
Как в два счета разметить большие массивы текстов с помощью моделей от OpenAI

Всем привет! Я продуктовый аналитик компании Интерсвязь, и у меня, как и у многих, часто всплывает потребность в том, чтобы «разложить по полочкам» кучу разных текстов. Например:
Я хочу знать, о чем вообще все отзывы в маркете про мой продукт.
У меня есть много писем от клиентов на разные темы, и я хочу их систематизировать.
Мне может понадобиться проанализировать старые обращения пользователей в техподдержку, которые не были размечены.
Для этого есть множество материалов про NLP, и чаще всего даже джуны, изучив только их часть, могут дать более-менее вменяемый результат. Кроме того, множество крупных компаний и вовсе имеют в штате специалистов по Data Science.
Но что делать, если:
Слабо понимаешь, что такое NLP;
Нет ресурсов, чтобы поднять у себя крутую модель с кучей параметров;
Роадмап NLP-специалистов в компании расписан на год вперед и для тебя нет места.
На помощь приходит OpenAI и их API. Открытое и доступное в РФ на момент написания статьи.
Про это и хотелось бы рассказать.
Для работы понадобятся:
Начальные навыки python;
И, конечно же, надежный источник кофеина.
Готовим данные ????????
Для работы понадобится среда для python. Будет удобнее, если вы умеете работать с jupyter или аналогами.
Понадобятся библиотеки от OpenAI и ещё несколько для работы с данными.
Установка библиотек:
pip install numpy==1.24.2 pandas==2.0.0 tqdm==4.65.0 openai==0.27.4 tiktoken==0.3.3 plotly==5.14.1Импортируем библиотеки и готовим окружение.
import openai
import tiktoken
import numpy as np
import pandas as pd
from os import environ
from tqdm import tqdm
from openai.embeddings_utils import get_embedding
openai.api_key = environ.get('OPENAI_TOKEN')
tqdm.pandas()Вместо environ.get('OPENAI_TOKEN') можно просто вставить строку с ключом, но использовать переменные окружения безопаснее.
Загрузим датасет с заранее предразмеченным вручную классом (столбец class). Это нужно, чтобы потом сравнить качество ручной (правильной) и автоматической разметки.
Ваш датасет, конечно, может не содержать столбец class.
Датасет из примера содержит 118 обращений в чат медицинской организации.
df = pd.read_csv('../data/appeals.csv')
df
Заодно глянем на баланс предразмеченных классов.
df['class'].value_counts()
#
# Результаты анализов 36
# Изменение времени приема 25
# Пластическая хирургия 25
# Запись на прием 18
# Справки 14Далее нам потребуются эмбеддинги сообщений. Это такое представление текста в виде вектора чисел, полученных от ml-модели. По идее, можно закодировать слова даже вручную, но качество числового представления сильно влияет на итоговый результат, и нынешние ml-модели неплохо определяют скрытые зависимости слов в тексте.
Выбираем, какая модель от OpenAI нам нужна для получения эмбеддингов, и решим, как они будут закодированы. Исходя из рекомендаций OpenAI лучше подходят text-embedding-ada-002 и cl100k_base.
embedding_model = "text-embedding-ada-002"
embedding_encoding = "cl100k_base"Далее мы почистим наш датасет, убрав слишком длинные сообщения. Этот пункт можно спокойно пропускать, если вам не жалко вашего баланса OpenAI.
max_tokens = 100 # Задаем максимальную длину токенов для сообщения
encoding = tiktoken.get_encoding(embedding_encoding)
# Рассчитываем длину сообщений в токенах
df["n_tokens"] = df['message'].apply(lambda x: len(encoding.encode(x)))Заодно узнаем, сколько мы потратим остатка на балансе.
print(f"Потратим: ${df['n_tokens'].sum() * 0.0004 / 1000}")
# Потратим: $0.0011896Убираем слишком длинные сообщения, чтобы не потратить слишком много токенов.
df = df[df["n_tokens"] <= max_tokens]Получаем эмбеддинги!
Обычно это занимает около минуты на сотню сообщений.
Советую использовать progress_apply из tqdm, чтобы понять, как долго еще ждать.
df["embedding"] = df['message'].progress_apply(lambda x: get_embedding(x, engine=embedding_model)),
# 100%|██████████| 118/118 [01:04<00:00, 1.82it/s]Сохраним эмбеддинги отдельно.
matrix = np.vstack(df['embedding'].values)
matrix.shape
# (118, 1536)Итак, у нас есть тексты и их числовые представления. Пора разбить эту кучку на кучки поменьше с помощью кластерного анализа.
Поиск кластеров с использованием K-means
from sklearn.cluster import KMeans
n_clusters = 5 # Кол-во кластеров можно менять по усмотрению
kmeans = KMeans(n_clusters=n_clusters, init="k-means++", random_state=42)
kmeans.fit(matrix)
labels = kmeans.labels_
df["сluster"] = labelsK-means — один из наиболее популярных способов разметить примеры на кластеры. На данном этапе количество кластеров можно подобрать визуально, зная примерно количество «тем», которое можно встретить в вашем датасете. А вообще подбор оптимального количества кластеров это тема, которую нужно рассматривать отдельно.
Полученные кластеры можно отобразить в 2D (и даже в 3D!). Это нужно, чтобы визуально понять, как сильно кластеры разделились. Для этого хорошо подходит t-SNE.
from sklearn.manifold import TSNE
import matplotlib
import matplotlib.pyplot as plt
tsne = TSNE(n_components=2, perplexity=15, random_state=42, init="random", learning_rate=200)
vis_dims2 = tsne.fit_transform(matrix)
x = [x for x, y in vis_dims2]
y = [y for x, y in vis_dims2]
for category, color in enumerate(["purple", "green", "red", "blue", "yellow"]):
xs = np.array(x)[df.сluster == category]
ys = np.array(y)[df.сluster == category]
plt.scatter(xs, ys, color=color, alpha=0.3)
avg_x = xs.mean()
avg_y = ys.mean()
plt.scatter(avg_x, avg_y, marker="x", color=color, s=100)
plt.title("Отображение кластеров в 2d используя t-SNE")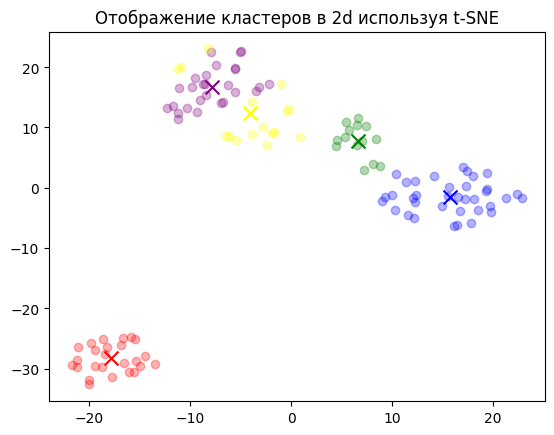
Как мы видим, четыре из пяти кластеров расположились относительно рядом. Это говорит о том, что они приблизительно схожи по тематике. Тогда как кластер снизу слева находится далеко от остальных.
Получаем названия для кластеров
Для того, чтобы примерно понять суть кластера и подобрать название, мы возьмём по пять случайных сообщений в каждом кластере и попросим модель gpt-3.5-turbo из ChatGPT описать, что у них общего, ради хайпового заголовка потому что сейчас это одна из самых качественных моделей для суммаризации от OpenAI. В то же время и модель text-davinci-003 отлично подойдёт, но будет стоить в 10 раз дороже.
Стоит обратить внимание на то, что стоимость генерации выйдет дороже получения эмбеддингов. Стоимость можно ограничивать:
Контролируя размер переменной
promt. Это затравка, которая передаётся в модель для получения ответа на неё.Контролируя размер получаемого ответа, изменяя параметр
max_tokens.
msg_per_cluster = 5 # Количество сообщений на кластер
for i in range(n_clusters):
joined_messages = "\n".join(
df[df['сluster'] == i]
.['message']
.sample(msg_per_cluster, random_state=42)
.values
)
promt = f'Что общего у этих обращений?\n\nОбращения:\n"""\n{joined_messages}\n"""\n\nТема:'
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "user",
"content": promt
}
],
temperature=0,
max_tokens=128, # Этот параметр можно изменять для более подробного или короткого описания
top_p=1,
frequency_penalty=0,
presence_penalty=0,
)
print(f"Тема кластера №{i}: ", response['choices'][0]['message']['content'].replace("\n", ""), '\n')
print(joined_messages)
print('\n\n')
# Тема кластера №0: Изменение времени приема у врача.
# Как отменить изменение времени приема?
# Есть ли ограничения по количеству раз, когда можно изменить время приема?
# Могу ли я изменить время приема через интернет?
# Какие данные нужно предоставить для изменения времени приема?
# Могу ли я выбрать время приема врача?
# Тема кластера №1: Медицинские справки и их получение.
# Какие медицинские справки нужны для трудоустройства?
# Какие медицинские справки нужны для получения водительского удостоверения?
# Как получить медицинскую справку?
# Какие медицинские справки нужны для выезда за границу?
# Могу ли я получить медицинскую справку по почте или электронной почте?
# Тема кластера №2: Пластическая хирургия.
# Добрый день, я хочу сделать операцию по подтяжке лица. Как долго будет идти восстановление после операции?
# Добрый день, я хотел бы узнать о возможностях пластической операции по удалению рубцов.
# Здравствуйте, я хотел бы узнать, какую процедуру можно сделать для коррекции формы бровей?
# Добрый день, мне не нравится форма моего живота. Какие есть варианты пластической коррекции?
# Здравствуйте, я хочу сделать операцию по изменению формы ушей. Какие ограничения будут после операции?
# Тема кластера №3: Результаты анализов.
# Какие услуги могут быть оказаны на основе результатов анализов?
# Как мне получить результаты анализов?
# Какие данные нужно предоставить для получения результатов анализов?
# Как понять, что означают результаты анализов?
# Могу ли я получить результаты анализов у лечащего врача?
# Тема кластера №4: Запись на прием к врачу.
# Как мне записаться на прием к врачу?
# Какие документы нужны для записи на прием?
# Как отменить запись на прием?
# Какие данные нужно указать при онлайн-записи?
# Могу ли я записаться на прием через интернет?Кластер №2 как раз тот, который «отдалялся» на графике с t-SNE. И он действительно тематически далёк от других тем датасета.
Проверочная работа
У нас теперь есть описание кластеров от gpt-3.5-turbo. Эти названия можно сопоставить с тем, как мы разметили сообщения в начале.
df['cluster_name'] = df['сluster'].replace(
{
0: 'Изменение времени приема',
1: 'Справки',
2: 'Пластическая хирургия',
3: 'Результаты анализов',
4: 'Запись на прием'
})Посмотрим баланс классов теперь:
df['cluster_name'].value_counts()
# Результаты анализов 36
# Пластическая хирургия 25
# Изменение времени приема 24
# Запись на прием 19
# Справки 14Он немного изменился. Выведем ошибки.
df[df['class'] != df['cluster_name']]
Их всего 4 на 118 сообщений. И на самом деле их сложно назвать ошибками, т.к. эти сообщения действительно можно отнести к двум кластерам сразу.
В итоге за $0.01 (за эмбеддинги и суммаризацию текстов) мы разметили больше сотни сообщений быстрее, чем за пять минут!
Даже если учесть, что в части данных мы точно ошибемся, количество ошибок будет вряд ли больше, чем при человеческой разметке.
Однако стоит учитывать, что никакая модель без дообучения не будет знать нюансов и бизнес-процессов компании. Так что лучше использовать эти инструменты для поверхностной аналитики, а не как инструмент для разбора «изнутри».
За референс взят эксперимент openai. Весь код и датасет выложен в GitHub.
Комментарии (4)

Lailore
10.04.2023 07:42А упоковка данных не поможет сэкономить? (Спрашиваю, как дилетант)
Например вырезать все приветствия, а так же распространенные словосочитания "медицинские справки" и т.п. привести к специальному коду?

svetofor_columb Автор
10.04.2023 07:42Да, поможет. Даже можно посчитать сумму токенов от сообщений. Если их 8-10, то, скорее всего, это приветствия или формальные фразы, которые можно спокойно пропустить.
Но так же это могут быть и фразы, на которые стоит обратить внимание. Например это положительные отзывы или благодарность.
К тому же, выделением ключевых фраз, можно будет выстрелить себе в ногу. Потому что словосочетания могут быть упомянуты вскользь, а на самом деле основная суть сообщения может быть в другом.
Очень сильно зависит от области применения и стоит быть аккуратным.
ramiil
А как вы заставили тикитокен работать с текстом на кириллице? У меня получилось только разбить кириллический текст на отдельные символы, а не на би/триграммы.
svetofor_columb Автор
Честно — никак. Здесь смысл токенизации только в подсчёте стоимости, поэтому n-граммы тут не нужны. Судя по всему OpenAI так же считают токены. Потому что количество потраченных токенов сходится со значением в личном кабинете.