
Мне понадобилось провести несколько вводных уроков по языку программирования C++. В интернете есть много разнообразных учебных пособий для начинающих. Но почти во всех из них символьные и строковые литералы в примерах и упражнениях даются на английском языке, начиная со знаменитой первой программы «Hello, world!».
Насколько я понимаю, действующий стандарт языка C++ (ISO/IEC 14882:2020) определяет для исходного кода (текста) программы базовый набор возможных символов (basic source character set) в количестве 96 штук (в том числе буквы латиницы), в который можно добавлять дополнительные символы из набора символов Юникода с помощью специальной нотации (universal character name). Например, символ ???? (U+1F60E) не входит в 96 символов базового набора, но я могу его добавить в исходный код программы с помощью последовательности \U0001F60E.
Таким образом, по идее, ничего не мешает нам использовать в исходном коде программы буквы русского алфавита или буквы алфавитов других языков. Почему авторы руководств для начинающих (в том числе — большинства русскоязычных) по языку C++ этого не делают — для меня загадка. Я пытался задать этот вопрос на известном сайте вопросов и ответов по программированию «Stack Overflow», но мой вопрос удалили, так как сайт «Stack Overflow» не принимает вопросы, на которые нельзя дать четкий ответ. То есть вопросы, на которые можно ответить с разных точек зрения по-разному, вызывающие дискуссии, там запрещены.
Всё же до удаления моего вопроса я успел получить несколько мнений по этому поводу. Цитата 1: «Because for beginners they have zero relevance. What would outputting Привет, мир instead of Hello, world add to the knowledge of C++?» Я думаю, что, как минимум, русскоязычному ученику было бы удобнее и интереснее (это важно!) писать первые программы, выводящие сообщения на русском языке и, к примеру, с эмодзи. Особенно, если речь идет об обучении детей. При этом я не имею ничего против английского языка, я люблю английский язык, на нем написано много полезной литературы по программированию.
Цитата 2: «because dealing with character encodings is an intermediate/advanced/complex topic, not well-suited for beginners. They have enough to deal with just focusing on the complexities of the standard language and its base features». Тут я соглашусь только частично. На мой взгляд, язык C++ — это изначально язык программирования, приближенный к «железу». Некоторые авторы даже относят C++ не к высокоуровневым языкам, а к языкам среднего уровня. То есть, по моему мнению, ученик изначально должен получить представление о хранении данных, особенно текстов, на компьютере. Текст (в том числе исходный код программы) всегда хранится в какой-то кодировке. Поэтому обучение языку C++ должно начинаться с кодировок текста, или хотя бы с одной кодировки, UTF-8.
Файлы с исходным кодом, кодировка и другие особенности
На сегодняшний день для текстовых файлов стандартом по факту стала кодировка UTF-8, одна из реализаций таблицы Юникода. Мне кажется очевидным, что начинающих изучать язык C++ следует учить писать тексты программ в этой кодировке, независимо от операционной системы. По этой теме есть отличный манифест — «UTF-8 Everywhere».
Еще при написании исходного кода примеров и упражнений для начинающих, думаю, имеет смысл стараться сохранять кроссплатформенность исходного кода, хотя бы для операционных систем «Windows» и «Linux». Современные редакторы кода и компиляторы облегчают эту задачу: они умеют работать с окончаниями строк разных видов (CRLF или LF), с кодировкой UTF-8 (с меткой BOM или без нее) и так далее.
Компилятор и другие инструменты
В принципе, для начального обучения языку C++ можно использовать веб-компиляторы, для работы с которыми нужен только доступ в интернет и браузер. Их довольно много, я приведу для примера несколько первых попавшихся мне в поисковой системе: OnlineGDB.com, Cpp.sh, Online-Cpp.com и так далее.
Однако, я хочу, чтобы сразу была видна работа с компилятором, компоновщиком, их ключами, как из интегрированной среды разработки, так и из командной строки. По идее, нужно сразу дать понять, что язык C++ — это компилируемый язык программирования. Поэтому мне удобнее для обучения использовать программы-инструменты на настольном компьютере, а не веб-приложения.
Вообще, хотелось бы размахнуться на работу сразу в двух операционных системах — «Windows 10» и каком-нибудь дистрибутиве «Linux» на отдельных компьютерах, но бюджет пока не позволяет, поэтому ограничиваюсь только операционной системой «Windows 10» с возможным использованием подсистемы «WSL» вместо «Linux».
Есть несколько хороших компиляторов, но я использую MSVC (Microsoft Visual C++) самой свежей версии в составе набора инструментов командной строки «Microsoft C++ Build Tools». Это тот же компилятор, который использует интегрированная среда разработки «Microsoft Visual Studio 2022», которую я тоже установил к себе на компьютер в виде бесплатной версии под названием «Visual Studio Community 2022». В дистрибутиве «Ubuntu» из семейства операционных систем «Linux» (через WSL) я использую компилятор C++ из набора компиляторов «GCC».
Интегрированную среду разработки я установил, только чтобы показать работу из нее. Вообще она очень неповоротливая и тяжелая, у меня еле ворочается. Для ученических упражнений я установил редактор «Visual Studio Code», который можно настроить для работы с набором инструментов «Microsoft C++ Build Tools» (компиляция, пошаговая отладка и другие удобные функции).
Для работы из командной строки в большинстве случаев я использую программу-оболочку «PowerShell» и программу-«эмулятор терминала» «Windows Terminal». (Для работы с компилятором MSVC из командной строки приходится использовать программу-оболочку «Developer PowerShell for VS 2022», построенную на основе устаревающей программы-оболочки «Windows PowerShell» версии 5.1.) В дистрибутиве «Ubuntu» операционной системы «Linux» я использую программу-оболочку «bash» (она там по умолчанию).
Первая программа с символами не из базового набора
Для этой статьи я буду использовать следующий исходный код первой программы на языке C++, который сохраню в файле «first.cpp» в кодировке UTF-8 без метки BOM, с окончаниями строк CRLF (хотя ничего мне не мешает использовать кодировку UTF-8 с меткой BOM и окончания строк LF):
#include <iostream>
int main()
{
std::cout << "Hello, World! Привет, мир! 你好, 世界! ????\n";
return 0;
}Как видно из блока кода выше, эта программа содержит множество символов, выходящих за пределы базового набора возможных символов (буквы русского алфавита, китайские иероглифы, эмодзи) и я не стал представлять их специальной нотацией (universal character name) вроде \U0001F60E, как того требует действующий стандарт языка C++.
Современные компиляторы (вроде MSVC и других) расширяют действующий стандарт C++, позволяя в качестве базового набора возможных символов использовать все символы, входящие в набор символов используемой кодировки, то есть в данном случае это все символы набора символов Юникода. Об этом сказано в документации на сайте компании Microsoft (при описании языка C++ там расширения, вводимые компанией Microsoft, помечены фразой «Microsoft Specific»).
Я думаю, что это расширение настолько очевидно необходимо, что его должны рано или поздно включить в состав стандарта языка C++.
Метка BOM, для чего она нужна, использовать ли её
Если все люди будут использовать для текстовых файлов кодировку UTF-8 по умолчанию, то метка BOM (Byte Order Mark) будет не нужна. Но мы живем не в идеальном мире. Если говорить об операционных системах «Windows», то их разработчики хотят пока что сохранять обратную совместимость с устаревшими однобайтными кодировками вроде Windows-1251, CP866 и так далее. Поэтому в операционных системах «Windows» для того, чтобы программы могли автоматически распознать (отличить от устаревших однобайтных) кодировку UTF-8, в начало файла добавляют так называемую «метку BOM», которая для кодировки UTF-8 представляет собой три байта EF BB BF.
Таким образом, кодировки «UTF-8 без BOM» и «UTF-8 с BOM» не являются разными кодировками, это одна и та же кодировка, но в случае последней длина файла с исходным кодом просто удлиняется на 3 байта за счет вставки метки BOM в начало файла.
Используемые мною интегрированная среда разработки «Visual Studio Community», редактор кода «Visual Studio Code» и редактор кода «Notepad++» умеют работать как с кодировкой «UTF-8 без BOM» (или просто «UTF-8»), так и с кодировкой «UTF-8 с BOM». Вообще, на мой взгляд, современная программа, имеющая дело с текстом, должна уметь обработать присутствие в файле метки BOM.
Решение о том, какой из двух вариантов «UTF-8 без BOM» и «UTF-8 с BOM» использовать, на мой взгляд, должен принимать программист (или группа программистов, если речь идет о выработке руководства по стилю в случае совместной разработки) и это должно зависеть от его соображений, а не от каких-то внешних рекомендаций или требований. Таким образом, хорошие программы-инструменты должны обеспечивать работу как с «UTF-8 без BOM», так и с «UTF-8 с BOM».
Например, компилятор MSVC умеет работать как с исходным кодом в кодировке «UTF-8 без BOM», так и с исходным кодом в кодировке «UTF-8 с BOM». Если исходный код хранится в кодировке «UTF-8 с BOM», то компилятор MSVC распознает кодировку UTF-8 по умолчанию. Если исходный код хранится в кодировке «UTF-8 без BOM», то компилятор MSVC по умолчанию не сможет распознать кодировку UTF-8, поэтому потребуется использование ключа компилятора /utf-8 (тут подробнее). Ниже я приведу два простейших примера запуска компилятора MSVC (cl.exe) из командной строки для этих двух вариантов.
Если файл «first.cpp» содержит исходный код программы в кодировке UTF-8 с меткой BOM:
PS C:\test> cl /EHsc "first.cpp"Если файл «first.cpp» содержит исходный код программы в кодировке UTF-8 без метки BOM:
PS C:\test> cl /EHsc /utf-8 "first.cpp"Ключ компилятора /EHsc (тут подробнее) определяет модель обработки ошибок. Это рекомендуемый ключ для начинающих. Его обсуждение выходит за рамки темы, заявленной в этой статье, поэтому я не буду тут про него писать.
Запуск программы «first.cpp» в веб-компиляторах
Некоторые веб-компиляторы успешно справляются с компиляцией приведенного выше исходного кода программы «first.cpp» в кодировке UTF-8, но некоторые могут не справиться и выдать результат, не соответствующий ожидаемому. Как я писал выше, я пока не собираюсь использовать веб-компиляторы, но, думаю, не повредит привести работающий пример. Вот иллюстрация успешной компиляции и запуска исходного кода программы «first.cpp» в кодировке UTF-8 в веб-компиляторе «OnlineGDB.com»:

Запуск программы «first.cpp» в системе «Windows 10»
В операционных системах «Windows» приходится учитывать стремление разработчиков этой операционной системы обеспечивать по умолчанию работу устаревших программ, использующих устаревшие однобайтные кодировки вроде Windows-1251, CP866 и так далее. Я об этом уже упоминал ранее в этой статье.
Это стремление выражается в том, что программы-инструменты, предназначенные для эмуляции терминала (консоли), по умолчанию настроены для работы с одной из устаревших однобайтных кодировок. Какая конкретно это однобайтная кодировка, зависит от текущей локали (языка системы, по английски «system locale») операционной системы (не путать с языком интерфейса операционной системы). Например, у меня язык системы — русский, для этого случая в эмуляторе терминала (консоли) в операционных системах «Windows» по умолчанию используется кодировка CP866.
Что тогда делать, если мы хотим использовать кодировку UTF-8? Я пользуюсь в разных случаях тремя способами для решения этой проблемы. Далее в примерах я буду использовать файл «first.cpp» с исходным кодом в кодировке UTF-8 (без метки BOM).
Способ 1. Самый легкий, сохраняющий кроссплатформенность исходного кода. Этот способ подразумевает предварительное переключение активной кодовой страницы в используемой программе-оболочке. Думаю, его и следует использовать при обучении языку C++.
(Кроме переключения активной кодовой страницы программы-оболочки для правильного отображения символов из набора символов Юникода требуется наличие шрифта, который содержал бы изображения всех нужных символов, так как почти все шрифты содержат только ограниченное количество символов из таблицы Юникода. Символов в таблице Юникода слишком много, чтобы в одном шрифте реализовали их все. Современные эмуляторы терминалов, кстати, умеют исполнять так называемый «font fallback», отображая отсутствующие символы другим шрифтом, в котором нужные символы есть. Впрочем, в операционной системе «Windows 10» при использовании современных программ проблем со шрифтами у меня почти не возникает. То есть специальных действий по настройке шрифта обычно не требуется.)
1.1. Компиляция из программы-оболочки «Developer PowerShell for VS 2022»:
**********************************************************************
** Visual Studio 2022 Developer PowerShell v17.5.3
** Copyright (c) 2022 Microsoft Corporation
**********************************************************************
PS C:\test> cl /EHsc /utf-8 "first.cpp"
Оптимизирующий компилятор Microsoft (R) C/C++ версии 19.35.32216.1 для x64
(C) Корпорация Майкрософт (Microsoft Corporation). Все права защищены.
first.cpp
Microsoft (R) Incremental Linker Version 14.35.32216.1
Copyright (C) Microsoft Corporation. All rights reserved.
/out:first.exe
first.obj1.2.а. Запуск полученного исполняемого файла из программы-оболочки «cmd.exe»:
Microsoft Windows [Version 10.0.19045.2846]
(c) Корпорация Майкрософт (Microsoft Corporation). Все права защищены.
C:\test>chcp
Текущая кодовая страница: 866
C:\test>chcp 65001
Active code page: 65001
C:\test>first
Hello, World! Привет, мир! 你好, 世界! ????Иллюстрация:
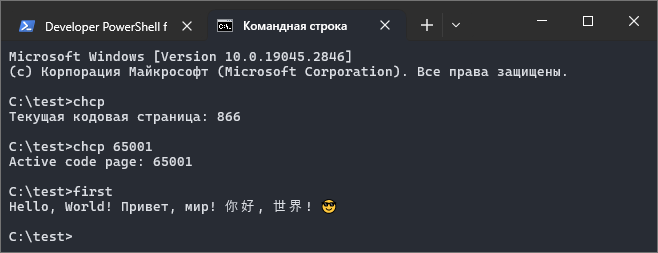
Команда chcp (тут подробнее) без параметров показывает номер активной кодовой страницы. Как я и писал выше, по умолчанию в программе-оболочке у меня включается кодовая страница с номером 866. Для работы с текстом в кодировке UTF-8 требуется кодовая страница с номером 65001.
1.2.б. Запуск полученного исполняемого файла из программы-оболочки «PowerShell» (версия 7) или «Windows PowerShell» (версия 5.1):
PS C:\test> ([System.Console]::OutputEncoding).CodePage
866
PS C:\test> [System.Console]::OutputEncoding = [System.Text.Encoding]::UTF8
PS C:\test> ([System.Console]::OutputEncoding).CodePage
65001
PS C:\test> .\first
Hello, World! Привет, мир! 你好, 世界! ????Иллюстрация:

Обратите внимание, что в программах-оболочках «PowerShell» и «Windows PowerShell» команда chcp может не срабатывать (рапортует, что активная кодовая страница переключена, а на самом деле переключения не происходит). Для программ-оболочек «PowerShell» для переключения активной кодовой страницы требуется изменение свойства «OutputEncoding» класса «System.Console» (платформа «.NET»). См. обсуждение этого вопроса на сайте «Stack Overflow».
Программное переключение активной кодовой страницы консоли в «Windows 10»
Исходя из вышесказанного, я хочу подытожить, что сложность использования кодировки UTF-8 в консольных программах в операционных системах «Windows» порождается не стандартом языка C++ и не компилятором (в нашем случае это MSVC), а тем, что активной кодовой страницей в консолях является не UTF-8 (как хотелось бы), а одна из устаревших однобайтовых кодировок, вроде CP866 в моем случае. Мне кажется, в будущем разработчики операционных систем «Windows» рано или поздно это исправят. Наверное, это зависит от того, насколько быстро пользователи будут отказываться от устаревшего программного обеспечения, использующего устаревшие однобайтные кодировки, и переходить на программное обеспечение, использующее кодировку UTF-8 для текстов.
Я в разных случаях использую два способа переключения активной кодовой страницы консоли из программы. Тут следует иметь в виду, что оба эти способа используют специфические для операционной системы «Windows» функции и поэтому их использование делает программу не кроссплатформенной. Из-за этого эти способы кажутся мне неудобными и не совсем подходящими для обучения языку C++.
С другой стороны, у этих способов есть преимущество перед описанным выше: от пользователя полученного исполняемого файла не потребуется предварительная настройка (переключение активной кодовой страницы) используемой им программы-оболочки. Пользователю достаточно будет просто запустить полученный исполняемый файл.
Способ 2. Продолжаем использовать «узкие» версии функций для работы с символами. Для переключения активной кодовой страницы используем функцию «SetConsoleOutputCP» из набора функций «Windows API» (то есть понадобится подключение заголовочного файла «windows.h»). Изменим исходный код:
#include <windows.h> // для функции SetConsoleOutputCP и константы CP_UTF8
#include <iostream>
int main()
{
SetConsoleOutputCP(CP_UTF8);
std::cout << "Hello, World! Привет, мир! 你好, 世界! ????\n";
return 0;
}Обратите внимание, я лишь добавил в исходный код две новые строки, а строки предыдущей версии исходного кода не изменял.
Компилируем, запускаем. Теперь предварительная настройка активной кодовой страницы в консоли не требуется, программа работает так, как от нее ожидалось:
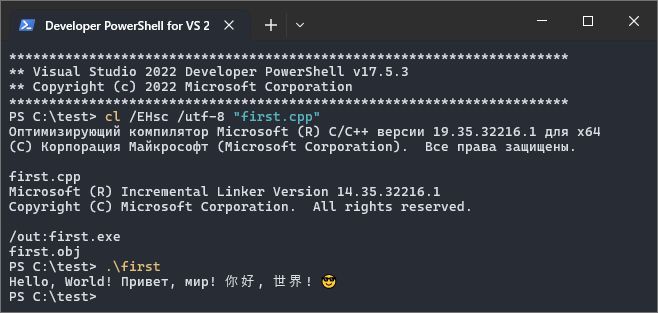
Способ 3. Если мы хотим использовать «широкие» версии функций для работы с символами, то для правильного вывода символов в консоль потребуется использовать функцию «_setmode» (требует подключения заголовочного файла «io.h»; если в коде используются соответствующие константы, то еще потребуется подключение заголовочного файла «fcntl.h»). Изменим исходный код:
#include <io.h> // для функции _setmode
#include <fcntl.h> // для константы _O_U8TEXT
#include <iostream>
int main()
{
_setmode(_fileno(stdout), _O_U8TEXT);
std::wcout << L"Hello, World! Привет, мир! 你好, 世界! ????\n";
return 0;
}Обратите внимание, что я не только добавил три новые строки в первоначальную версию исходного кода из начала поста, но еще заменил функцию std::cout на std::wcout, а также сделал приставку «L» к строковому литералу. Эти два последних изменения нужны для работы с так называемыми «широкими» символами (тип «wchar_t»).
Компилируем, запускаем. Теперь предварительная настройка активной кодовой страницы в консоли не требуется (как и при использовании способа 2), программа работает почти так, как от нее ожидалось:

Обратите внимание на то, что символ эмодзи ???? (U+1F60E) отобразился неверно. Это не ошибка программы-оболочки или программы-«эмулятора терминала». Также это не ошибка способа 3 в целом, но тут есть одна тонкость. Дело в том, что тип «wchar_t» («широкие» символы) по стандарту языка C++ является платформозависимым (поэтому многие программисты его недолюбливают). В операционных системах «Windows» «широкие» символы имеют фиксированный размер в 2 байта и, следовательно, могут представить только 65536 символов (2 в шестнадцатой степени). (В операционных системах «Linux», насколько я знаю, «широкие» символы имеют размер в 4 байта.)
Таким образом, «широкий» символ может представлять букву русского алфавита или китайский иероглиф, потому что в таблице Юникода коды русских букв и китайских иероглифов входят в состав первых 65536 позиций (основная многоязычная плоскость, по-английски «Basic Multilingual Plane» или сокращенно «BMP»). Как видно по коду символа эмодзи ???? (U+1F60E), он не входит в эти 65536 позиций и поэтому «широкий» символ в операционных системах «Windows» не может хранить символ эмодзи ???? (U+1F60E).
То есть ошибка — в 9 строке исходного кода, в которой определен строковый литерал. Строковый литерал с приставкой «L» не может содержать символ эмодзи ???? (U+1F60E), как уже было объяснено выше. Насколько я понимаю, код символа ???? (U+1F60E) обрезается так, чтобы символ влез в строку «широких» символов, в итоге получается не то, что ожидалось.
Если использовать способ 3 только для русских букв, китайских иероглифов и/или других символов, коды которых входят в основную многоязычную плоскость (BMP) Юникода, проблем не возникнет.
Запуск программы «first.cpp» в системе «Linux»
Вернемся к самому первому варианту исходного кода программы «first.cpp» из начала этой статьи. Я его сохранил в своей основной операционной системе «Windows 10» в местоположении «C:\Users\Илья\source\repos\test\first.cpp». Через подсистему «WSL 2» я могу работать с установленным у меня дистрибутивом «Ubuntu» операционной системы «Linux». В дистрибутиве «Ubuntu» я установил пакет «g++» с компилятором языка C++ из набора компиляторов «GCC». Запускаем компиляцию, а затем запускаем полученный исполняемый файл на выполнение:
ilya@IlyaComp:~/test$ g++ /mnt/c/Users/Илья/source/repos/test/first.cpp -o first
ilya@IlyaComp:~/test$ ls -l
total 16
-rwxr-xr-x 1 ilya ilya 16376 Apr 22 18:35 first
ilya@IlyaComp:~/test$ ./first
Hello, World! Привет, мир! 你好, 世界! ????Иллюстрация:
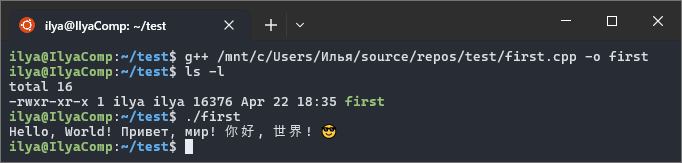
Как видно из примера выше, я использовал тот же файл, что и при работе с компилятором MSVC в операционной системе «Windows 10». То есть исходный код в файле «first.cpp» из начала статьи является кроссплатформенным для операционных систем «Windows» и «Linux». Конечно, исполняемые файлы получаются абсолютно разные: формата PE и формата ELF соответственно.
Работать с кодировкой UTF-8 в операционных системах «Linux» легче, чем в операционных системах «Windows», так как, насколько я понимаю, в операционных системах «Linux» кодировка UTF-8 используется по умолчанию.
Заключение
Главная цель этой статьи — показать, что обучать программированию на языке C++ можно, сразу начав работу в кодировке UTF-8. Думаю, что хороший учебник по программированию на языке C++, написанный на русском языке, должен в основном включать примеры и упражнения с символьными и строковыми литералами на русском языке. Пока я не видел хороших учебников, которые учитывали бы это соображение. Но, надеюсь, они вскоре появятся, как в бумажном виде, так и в виде сайта или веб-приложения.
Комментарии (45)

nerudo
25.04.2023 18:50+10Собственно ваш пост — хорошее объяснение, почему в первой главе учебника по С++ стараются использовать ASCII.

ilyachalov Автор
25.04.2023 18:50+1Вы не могли бы развернуть немного подробнее? Хотя бы в двух словах. Ваше утверждение может подразумевать десяток различных вещей. А мне хотелось бы конкретики.

COKPOWEHEU
25.04.2023 18:50А чего тут разворачивать? Вам целую статью написать пришлось чтобы рассказать как обойти грабли совместимости. При том, что обычный ASCII хелловорлд пишется строки в четыре. И на этапе обучения, когда хелловорлд актуален, важнее рассказать о типах данных, ветвлениях, алгоритмическом мышлении. А не о глюках различных ОС.
Кстати о глюках, совет использовать msvs вреден: приходится отдельной строчкой приказывать тамошнему компилятору придерживаться стандарта, а не навязывать свои псевдо-безопасные strcmp_s и подобные функции.
Плюс не забывайте о локализации: если уж вы хотите использовать в своей программе не международный язык, имеет смысл сразу же рассказать про локализацию. Что в исходном коде все сообщения так и так пишутся на английском, а переводы подкладываются отдельно. Ну и соответственно как именно эти переводы сгенерировать, куда подложить и как потом подцепить. Не говоря даже об уважении к пользователю, которому может быть сложно читать на казахском языке, бывают и проблемы с терминалом. Вы вон сами воткнулись в кодировку cp1251 / 866, которая русские буквы не отображает. А так указали бы локаль
LC_ALL="C", и весь интерфейс переключился бы на английский. Не очень удобно, но хоть понятно. Да, из соображений переносимости лучше неSetOutputCP + SetConsoleOutputCPделать, аsystem("chcp 65001");. В других ОС этих windows-специфичных функций нет, соответственно программа просто не соберется. А system просто ругнется что программа chcp не найдена — и продолжит работать дальше. Впрочем, еще лучше все же обернуть в #ifdef, но это уже гораздо больше кода, да и знаний потребует.

kin4stat
25.04.2023 18:50+7В начале статьи говорите о том, какие все плохие, не показывают юникод в новичковых курсах, а после показываете 100500 способов вывести смайлик в консоль, из которых переносимых между системами, дайте посчитать….
…ноль.
Я дартаньян, вы все пи…, вот вам пугало, смотрите, любуйтесь!
Не смешно самому?
ilyachalov Автор
25.04.2023 18:50+1Не-не, я не считаю никого плохим, отнюдь )). Один способ кроссплатформенный я привел.

IgorLutiy
25.04.2023 18:50+4русскоязычному ученику было бы удобнее и интереснее (это важно!) писать первые программы, выводящие сообщения на русском языке и, к примеру, с эмодзи. Особенно, если речь идет об обучении детей.
Я прям вижу, как ученик (особенно ребенок), офигевает когда ему, вместо того чтобы за пару минут показать, как написать Hello world, что действительно сможет заинтересовать (сходу можно писать программу, которая что-то реально делает), начинают читать вот такую длинную лекцию о кодировках и прочем, о чем он ни сном ни духом. От которой желание писать программы может внезапно пропасть.
Главная цель этой статьи — показать, что обучать программированию на языке C++ можно, сразу начав работу в кодировке UTF-8
Можно, но не нужно. Учебники не дураки пишут.
ilyachalov Автор
25.04.2023 18:50+1Согласен с вами, эту статью нельзя использовать в качестве первого урока. Но эта статья изначально написана для тех, кто начинает учить, а не для тех, кто начинает учиться. Ученику на первом уроке достаточно дать код из первого блока кода в статье и сказать о том, что для текстов сейчас используют кодировку UTF-8, поэтому и ему тоже стоит ее использовать для исходного кода.

lorc
25.04.2023 18:50-1Чтобы сказать "используй кодировку UTF-8", у человека сначала в голове должна быть концепция "кодировка" как таковая. И навыки для того чтобы проверить какая кодировка используется в открытом файле и как ее изменить, если там выставлено не то что нужно.
ilyachalov Автор
25.04.2023 18:50Есть разные методы обучения. Например, ученик может сначала просто делать то, что ему говорит учитель, даже не понимая смысла. Главное - показать получение результата. Вы учите ученика работать с выбранным редактором кода, показываете, как там настроить нужную кодировку, как изменить кодировку имеющегося файла и т.д. На первых уроках можно не углубляться, что такое кодировка и какие они бывают вообще. В следующих уроках ученику постепенно и взаимосвязанно с другими темами раскрывается смысл действий и понятий. При таком способе ученику не нужно ничего знать заранее, он узнает о деталях позже.
Второй способ - сначала по максимуму погрузиться в тему, о том, что такое кодировка, как устроены компьютеры, что такое организация ЭВМ, как работает память и процессор, история языков программирования от машинного кода и ассемблера до Python и других высокоуровневых языков, что такое абстракции, платформы, история операционных систем и так далее. Это называется комплексным подходом и практикуется в университетах.
Оба способа хорошие и дадут результат, если правильно взяться.

VADemon
25.04.2023 18:50+1Второй способ ... практикуется в университетах.
В итоге, когда учащиеся доходят до программирования, то их либо уже не стало (потеря + неразвитие мотивации), либо уже забыли зачем им на первой лекции минут 5 объясняли, что там есть биты-байты, и как там компьютер абы как это в памяти хранит.
Устойчивых реляционных связей между предметами не возникает, нету на это времени и пока неясна, скажем, высокоуровневая структура, запомнить детали будет практически невозможно. А детали становятся интересны именно тогда, когда есть понимание для чего они требуются и где применимы.
Вы описали две крайности, первая - зачастую видная в интернете: статьи обрезки, пошаговые руководства типа "сделай так и будет щастье", индусские копирайтеры в т. ч. Второй: закопаться и не выбраться. Хорошие книги пытаются между ними балансировать. Статьи -- реже (возьмем скопом как плохой пример -- все техническо-прикладные статьи из блогов компаний на Хабре).
Поэтому в гробу я видел второй подход (см. предпредыдущий абзац). А первый у меня лишь с презрением ассоциируется, человек пусть и бестолково, но что-то делает и интерес не теряется.
Сам, признаюсь, из-за систематичного подхода, начинаю слишком часто с bottom-up approach, на это уходит чрезмерно много усилий и времени. Я замечаю, как это не окупается. Пример: выбрать между несколькими альтернативами, это значит потратить минут по 15 на каждый мануал/доку, ни черта не понять, а потом таки начать щупать (первый подход). Это может и работает с физическими вещами, но не софтом, где стоимость пробы может равняться нулю.
ilyachalov Автор
25.04.2023 18:50+1Согласен с тем, что можно обучать, балансируя между двумя подходами. Мне кажется, можно в каждом конкретном случае исходить из того, что ученик уже знает (если обучение один на один). Я не хочу углубляться здесь в дискуссию о способах обучения. Я лишь хотел подчеркнуть, что UTF-8 для начинающих с первого урока - это возможно (по-моему, даже необходимо).

freegemini
25.04.2023 18:50Не вижу никаких противоречий или каких-то революционных находок. Очень подходит для таких случаев волшебная фраза: "Сейчас мы с вами просто сделаем так как показано в примере, а чуть позже, когда у вас появится понимание сути вопроса, мы вернемся к этому примеру и разберемся почему мы сделали именно так, какие еще варианты доступны и пр."
VADemon
25.04.2023 18:50+1Насчет wchar_t и эмодзи, тут я не разбираюсь, но по-моему работать это может, при определенных обстоятельствах и должной поддержке. Вот тут об emoji in SMS: UCS-2 vs UTF-16
Основываясь же на своем предыдущем комментарии, теперь уже после прочтения подчеркну, что забраться в такие дебри... а оно нужно ли? Тем важнее вопрос, на каком уроке? Если первом то у меня бы (как начинающего), наверно голова вспухла ещё до вывода строки. Но при цели поддержки Uncode, без головоломки flat vs wide character + 8-bit ASCII vs UTF-8/UTF-16 (насчитываем, грубо, четыре варианта) невозможно будет обойтись, из-за требований к типам в Win32 API.
С другой стороны, конечно, всякие `C:\Users\Илья\Рабочий стол\урок cpp 1\`
Если стоит цель вывода в
консольвиртуальный терминал, то я придерживаюсь мнения, что надо дать магическую ifdef функцию для винды, и остановиться пока на том, что она включает многоязычность вывода.

m0xf
25.04.2023 18:50В windows можно вызвать setlocale(LC_ALL, ".UTF8") в самом начале программы. Это переведёт стандартную библиотеку на utf-8.

patyupin
25.04.2023 18:50-4мы ищем опытного C++ девелопера. английский и опыт с linux обязателен. работа удаленная. вопросы шлите сюда: raymond@dcmsys.com

alexxisr
25.04.2023 18:50по-моему в С можно просто писать printf("что угодно, включая символы хекскодами") и программа просто зашлет эти байты в консоль, а та уже пусть и разбирается что там за кодировка. Зачем все эти пляски именно внутри программы?
Я заходя в статью думал тут про работу со строками — как порезать, не попав между байтами одного символа например. А вывод в консоль у меня работал по умолчанию еще в 90-х.
mayorovp
25.04.2023 18:50Ну вот и попробуйте просто записать в консоль строку с русскими буквами на винде, увидите как она разберётся...
mayorovp
25.04.2023 18:50+1То есть ошибка — в 9 строке исходного кода, в которой определен строковый литерал. Строковый литерал с приставкой «L» не может содержать символ эмодзи ???? (U+1F60E), как уже было объяснено выше. Насколько я понимаю, код символа ???? (U+1F60E) обрезается так, чтобы символ влез в строку «широких» символов, в итоге получается не то, что ожидалось.
Неа, ошибка тут в стандартной библиотеке, которая рассматривает символ U+1F60E, состоящий из двух whar_t, как два отдельных символа.


vadimr
25.04.2023 18:50-1Зачем героически создавать самим себе и не менее героически преодолевать трудности, сначала используя для обучения систему, в которой нет сквозной кодировки символов, потом набирать программу в GUI, а потом её результаты смотреть в консоли?
apro
Вроде бы это в C++23 обещали починить и:
без дополнительный действий со стороны программиста в Windows консоли напечатает нужный текст, так как C++ runtime определит с чем соединен stdout и вызовет, если нужно
SetConsoleOutputCP(CP_UTF8);самостоятельно.ilyachalov Автор
Я не большой специалист, но, мне кажется, что стандарт должен описывать какие-то общие вещи, а эта особенность характерна для операционных систем Windows. Мне кажется, вряд ли такое вставят в стандарт. Но я был бы вам благодарен, если бы вы дали ссылку на источник, в котором обещали починить (если вам будет несложно). Мне было бы интересно почитать.
apro
https://en.cppreference.com/w/cpp/io/vprint_unicode
И новый
std::printlnсоотвественно будет использовать "vprint_unicode".Я об этом узнал на cppcon: https://youtu.be/eD-ceG-oByA?t=4925
ilyachalov Автор
Спасибо. Плюсанул в карму.