
Привет, Habr! Меня зовут Сергей, я инженер в ДОМ.РФ, и одна из моих задач - развитие ИТ-мониторинга. В этой статье я расскажу, как мы самостоятельно и с минимальными затратами пришли от идеи к рабочему инструменту, с помощью которого в одном месте в простой и понятной форме можно определить текущее здоровье наших систем.
В идеале итоговый результат должен выглядеть как-то так:

При этом информация должна собираться из разных источников.
Вводные:
единый интерфейс, отображающий все ИТ-системы в виде иконок со статусами,
визуально понятные статусы,
звуковое оповещение в случае изменения статуса работоспособности в разрезе каждой ИТ-системы,
возможность просмотра расширенной информации, а именно - причин, повлиявших на статус работоспособности.
Чем подобный инструмент должен помочь:
уменьшить время реакции дежурной смены при массовых сбоях,
поможет коррелировать события между зависимыми ИТ-системами,
прозрачно укажет очаги возгорания в ИТ для людей как углубленных, так и не углубленных в ИТ.
Звучит удобно? Удобно!
Идея на самом деле не нова и на первый взгляд нам могла бы подойти какая-либо система зонтичного мониторинга, коих, благо, на рынке сейчас достаточное количество, есть из чего выбирать. Плюс надо отталкиваться от того, что у нас уже есть, в частности, с чем этот инструмент интегрировать.
А это минимум Zabbix, являющейся у нас основной системой мониторинга, в котором уже заведены все ИТ-системы. Он же занимается агрегацией событий из смежных систем мониторинга. Он же отвечает за визуализацию событий дежурной смене.
Не забываем про существование Grafana, которая визуализирует дашборды команд. Тут появляется еще одно требование к инструменту: возможность добавлять к сущностям ИТ-сервисов линки на дашборды Grafana.
К большим enterprise душа сразу не лежала, и вот почему:
муки выбора: быстро найти подходящий инструмент непросто, а это означает, что нас ждут длительные пилоты,
закупки — пилот → бюрократия → промышленная эксплуатация, путь далеко не быстрый,
доработки: в случае возникновения каких‑либо дополнительных потребностей мы зависимы от поставляемого продукта. Мало того, что надо договориться с вендором о возможности кастомизации, так еще и 90% вероятность, что это приведет к пункту закупок,
интеграции — очень каверзный пункт. У нас есть два варианта развития событий: как правило, многие системы зонтичного мониторинга являются самостоятельным продуктом или агрегатором событий/данных из нижнеуровненвых систем мониторинга.
Это означает, что все уже имеющиеся сущности ИТ-сервисов из Zabbix придётся дублировать в новую систему. Одно дело - скопипастить названия, если предусмотрена тонкая интеграция, другое дело - выстроить зависимости (как событие из системы мониторинга "А" должно отобразиться в верхнеуровневой системе "Б"), перенести правила оповещений, корреляцию событий и взаимосвязи систем.
Далее необходимо запустить процесс обработки событий. Из чего появляются требования к обработке событий. В привычном Zabbix есть возможности проставлении статусов обработки событий, временного подавления события и снижения критичности.
Необходимо обучить персонал дежурной смены и администраторов/владельцев ИТ-систем пользоваться новым продуктом, в частности обработки событий и самостоятельной корректировки параметров мониторящихся ИТ-систем.
Необходим продукт с тонкой интеграцией с Zabbix. Который будет только подхватывать активные события и визуализировать их, то есть вся логика останется на стороне Zabbix.
Был один вариант (название умолчим), который мог собирать и обрабатывать события из Zabbix по API, но делал он это минут 15 на одну итерацию. Согласитесь, "такой себе" оперативный мониторинг. Вишенкой стало отсутствие возможности корреляции событий между смежными ИТ-системами.
Подходим к разработке
А раз уж это в любом случае в каком-то виде разработка, можно подумать и об обслуживании инструмента. Если это самостоятельное приложение, оно обязательно должно быть построено на HA-архитектуре, что несет за собой дополнительные трудозатраты на разработку + дальнейшее обслуживание.
А если нет? У нас же есть Grafana! Grafana умеет в HA, легко обслуживается, она используется как основной инструмент визуализации метрик для команд. Используя именно её как инструмент отображения статусов ИТ-систем, мы избавляемся от лишних переходов между инструментами и лишнего балласта, который бы нам пришлось в последующем обслуживать.
А может, получится обойтись малой кровью без разработки?
Посмотрим на возможности, предоставленные из коробки:
Grafana имеет интеграцию с Zabbix. - Хорошо
Grafana из системы Zabbix может визуализировать метрики, количество проблем по какой-либо хост группе, статус "Услуга". - Вроде хорошо, но нет. Все это не подходит. Сущности "Услуга" — это заготовка от Zabbix для визуализаций зонтичного типа, здесь боль в том, что услуги заполняются вручную. Вручную, Карл! Не наш путь. Остальное совсем мимо.
У Grafana есть различные плагины для визуализаций, наиболее подходящая из коробки это "Stat". - Вроде хорошо, но нет. "Stat" - отображает красивую панельку, можно убрать тайтл, отображать имена значений, а не само значение, но нет визуального и звукового оповещения + не вставить два значения в одну плашку. Не подходит.

Значит, от разработки не уйти
Ок. Настало время структурировать требования, дополнить их, и собрать в единое ТЗ. Которое вкратце выглядит так:
единый дашборд отображающий все ИТ-системы в виде плашек,
возможность перемещения, изменения размеров плашек для визуального обозначения значимости ИТ-системы,
визуальное отображение статусов работоспособности в разрезе каждой ИТ-системы /плашки в виде цветового индикатора,
визуальное (blink - мигать) и звуковое оповещение в случае изменения статуса работоспособности в разрезе каждой ИТ-системы/плашки,
возможность добавления своих ссылок/линков к сущностям ИТ-системы /плашки,
отображать статусы работоспособности ИТ-систем, основываясь на событиях в системе Zabbix,
оперативно отображать изменения статусов с задержкой не более 1 минуты от времени возникновения событий,
при отображении статусов учитывать обработку событий в системе Zabbix (периоды технического обслуживания, подавление событий, снижение уровней критичности, а так же статус обработки),
отображение на сущностях ИТ-системы /плашки количества не обработанных событий если таковые имеются,
второй уровень дашборда , возможностью просмотра расширенной информации (текущий статус, события, повлиявшие на статус работоспособности ИТ-системы /плашки, список текущих активных проблем, отображение сущностей мониторинга, входящих в ИТ-систему в виде плашек с отображением статусов работоспособности сущности).
Рассмотрим техническую составляющую
Определимся, каким образом будем получать из Zabbix статусы ИТ-систем и количество необработанных событий.
Какие есть варианты:
собирать статусы активных событий из Zabbix по API, структурировать и агрегировать их, далее перекладывать их в какую-то систему хранения, из которой Grafana будет брать статусы,
собирать лог событий, складывать в Elastic, структурировать и агрегировать их, далее перекладывать их в какую-то систему хранения, из которой Grafana будет брать статусы,
собирать лог событий, складывать в Elastic, собирать статус Grafana из Elastic,
направлять события в виде оповещения стандартными средствами Zabbix в обработчик, которым складывать в какую-то систему хранения, из которой Grafana будет брать статусы.
Минусы везде схожи. А именно: возможна длительная обработка событий, дополнительное ПО - инструмент нуждающийся в периодическом обслуживании.
В итоге мы решили брать статусы событий напрямую из БД Zabbix, структурировать и агрегировать их на уровне SELECT.
Минусы данного подхода: дополнительная нагрузка на БД. Но нагрузка незначительная + она все равно была при использовании любого другого метода, меньше, но была бы.
Для визуализации в Grafana нужен новый плагин, который будет учитывать все требования, описанные выше. Какие есть варианты:
писать плагин с нуля. - Боль, подрядчиков нанимать не хочется из соображений описанных про enterprise, у своих разработчиков и без нас дедлайны горят.
поискать исходники плагина "Stat" или любого другого подходящего по смыслу стороннего плагина и дописать необходимый функционал. - и такой плагин есть! Status Panel, нам подходит.

Status Panel - плагин, способный отображать визуально статус какой-либо сущности, основываясь на нескольких показателях сущности + отображать эти показатели на этой же плашке (в отличие от того же коробочного "Stat"). А самое главное - у него открытый исходный код!
Фактически мы получаем весь нужный функционал, а недостающий можем дописать. Да, есть минусы - в отсутствии поддержки (автор его забросил два года назад) и количестве поддерживаемых источников данных.
Приступаем к применению напильника
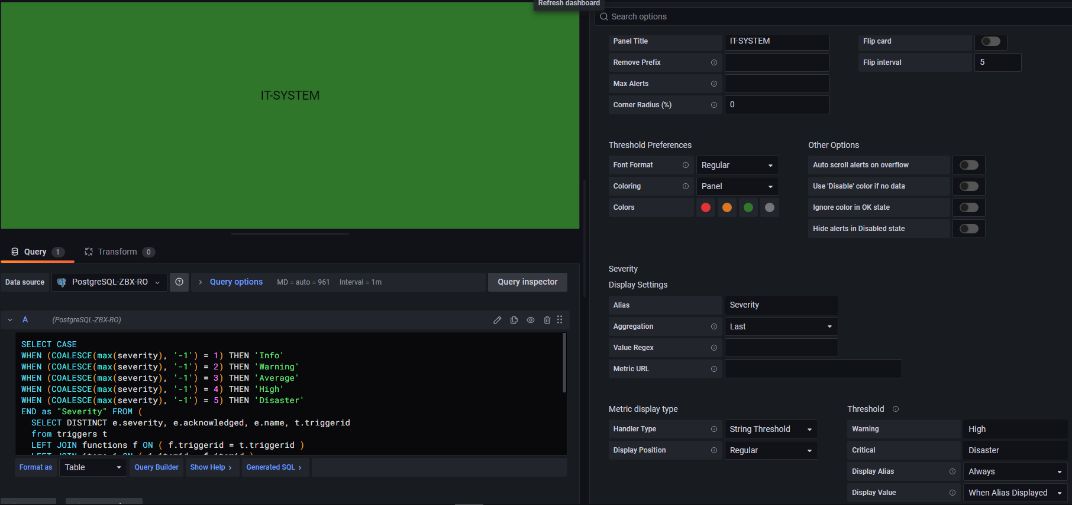
Далее мы разберем, как прорабатывался верхнеуровневый дашборд с отображением статусов работоспособности ИТ-систем. Второй слой с расширенной информацией рассматривать не будем. Так как в Zabbix уровней severity шесть, а в Status Panel из коробки всего два, оперировать будем матчингом Zabbix High → Status Panel Warning, Zabbix Disaster → Status Panel Critical. Для нас достаточно отображения последних двух уровней severity из Zabbix. В случае необходимости добавить в Status Panel дополнительные severity можно путем правки statis_ctrl.js - то есть добавить в код недостающие severity по аналогии с уже имеющимися.
Начнем с запросов. Сейчас стоит задача собрать по одной ИТ-системе статус и количество необработанных событий. Для выборки данных по ИТ-системе можно отталкиваться от хост-групп или тегов, тут кому как удобнее. Мы пошли по пути тегов, так как теги можно раскидать где угодно, тем самым покрыть зависимости систем от друг друга. Для начала отобразим в стандартном плагине Stat, дабы убедиться, что все работает:

Пример одного из запросов:
SELECT CASE
WHEN (COALESCE(max(severity), '-1') = 4) THEN 'High'
WHEN (COALESCE(max(severity), '-1') = 5) THEN 'Disaster'
END as "Severity" FROM (
SELECT DISTINCT e.severity, e.acknowledged, e.name, t.triggerid
from triggers t
LEFT JOIN functions f ON ( f.triggerid = t.triggerid )
LEFT JOIN items i ON ( i.itemid = f.itemid )
LEFT JOIN events e ON ( e.objectid = t.triggerid )
LEFT JOIN problem_tag pt ON ( pt.eventid = e.eventid )
LEFT JOIN problem p ON ( p.eventid = e.eventid )
LEFT JOIN hosts ON ( i.hostid = hosts.hostid )
left join trigger_depends td on t.triggerid = td.triggerid_down
where pt.tag='IT-SYSTEM' AND pt.value='SYSTEM-NAME'
AND i.status =0 AND t.status =0 AND hosts.status =0 AND (e.object-0)=0
AND e.severity > 3 AND p.r_eventid IS NULL AND hosts.maintenance_status = 0
AND e.eventid NOT IN (select eventid from event_suppress where userid IS not NULL)
) AS rowДалее плагин. Для начала запустим AS IS с одним запросом выборки статусов. Заранее известно, что запрос должен вернуть High. Указываем матчинг с нашей метрикой Severity, текстовые трешхолды. Но трешхолд не работает, хотя плашка должна была изменить цвет и показать, по какому параметру засветилась.
Почему ничего не изменилось? Есть такой пункт Use 'Disable' color if no data, который в явном виде дал понять, что скрипт данных не видит. В принципе, ожидаемо, в доке есть упоминание:
Currently the plugin was tested with influxDB and Graphite. Support for other data sources could be added by demand
Благо это js, а значит путем просмотра кода и DevTools браузера сможем разобраться, что к чему. Основной код плагина находиться в файле statis_ctrl.js, за рендер отвечает функция onRender(), т.к. у нас нет данных по мнению этой функции, посмотрим, какие данные в неё приходят. За передачу данных рендеру отвечает функция onDataReceived(), которая уже берет данные из запроса, консолидирует данные в seriesHandler и возвращает обратно на рендер.
onDataRecevied()
key: "onDataReceived",
value: function onDataReceived(dataList) {
this.series = dataList.map(StatusPluginCtrl.seriesHandler.bind(this));
this.render();
seriesHandler
key: "seriesHandler",
value: function seriesHandler(seriesData) {
var series = new TimeSeries({
datapoints: seriesData.datapoints,
alias: seriesData.target
});
series.flotpairs = series.getFlotPairs("connected");
return series; Как видно из кода, от Grafana ожидаются данные target и datapoints. Посмотрим, что мы получаем фактически. Для этого выведем в лог данные из переменной dataList (console.log(dataList);):


Как видим, при запросе к БД вида table мы не получаем данные в необходимом для нас виде. Два варианта, либо написать обработчик, либо переделать запрос возвращающий TimeSeries. Изначально мы пошли по неправильному пути и написали обработчик.
onDataRecevied()
key: "onDataReceived",
value: function onDataReceived(dataList) {
try {
this.series = dataList.map(StatusPluginCtrl.seriesHandler.bind(this));
this.render();
} catch (e) {
var newserie2 = new Array;
for (var j = 0; j < dataList.length; j++) {
for (var i = 0; i < dataList[j].rows.length; i++) {
var newserie = {
"alias": `${dataList[j].columns[i]['text']}`,
"target": `${dataList[j].columns[i]['text']}`,
"datapoints": [[dataList[j].rows[i][0],0],[dataList[j].rows[i][0],1]]
};
newserie2[j] = newserie;
}
}
this.series = newserie2.map(StatusPluginCtrl.seriesHandler.bind(this));
this.render(); Да, работает, но есть вариант проще: добавляем в запрос выборку time, чтобы Grafana возвращала TimeSeries.
Пример одного из запросов:
.............
END as "Severity", extract(epoch from now()) as time FROM (
.............

И о, чудо! Можно приступать к остальным пунктам тз.
Начнем с отображения данных. Из коробки доступны варианты: выводить метрику по достижению какого-либо трешхолда либо выводить только текст/значение метрики, не отталкиваясь на трешхолды. Нам не подходит. Надо сделать/дописать две вариации вывода:
не отображать метрику совсем, при этом использовать трешхолд (используем для Severity, в случае изменения статуса работоспособности ИТ-системы у нас должен поменяться цвет, зачем нам еще текстом это выводить, тем самым занимая место?)
Поступим немного по-варварски: в файле module.html, есть блоки, отвечающие за выводы метрик, наподобие:
module.html
<div ng-style="ctrl.panel.colorMode === 'Metric' && {'color':ctrl.panel.colors.crit}"
ng-class="{'boldAlertMetric': ctrl.panel.fontFormat === 'Bold', 'italicAlertMetric': ctrl.panel.fontFormat === 'Italic'}"
ng-repeat="crit in ctrl.crit">
<a ng-show="crit.url" ng-href="{{ crit.url | interpolateTemplateVars:this }}" target="_blank" style="color:inherit">{{ crit.alias }}</a>
<span ng-hide="crit.url">{{ crit.alias }}</span>
<span ng-show="crit.isDisplayValue"> - {{ crit.display_value | numberOrTextWithRegex : crit.valueDisplayRegex }}</span>
</div> Упростим его до:
module.html
<div ng-style="ctrl.panel.colorMode === 'Metric' && {'color':ctrl.panel.colors.crit}"
ng-class="{'boldAlertMetric': ctrl.panel.fontFormat === 'Bold', 'italicAlertMetric': ctrl.panel.fontFormat === 'Italic'}"
ng-repeat="crit in ctrl.crit">
<span ng-show="crit.isDisplayValue">{{ crit.alias }} - {{ crit.display_value | numberOrTextWithRegex : crit.valueDisplayRegex }}</span>
</div> Тем самым мы убрали привязку к выбору меню Display Alias и оставили только Display Value, зависящую от переменной isDisplayValue. Соглашусь, не самый хороший ход - вырезать часть имеющегося функционала из коробки, но под наши нужды сойдет.
Отображать метрику только в случае прохождения порога, но не учитывать в состоянии самой плашки (используем для Not acknowledged - отображения не обработанных событий).
Добавим свой Hendler Type. Так как нам необходимо отображать метрику только в случае превышения трешхолда, и у нас он будет неизменный, то зададим его в явном виде в коде и назовем Hendler Type, соответственно, 'More Zero'.
statis_ctrl.js
-----
< _this.valueHandlers = ['Number Threshold', 'String Threshold', 'Date Threshold', 'Disable Criteria', 'Text Only'];
--
> _this.valueHandlers = ['Number Threshold', 'String Threshold', 'Date Threshold', 'Disable Criteria', 'Text Only', 'More Zero'];
-----
< } else if (target.valueHandler == "Text Only") {
< _this5.handleTextOnly(s, target);
--
> } else if (target.valueHandler == "Text Only") {
> _this5.handleTextOnly(s, target);
> } else if (target.valueHandler == "More Zero") {
> _this5.handleMoreZero(s, target);
-----
< }, {
< key: "updatePanelState",
--
> }, {
> key: "handleMoreZero",
> value: function handleMoreZero(series, target) {
> if (series.displayType == "Annotation") {
> this.annotation.push(series);
> } else {
> if (series.display_value == 0 ) {
> delete series.isDisplayValue;
> }
> this.display.push(series);
> }
> }
> }, {
> key: "updatePanelState",
-----


Уже неплохо, осталось добавить визуальное и звуковое оповещение. Для визуального оповещения воспользуемся эффектом анимации, применяемым к плашке. В данном случае нам необходимо учесть, что анимация должна появляться, когда изменяется статус и пропадать если статус сохраняется. Отталкиваться будем от обновления данных на странице. Так как встраивать все это дело будем в js, нужно как-то между собой различать плашки.
CSS по линку выше добавляем к нашим CSS плагина (сразу не много поправим, чтобы эффект не вызывал эпилепсию):
/css/status_panel.css
.blink {
animation-name: blinker;
animation-iteration-count: infinite;
animation-timing-function: cubic-bezier(1.0,2.0,0,1.0);
animation-duration: 1s;
animation-play-state: running;
-webkit-animation-name: blinker;
-webkit-animation-iteration-count: infinite;
-webkit-animation-play-state: running;
-webkit-animation-timing-function: cubic-bezier(1.0,2.0,0,1.0);
-webkit-animation-duration: 1s;
}
@keyframes blinker {
from { opacity: 1.0; }
50% { opacity: 0.5; }
to { opacity: 1.0; }
}
@-webkit-keyframes blinker {
from { opacity: 1.0; }
50% { opacity: 0.5; }
to { opacity: 1.0; }
} Далее строим логику в js, чтобы эффекты применялись когда нужно. Для начала объявим переменную массив для хранения статусов, где-нибудь в начале кода:
statis_ctrl.js
-----
< }();
< panelDefaults = {
--
> }();
> var GlobalpanelState = [];
> panelDefaults = {
----- Ну и сама логика, за обновление статусов отвечает функция updatePanelState(), до и после описывать не будем, конечный результат выглядит вот так:
updatePanelState()
key: "updatePanelState",
value: function updatePanelState() {
this.$panelContainer.removeClass('blink');
if (this.duplicates) {
this.panelState = 'error-state';
} else if (this.disabled.length > 0) {
this.panelState = 'disabled-state';
} else if (this.crit.length > 0) {
this.panelState = 'error-state';
} else if (this.warn.length > 0) {
this.panelState = 'warn-state';
} else if ((this.series == undefined || this.series.length == 0) && this.panel.isGrayOnNoData) {
this.panelState = 'no-data-state';
} else {
this.panelState = 'ok-state';
}
if ((GlobalpanelState[this.panel.id] != 'notplaycrit') & this.panelState === 'error-state') {
const music = new Audio('https://zabbix/audio/alarm_disaster.mp3').play();
if (typeof GlobalpanelState[this.panel.id] != "undefined") {
this.$panelContainer.addClass('blink');
}
GlobalpanelState[this.panel.id] = 'notplaycrit';
} else if ((GlobalpanelState[this.panel.id] != 'notplayok') & this.panelState === 'ok-state') {
const music = new Audio('https://zabbix/audio/alarm_ok.mp3').play();
if (typeof GlobalpanelState[this.panel.id] != "undefined") {
this.$panelContainer.addClass('blink');
}
GlobalpanelState[this.panel.id] = 'notplayok';
} else if ((GlobalpanelState[this.panel.id] != 'notplayhigh') & this.panelState === 'warn-state') {
const music = new Audio('https://zabbix/audio/alarm_high.mp3').play();
if (typeof GlobalpanelState[this.panel.id] != "undefined") {
this.$panelContainer.addClass('blink');
}
GlobalpanelState[this.panel.id] = 'notplayhigh';
}
} ")

Некоторые особенности:
В процессе добавления функционала все правки плагина были сделаны “на живую”, непосредственно в коде самого установленного плагина. С восьмой версии Grafana появилась проверка валидации плагина. В случае, если в коде какого-либо плагина были какие-то изменения, Grafana не подхватит его при последующей перезагрузке. Чтобы этого не произошло, плагин надо пересобрать и переподписать. Сходу пересобрать не получилось, но переподписать то, что получилось, нам это не мешает. Для этого регистрируемся на сайте Grafana, получаем API-key роли PluginPublisher. Задаем переменную окружения GRAFANA_API_KEY. Устанавливаем nodejs с npx. Устанавливаем @grafana/toolkit. Качаем исходники плагина, заменяем файлы в директории dict нашими. И запускаем из корня исходников приватное подписывание плагина: "npx @grafana/toolkit plugin:sign --rootUrls http://ваш_url_grafana/".
После чего будет получен заветный файл MANIFEST.txt, который поможет нам пройти валидацию, для этого не обходимо в директории плагина заменить файл на полученный.
Планы на будущее:
переписать плагин полностью под актуальный фреймворк использующейся в Grafana,
пересобрать и переподписать плагин уровнем community, а не private,
вернуть недостающий функционал, все возможные переменные добавить в поля редактирования,
поглотить наработки по плагину "Status By Group Panel".
BigD
Круто! А что используете для централизованного хранения логов и SIEM?
Dan_Melnikov Автор
Siem – Maxpatrol, логи – kafka+Graylog+ElasticSearch