
При умеренных объёмах базы данных в использовании offset нет ничего плохого, но со временем база данных растёт и запросы начинают «тормозить». Становится актуальным ускорение запросов.
Очевидно, если причина в росте объёмов базы данных, то используя главный принцип дзюдо «падающего - толкни, нападающего - тяни», следует ещё увеличить объём, в данном случае путём добавления нового поля в таблицы для последующей сортировки по нему.
Вообще говоря, этот приём не нов, например, https://medium.com/swlh/sql-pagination-you-are-probably-doing-it-wrong-d0f2719cc166. Но, на мой, используется незаслуженно редко.
Собственно, цель этой статьи привлечь внимание к этому приёму и показать на реальных базах данных его несложную реализацию и эффективность сравнительно со стандартным использованием offset.
Зачастую при запросах к БД используют offset и пока таблицы не более 100 000 строк запросы работают быстро, но как только объёмы данных увеличиваются и пользователю необходимо перейти на страницу 1001, возникают проблемы со скоростью ответа.
Замечу, что большинство поисковых систем не показывают количество найденных страниц, а просто предлагают перейти на следующую страницу.


Хотя ранее данная информация присутствовала, но видимо разработчики произвели оптимизацию:

Предложение состоит в том чтобы не использовать offset в запросах и не выводить общее количество записей, а внедрить сортируемые данные в таблицы.
Произведём замеры при получение одних и тех же данных в сортируемой и не сортируемой таблице (выполняю локально):
Запрос к не сортируемой таблице:
sql: 'select table_name.* from table_name group by ID limit ? offset ?'
Limit offset |
Duration |
Bytes |
Deceleration |
limit 10 offset 0 |
179ms |
1320 |
|
limit 10 offset 1000 |
191ms |
1320 |
1.06 |
limit 10 offset 100 000 |
606ms |
1320 |
3.38 |
limit 10 offset 200 000 |
790ms |
1320 |
4.41 |
limit 10 offset 300 000 |
864ms |
1320 |
4.82 |
limit 10 offset 400 000 |
1115ms |
1320 |
6.22 |
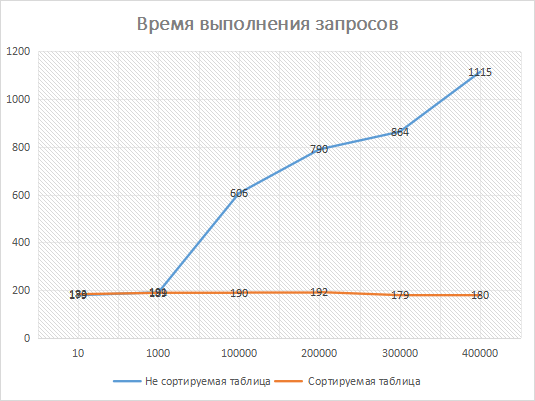
По результатам шести запросов с offset от 0 до 400 000, мы видим увеличение скорости выполнения запроса более чем в 6 раз. Это связанно с тем, что оператор offset является не эффективным и запрос выгрузил все 400 000 записей, а уже потом проверил их на соответствие условиям. Так же отдельного внимания стоит уделить запросу на получение значения общего числа найденных сущностей, так как данный запрос используется для указания числа страниц. Длительность выполнения данного запроса составляет около 3000ms на таблице с 400 000 записей. Данное время можно смело прибавлять к общему значению Duration, так как единожды данный запрос необходимо будет выполнить.
Пример запроса: 'select count(*) from table_name'.
Запрос к сортируемой таблице:
sql: 'select table_name.* from table_name where (table_name.sortID > ?) group by sortID order by sortID asc limit ?'
Оператор offset в данном запросе не используется. В качестве переменной для сравнения с sortID используем sortID 0 или значение sortID последней сущности из предыдущего запроса.
SortID limit |
Duration |
Bytes |
Deceleration |
sortID 0 limit 10 |
183ms |
1320 |
|
sortID 1000 limit 10 |
189ms |
1320 |
1,032 |
sortID 100000 limit 10 |
190ms |
1320 |
1,038 |
sortID 200000 limit 10 |
192ms |
1320 |
1,049 |
sortID 300000 limit 10 |
179ms |
1320 |
0,978 |
sortID 400000 limit 10 |
180ms |
1320 |
0,983 |
По результатам шести запросов с sortID от 0 до 400 000, мы видим увеличение времени выполнения запроса близко к погрешности. Это связано с тем что БД загружает только 10 записей.
Результаты эксперимента на графике:
Ось X - Значение offset/sortID.
Ось Y - Время выполнения запроса в миллисекундах.
На графике наглядно видно, что в не сортируемых таблицах при значении offset/sortID > 1000 резко возрастает время выполнения запроса. Очевидно при увеличении количества записей время выполнения запроса будет расти.
Как оптимизировать существующие таблицы и запросы к БД.
-
Добавляем в таблицу сортируемое поле. Создаём миграцию:
ALTER TABLE table_nameADD COLUMN sortID bigint(15) UNSIGNED NOT NULL AUTO_INCREMENT UNIQUEFIRST; -
Переписываем запросы:
Было: '
select table_name.* from table_name group by ID limit ? offset ?' (limit =10, offset=100 000)
Стало: 'select table_name.* from table_name where (table_name.sortID > ?) group by sortID order by sortID asc limit ?' (sortID =100 000, limit =10).
Итог: Данные действия с таблицами позволят уменьшить время выполнения запросов в разы при объёмных таблицах и время выполнения запросов будет стабильным даже если таблицы будут большими. Но необходимо понимать, что за данную оптимизацию мы платим тем, что мы испытываем сложности с дополнительной сортировкой (например, по алфавиту), но на мой взгляд, эта плата не значительна. По сути простой и быстрый метод ускорения запросов, но во многих проектах до сих пор используется классический offset.
Комментарии (21)

Akina
29.06.2023 11:57+5Ну хочется как минимум отметить пару моментов.
Допустим, набор записей может сортироваться по нескольким критериям. В простейшем случае ASC/DESC, а вообще по разным полям (по алфавиту, дате, цене и пр.). Получается, на каждую мыслимую сортировку нужно прикручивать своё поле sortID_N. Расточительно.
Записи иногда добавляются. Причём далеко не всегда добавленные записи оказываются в самом конце списка при требуемой сортировке. Как итог - после каждой подобной вставки требуется пересчёт sortID. А пересчитать и обновить поле для сотни тысяч записей - это не мгновенно.
Так что метод если и применим, то очень редко, в очень узкой области вывода статических, неизменяемых наборов данных. То есть ценность метода, по большому счёту, куда как ниже, чем декларируется. Потому и используется редко. ИМХО.
Да, ещё момент. Не понял, зачем в запросах группировка. Глупо как-то. Если ID - первичный ключ, то бессмысленно. А если не первичный ключ - так запрос и вовсе синтаксически неверен. В MySQL ещё худо-бедно выполнится при отключенном ONLY_FULL_GROUP_BY, а вот PostgreSQL просто обидится..
И последнее. LIMIT без использования ORDER BY - это не более чем лотерея. Угадай, что выведет сервер.. да, в большинстве случаев при тупом SELECT без WHERE сервер возвращает записи в соответствии с сортировкой по выражению первичного индекса - но даже это не догма.

MihaTeam
29.06.2023 11:57Я так понимаю автор в этой статье хотел показать пагинацию по ключам, но тему эту даже близко не раскрыл и зачем-то прикрутил новую колонку sortID. Такую пагинацию вполне можно выполнять и по pk. Правда в случае сортировки данных по какой-то другой колонке нужно прописывать дополнительную логику (в случае если колонка не уникальна)
WHERE some_field > $1 OR (some_field = $1 AND id > $2) ORDER BY some_field, idНу и конечно без индексов никуда
Gotlieb Автор
29.06.2023 11:57К сожалению, PK не всегда бывает сортируемым, в часто uuid. Я показал на примере как внедрить сортируемое поле и в дальнейшем его использовать.
Gotlieb Автор
29.06.2023 11:57Спасибо за интересный комментарий.<o:p></o:p>
В статье я писал: «Но необходимо понимать, что за данную оптимизацию мы платим тем, что мы испытываем сложности с дополнительной сортировкой (например, по алфавиту)». Чтобы избежать внедрения дополнительных полей (помимо sortID), я использовал фильтрацию: по имени (алфавит), по дате...
Прошу учесть, что в миграции я добавлял поле sortID AUTO_INCREMENT. В свою очередь AUTO_INCREMENT: Значение будет увеличиваться для каждой новой строки; Значение уникально, дубликаты невозможны; Если строка удалена, auto_increment столбец этой строки не будет повторно назначен. То есть перерасчёт sortID не требуется. У новой записи всегда будет sortID больше чем у предыдущих (это можно назвать сортировкой по дате создания).
Согласен в первом запросе можно обойтись без group by ID, указал его для наглядности, так как во втором запросе использую group by sortID.
Так же согласен, что необходимо дополнительно подстраховаться и указать ORDER BY в первом запросе.

FanatPHP
29.06.2023 11:57+3Я нихчего не понял.
Сначала идет запрос сgroup by ID. Тут я вижу только два варианта: либо ID неуникален (что уже идет вразрез со всеми соглашениями об именовании полей), либо тут просто перепутано group by c order by. Но кончается всё запросомgroup by sortID. Куда делась группировка по ID? Она была не нужна? Зачем тогда было делать новое поле sortID, если можно было просто сделать существующее поле ID первичным ключом.Ну и традиционно, умиляет наличие в тегах бигдаты.

pda0
29.06.2023 11:57+1Я бы с удовольствием почитал статью о решении проблемы пагинации, если бы это была более реальная статья, а не очередное унылое откровение "делайте where id > ...". А если надо пагинировать результаты сортировки по нескольким полям? Причём одни asc, а вторые desc? А если в where были дополнительные условия фильтрации и больше нельзя установить соответствие кол-во записей на странице - кол-во ключей?
FanatPHP
29.06.2023 11:57Ну так стандартно — возвращаться к тому же LIMIT-у, но ограничивать запрашиваемый объём. Если это пагинация для людей, то больше, скажем, тысячи страниц показывать бессмысленно.
Если это пагинация для АПИ, то делать обязательный параметр, ограничивающий выборку, например по дате.pda0
29.06.2023 11:57Я встречал один совет (для MySQL, но по идее должен работать и на других базах), но пока за занятостью руки проверить всё никак не дойдут.
Кто-то советовал LIMIT, OFFEST выбирать первичные ключи из целевой таблицы, а вторым запросом уже по ним нужные записи. По идее тут сканирование будет идти по индексу, который и так может быть в памяти закеширован.
FanatPHP
29.06.2023 11:57Это может помочь, но главная проблема здесь в другом. "Сканирование будет идти по индексу" только если выборка идет по этому индексу. А если выборка идёт с сортировкой, или с дополнительными условиями, то никакой первичный ключ тут не поможет. Значения полей для WHERE все равно придется читать с диска, а сортировка будет файлсортом.
Поэтому самое важное здесь — это сделать кастомный индекс, в котором сначала указаны поля, по которым идёт сортировка, а потом все поля, которые используются в условиях. Вот тогда выборка будет идти по этому индексу и только из памяти. И выборка только первичных ключей здесь как раз будет к месту.
FanatPHP
29.06.2023 11:57Но, если вернуться к исходному вопросу, выборка с лимитом, даже по индексу, все равно будет относительно медленной, и — главное — скорость запроса для каждой следующей страницы будет падать.
И в этом случае поможет то, чем я говорил выше — не раздувать пагинацию на сотни тысяч страниц, а ограничивать выборку определенным диапазоном.




ioncorpse
29.06.2023 11:57-1Ускорение запросов на разных СУБД. Судя по тегам. Ок. А планы конечно лесом.
Getequ
Что за пагинация такая что в ней по дефолту идёт группировка по первичному ключу???
"select table_name.* from table_name group by ID limit ? offset ?"
Gotlieb Автор
Согласен в первом запросе можно обойтись без group by ID, указал его для наглядности, так как во втором запросе использую group by sortID.
FanatPHP
Отличное объяснение. Теперь осталось только понять, зачем во втором запросе group by.
Gotlieb Автор
Так как sortID не является PK для таблицы
FanatPHP
Не могли бы вы пояснить свою мысль более развернуто?
Зачем вообще группировать выборку по уникальному полю? Вы в принципе понимаете, для чего служит оператор group by? Ни с каким другим не путаете? В чем вообще смысл гениальной конструкции
group by sortID order by sortID asc?Gotlieb Автор
Спасибо за справедливое замечание, как я писал мы можем обойтись без group by . Group by имеет смысл использовать когда есть вероятность повторения значения поля (например при join других таблиц). В данном случае, вы правильно заметили, поле уникальное. Group by можно не использовать.