
Один из моих знакомых недавно сходил на собеседование, на котором его попросили спроектировать укорачиватель ссылок. Он растерялся и задачу — как хотел интервьюер — не осилил, а потом нашел в интернете популярное решение и попросил меня прокомментировать. Полная формулировка поставленной проблемы: «Как бы вы разработали службу сокращения URL-адресов, подобную TinyURL?»
К моему сожалению, я — человек любознательный, поэтому я не закрыл окно чата, а пошел почитать, как принято в высшем свете такую задачу нынче решать. То, что я увидел, заставило меня набросать свою собственную архитектурку, потому что даже в страшном сне согласиться с предложенным по ссылке дизайном — не вариант. В тексте ниже я заочно дискутирую с автором решения по ссылке выше.

С чего все началось
Вышеупомянутый пост начинается с мудрого совета
Когда вам зададут этот вопрос на собеседовании, не переходите сразу к техническим деталям.
Это прекрасный совет, я бы даже его обобщил до «Когда вам нужно решить задачу, не переходите сразу к техническим деталям». Время, затраченное на ввод решения с клавиатуры, не должно превышать 10-20% от общего времени, ушедшего на выполнение задачи. Заблаговременное обдумывание окупается лучше, чем последующее устранение неполадок.
Но затем автор бросается в пучину неоправданных предположений, создавая иллюзию любовно построенной башни из слоновой кости.
Давайте предположим, что наш сервис ежемесячно укорачивает 30 миллионов новых URL-адресов.
Нет, пожалуйста, не делайте так. Предполагайте, что сервис может вырасти до миллионов новых сокращений в месяц и убедитесь, что он будет готов к масштабированию. Если вас наняли для обработки существующего трафика в 30 млн/м, поверьте мне, вам будут задавать совсем другие вопросы во время собеседования, например: «какой существующий сервис мы можем купить».
Чтобы преобразовать длинный URL-адрес в уникальный короткий URL-адрес, мы можем использовать некоторые методы хеширования, такие как Base62 или MD5.
Эх. Прежде чем обсуждать, какой метод хеширования использовать, мы должны уточнить наиболее важное требование: можем ли мы генерировать новые короткие URL-адреса для того же самого длинного URL-адреса при последующих запросах, или мы должны возвращать уже сгенерированный. Последний подход намного сложнее реализовать, но обычно можно обойтись без этого. Я сходил на BitLy и убедился, что они этого не делают. Мы тоже не будем.
Возможность не отслеживать обратные ссылки (длинные → короткие) позволяет легко забыть о хешировании вообще и просто использовать случайные последовательности в качестве идентификатора, кстати.
База данных
Стоп, что? Кто сказал, что нам когда-либо вообще понадобится база данных? Что за дурацкое веяние тащить базу всюду, даже туда, где она вообще не нужна, по крайней мере — на этапе прототипирования?
Ну а затем автор сравнивает RDBMS с NoSQL и приходит к неоднозначному выводу «чтобы обрабатывать огромный объем трафика в нашей системе реляционные базы не подходят, а еще RDBMS не особо хорошо масштабируются». Ровно на этом месте я прекратил читать и решил, ладно, напишу, как надо справляться с такой задачей, если здравый смысл пока все еще превалирует над десятком изученных современных технологий.
Как это сделать правильно
Для начала, нужно выбрать чуть менее предвзятый подход и определить, что нам действительно нужно. Требований, оказывается, не так и много.
мы оптимизируем сервис для чтения (пусть даже и в ущерб записи)
мы не выбираем серверную часть для хранения ссылок сразу
мы начнем с подхода, позволяющего обрабатывать некоторый трафик, но не забудем про потенциальную возможность масштабируемости
Вот и все.
Эта задача интересна, например, тем, что нам не нужно хранилище с высокой степенью связности, более того: нам вообще не нужно, чтобы оно было связно. Лучшим подходом для перетасовки запросов между разными «сегментами» (что бы это ни означало в данном контексте) будет hashring, но есть проблема: изменение размера хэширования (масштабируемость!) на лету привело бы к повторному хэшированию, а это не то, что мы можем себе позволить. Короткая ссылка abcdefg всегда должна вести на один и тот же сегмент, несмотря ни на что, а количество сегментов, несомненно, будет увеличиваться.
Пока примерно понятно. Что же дальше?
Говорят, программисты принимают только три вида чисел: 0, 1, ∞. Все должно быть бесконечно расширяемым. Если я смог создать третий сегмент, я должен быть в состоянии создать 1_000_000_003й. Но я не настоящий программист по этому определению, меня вполне устраивает первоначальное масштабирование до 62 сегментов (а когда у нас закончатся сегменты, я, ну, например, продам бизнес или, хоть это и стыдно, переключусь на короткие URL-адреса из 8 символов.) Первая буква в коротком URL-адресе будет указывать на физический сегмент, жестко закодированный. Я начну с единственного экземпляра, обслуживающего первых пользователей, с именем a. Все ссылки в этом сегменте будут начинаться с a. Например, abcdefg или a8GH0ff. Затем, после первого миллиарда или около того пользователей, я выберу b. Это отвратительный, неэлегантный хак, я в курсе. Зато он работает.
С разбиением на, если хотите, шарды — вроде справились. Что же теперь делать со ссылками в одном и том же шарде? О, вот тут как раз во всем блеске можно пользоваться магией Hashring. Создадим N отдельных хранилищ (это могут быть таблицы в БД или даже каталоги на файловой системе), где N приколочено гвоздями. Я слишком ленив, чтобы навести тут какую-нибудь математику, но это число можно было бы получить, разделив весь объем хранилища на приемлемый для хранилища с быстрым доступом размер, который можно достать из бенчмарков. Для продакшена, скорее всего, все-таки потребуется какой-то сравнительный анализ. Но пока давайте просто ткнем пальцем в небо и положим N тоже равным 62, просто потому, что 62, в конце концов, — достаточно большое число.
По запросу на сокращение URL-адреса будем создавать тарабарщину из коротких 6 символов, добавлять a к ней (текущий «префикс», обозначающий фактический физический сегмент/узел) и проверять, не занят ли он уже в хранилище.
Если занят — ну что ж, повторим попытку. Если нет, запускаем (это псевдокод, который очень легко реализовать прямо на коленке) Hashring.who?(six_symbols), добираемся до локального фрагмента и сохраняем там пару ключ-значение. (Памятка на будущее: в какой-то момент шард заполнится настолько, что много раз будет возвращаться уже существующий ключ: это надо отслеживать метриками и перейти на следующий шард задолго до того, как текущий заполнится на все 100%.)
Доступ к длинному URL-адресу теперь практически мгновенный:
abcdefg
^ имя физической ноды (шарда)
^^^^^^ локальный для шарда ключОсталось только выбрать его из хранилища по ключу.
Реализация
Помните, я говорил, что в DB может вообще не быть необходимости? Все, что нам нужно на первых порах, — это интерфейс, выглядящий как пара функций get/1 и put/2 (и, возможно delete/1, но об этом можно будет подумать позже). Наивной, но надежной реализацией этого интерфейса было бы множество каталогов на файловой системе, организованных таким же образом, как дистрибутивы Linux хранят пакеты: для ключа из 7 символов это был бы путь типа, /hashring-id/b/c/d/e/f/g где на пути g находится файл, содержимое которого представляет длинный исходный URL. inode работают медленно, когда в каталоге слишком много файлов / подкаталогов, но здесь у нас есть 62 вершины на каждом уровне, так что все в порядке, и доступ будет мгновенным. Если этого не произойдет, мы перейдем к 62 таблицам в СУБД, или к 62 сегментам в NoSQL, или к чему-то еще.
В принципе, это все. У нас есть чистое масштабируемое решение, не зависящее от внутреннего хранилища.
Дальнейшие улучшения
Мы могли бы легко хранить количество обращений по сокращенной ссылке, а также любые другие прикрепленные данные, ведь конечный файл может быть какого-угодно формата (в том числе, он сам может быть директорией). Более того, можно модернизировать этот подход для повторного использования коротких ссылок, что увеличило бы время записи, но сохранило бы время доступа прежним (устранение коллизий было бы самой интересной частью этого решения, и я, пожалуй, оставлю его дизайн дотошному читателю).
Комментарии (86)

Oceanshiver
07.07.2023 11:49+15Зачем делать так сложно, если можно взять БД (sql/nosql) и сделать просто?

vvzvlad
07.07.2023 11:49+6Так автор сторонник подхода "если это можно сделать на логике, не надо брать микроконтроллер". П-преждевременная оптимизация.

Tasta_Blud
07.07.2023 11:49+4сделать просто можно и нужно, если хочется сделать пет-проект.
если нужен коммерческий сервис, то необходимо сначала продумать/спросить различные юзкейсы и прочие требования, включая бюджет, сроки и юридические моменты.
если это задачка на собеседование, то вообще очень важно сначала уточнить все требования. потому что такие абстрактные формулировки (сделайте нам сокращалку урлов) почти всегда являются минным полем, (если не задавать кучу уточняющих вопросов), на котором растёт чсв интервьюера, от "у нас миллион запросов в секунду, поэтому ваше решение не годится,
вы самое слабое звенопрощайте" вплоть до "выглядит некрасиво, этим пользоваться нельзя!". и если не спрашивать требования очень подробно, то можно и не угадать, что же от вас как от кандидата ожидалось.не так давно на хабре была статья, как в качестве тестового задания дали сделать сложное production ready приложение, и кинули потом с претензиями "нету анимаций, надписи не выровняны с точностью до пикселя"

Didimus
07.07.2023 11:49Есть куча людей, которых бесят уточняющие вопросы. Вы слишком много спрашиваете!

segment
07.07.2023 11:49+15Не то, чтобы это моя область, но почему бы просто не взять тот же postgres и реализовать простой вариант в лоб? В чем подводные камни?

Skykharkov
07.07.2023 11:49Любой микрохост с доменным именем и всего-то функциями
- получить полную ссылку
- преобразовать ее в короткую со своим доменным именем, типа https://myhost.com/cFdsfrf
- по приходу такой ссылки на myhost.com редиректить юзера на "нормальный" хост
Господи, да там даже база то толком и не нужна. В текстовый файл писать можно...
MajorMotokoKusanagi
07.07.2023 11:49+1Немного фантазии.
В несколько текстовых файлов, если записей от десятков тысяч, имена файлов по первым N символам идентификатора ссылки. Причём массивы идентификаторов сгенерированы и отсортированы заранее, вставка (добавление ссылки к идентификатору) и чтение — через двоичный поиск. Или же по некому алгоритму сразу рассчитать номер строки.Skykharkov
07.07.2023 11:49-1И вот мы уже подбираемся к базам данных. :)
Тогда уж, sqlite взять да и не париться вообще, блокировками чтения записи и так далее. Все, конечно-же от задачи зависит. Если там триллионы записей, то текстовый файл конечно того... Да и sqlite тоже. Но мы сейчас тут до кластеров договоримся. Я себе еще и "кастомный код" делал. Ну типа чтобы что-то свое можно было в ссылке указывать. Но это уже "рюшечки".

isden
07.07.2023 11:49Я пошел чуть дальше, и начал прикручивать редис для горячего кэша :)
Потом вовремя одумался и забросил этот проект.
Кмк, почти все пробовали писать что-то подобное :)

randomsimplenumber
07.07.2023 11:49sqlite взять да и не париться вообще, блокировками чтения записи
sqlite взять - с блокировками париться. sik.




onyxmaster
07.07.2023 11:49+8Зачем-то упёрлись в производительность, хотя часто для публичного сервиса как минимум настолько же важна отказоустойчивость. Сразу использовать БД, желательно с автоматической репликацией становится более интересно, чем пытаться реализовать "на коленке" отказоустойчивую ФС или бороться с любым из обманчиво простых в настройке "готовых распределённых ФС".

izloy1
07.07.2023 11:49+6хорошая задачка, чтобы изучить новый язык например. сам лет 8 назад так Golang изучал. Помимо алгоритмистики, ещё и бд/логи/файлы, обращение к сервисам для проверки урла на фишинг/опасность и т.д. Вышло легко и быстро, особенно было допиливать сервис, глядя на попытки кулхацкеров взломать go методами для PHP. до сих пор сайтик живет в домене .uy :)

DreamingKitten
07.07.2023 11:49+32до сих пор сайтик живет в домене .uy :)
почему-то я даже не сомневался



MikhailZakharov
07.07.2023 11:49+8Статья начиналась с хорошего посыла "не приступать к реализации без деталей", который был проигнорирован.
Вопрос "как будут использоваться укороченные ссылки?" может дать ответ "хотим на плакате печатать". Получится что от решения "mytinyurl.con/abh8iqbhj" толку меньше чем от "a.con/mydog". Второй вариант запоминается, но требует и базы и всего остального.

Leetc0deMonkey
07.07.2023 11:49-7Статья начиналась с хорошего посыла "не приступать к реализации без деталей", который был проигнорирован.
Хитрая уловка менеджеров, продуктоунеров и прочих аналитиков и постановщиков, чтобы не делать свою работу и переложить её и ответственность на исполнителей.
Вопрос "как будут использоваться укороченные ссылки?" может дать ответ "хотим на плакате печатать".
А почему это должно исполнителя колыхать? Почему он должен чесаться, задавать вопросы и чего-то предугадывать? ОК, за дополнительный прайс я возьму на себя обязанности постановщика и аналитика.
MikhailZakharov
07.07.2023 11:49+9Обычно, если речь идёт о найме опытного разработчика, то способность анализировать и предлагать идеи - это важный навык. Не всегда способ реализации очевиден самому аналитику. Например, разработчик решает выбрать компонент под лицензией gpl, но этого нельзя сделать, поскольку продукт не будет открытым. Если молча реализовывать, проблемы появятся, когда их сложно будет исправить.
Есть ещё один аргумент - ближайшего будущего. Чем более чёткие инструкции (или чёткие процессы), тем быстрее эта работа будет заменена искусственным интеллектом. Получается, что навык анализа нужен будет, чтобы победить машину за рабочее место.
Leetc0deMonkey
07.07.2023 11:49+1Например, разработчик решает выбрать компонент под лицензией gpl, но этого нельзя сделать, поскольку продукт не будет открытым.
То есть разработчик должен взять на себя ещё и функции юриста? Нет, я не против даже, но это будет стоить совсем других денег. А пока всё выглядит как на лоховатых "разработчиков" все кому не лень спихивают свои обязанности. А те на серьёзных щщах чувствуют себя виноватыми что не уточнили что "заказчик будет печатать на плакате". Ребят, тут к психологу надо. Свои интересы надо уметь отстаивать (или требовать компенсации), а не быть покорным "ответственным за всё", и всех остальных к этому призывать. В других специальностях, те же юристы, пальцем лишний раз не пошевелят без доплаты.

cupraer Автор
07.07.2023 11:49Судя по тому, что у вас все проблемы и требования сводятся к дополнительной оплате, вы, наверное, очень нищенствуете, да?
Среди разработчиков есть и такие, которым платят более-менее достаточно, чтобы в свободное время поупражняться в решении забавных задачек бесплатно.
Leetc0deMonkey
07.07.2023 11:49+2Нет, я просто уважаю себя. Я лучше эти деньги отдам на благотворительность, чем позволю небедным продуктоунерам, аналитикам или юристам лошить себя.

igorzakhar
07.07.2023 11:49+7Эх. Прежде чем обсуждать, какой метод хеширования использовать, мы должны уточнить наиболее важное требование: можем ли мы генерировать новые короткие URL-адреса для того же самого длинного URL-адреса при последующих запросах, или мы должны возвращать уже сгенерированный. Последний подход намного сложнее реализовать, но обычно можно обойтись без этого. Я сходил на BitLy и убедился, что они этого не делают. Мы тоже не будем.
Для того же самого URL-адреса сервис Bitly возвращает ту же короткую ссылку, которая была сгенерированна ранее, проверил как через web интерфейс, так и черз запрос к API используя токен.
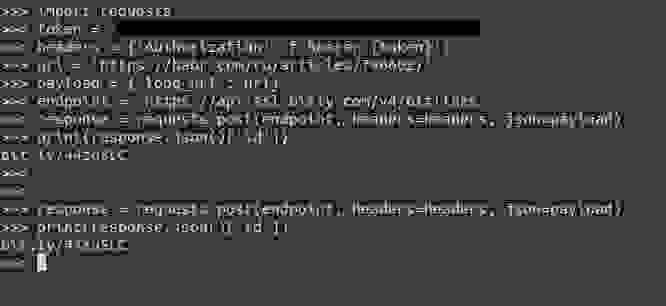

cupraer Автор
07.07.2023 11:49+1Наверное, недавно прикрутили. Тексту больше двух лет, тогда не было.



shai_hulud
07.07.2023 11:49+1130.000.000 url / month = 52 bytes/url + 8 bytes/short-url = 1,716 MiB / month
Выделенного сервера за 50$/m с 64г памяти хватит на 37 месяцев, так что можно хранить в памяти и дампить это барахло на диск. После 24 месяцев 2 раунда инвестиций должны быть уже съедены и можно продавать свою долю и начинать делать следующий стартап.

aborouhin
07.07.2023 11:49+3Про логи кликов по URLам, без которых такой сервис мало кому нужен, мы конечно же забываем :) В которых, чтобы юзер мог получить полезную себе аналитику, нам хранить бы как минимум время, IP (и полученную по нему геолокацию) и user agent (который тоже лучше сразу парсить и классифицировать). В зависимости от позиционирования сервиса и типовых сценариев его использования, кликов может быть в тысячи раз больше, чем самих URLов.
Ну а то, что запись про каждый URL - это не только полная и короткая версия, но ещё и как минимум id юзера, время создания, срок действия, - на этом фоне уже несущественно...shai_hulud
07.07.2023 11:49пфф, смотрим nginx логи на предмет обращения.
aborouhin
07.07.2023 11:49+2А nginx логи у нас места на диске не требуют? И мы их сумеем, не перекладывая в базу с индексированием, достаточно быстро парсить?
Допустим, у нас по каждой ссылке перешли в среднем всего 1 раз (ниже в комменте написал, что в зав-ти от того, что за сервис, может быть гораздо больше). За Ваши 2 года мы получили 720 миллионов переходов. И теперь пользователь хочет посмотреть, из каких стран по его ссылкам переходили чаще всего. Мы будем для этого парсить 720 миллионов текстовых строк, выбирать из них те ссылки, которые созданы этим пользователем, и потом ещё каждый IP клиента сверять с базой GeoIP (лучше бы, причём, с версией на момент обращения, а то вдруг IP с тех пор переехал)? Вряд ли же.
shai_hulud
07.07.2023 11:49+5Бич хостинг с SSD за те же 50$ дает скорость чтения в районе 500 MiB/s, если gzipать логи, то за счёт стриминга архивированных данных можно получить множители до 10х т.е. в районе 5 GiB/s, избирательно парсить на такой "скорости" не рокет саинс.
Я уж не говорю что архивные логи можно предварительно "переварить" и разложить по префиксам. А результат класть в вытесняющий кеш в памяти.
---------------------
Но опять же, в описании задачи ничего нет про гео-привязку и просмотр логов. Так можно "придумывать" новые фичи вечно, в конце будет только одно решение Spring, Oracle и штат в 5000 человек.
Для для просто сокращалки БД не нужна. Программисты которые сразу думают какую БД выбрать еще не познали дзен.
aborouhin
07.07.2023 11:49+2Я там ниже написал, что непонятно, на какую вообще позицию с такими вопросами собеседуют. Вряд ли программиста - для него слишком абстрактно. А архитектору уже не грех подумать про то, зачем система вообще существует, какие требования к ней могут быть, как она будет монетизироваться и стóит ли тупо отбрасывать имеющие ценность данные, даже если мы их в текущем моменте пока не используем (не клиентам покажем, так сами монетизируем).
(кстати, глянул набор фич и тарифные планы bit.ly и понял, что у меня ещё очень бедная фантазия...)Если бы я был интервьюером - меня бы гораздо больше интересовали уточняющие вопросы, которые задаст кандидат, чем какие-то конкретные решения, которые он предложит.
А до выбора конкретной БД или не БД, соглашусь, тут и правда бесконечно далеко. Но проектировать так, чтобы не приколачивать ничего гвоздями к конкретной технологии хранения данных, надо с самого начала.

dsh2dsh
07.07.2023 11:49+8Насколько я вижу, много разработчиков болеют преждевременной оптимизацией. Это может быть нормальным для хобби, но совершенно не годится для коммерческого проекта. Если в задаче не описаны конкретные требования - не пытайтесь угадать будущее, всё равно не угадаете . Делайте максимально простым способом. Вот когда будет известно конкретно бутылочное горлышко, вот тогда и придёт время оптимизации. Естественно, всё это нужно делать с умом, даже максимально простым способом.
К сожалению, в случае тестовых задач, может оказаться, что нанимающий просто не поймёт этих элементарных истин, в силу своей неопытности.
aborouhin
07.07.2023 11:49+2Если в задаче не описаны конкретные требования - её рано выполнять :)
Как минимум, в этой задаче, IMHO, самая критичная часть - сколько кликов будет в среднем на каждый URL. И тут зависит от позиционирования сервиса. Если это сокращалка для ссылок в транзакционных СМС/уведомлениях (какие-нибудь ссылки на статус заказа в магазине и пр) - соотношение будет близко к 1:1, они по природе своей одноразовые. Если для того, чтобы в приватном порядке делиться ссылками, - больше, но не сильно (но тут будет актуален доп. функционал - ограничение времени действия, макс. числа кликов и т.п.) Встроенная сокращалка для какой-то соцсети - ещё больше (будут как никому вообще не интересные ссылки, так и те, по которым в первый час после публикации будут сотни тысяч переходов). Инструмент для аналитики охвата аудитории ссылками, размещёнными в соцсети / рассылке? Тут может получиться и 1000:1, поскольку такими вопросами заморачиваются только те, кто ожидает достаточно широкого распространения своих ссылок.
В итоге наши "30 миллионов новых ссылок в месяц" могут оказаться как крайне лёгкой, так и очень серьёзной нагрузкой.dsh2dsh
07.07.2023 11:49+1Если в задаче не описаны конкретные требования - её рано выполнять :)
Ох, вашими бы устами... Постоянно менеджеры открывают задачи в таком вот стиле. И опыт показывает, что задавать уточняющие вопросы - бесполезно, он будет бекать и мекать, но ничего конкретного не скажет. Опыт подсказывает, что единственный вариант - это сделать как нибудь и что нибудь. После этого можно спросить - это то? И вот тогда уже пойдёт конструктив.
aborouhin
07.07.2023 11:49Дайте мне, как менеджеру, такого исполнителя, которому можно поставить задачу уровня "спроектировать сервис" (!), при этом не дать никаких уточнений, и он не пошлёт меня нафиг и не саботирует, а сделает хоть что-то :)
Тут, в общем-то, обсуждается не точечная задача не для исполнителя, а целый проект для того самого менеджера. И очевидно, что в формате собеседования невозможно найти никаких конкретных решений, - но вполне можно понять, достаточно ли широкий и всесторонний взгляд у человека на проблему, задаст ли он правильные вопросы, увидит ли подводные камни, направления развития и т.п. Или, как автор статьи, с порога бросится изобретать конкретные технические решения, которые, с высокой вероятностью, после уточнения ТЗ окажутся неподходящими.

l0ser140
07.07.2023 11:49+2Это же стандартный вопрос с system design секции.
В секции нет правильных и неправильных решений, и непонятно что делал его знакомый "решив не так, как хотел интервьювер".
В секции оценивается как раз то, как кандидат уточняет функциональные и нефункциональные требования, как размышляет, какие предполагает сценарии нагрузки, какие паттерны проектирования знает и использует, знает ли узкие места предложенного решения и предлагает ли какие-то варианты их устранения, софт скиллы.
Именно поэтому на старте даются хоть как-то существенные значения по нагрузке/обёму данных, чтобы было о чем поговорить.А сама архитектура системы достаточно вторична, если примерно удовлетворяет требованиям.
aborouhin
07.07.2023 11:49+1Вообще, только заметил, что в посте не указано, на какую, собственно, должность собеседовался знакомый с такой задачей? Программиста? Архитектора? Аналитика? Product owner'а? CTO?
В каждом случае, по идее, должны быть свои ожидания от ответа (и, что едва ли не важнее - от уточняющих вопросов кандидата). Скажем, если программисту допустимо забыть про существование какого-нибудь списка экстремистских материалов (предположим, мы в России сервис делаем), на URLы из которого, во избежание юридических рисков, короткие ссылки не надо позволять делать, - то для аналитика или product owner'а это недопустимый прокол.

GoodGod
07.07.2023 11:49+1Немного грубовато (наверное по-этому вы ловите минусы), но отличный свежий взгляд на решение проблемы.
cupraer Автор
07.07.2023 11:49-11Спасибо.
Минусы я ловлю потому, что вокруг полнó теоретиков, которые не умеют читать, но бесценное единственно верное мнение имеют. Это называется хабр, ничего нового.

nin-jin
07.07.2023 11:49+21Вам сначала не понятно чем не угодило хеширование (ууу, какая сложная штука). Про банальный счётчик вы даже не заикнулись (слишком просто видимо). А потом придумали ходить на каждый запрос по 7 каталогам (ведь банальный btree - это похоже слишком быстро). И совсем не рассказали как собираетесь это всё инкрементально реплицировать (или серьёзные дяди таким не заморачиваются?). Просрали до половины коротких идентификаторов (благодаря недозаполненным сегментам). А все проблемы с закончившимися сегментами любезно свалили на тех, кто придёт после вас (а до тех пор вы будете вручную выуживать по мониторингам оптимальный момент смены сегмента). Это называется хабр, ничего нового.
cupraer Автор
07.07.2023 11:49-12А я-то наивно полагал, что тупее вчерашних предъяву уже и не придумать. Как же я ошибался.

MiraclePtr
07.07.2023 11:49+5Да в общем-то нет. Из комментариев видно, что люди внимательно читают и хорошо понимают вашу статью, вполне вежливо высказывают очень даже обоснованную критику к вашим решениям, а вы в ответ хамите и огрызаетесь как обиженный школьник.

czz
07.07.2023 11:49-1Да можно просто взять AWS DynamoDB, и все вопросы с шардированием, масштабированием и отказоустойчивостью БД решатся сами собой :)
onyxmaster
07.07.2023 11:49+4Главное решить вопрос с тем, кто будет оплачивать ежемесячный счёт :)
czz
07.07.2023 11:49Перевести разработчика на полставки :)

funca
07.07.2023 11:49"Серьезная фирма возьмёт в аренду дырокол". Девопс, который будет заниматься разработкой и поддержкой on-prem решения с аналогичными характеристиками по безопасности и отказоустойчивости обойдётся как контракт на ближайшие 100 лет.

mvv-rus
07.07.2023 11:49+8Странное решение: использовать файловую систему как импровизированную иерархическую базу данных. Особенно — произвольную файловую систему, которая не дает нескоторых полезных гарантий. Например — гарантию хранения коротких кусков данных вместе с метаданными файла: такое есть в NTFS, но здесь ее использовать, наверное не получится, есть ли такое в FS для Linux — не в курсе. В результате поимеем а) лишнюю операцию чтения (а она даже на NVMe не бесплатна), б) кучу мелких файлов, на которые отведено крайне много неиспользуемого пространства (размер блока, сразу отводимого под файл, почти наверняка сильно больше длины типичного URL).
И тут мне почему-то на ум сразу приходит заковыристое прилагательное "дендрофекальный".
Куда лучше, наверное, взять в качестве хранилища СУБД: она специально под это заточена.
Вообще-то для решения ровно такой задачи есть специальный тип NoSQL БД — key-value. При желании можно один-в-один вместо FS использовать NoSQL БД, реализующую иерархическую БД (точнее, сетевую: иерархическая — это ее подвид). Но лучше IMHO взять обычную реляционную БД, поддерживающую кластерный индекс (MS SQL, PostgreSQL не слишком древний — короче, таких много) сделать таблицу с кластерным индексом по короткой ссылке (в поле ключа), исходным URL и прочими полезными данными в в остатке записи. Или — несколько сходных таблиц: по одной на раздел.
Что в таком решении не подходит автору — ума не приложу. Разве что, он не любит реляционные БД, потому что просто не умеет их готовить?cupraer Автор
07.07.2023 11:49-14Что в таком решении не подходит автору — ума не приложу.
Ничего удивительного. Вы же даже читать не умеете, судя по выводу «не подходит».
mvv-rus
07.07.2023 11:49+6Нет, я просто такой человек, читаю ровно то, что написано в тексте. Например:
Стоп, что? Кто сказал, что нам когда-либо вообще понадобится база данных? Что за дурацкое веяние тащить базу всюду
А вот мысли написавшего я действительно читать не умею.
PS Как я смотрю по вашему стилю общения (не только со мной — со всеми), вам нравится грубить людям. Зачем вы это делаете?cupraer Автор
07.07.2023 11:49-1Эээ, нет, господин студент, этот ad hominem мимо. Я никогда не грублю людям, которые не грубят мне (и умным в принципе — тоже никогда не грублю).
1 комментарий тому назад вы совершенно облыжно усомнились в моей способности работать с базами, тут же я на основе фактического материала усомнился в вашей способности читать. Ситуация совершенно зеркальная, но вы тут же обратили на это внимание.
И, наконец, по существу. Из (не для любого решения может быть нужна база) никак не следует (база не нужна никогда). Более того, в конце я русским по белому написал, что вот, если надо, с такой архитектурой база втыкается за 10 минут.
mvv-rus
07.07.2023 11:49+5Эээ, нет, господин студент, этот ad hominem мимо.
Я не понял, к кому вы тут обращаетесь, ну да ладно. А аргумент был по сути: странно не использовать БД в задаче, в которой ее использование напрашивается, а вместо этого заменять БД суррогатом.
Я никогда не грублю людям, которые не грубят мне (и умным в принципе — тоже никогда не грублю).
Судя по количеству людей, которым вы тут нагрубили, вы тут нас всех дураками считаете, правильно?
1 комментарий тому назад вы совершенно облыжно усомнились в моей способности работать с базами
Ну почему же — облыжно? Неправильное использование реляционной БД вами мы тут уже наблюдали: вы записали в ее таблицу объекты JSON целиком — в одно поле каждой записи БД — и потом пытались аггрегировать/фильтровать записи по паре полей из объекта, вместо того, чтобы разобрать JSON, выделить из него эти самые поля, по котроым требуется обработка, и записать их отдельно в каждую запись БД. А сейчас мы видим, что вы вместо БД используете суррогат ее на базе файловой системы. Вот и возникает такое предположение — о вашей программной несовместимости с концепцией БД, логично да? Ничего страшного в этой несовместимости нет — например, работать на фронте она вряд ли помешает. И вообще, достаточно знать границы своей компетентности (а они есть у всех, ибо "нельзя объять необъятное" ((с)Козьма Прутков)) и воздержаться от раздачи советов в тех областях, в которых не разбираешься — и все будет хорошо. Но вы, вот почему-то не следуете этой, очевидной, стратегии. Да ещё и грубите при этом. Зачем?
Более того, в конце я русским по белому написал, что вот, если надо, с такой архитектурой база втыкается за 10 минут
Мне странно, что вы не потратили эти 10 минут сразу. Лучше такие решения не откладывать, потому что неизбежно вырастающие в процессе дальнейшей работы над кодом костыли приведут потом к тому, что для втыкания потребуется далеко не 10 минут: ну, природа у костылей такая, чисто конкретная, вся эта продуманная (или не очень) архитектура с ее абстракциями в костылях обычно игнорируется.

nronnie
07.07.2023 11:49Так-то нормальный чел уровня хотя бы мидла начнет с того, что создаст какую-нибудь абстракцию для хранилища. После этого прикрутить любое выбранное или сменить одно на другое будет уже на порядок проще.

SuperCat911
07.07.2023 11:49+2Решение на файлах - такое себе. Данные можно хранить хоть в json, но масштабируемости не будет. Наверняка потом надо будет учитывать время устаревания ссылки или аналитику провести.
Ну и кстати на ру-хостингах на некоторых тарифах еще любят ограничение делать в 10000 файлов на VPS.
Поэтому я за решение с использованием БД. Адрес короткого урла тоже довольно просто можно сгенерить, например: base62(index) . base62(md5(url)).

Suor
07.07.2023 11:49+9Автор предлагает не делать предположений и критикует за абстрактные решения и потом сам делает кучу и тех, и других))
cupraer Автор
07.07.2023 11:49-10Даже жалко, что ни единого примера, подтверждающего этот тезис, привести не удастся. Зато уродские скобочки, однозначно классифицирующие комментатора, на месте. Интересно, почему компетентные люди никогда не завершают комментарии скобочками, не знаете?

Politura
07.07.2023 11:49Это систем-дизайн этап интервью, пошло со всяких фаангов, там даже если изначально будут даны какие-то смешные цифры, обязательно скажут что-нибудь типа того, что "сервис вырос и теперь у нас 1 млн. запросов в секунду" и спросят как вы будете масштабировать. И если масштабировать не получится, а только заново переделать, то будет уже минусом.
cupraer Автор
07.07.2023 11:49Пошло́ оно не с фаангов, наоборот, из стартапов, где все эти навыки востребованы, даже когда простого разработчика нанимают. Фаанги потом уже переняли.
И да, все правильно, основные цели — масштабирование и возможность замены фактически любого компонента на лету, что я как раз и продемонстрировал: тут нет ни единого прибитого гвоздями решения (кроме шардинга, но он в любом случае неизбежен).

mtivkov
07.07.2023 11:49+2Если короткие ссылки выдавать последовательно, а не случайно, тогда будем сразу получать упорядоченное множество, в котором не надо искать элемент - мы будем сразу знать номер элемента.

fo_otman
07.07.2023 11:49Простите за тупой вопрос, но нельзя ли придумать алгоритм шифрования/дешифрования, чтобы вообще ничего не хранить в базе?

YMA
07.07.2023 11:49Одному хешу соответствует бесконечное множество возможных URL (почти бесконечное, учитывая ограничение на длину).
Поэтому без базы, где будет храниться соответствие короткий-длинный - никак не выйдет.

raspberry-porridge
07.07.2023 11:49Но ведь алгоритм хэширования считается хорошим, если вероятность коллизии хэшей околонулевая.
l0ser140
07.07.2023 11:49Пока мы отображаем большее множество URL адресов на меньшее множество хешей, коллизии будут у любого алгоритма хеширования.
Иначе сервис перестаёт быть сокращателем ссылок.

SergeiMinaev
07.07.2023 11:49Чтобы по короткому URL можно было восстановить исходный? Тогда это будет архивация, можно WinRAR прикрутить :)


BlinOFF
07.07.2023 11:49На ютубе есть интервью по системному дизайну,как раз на эту тему https://youtu.be/PZoueQ9kjCU

baguwka
07.07.2023 11:49+1Если честно - слишком сильно сочит ЧСВ. Если по теме - то при постановки такой задачи на этапе тестового задания лично меня обычно просили сделать аналог tinyurl, а это значит:
- реализовать счётчик посещений
- возможность указать alias ссылки
- получить список всех созданных мной ссылок.
Мне видится немного сложным это все сделать на уровне ФС, в то время как это все элементарно делается на любой БД.cupraer Автор
07.07.2023 11:49-10Я прямо в тексте написал, как это все (и еще вагон дополнительных требований) элементарно реализовывается на ФС.
Вам всегда, когда вы чего-то не понимаете, видится ЧСВ?

melazyk
07.07.2023 11:49+2/hashring-id/b/c/d/e/f/g inode работают медленно
1) Это не правда, медленно работает readdir, потому что для доступа к каждому файлу в большом каталоге недо будет целиком читать содержимое директории ( при чем на многих фс вообще нет никаких inode, а проблема останется )
2) ели говорить про фс, где эти самые inode существуют ( ext* ) то создавать большую глубину каталогов для хешей - тоже роде антипатерн, как и делать большие директории, т. к. Создавая /1/2/3.txt - это 3 inode ( при условии что файл занимает одну ), а /1/2/3/4/5/6.txt - 6 inode. Поэтому создавая по 1 файлу в конечной директории - это будет трата inode а скорости это не добавит. ( Обычно не делают больше 2-3 вложений )

Akina
07.07.2023 11:498-символьный формат при использовании латинских букв и цифр даёт 2,8кккк вариантов. Если поток ссылок на сокращение будет, например, 100 ссылок в секунду, этого количества хватит на почти 9 веков.
Если принять решение использовать-таки SQL, то получится таблица с 64-битным (беззнаковый длинный целый) первичным ключом (32-битный коротковат будет), который для получения ссылки тупо преобразуется в 36-ричное число, и текстовым полем сокращаемого адреса. Если же хочется избежать последовательных ссылок - можно генерить случайное целое в посчитанном диапазоне. На 1% вероятность того, что сгенерированное случайное уже использовалось, которая накопится через 9 лет, можно наплевать. Ну то есть если вдруг коллизия - просто выполнить повторную генерацию.
Для быстрого получения полного адреса по ссылке ничего дополнительного не требуется. Для быстрой проверки на то, что адрес уже имеет укороченную версию, и возврат этого укороченного адреса, требуется индекс по строке адреса.
Как по мне, так вся разработка упрётся в правильное предсказание потребных аппаратных ресурсов для хранения описанного массива данных. Хотя, по моим прикидкам, речь пойдёт об объёме порядка всего лишь 10 Tб в год.

kolya7k
07.07.2023 11:49+1Вообще еще надо учитывать время жизни ссылки (30 дней обычно) и были ли клики на неё (обычно ссылку удаляют если 30 дней не было по ней ни одного клика).
Итоговый хэш должен быть максимально коротким и непредсказуемым, чтобы нельзя было вставить что-то свое и получить какую-то ссылку, а нужно было еще перебором найти работающий хэш. Тогда можно сделать блокировку по количеству запросов с одного IP.
То есть предсказуемости в виде первая буква - номер шарда не должно быть. В идеале 5 символов чистого рандома, что дает нам примерно 1 миллиард вариантов. 5 можно заменить на 4 или даже 3 при маленькой начальной нагрузке.
5 символов теоретически хватит для нагрузки 10 миллионов ссылок в месяц.
4 символа можно использовать при нагрузке в 150 тысяч ссылок в месяц.
3 символа при нагрузке 2 тысячи
Значения выбраны с учетом 1% заполняемости, чтобы было не подобрать.
% заполняемости задаем константой, нагрузку считаем обычным счетчиком в памяти, количество отдаваемых букв вычисляем автоматически.
Проверку ссылки на наличие в «базе» делаем с помощью фильтра Блума, без обращения к базе.
funca
07.07.2023 11:49+1Если это статья про system design, то и подход к решению должен быть системным, нет? В статье, с которой вы дискутируете, системность выражена заголовками, прямо отвечающими на вопрос - на какие аспекты, существенно влияющие на архитектуру системы, нужно обратить внимание. Ваш вариант больше фокусируется на отдельных моментах реализации и это скорее уровень инженера, нежели архитектора.
Один из принципиальных моментов, отмеченным в оригинале, была доступность - ведь если вся эта конструкция внезапно падает, то разом миллионы ссылок становятся недоступными. Даже если взять 99.99 (чуть меньше часа в год ваш сервис может не отвечать), то вы ни при каких условиях не сможете обеспечить такие требования одной машинкой, и даже несколькими в одном датацентре. Соответственно распределенность нужно закладывать изначально, и именно с ней будет связано в решении все самое интересное.

eee
07.07.2023 11:49Пишем в базу с инкрементальным идентификатором, генерируем короткую ссылку через биективную функцию, на вход подаём идентификатор.
KivApple
30 миллионов запросов в месяц это 11 запросов в секунду. А с этим точно не справится классический постгрес с одной таблицей с 2-3 колонками и бекэнд на чём-угодно от PHP до Джавы?
vagon333
Не уверен, что нужна реляционная база.
Key-value с уникальным индексом по ключу должно быть достаточно.
У вас-же задача - получить длинное на основании ключа (короткой версии url), с минимальными затратами ресурсов и максимальной скоростью.
mst_72
Слегка накину ;)
Предположим, у нас уже есть решение на AWS, которое использует Aurora DB (Postgresql). И мы решили добавить сокращение ссылок.
Будем добавлять Key-Value или обойдёмся реляционкой?
programmerjava
Сначала хранилище, которое есть.
Если взлетит и не будет хватать - мигрировать на key-value не составит труда :)
vagon333
Вопрос не в том, что у вас есть, а какая минимально-достаточная архитектура нужна для решения задачи.
В этом Subj. Верно?
lyric
Зависит от геораспределенности пользователей. Если они сосредоточены в одном регионе - может падать до низких значений ночью и расти до неприличных значений в часы пик (тоже зависит от целевой аудитории - или в рабочее время, или вечером). А в среднем за сутки - да, 11 в секунду.
aborouhin
Там речь была не про 30 миллионов запросов в месяц, а про 30 миллионов новых адресов в месяц. А к каждому адресу, если он использован, скажем, в соцсети популярного блогера, может быть миллионы обращений в день. При этом означенный блогер наверняка захочет анализировать статистику кликов по своим ссылкам, в разрезе времени, локации пользователей и т.д. и т.п. И все эти радующие блогерскую душу дашборды по миллиардам записей в логах должны строиться быстро...
rusik2293
Нет) В час пик будет совсем другое
Maur
Запросы не будут распределены равномерно (день/ночь, праздники, время года), будут считаться нормальными пики для распределения, это где-то 14.6-26.58 запросов в секунду.