЖЖ
Можно было бы сразу перейти к практической реализации вышеупомянутого алгоритма скачивания всех постов определенного журнала, но этот алгоритм будет непонятен (хотя для реализации алгоритма в коде его понимание, в принципе, не требуется, но лично я предпочитаю сначала понять, а потом кодить), если вы не представляете (хотя бы примерно), как устроено хранение и выдача по запросу постов журнала в ЖЖ и как устроен процесс синхронизации оригинала журнала на сервере ЖЖ с локальной копией журнала на компьютере пользователя.
Я не знаю, как ЖЖ устроен на самом деле, как хранятся данные, в какой СУБД (системе управления базами данных) и тому подобное. Тем более, что открытым исходный код ЖЖ был только первые 15 лет своего существования (с 1999 года), все известные его форки (ответвления кодовой базы), вроде «Dreamwidth» и тому подобных, были созданы в этот период. Вскоре после того, как компания «SUP Media» в 2013 году вошла в группу компаний «Rambler&Co», код ЖЖ окончательно закрыли. Это случилось примерно в начале 2014 года. Я буду рассматривать «устройство» ЖЖ в том виде, в котором оно представляется, если смотреть сквозь призму клиент-серверного протокола ЖЖ.
Мы получаем по клиент-серверному протоколу ЖЖ по интерфейсу «flat» посты журнала в виде многострочной строки (multiline string) в теле ряда HTTP(S)-ответов (порции постов). Эту многострочную строку я преобразую в хеш-таблицу, содержащую множество выходных параметров, как и рекомендовано в документации. Далее из полученной хеш-таблицы я формирую таблицу постов журнала. В этой таблице каждая строка представляет отдельный пост журнала. Вот как выглядят открытые (общедоступные) посты журнала в этой таблице (это упрощенное представление, для постов с ограниченным доступом есть дополнительные поля, тут не показанные; кроме того, здесь не показаны свойства постов, по-английски «props»), пример из практики:
num itemid anum eventtime subject url event
--- ------ ---- --------- ------- --- -----
1 2 140 2010-10-16 19:53:00 Осень на улицах 652.html %D0%9B%D0%B5%D0…
2 3 240 2010-10-17 15:05:00 Траншея на авто… 1008.html %D0%96%D0%B5%D0…
3 4 108 2010-10-18 22:37:00 Режим работы сб… 1132.html %D0%9B%D0%B5%D0…
4 5 131 2010-10-20 00:21:00 Квартирный вопр… 1411.html %D0%9C%D0%B5%D0…
5 6 166 2010-10-22 00:29:00 Налоговая инспе… 1702.html %D0%A3%D0%BB%D0…В блоке кода выше показаны только первые 5 строк полной таблицы с постами журнала. Содержимое выходных параметров «subject» (название поста) и «event» (текст поста) сокращено, чтобы получить таблицу постов в компактном виде, удобном для формата статьи (не поместившаяся в ячейку часть содержимого обозначена многоточием). Содержимое выходного параметра «url» на самом деле содержит полный постоянный URL-адрес поста, но я оставил только концовку каждого постоянного URL-адреса, чтобы содержимое этих параметров влезло в формат статьи. Текст поста, как видно из блока кода выше, дополнительно закодирован с помощью процентной кодировки. Для получения исходного текста поста можно применить метод «UrlDecode» класса «System.Web.HttpUtility» платформы «.NET».
Идентификаторы постов (содержатся в выходном параметре «itemid») представляют собой обычное положительное целое число и присваиваются новым постам с увеличением предыдущего идентификатора на единицу. Нумерация постов в каждом журнале ведется, начиная с единицы. Если автор журнала создал, а потом по какой-то причине удалил некий пост, то использованный для такого поста идентификатор не присваивается следующим постам. Таким образом, в нумерации постов образуются «прорехи». Вследствие чего, к примеру, если автор журнала создал 149 постов всего, 2 из которых в какой-то момент удалил (например, с идентификаторами 1 и 69), то в журнале содержится 147 постов всего, а идентификаторы последних двух постов — 148 и 149 (ситуация из практики). При этом клиент, не зная «внутренней кухни», может удивляться, почему у 147-го поста в журнале внезапно идентификатор поста — 149.
В таблице, показанной в блоке кода выше, строки с постами отсортированы по идентификатору поста (по колонке «itemid»), я это сделал уже после получения постов. Однако, получаем мы их в порядке модификации постов (дата первоначального создания поста или дата изменения поста, если автор журнала вносил в пост изменения после его создания). Очевидно, что порядок идентификаторов постов и порядок модификации постов может не совпадать (например, в случае внесения изменения в какой-то старый пост).
На первый взгляд задача порционного получения всех постов журнала не выглядит слишком сложной. В алгоритме решения этой задачи нам понадобится анализировать идентификаторы постов и дату модификации каждого поста. Вот же, в таблице содержатся нужные выходные параметры «itemid» (идентификатор поста) и «eventtime» (дата и время поста). Однако, дата и время поста, которые содержатся в выходном параметре «eventtime», не являются датой и временем модификации поста! При создании или изменении поста вы можете менять дату и время в поле «eventtime», как вам, автору поста, захочется. С помощью этой даты вы можете произвести «отложенную» публикацию поста, указав будущие дату и время. Либо автор журнала может создать несколько «закрепленных» постов в начале своего блога, изменив дату и время какого-либо поста на будущие дату и время.
Таким образом, вы можете получить первые самые старые (по дате модификации) 100 постов с помощью удалённой функции «getevents», выбрав для входного параметра «selecttype» значение «syncitems» и не указывая дополнительный параметр «lastsync». Но для получения следующей порции постов вы должны уже будете указать дополнительный параметр «lastsync», а у вас для него нет значения, так как содержимое выходного параметра «eventtime» для этого не подходит по описанной выше причине.
Таблица записей об обновлениях журнала
Дата и время, указанные в выходном параметре «eventtime», возвращаемом удалённой функцией «getevents» при описанной выше настройке, не подходит для синхронизации оригинала журнала на сервере ЖЖ и вашей локальной копии журнала на вашем компьютере еще и потому, что автор журнала может внести изменение в какой-либо свой старый пост, не изменив дату и время «eventtime».
Недоступная для изменения автором журнала дата модификации поста (дата его создания или последнего изменения), автоматически назначаемая программой-сервером ЖЖ, существует, но она хранится не в таблице с постами, а в отдельной таблице с записями об обновлениях журнала. Если посты мы можем получить с помощью удалённой функции «getevents», описанной выше, то таблицу об изменениях в журнале мы можем получить с помощью другой, отдельной, удалённой функции «syncitems» (не путать с описанным выше значением «syncitems» входного параметра «selecttype» удаленной функции «getevents»).
Содержимое таблицы об обновлениях журнала мы тоже получаем не сразу целиком, а тоже порционно. Только для этой таблицы ЖЖ определяет максимальный размер порции на данный момент в 500 записей, а не в 100 постов, как для удалённой функции «getevents». Думаю, такое увеличение размера порции продиктовано тем, что размер записей об обновлениях журнала на порядок меньше размера постов журнала. Вот пример таблицы с записями об обновлениях журнала, пример из практики:
num item itemT itemN action time
--- ---- ----- ----- ------ ----
95 L-78 L 78 update 2011-08-26 15:38:36
193 C-148 C 148 update 2023-02-04 14:45:59
115 C-34 C 34 update 2012-02-10 09:40:07
72 L-60 L 60 create 2011-06-03 19:45:37
167 L-135 L 135 create 2013-11-16 13:20:49На самом деле, удалённая функция «syncitems» возвращает только выходные параметры «item», «action» и «time». Колонки «itemT» и «itemN» я создал дополнительно из колонки «item». Выходной параметр «item» содержит идентификатор записи об обновлении журнала. Этот идентификатор состоит из двух частей, разделенных символом дефиса: тип записи об обновлении журнала и идентификатор модифицированного поста. Таким образом, таблица об обновлениях журнала и таблица постов связаны между собой по значениям в колонках «itemN» и «itemid» соответственно.
В качестве типа записи об обновлении журнала на данный момент используются только буквы «L» (сокращение от слова «log», которое обозначает пост журнала) и «C» (сокращение от слова «comment», которое обозначает комментарий к посту журнала).
Для каждого поста журнала в таблице записей об обновлениях журнала может быть только одна запись с типом «L» и одна запись с типом «C» (если к данному посту есть комментарии). Таким образом, записей об обновлениях журнала обычно больше количества постов на количество записей об обновлениях журнала, касающихся комментариев к постам, то есть с типом «C». Например, всего постов в журнале может быть 147, а число записей об обновлениях журнала всего 193 (пример из практики), в том числе 147 записей об обновлениях журнала типа «L» и 46 записей об обновлениях журнала типа «C».
В вышеприведенной таблице поле «action» является малополезным, так как в ЖЖ хранится только последняя версия поста, поэтому не имеет значения, когда появилась эта версия поста — при его создании или при его последнем изменении. Главное — это поля «item» и «time». Как раз в выходном параметре «time» и содержатся нужные нам для получения постов (для входного параметра «lastsync» удалённой функции «getevents») дата и время модификации поста (дата создания поста или дата последнего изменения поста).
Алгоритм скачивания всех постов журнала
Учитывая всё вышеизложенное, можно описать сокращенную версию псевдокода, предлагаемого в уже упоминавшейся ранее главе «Downloading Entries» документации:
скачать в цикле порциями таблицу записей об обновлениях журнала
оставить в таблице записей об обновлениях журнала только записи с типом «L»
скачать в цикле порциями все посты журнала,
ориентируясь на таблицу записей об обновлениях журнала, полученную ранееНу или вот попытка (тут подробнее) полного перевода псевдокода из вышеуказанной главы документации на русский язык (я внес изменение от себя во втором цикле):
отправить запрос на запуск функции «syncitems» без входного параметра «lastsync»
получить из ответа список записей об обновлениях журнала и число «sync_total»
while (размер_списка < sync_total) {
найти новейшее время в списке
отправить запрос на запуск «syncitems» с «lastsync», равным новейшему времени
добавить записи об обновлениях журнала из ответа в список
}
оставить в списке только записи об обновлениях журнала, касающиеся постов
(идентификаторы таких записей начинаются на букву «L»)
добавить к списку записей об обновлениях колонку «downloaded» со значением 0
(в итоге в списке каждая запись содержит поля «itemid», «time», «downloaded»)
while (в списке есть записи с полем «downloaded», равным 0) {
отправить запрос на запуск функции «getevents» с «selecttype», равным «syncitems»
(в первой итерации — без «lastsync», далее для «lastsync» вычисляем время)
получить из ответа посты и сохранить их в какое-либо хранилище (на диске и т.п.)
пометить в списке полученные посты (в поле «downloaded» присвоить 1)
найти в списке новейшее время у полученных постов (для «lastsync»)
}Практическая реализация: скрипт «Get-LiveJournal»
Я написал практическую реализацию описанного выше алгоритма скачивания всех постов определенного журнала на языке «PowerShell» и успешно опробовал ее на двух моих журналах в ЖЖ. Скрипт называется «Get-LiveJournal», его код можно посмотреть на веб-сервисе «GitHub».
Вот иллюстрация работы этого скрипта (в данном случае использовались программа-оболочка «PowerShell» версии 7.3.3 и программа-«эмулятор терминала» «Windows Terminal» версии 1.17):
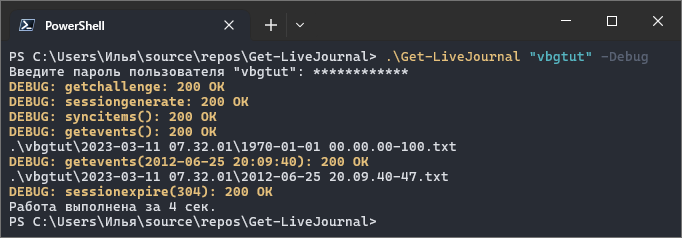
В этой реализации много чего интересного, но в данной статье я хотел бы отметить только четыре момента.
Первое. Для представления таблицы постов и таблицы записей об обновлении журнала я использовал структуру данных в виде коллекции объектов класса «System.Management.Automation.PSCustomObject». В качестве коллекции я использовал либо обычный массив объектов (тип System.Object[], производный класс от базового класса «System.Array»), если было достаточно неизменяемого (по-английски «immutable») массива, либо класс «System.Collections.ArrayList», если требовалось выполнять множество операций по добавлению элементов в массив.
Возможно, такая структура данных не самая эффективная в данном случае, но она удобна при отладке, если нужно вывести содержимое получаемых от сервера ЖЖ таблиц в окно программы-оболочки в виде таблицы (как показано в примерах выше) с помощью командлета «Format-Table», который позволяет настроить ширину колонок, выравнивание данных в колонках, названия колонок и так далее. Кроме этого, коллекцией объектов (где каждый объект представляет строку таблицы) в программе-оболочке «PowerShell» легко манипулировать, для этого существует масса командлетов вроде «Sort-Object» (сортировка строк таблицы), «Where-Object» (фильтр строк таблицы), «ForEach-Object» (обработка строк таблицы) и других.
Например, второй этап показанного выше сокращенного псевдокода алгоритма скачивания всех постов журнала (отбор в таблице записей об обновлении журнала только записей, касающихся постов) можно реализовать всего лишь одной командой:
$tableSL = $tableS | Where-Object { $_.itemT -eq "L" }В блоке кода выше в переменной $tableS содержится полная таблица записей об обновлении журнала, а в переменной $tableSL — такая же таблица, но содержащая только строки, касающиеся только обновления постов журнала, то есть с типом «L».
Второе. Для аутентификации я использовал создание сессии и работу в рамках сессии с помощью значения-«cookie», сгенерированного сервером ЖЖ. Я подробно описывал все три способа аутентификации при работе по клиент-серверному протоколу ЖЖ в отдельной статье. Способ аутентификации «clear» не рекомендуется документацией из соображений безопасности, а способ аутентификации «challenge-response» в данном случае неэффективен, так как значение «challenge» является разовым, то есть может использоваться только для одного вызова удалённой функции «getevents» или удалённой функции «syncitems», а нам, как видно из псевдокода алгоритма, изложенного выше, требуется выполнять серии таких вызовов в двух циклах.
Третье. Напомню, что по правилам ЖЖ для роботов скрипты должны работать в рамках определенных ограничений. Например, не следует делать ботов многопоточными и боты не должны создавать чрезмерную нагрузку на сервер ЖЖ. Бот, нарушающий правила ЖЖ, может быть заблокирован. В частности, скрипт не должен устанавливать более 5 соединений в секунду.
Про последнее ограничение отмечу, что при работе по клиент-серверному протоколу сервер ЖЖ пользуется протоколом HTTP версии 1.1. А именно, используется так называемое «постоянное соединение» (по-английски «persistent connection»), в рамках которого вы можете выполнить столько HTTP(S)-запросов, сколько вам понадобится (что я и делаю в скрипте). Пары HTTP(S)-запросов/ответов выполняются последовательно, одна за другой. Единственное условие — разрыв (timeout) между парами HTTP(S)-запросов/ответов не должен превышать 50 секунд (иначе TCP-соединение прервется и следующие пары HTTP(S)-запросов/ответов придется выполнять в рамках другого TCP-соединения), это оговорено в заголовках HTTP(S)-ответов от сервера ЖЖ:
...
Connection: keep-alive
Keep-Alive: timeout=50
...Пользуясь этим «постоянным соединением», удается всю работу скрипта уместить в одно-единственное TCP-соединение.
Четвертое. Как видно из иллюстрации, показанной выше, скрипт сохраняет полученные от сервера ЖЖ в телах HTTP(S)-ответов посты в текстовые файлы. Полученное сохраняется в том виде, в котором пришло от сервера ЖЖ. При этом в текущей папке создается следующая структура папок и файлов (пример из практики):
.\Get-LiveJournal.ps1
.\vbgtut\
2023-03-11 07.32.01\
1970-01-01 00.00.00-100.txt
2012-06-25 20.09.40-47.txt
2023-03-17 13.53.33\
...
.\ilyachalov\
...При очередном вызове скрипта на верхнем уровне создается папка для указанного журнала (пользователя ЖЖ), если такой папки еще нет. У меня два журнала, для которых скрипт создал две папки — «vbgtut» и «ilyachalov». Внутри папки журнала (пользователя ЖЖ) для каждого нового вызова скрипта для данного журнала создается отдельная папка, в названии которой записываются текущие дата и время моего компьютера. В блоке кода выше видно, что для пользователя «vbgtut» я запускал скрипт дважды. В качестве разделителя часов, минут и секунд используется символ точки вместо общепринятого символа двоеточия, так как в названиях файлов в операционных системах «Windows» символ двоеточия запрещен (я работаю в операционной системе «Windows 10»).
Как видно из блока кода выше, при запуске скрипта 11 марта он получил от сервера ЖЖ две порции постов, каждую из которых сохранил в отдельном текстовом файле. В названии каждого текстового файла записывается значение входного параметра «lastsync», по которому была получена данная порция постов, и через дефис — количество постов, полученных в этой порции постов. Как видно из блока кода выше, скрипт получил 11 марта в первой порции 100 постов, во второй порции — 47 постов (в данном журнале всего 147 постов).
Заключение
Скрипт «Get-LiveJournal» не является готовым продуктом. Это всего лишь пример реализации алгоритма скачивания всех постов журнала, предложенного в документации клиент-серверного протокола ЖЖ. Да, вы получите все посты указанного журнала из ЖЖ, но полученные текстовые файлы малопригодны для просмотра полученных постов журнала локально на своем компьютере.
Полученные текстовые файлы можно использовать для сохранения журнала из ЖЖ у себя на компьютере на случай внезапной смерти этого веб-сервиса. Но если это произойдет, для восстановления журнала из хранящихся текстовых файлов понадобится написать какой-нибудь дополнительный скрипт, который поместит данные в СУБД какой-либо системы управления содержимым (CMS), самописной или любой, присутствующей на рынке, вроде «WordPress» или другой тому подобной. (С другой стороны, у других систем управления содержимым могут уже существовать свои инструменты для импорта постов из ЖЖ. У «WordPress», к примеру, такой инструмент есть, но я не знаю, насколько хорошо он работает, так как мне не приходилось его использовать.)
Комментарии (10)

red_dragon
00.00.0000 00:00Интересно, считал, что пациент скорее мёртв, чем жив. А оказывается, есть ещё пользователи.

ilyachalov Автор
00.00.0000 00:00У ЖЖ есть свои плюсы. Например, посты быстро попадают как в результаты поиска в Google, так и в результаты поиска в Яндексе. У ЖЖ, на мой взгляд, только один серьезный минус - там довольно много рекламы от сервиса. Кроме того, вот все говорят о том, что ЖЖ умер, а хорошей альтернативы ему найти не получается (если не считать соц.сети типа Телеги, ВК и т.д., в которые мне пока что неинтересно). Если вы знаете альтернативу, посоветуйте. (Все показывают на Medium, но там никто не читает русские тексты.)

shuhray
00.00.0000 00:00Альтернатива какого рода? ЖЖ хорош, чтобы поговорить. Кое-где там оживлённые места (например, в блоге ivanov-petrov). Если хотите поговорить, лучше ЖЖ ничего нет. Если же выкладывать фото и получать лайки, тогда другое дело.
ilyachalov Автор
00.00.0000 00:00Поговорить я могу где угодно, хоть в ЖЖ, хоть на любом сервисе, где есть комментарии. С этим нет проблем. Выкладывать фото и получать лайки можно хоть в ЖЖ, хоть в других местах, тоже нет проблем. Нужен сервис для публикации лонгридов (длинных текстов с картинками или без), с возможностью комментариев, с быстрой индексацией в поисковых системах, надежный, с наличием API для сторонних веб-клиентов (это всё есть в ЖЖ). Плюсом (чего нет в ЖЖ) хотелось бы системы управления версиями, возможности быстрой выгрузки полного архива блога, удобных блоков для вставки фрагментов кода в статью (настраиваемая подсветка кода, номера строк, подсветка кода для популярных языков программирования и т.п.), возможность вставки в статью математических формул.
shuhray
00.00.0000 00:00Ну, всё сразу не могу, но знакомые математики сейчас собираются на сайте
ilyachalov Автор
00.00.0000 00:00Непохоже, что там удобно размещать лонгриды, люди пишут небольшие посты. Но всё равно спасибо за совет, я не знал про этот сервис. Как я понял, там должно быть удобно использовать математические формулы.

bnzs1
00.00.0000 00:00было бы удобно если бы у вас ilyachalov в README.md появился "обычный" пункт how to install/use потому, что не все (я к примеру) способны "это" запустить.
У меня к примеру такой https://i.imgur.com/a7Fkysg.jpg результатp.s. когда то кто то уже делал(возможно вам как автору будут интересны чужие реализации) подобное https://github.com/ati/ljsm но "там" было удобней потому, что было уже собрано в бинарик...
ilyachalov Автор
00.00.0000 00:00Я в конце статьи специально написал, что этот скрипт не является готовым продуктом. То, что вы предлагаете, является частью продвижения готовой программы. Скрипт написан для тех, кто хочет разобраться с программной точки зрения как работает API ЖЖ, и для тех, кто изучает язык PowerShell. Скрипт не предназначен для широкого распространения.
Если хотите, я могу помочь вам разобраться в том, как запустить этот скрипт. Напишите мне на GitHub в Issues этого репозитория, там будет удобнее. Вообще, судя по вашему снимку экрана, думаю, PowerShell просто не нашел в текущей папке указанный скрипт. Возможно, дело в том, что вы задали неправильное имя файла скрипта:
get-livejournal.ps1-livejournal.ps1. Какое-то оно у вас странное. Скрипт называется простоget-livejournal.ps1, расширение при запуске указывать необязательно.Спасибо за ссылку на другую реализацию. Я знаю десятки реализаций (начиная с той, на которую есть ссылка из документации), причем некоторые из них гораздо удобнее для конечного пользователя. Но эта реализация на языке Perl, я его не изучал.
{kind=link}
shuhray
На dreamwidth раньше можно было копировать ЖЖ (кроме встроенного видео), но давно не копировал.
ilyachalov Автор
Да, я читал об этом. На блог-платформе teletype.in тоже есть инструмент для этого. Но я им не пользовался, поэтому не могу его оценить. Вообще, я хотел поработать с teletype.in, но оказалось, что у них, к сожалению, нет API для сторонних веб-клиентов.