
Привет! Меня зовут Руслан Федоров, я продуктовый дизайнер в Тинькофф. Хочу поделиться кейсом, как мы поменяли шрифт у нескольких символов и тем самым ускорили регистрацию бизнеса наших клиентов. Погнали!
Контекст
Каждый день тысячи клиентов по всей России регистрируют бизнес через Тинькофф. Представим, что вы один из них и хотите открыть ИП. Для этого нужно подписать электронной подписью документы в нашем приложении. Чтобы выпустить подпись, нужно встретиться с представителем банка. На встрече вы показываете уникальный для вашего устройства код из 10 буквоцифр в приложении, а представитель переписывает его в заявление.


После этого представитель сканирует заявление в специальном приложении и отправляет оператору, чтобы он ввел код в систему. Если код такой же, как у вас в телефоне, система выпускает подпись. Если нет — выдает ошибку, и нужно попробовать еще раз.
Проблема
У представителей разный почерк. Чей-то легче разобрать, чей-то сложнее. Поэтому операторы не всегда могут разобрать код в заявлении, и система его не принимает.
43% от всех заявлений в январе не прошли проверку с первого раза. А 8% не прошли и со второго
Операторы не понимают, какие же символы они неправильно ввели, и перебирают варианты. А в это время вы сидите в машине с представителем и ждете, пока оператор закончит проверку. В худшем случае у него не получится подобрать код, и вам придется встретиться с представителем еще раз и проделать все заново.
Решение: прописи для взрослых
Начали думать, как убрать фактор индивидуальности почерка представителей. И поняли, что такую проблему уже решила почта. Нужно написать индекс на конверте так, чтобы любой сотрудник почты смог понять его.
Решение состоит из двух частей: пунктирная сетка и образец написания цифр на ней.

Сетка с конверта нам не подошла, так как у нас не только цифры, но и некоторые буквы латиницы. Остановились на квадратной сетке 2x4.

Так как такое отображение символов нестандартное, мне нужно было с нуля объяснить разработчикам, как верстать эту прелесть. Спецификация, которая получилась:
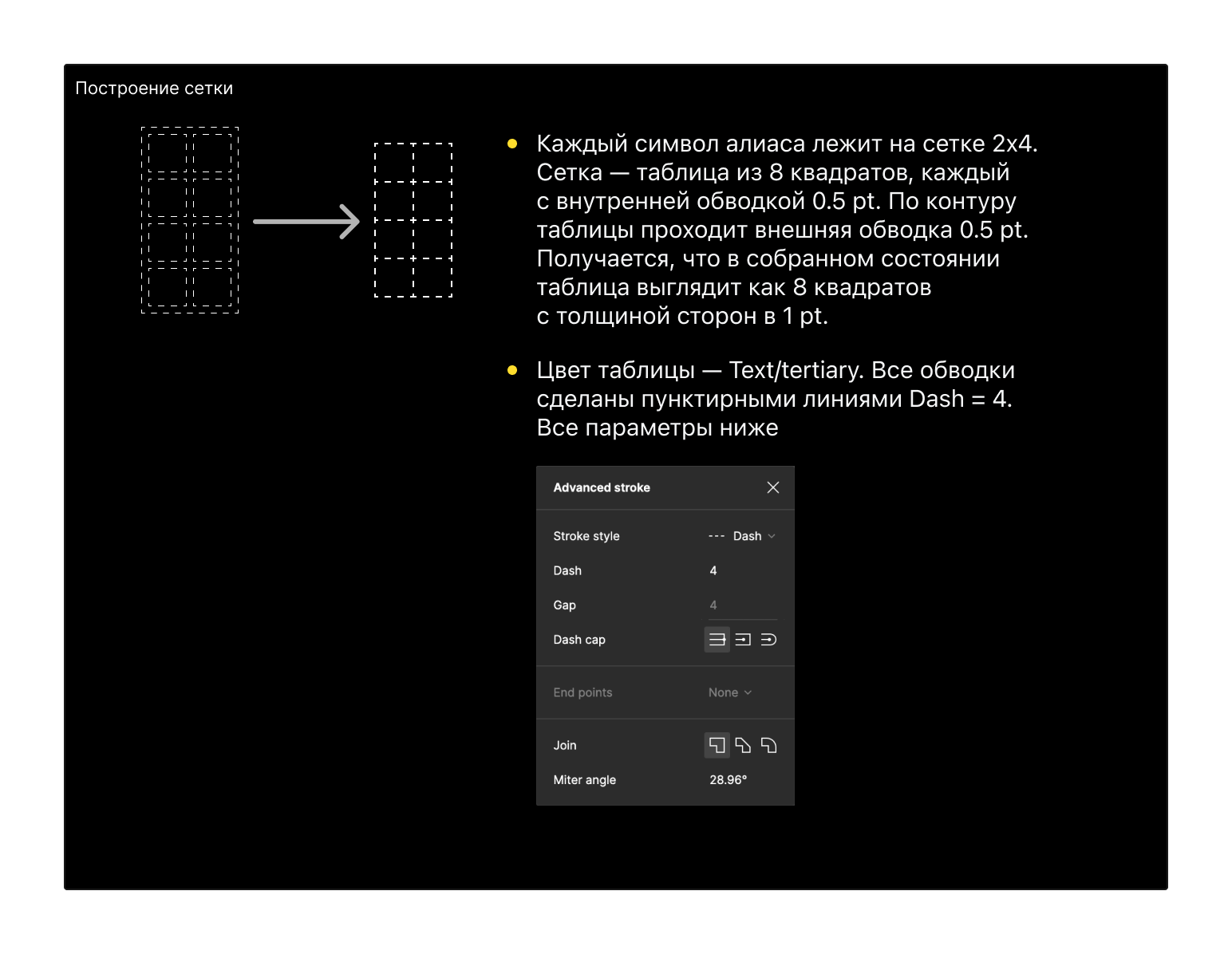
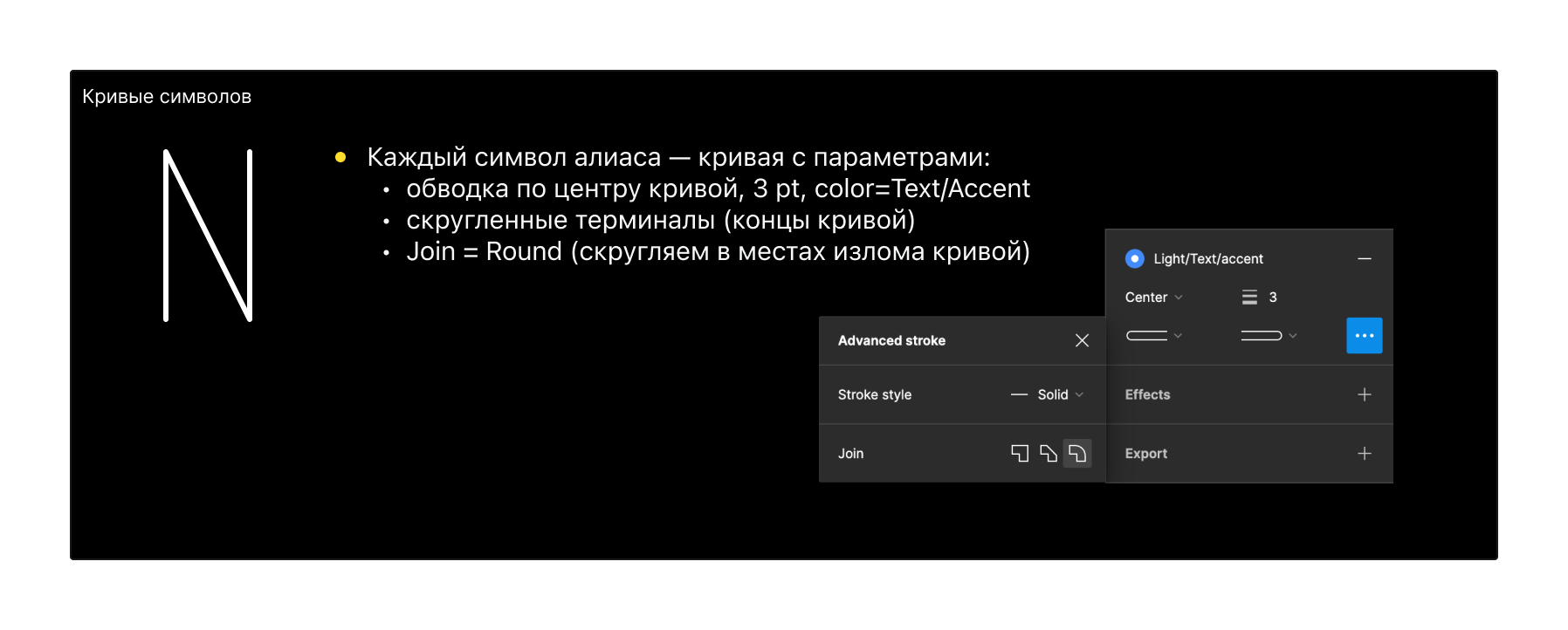



Результат и цифры


Добавили новые символы сначала на заявление, а потом и в приложение. Результат суперский. Судите сами: в июне не прошли проверку с первого раза всего 2% от всех заявлений, а в январе — 43%.

Теперь почти все заявления (97%) обрабатываются меньше, чем за 10 минут. Раньше только 81% заявлений обрабатывались за это время. Долгие проверки почти испарились.

От решения выиграли все. Для операторов код стал намного понятнее, а представителям не нужно думать о почерке — просто перерисовываешь на бумагу то, что видишь на экране клиента. Прочитать код стало проще, от этого ускорилась проверка, и встречи стали проходить быстрее. А значит, оформить ИП с Тинькофф стало еще проще ????
Комментарии (18)

Noospheratu
22.08.2023 08:22+3"в июне не прошли проверку с первого раза всего 2% от всех заявлений, а в январе — 43%. "
Рост ошибок в 20 раз - "суперский результат"?
Было - в июне - 2%, а стало - в январе - 43%? Или всё-таки наоборот?
mraat
22.08.2023 08:22+3Июнь и январь видимо одного года, поэтому сначала январь был. Но да, написали бы в другом порядке и было бы гораздо понятнее

Kyrgyz
22.08.2023 08:22+1Было - в июне - 2%, а стало - в январе - 43%? Или всё-таки наоборот?
Январь раньше июня

shaggyone
22.08.2023 08:22Решали подобную проблему тем, что исключали символы, которые могут визуально плохо различаться, из разрешенных для генерации кода. Примеры I/l/1, O/0 и т.п.

K0styan
22.08.2023 08:22+1А здесь, заметьте тоже - ноль есть, а буквы О нету
shaggyone
22.08.2023 08:22Я российские автономера по дефолту в латинице читать пытаюсь и исходя из этого считаю, что проще вообще без таких символов имеющих схожее начертание обойтись. Если нужно чтобы количество вариантов не уменьшалось, проще пару разрядов добавить. IMHO.

YurySS
22.08.2023 08:22+1Если быть точным, нет букв I, J, О, S, так что путаница практически исключена

dom1n1k
22.08.2023 08:22+3Я понимаю, что почерки могут быть разными, но изначально 43% ошибок это… надо левой ногой писать?
Это ведь сотрудник — его можно административными методами заставить разборчиво написать 10 символов.
saege5b
22.08.2023 08:22Тут скорее проблема дизайнерских шрифтов без засечек, например: l/1/I/t/j; 0/O; U/V и т.д.
На эти грабли с конца 20 века наступают все, кому лень.
Не надо забывать, что посыльный заполняет бланки как правило в машине, часто в условиях дефицита освещения и вдобавок его клиент в этот момент может спрашивать о чём-то.
dom1n1k
22.08.2023 08:22+1Из поста видно, что буквы I, J, O не используются. И все буквы заглавные, то есть никаких i, l или t там тоже нет. Единственная потенциальная путаница U/V.
saege5b
22.08.2023 08:22Из поста первоначальный набор символов - неочевиден.
Приведённые таблицы символов - для варианта: "стало".
Для варианта "было" приведено только девять символов, на первом изображении.

Pavel1114
22.08.2023 08:22+4Можно ещё как нибудь человеческого фактора добавить? Например, не сканировать заявление, а делать из него бумажный самолётик и пытаться попасть им в окно сотрудника, ответственного за приём заявлений.

alnat2
22.08.2023 08:22+1А вариант с QR-кодами не рассматривали? Представитель заполняет заявление, после этого сканирует его в специальном приложении + сканирует код с телефона клиента и отправляет оператору.

denim
22.08.2023 08:22+1Зачем символы в коде, неужели нельзя было обойтись цифрами? Или например что мешало генерить фразу, пускай и бессмысленную но с понятными простыми словами, например утка, осьминог, майонез перец? Для чего латиница?
Yuriy_krd
Странно, что цифру 7 не отрисовали в привычном виде — там же, по сетке, отлично ложится наклонная линия.
K0styan
Такая отрисовка была привычной во времена индексов, но тех, кто бумажное письмо самостоятельно не отправлял, становится всё больше.
А вот прямоугольный вариант по 7-сегментным индикаторам (от домофонов до часов на микроволновке) знаком уже абсолютно всем.
Yuriy_krd
Тогда вопрос к цифре 1. Тут вспоминается: "либо крестик снимите, либо трусы наденьте".
FatherYan
Тоже, еще не читая комменты, споткнулся на 7 и полез смотреть выше, что это. Вероятно, как ниже написали, я из тех, кто помнит бумажные конверты.