
В этой статье будут рассмотрены инструменты наблюдения за сетевой инфраструктурой Kubernetes и основные составляющие Observability/Наблюдаемости – мониторинг, журналы событий, метрики, распределенная трассировка и оповещения. Обсудим, как эти инструменты могут помочь обеспечить надежную и эффективную работу кластеров Kubernetes и запущенных на них микросервисах, а также какие преимущества и недостатки существуют при использовании этих решений.
Эта статья для DevOps, Kubernetes administrators и SRE инженеров, которым важно и интересно разобраться в том, как устроена сетевая инфраструктура Kubernetes, какое взаимодействие происходит на уровне ядра Linux и различных приложений (Go, Java, Python и т.п.); изучить две обширные технологии eBPF и OpenTelemetry, активно продвигаемые CNCF сообществом. А главное при помощи каких инструментов можно упростить принятие решений инженерам при использовании Kubernetes в своих проектах и продуктах.
Статья будет разбита на три части, в связи с большим количеством информации. Первая часть посвящена обзору подходов для наблюдения за инфраструктурой Kubernetes. Во второй части будут разобраны инструменты, базирующиеся на eBPF. В третьей части инструменты, использующие OpenTelemetry.
Содержание
-
Существующие подходы к мониторингу и Наблюдаемости в Kubernetes
Классы инструментов наблюдения за сетевой инфраструктуры Kubernetes
Введение
Современные масштабируемые приложения строятся на распределенных системах, использующих облачную инфраструктуру (cloud-native, serverless) и микросервисные программные архитектуры. К сожалению, принося много преимуществ компаниям, внедряющим их, эти системы также усложняют процессы по обеспечению стабильного функционирования программных продуктов а также отладки возникающих проблем.
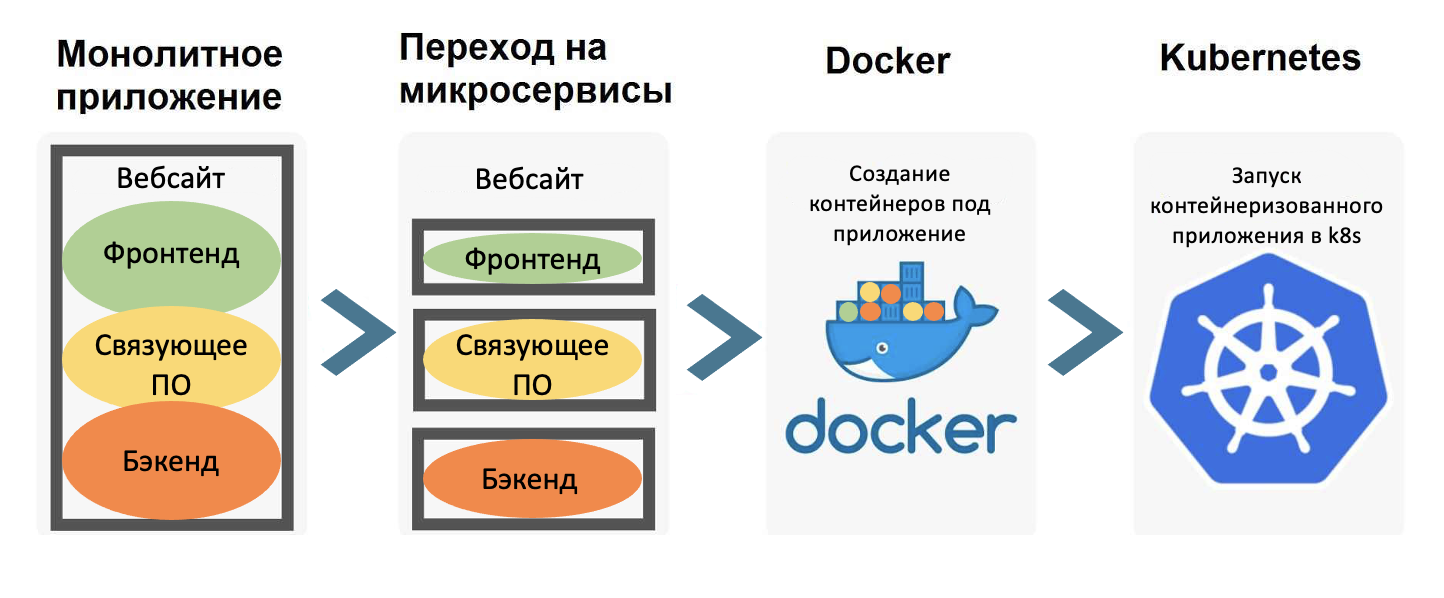
Существенную ценность приобретают инструменты, которые позволят инженерным командам понять и устранить проблемы и улучшить работоспособность разрабатываемых платформ и сервисов. Отсюда возникает новый термин / класс инструментов – Наблюдаемость, на английском Observability. Который позволяет находить ответы, на такие вопросы: "Почему это происходит?" / "что послужило причиной?" / "Как сделать так, чтобы эта проблема больше не возникала?" – то есть понять систему извне, не зная её внутреннего устройства.
Обзор сетевой инфраструктуры Kubernetes
Kubernetes - это система контейнерной (а в расширенном случае и виртуальных машин) оркестрации, цель которой - выстроить повторяемые процессы, связанные с автоматизацией развертывания, масштабирования и обновления контейнерных сред. Системы Kubernetes, называемые кластерами (cluster), обычно работают на нескольких потенциально разнородных хост-машинах (hosts, термин из ЦОДа), называемых узлами (Nodes). Под (pod, абстрактный объект Kubernetes, представляющий собой «обертку» для одного или группы контейнеров) - это атомарный блок, которым управляет Kubernetes. Типичная конструкция кластера: он содержит несколько подов, которые в свою очередь запущенны на узлах. Каждый pod изолирован от хост-машины с помощью пространств имен и cgroups. Контейнеры в одном и том же pod не изолированы друг от друга и используют общие пространства имен.
☝️ Контейнеры, выполняющие вспомогательные функции по отношению к основному контейнеру в pod, называются sidecars.
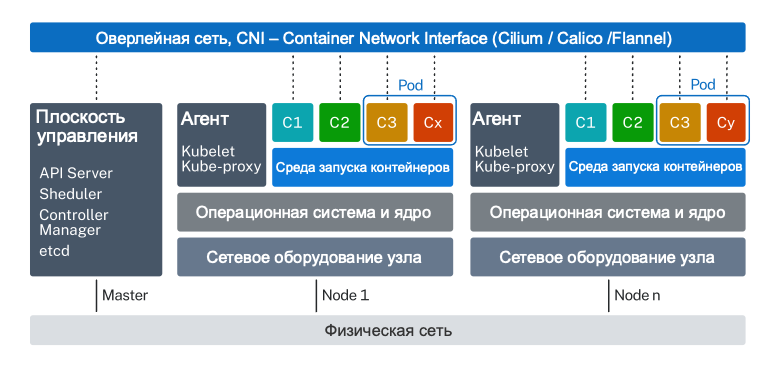
Kubernetes не имеет строго закрепленной реализации сетевой инфраструктуры – существует лишь небольшой набор правил для однозначной идентификации подов. Вместо этого организация сетей в k8s достигается через использование сетевых плагинов, благодаря которым можно реализовывать свои настраиваемые сети.
Существует две основные категории сетевых плагинов: kubenet, CNI.
Первая категория: плагин Kubenet (старое название, в документации он уже присутствует под названием noop, который распространяется вместе с Kubernetes и предоставляет минимальный набор функций для функционирования кластера Kubernetes.
Вторая категория: сетевые плагины, реализующие спецификацию Container Network Interface (CNI), называемые CNI плагины: Flannel, Weave, Calico, Cilium, Istio и другие. CNI плагины могут реализовывать сетевую модель с помощью совершенно разных подходов (Cilium – BPF+XDP для контейнеров, Linen/ovn-kubernetes – Open vSwitch'и для оверлейных сетей и SDN/OpenFlow сред и т.д.).
Kubernetes (k8s) можно настроить с одновременных использованием нескольких CNI плагинов – либо при помощи ручной установки, либо при помощи сторонних решений, как Multus.
Инфраструктура Kubernetes также включает в себя сервисы (Services) и сетевые политики (Policies), которые позволяют приложениям взаимодействовать друг с другом внутри кластера:
Services Kubernetes обеспечивают постоянный IP-адрес и DNS-имя для набора подов, которые выполняют определенную функцию или предоставляют доступ к конкретному приложению. Сервисы могут быть созданы для любого набора подов, даже если они находятся на разных узлах кластера или в разных пространствах имен. Сервисы Kubernetes также обеспечивают балансировку нагрузки между подами, что позволяет распределять сетевой трафик между несколькими экземплярами приложения.
Network Policies Kubernetes позволяют управлять трафиком внутри кластера, определяя правила доступа к сервисам и подам. Например, сетевая политика может быть создана для разрешения доступа только из определенного пространства имен или для определенных IP-адресов. Политики также могут использоваться для настройки маршрутизации, например, для перенаправления трафика на другие сервисы или кластеры.
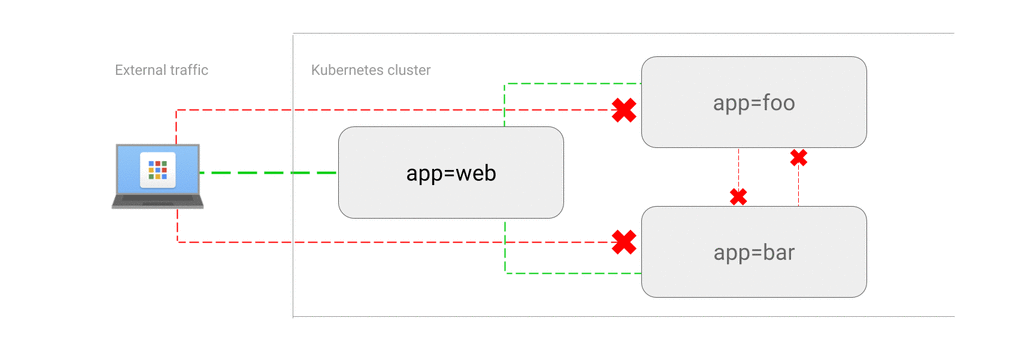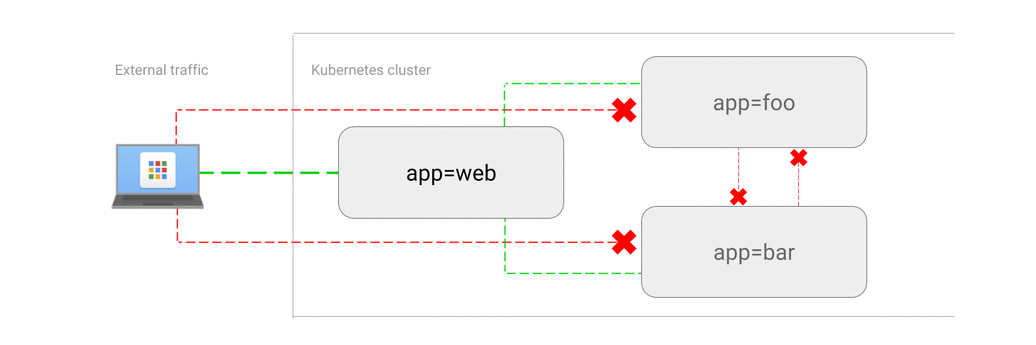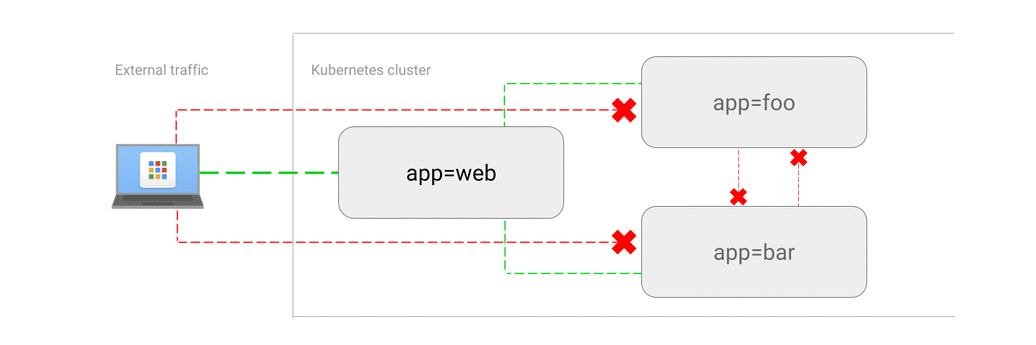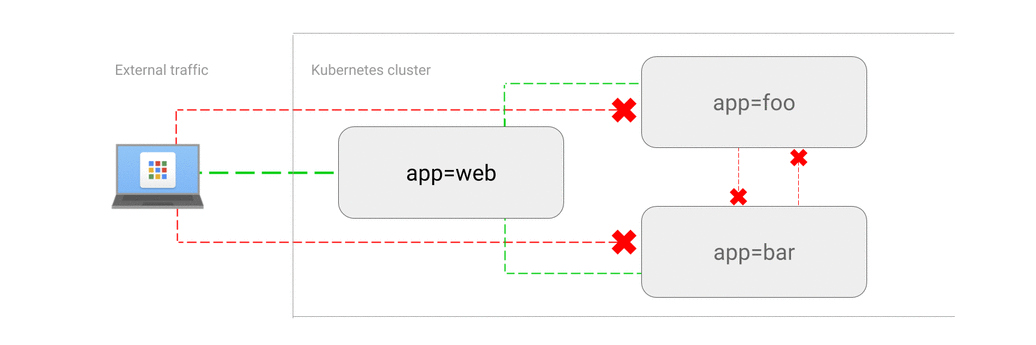
Мониторинг, вопросы безопасности и устранение неполадок сетевой инфраструктуры Kubernetes могут стать головной болью из-за больших различий в реализациях CNI а также свободе выбора при дальнейшей настройке k8s. Чем более сложное архитектурное взаимодействие между сервисами и компонентами k8s пытается настроить инженер, тем более вероятно возникновение проблем, например, таких – как блокировка сетевого трафика или неожиданные простои при работе приложения. А в свою очередь отказ от использования сетевых политик и шифрования трафика для упрощения микросервисной архитектуры поставит под угрозу безопасность разрабатываемого продукта.
Если вы хотите получить подробную информации о сетевых компонентах и взаимосвязях Kubernetes, могу порекомендовать следующее руководство.
???? Уже на этапе поднятия CNI для k8s можно наблюдать за функционированием
инфраструктурой при помощи встроенных инструментов Kubernetes (Kubernetes Dashboard, kubectl, Kubernetes Metrics Server и kube-state-metrics и получать информацию через Kubernetes API) либо при помощи инструментов, имеющихся в CNI плагинах (Calico observability tools, Cilium Hubble и т.д.).
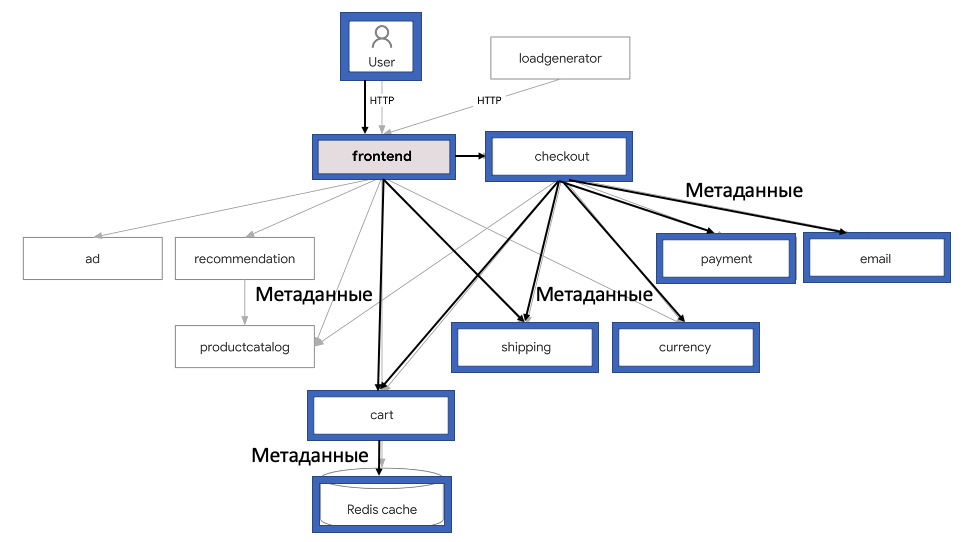
Пример микросервисной архитектуры в Kubernetes
За основу для тестов и экспериментов (во второй части) было выбрано следующее демо (14 тыс. звёзд и 5 тыс. форков):
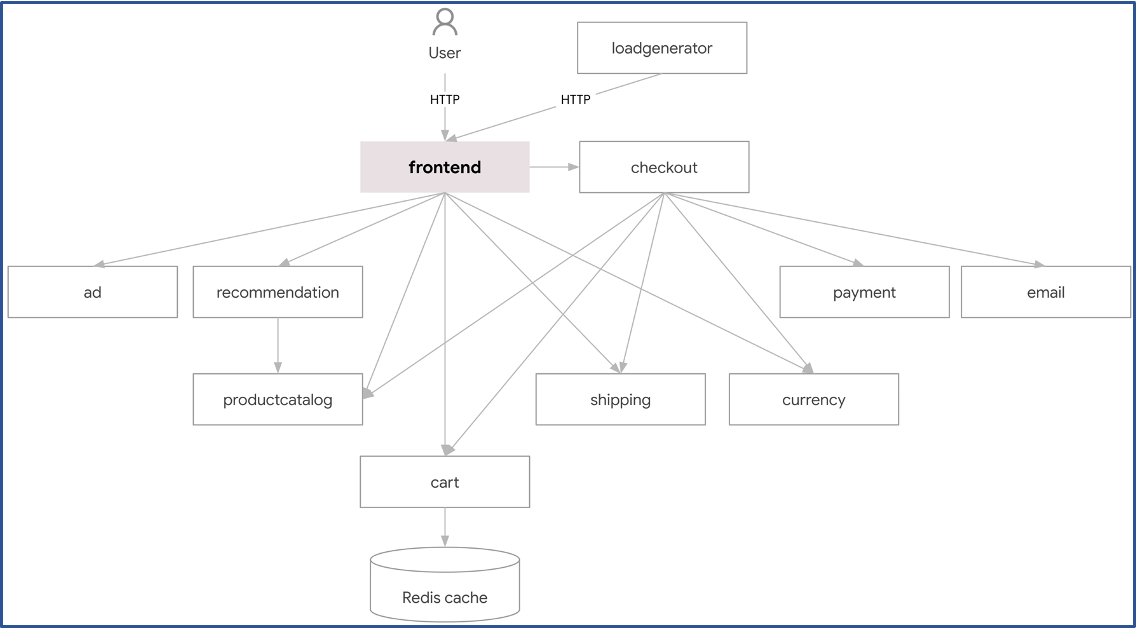
Данное приложение состоит из 11 микросервисов, написанных на разных языках (go, c#, JavaScript, Python, Java...), которые общаются друг с другом через gRPC:
Далее рассмотрим два проекта/"технологии" eBPF и OpenTelemetry, без которых невозможно дальнейшее обсуждение Observability и Kubernetes (либо нам придётся резко ограничить себя в выборе инструментов и соответственно информации, которую можно получить из микросервисов).
Подробный видео разбор с CNCF NA 2022 про возможности двух технологий, рассказывает разработчик продукта New Relic Pixie, о котором вскоре будет также рассказано.
eBPF и OpenTelemetry
eBPF (enhanced Berkeley Packet Filter) - это функционал ядра Linux, которая позволяет создавать и встраивать на уровне ядра программы, которые могут мониторить и контролировать различные события в системе. В Kubernetes eBPF может быть использован для мониторинга сетевого трафика между подами, анализа производительности приложений и обнаружения утечек ресурсов. Также с помощью eBPF можно создавать пользовательские метрики и отслеживать запросы приложений.
Для того, чтобы показать насколько eBPF стал популярен, стоит продемонстрировать количество проектов использующих его:
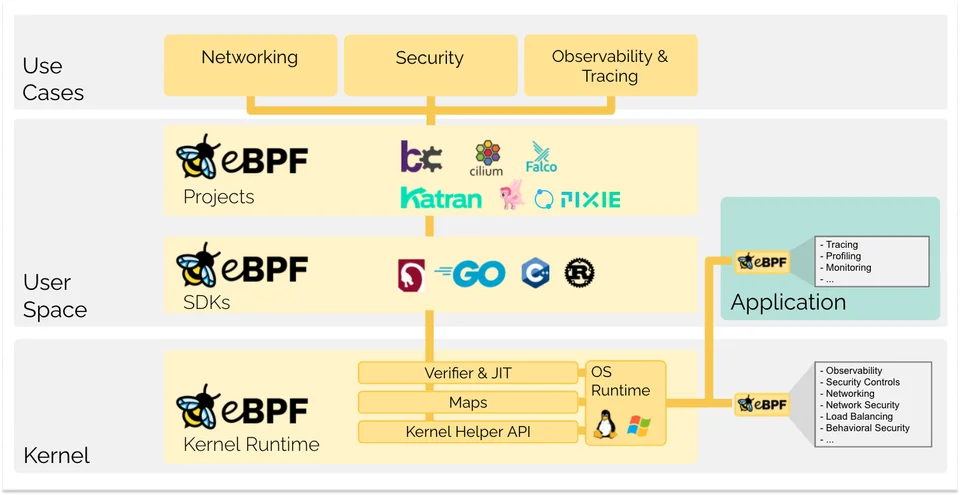
OpenTelemetry (OTel) - это набор инструментов и библиотек для сбора, анализа и экспорта метрик, трасс и журналов из приложений и инфраструктуры. OpenTelemetry может быть использован для мониторинга Kubernetes, включая мониторинг производительности, отслеживания запросов и обнаружения ошибок (в случае, если агент на нодах будет выдавать ему эту информацию). OTel поддерживает несколько языков программирования, включая Java, Python, Go, Ruby и другие, что делает его универсальным решением для сбора телеметрии из различных приложений и систем.
OpenTelemetry состоит из трёх основных компонент – формата данных, SDK для инструментирования приложений и коллектора для сбора, хранения и передачи данных. Связующим звеном является OTLP – OpenTelemetry Protocol.
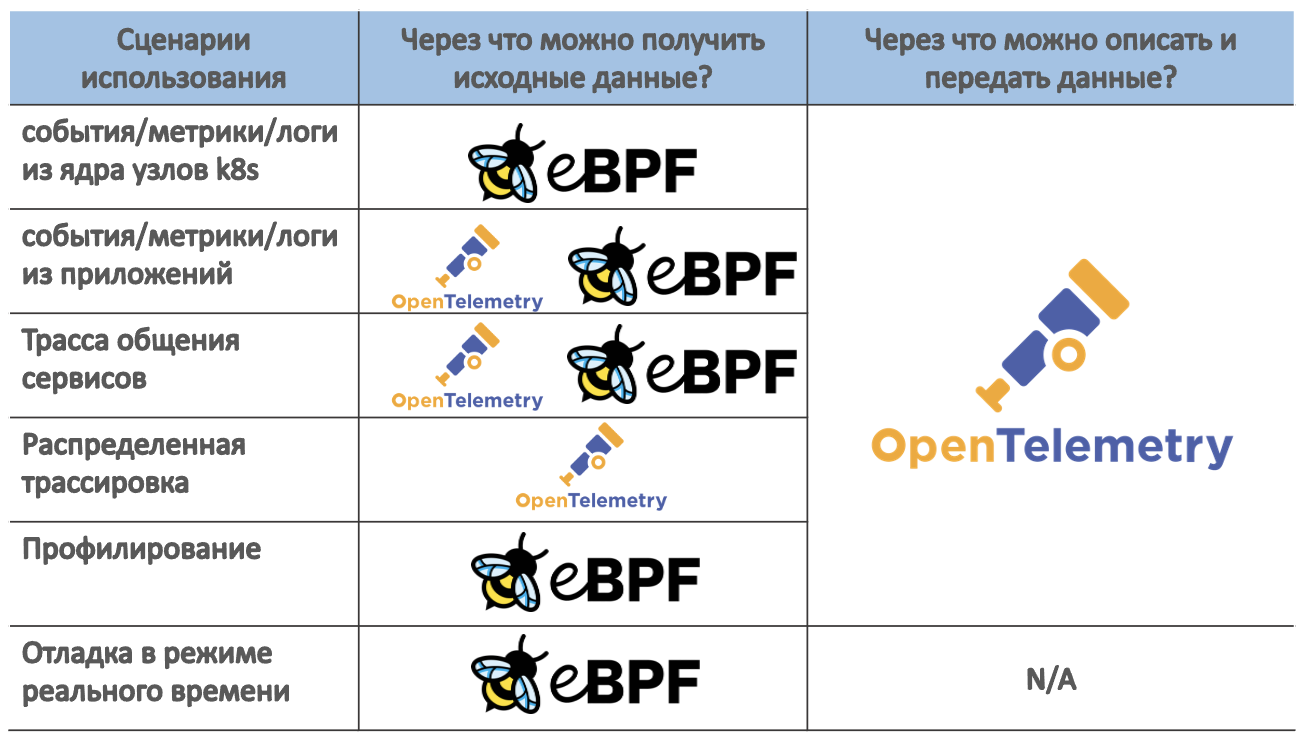
Обе технологии - eBPF и OpenTelemetry - имеют большой потенциал для улучшения Kubernetes Observability и способны точнее и быстрее диагностировать и устранять проблемы в микросервисной архитектуре.
Подробнее о eBPF
Berkeley Packet Filter (классический BPF) - это функционал ядра Unix, который был представлен в 1992 году и позволял программам пользовательского пространства выполнять код в определенных точках сетевого стека (рисунок 6). Основное назначение технологии заключалось в том, чтобы обеспечить настраиваемую stateless фильтрацию пакетов (работает быстрее statefull при интенсивном трафике) без накладных расходов, связанных с копированием пакетов в пользовательское пространство. Классический BPF широко использовался в таких инструментах, как tcpdump.
???? Если вы запустите tcpdump с фильтром (определенный хост или порт), он скомпилируется в оптимальный байткод BPF, который выполнится встроенной виртуальной машиной в ядре.
Разработка extended Berkeley Packet Filter (eBPF, расширенного BPF) в 2014 году открыла множество новых вариантов использования, особенно в серверных и микросервисных средах. Добавление новых точек подключения в ядре и в пространстве пользователя теперь позволяет контролировать или изменять поведение компонентов всей системы. Были введены постоянные структуры данных ядра, доступные как в пользовательском пространстве, так и в программах eBPF – eBPF maps, что позволило создавать программы eBPF с возможностью изменения состояний программ. Также на эволюцию eBPF повлияло увеличения числа регистров и увеличения размера регистров до 64 бит, введения соглашения о вызове с нулевыми накладными расходами и увеличения максимального размера стека. Хотя eBPF не является Тьюринг полным (из-за ограничений, накладываемых проверкой программы verifier'ом), его можно использовать для широкого спектра задач (рисунок 6). Развитие eBPF все еще продолжается: в новых версиях ядра доступны дополнительные точки перехвата, типы для eBPF maps и др.
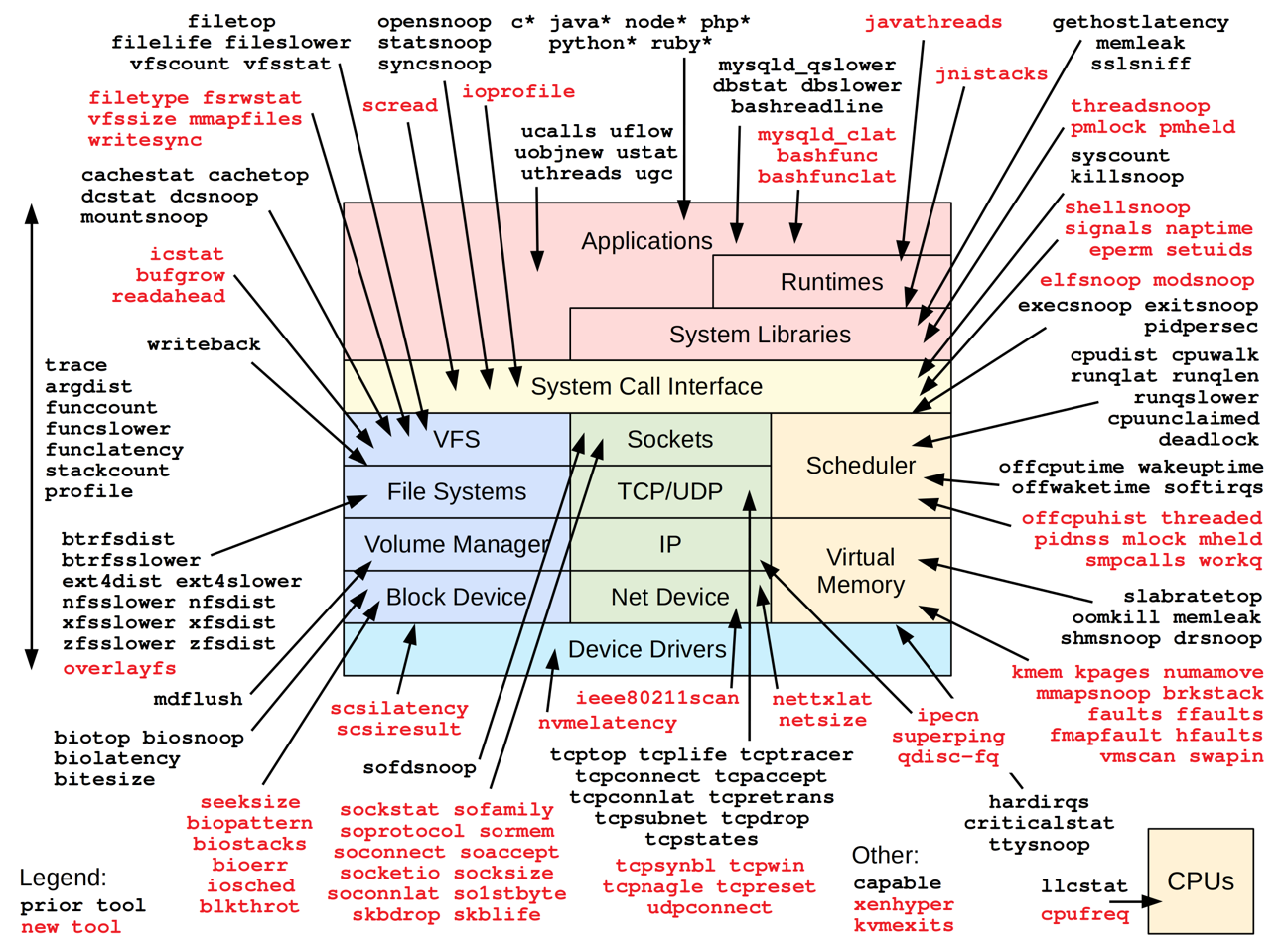
Программы eBPF могут быть запущены в различных "хуках" (hooks) ядра таких, как входящие и исходящие пакеты, системные вызовы и пр.:
XDP – Express Data Path, позволяет запускать программы BPF из сетевого драйвера;
kprobes – kernel probes, динамический доступ к внутренним компонентам ядра;
ebPF TC hooks – "TC" это "Traffic Control(er)", подсистема ядра Linux для формирования и приоритизации сетевого трафика. Использование eBPF обеспечивает более быстрое и точное управление правилами в ядре;
tracepoints – статический доступ к внутренним компонентам ядра;
uprobes – user-space probes, динамический доступ к программам, работающим в пространстве пользователя;
USDT – User statically defined tracepoints, статический доступ к программам, запущенным в пространстве пользователя;
и другие.
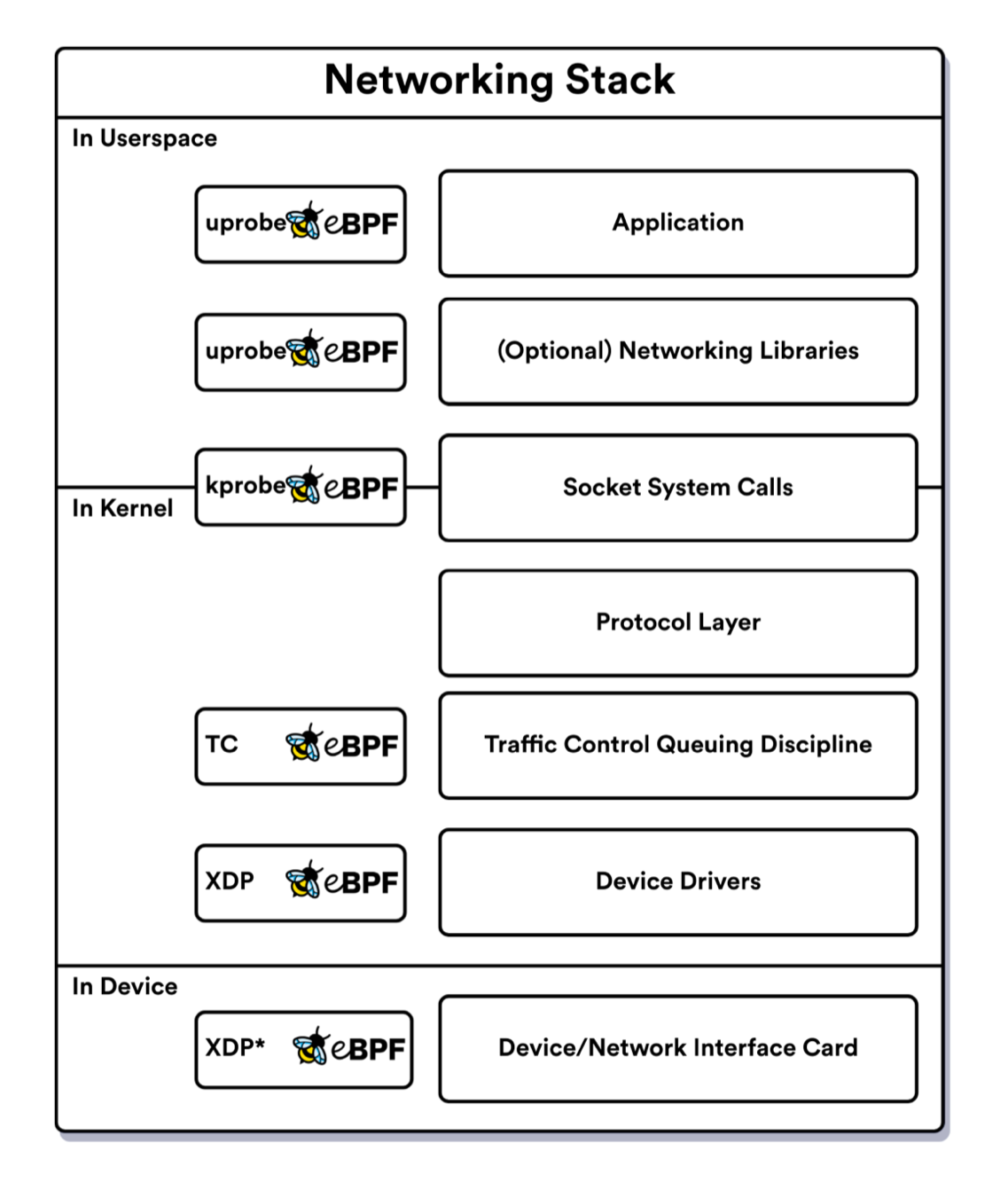
Другое определение более точно описывающее текущие возможности eBPF – это виртуальная машина, которая запускает программы из пространства пользователя и привязывает их к заданной точке ядра/пользовательского пространства/драйвера устройства для наблюдения за различными событиями.
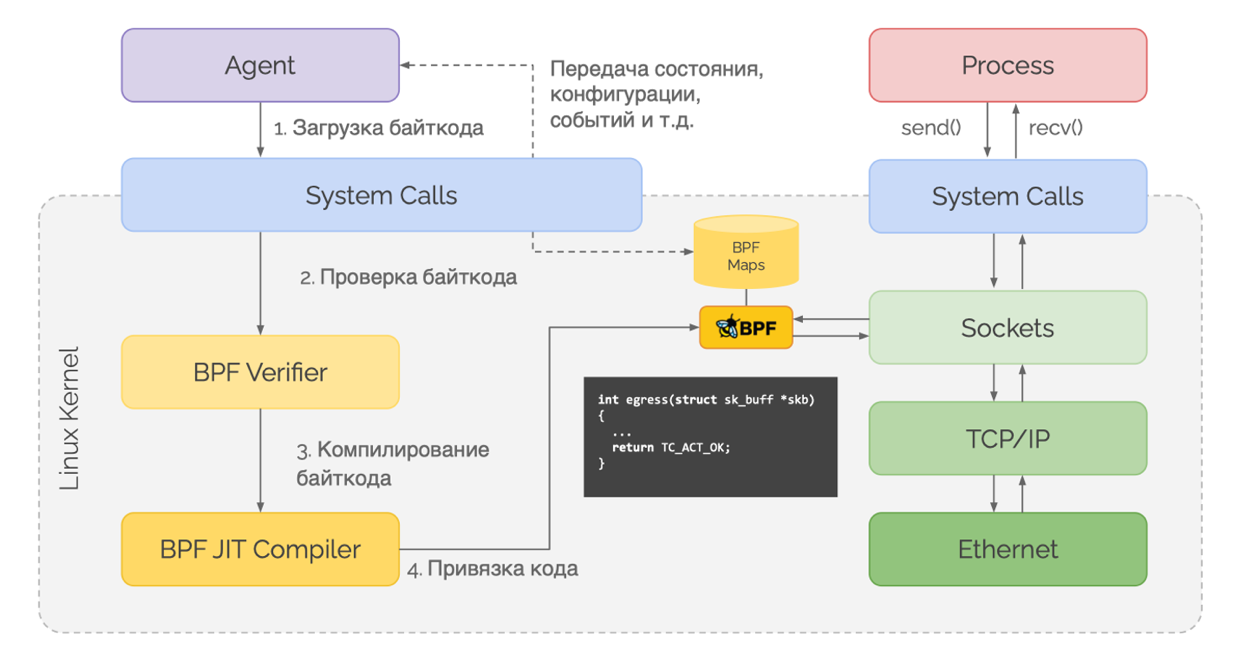
Применимость eBPF в Kubernetes
Архитектура приложений в Kubernetes отличается от традиционных серверных приложений, для которых изначально разрабатывалось ядро Linux. Так изменение поведения ядра может привести к упрощению, повышению производительности и улучшению других функциональных возможностей Kubernetes. Однако, добавление нового функционала в ядро – трудоемкий процесс.
eBPF позволяет быстро реализовывать новые инструменты (за счёт различных хуков), которые направлены на инфраструктуру Kubernetes и не могут быть включены в основное ядро без разработки собственных версий ядра или модулей ядра. Также программы eBPF могут быть использованы для создания функциональности ядра, которая будет лучше поддерживать приложения в контейнерных средах.
Cilium построили всё CNI решение на основе eBPF+XDP – это позволило им заметно ускорить сетевое взаимодействие сервисов в Kubernetes в сравнении с iptables. Calico тоже переводят свой CNI на eBPF, делясь знаниями по тому, как функционирует eBPF.
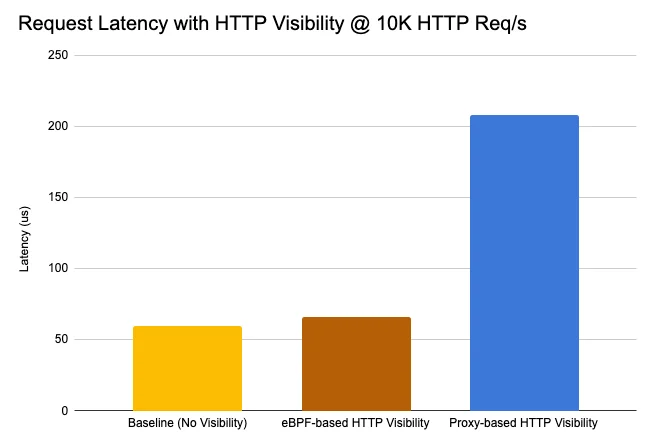
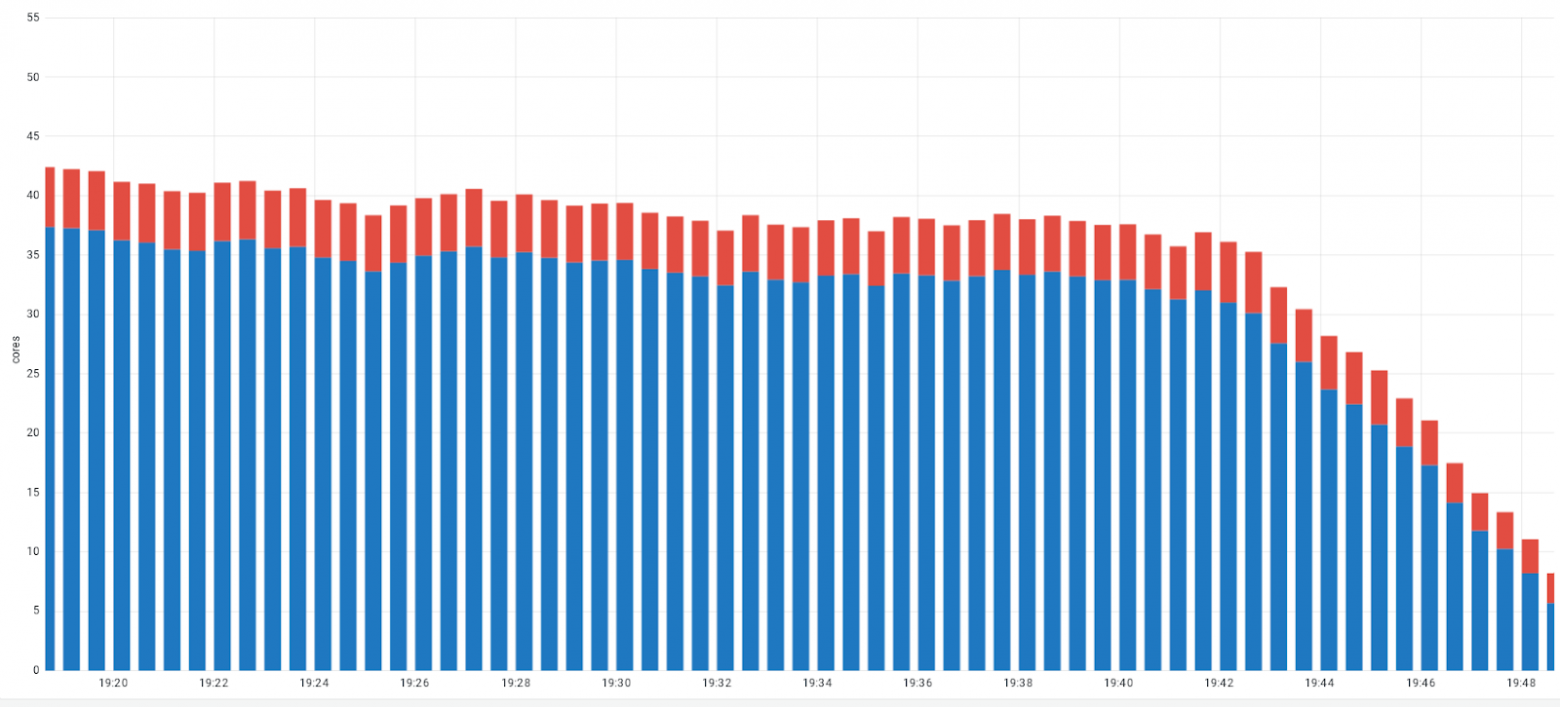
А на графике 1 сравнивается насколько сильно увеличивается задержка запросов и ответов при мониторинге HTTP протокола при помощи парсера на основе eBPF (коричневый столбец, Cilium eBPF + Envoy) и при использовании sidecar контейнера работающего, как HTTP прокси (синий столбец, Istio service mesh + Envoy). Где Envoy – это прокси для парсинга протоколов на уровне приложений, таких как HTTP, Kafka, gRPC и DNS.
Подробнее об OpenTelemetry
OpenTelemetry (Otel) – это стандарт распределенной трассировки и мониторинга. Otel в первую очередь ориентирован на сбор данных, а не на хранение или обработку запросов.
Основные типы обираемых данных при использовании OpenTelemetry:
Traces – контекст того, что произошло.
Resources – контекст, где произошла проблема.
Metrics – прикрепленный к трассам данные.
Logs – прикрепленные к трассам события.
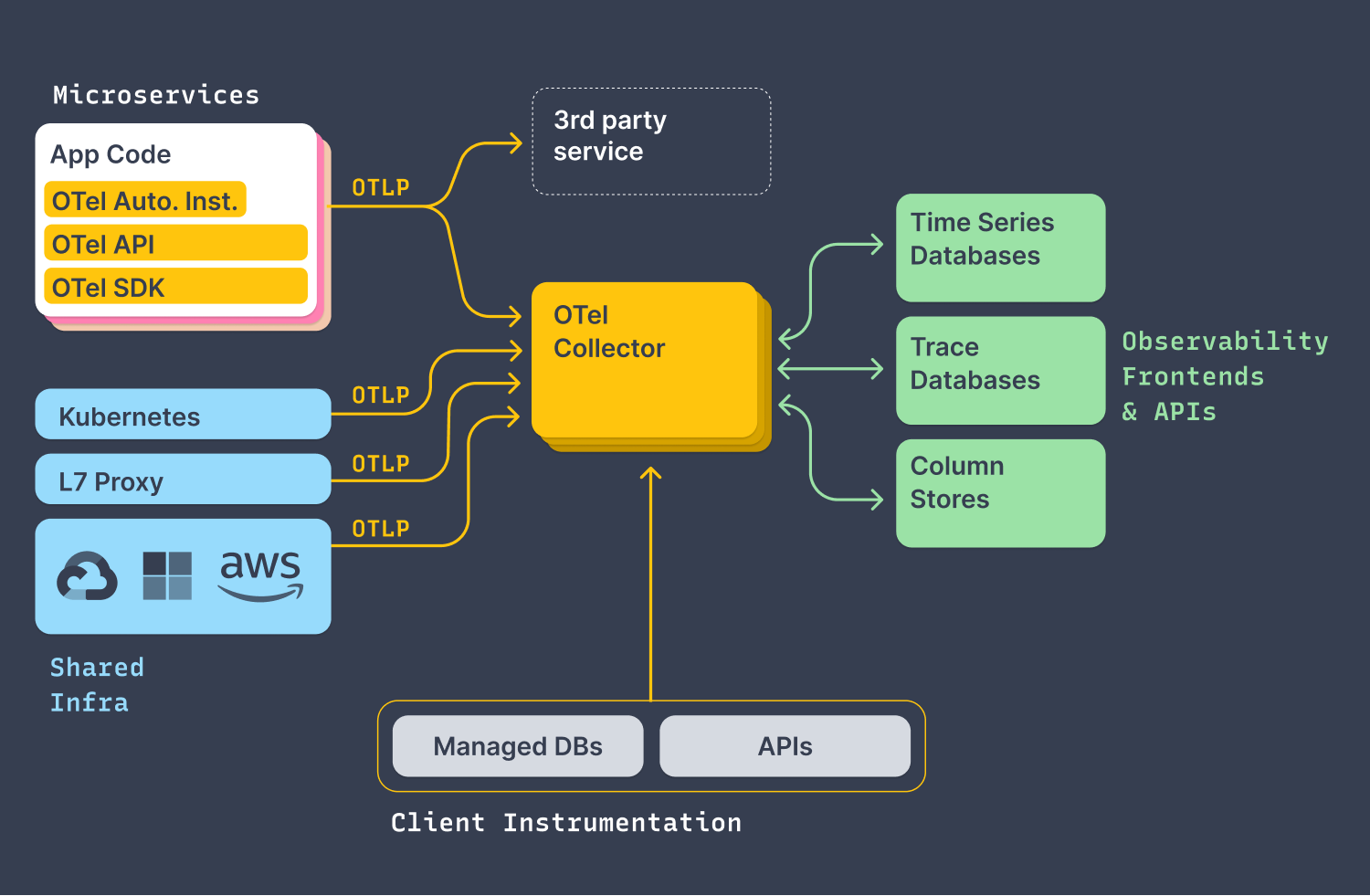
OpenTelemetry Collector
OpenTelemetry Collector может собирать данные из OpenTelemetry SDK и других источников, а затем экспортировать эту телеметрию в любой поддерживаемый бэкэнд, такой как Jaeger, Prometheus или очереди Kafka. OTel Collector может служить как локальным агентом, расположенным на одном узле k8s, так и центральным сервисом в распределенной системе, агрегирующим данные с нескольких узлов k8s.
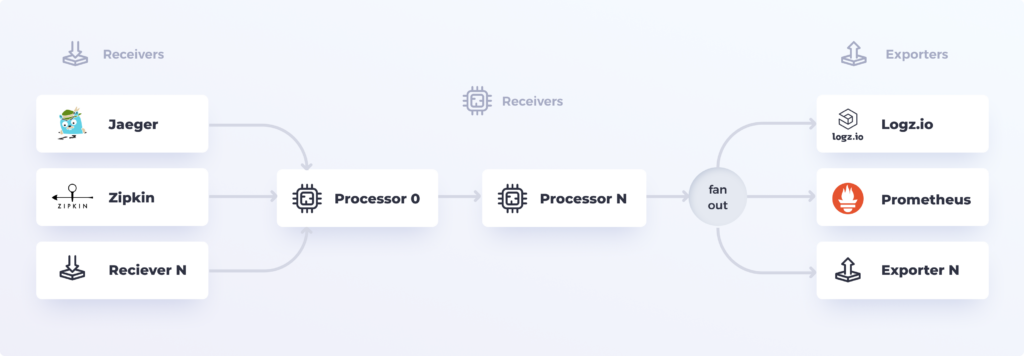
OpenTelemetry Collector построен как конвейер, состоящей из четырех основных частей:
Receivers для приема входящих данных различных форматов и протоколов, таких как OTLP, Jaeger и Zipkin. Список доступных приемников можно найти здесь.
Processors для выполнения агрегации данных, фильтрации, выборки и другой логики коллекторной обработки телеметрических данных. Процессоры можно объединять в цепочки для создания продвинутой логики обработки.
Exporters для передачи телеметрических данных в один или несколько конечных пунктов назначения (обычно инструменты анализа или агрегаторы более высокого порядка) в различных форматах и протоколах, таких как OTLP, Prometheus и Jaeger. Список доступных экспортеров можно найти здесь.
Connectors для соединения различных конвейеров в одном коллекторе. Коннектор служит как экспортером, так и приемником, поэтому он может потреблять данные как экспортер из одного конвейера и передавать их как приемник в другой конвейер. Например, Span Metrics Connector может агрегировать метрики из Span'ов.
OpenTelemetry protocol (OTLP) – единый, связный поток данных, содержащий ресурсы, трассы, метрики, журналы, профилирование и многое другое. За счёт наличия такого протокола можно, например, проводить простую миграцию с одного backend решения на другое (главное, чтобы другой инструмент поддерживал OTLP). OTLP работает в связке либо с gRPC, либо с HTTP. Для сериализации структурированных данных используется ProtoBuf (Protobuf payloads).
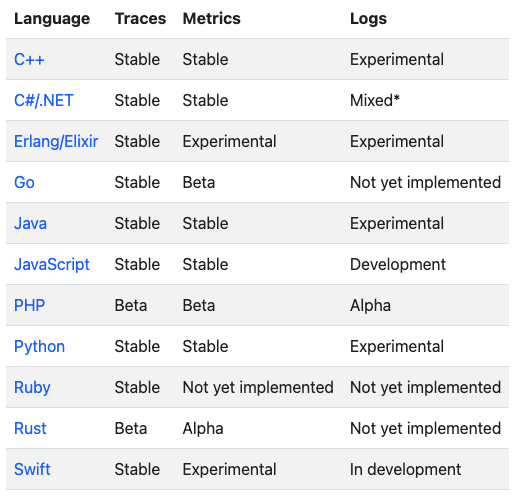
Приступая к оценке OpenTelemetry для своего проекта, вы должны сначала узнать свой стек разработки. Начните с этих трех основных вопросов:
Какие языки программирования и фреймворки? Например, Java и Spring для бэкенда и NodeJS и Express для фронтенда будут хорошим началом. Это определит клиентские библиотеки, которые вы будете использовать, и, возможно, агентов для инструментирования фреймворков (источник).
Какие типы сигналов и протоколы? Собираете ли вы журналы событий/метрики/трассу? Они поступают из вашего приложения через SDK или из других источников, таких как Kafka, Docker или MySQL? Это определит Receivers, которые вы будете использовать в вашем OpenTelemetry Collector.
Какие аналитические инструменты в бэкенде? Отправляете ли вы данные трассировки в Jaeger? Отправляете ли вы метрики в Prometheus? Или, возможно, в кластер Kafka для последующей постановки в очередь? За это отвечают Exporters.
Эволюция архитектуры инструментирования приложений
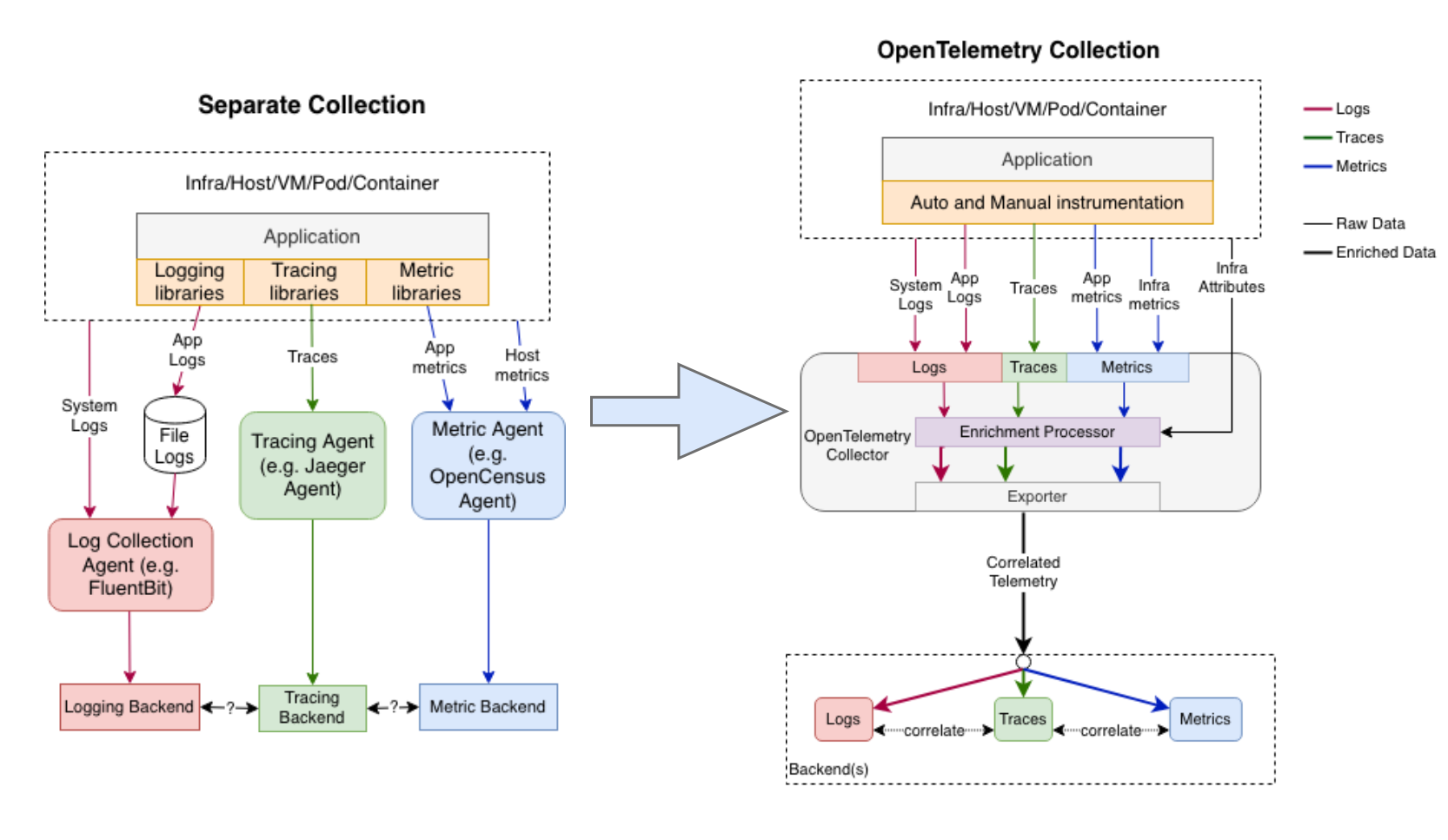
В традиционной архитектуре журналы, трассы и метрики генерируются и собираются отдельно. С OpenTelemetry все данные будут собираться OpenTelemetry Collector и передаваться на единый бэкэнд для объединения. Преимущества при таком подходе:
Приложение может реализовать Observability через OTel SDK, с меньшим количеством зависимостей и как одним из следствие меньшим потреблением используемых ресурсов.
Требуется только один коллектор, что снижает затраты на развертывание и эксплуатацию.
Формат данных унифицирован, что упрощает корреляцию данных.
На рисунке 10 показана конечная цель для архитектуры. Однако, по оценкам OTel сообщества, в ближайшие один-два года потребуются другие коллекторы журналов событий, поскольку OpenTelemetry Collector в настоящее время не обеспечивает достаточно надежную поддержку Log'ов.
Распределенная трассировка ввела понятие распространения контекста трассировки через метки TraceId и SpanId. И ничто не мешает для журналов событий принять те же концепции распространения контекста. Если бы записанные журналы содержали идентификаторы контекста трассировки (TraceId/SpanId/Resources или другие определяемые пользователями метки), это привело бы к гораздо более сильной связи между журналами, метриками и трассами; а также между журналами, собираемыми из различных компонент распределенной системы.
Это одно из перспективных направлений развития инструментов Наблюдаемости. Стандартизация корреляции журналов с трассировками и метриками через OTel повысит совокупную ценность Observability информации для различных систем (напоминает
подход Datadog со своими связующими тэгами для разных типов данных).
Применимость такого метода в Kubernetes
Например, OpenTelemetry Collector может добавить ко всем телеметрическим данным, поступающим от Kubernetes Pod, несколько атрибутов, которые описывают pod, и это может быть сделано автоматически с помощью k8sprocessor без необходимости для приложения делать что-либо специальное. Самое главное, что такое обогащение полностью одинаково для всех трех типов данных. Коллектор выступит гарантом, что журналы, трассы и метрики имеют точно такие же имена и значения атрибутов, описывающих k8s pod, из которого они получены.
Существующие подходы к мониторингу и Наблюдаемости в Kubernetes
Существует множество подходов к мониторингу кластеров Kubernetes. Далее проведем обзор нескольких общих подходов и их пригодность для различных сценариев.
Распределенная трассировка
Распределенная трассировка (трасса) - это подход к инструментированию сервисов k8s для профилирования (сбора характеристик программы во время её выполнения) и мониторинга приложений на базе микросервисов. Подобно трассировке в традиционных сетях, целью распределенной трассировки является создание и сбор низкоуровневой информации о выполнении программы так, чтобы запросы и ответы конкретного микросервисного приложения можно было отслеживать на протяжении всего времени их жизни в программе. Эта информация может быть использована для мониторинга работоспособности/производительности приложения а также во время процесса его отладки. Например, распределенная трассировка может использоваться для выявления узких мест функционирования сервисов при решении задач оптимизации и повышения производительности прикладной инфраструктуры.
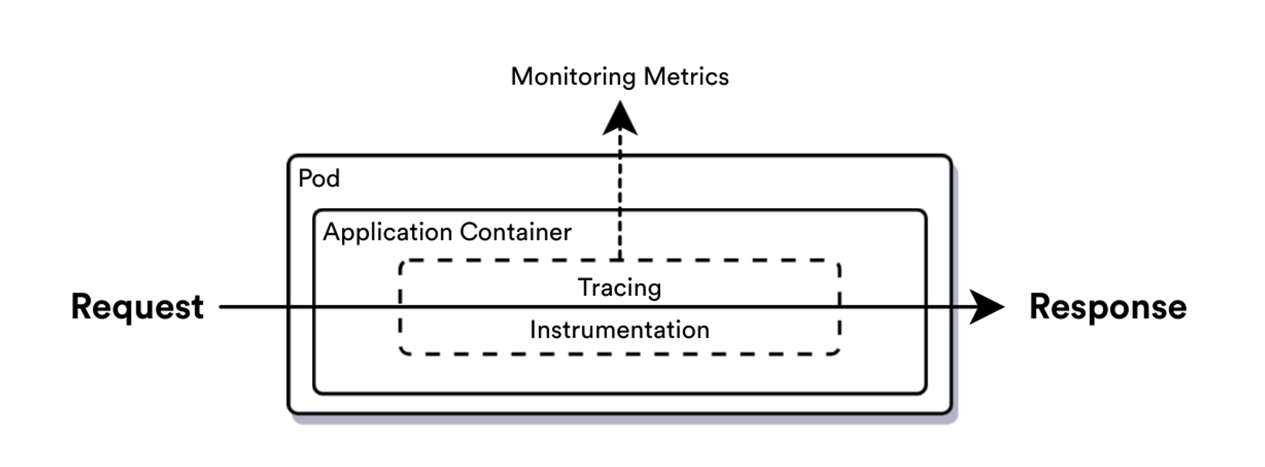
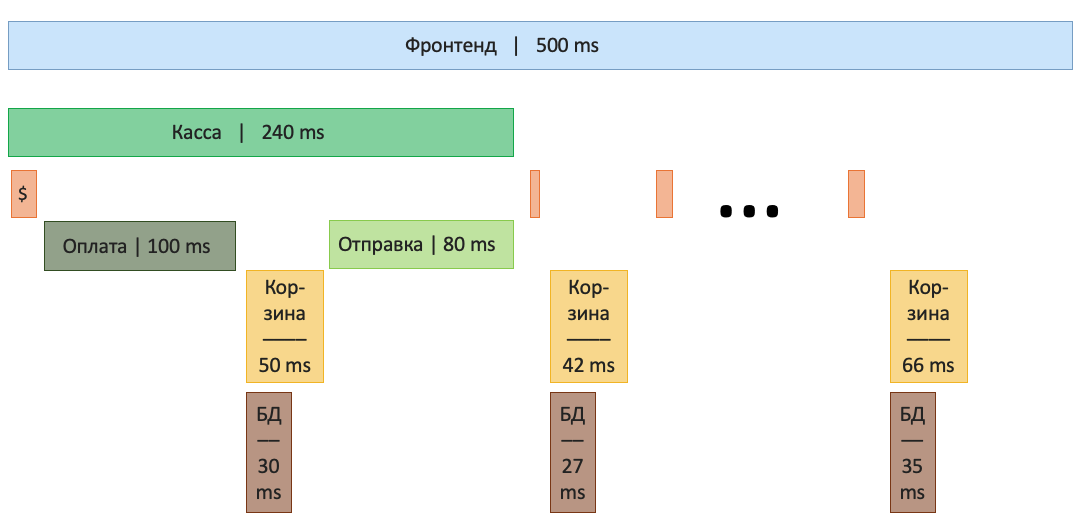
Базовый пример сбора распределенной трассы на основе микросервисной архитектуры магазина товаров:
1. Клиент начинает взаимодействие с интерфейсом приложения.
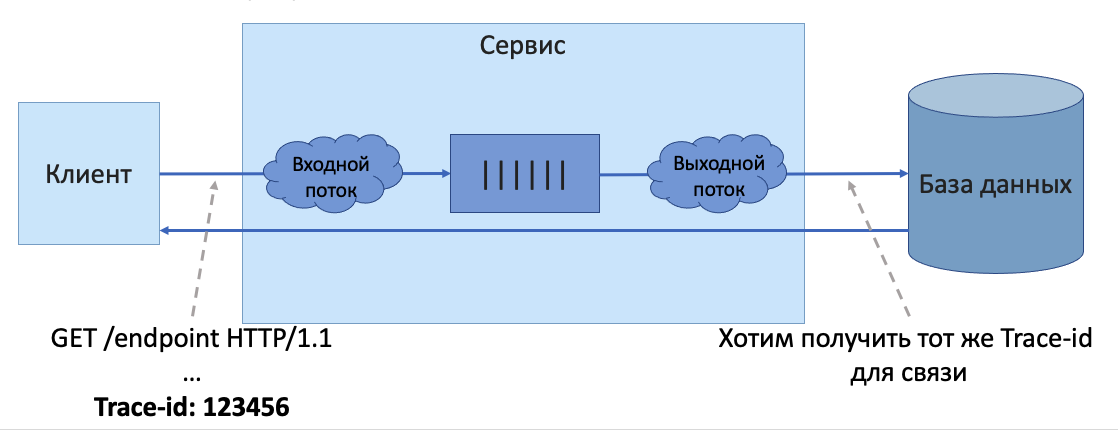
2. Инфраструктура приложения должна уметь распространять контекст/метаданные (уникальный идентификатор запроса и характеристики, которые хотим пронаблюдать) между микросервисами, чтобы собирать всю информацию о конкретной трассе исходящей от пользователя.
3. Формируется распределенная трасса приложения, при помощи которой можно проследить сколько времени выполнялся каждый микросервис (в терминах распределенной трассы – spans, на рисунке 13 эти прямоугольники выделены синим) от общей продолжительности запроса пользователя, зашедшего на сервис и получившего ответ в Web UI. К тому же в каждом из таких spans можно переносить метрики (иногда логи) или просто метки процессов, по которым можно скоррелировать информацию, выдаваемую при помощи других Observability инструментов.
Распределенную трассу можно получить использую различные API и инструменты, такие как OpenTelemetry, Jaeger, Elastic, Odigos (проект на основе OpenTelemetry и eBPF).
Основным недостатком подхода распределенной трассировки является то, что он не всегда может быть динамически инструментирован. Часть функционала того же OpenTelemetry можно внедрить только после написания дополнительного кода под конкретный микросервис. Поэтому добавление распределенной трассировки в существующие приложения может быть длительным и трудоемким процессом.
В тех случаях, когда инструментировать код невозможно, например, в закрытых бинарных файлах сторонних разработчиков, можно анализировать входящие и исходящие запросы микросервиса при помощи eBPF. Однако такой способ проигрывает распределенной трассировке в уровне детализации.
Важно отметить, что решения для полного сбора распределенной трассы, основанного на eBPF, на данный момент нет. Это связано с тем, что распространение контекста/метаданных требует, во-первых, ручного интструментирования кода при помощи USDT хуков. А, во-вторых, прикрепления Trace-id в заголовок сообщений между микросервисами. Также сложной задачей является сохранение этой информации при прохождении "конвейера" функций одного из сервисов.
Service Meshes
Service Mesh – это отдельный инфраструктурный уровень, который мы добавляем к приложениям для взаимодействия между сервисами k8s.
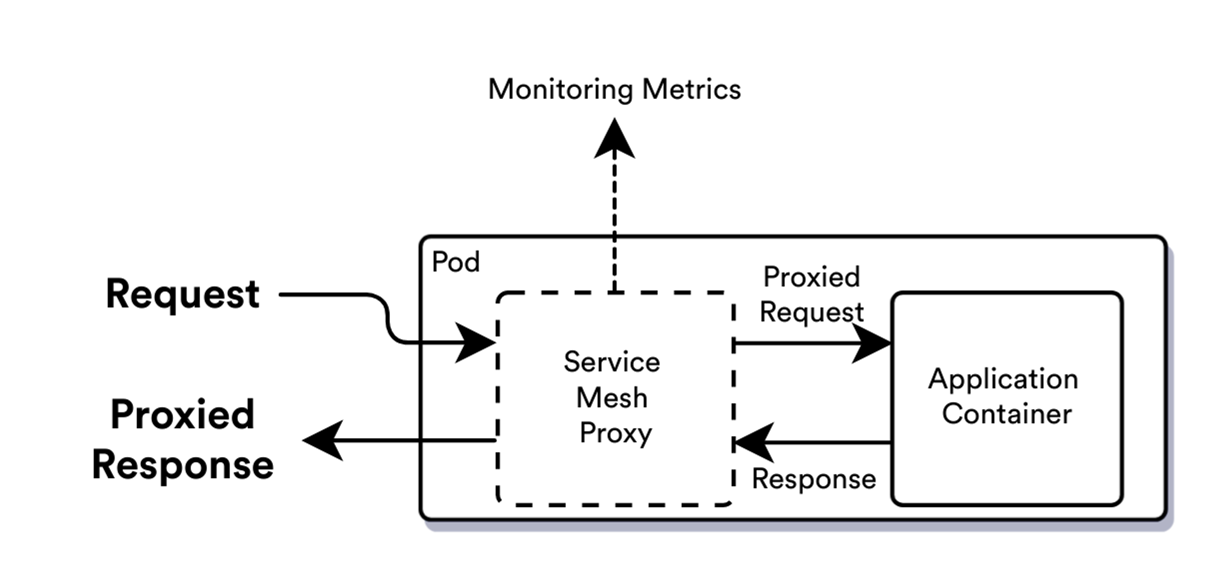
В Service Mesh входит широкая категория инструментов Kubernetes, которые обычно направлены на управление нагрузкой, маршрутизацию трафика, обеспечение безопасности и Наблюдаемость. Однако, у Service Mesh есть некоторые недостатки, например, этот подход требует изменения инфраструктуры k8s в сравнении с распределенной трассировкой, к тому же обладает меньшей производительность по сравнению с Cilium (график 1). Кроме того, Service Mesh требует точного подсчёта дополнительных используемых ресурсов. Поэтому, прежде чем принимать решение о реализации Service Mesh в собственной системе, необходимо тщательно изучить его возможности и ограничения.
Далее подробно остановимся на описании двух решений: Linkerd и Istio.
Linkerd – это Service Mesh, обладающий малым набором функций, но и низким потреблением ресурсов. Использует специализированный прокси linkerd2-proxy, который не позволяет пользователям создавать собственные метрики, но предоставляет набор функций мониторинга по умолчанию:
1. Метрики на уровне приложений (объемы запросов, коды ответов HTTP или gRPC и успешность отправки сообщений).
2. Метрики транспортного уровня (количество открытых или закрытых TCP-соединений, общее количество байт, отправленных или полученных по TCP, и продолжительность времени, в течение которого TCP-соединения были открыты).
3. Метрики для протоколов – общее количество запросов либо ответов и данные по задержке.
4. Маркировка рабочей нагрузки (k8s workload) запущенных приложений в k8s. Предыдущие метрики из пунктов 1-3 маркируются связанными с ними рабочими нагрузками Kubernetes.
Istio обладает более широким набором функций, чем Linkerd, и использует прокси-сервер общего назначения Envoy. Данный Service Mesh предоставляет API для реализации пользовательских метрик с доступом ко всем стандартным атрибутам Envoy, что позволяет пользователям лучше адаптировать мониторинг с помощью Istio под свои сценарии. По умолчанию Istio включает метрики аналогичные Linkerd плюс метрики внутреннего состояния Envoy (время работы и использованная память). В итоге для обеспечения этих функций Istio имеет более высокие накладные расходы по производительности в сравнении c Linkerd (плюс у Istio есть Web UI Kiali с довольно обширной кастомизацией данных). Отсюда вывод, многое будет зависеть какой прокси для sidecar использует конкретный Service Mesh.
Istio, с точки зрения популярности, является текущим лидером в подходе Service Mesh. С точки зрения возможностей, это самый мощный и продвинутый инструмент. С положительной стороны Istio выделяет его большое сообщество разработчиков. Установка и использование Istio сравнимы по сложности с установкой кластера Kubernetes поверх кластера Kubernetes.
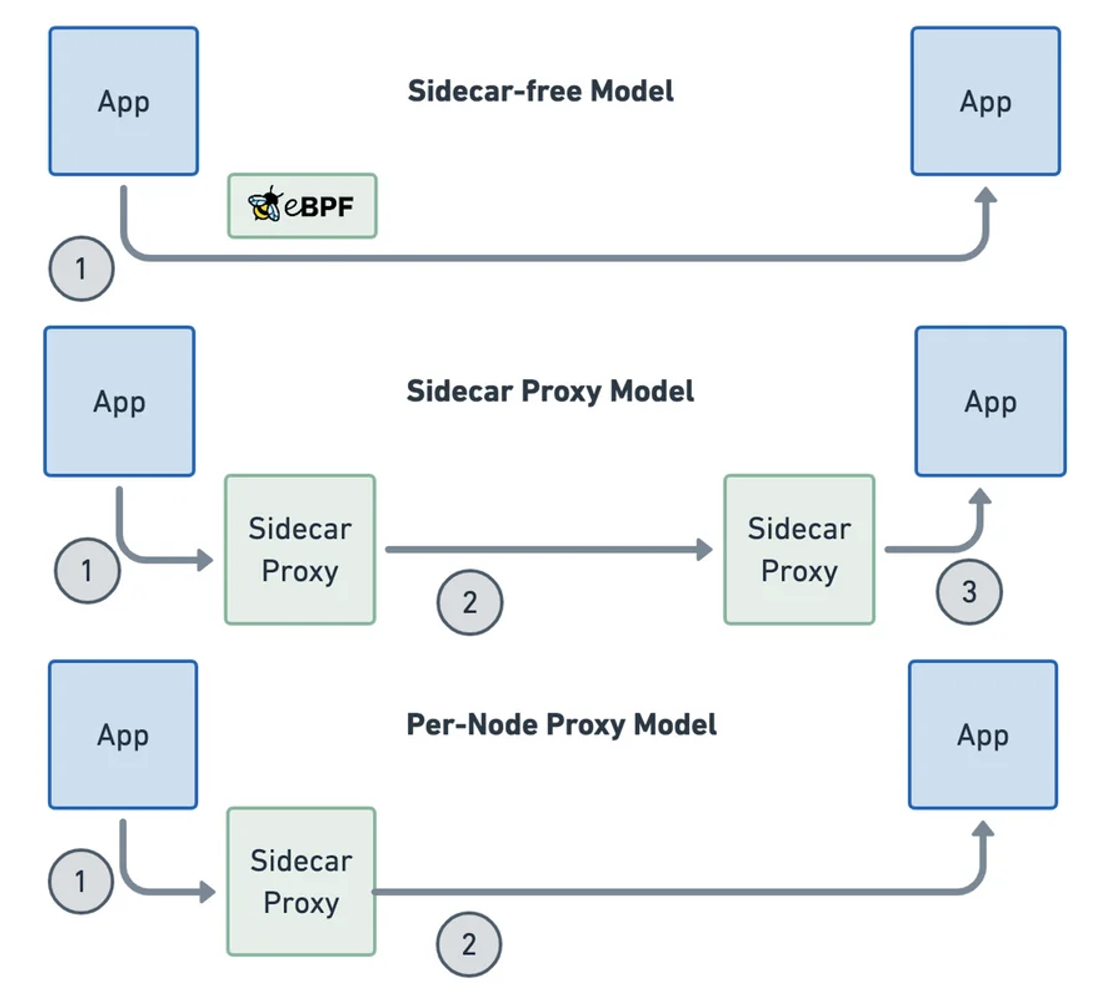
Основным недостатком Service Meshes является то, что это тяжеловесные решения, особенно если основной функцией, представляющей интерес, является только Наблюдаемость. Каждому поду на кластере требуется свой собственный выделенный прокси sidecar, который в Service Mesh'ах, таких как Istio, является полноценным прокси общего назначения. Это приводит к увеличению задержки, поскольку весь сетевой трафик пода должен быть перенаправлен через этот прокси. Это также приводит к более высокому использованию ресурсов, особенно памяти, так как для каждого пода на кластере работает отдельный прокси.
Анализ, проведенный Эндрю Вэем, показал, что для микросервисного приложения, работающего на minikube с симулированной нагрузкой, Istio увеличил использование памяти примерно на 20% по сравнению с той же нагрузкой без Service Mesh. Схожие цифры получились на CNCF конференции при сравнении решения Service Mesh (Istio + Envoy) с eBPF в 2020 году. Хотя показатель нагрузки на кластер может значительно варьироваться в зависимости от конфигурации, исследования демонстрируют избыточное использование ресурсов при подходе Service Mesh.
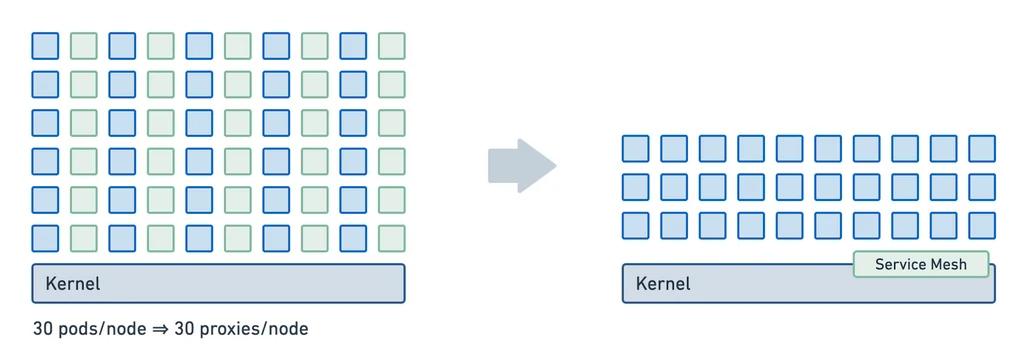
Существуют проекты, пытающиеся реализовать Service Meshes без sidecars для повышения производительности (Istio также смотрит в эту сторону и сейчас внедряет собственное решение без sidecars - Istio Ambient Mesh). Одним из проектов, на который стоит обратить внимание, является Cilium Service Mesh, которая использует eBPF для выполнения некоторых функций Service Meshes непосредственно в ядре, а для неподдерживаемых функций возвращается к модели proxy-per-node, в отличие от модели proxy-per-pod, используемой в sidecars.
Если вам интересно углубиться в сравнение разных подходов Service Meshes, существует открытая таблица от learnk8s research (на сайте присутствуют и другие другие сравнительные таблицы) с периодическими обновлениями (последнее от 25 мая 2022 года) – таблица здесь.
Системы мониторинга на основе eBPF
Как уже говорилось, eBPF можно использовать для высокоэффективного мониторинга кластеров Kubernetes. Следует отметить три больших и популярных open-source проекта по мониторингу: Cilium Hubble, Weave Scope и Pixie, которые в значительной степени используют eBPF. Есть open-source инструменты менее масштабные, но так же использующие eBPF для мониторинга: Coroot (российский разработчик), Caretta, Packet where are you, Inspektor Gadget и др.

Cilium Hubble - это инструмент Наблюдаемости, интегрированный с CNI плагином Cilium. Cilium CNI присоединяет eBPF программы к различным точкам сетевого стека Linux для реализации сетевой модели Kubernetes и дополнительных функций, таких как внедрение сетевых политик. Интегрируясь во многие уровни сетевого стека для обеспечения основной функциональности, он также легко может собирать данные о поведении этих систем. Полученные данные плагином Cilium CNI используются Hubble для получения таких показателей, как количество HTTP-запросов и DNS-запросов, а также количество потерянных пакетов. Hubble также создает граф зависимости сервисов k8s, что позволяет пользователям анализировать потоки данных их приложения.
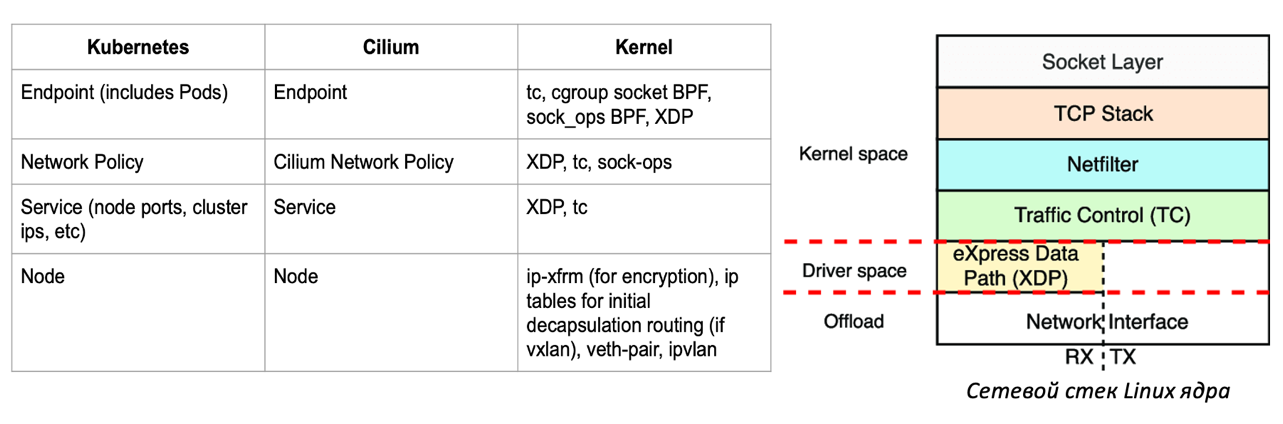
Hubble зависит от всего проекта Cilium. Поскольку Cilium - это в первую очередь сетевой плагин для Kubernetes, а не решение для мониторинга, для многих пользователей Observability функции являются дополнительным преимуществом Cilium и часто не являются достаточной причиной для его развертывания. В Cilium реализованы функции безопасности и кардинально другой подход к реализация сетевого взаимодействия (а не привычные iptables/netfilter). Это также может стать препятствием для его использования, если существующие конфигурации кластеров клиентов несовместимы с прикладной инфраструктурой – определенные версии ОС Linux на момент написания статьи могут не поддерживать Cilium (и другие инструменты на eBPF). Например, Cilium не работает на "самой защищенной" Astra Linux (комментарий из VK Kubernetes Conf'23 тайм код 1:06:08, вопрос звучит чуть раньше). Другим препятствием может быть случай, когда затраты на вычислительные ресурсы превышают пользу от использования Hubble для мониторинга (об этом говорилось на прошедшей конференции Яндекс Kuber Conf’23 ).
Важно учитывать, что функционал eBPF напрямую зависит от версии ядра. Например, для проекта Cilium минимальная поддерживаемая версия ядра выше, чем может потребоваться только для некоторых метрик в вашем проекте или продукте. Отсюда возникает идея с модульным подходом – предоставление набора инструмента. Из которого уже можно выбрать нужный вам функционал, а не поднимать все инструменты сразу, что в свою очередь облегчит поддержку старых версий ядра.
New Relic Pixie и Weave Scope - системы ориентированные на мониторинг. И включающие в себя, на примере Pixie, модульный подход при разработке инструментов для k8s инфраструктуры.
Pixie использует eBPF для сбора метрик и событий, без необходимости ручного инструментирования (изменения кода, повторного развертывания и т.д.). Pixie хранит и обрабатывает данные телеметрии в памяти кластера до 24 часов, с возможностью дальнейшего экспорта в формате OpenTelemetry в другие бэкенды.
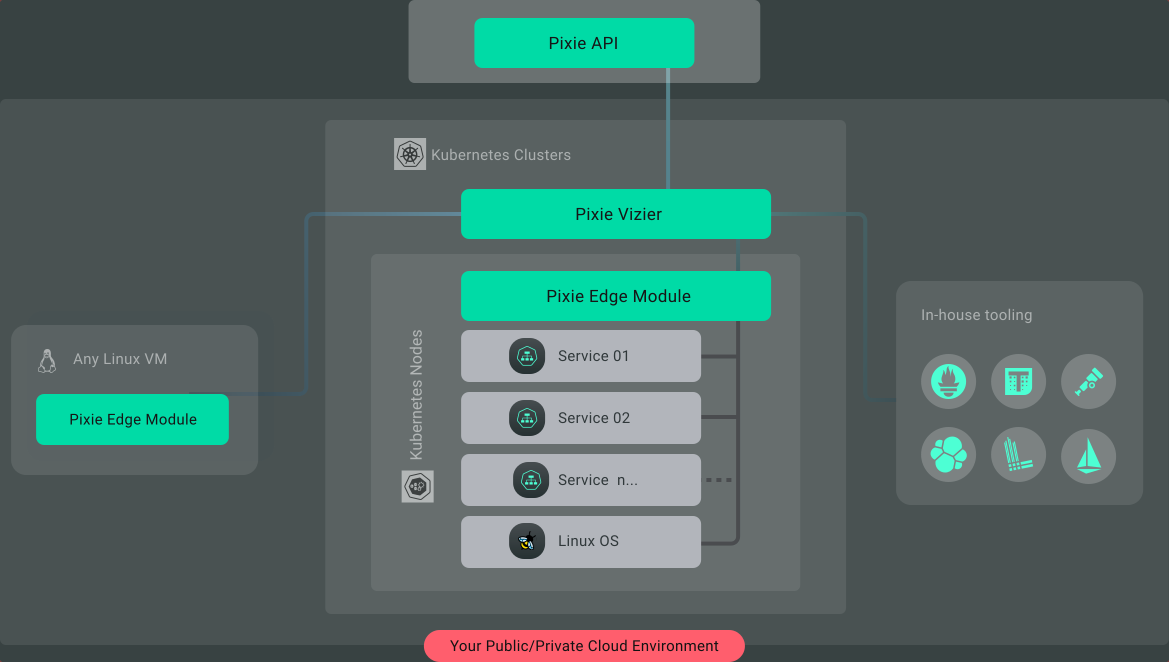
Weave Scope - это система мониторинга и управления кластером в реальном времени. Программы eBPF подключаются к TCP сокетам пода для перехвата точек отправки и назначения текущего трафика. Эти данные используются в пользовательском интерфейсе Weave Scope для создания топологии кластера в реальном времени. Исторические данные не сохраняются, что ограничивает возможности использования собранных метрик и делает инструмент в первую очередь ориентированным на управление в реальном времени (тоже относится и к Hubble/Pixie). В Weave Scope реализованы дополнительные плагины, которые могут быть использованы, например, для создания пользовательских метрик из захваченного HTTP-трафика. У Scope коллекторы не поддерживают экспорт данных во внешние сервисы (например, Grafana), что делает его не подходящим для построения единой Observability системы.
Pixie нпредлагает более широкий спектр инструментов по сравнению с Weave Scope и генерирует исторические данные (но хранить их можно либо в Pixie Cloud либо отправлять через OpenTelemetry формат в другой сервис). Например, один из сценариев по созданию FlameGraph'а нагрузки:
1) PEM агенты подключают eBPF kprobes хуки к системным вызовам ядра.
2) Далее от этих хуков приходят eBPF события содержащие измеренную производительность, которые PEM сохраняют на узле, а затем передают Vizier коллектору.
3) Данные передаются из коллектора в API для создания FlameGraph'ов выполненных рабочих нагрузок.
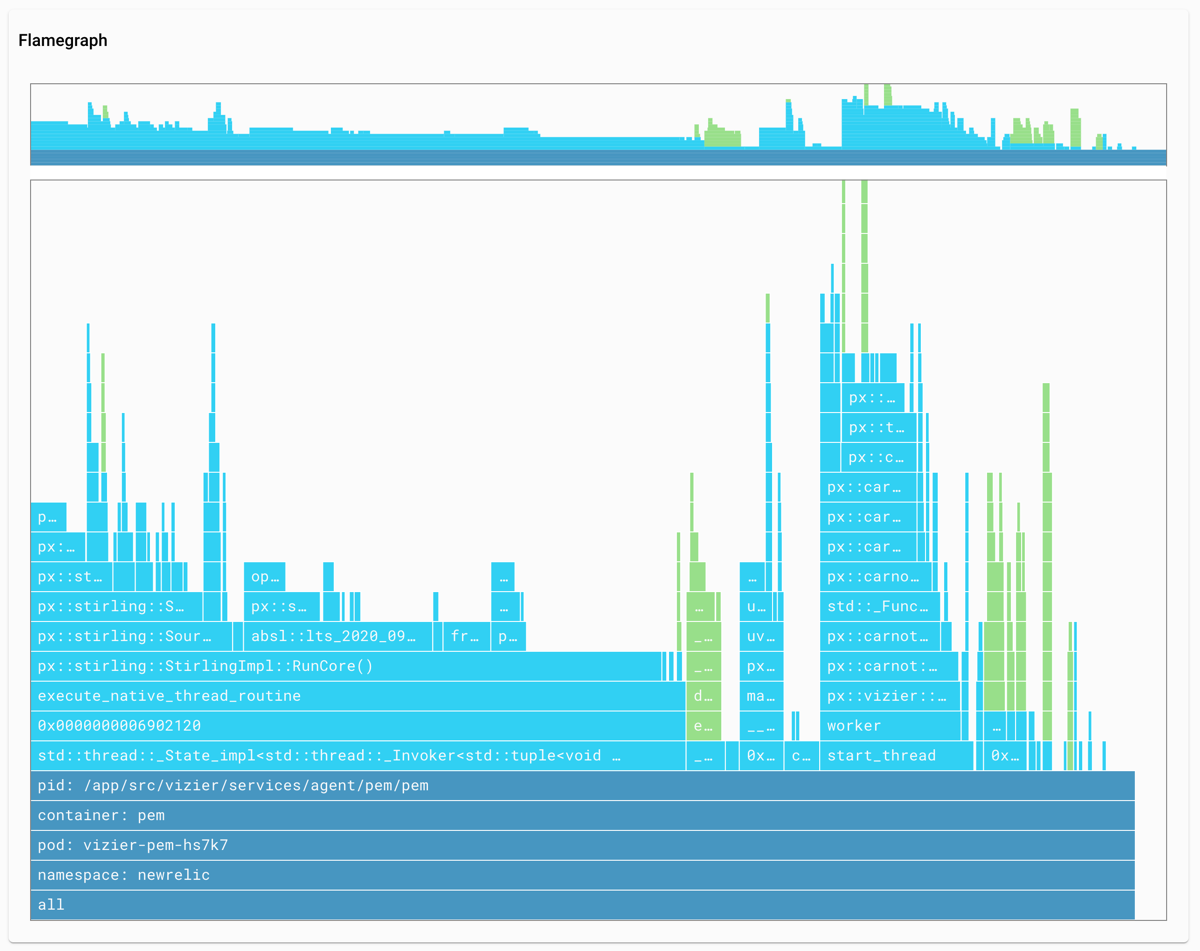
В Pixie также можно использовать uprobes либо bpftrace хуки, для наблюдения за событиями в пользовательском пространстве либо для профилировании индивидуальных событий через CLI, соответсвенно.
В дополнение к тому, что Weave Scope и Pixie это плотно интегрированные системы, они в части своего функционала используют не самый оптимизированный модуль для eBPF программ – BPF Compiler Collection (BCC), написанную на Си (сейчас происходит переход на более новую библиотеку libbpf). Это ещё одна особенность использования eBPF, нужно понимать в какой среде разрабатывались программы для конкретного инструмента. Так как это влияет:
1) на размер используемых ресурсов запущенных eBPF программ;
2) нужно ли загружать дополнительные зависимости в легковесные контейнеры, чтобы работала компиляция;
3) а также на поддержку портативности одного и того же функционала на разных версиях ядра.
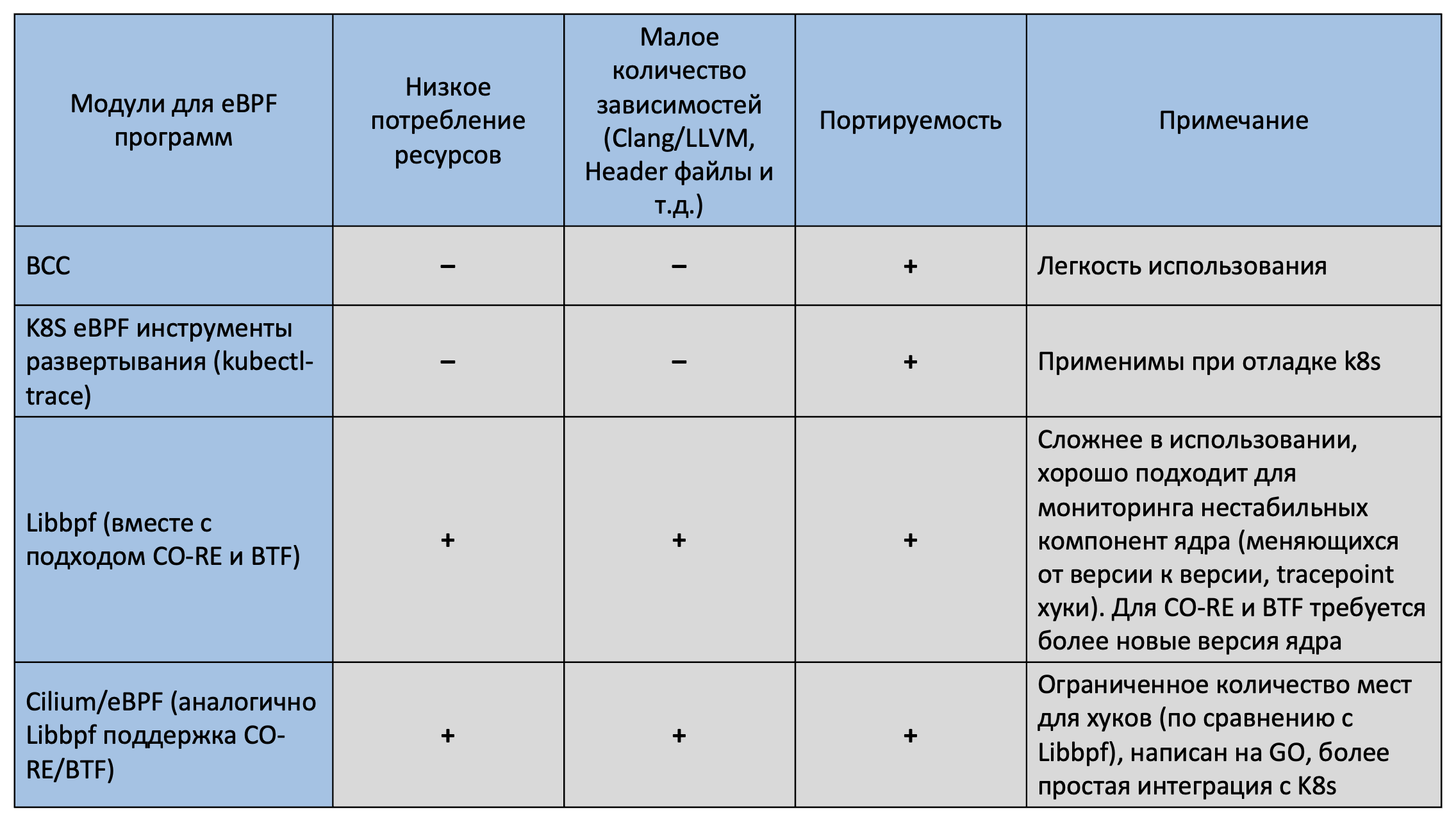
Например, для установки нужных заголовочных файлов для компиляции BCC eBPF программ Pixie комплектует узел подмножеством заголовков ядра. Во время выполнения, если заголовки не установлены на машине, выбираются наиболее подходящие из поставляемых заголовков. Чтобы убедиться, что динамически выбираемые заголовки совместимы с работающей системой, разработчики Pixie вручную формируют множество всех версий ядра, которые изменяют нужные структуры данных. Это довольно нестабильный подход и требует непрерывной технической поддержки по мере выпуска новых версий ядра.
Если интересно подробнее узнать про модули разработки eBPF программ – видео с конференции CNCF NA 2021
Классы инструментов наблюдения за сетевой инфраструктуры Kubernetes
Сформулируем классы инструментов, которые могут помочь при мониторинге и устранении неисправностей сетевой инфраструктуры Kubernetes. Как было написано ранее, часть из них идут как отдельные проекты по Наблюдаемости, другая часть реализуют свои инструменты как дополнение к основному функционалу продукта. Разобьём решения на следующие классы.
I. Инфраструктурные продукты с инструментами по Наблюдаемости:
Kubernetes: Kubernetes CLI/API (+ отдельная установка kubectl-trace).
Service Mesh: Istio (+ Kiali UI), Linkerd.
CNI: Cilium Hubble, Calico.
II. Продукты нацеленные на покрытие задач по Наблюдаемости:
Комплексные системы мониторинга: Pixie, Weave Scope, Caretta, Coroot.
Точечные решение по сетевой и распределенной трассировке: PWRU ("paket, where are you?", сетевой трасса ядра), Odigos (распределенная трасса приложений, дополненная информацией от eBPF).
Профайлеры (CPU, user/kernel space вызовы и Network Performance): PyroScope, Parca, Skywalking-rover, Kepler.
Инструменты для отладки: Inspektor-gadget, Kubectl-trace.
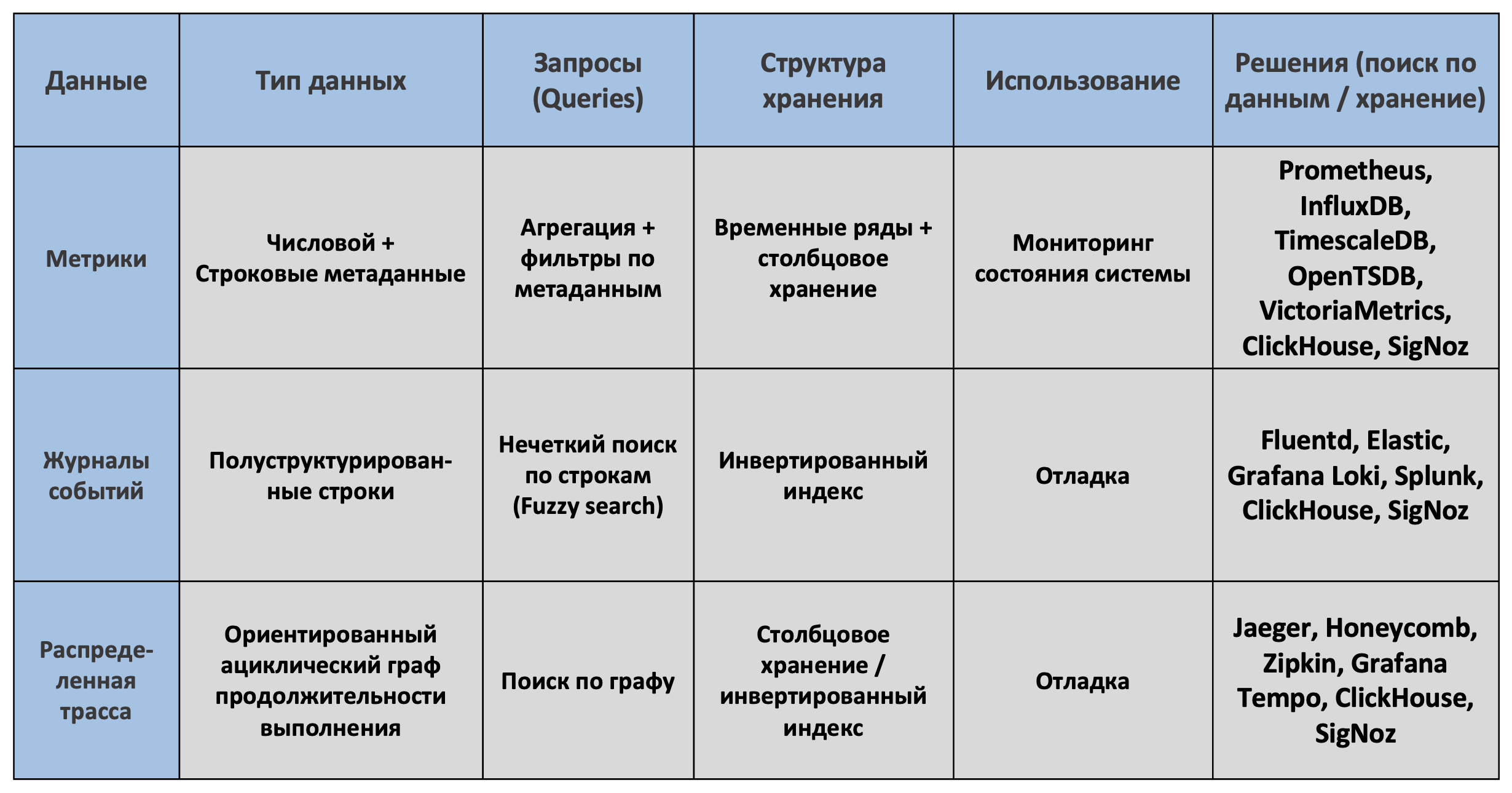
Тип собиаремых данных и потенциальные бэкенды для их последующего хранения и обработки:
Заключение
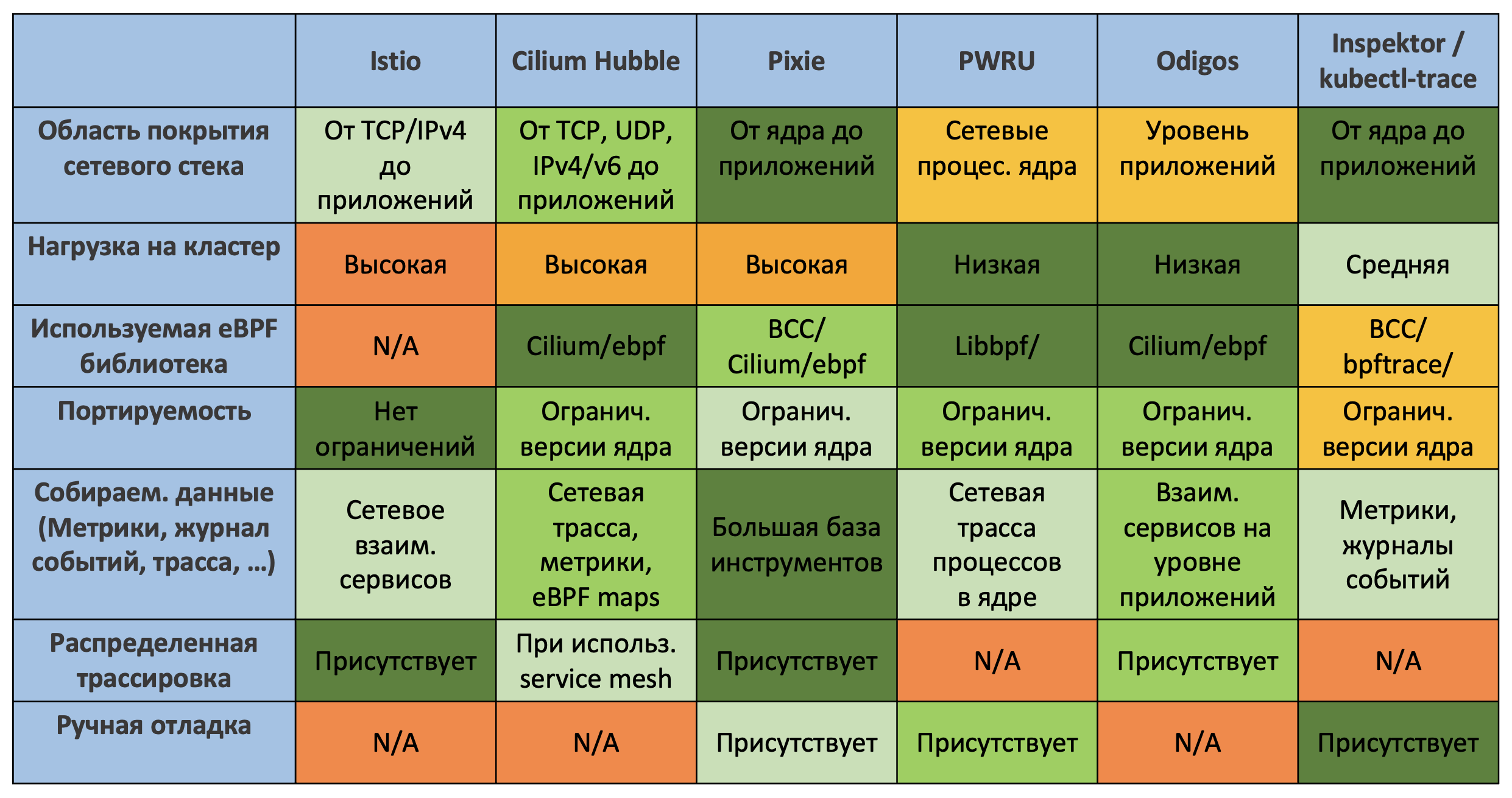
В заключении приведу таблицу сравнения основных инструментов каждого из подходов после их теоретического исследования.
В следующей части статьи уже будет дано развернутое описание того, как разворачивались инструменты (будут и другие инструменты не представленные в таблице ниже), как проводилось тестирование, какие подводные камни встретились и какие результаты были получены (по нагрузке на CPU/RAM k8s кластера и по сетевым метрикам микросервисного приложения RPS/latency).
STAY TUNED!
olku
Таблица поддержки языков устарела. Например, в Яву уже все завезли, см https://opentelemetry.io/docs/instrumentation/java/
Для экспериментов собрал образы тестовых сервисов для четырех техстеков со включенным автоинструментированием. https://gitlab.com/plgrnd/ Через переменные окружения передаются эндпойты коллектора и протокол. Работает как в кубере, так и в докер композ. Не благодарите.
RewRin Автор
Поправка верная, спасибо. Статус для Java логов обновили с "Experimental" на "Stable". Остальные пока без изменений.
Отслеживать обновления по таблице можно здесь: https://opentelemetry.io/docs/instrumentation/