

Приветствую, дорогие читатели, меня зовут Алексей Федулаев. Я работаю на позиции DevSecOps в компании Bimeister и делаю наши продукты безопаснее.
Данная статья будем по мотивам моего выступления на конференции Highload++ 2022, где я рассказывал про «Построение архитектуры с использованием формальных моделей безопасности». В статье мы узнаем:
Как максимально сдвинуться в Shift Left Security?
Почему важно поддерживать архитектуру в актуальном состоянии?
Как это можно делать?
Как выявлять нарушения безопасности в архитектуре?
Что такое Shift Left Security?
Сдвиг влево — это применение практик безопасности на более ранних этапах жизненного цикла продукта в процессе его разработки. На картинке ниже представлена диаграмма жизненного цикла продукта. Разработка продукта – это итерационный процесс и пройдя все этапы в итерации, процесс повторится. Сдвиг влево на данной диаграмме будет обозначать применение практик к более раннему этапу. И сегодня я бы хотел рассказать о максимальном сдвиге влево на этой диаграмме процесса разработки продукта, а именно на этап идеи/архитектуры.

Что это дает?
Сдвиг влево позволит находить проблемы с безопасностью и выявлять баги на более ранних этапах жизненного цикла продуктов, а чем раньше мы выявим проблемы, тем дешевле и быстрее мы это сможем исправить. Помимо этого, следование принципам Shift left позволит доставлять клиентам более качественные продукты.
Простой пример: ошибка в продукте, выявленная после релиза, может потребовать срочных действий, в т.ч. и сверхурочных для устранения такой ошибки. А что если этой ошибкой уже смогли воспользоваться злоумышленники? Это грозит как репутационными, так и другими потерями для компании, выпускающей данный продукт. А теперь представим, что данная ошибка была выявлена на этапе тестирования? Выглядит уже лучше, можно будет зафиксировать баг и исправить его в обычном ритме команды. Более того, это никак не сможет затронуть потребителей данного продукта. Аналогично для проверок на этапе кода различными специализированными средствами: не нужно будет тратить ресурсы команды тестирования для повторных перепроверок и стоимость бага понижается.
Вот тут мы и дошли до этапа архитектуры, этапа идеи. Выявление ошибки на таком этапе позволит максимально сократить ресурсы команды. Посудите сами: код еще не написан, а значит на его написание не потрачены ресурсы, его не нужно переписывать, и это опять сэкономленные ресурсы команды. Именно про сдвиг влево на этап архитектуры мы и обсуждаем сегодня.
Архитектура продукта — это компоненты из которых продукт состоит и связь между ними:
позволяет выявлять и исправлять ошибки на этапе идеи;
однозначная интерпретация идеи. Нет никакого испорченного телефона в понимании того, как должен строиться продукт;
эталонная модель для верификации. Мы всегда можем проверить, правильно ли мы следуем стратегии реализации;
легкий онбординг для новых людей в команде. Не нужно никого отвлекать вопросами, вся необходимая информация для понимания перед глазами.
Давайте разберем классический пример архитектуры на примере приложения, который позволяет пользователям подключать камеры и смотреть трансляции с этих камер. Изначально у нас абсолютно плоская сеть между компонентами. Архитектура представляет собой взаимодействия микросервисов по принципу “все со всеми”.

Имеются ли тут какие-то проблемы? Самая основная опасность заключается в том, что в случае взлома одного из сервисов, есть возможность беспрепятственно горизонтально перемещаться к другим сервисам, при этом они могут обрабатывать информацию разной чувствительности. Таким образом, взлом, казалось бы, незначительного микросервиса, не содержащего никакой чувствительной информации, может обернуться, по факту, более серьезной утечкой.
Давайте попробуем исправить эту ситуацию. Можем предположить, что каждому сервису необязательно общаться со всеми сервисами. Можно ограничить его взаимодействия опираясь на необходимости данного взаимодействия с другими. Тут на помощь нам придет нотация Data Flow Diagram (далее по тексту – DFD) или диаграммы потоков данных.
Как строить DFD?
Для построения DFD будем использовать следующие обозначения:
процесс (выполняет какое-либо преобразование, либо получение/отправку данных);
хранилища данных;
внешние сущности (по отношению к нашей системе);
и, непосредственно, сами потоки данных.
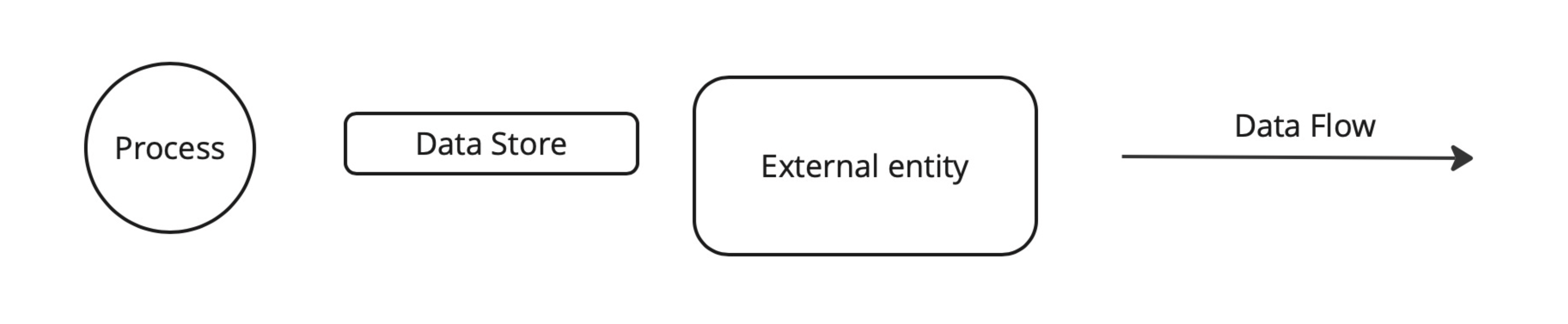
Пример DFD на изображении ниже

Также мы будем руководствоваться следующими правилами:
внешние сущности располагаются по краям;
хранилища данных не могут передавать данные между собой без процесса;
каждый процесс и хранилища данных должны иметь входные и выходные данные (т.е. у системы должны быть начальные и конечные внешние сущности).
Выбор пал на DFD, потому что:
просто;
удобно масштабировать;
основной упор на потоки данных.
А ведь данные – это важнейшая часть продуктов.
Более того, это все просто применить к микросервисам:
в качестве процесса будет выступать микросервис;
в качестве хранилищ – любые сущности для хранения данных (БД, файлы и др.);
в качестве внешних сущностей – пользователи и системы;
потоки данных остаются потоками данных.
Применим все это к нашей архитектуре
Обговорим сразу, для удобства восприятия общая схема была упрощена, в частности на ней отсутствуют потоки данных и хранилища, однако далее мы будем работать с более детализированными частями.
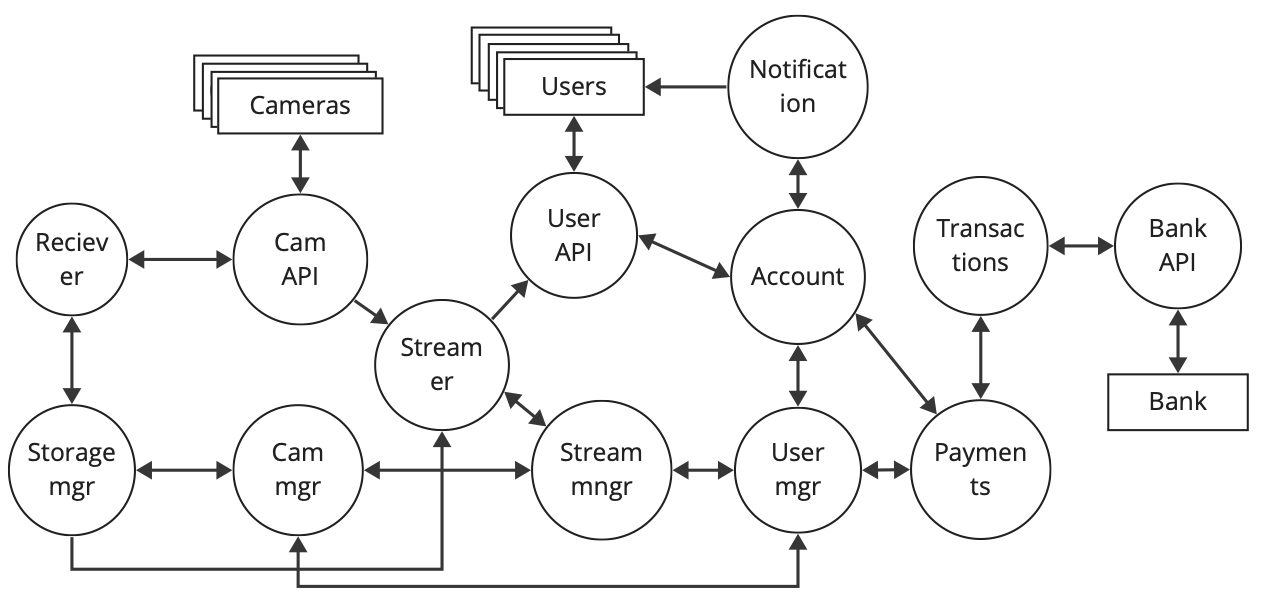
На приведенной выше архитектуре мы уже видим взаимосвязи между микросервисами и можем пройтись по трактам прохождения информации от одного микросервиса до другого. Теперь, когда мы имеем более понятную для восприятия архитектуру, как нам ее оценить? Как можно сделать выводы: безопасна ли она и какие в ней могут быть проблемы. Тут нам на помощь придут формальные модели безопасности, а именно: модель Биба и модель Белла ЛаПадула. Данные модели используются во многих современных ОС.
В данной статье я не буду приводить различные заумные и правильные определения данных моделей, мы просто обговорим простые правила для них.
Модель Биба, вы ее можете знать, как модель Мандатного контроля целостности, вводит разные уровни целостности. Для максимального упрощения введем два простых правила для данной модели: нельзя читать вверх, можно писать вниз.
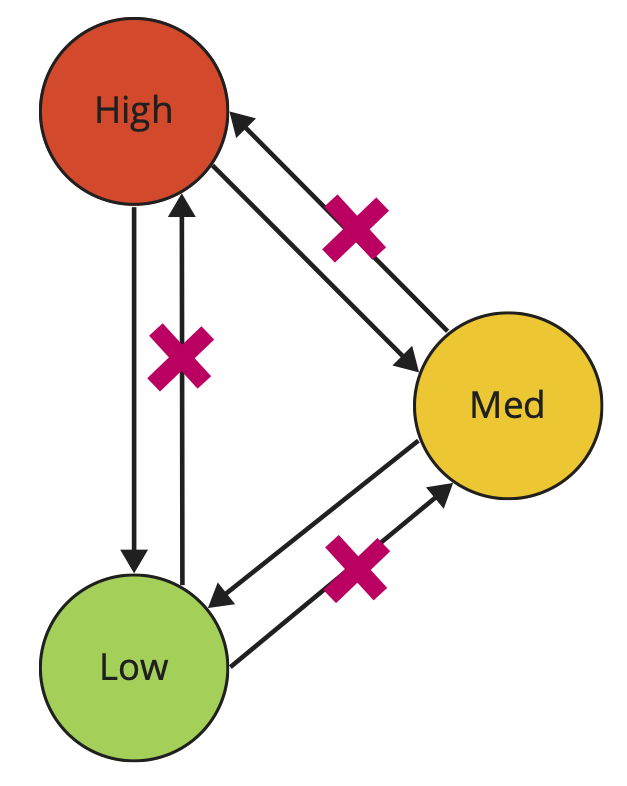
Поясню: у нас есть некие внешние для нашей системы данные, они являются нецелостными. Мы попросту не знаем, что в этих данных. Они могут содержать, как хорошие данные, так и злоумышленники могут пытаться проводить атаки на нашу систему. Соответственно, мы не можем просто так взять и затянуть эти данные в систему. Также мы не можем просто взять данные из контура с меньшим уровнем целостности данных и втянуть их наверх. В свою очередь, мы можем спокойно выдавать данные в контуры с меньшим уровнем целостности, мы знаем, что они целостные и проблем с ними нет.
Не будем обходить стороной и конфиденциальность. Модель Белла ЛаПадула или модель мандатного контроля доступа. Модель вводит разные уровни конфиденциальности информации. Мы также введем тут два простых правила: нельзя писать вниз, можно читать вверх. Многим из вас она может быть знакома на примере грифов информации (несекретно, для служебного пользования, секретно). И действительно, недопустимо, что бы секретная информация попала в несекретный контур, при этом мы можем спокойно читать несекретную информацию в более высоких контурах.
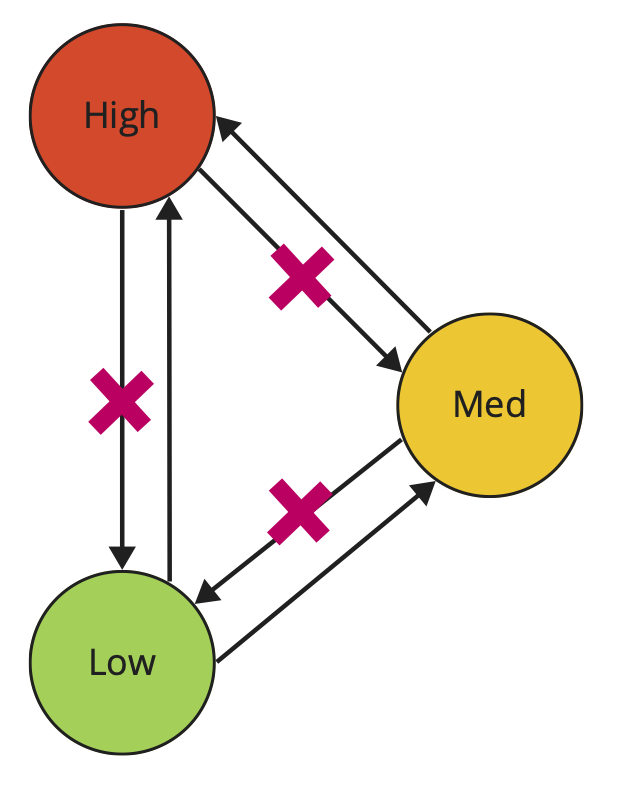
И возникает интересный момент с этими моделями. Получается это некая система, состоящая из нескольких изолированных контуров. Ведь как только мы попытаемся прочитать данные из более низкого контура или получить внешние данные, уровень нашей системы понизиться до уровня принимаемых данных, внешние данные вообще имеют наименьший уровень целостности. Аналогичное справедливо и для модели Белла ЛаПадула. Как быть тогда? Трудно представить продукт, который никак не взаимодействует с внешним миром.
Поэтому мы введем понятие: нарушение формальной модели. Это именно те места, где мы получаем низкоцелостные данные в контур с более высоким уровнем целостности, и те места, где мы выдаем данные, выше уровнем конфиденциальности, в более низкий уровень конфиденциальности. И именно в этих точках нарушений формальных моделей мы будем искать различные слабые места в нашей архитектуре. Правильно построенные процедуры нарушения формальных моделей позволят повысить доверие к данным, а также понизить конфиденциальность данных. Для этого мы будет использовать типизацию, санитизацию и валидацию.
Типизация - приведение данных к определенному типу. Например, IP-адрес камеры легко привести к типу. Аналогично и в обратную сторону, номер карты легко привести к типу и убедиться, что необходимые части закрыты звездами.
Санитизация - преобразование данных в безопасный вид. Например, удаление и экранирование небезопасных символов, удаление из данных конфиденциальных полей.
Валидация - проверки на соответствия различным алфавитам, диапазонам значений и т.д. Например, в случае использования IP-адресов v4, каждый из октетов может принимать значение не выше 255. Валидацию можно использовать и для проверки границ полей ввода, границ массивов и т.д. Аналогичным образом могут проверяться границы и значения полей выходных данных.
Соглашение об обозначениях
черным цветом – минимальный уровень (как целостности, так и конфиденциальности);
Зеленым цветом – низкий уровень;
желтым цветом – средний уровень;
красным цветом – высокий уровень;
фиолетовым – нарушения целостности;
голубым – нарушения конфиденциальности.
Оценим активы
Далее мы введем 3 уровня информации, на основании оценки рисков. Высоким риском будем считать утерю данных платежных карт, персональных данных пользователей. Средним риском считаем утерю информации с камер наблюдения. Мы также не хотим их потерять, но для примера критичность этих данных оценим ниже. И низкий риск — это утеря данных с уведомлениями, не содержащими данные пользователей. Внешние данные – это минимальный уровень.
На основании оценки активов подсветим уровни данных в нашей системе.

Взглянем на верхний уровень абстракции.

Мы можем наблюдать, как у нас появились некоторые домены информации: набор микросервисов, работающих с данными камер, с платежными данными, с уведомлениями.
Для удобства мы можем менять уровень абстракции. Например, мы можем свернуть домен с данными камеры в единый процесс обработки этих данных. Можем развернуть каждый из сервисов и внутри нарисовать DFD на модульном или функциональном уровне. Мы можем экспериментировать с границами системы. Сейчас камеры – это внешние сущности, но ничего не мешало бы нам рассмотреть эту часть системы, если бы камеры были ее частью, а мы бы их выделили во внешние сущности. Это то самое удобство масштабирования, о котором мы говорили ранее.
Отметим нарушения формальных моделей
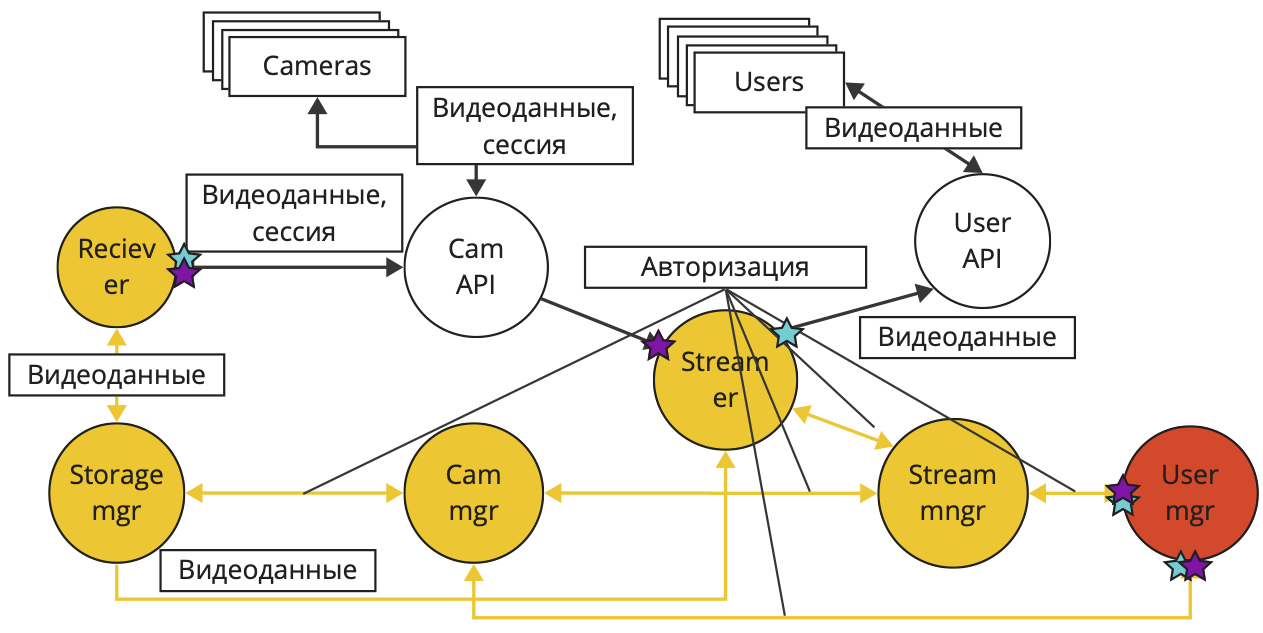
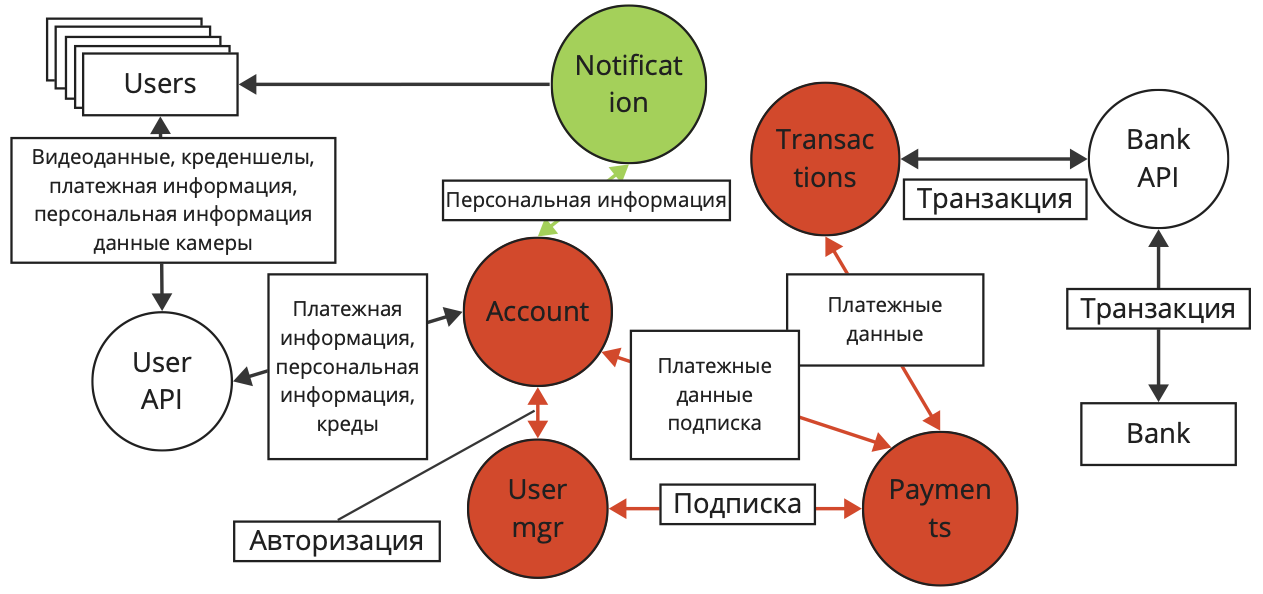
На схеме мы видим, что микросервисы Receiver и Streamer получают внешние данные, в них может быть все что угодно. Нам необходимо проверять получаемые данные. Также эти сервисы выдают данные внешним сущностям. Мы должны убедиться, что не передаем конфиденциальной информации, не предназначенной конкретному получателю. Аналогично для сервиса User Manager. В нем циркулируют данные пользователей, а он взаимодействует с сервисами более низкого уровня.
Аналогично поступим со второй частью архитектуры.

Сервисы Account, Notification, Transactions работают с внешними сущностями. Получаемые и передаваемые данные должны проходить проверки. Также происходит взаимодействие сервисов с разными уровнями: Account и Notification. При покидании данными сервиса Account происходит понижение конфиденциальности данных, а значит они не должны содержать чувствительных данных. Получаемые данные от низколцелостного сервиса тоже необходимо проверить.
Получаем общий вид архитектуры.

На архитектуре звездами отмечены потенциальные нарушения безопасности. Это и есть те слабые места в архитектуре, на которые нам нужно обратить внимание. Помним, что применение только таких методов анализа не является исчерпывающим. Например, пользователь в личном кабинете может посмотреть часть данных своей карты и свои персональные данные, значит тракт сервис Account – User легитимный. Но по этому же тракту в результате атак, теоретически, могут быть получены данные другого аккаунта, без подтверждения авторизации. Поэтому анализ архитектуры должен применяться как один из многих способов обеспечения защиты.
О чем мы забыли?
О хранилищах данных. Важно помнить, что данные могут утекать в логи. Так будет выглядеть применение моделей

Еще мы не поговорили про БД. Правила тут никак не меняются.

Так выглядит архитектура при взаимодействии с БД. Для лучшего контроля и понимания циркуляции информации желательно не допускать совместное использование баз данных, а взаимодействовать через API сервисов.
Плюсы такого подхода:
Низкий порог входа. Для такого анализа не нужны глубокие знания в информационной безопасности и понимания аспектов работы различных используемых технологий.
Контроль путей приема и передачи информации, понимание схемы ее циркуляции.
Границы информации внутри системы.
Существенное затруднение горизонтального продвижения. Увеличивается цепочка взломов до получения конфиденциальной информации, больше времени на реагирование, больше шансов заметить атаку.
Всегда есть понятная схема взаимодействия сервисов, упрощается написание, например, Network Policy для кластера.
Myclass
ивиняюсь за претензии не по теме, но когда такое вижу, то не могу это больше развидеть и всё остальное становится неинтересным. Люди не обращают на это внимания, и даже не думают, что о них, об их мыслях и образе мышления такое рассказывает больше, чем они хотели-бы.
И все архитектурные стремления "убиваются" об эту "стенку".