

В последнее время в области компьютерного зрения произошло много революционных событий, но есть ряд классических задач, решение которых остается актуальным. Одна из них — матирование, которое применяется для редактирования изображений и видео через извлечение нужных объектов с субпиксельной точностью. Решения этой задачи вы можете видеть в программах для кинопроизводства и фоторедакторах. В этой статье мы хотим познакомить вас с нашим новым подходом к матированию изображений. Изначально мы в SberDevices стремились решить задачу для портретов, но обобщающая способность модели позволяет использовать её и для изображений, выполненных в полный рост, для картинок с животными и так далее.
Сегодня мы поговорим о том, что такое матирование изображения (image matting), в чем заключаются его основные сложности, раскроем наши подходы к решению и покажем полученные результаты.
Image matting
Матирование (или matting) — это разложение начального изображения на фон (background), объект (foreground) и альфа-канал. По сути, это есть решение уравнения альфа-блендинга:

В целом, по такому определению сложно увидеть, чем это отличается от сегментации, однако, отличия все же присутствуют. Во-первых, сегментация объекта не учитывает высокочастотные детали изображения (такие как волосы, усы), и зачастую также игнорирует прозрачные объекты (такие как очки, так называемый «true matting»). Во-вторых, дискретизация изображения может сильно влиять на качество матинга. Причина в том, что очень маленькие детали изображения могут оказаться меньше размера одного пикселя при недостаточно высоком разрешении, из-за чего возникает неопределенность в принадлежности этого пикселя к фону или объекту переднего плана. Это приводит к смешиванию фона с объектом, из-за чего зачастую невозможно выделить маску.

StyleMatte
Представляем вашему вниманию трансформерную архитектуру для решения задачи матирования (image matting). Подробно остановимся на каждом слое нейронной сети.
В качестве бэкбона используется энкодер Swin-v2. Swin-трансформер имеет ряд преимуществ в сравнении с другими нейросетевыми подходами. Обычные трансформеры имеют квадратичную сложность вычисления self-attention от размера картинок, но из-за подхода со сдвигом окон (shifted windows) у этой модели сложность линейная. Swin позволяет сохранять точность работы на входах разных размерностей из-за нового подхода слияния патчей (patсh merging). А его конфигурация Swin-T часто используется в качестве базовой модели во многих задачах компьютерного зрения: детекции объектов, классификации и разных типах сегментации.
Итак, RGB-изображение подается на вход Swin-v2 энкодеру, выходы из которого — это скрытые состояния разной канальности и варьирующихся разрешений, которые содержат довольно качественное представление о картинке, пригодное для нашей задачи. Далее, происходит постепенное увеличение разрешения полученных скрытых признаков и их приведение к точной маске. Эти скрытые состояния обрабатываются блоком Pixel Decoder для получения пиксельных эмбедингов высоких разрешений путем постепенного увеличения признаков низкого разрешения. Данный декодер впервые был представлен создателями модели Mask2Former.
Затем состояния декодера прокидываются через Feature Pyramid Network (FPN) — пирамидальный блок, который выполняет довольно простые преобразования на каскаде признаков на разрешениях от 1/32 до 1/4. На выходе из слоя получаем тензор размера в 4 раза меньше нужного, с 256 каналами. Простая сверточная голова сворачивает эти каналы в один. FPN-блоки важны при end-to-end обучении, так как для картинок высокого разрешения это помогает сэкономить память и ускорить обучение, не теряя семантической значимости агрегируемых признаков.

Так как весь процесс извлечения маски работает в низком разрешении, необходимо в конце увеличить её до исходных размеров. Для этого можно воспользоваться простым upsampling слоем (bilinear, bicubic или др.) или применить специальные фильтры (guided filter, GF). Обычные способы повышения дискретизации страдают от того, что увеличение разрешения происходит за счёт обычной аппроксимации на основе цвета прилегающих пикселей, без учёта исходного контекста картины. Эксперименты подтвердили, что GF-блоки гораздо точнее увеличивают разрешение маски при помощи хитрого трюка. Все дело в том, что такой блок получает на вход маску и изображение в низком разрешении, а также изображение в высоком разрешении. На выходе — маска в высоком разрешении, рассчитанная с учетом попарных ковариаций входных тензоров. Это позволяет сохранять существенные детали и избегать размытия и побочных неточностей в контурах, которые обычно возникают при других способах интерполяции. В целом, GF-фильтры используются не только для бинарных масок. Их также зачастую используют для задач переноса структуры или устранения шума. Мы в своих экспериментах применяли разные вариации фильтров (FastGF, ConvGF), а также их обучаемые модификации. Сравнение способов можно увидеть на изображении ниже.

StyleMatteGAN
Помимо основной нейросети по выделению матинговой маски, мы также предлагаем рассмотреть новый подход генерации четырехканальных изображений, которые помогут расширить обучающий датасет новыми синтетическими данными. Эта модель базируется на StyleGAN-3, потому что она имеет хорошо настраиваемую стилизацию генерации путем простой параметризации, как, например, с коэффициентом усечения (truncation) на картинке ниже:

Коэффициент усечения позволяет ограничивать генерацию z-вектора (cм. рисунок с архитектурой StyleMatteGAN), из которого генератор получает изображения, тем самым сужая распределение извлекаемой выборки до необходимого (например, при значениях близких к 1 — портреты в основном женские и с вьющимися волосами, а при −1 — мужчины, появляются также аксессуары, волосы более прямые).
Выходы из генератора используются в противовес к целевым изображениям для обучения дискриминатора, который также был переделан для классификации RGBA-картинок. В качестве ground truth примеров мы взяли датасет FFHQ с изображениями, в качестве альфа-канала использовали маски из нашей матирующей сетки (StyleMatte). Это грубое приближение, так как при плохо обученной матирующей сетке наши истинные примеры будут с некачественными масками, из-за чего обучение может вовсе не сойтись. Однако, обученная без синтетических данных StyleMatte возвращала довольно качественные маски, что позволило получать приемлемые семплы для дискриминатора.
Но, как оказалось, этого было недостаточно для того, чтобы обучить хороший генератор. Лица получались смазанные, зачастую неестественной формы и с неправильными контурами. Чтобы контролировать генератор, дополнительно был добавлен трехканальный дискриминатор (Vision-aided 3-channel Discriminator на картинке StyleMatteGAN), который работал на композитах, полученных при помощи альфа-блендинга с рандомным фоном из BG-20k синтетического выхлопа из генератора. В качестве истинных примеров берутся изображения из FFHQ. Такая настройка сетки позволила значительно стабилизировать обучение и прийти к более четким синтетическим портретам. На изображении приведены примеры сгенерированных лиц при разных комбинациях дискриминаторов.

Архитектура StyleMatteGAN представлена на картинке ниже. Мы использовали генератор StyleGAN-3, переделав его в четырехканальный формат для выдачи RGBA-картинок.

Эксперименты, метрики и результаты
Мы провели серию экспериментов с разными конфигурациями нейросети по выделению альфа-маски. Существенное отличие в метриках замечается, когда мы не используем GF-блок. Также FPN-блок помогает сходиться сетке быстрее и точнее.
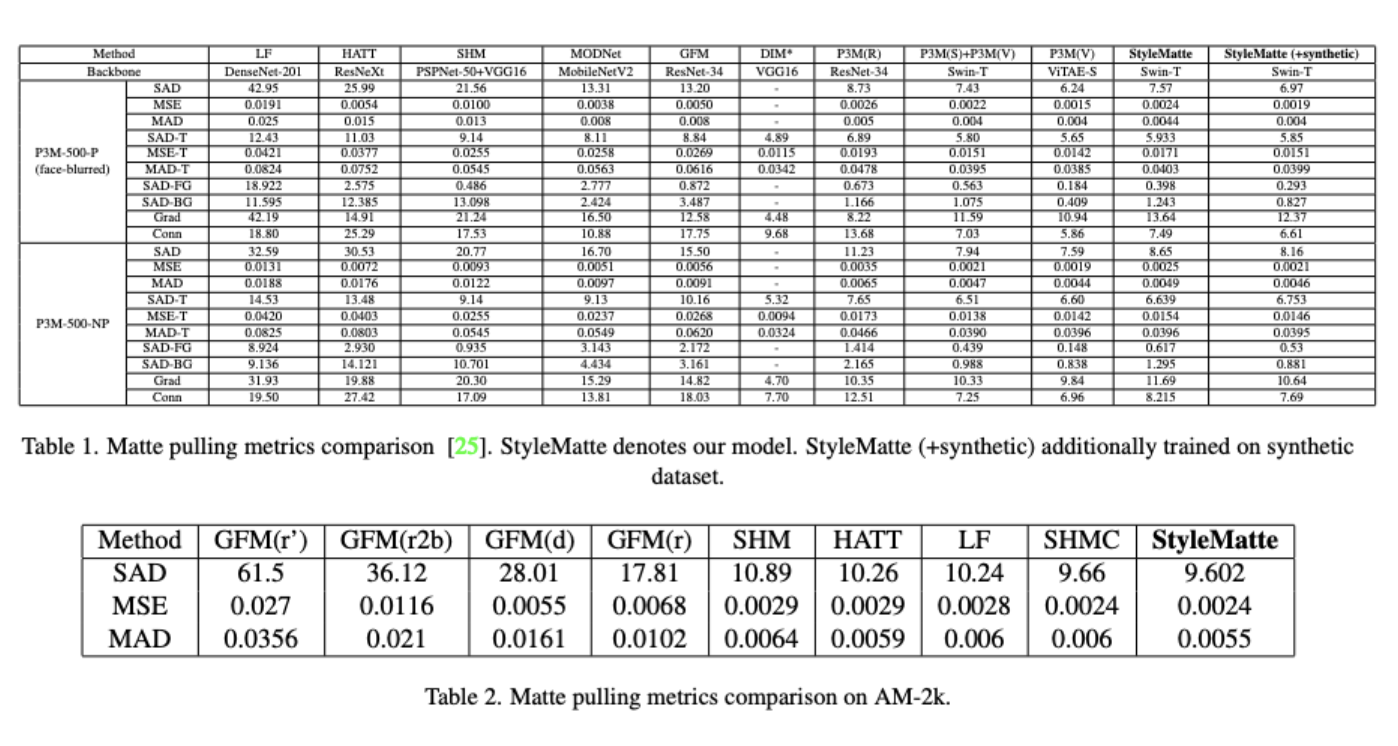
Основным обучающим датасетом является P3M-10k, где порядка 10 тыс. фотографий людей с заблюренными лицами (к датасету прилагаются тестовая и валидационная выборки). Также для доучивания использовались AM-2k (картинки с животными, размеченные вручную) и наш синтетический датасет с людьми.
Обучение строилось в несколько этапов. Сначала мы учили сетку сегментировать, затем доучивали матировать изображения. Для сегментации использовались классические лоссы (Dice loss, BCE), также 5 эпох предобучали на Hausdorff loss. Если сильно не вдаваться в математику, расстояние Хаусдорфа вычисляется как супремум расстояний точек из первой маски до второй маски как множества. Последний, хоть и смещает результаты обучения на сегментацию, но позволяет на этом этапе получать качественные детали на высокочастотных частях изображения, что потом помогает доучивать сетку на матирование.

Описание схемы цикла улучшения качества матирования путем добавления синтетических данных.
После первого этапа переключаемся на оптимизацию квадратичной ошибки на полученных масках. Если посмотреть на картинку с описанием цикла улучшения матирования, то таким образом, мы предобучили StyleMatte на доступных данных. Далее с помощью сгенерированной маски из обученной сетки на датасете FFHQ получаем RGBA-вход для обучения StyleMatteGAN, который генерирует нам синтетический датасет с четырехканальными портретами. Последний мы использовали для доучивания нашей матирующей сетки. Это полный цикл обучения двух моделей, который улучшил основные показатели и метрики (SAD, MAD, MSE) на тестовых датасетах P3M-500.
Для проверки качества генеративной модели мы сравнили его с аналогами по метрике FID (Fréchet inception distance), которая сравнивает распределения целевых и синтетически сгенерированных изображений:

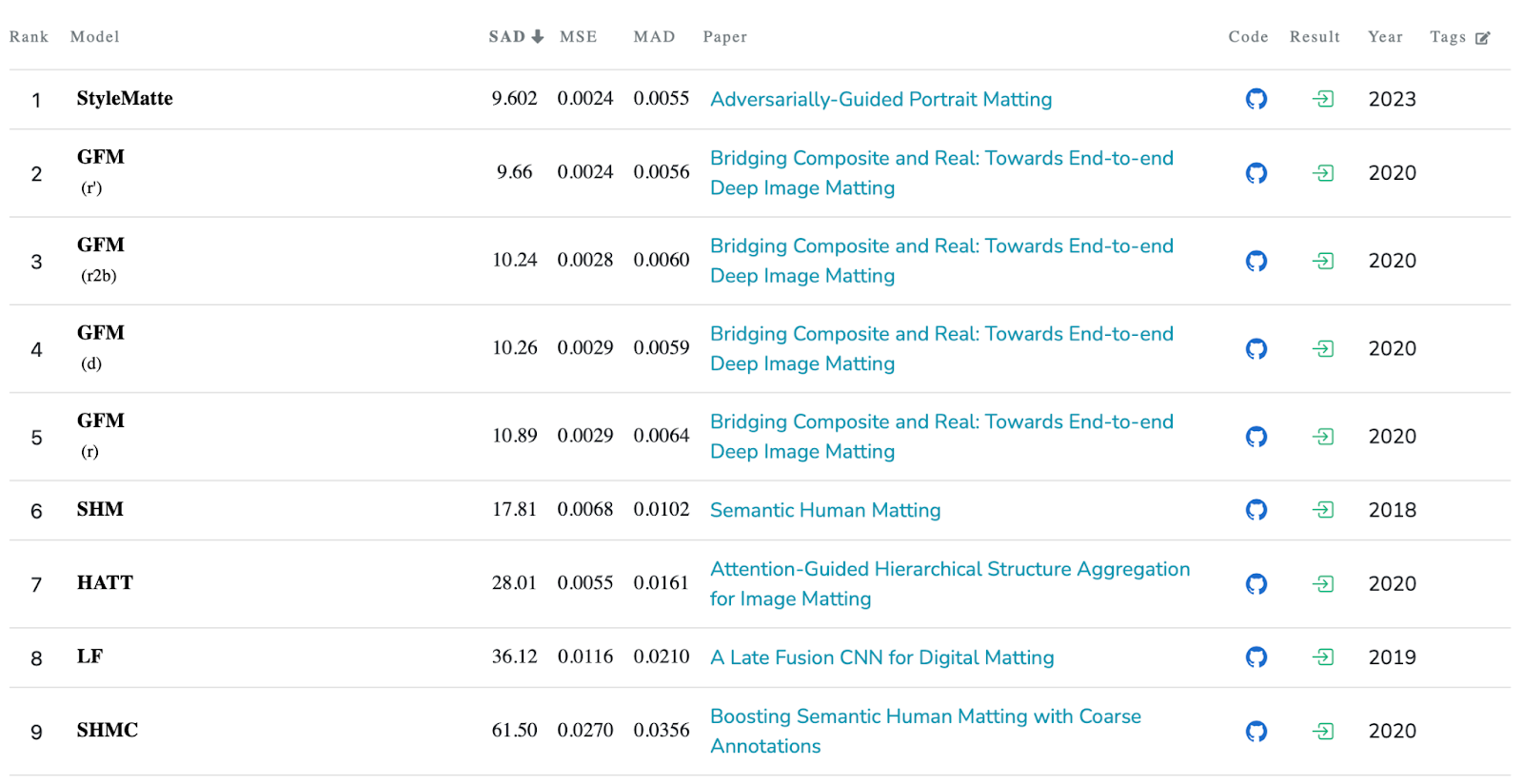
Дополнительный эксперимент, проведенный на датасете животных AM-2k позволил получить state-of-the-art метрики на этом датасете. Сравнительные результаты приведены ниже в таблице.
Примеры полученных матирующих масок:


Заключение
Мы рассказали о задаче матирования и подходе команды RnD CV SberDevices к его решению, а также о новом способе генерации тренировочных семплов при малом количестве доступных датасетов с использованием преимуществ генеративной модели StyleGAN-3.
Наше решение может быть использовано для создания сервиса по переносу портрета на новый фон. Помимо этого, матирующая сеть может быть использована в качестве учителя для дистилляции сегментирующей нейросети в SberJazz, либо может найти применение в задаче замены фона вместо классического подхода на основе сегментации.
Матирование является важной частью задачи замены фона, к которому мы движемся глобально. Но для качественной замены фона этого недостаточно, нужно разрешить проблемы background removal, разной освещенности и цветовых искажений при альфа-блендинге с новым бэкграундом. Об этом расскажем вам в ближайшем будущем!
Ссылки:
Подписывайтесь на telegram-канал нашей команды.
Авторы:
Сергей Чичерин (chroneus) и Карен Ефремян (befozg)
Отдельная благодарность Карине Кванчиани (karinakvanchiani) за активное участие в постановке первичных экспериментов!
Комментарии (13)

Nataliszu
20.06.2023 09:40Какой смысл матирования не в real-time? Я считаю, что никуда не годится такая сетка, еще и трансформерная.

befozg Автор
20.06.2023 09:40+1действительно, transformer-based сетка не для real-time, но можно его использовать в редакторах, или как учителя для сегментационных сеток, которые работают быстро в режиме inference.

dimusoltsev
20.06.2023 09:40Почему тогда не используют везде guided фильтры, если они настолько "хороши" по сравнению с обычными bilinear и подобными методами?
befozg Автор
20.06.2023 09:40да, это не панацея. Классические способы увеличения размерности картинки не требуют дополнительных входных данных (как в случае с guided filter, которому в нашем случае для увеличения размерности маски требуется исходное изображение в высоком разрешении, а такого дополнительного знания не во всех задачах можно подыскать). Помимо этого, классический upsampling может работать с произвольным тензором, независимо от числа каналов и информации, которая в них содержится. Поэтому guided filter не будет решением получше, например, в промежуточных слоях UNet-подобных автоэнкодеров.

zodiak
20.06.2023 09:40Эх, хотелось бы что-то крутое увидеть...
Например собственный публичный датасет для маттирования на пару тысяч уникальный масок. Или какое-то новшество в архитектуре (да чтобы еще и на Comp1K соту выбить).
А то GuidedFilter так-то уже давно известная и точно не самая крутая в плане качества штука для апсемплинга.
befozg Автор
20.06.2023 09:40+1Насчет датасета - конечно же хочется, и, возможно, в будущем сделаем. Но у нас есть описание способа генерации новых изображений, что частично покрывает этот вопрос.
А про upsampling и архитектуру - тут уже субъективно, что применять и чего добиться, для трансфера стилей и деталей guided filter и его модификации вполне до сих пор используются в разных решениях (не только матирование).
Возможно вам хочется увидеть более фундаментальное и прорывное решение. Мы будем стараться улучшать качество и обобщающую способность нашей модели.

SmallDonkey
20.06.2023 09:40Мистическое совпадение, я как раз только, только начал тренировать https://github.com/xuebinqin/U-2-Net для удаления заднего фона и тут вы, пригодиться статья

befozg Автор
20.06.2023 09:40На самом деле для удаления фона недостаточно хорошей маски, поэтому я б посмотрел в сторону background removal алгоритмов. А приложенная маска похожа на результат слабо обученного автоэнкодера :) попробуйте учить дольше и с меньшим шагом. Ну и блюр тоже уйдет, но границы станут грубее.



SmallDonkey
20.06.2023 09:40+1Датасет https://github.com/JizhiziLi/P3M, RTX 2060 12GB, SSD, 32 GB RAM
Winklnix
На первый же запрос по matting dataset много датасетов общедоступных, зачем синтетика?
befozg Автор
датасетов практически по любому запросу можно найти очень-очень много, но качество разметки, чаще всего, оставляет желать лучшего :)