

История этого эксперимента началась где-то в 2022 году с желания фильтровать поступающую из разнородных каналов информацию. В современном мире люди вынуждены находиться в бурном потоке всевозможных новостей, публикаций и коммерческих объявлений и вручную пытаться найти в этом потоке то, что им нужно.
Для этого используются:
Поисковые системы - Google, Яндекс
Социальные сети - VK, Facebook, ...
Системы мгновенного обмена сообщениями - Telegram, WhatsApp, ...
Прочие сервисы - RSS, YouTube, Instagram, Linkedin, ...
Было бы здорово объединить все эти потоки информации в одно русло и автоматизировать уведомления о таких сообщениях, которые релевантны заранее определенным критериям. То есть требуется что-то вроде поисковой системы, фильтрующей входной поток информации.
Можно представить поступающую информацию как поток сообщений, которые имеют данные (aka payload) и метаданные (key-value map). Для простоты, в первом приближении можно считать что ключи и значения метаданных - это текст. Тогда можно выразить подписку на интересующие сообщения как "ключ: шаблон". Шаблон должен поддерживать хотя бы минимальные возможности регулярных выражений.
Существующие Pub/Sub системы не позволяют этого достичь, они ограничены возможностью подписки на "канал" или "топик" (далее - просто "канал"). В некоторых из них, таких как Kafka или NATS есть зачатки фильтрации этих каналов с применением шаблонов (примитивных "глобов" или полноценных регулярных выражений).
Пример wildcard subject из NATS:
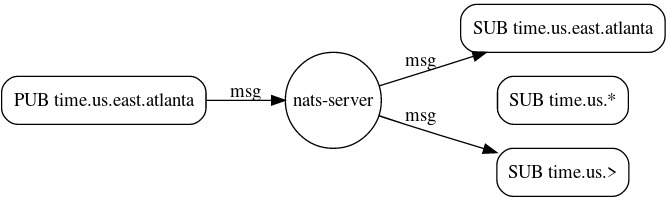
Как видно, возможности подписки по произвольным полям метаданных сообщений в NATS нет.
Пример из Kafka Consumer API:
public void subscribe(Pattern pattern, ConsumerRebalanceListener listener)В случае Kafka фильтрация происходит вообще на стороне клиента (consumer), что приводит к тому, что весь поток данных льётся всем клиентам с надеждой на то, что они сами там разберутся, что им нужно.
В существующих решениях процесс нахождения совпадающих подписок по входящему сообщению либо слишком ограничен (NATS), либо приводит к перебору всех шаблонов в лоб (Kafka). Допустим, система содержит миллиарды сложных подписок для разных пользователей. Тогда каждое входящее сообщение будет приводить к перебору всех зарегистрированных условий, чтобы проверить каждое на предмет совпадения.
Задача сводится к задаче поиска всех совпадающих шаблонов по примеру текста. Обычно шаблоны применяются с точностью до наоборот, для поиска всех удовлетворяющих ему текстов, но это - обратная задача. Необходим алгоритм и структура данных, позволяющие за менее чем линейное время находить все подходящие шаблоны. Что-нибудь вроде префиксного/суффиксного дерева, позволяющего делать такой поиск за логарифмическое время. Существуют алгоритмы, делающие нечто похожее, например Aho-Corasick. Но по ряду ограничений, таких как необходимость пересчитывать и хранить в памяти функции ошибок эти алгоритмы также не являются по-честному горизонтально масштабируемыми.
Для решения этой задачи удалось применить специальную структуру данных, которая была названа Kiwi Tree. Слово Kiwi здесь является сокращением от Key-Input WIldcard. Следует рассматривать Kiwi Tree как рабочий вариант решения, возможно ещё не самый эффективный.
Для начала потребуется определить, какие типы шаблонов нужно поддерживать. В реализации Kiwi Tree было решено остановиться на формате, приближенном к Unix Globs, который описывает специальные символы, такие как "*", "?" и некоторые другие. Эти глобы должны быть разделены на т. н. "нейтральные" и остальные. Нейтральный глоб может означать только 1 символ. Это различие между глобами понадобится в дальнейшем.
Вставка шаблона в Kiwi дерево изначально работает как в обычном префиксном дереве. Все встреченные глобы заменяются на соответствующие непечатаемые коды, чтобы отличать узлы с глобами от узлов с символами вроде "*".
символ |
код |
нейтральность |
описание |
* |
1 |
нет |
последовательность символов, в т. ч. пустая |
? |
2 |
да |
одиночный символ |
$ |
3 |
да |
буква |
# |
4 |
да |
цифра |
... |
... |
... |
... |
Таблица ASCII позволяет использовать до 31 различных символов глобов, которые можно заменить на непечатаемые коды. Код 0 зарезервирован для корневого узла дерева, которое может соответствовать пустой строке.
Тогда шаблон - это строка, содержащая обычные символы и символы глобов в произвольном порядке. Пример:
foo*bar?
Алгоритм в текущей реализации не возволяет использовать в шаблоне более одного не нейтрального глоба, поэтому следующий шаблон будет некорректным:
foo*bar*
Главная особенность алгоритма - направление поиска меняется при встрече не-нейтрального глоба на противоположное. То есть от корня дерево является префиксным, но любое поддерево узла с кодом, например 1 (что соответствует символу глоба "*") является суффиксным.
исходный шаблон |
префикс |
не-нейтральный глоб |
суффикс |
путь в дереве |
*foo |
[*] |
foo |
[*]oof |
|
* |
[*] |
[*] |
||
?foo*bar |
[?]foo |
[*] |
bar |
[?]foo[*]rab |
foo |
foo |
foo |
||
hello* |
hello |
[*] |
hello[*] |
|
hello? |
hello[?] |
hello[?] |
||
hello*? |
hello |
[*] |
[?] |
hello[*][?] |
Для поиска достаточно поместить в контекст исходный текст и по мере продвижения по дереву выкидывать символы, пока не останется пустой символ или глоб, который вызывает совпадение с остатком текста.
Шаги алгоритма поиска:
-
Если текущий узел содержит данные и удовлетворяет текущему контексту поиска, тогда добавить текущий путь в дереве в результаты. Критерии совпадения с контекстом поиска:
Текущее направление дерева - префиксное (не-нейтральные глобы не встречались) и в контексте больше нет символов исходного текста (пусто).
Направление - суффиксное (есть в пути не-нейтральный глом) и оставшиеся символы исходного текста удовлетворяют ему.
-
Взять следующий символ исходного текста из контекста:
Забирать с начала исходного текста, если направление - префиксное.
Забирать с конца, если - суффиксное.
-
Цикл по дочерним узлам:
-
Сравнить выбранный на шаге (2) символ с:
Если символ дочернего узла является печатаемым символом и совпадает, то продолжить поиск для такого дочернего узла. Выкинуть символ как потраченный.
-
Иначе в дочернем узле - код глоба. Тогда:
Если глоб нейтральный, проверить, что он удовлетворяет символу текста (например коду 1, соответствующему глобу "?" будет удовлетворять любой символ) - продолжить поиск для такого дочернего узла. Выкинуть символ как потраченный.
Иначе глоб не-нейтральный. Запомнить его в контексте, чтобы знать, что под-дерево становится суффиксным. Продолжить поиск для такого дочернего узла без выкидывания символа исходного текста.
-
Иллюстрация Kiwi дерева для наглядности:

Эта структура данных была успешно перенесена на MongoDB, а алгоритм был реализован в виде сервиса с gRPC API. С исходным кодом можно ознакомиться здесь: https://github.com/awakari/kiwi-tree
В следующей статье я планирую рассказать, как это применяется в полноценной Pub/Sub системе, построенной на основе Kiwi Tree. Stay tuned.
Комментарии (5)

dyadyaSerezha
19.06.2023 11:27Интересно сравнить время передачи (и затраты CPU/сети) среднего сообщения со временем CPU, затраченным на фильтрацию по шаблонам. При каком количестве шаблонов дешевле передать сообщение, чем фильтровать его.

akurilov Автор
19.06.2023 11:27Куда передать? Вы предлагаете каждое сообщение отправлять всем клиентам, как в кафке?
wataru
Интересная задача.
Если ограничится только одной "*" в шаблоне, то очевидно, что можно легко проверить на совпадение с запросом отдельно префикс до и суффикс после "*" для каждого шаблона. Вопрос в том, как можно сравнивать со всеми шаблонами сразу.
Вот как ваш алгоритм обрабатывает два шаблона "abc*ff" и "abcdef"?
Я правильно понял, что на строке "abcdxf", после поглощения "abc" алгоритм пойдет сразу в обе ветки — и по "f" с конца и по "d" сначала? Т.е. в худшем случае он может обойти все дерево на каждый запрос?
Вообще, задача очень похожа на вот эту с литкода. Только тут в префиксах и суффиксах есть всякие "?#" — удовлетворяющие одному из некоторых наборов символов.
Вообще, есть известный трюк в таких задачах на суффиксы и перфиксы: вы символы вашего суффикса/префикса используйте поперменно. Из корня дерева будут только символы для префиксов. Из детей корня — первые символы всех суффиксов. Потом опять префиксы и т.д.
Если в каком-то запросе суффикс короче префикса, то соответствующие переходы заменяются на какой-нибудь '\0', означающий, что переход есть, но ничего не потребляет. Полученное таким образом дерево концептуально проще. Не надо помнить, в каком вы сейчас режиме.
Потом, можно строку-запрос перемешать в виде символ-сначала, символ-сконца, второй, предпоследний,… Получите строку в 2 раза длинее, но тут уже не надо думать про начало-конец вообще. Только знать, что вы нашли совпадение, если пришли в допускающую вершину на каком-то префиксе входной строки.
А потом уже для этой задачи сопоставления строки с шаблоном только из нейтральных глобов можно построить НКА, который будет принимать только строки удовлетворяющие какому-то шаблону. А уж дальше его можно детерминизировать и тогда любой запрос будет обрабатываться за O(длина запроса), а не за O(сумма длинн всех шаблонов) в худшем случае, как у вас.
akurilov Автор
Да, так как задача - найти все шаблоны.
У меня тоже есть устойчивое ощущение, что полученную реализацию можно улучшать.