

Привет, Хабр, меня зовут Дима. В последние пару лет занимаюсь аналитикой, отвечаю за данные в Почте Mail.ru. Развиваю аналитическое хранилище данных и инструменты для работы с ними. Мы плотно работаем со стеком Hadoop, Hive, Spark, Clickhouse и Kafka. Я хочу остановиться на некоторых аспектах работы с данными в Spark: как мы храним петабайты информации и как выполняем запросы к ним?
Прежде всего поделюсь своими практическими наблюдениями. Расскажу как в нашем хранилище мы превратили 7 петабайт в 0,5 петабайт, что позволило сэкономить годовой бюджет по закупке серверов. И также расскажу о ключевых проблемах с данными, знание о которых помогло бы вам построить своё классное хранилище без последующей переделки.
Содержание
Архитектурные паттерны в хранилище Почты
Эффективное хранилище данных
-
Форматы хранения данных
Текстовый формат хранения данных
Параллельная обработка данных в Spark
Сжатие данных
Колоночный формат хранения данных
Запись ORC-файлов
Запросы к данным в Spark
Про стек и архитектурные паттерны в хранилище Почты
Мы с командой Data-инженеров строим аналитику для самой большой электронной почты в России. У нас действительно огромный сервис, и возникает очень много интересных задач, связанных с данными.
Немного фактов о нашем стеке. Hadoop — это один из инструментов для хранения больших объёмов. Наши данные для аналитики занимают более 15 петабайт. Много? С одной стороны, да, но с другой стороны, для сервиса, который посещают более 25 млн пользователей ежедневно не так уж и много :)
Прежде всего я рассматриваю Hadoop как распределённое файловое хранилище. Hadoop сам делит файлы на блоки и делает по три копии каждого блока на разных серверах кластера. В случае отказа одного из ЦОДов сохранённые файлы останутся доступным для работы с ним.
В Hadoop Почты более 130 серверов, на каждом по 512 ГБайт ОЗУ и примерно по 10-12 обычных HDD-дисков. Серверы расположены в трёх ЦОДах. Для работы с данными мы используем Spark — инструмент для запуска задач в кластере Hadoop. Если вы совсем не знакомы со Spark, то я рекомендую почитать некоторые ознакомительные статьи,
например эту. В конце этой статьи тоже есть список полезных ссылок.
У нас вполне состоявшаяся, можно сказать классическая архитектура для работы с данными. Они разделены в хранилище на слои: RAW, ODS, DDS и CDM. Про такую архитектуру есть очень классная статья.
Для моделирования данных мы используем подход под названием activity schema. Он очень прост: это плоская широкая таблица, в которой больше 1000 колонок. Данные заранее обогащены всеми нужным колонками для продуктовой аналитики. Для работы с activity schema мы используем Clickhouse. Хранилище данных Clickhouse на момент написания статьи занимает два петабайта. Но моделирование данных — это тема для отдельной статьи.
Также не могу не упомянуть Николая Голова и чат «Между скобок», в котором обсуждают много интересных тем. Коля, спасибо тебе большое за статьи, вебинары, ответы в чатах и советы по работе с данными!
Как организовать эффективное хранилище данных?
Допустим, мы планируем хранить серверные логи наших сервисов, чтобы использовать наши данные для построения продуктовой аналитики. Как их хранить и работать с ними? Что мы можем извлечь из наших данных? Какое DAU у нашего сервиса? Как пользователи распределены по странам, регионам, полу и любым другим характеристикам? Что если потребуется строить аналитику по разным событиям: сколько уникальных пользователей нажало на кнопку, сколько человек пролистало до конца страницы? Как получить конверсию из показов рекламных баннеров в клики (это ещё называют CTR или воронкой)? Могут потребоваться задачи с более сложными воронками: «показ» + «клик» + «покупка товара на стороннем сайте», и т. д.
Всё это — типовые R&D-задачи для продуктовой аналитики. То, с чем мы работаем ежедневно. Но нам с вами нужно рассмотреть примеры того, как нужно организовать хранение данных, чтобы получать ответы на подобные вопросы. Нужно учесть что объемы данных огромные. Наши запросы должны выполняться эффективно и быстро, а хранилище должно быть оптимальным по размеру.
Итак, задачу и вопросы прояснили, погнали дальше!
Форматы хранения данных
Данные можно хранить в различных форматах: в строковом или колоночном, в текстовом или бинарном. Можно сжимать данные различными способами, о них тоже поговорим. Иногда хорошо подходит один формат для хранения, а иногда нужен другой. Есть много нюансов при выборе того или иного формата. Предлагаю разобраться в этом по-порядку.
Текстовый формат хранения данных
Часто логи приложения или сервиса записываются в текстовом формате. Это удобно, их легко читать и интерпретировать. По текстовым логам достаточно просто искать нужную информацию при помощи команды grep, или, как мы ещё говорим, «грепать по логам». Удобно, но до определённого момента: как только логи вырастают до десятков гигабайтов в день, их обработка становится долгой. Обычно текстовые логи хранятся в Hadoop в RAW-слое и сжимаются алгоритмом: gzip, bz2, zstd, zlib или каким-то другим.
Допустим, мы разместили в HDFS текстовые логи нашего сервиса. Для примера я скопировал образец настоящих логов к себе в песочницу:
-bash-4.2$ hdfs dfs -du -h -s /home/shveenkov/log_store/raw
22.5 G 67.5 G /home/shveenkov/log_store/raw
Команда du показывает размер данных 22,5 Гб, а также размер с учетом фактора репликации (Replication Factor, RF). В нашем Hadoop хранилище используется RF3, то есть наши данные реально займут 67,5 Гб на дисках хранилища.
Посмотрим на сами файлы, важно понимать, с чем мы имеем дело:
-bash-4.2$ hdfs dfs -du -h -s /home/shveenkov/log_store/raw/* | sort -k1 -n | tail -5
152.3 M 457.0 M /home/shveenkov/log_store/raw/h1686255025938-510.dat.gz
153.0 M 459.0 M /home/shveenkov/log_store/raw/h1686255025938-509.dat.gz
154.3 M 462.9 M /home/shveenkov/log_store/raw/h1686255025938-500.dat.gz
155.4 M 466.3 M /home/shveenkov/log_store/raw/h1686255025938-507.dat.gz
155.6 M 466.9 M /home/shveenkov/log_store/raw/h1686255025938-508.dat.gzАга, файлики сжатые gzip, примерно по 150 Мб каждый. Посмотрим на общее количество файлов:
-bash-4.2$ hdfs dfs -ls /home/shveenkov/log_store/raw | wc -l
296Взглянем и на содержимое одного из логов, посмотрим на несколько строк. Для удобства выведем три строки, каждую отделив ещё одним символом пустой строки:

Видно, что это слабоструктурированные логи. Команде Data-инженеров часто приходится работать именно с такими текстовыми логами, выделять из них нужную информацию — парсить: раскладывать отдельные части логов по колонкам таблицы в базе данных, делать логи более структурированными.
Что в них есть полезного? Они содержат информацию об активности клиентских приложений — Почты, Облака, Главной страницы и т. д.: клики, показы, различные статистические события, тайминги работы приложения; всё то, что может помочь нам получить представление о работе отдельных частей наших сервисов и приложений.
Цветом в логах выделены важные фрагменты (примеры):
имя хоста на который пришёл запрос:
is-radar54;дата и время события:
1686315866;идентификатор сервиса, который прислал событие:
p=resplash;email пользователя:
email=bar%40mail.ru;тип события:
t=ml_news_show;IP-адрес пользователя:
85.249.20.54;user agent пользователя:
Mozilla/5.0 (Windows NT 10.0; Win64; x64)...
Примечание: настоящие адреса почты заменены на несуществующие.
Всё это — ценная информация для аналитики. Она поможет нам ответить на вопросы, которыми мы задавались в начале статьи.
Для начала попробуем прочитать эти логи и подсчитать количество строк. Будем использовать Spark.
Примечание: далее в статье будут примеры кода на Spark с пояснениями. Это вовсе не значит, что вам нужно быть гуру в Spark. По мере погружения в хранение данных мы будем комментировать и разбирать примеры их поведения. Рассмотрим примеры и посмотрим, как ведёт себя Spark-приложение. И вместе ответим на вопрос: «почему так?»
from pyspark import SparkContext
from pyspark.sql import SparkSession
# создаем спарк сессию
spark = (
SparkSession.builder
.appName('spark logs')
.enableHiveSupport()
.getOrCreate()
)
# читаем файлы как текст в дата фрейм
df = spark.read.text('/home/shveenkov/log_store/raw')
# получаем количество строк
df.count()
326509208Со Spark мы обычно работаем через Jupyter-notebook. Обратим внимание на некоторые важные моменты в работе нашего приложения:

Spark-приложению потребовалось чуть меньше минуты для обработки 296 сжатых лог-файлов размером 22,5 Гб. Это достаточно быстро. Spark крутой, а самое главное — наш код лаконичный, занимает буквально две строчки, а проделывает большую работу.
Обратите внимание на то, как Spark выполняет наш код. Он создал в Hadoop execution engine 32 контейнера для исполнения (Executors), а также суммарно выделил 160 ядер (Cores) в нашем кластере и выполнил 240 задач (Tasks). Мы используем Dynamic allocation для Spark, в таком случае он выделяет нужные ему ресурсы по мере необходимости. Одному контейнеру выделяется 5 ядер, которые используют общую память контейнера. В нашей конфигурации контейнер (Executor) ограничен 14 Гб памяти. Это обусловлено количеством доступной памяти и процессорных ядер на серверах, а также характером выполняемых задач. Ресурсы для запуска Spark-приложений подбираются эмпирически.
Параллельная обработка данных в Spark
Здесь мы не станем погружаться в подробности запуска Spark, но в некоторых моментах нужно разобраться. Как Spark читает все эти текстовые файлы? Как он с ними работает? Как он делает работу параллельной?
Spark разбивает всю работу на этапы (Stages), у нас их две. Каждый Stage разбивается на отдельные задачи, которые выполняются контейнерами на отдельных ядрах. Задачи выполняются параллельно, это сердце Spark. Выполнение всех задач координируется программой Spark driver. Подробно почитать о Spark можно в материалах, приведённых в конце статьи.
Прежде всего необходимо подсчитать количество строк в каждом из файлов (Stage1), а затем сложить общее количество строк (Stage2). Обрабатывать каждый файл можно независимо от других. Поэтому Spark сделал одну задачу для каждого текстового файла. Он выполнил все задачи параллельно и сложил итоговое количество строк во всех файлах. В нашем примере количество задач не может быть более 296 (столько файлов). Spark сам подбирает их оптимальное количество, в данном случае он разбил Stage на 240 задач.
Так выглядит статистика выполнения Stage в инструменте Spark-UI:

Видно, что Spark прочитал 22,5 Гб данных, что соответствует их размеру на диске. Промежуточные результаты работы Stage 1 были записаны в так называемый Shuffle, данные оттуда используются в Stage 2. Понятно, что количество строк — это несколько байтов, и поэтому размер Shuffle оказался маленьким, всего 13,8 Кб.
Очень полезно перейти по ссылке в Stage1 и посмотреть сводную статистику по всем завершенным задачам.

Видно, сколько выполнялись наши задачи, медианный размер одного входного файла
90 Мб, файлы содержали по 1,2 млн строк и обрабатывались по 5 секунд. На следующем Stage в Shuffle одной задачей было записано 59 байтов. Очень важно посмотреть на колонки Min и Max в этой таблице и сравнить их значения с медианой.
Например, может оказаться так, что одни файлы весят килобайты, а другие — гигабайты. Такие данные называют перекошенными (или проблемой Data Skew). Такой перекос — всегда плохо. Почему это может быть проблемой для нас? Как мы помним, один файл читается одним ядром в одной задаче, поэтому мелкие файлы могут быть обработаны за секунды, а большие будут обрабатываться часы. Выполнение приложения будет ждать, пока не закончится обработка самого большого файла. Это сильно замедлит работу.
Важно понимать, что при работе со строковыми форматами, с текстовыми данными, один файл не может быть обработан несколькими задачами. Нельзя разбить большой файл и прочитать его параллельно, потому что Spark не умеет читать текстовый файл с «середины». Для параллельной обработки текстовых данных они должны быть разбиты по файлам достаточного размера. Слишком большие могут замедлить работу приложения, потому что не хватит параллельности их обработки, а много мелких файлов потребуют частого переключения контекста между задачами.
Как подобрать оптимальный баланс? Можно привязаться к размеру блока в HDFS и делать файлы не меньше его. Поэкспериментируйте на своих данных и задачах.
Сейчас проблемы перекоса у нас нет, всё хорошо. Мы объективно понимаем распределение размеров данных в сводной статистике. Да, некоторые файлы немного больше, но это не критично. Перекосом считается разница на порядок или больше. Мы ещё вернёмся к проблеме перекоса в данных и разберём на примере, как с этим бороться.
Сжатие данных
Наши данные сжаты алгоритмом gzip. Какие ещё варианты возможны?
Можно разделить алгоритмы сжатия на два типа:
алгоритмы, ориентированные на сильное сжатие: gzip, zlib;
алгоритмы, ориентированные на быструю распаковку: snappy.
Дело в том, что мы можем сильно сжать наши данные и сохранить их на диск. Они могут понадобиться один или два раза в год. Самое главное, что нам потребуется их распаковать, а это не такая частая операция. Нам важно, чтобы данные занимали как можно меньше места в нашем хранилище, и не имеет особого значения, если алгоритм распаковки будет потреблять много ресурсов и займёт немало времени.
Другое дело, если наши данные нужно постоянно распаковывать и обрабатывать. В таком случае нам важна скорость распаковки и длительность выполнения наших запросов. Потребуется, чтобы запросы выполнялись максимально быстро и потребляли минимум ресурсов сервера. Нам не так важно, если данные в сжатом виде будут занимать больше места, лишь бы обрабатывались быстро.
Алгоритмы сильного сжатия — это gzip и zlib, алгоритм быстрой распаковки — snappy. Последний сжимает данные примерно на 30 % хуже, чем zlib, но при этом потребляет меньше ресурсов процессора.
Так как и чем сжимать? Выберите профиль нагрузки под ваши данные и используйте один из доступных алгоритмов. Мы сжимаем логи с помощью zlib, потому что нам важно их долговременное хранение. При проблемах с обработкой очень полезно иметь сырые данные для их повторной обработки.
Запросы по текстовым данным в Spark
Подумаем над такой задачей: нам нужно достать адреса почты из наших текстовых логов и подсчитать количество уникальных. В таком случае нам потребуется прочитать 22,5 Гб данных, распарсить в них нужные колонки и затем обработать.
Попробуем подтвердить эту гипотезу, написав несколько строк кода на Spark:
import pyspark.sql.functions as F
# опустим код для создания spark-сессии
# читаем текстовые логи в Spark дата фрейм
df = spark.read.text('/home/shveenkov/log_store/raw')
rx = r'email=([^& ]+)'
(
df
.filter(
col('value').rlike(rx) # фильтруем регуляркой
)
.select(
F.regexp_extract('value', rx, 1).alias('email') # достаем из текста email
)
.distinct() # считаем количество уникальных email-лов
.count()
)Даже если вы не работали со Spark, код выглядит предельно просто. Запустим его в Jupyter-notebook:

В этот раз для Spark-приложения выделено чуть больше ресурсов, суммарно 185 ядер для выполнения всех расчётов. Конвейер отработал примерно за 1,5 минуты.
С помощью Spark-UI получим статистику выполнения конвейера:

Мы подтвердили гипотезу, что для извлечения адресов почты из текстовых данных необходимо прочитать их полный объём — 22,5 Гб. Также мы видим, что после чтения и распаковки в Shuffle записано всего лишь 902,3 Мб данных. Можно сделать интуитивное предположение, что это и есть полезный объём адресов с учётом их размещения в памяти Spark-приложения.
Если обрабатывать данные нужно редко и нам не важна производительность конвейера, то можно использовать и текстовые логи. Они удобны для интерпретации, а Spark без проблем с ними работает.
В нашем примере очень мало данных, в реальности их бывает гораздо больше. Например, для логов Почты 3 Тб сжатых данных за сутки — это вполне обычное дело. Что если нам нужно решить ту же самую задачу: подсчитать количество уникальных адресов почты по логам, но получить статистику по дням за год? Можно оценить объём, который придётся прочитать и распаковать: 3 Тб × 365 дней. Это концептуально очень много.
Как сделать так, чтобы для извлечения адресов из логов достаточно было бы читать только нужную информацию, а не всю строку? Для этого как раз нужны колоночные форматы данных. Сначала немного поговорим о них, а затем попробуем распарсить наши логи в колонки и решить аналогичные задачи по обработке данных.
Колоночный формат хранения данных
Мы рассмотрели преимущества и недостатки текстового формата данных. Колоночные форматы устроены немного иначе. В Hadoop поддерживаются Parquet, ORC и другие. Мы не будем рассматривать различия между ними, это не столь важно сейчас. Главное понимать принципы работы с данными в колоночных форматах. Остановимся на формате ORC, в основном мы работаем с ним. Структура ORC-файла:

Данные в ORC-файле упорядочены, или отсортированы. Сортировка очень важна, и мы к ней ещё вернёмся. Данные нарезаются на группы строк, их называют страйпами (Stripe). Каждый Stripe — это бинарный блок данных размером 250 Мб. Важно, что в страйпе строки разбиты на отдельные колонки.
Кроме того, данные каждой отдельной колонки сжаты. Принципы и алгоритмы тут такие же, как и рассмотренные нами выше. Важно понимать, что сжатие по колонкам может дать куда больший эффект (по сравнению со сжатием текстовых данных по строкам), особенно если информация в колонках повторяется. Также нет никаких проблем сжимать большое количество null-значений. Попробуем всё это подтвердить на практических примерах с нашими логами.
Это ещё не всё. Каждый страйп содержит раздел Index Data, который позволяет позиционировать чтение отдельных колонок. По сути, содержит указатель на начало и конец данных колонки. Здесь ключевое отличие от текстовых форматов заключается в том, что мы читаем и разжимаем данные отдельной колонки. Для извлечения адресов почты нам не нужно читать всю строку лога. Это может сильно уменьшить объёмы данных для чтения и обработки.
Но и это ещё не всё. Каждый страйп хранит некую статистику по значениям для каждой колонки. Пусть у нас есть табличные данные, которые мы записали в ORC-файл. Данные отсортированы по колонкам event_name и user_id. У ORC-файла два страйпа, логически это можно представить так:

Иногда данные в stripe meta называют «индексами», но это не совсем так. Это не btree-индекс по данным.
Разберём первый страйп из таблицы-примера. Мы видим, что колонка event_name содержит только одно значение “click” во всех строках. В stripe meta для этой колонки сохранены минимальное и максимальное значение, и они совпадают. Второй страйп (в отличие от первого) для этой же колонки в stripe meta содержит разные min- и max-значения. Это всё потому, что второй страйп содержит строки с разными событиями.
Представьте себе задачу: требуется извлечь все строки, у которых значение колонки event_name равно “open”. Другими словами — выполнить SQL-запрос:
SELECT user_id FROM events WHERE event_name=“open”
Как нам может помочь в этом stripe meta? Мы сможем прочитать метаданные из каждого stripe, проанализировать min- и max-значения для col1 и решить нужно ли нам распаковывать данные из колонки user_id. Первый страйп мы можем полностью пропустить и не трогать данные из колонок.
Таким образом, минимальные и максимальные значения колонки позволяют нам эффективно фильтровать явно неподходящие под запрос данные. Это повышает эффективность: мы можем читать только нужные интервалы строк, не тратя время на ненужные.
Блок stripe мета содержит не только min/max по колонке, но и:
min/max для каждой колонки;
sum: сумму всех значений;
has_null: флаг not null-значений;
count: количество строк;
bloom filter: опциональный фильтр Блума.
Всё это статистическая метаинформация, которая может сильно ускорить запросы, оптимизировав index condition push down, group by-запросы и другие.
Немного забежим вперёд и посмотрим структуру конкретного ORC-файла при помощи команды:
-bash-4.2$ hive --orcfiledump /home/shveenkov/log_store/ods/part-00033-... ec3b-c000.zlib.orc
Processing data file /home/shveenkov/log_store/ods/part-00033-ab03c695-27d0-4f91-a803-128d51e6ec3b-c000.zlib.orc [length: 181954422]
Structure for /home/shveenkov/log_store/ods/part-00033-ab03c695-27d0-4f91-a803-128d51e6ec3b-c000.zlib.orc
File Version: 0.12 with FUTURE
Rows: 2698038
Compression: ZLIB
Compression size: 262144
Type: struct<host:string,dttm:bigint,params_raw:string,email:string,ip_address:string,user_agent:string>
Stripe Statistics:
Stripe 1:
Column 0: count: 250880 hasNull: false
Column 1: count: 250880 hasNull: false bytesOnDisk: 65453 min: is-radar03 max: is-radar67 sum: 2508800
Column 2: count: 250880 hasNull: false bytesOnDisk: 245446 min: 1686260908 max: 1686344303 sum: 423064099280029
Column 3: count: 250880 hasNull: false bytesOnDisk: 14181704 min: __radars_preprod=1&dwh=%7B%22country_id%22%3A%22188%22%2C%22province_id%22%3A%22468%22%2C%22region_id%22%3A%22256%22%2C%22duration_type%22%3A%22instantly3%22%7D&t=adman-c-api&oid=kyAJN9skM92jj3HtmdRd&o_ss=5354%2C5428%2C5454%2C5448.w&uid=1982&pgid=lind1ic1.zlg&v=1&email=bar%40mail.ru&skipdwh=false&i=status_hit%3A329.89999997615814%2Cstatus_sc-instantly3_hit%3A329.89999997615814&o_v=1770&vid=2Thhdk3M4FII00000h1ML4II&r=https%3A%2F%2Fe.mail.ru%2Finbox%2F&p=octavius max: vid=3zzDhQ2uR6II00000b1AH4YI&p=touchmail&t=adman-ya-cntx&oid=693TN2KCtdxdPJZ96rSZj&pgid=liotbewu.arm&split=sDWH22767s42s5565.2s3992.5as3992.5s104s&email=foo%40inbox.ru&v=1&i=load%3A1%2Cload_instantly3%3A1&dwh=%7B%22country_id%22%3A%2247%22%2C%22province_id%22%3A%222249%22%2C%22region_id%22%3A%222249%22%2C%22duration_type%22%3A%22instantly3%22%7D&uid=18&r=https%3A%2F%2Fmail.ru%2F sum: 75118211
Column 4: count: 250880 hasNull: false bytesOnDisk: 58368 min: aaa@bk.ru max: baz@mail.ru sum: 4072199
Column 5: count: 250880 hasNull: false bytesOnDisk: 56406 min: 101.137.48.34 max: 99.208.10.106 sum: 3316516
Column 6: count: 250880 hasNull: false bytesOnDisk: 54955 min: Agent Android #no_user_id# ic1buNetbFsKbPsz 22.11.0(800861) Android_10_29 SM-A022G max: okhttp/4.9.3 sum: 24561768
Stripe 2:
Column 0: count: 225280 hasNull: false
Column 1: count: 225280 hasNull: false bytesOnDisk: 56095 min: is-radar03 max: is-radar67 sum: 2252800
Column 2: count: 225280 hasNull: false bytesOnDisk: 203592 min: 1686260908 max: 1686344305 sum: 379894449771036
Column 3:
…Мы можем увидеть количество строк в ORC-файле, алгоритм сжатия, размер сжатых данных, структуру колонок, а также статистику по колонкам для каждого страйпа. Всё это поможет понять нам, насколько хорошие ORC-файлы мы записали. А также мы сможем разобраться, насколько поможет статистика в страйпе при работе с данными.
Мы уже работали с текстовыми файлами в Spark и понимаем, что каждый файл обрабатывается отдельной задачей. А как быть с ORC-файлами? В отличие от текстовых файлов в ORC все страйпы можно обработать параллельно, независимо друг от друга. Поэтому колоночное хранение позволяет обрабатывать данные гораздо эффективнее. Однако запись в колоночном формате может потребовать больше ресурсов. Создание ORC-файла можно сравнить с полной перезаписью таблицы в реляционной базе данных.
Осталось проверить все наши гипотезы и утверждения. Перейдём к примерам: попробуем записать данные в колоночном формате и поработать с ними.
Запись ORC-файлов
Запись колоночных файлов играет ключевую роль в эффективности хранилища. Именно этот важный момент позволил провернуть с данными Почты трюк со сжатием. И у нас всё получилось, 7 Пб данных превратилось в 0,5 Пб. Это позволило нам целый год не заказывать серверы. Разберем подробности на примере.
Функция для парсинга текста на отдельные колонки приведена ниже:
import re
from urllib.parse import unquote
rx_log = re.compile(r'^(\S+) ([^:]+)\:\S+\s+(?:\d+) \S+ radar\[\d+\]\: (.+)$')
unparsed_row = {'is_parsed': False}
def parse_log(row):
row_value = row['value']
rv = rx_log.match(row_value)
if not rv:
return unparsed_row
host, dttm, params_raw = rv.groups()
other_split = params_raw.split('|RD|', 2)
if len(other_split) < 2:
return unparsed_row
params, ip = other_split[0], other_split[1]
if ip == '-':
ip = None
ua = None
if len(other_split) == 3:
ua = other_split[2]
email = None
col_p, col_t = None, None
for pkv in params.split('&'):
try:
pk, pv = pkv.split('=', 1)
if not pv:
break
except ValueError:
break
pk = unquote(pk)
pv = unquote(pv)
if pk in ('email', 'e'):
email = pv
elif pk == 'p':
col_p = pv
elif pk == 't':
col_t = pv
return {
'is_parsed': True,
'host': host,
'dttm': int(dttm),
'params_raw': params,
'service': col_p,
'event_name': col_t,
'email': email,
'ip_address': ip,
'user_agent': ua,
}Реализация функции не так важна, можно не углубляться в её код. Функция parse_log просто достаёт нужные нам колонки из текста, который она получила на вход. Двигаемся дальше.
Запустим в Jupyter-notebook код, который читает текстовые данные, обращается к Spark RDD API и вызывает функцию парсинга строки текстового лог-файла:
from pyspark.sql.types import IntegerType, BooleanType, StringType, LongType
from pyspark.sql.types import StructType, StructField
# читаем текстовые лог файлы
df = spark.read.text('/home/shveenkov/log_store/raw')
df = (
df
.rdd
.map(parse_log) # для каждой строки лога парсим данные
.filter(lambda row: row['is_parsed']) # фильтруем только то, что распарсилось
)
# создаем схему дата фрейма и сам дата фрейм
schema = StructType([
StructField('host', StringType()),
StructField('dttm', LongType()),
StructField('params_raw', StringType(), True),
StructField('service', StringType(), True),
StructField('email', StringType(), True),
StructField('event_name', StringType(), True),
StructField('ip_address', StringType(), True),
StructField('user_agent', StringType(), True),
])
df_out = spark.createDataFrame(df, schema)Осталось записать данные в HDFS. Запускаем код для записи data-фрейма в Jupyter-notebook:
output_path = '/home/shveenkov/log_store/ods'
(
df_out
.repartition(100) # делаем 100 ORC-файлов
.write
.mode('overwrite')
.option('compression', 'ZLIB')
.format('orc')
.save(output_path)
)Код для парсинга и записи ORC-файла максимально простой, понятный, декларативный и краткий. Я бы хотел обратить ваше внимание на вызове repartition(100). Он приводит к дополнительному Stage из-за потребности сделать Shuffle, случайно раскидать данные по 100 партициям, и уже для каждой партиции записать ORC-файл. То есть на выходе получим 100 ORC-файлов.
Как мы уже выяснили запись ORC-файла — не совсем тривиальный процесс, он требует ресурсов и времени. Поэтому целесообразно разбивать запись всего объёма данных на несколько частей и для каждой делать свой ORC-файл.
Нам необходимо выполнить дополнительный Shuffle, потому что нужно контролировать количество файлов на выходе. Партиций на предыдущем Stage может быть слишком мало, в таком случае ORC-файлы будут записываться очень долго. Или партиций может быть слишком много, тогда мы запишем много ORC-файлов, в каждом из которых будет по одному неполному страйпу, это тоже плохо с точки зрения дальнейшей обработки. Количество партиций мы подбираем эмпирически в зависимости от конкретных данных.
Посмотрим на статистику по Stage, который записывает данные на диск:

Выглядит всё отлично, перекосов нет, данные хорошо распределены для записи. Посмотрим на все Stage при записи ORC-файлов.

Здесь видна явная проблема роста объёма данных при записи. По отчету работы Spark-приложения видно, что прочитали 22,7 Гб, а записали почти в два раза больше — 42,7 Гб! Убедимся в существовании проблемы, выполнив команду du:
-bash-4.2$ hdfs dfs -du -h -s /home/shveenkov/log_store/ods
42.7 G 128.0 G /home/shveenkov/log_store/ods
Да, Spark-UI не обманул, данных стало много :) Но почему??? Ведь колоночный формат должен оптимально сжимать данные, а он этого не делает. Зачем тогда он нужен?
Всё дело в сортировке. В исходных данных запросы пользователей могут находиться не так далеко друг от друга, и поэтому информация может сжиматься лучше. Мы добавили вызов repartition(100), это сильно перетасовало данные в случайном порядке и повлияло на их итоговый размер. Очень важный момент, попробуем его учесть.
Очевидное решение — отсортировать данные внутри ORC-файлов. Если мы отсортируем по колонке email, то, скорее всего, одинаковые данные окажутся рядом: вряд ли у пользователя меняется IP-адрес или user-agent.
Эти колонки тоже имеет смысл использовать в сортировке.
Есть ещё один нюанс, связанный с вызовом repartition(100): один и тот же email случайно распределится по 100 партициям. Чтобы этого не происходило, распределим данные по колонке email и один и тот же почтовый адрес отправим в одну и ту же партицию. Это должно улучшить сжатие.
output_path = '/home/shveenkov/log_store/ods'
(
df_out
# добавим партиционирование по email
.repartition(100, 'email')
# и отсортируем данные внутри партиций
.sortWithinPartitions('email', 'ip_address', 'user_agent', 'dttm')
.write
.mode('overwrite')
.option('compression', 'ZLIB')
.format('orc')
.save(output_path)
)Посмотрим на результат:

Во-первых, данных стало меньше, то есть сортировка повлияла на сжатие. Во-вторых, длительность записи выросла с 2,5 до 21 минуты. Это не то чтобы хороший результат, поэтому предлагаю покопаться в причинах такого поведения Spark.
Если зайти в статистику Stage записи файлов, то можно наблюдать явную проблему Data Skew:
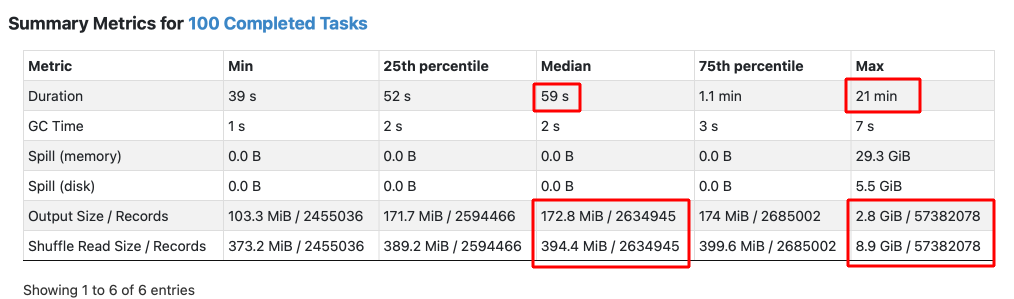
Одна задача выполнялась очень долго, явно в неё попало слишком много данных — 57 млн строк. Медианное количество строк в записываемых файлах составляет 2,6 млн. Также мы видим, что размер выходных данных 2,8 Гб, по сравнению с медианой в 171,7 Мб разница на порядок. Понятное дело, чем больше строк в файле, тем больше он занимает места :)
Можем убедиться в проблеме по диаграмме выполнения задач в Spark-UI:

Примерно за 1 минуту отработало 239 задач, и одна задача выполнялась 21 минуту. Попробуем прочитать наши данные и понять, какое значение для колонки email — явный лидер.
Это делается очень просто. Запустим такой код на Spark:
df = spark.read.orc('/home/shveenkov/log_store/ods')
(
df
.groupBy('email') # группируем по email
.agg(F.count('*').alias('cnt')) # считаем количество уникальных емейлов
.orderBy(F.col('cnt').desc()) # сортируем в обратном порядке по колонке cnt
).show(n=50, truncate=False) # выводим топ 50 записейРезультат можем посмотреть в Jupyter-notebook:

Видно, что основная проблема перекоса — это Null-значения для колонки email. Именно такие строки попадают в один файл. Это главная причина долгой работы одной из задач нашего приложения. То есть наш план хорош, но есть строки без адресов почты и нужно подумать, как распределить их так, чтобы не было перекоса. И заодно подумать об их «одинаковости», чтобы улучшить сжатие.
Можем предположить, что если пользователь не авторизован и email отсутствует, то, скорее всего, он заходит с одних и тех же IP-адресов и запросы могут содержать одинаковый user agent. Попробуем изменить код под такие особенности и посмотрим на результат.:
output_path = '/home/shveenkov/log_store/ods'
(
df_out
.repartition(
100,
F.when(
F.col('email').isNotNull(),
F.col('email')
).otherwise(
F.concat(F.col('ip_address'), F.lit('|'), F.col('user_agent'))
)
)
.sortWithinPartitions('email', 'ip_address', 'user_agent', 'dttm')
.write
.mode('overwrite')
.option('compression', 'ZLIB')
.format('orc')
.save(output_path)
)Отличие лишь в том, что мы через вызов F.when распределяем пустые адреса почты по IP-адресу и значению в user agent (это как условный оператор if в Python или других языках). Посмотрим на изменение:

Неплохой результат по сжатию данных: 13,7 Гб вместо 19,3 Гб в предыдущий раз — разница в 40 %. Только представте подобную экономию в масштабах Почты. Чтобы хранить данные за несколько лет нужно купить серверы под 10 Пб или под 6? Заказать 100 или 60 серверов на ближайший год. А такую экономию даёт изменение всего в несколько байтов кода.
Убедимся ещё раз в том, что проблемы с перекосом данных больше нет:
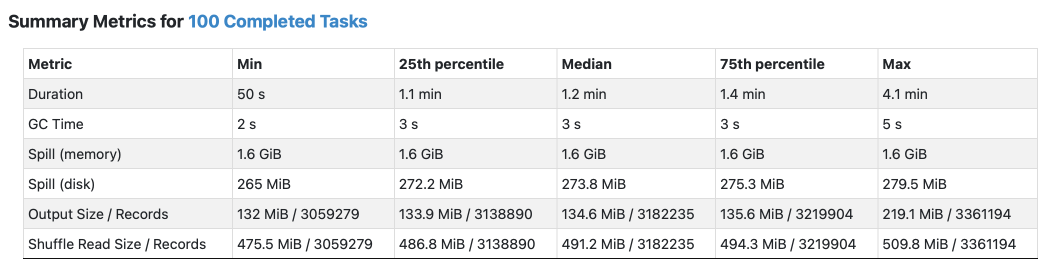
Объективно понятна разница в работе наших Spark-задач. Мы видим что данные распределены одинаково и большого различия между медианой и min/max сейчас нет. И это прекрасно!
Мы записали данные в колоночном формате, сохранили их в ORC-файлах. Посмотрели на сортировку внутри файлов и распределение между разными ORC-файлами. Сортировка и распределение через вызов repartition(...) — это очень важные нюансы, от таких тонкостей зависит, насколько хорошо будут сжаты данные в хранилище.
Запросы к данным в Spark
Выполним аналитические запросы к нашим данным и посмотрим на результаты работы Spark-приложения.
Запрос по ORC-файлам
Обычно вся аналитика строится на основе группы событий в сервисе. Типовой запрос к нашим данным выглядит так: получить конкретное событие X для сервиса Y, и посмотреть на количество уникальных пользователей по этому событию с разбивкой по дням.
Попробуем поискать событие в наших структурированных логах с фильтром “cloud-android-analytics» по колонке service, а также с фильтром “launch» по колонке event_name. Смысл этого запроса в том, чтобы получить уникальных пользователей, запустивших приложение Облако.
df = spark.read.orc('/home/shveenkov/log_store/ods')
(
df
.filter(
(F.col('service') == 'cloud-android-analytics')
&(F.col('event_name') == 'launch')
)
.select(F.col('email'))
.distinct()
.count()
)
>> 6717Нужно снова обратить внимание на Spark-UI:

Для выполнения запроса понадобилось прочитать всего лишь 321 Мб, в то время как все наши данные занимают 13,7 Гб. Фантастика! Здесь явно видна разница между тем, сколько данных читается с диска, если работать с файлами в колоночном и текстовом формате.
Посмотрим на план запроса в Spark-UI:

Цветом выделены фрагменты плана запроса, на которые стоит обратить внимание. У нас 100 файлов общим размером в 13,7 Гб. Но для выполнения запроса Spark читает с диска лишь небольшой объём нужных ему данных.
Также стоит обратить внимание на детальный план запроса:
(1) Scan orc
Output [3]: [service#1392, email#1393, event_name#1394]
Batched: true
Location: InMemoryFileIndex [viewfs://dwh/home/shveenkov/log_store/ods]
PushedFilters: [IsNotNull(service), IsNotNull(event_name), EqualTo(service,cloud-android-analytics), EqualTo(event_name,launch)]
ReadSchema: struct<service:string,email:string,event_name:string>
(2) ColumnarToRow [codegen id : 1]
Input [3]: [service#1392, email#1393, event_name#1394]
(3) Filter [codegen id : 1]
Input [3]: [service#1392, email#1393, event_name#1394]
Condition : (((isnotnull(service#1392) AND isnotnull(event_name#1394)) AND (service#1392 = cloud-android-analytics)) AND (event_name#1394 = launch))Здесь есть очень важный раздел PushedFilters. Это тот самый механизм, который во время сканирования страйпов в ORC-файле позволит быстро пропустить ненужные куски данных и не распаковывать их.
Ускорение запросов по ORC-файлам
Но можно ещё ускорить работу с данными! Попробуем сделать так, чтобы Spark читал с диска ещё меньше данных. Учитывая специфику наших запросов, нужно делать фильтр по колонкам service и event_name почти в 99 % случаев обращения к данным. Кардинальность этих колонок не так высока, и если мы отсортируем данные по ним, то ускорим Stage фильтрации страйпов. Финальный код для подготовки данных с сортировкой по service, event_name:
output_path = '/home/shveenkov/log_store/ods_v2'
(
df_out
.repartition(
100,
F.when(
F.col('email').isNotNull(),
F.hash(F.col('email'))
).otherwise(
F.concat(F.col('ip_address'), F.lit('|'), F.col('user_agent'))
)
)
.sortWithinPartitions('service', 'event_name',
'email', 'ip_address', 'user_agent',
'dttm')
.write
.mode('overwrite')
.option('compression', 'ZLIB')
.format('orc')
.save(output_path)
)Я записал данные в соседний каталог с суффиксом “_v2”, чтобы можно было сравнить поведение запросов. Снова посчитаем уникальных пользователей и оценим разницу с _v2-данными:

Обратите внимание на то, что мы ещё примерно в 6 раз уменьшили объём, который нужно прочитать с диска для выполнения аналитического запроса. Также обратите внимание на разницу в длительности чтения данных: 13 сек вместо 1 минуты. Но я подчеркну важность уменьшения размера входной информации. Очевидно, что чем меньше нужно прочитать, тем меньше времени это займёт.
План запроса не изменился, но явно видна разница в статистике по чтению и фильтрации входных данных. Для сравнения ниже показаны оба запуска, второй — с сортировкой колонок service и event_name:

Когда данные отсортированы по колонке email, оптимизация PushedFilters работает, но не так эффективно: на этапе сканирования необходимо обработать 315 млн строк, затем распаковать данные и сделать дополнительную фильтрацию.
Но когда данные отсортированы по колонкам service_name и event_name, алгоритм оптимизации PushedFilters отобрал всего лишь 2 млн строк. То есть объём данных для распаковки будет гораздо меньше, что мы и видим в статистике работы самого Spark-приложения.
Важно заметить, что после изменения сортировки улучшился поиск по данным для выполнения большей части наших аналитических запросов. Для нас это важно, потому что для анализа данных глубиной в несколько лет читать объёмы в 6 раз меньше будет эффективно для наших запросов.
Хочу ещё раз подчеркнуть важность сортировки данных. Она влияет на сжатие и фильтрацию данных. Всё это главные факторы работы с данными.
Если внимательно присмотреться к нашим картинкам, то можно заметить, что при последних изменениях сортировки итоговый объём вырос! Понятно даже, почему. Сортировка по колонке email давала более сильное сжатие, одинаковые данные в бо̒льшем количестве находились рядом. А теперь мы немного «разбавили» их одинаковость, добавив в сортировку новые колонки.
Разница между 15,9 и 13,7 Гб не так уж и велика, но всё же в таком виде мы экономим
30 % хранилища.
Что лучше: сильнее сжимать или меньше читать?
Всегда встает вопрос, что лучше: сильнее сжимать или меньше читать для выполнения запросов? Мы выбираем разные стратегии в зависимости от характера данных и запросов к ним. У вас теперь тоже есть понимание этого сложного выбора.
Также можно использовать смешанный подход при хранении данных в Hadoop. Пример организации хранилища:

Для эффективной работы запросов мы используем retention в три месяца: оптимизируем данные под быстрое выполнение запросов за этот период. Также к этим данным можно применить алгоритм сжатия snappy, адаптированный под быструю распаковку.
Исторические данные нужно сортировать для более эффективного сжатия и пережимать алгоритмом zlib. Так мы экономим место и храним больше полезной информации. Запросы по историческим данным будут работать медленнее, но они по-прежнему будут эффективны.
Заключение
В этой статье мы рассмотрели вопросы эффективности аналитического хранилища. Разобрали особенности колоночного хранения данных на примерах работы с логами Почты. Посмотрели, как Spark работает с текстовыми данными, читая их по строкам, и сравнили с обработкой аналогичных запросов по колоночным ORC-файлам.
Запись колоночного файла требует много ресурсов. Во-первых, данные нужно отсортировать, во-вторых, правильно разбить на куски, в-третьих, нужно собрать статистику по колонкам для каждого куска данных, разбить по колонкам, сжать и записать структурированную информацию. Гораздо проще записывать текстовые данные.
По планам запросов в Spark-UI мы объективно убедились, что колоночный формат весьма эффективен для работы с данными. В статье показана разница на примерах с объяснением причин такого поведения Spark.
Это тема кажется и простой, и сложной одновременно. Очень много тонких моментов и проблем, и я надеюсь, что у меня получилось их описать. И если вы будете работать с данными, статья будет полезна и для вас.
А вам нравится работать с данными в Spark?
Список литературы по теме BigData и Spark
Data Engineering
Статьи про архитектуру DWH, слои и Data Modeling: https://habr.com/ru/companies/yandex/articles/557060/
https://habr.com/ru/companies/yandex/articles/557140/
Clickhouse
Spark
-
Общая информация о Spark
-
Сервис Spark Shuffle
-
Тюнинг параметров для данных Spark Big Shuffle
Spark Joins:
https://towardsdatascience.com/strategies-of-spark-join-c0e7b4572bcf
https://towardsdatascience.com/the-art-of-joining-in-spark-dcbd33d693c-
Серия статей о приёмах в Spark: