
Полагаться на абстракции, а не на конкреции
В первые несколько лет реализации программного проекта можно добиться многого. С небольшой командой и правильными инструментами мы можем быстро предоставить функциональные особенности, которые удовлетворят как компании, так и их клиентов. На ранних стадиях проекта доставка часто приоритетнее архитектуры, но архитектура должна развиваться, если мы хотим, чтобы программное обеспечение разрабатывалось и поддерживалось в долгосрочной перспективе. Любой проект, который живет дольше нескольких лет, будет претерпевать изменения. Бизнес-требования поменяются, разработчики приходят и уходят, сервисы платформы, от которых зависит программное обеспечение, устаревают и заменяются, среды развертывания меняются, а новые технологии предлагают новые возможности, в то время как прежние технологии устаревают.
Абстракция лежит в основе архитектуры программного обеспечения. Отделение what (что) от how (как), позволяет нам сосредоточиться на основной бизнес-проблеме, которую мы пытаемся решить, не теряясь в деталях конкретной реализации.
Абстракция
Следует полагаться на абстракции, а не на конкреции.
-- Принцип инверсии зависимостей
Конкреция - это когда мы полагаемся на имплементации, а не абстракции. Рассмотрим следующее приложение, которое предоставляет REST API для получения статьи блога из базы данных SQL:
(ns app.db
(:require [next.jdbc.sql :as sql]))
(defn get-article-by-id
"`data-source`: javax.sql.DataSource, `id`: article id"
[data-source id]
(sql/get-by-id data-source :article id))(ns app.server
(:require [app.db :as db]
[reitit.ring :as ring]))
(defn get-article [data-source request]
(let [id (get-in request [:path-params :id])
article (db/get-article-by-id data-source id)]
{:status 200
:body article}))
(defn router [data-source]
(ring/router
[["/api/article/:id" {:get {:parameters {:path {:id int?}}}
:handler #(get-article data-source %)}]]))(ns app.system
(:require [app.server :as server]
[next.jdbc :as jdbc]))
(defn init [db-spec]
(let [data-source (jdbc/get-datasource db-spec) ;; javax.sql.DataSource
router (server/router data-source)] ;; reitit.core/Router
...))В примере get-article связана с имплементацией get-article-by-id; маршрутизатор связан с get-article. В результате возникает эффект пульсации, который требует, чтобы маршрутизатор и обработчик знали о data-source, но единственная функция, которой нужно знать о data-source, — это get-article-by-id. Нам нужна действующая база данных SQL для тестирования текущей реализации маршрутизации.
Мы можем инвертировать зависимости, используя абстракцию. Если мы используем ту же сигнатуру, что и db/get-article-by-id, но удалим data-source, у нас останется функция, которая принимает id и возвращает article:
(fn get-article-by-id [id]
article)Мы можем настроить имплементацию нашей абстракции, используя функции высшего порядка:
(fn [id]
(db/get-article-by-id data-source id))
(partial db/get-article-by-id data-source)
#(db/get-article-by-id data-source %)Теперь мы можем передать функцию в server/get-article, куда ранее мы передали data-source, в результате чего получим чистую функцию:
(defn get-article
"`get-article-by-id`: (fn [id] article)"
[get-article-by-id request]
(let [id (get-in request [:path-params :id])
article (get-article-by-id id)]
{:status 200
:body article}))Действуя аналогичным образом, мы можем удалить первый параметр get-article, чтобы сформировать нашу следующую абстракцию — обработчик запроса:
(fn handler [request]
response)
#(server/get-article get-article-by-id %)Последнее изменение необходимо внести в маршрутизатор; нам нужен способ передачи обработчика. В нашем примере показан один маршрут, но на практике, скорее всего, их будет много; мы можем использовать функцию, которая принимает ключ route и возвращает обработчик:
(fn route->handler [route]
(fn handler [request]
response))Мы можем реализовать route->handler с помощью карты:
{:get-article #(server/get-article get-article-by-id %)}Теперь мы разделили маршрутизатор и обработчик и устранили зависимость от data-source:
(ns app.server
(:require [reitit.ring :as ring]))
(defn get-article
"`get-article-by-id`: (fn [id] article)"
[get-article-by-id request]
(let [id (get-in request [:path-params :id])
article (get-article-by-id id)]
{:status 200
:body article}))
(defn router
"`route->handler`: (fn [route] (fn [request] response))"
[route->handler]
(ring/router [["/api/article/:id" {:get {:parameters {:path {:id int?}}}
:handler (route->handler :get-article)}]]))На первый взгляд, это может показаться небольшим изменением, но версия, прошедшая рефакторинг, существенно отличается: теперь функции являются чистыми и могут быть протестированы изолированно без запущенной базы данных.
Мы можем использовать вместо get-article-by-id любую функцию с такой же сигнатурой без каких-либо изменений в коде app.server. Это может быть стаб/мок во время тестирования, обертка, добавляющая мониторинг/логирование/кэширование, или альтернативная реализация, которая получает статью из другой базы данных или внешнего источника.
Маршрутизатор имеет единственную обязанность: направить входящий запрос в обработчик. Обработчик также несет единственную ответственность: преобразование входящего запроса во внутренний вызов, где выполняется действие.
Протоколы
Протокол — это еще одна форма абстракции, которую мы можем использовать для разделения модулей. Такой подход в большей степени объектно-ориентированный, чем функциональный, но протоколы могут быть полезны, когда мы хотим получить более формальную абстракцию, или когда имеет смысл сформировать целостный набор моделей поведения. В предыдущем примере мы использовали единственную функцию для абстракции при извлечении статьи; в качестве альтернативы можно использовать паттерн репозитория, популярный в Domain Driven Design (Предметно-ориентированное проектирование):
(ns app.article-repository)
(defprotocol ArticleRepository
(create [_ article])
(get-by-id [_ id])
(publish [_ id])
(archive [_ id])
(update-title [_ id title]))(ns app.db
(:require [app.article-repository :refer [ArticleRepository]]
[next.jdbc.sql :as sql]))
(defrecord SqlArticleRepository [data-source]
ArticleRepository
(get-by-id [_ id]
(sql/get-by-id data-source :article id))
...)(ns app.server
(:require [reitit.ring :as ring]
[app.article-repository :as article-repository]))
(defn get-article [article-repository request]
(let [id (get-in request [:path-params :id])
article (article-repository/get-by-id article-repository id)]
{:status 200
:body article}))Интерфейс в этом примере является более формальным, в том смысле, что мы запрашиваем пространство имен хранилища и ссылаемся на него напрямую, что отличается от первоначального использования ссылки на функцию, определенную через defn, поскольку мы ссылаемся на абстракцию, а не на протокол, определенный в app.db.
Он более многословен, но передавать экземпляры протоколов может быть предпочтительнее, чем передавать множество функций, особенно когда требуется много тесно связанных между собой моделей поведения; в конечном счете, это сводится к вопросу стиля. Одним из преимуществ протоколов перед функциями является то, что читателю более понятно, от чего зависит функция; мы используем require для запроса пространства имен, и наш код указывает туда, где определен протокол. С другой стороны, это не настолько гибко и лаконично, как функциональная альтернатива.
Композиция
Мы достигли развязки путем введения абстракций, следующим шагом будет объединение наших функций в систему. Для начала создается data-source и используется анонимная функция для обертывания db/get-article-by-id, в результате чего получается функция (fn [id] article). get-article-handler создается таким же образом, в результате чего получается функция (fn [request] response), которая помещается внутрь карты для построения абстракции route->handler:
(ns app.system
(:require [app.db :as db]
[app.server :as server]
[next.jdbc :as jdbc]))
(defn init [db-spec]
(let [data-source (jdbc/get-datasource db-spec) ;; javax.sql.DataSource
get-article-by-id #(db/get-article-by-id data-source %) ;; (fn [id] article)
get-article-handler #(server/get-article get-article-by-id %) ;; (fn [request] response)
route->handler {:get-article get-article-handler} ;; (fn [route] (fn [request] response))
router (server/router route->handler)] ;; reitit.core/Router
...))Одним из компромиссов такого подхода является то, что он приводит к дополнительной проводке; функции должны быть переданы их зависимостям и связаны вместе, чтобы сформировать систему. Перенаправление означает, что мы больше не можем перейти к определению get-article-by-id в пространстве имен сервера. Стоит ли идти на компромиссы — решать вам; абстракция может оказаться преждевременной для недолговечных проектов, но развязка поможет обеспечить более крупные проекты легкостью сопровождения.
Составление больших систем может быть сложной задачей. Процессы должны запускаться и останавливаться в определенном порядке, а граф зависимостей может получиться большим, если следовать принципу инверсии зависимостей. Мы часто обращаемся к таким фреймворкам, как Component или Integrant, для помощи в построении больших систем, на момент написания статьи Integrant является рекомендуемым вариантом на нашем Clojure Radar.
Код для построения системы с помощью Integrant похож на код, который мы определили в привязке let:
(defmethod ig/init-key ::get-article-by-id [_ {:keys [data-source]}]
#(db/get-article-by-id data-source %))
(defmethod ig/init-key ::get-article-handler [_ {:keys [get-article-by-id]}]
#(server/get-article get-article-by-id %))
(defmethod ig/init-key ::router [_ {:keys [route->handler]}]
(server/router route->handler))С системой, объявленной в карте:
{::data-source {:db-spec db-spec}
::get-article-by-id {:data-source (ig/ref ::data-source)}
::get-article-handler {:get-article-by-id (ig/ref ::get-article-by-id)}
::router {:route->handler {:get-article (ig/ref ::get-article-handler)}}}По мере роста системы мы можем разделить ее на целостные модули, с картами, создаваемыми для каждого из них, а затем смердженные в более крупные системы. Мы можем использовать ig/pre-init-spec чтобы убедиться, что зависимости соответствуют ожиданиям:
(s/def ::data-source #(instance? javax.sql.DataSource %))
(defmethod ig/pre-init-spec ::get-article-by-id [_]
(s/keys :req-un [::data-source]))Здесь хорошо работают протоколы; мы можем валидировать их с помощью satisfies? и отлавливать проблемы с подключением при инициализации системы:
(s/def ::article-repository #(satisfies? ArticleRepository %))
(defmethod ig/pre-init-spec ::get-article-handler [_]
(s/keys ::req-un [::article-repository]))
(defmethod ig/init-key ::get-article-handler [_ {:keys [article-repository]}]
#(server/get-article article-repository %))Такие фреймворки, как Component или Integrant, помогают нам при создании больших систем, но мы должны следить за тем, чтобы они оставались на периферии - проектные решения, которые принимаются с помощью фреймворков, могут повлиять на дизайн вашего проекта. Если вы обнаружите, что вынуждены использовать определенную структуру данных в своем внутреннем коде, для соответствия ограничениям фреймворка, вам следует подумать, помогает или мешает это вашей архитектуре.
Стабильность
Зависимости должны быть направлены в сторону устойчивости.
-- Принцип стабильных зависимостей
В каждой системе есть стабильные и нестабильные компоненты. В Clojure мы можем считать функцию стабильной, если она ссылочно прозрачна, и наоборот, мы можем считать любую функцию, которая общается с внешним миром или зависит от чего-то не соответствующего ссылочной прозрачности, непостоянной.
В нашем примере база данных является непостоянным компонентом, что, в свою очередь, делает нестабильными пространства имен сервера и системы. Красные стрелки на диаграмме показывают компоненты, которые являются нестабильными из-за своих зависимостей:

Благодаря введенным абстракциям пространство имен server больше не зависит от волатильной зависимости; теперь это стабильный компонент.

Альтернативная реализация с протоколом ArticleRepository имеет дополнительные стрелки, показанные светло-зеленым цветом, которые указывают на него:

Пример: Приложение для управления проектами
На таком тривиальном примере преимущества развязки, возможно, не столь очевидны. Рассмотрим более сложный пример приложения для управления проектами, в котором пользователи могут создавать проекты и управлять тикетами в рамках проекта, с отправкой уведомлений при изменении статуса тикета:
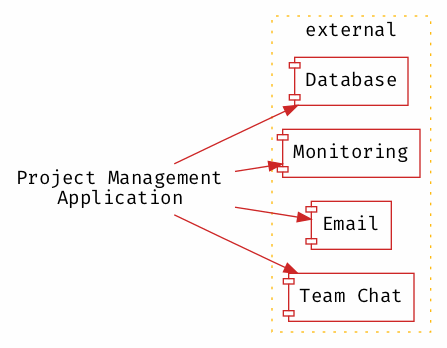
Управляемые сервисы являются нестабильными компонентами, и их имплементация требуется непосредственно в ходе проекта, что приводит к созданию тесно связанной системы, в которой все является волатильным. Хотя некоторые компоненты в системе должны быть изменчивыми, крайне нежелательно, чтобы полностью все в ней было волатильным.

Многослойные архитектуры
Hexagonal (гексагональная) архитектура, Onion (луковичная) архитектура, Clean (чистая) архитектура и Functional Core(функциональное ядро), Imperative Shell (императивная оболочка) — все они помещают высокоуровневую бизнес-логику в ядро приложения и используют слои для того, чтобы низкоуровневые детали, такие как база данных и транспортные протоколы, оставались на периферии.
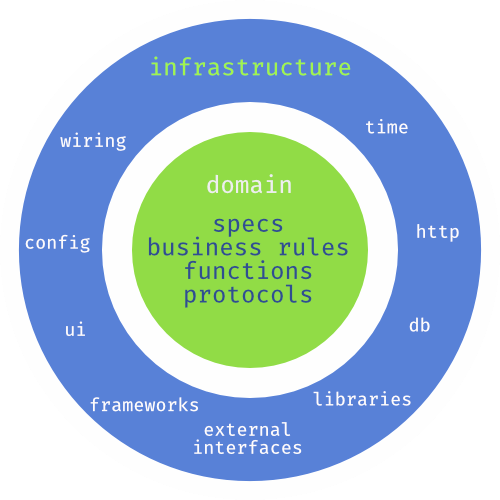
Мы можем разделить приложение для управления проектами на слои, отделив основной домен от специфики реализации. В результате получается слой domain, который зависит только от абстракций и не знает о внешних зависимостях; обратите внимание, что стрелки никогда не направлены от домена к слою инфраструктуры. Абстракции реализуются в слое infrastructure и соединяются вместе, образуя систему:
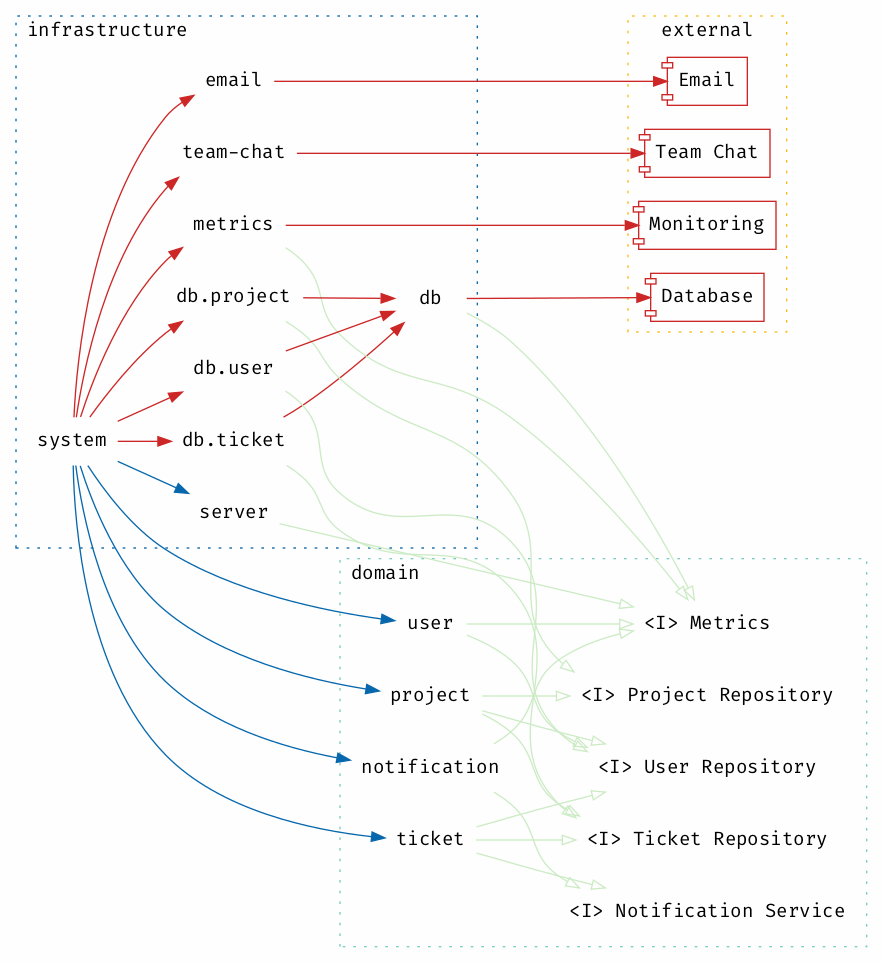
В многоуровневой архитектуре больше узлов и больше границ, где были введены абстракции, но граф не такой глубокий, и все компоненты в домене теперь стабильны. Нестабильные компоненты инфраструктуры обеспечивают имплементации абстракций в доменном слое, связи в доменном слое остаются прежними, но теперь обеспечиваются с помощью абстракций.
Заключение
Осознайте, что когда вы упрощаете что-то, зачастую вы в конечном итоге получаете гораздо больше. Упрощение - не означает подсчитать количество. Я бы предпочел иметь больше вещей, висящих красиво, ровно, не скрученных вместе, чем всего пару вещей, завязанных в узел. И самое прекрасное в том, чтобы разделить их, - тогда у вас будет гораздо больше возможностей изменить их, а именно в этом, как мне кажется, и заключается главное преимущество.
-- Рич Хикки (Rich Hickey) Простое сделать легким
Строгое разделение "что" и "как" — это ключ к тому, чтобы сделать "как" чьей-то проблемой. Если вы сделали это действительно хорошо, то можете переложить работу над "как" на кого-то другого. Вы можете сказать: "Механизм базы данных — выясни, как сделать эту вещь" или " Логическая схема — выясни, как найти это". Мне не нужно вникать.
-- Рич Хикки (Rich Hickey) Простое сделать легким
Абстракции очень важны, если мы стремимся разрабатывать большие системы, которые будут простыми и удобными для обслуживания в долгосрочной перспективе. Взгляните на свою собственную кодовую базу и определите, где вы привязаны к определенной реализации, нарисуйте граф и посмотрите, куда указывают все стрелки, найдите нестабильные компоненты и рассмотрите возможность внедрения абстракций для разделения модулей и отделения what от how.
Проектирование программного обеспечения — это хорошо изученная и понятная задача; его паттерны и принципы широко применяются с начала века, а многие идеи, лежащие в основе решений, появились за несколько десятилетий до этого. Многие из этих идей в равной степени применимы к функциональному программированию, и они могут помочь нам разрабатывать приложения, которые будут поддерживаться в долгосрочной перспективе.
Приглашаем всех желающих на открытый урок «Написание игры "Game Of Life" на Clojure». На этом уроке вы увидите, как классическая задача computer science — Game of Live, может быть реализована на Clojure. Также мы обсудим разные способы визуализации работы алгоритма, как представить состояние игры с помощью персистентных структур данных и как вести разработку интерактивно через REPL. Записаться на урок можно на странице курса "Clojure Developer".