

Традиционно для сегментации изображений требуется большое количество размеченных данных и специализированные модели для каждого типа объектов. Однако, что если бы существовала модель, которая могла бы сегментировать любой объект на любом изображении с помощью одного щелчка мыши? И что если бы эта модель могла адаптироваться к новым объектам и изображениям без дополнительного обучения? Звучит фантастично, но такая модель уже существует! Она называется SAM (Segment Anything Model) и была разработана исследователями из Meta AI — одной из крупнейших компаний в области искусственного интеллекта.
SAM — это промптабельная система сегментации, которая может принимать разные виды запросов (текст, точки, рамки) и генерировать несколько вариантов масок для неоднозначных запросов. SAM также обладает способностью к нулевой адаптации к незнакомым объектам и изображениям без необходимости дополнительного обучения. SAM был обучен на самом большом датасете для сегментации (SA-1B), который содержит более 1 миллиарда масок на 11 миллионах лицензированных и конфиденциальных изображений. SAM также спроектирован таким образом, чтобы быть эффективным и гибким для высокого качества и скорости сегментации.
В этой статье вы узнаете подробнее о SAM и его возможностях и рассмотрим его перспективы для развития компьютерного зрения и других систем и приложений.
Основные особенности SAM
Одна из ключевых особенностей SAM — это его способность к нулевой адаптации к новым объектам и изображениям без необходимости дополнительного обучения. SAM обучен на самом большом датасете для сегментации (SA-1B), который содержит более 1 миллиарда масок на 11 миллионах лицензированных и конфиденциальных изображений. Благодаря этому SAM приобрел общее понимание того, что такое объекты и как их выделять. Это позволяет ему сегментировать любой объект на любом изображении, даже если он не встречался ему раньше. Например, SAM может сегментировать динозавра или космический корабль, несмотря на то, что он не видел таких объектов в своем датасете.
Еще одна важная особенность SAM — это его умение генерировать несколько вариантов масок для неоднозначных запросов. Иногда запрос может быть нечетким или неясным, например, "выделить цветок" на изображении с несколькими цветами. В таких случаях SAM может предложить несколько возможных масок для разных интерпретаций запроса и позволить пользователю выбрать наиболее подходящую. Это важная и необходимая возможность для решения задачи сегментации в реальном мире.
Обучение SAM: как был создан самый большой датасет для сегментации (SA-1B) с помощью модели в цикле аннотации данных
Для обучения SAM исследователи из Meta AI разработали эффективную модель в цикле аннотации данных, которая позволила им создать самый большой датасет для сегментации (SA-1B). Датасет содержит более 1 миллиарда масок на 11 миллионах лицензированных и конфиденциальных изображений. Датасет охватывает широкий спектр доменов изображений, таких как подводные снимки, снимки клеток, спортивные события и т.д.
Цикл аннотации данных состоял из следующих шагов:
Сбор изображений из разных источников, таких как Flickr, Instagram и YouTube.
Предварительное обучение модели SAM на небольшом подмножестве изображений с масками, полученными из других датасетов или с помощью полуавтоматических методов.
Использование модели SAM для интерактивной аннотации новых изображений с помощью разных видов запросов (текст, точки, рамки, полигоны).
Обновление модели SAM с помощью новых масок и повторение цикла.
После аннотации достаточного количества масок с помощью SAM исследователи использовали его продвинутый дизайн, учитывающий неопределенность, для автоматической аннотации новых изображений. Для этого они представляли SAM сетку точек на изображении и просили его сегментировать все, что находится в каждой точке. Этот метод позволил им получить более 1 миллиарда масок на 11 миллионах изображений.
Датасет SA-1B является уникальным ресурсом для исследования и развития моделей сегментации и компьютерного зрения в целом.
Эффективность и гибкость SAM: как была спроектирована и оптимизирована модель для высокой скорости и качества сегментации
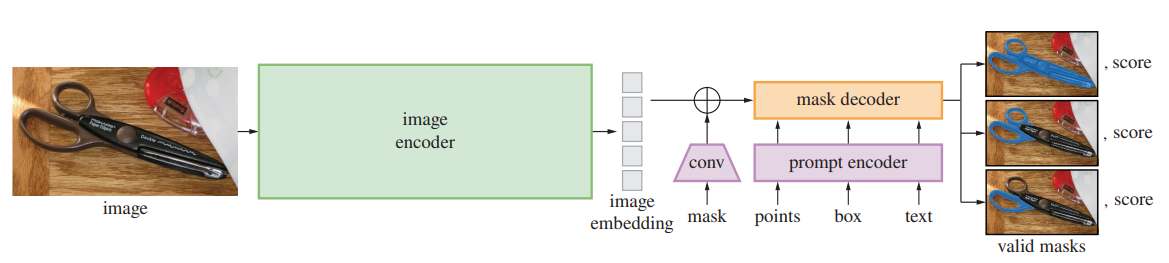
SAM — это не только мощная, но и эффективная и гибкая модель сегментации. Она спроектирована таким образом, чтобы обеспечить высокое качество и скорость сегментации при разных условиях и задачах. Для этого SAM использует следующие особенности:
Сетевая архитектура SAM основана на модели CLIP, которая использует контрастное обучение для сопоставления текста и изображений. SAM расширяет CLIP, добавляя дополнительный декодер для генерации масок. Декодер имеет несколько уровней детализации, что позволяет ему адаптироваться к разным размерам изображений и объектов.
SAM использует технику, называемую промптинг, для адаптации к разным видам запросов и задачам сегментации. Промптинг заключается в том, что модели подается специальный текстовый запрос, который указывает ей, что нужно сделать. Например, запрос "выделить собаку" скажет модели, что нужно сегментировать собаку на изображении. Промптинг позволяет модели переносить свои знания на новые домены и задачи без дополнительного обучения.
SAM учитывает неопределенность при сегментации объектов. Иногда запрос может быть нечетким или неясным, например, "выделить цветок" на изображении с несколькими цветами. В таких случаях SAM может предложить несколько возможных масок для разных интерпретаций запроса и позволить пользователю выбрать наиболее подходящую. Это важная и необходимая возможность для решения задачи сегментации в реальном мире.
SAM оптимизирован для высокой скорости сегментации. Он использует эффективные методы обработки изображений, такие как квантование и сжатие, чтобы уменьшить объем данных и вычислений. Он также использует технику, называемую предвычисление встраиваний изображений, которая заключается в том, что модель заранее вычисляет векторные представления изображений и сохраняет их в памяти. Это позволяет модели мгновенно генерировать маски для любого запроса без повторного анализа изображения.
Благодаря этим особенностям SAM является эффективной и гибкой моделью сегментации, которая может работать в режиме реального времени и адаптироваться к разным условиям и задачам.
Вывод
Это новый прорыв в области компьютерного зрения, который открывает множество возможностей для исследования и разработки моделей сегментации и других задач.SAM может быть использован в различных системах и приложениях, которые требуют выделения объектов на изображениях или видео. Например, SAM может помочь в редактировании изображений, создании контента для метавселенной, анализе медицинских снимков, распознавании лиц и сцен, обучении роботов и т.д. SAM также может быть интегрирован с другими моделями, такими как CLIP или MCC, для создания мультимодальных систем, которые могут понимать и обрабатывать текст и изображения.
SAM — это шаг к созданию фундаментальной модели для компьютерного зрения, которая может служить универсальным инструментом для решения всевозможных задач.

Комментарии (7)

Vindicar
08.04.2023 20:12+1Деталей нет, внятного пояснения принципа работы нет (кроме одной иллюстрации), ссылок на оригинальные публикации тоже нет... в общем, статья - констатация факта. "Живёт в таком-то городе Пётр Иванович Бобчинский".
Спасибо и на этом, конечно, но хотелось бы большего. Потому что уж очень смелые заявления делаются, насчёт "нулевой адаптации". Без дообучения в таких случаях никак нельзя - тут и человек-то не справится, особенно если незнакомых объектов больше одного.

lain8dono
08.04.2023 20:12+1Благодаря аниме я знаю, как выглядит разработчик вот этого всего. Примерно вот так:

Аниме называется Higashi no Eden. Помимо прочего сайфая важной сюжетнополезной штукой является приложуха на мобилки, которая очень хорошо распознаёт объекты. В 2009 году анимеха вышла. Примерно 14 лет назад, ага. Тогда подобные штуки были чем-то вроде магии.
А ещё там годнейшая завязка. ГГ появляется перед Белым Домом полностью голым, с револьвером в руке и со стёртой памятью. Вот так:



blik13
Я так и не понял на каком же количестве изображений обучали эту нейросеть.
Nikuson Автор
"SA-1B состоит из 11 миллионов разнообразных изображений с высоким разрешением, защищающих конфиденциальность, и 1,1 миллиарда высококачественных масок сегментации"
ElKornacio
Я тоже не уловил. Там использовался какой-нибудь датасет из 11 миллионов разнообразных изображений, или мне показалось?
CAJAX
Вроде там где-то в тексте однажды упоминались 11 миллионов.
dimnsk