

Не так давно мы рассказывали про то, как обучили модель-полиглот mGPT, которая говорит на 61 языке. Этим летом мы выложили большую мультиязычную модель (претрейн) mGPT-13B под открытой лицензией MIT.
Сегодня мы представляем вам семейство моделей-экспертов на основе оригинальной mGPT для языков СНГ и малых народов России. Оригинальная модель уже владела этими языками, но нам хотелось сделать максимально качественные отдельные моноязычные модельки, использовав доступные открытые сеты.
Из общего набора в 61 язык мы дообучили 23 модели на дополнительных данных под каждый язык стран СНГ и малых народов России. И в этой статье мы расскажем про то, как мы это сделали и насколько лучше каждый конкретный файнтьюн знает свой язык. А сами модели можете найти на Hugging Face.
Вот список языков для которых представлены улучшенные моноязычные модели:
???????? mGPT-1.3B Armenian — армянский
???????? mGPT-1.3B Azerbaijan — азербайджанский
???? mGPT-1.3B Bashkir — башкирский
???????? mGPT-1.3B Belorussian — белорусский
???????? mGPT-1.3B Bulgarian — болгарский
???? mGPT-1.3B Buryat — бурятский
???? mGPT-1.3B Chuvash — чувашский
???????? mGPT-1.3B Georgian — грузинский
???? mGPT-1.3B Kalmyk — калмыцкий
???????? mGPT-1.3B Kazakh — казахский
???????? mGPT-1.3B Kirgiz — киргизский
???? mGPT-1.3B Mari — марийский
???????? mGPT-1.3B Mongol — монгольский
???? mGPT-1.3B Ossetian — осетинский
???????? mGPT-1.3B Persian — персидский
???????? mGPT-1.3B Romanian — румынский
???????? mGPT-1.3B Tajik — таджикский
☕ mGPT-1.3B Tatar — татарский
???????? mGPT-1.3B Turkmen — туркменский
???? mGPT-1.3B Tuvan — тувинский
???????? mGPT-1.3B Ukranian — украинский
???????? mGPT-1.3B Uzbek — узбекский
???? mGPT-1.3B Yakut — якутский
Модели mGPT, mGPT-13B и моноязычные mGPT
Исходные версии моделей mGPT описаны в нашей академической статье на ArXiv, где доступны детали обучения, сравнения с предобученной моделью XGLM моделью и многое другое.
Напомним лишь, что модель содержит 1,3 млрд параметров, а версия mGPT-13B — 13 млрд. Мы учили модели, используя размер батча 2048 и контекстное окно размером 512 токенов для первых 400 000 шагов. После этого мы дополнительно доучивали на обновленной очищенной версии датасета на ещё 200 000 шагах, уже с контекстом 2048. Модель может использоваться для генерации текста, решения различных задач в области обработки естественного языка на одном из поддерживаемых языков путём дообучения или в составе ансамблей моделей. Модели также доступны на российской платформе ML Space в хабе предобученных моделей. С этого лета обе модели доступны в HuggingFace под открытой лицензией MIT, мы рады наконец поделиться с ними сообществом.
Новые многоязычные версии моделей основаны на претрейне mGPT. В теории, даже самые малоресурсные языки, которые видела модель, всё равно должны поддерживаться и решать даун-стрим таски благодаря трансферу знаний с ресурсных языков. Однако, по факту пользоваться моделькой, обученой на конкретный язык, очевидно приятнее и имеет больший смысл, т. к. в таком случае мы получаем и знания от остальных языков, и текущего, на котором дообучаемся. Каждая модель была обучена на открытых и очищенных данных для своего языка, об этом ниже.
Данные для дообучения моделей
Самое интересное — это конечно данные =) Для того, чтобы дообучить модели на нужных нам языках, необходимо было собрать моноязычные корпуса. Для этого мы взяли подкорпуса на соответствующих языках из открытых источников:
Wiki, Blogs, LibGen, Archive
и дополнили их специальными открытыми корпуса под каждый язык:
EANC — [армянский] Восточноармянский национальный корпус (ВАНК) является справочно-информационной системой и огромным корпусом, в основе которого лежит обширная коллекция размеченных текстов на литературном варианте восточноармянского языка, государственного языка Республики Армения.
TED talks (ted_talks_iwslt) — [азербайджанский, белорусский. грузинский, казахский, персидский, румынский, таджикский, татарский, украинский, узбекский] (CC BY-NC-ND 4.0) The Web Inventory Talk — это коллекция оригинальных транскриптов с TED talks и их переведенных на разные языки версий. Переводы доступны на более чем 109+ языках, хотя распределение неоднородное.
minorlangs — [башкирский, бурятский, чувашский, калмыцкий, марийский, татарский, тувинский, якутский]. Коллекции текстов для малых языков России. На данном ресурсе представлена информация о том, какие языки представлены в интернете, а какие – нет, а также можно найти и скачать тексты на интересующем вас языке. Проект академический, реализован в рамках магистерской программы «Компьютерная лингвистика».
-
Bashkir — [башкирский] (GPL-3.0 license) parallel-corpora 520K башкирско-русский и русско-башкирский параллельные корпуса (открытые книги, переведенные с русского материалы и многое другое).
bashkir corpus – в открытом доступе представленная коллекция из 20 934 729 токенов чистых башкирских текстов.
XNLI — [болгарский] (Attribution-NonCommercial 4.0 International) болгарская часть известного академического сета XNLI. XLNI представляет собой часть примеров из MNLI (задача textual entailment), переведенного на 14 различных языков.
chuvash_parallel, chv_corpus — [чувашский] (CC0) чувашско-русский параллельный корпус, около одного миллиона предложений, выровненных вручную.
oyrad_corpus — [калмыцкий] (MIT) открытый бесплатный лингвистический корпус калмыцкого и ойратского языков. Различные тексты для изучающих калмыцкий язык, литературу и культуру (стихи, фольклор, проза, религиозная литература)
udhr — [монгольский] The Universal Declaration of Human Rights (UDHR). Набор данных включает в себя переводы документа на более чем 400 языках и диалектах.
VOA Corpus и Kayhan Corpus [персидский] Персидско-арабский корпус, собранный за 2003–2008 годы, 7,9 миллионов слов, лицензия: public domain. И Kayhan корпус — данные за 2005, транслитерированный, 19 миллионов слов, лицензия: public domain.
Стоит отметить, что итоговые датасеты для разных языков получились не очень равнозначными, и для части малоресурсных языков количество текстов оказалось небольшим и из достаточно узкого круга доменов. Для сравнения, для персидского мы обучали модель на 54 079 874 текстах, в то время как для калмыцкого языка нашлось всего 9 181 текстов. При этом каждый текст содержит разное количество слов, в зависимости от его содержания, языка и домена. В среднем на один текст приходится тысяча слов. Для файнтюна каждый моноязычный датасет был разбит на шарды и отформатирован следующим образом:«какой-то текст <|токен конца текста|>
ещё какой-то текст <|токен конца текста|>»
Спасибо всем коллегам, которые неравнодушны к малоресурсным языкам, занимаются развитием и созданием корпусов. Мы уверены, это далеко не весь список источников и инициатив. Мы открыты для коллаборации, если у вас есть данные, на которых вы бы хотели дообучить модель, или вы просто хотите поделиться ими с сообществом, напишите нам. Попробуем вместе собрать датасеты в едином месте и по возможности дообучить модельки на вашем языке.
Тюнинг моноязычных моделей
Вооружившись данными для файнтьюна, мы приступили к дообучению моноязычных моделей.
Каждую модель мы дообучали 250к шагов, что занимает около недели на суперкомпьютере Christofari на одной GPU A100 с 80Gb видеопамяти, делая промежуточный чекпоинт каждые 50к шагов. Для дообучения мы использовали следующую конфигурацию гиперпараметров:
model-parallel-size = 1
num-layers = 24
hidden-size = 2048
num-attention-heads = 16
batch-size = 4
seq-length = 2048
max-position-embeddings = 2048
train-iters = 250000
distributed-backend = nccl
lr = 0.00001
lr-decay-style = cosine
lr-decay-iters = 200000
min-lr = 0.000005
warmup = .001
fp16 = True
После этого мы проверяли, вышла ли моноязычная модель на плато по лоссу на обучающем корпусе. Если модель вышла на плато раньше заключительного шага, то мы брали лучший чекпоинт из имеющихся, оценивая качество уже на отложенной тестовой выборке. Если же этого количества шагов оказывалось недостаточно, и лосс модели на 250 тысячах шагов все еще продолжал падать (таких моделей оказалось 10 из 23), то мы продолжали ее дообучение до выхода на плато. Например, для армянского и белорусского на это потребовалось миллион шагов. Стоит, наверное, пояснить, что конечно лучше было бы ориентироваться лишь на метрики на отложенной выборке, но считать их в процессе обучения было слишком затратно, поэтому мы и прибегли к такой хитрости, провалидировав лишь отдельные чекпоинты.
В качестве отложенной выборки мы использовали тестовый набор данных, который не пересекается с данными для дообучения, дополнительно профильтровав его и выкинув те примеры, которые вошли в обучающий корпус базовой модели mGPT.
Посмотрим, как выглядят кривые обучения, и как снижался лосс и перплексия при дообучении на разных языках.


Мы видим, что кривые выглядят очень по-разному для разных языков.
Так например для армянского:
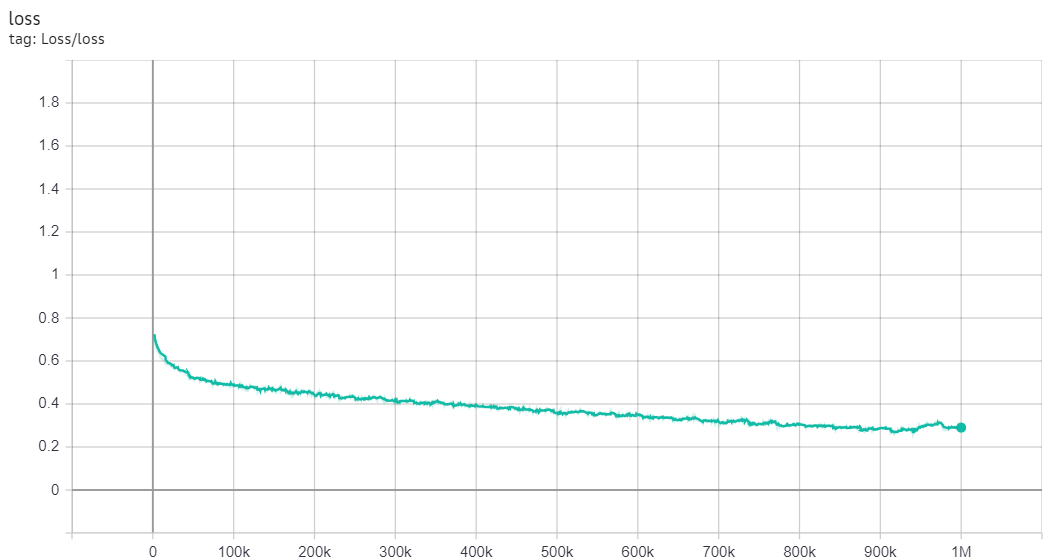

обучение изначально началось с очень низкой перплексии, но для полноценного выхода на плато потребовалось 500к шагов.
А вот для марийского график выглядит совершенно по-другому:

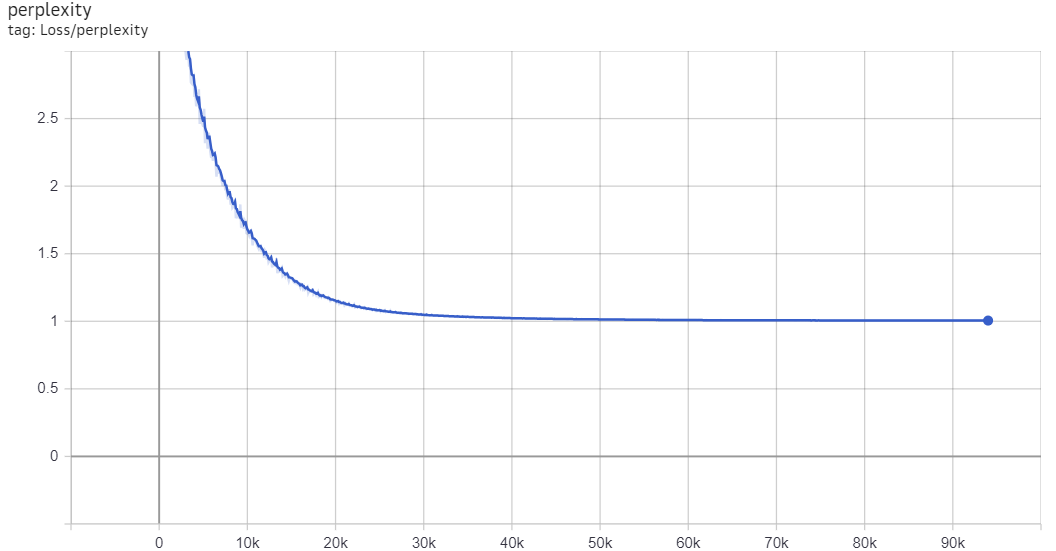
здесь обучение началось с очень большой перплексии, но всего за 5к шагов она вышла на плато на уровне единица. Для персидского мы видим промежуточный вариант, когда плато наступает за 200 тысяч шагов:


Но при этом мы видим, что для персидского график достаточно сильно «штормит». Такие различия в обучении скорее всего связаны с тем, что, как мы уже упоминали, обучающие корпуса для разных языков очень различаются как по объему, так и по количеству доменов. И в то же время как для персидского и армянского обучающие корпуса достаточно большие, данных для марийского крайне мало, и они скорее всего представлены достаточно ограниченным кругом доменов. Данный вопрос однако требует более детального изучения, и пока мы его оставим для будущих исследований.
Ниже представлена сводная таблица с результатами для чекпоинтов для всех языков.
Язык |
loss/ppl на test |
Лучший шаг |
Армянский |
loss: 0.55 ppl: 1.73 |
500000 |
Азербайджанский |
loss: 1.68 ppl: 5.37 |
70000 |
Башкирский |
loss: 1.95 ppl: 7.06 |
5000 |
Белорусский |
loss: 3.32 ppl: 27.65 |
10000 |
Болгарский |
loss: 2.72 ppl: 15.20 |
200 |
Бурятский |
loss: 2.87 ppl: 17.63 |
1000 |
Чувашский |
loss: 3.36 ppl: 28.76 |
1000 |
Грузинский |
loss: 2.82 ppl: 16.85 |
10000 |
Калмыцкий |
loss: 2.64 ppl: 13.97 |
200 |
Казахский |
loss: 1.22 ppl: 3.38 |
150000 |
Киргизский |
loss: 2.10 ppl: 8.20 |
50000 |
Марийский |
loss: 3.05 ppl: 21.19 |
5000 |
Монгольский |
loss: 1.47 ppl: 4.35 |
50000 |
Осетинский |
loss: 2.93 ppl: 18.70 |
200 |
Персидский |
loss: 3.51 ppl: 33.44 |
200 |
Румынский |
loss: 1.24 ppl: 3.44 |
5000 |
Таджикский |
loss: 1.88 ppl: 6.52 |
50000 |
Татарский |
loss: 1.31 ppl: 3.69 |
5000 |
Туркменский |
loss: 3.35 ppl: 28.47 |
200 |
Тувинский |
loss: 3.71 ppl: 40.84 |
2000 |
Украинский |
loss: 1.96 ppl: 7.10 |
10000 |
Узбекский |
loss: 1.92 ppl: 6.84 |
50000 |
Якутский |
loss: 2.37 ppl: 10.65 |
2000 |
Оценка модели: смотрим на результат
Моноязычные файнтьюны получены, осталось проверить, а есть ли от всей нашей деятельности практический результат. Стали ли модели реально лучше знать целевые языки? Вдруг исходная mGPT, которая знает аж 61 язык, понимала их так же хорошо, а все обучение было зря? Спойлер: сейчас мы убедимся, что, конечно, это было не зря.
Итак, для сравнения качества оригинальной mGPT и ее моноязычных файнтьюнов на целевом языке мы в первую очередь оценили лосс и перплексию обеих моделей на целевом языке на тестовой выборке. Как мы уже упоминали, данная выборка не входила ни в корпус для дообучения моноязычных чекпоинтов, ни в обучающий корпус оригинальной модели.
Языки |
Моноязычный файнтьюн mGPT |
Оригинальная mGPT |
Прирост |
Армянский |
loss: 0.55 ppl: 1.73 |
loss: 1.83 ppl: 6.23 |
260% |
Азербайджанский |
loss: 1.68 ppl: 5.37 |
loss: 3.86 ppl: 47.46 |
783% |
Башкирский |
loss: 1.95 ppl: 7.06 |
loss: 3.56 ppl: 35.01 |
395% |
Белорусский |
loss: 3.32 ppl: 27.65 |
loss: 4.14 ppl: 62.73 |
126% |
Болгарский |
loss: 2.72 ppl: 15.20 |
loss: 4.45 ppl: 85.70 |
463% |
Бурятский |
loss: 2.87 ppl: 17.63 |
loss: 4.19 ppl: 65.70 |
272% |
Чувашский |
loss: 3.36 ppl: 28.76 |
loss: 4.79 ppl: 120.66 |
319% |
Грузинский |
loss: 2.82 ppl: 16.85 |
loss: 4.05 ppl: 57.20 |
239% |
Калмыцкий |
loss: 2.64 ppl: 13.97 |
loss: 4.30 ppl: 74.12 |
430% |
Казахский |
loss: 1.22 ppl: 3.38 |
loss: 3.27 ppl: 26.43 |
680% |
Киргизский |
loss: 2.10 ppl: 8.20 |
loss: 4.23 ppl: 68.44 |
734% |
Марийский |
loss: 3.05 ppl: 21.19 |
loss: 5.26 ppl: 193.19 |
811% |
Монгольский |
loss: 1.47 ppl: 4.35 |
loss: 3.32 ppl: 27.69 |
536% |
Осетинский |
loss: 2.93 ppl: 18.70 |
loss: 4.36 ppl: 78.17 |
318% |
Персидский |
loss: 3.51 ppl: 33.44 |
loss: 4.45 ppl: 86.05 |
157% |
Румынский |
loss: 1.24 ppl: 3.44 |
loss: 1.63 ppl: 5.08 |
47% |
Таджикский |
loss: 1.88 ppl: 6.52 |
loss: 4.09 ppl: 59.88 |
818% |
Татарский |
loss: 1.31 ppl: 3.69 |
loss: 3.17 ppl: 23.84 |
546% |
Туркменский |
loss: 3.35 ppl: 28.47 |
loss: 5.29 ppl: 199.11 |
600% |
Тувинский |
loss: 3.71 ppl: 40.84 |
loss: 5.10 ppl: 164.40 |
302% |
Украинский |
loss: 1.96 ppl: 7.11 |
loss: 4.00 ppl: 54.93 |
672% |
Узбекский |
loss: 1.92 ppl: 6.84 |
loss: 5.33 ppl: 206.85 |
2924% |
Якутский |
loss: 2.37 ppl: 10.65 |
loss: 4.31 ppl: 74.74 |
611% |
Ура! Мы видим явный прирост качества абсолютно для всех языков, а для многих языков перплексия снизилась в разы, а то и в десятки раз.
Помимо этого, мы также сравнили качество полученных моноязычных файнтьюнов с оригинальной моделью mGPT на задаче машинного перевода. Для этого мы взяли интересующие нас языки из FLORES-200 — параллельного корпуса для машинного перевода на 200 языков. Перевод осуществлялся с русского и английского языков на язык, соответствующей языку файнтьюна. Оценка модели проводилась в zero-shot и few-shot формате с использованием затравок (англ. prompts) на английском языке (en prompt) и языке файнтьюна (tgt prompt). Пример затравки на английском языке:
“Translate from SRC_LANG to TGT_LANG: SRC_TEXT ==> “,
где SRC_LANG — язык исходного текста, TGT_LANG — язык, на который осуществляется перевод, SRC_TEXT — исходный текст. Для few-shot формата мы использовали 1 и 4 примеров.
Качество мы оценивали с помощью стандартных метрик машинного обучения ROUGE и BLEU. В таблице ниже представлены результаты.
mono mgpt |
original mgpt |
mono mgpt |
original mgpt |
|||||||
en prompt |
tgt prompt |
|||||||||
SRC_LANG |
TGT_LANG |
n_shots |
rouge |
bleu |
rouge |
bleu |
rouge |
bleu |
rouge |
bleu |
russian |
armenian |
0 |
0.381 |
0.007 |
0.098 |
0.008 |
0.420 |
0.056 |
0.426 |
0.050 |
1 |
0.377 |
0.009 |
0.386 |
0.009 |
0.414 |
0.052 |
0.417 |
0.054 |
||
4 |
0.408 |
0.007 |
0.321 |
0.000 |
0.439 |
0.061 |
0.364 |
0.013 |
||
azerbaijani |
0 |
0.371 |
0.048 |
0.150 |
0.018 |
0.453 |
0.085 |
0.247 |
0.055 |
|
1 |
0.418 |
0.085 |
0.364 |
0.083 |
0.460 |
0.106 |
0.520 |
0.181 |
||
4 |
0.506 |
0.110 |
0.334 |
0.047 |
0.521 |
0.138 |
0.145 |
0.017 |
||
bashkir |
0 |
0.413 |
0.052 |
0.356 |
0.053 |
0.475 |
0.085 |
0.492 |
0.087 |
|
1 |
0.444 |
0.067 |
0.453 |
0.090 |
0.495 |
0.101 |
0.531 |
0.128 |
||
4 |
0.476 |
0.068 |
0.382 |
0.035 |
0.522 |
0.110 |
0.440 |
0.038 |
||
belarusian |
0 |
0.231 |
0.033 |
0.429 |
0.073 |
0.305 |
0.041 |
0.499 |
0.105 |
|
1 |
0.425 |
0.070 |
0.533 |
0.149 |
0.468 |
0.080 |
0.656 |
0.214 |
||
4 |
0.398 |
0.053 |
0.507 |
0.106 |
0.485 |
0.075 |
0.511 |
0.052 |
||
bulgarian |
0 |
0.291 |
0.064 |
0.439 |
0.113 |
0.356 |
0.086 |
0.487 |
0.133 |
|
1 |
0.390 |
0.100 |
0.544 |
0.238 |
0.448 |
0.124 |
0.651 |
0.253 |
||
4 |
0.321 |
0.087 |
0.485 |
0.215 |
0.371 |
0.098 |
0.566 |
0.243 |
||
georgian |
0 |
0.306 |
0.050 |
0.028 |
0.008 |
0.384 |
0.067 |
0.257 |
0.056 |
|
1 |
0.416 |
0.078 |
0.249 |
0.091 |
0.429 |
0.080 |
0.541 |
0.197 |
||
4 |
0.343 |
0.078 |
0.171 |
0.039 |
0.419 |
0.084 |
0.407 |
0.092 |
||
kazakh |
0 |
0.290 |
0.042 |
0.393 |
0.057 |
0.414 |
0.083 |
0.518 |
0.114 |
|
1 |
0.468 |
0.093 |
0.485 |
0.106 |
0.463 |
0.108 |
0.563 |
0.158 |
||
4 |
0.513 |
0.084 |
0.417 |
0.047 |
0.559 |
0.142 |
0.471 |
0.043 |
||
kyrgyz |
0 |
0.352 |
0.052 |
0.419 |
0.058 |
0.539 |
0.095 |
0.511 |
0.089 |
|
1 |
0.513 |
0.091 |
0.496 |
0.114 |
0.557 |
0.103 |
0.594 |
0.154 |
||
4 |
0.525 |
0.083 |
0.450 |
0.067 |
0.573 |
0.105 |
0.471 |
0.065 |
||
mongolian |
0 |
0.262 |
0.034 |
0.378 |
0.041 |
0.337 |
0.057 |
0.512 |
0.103 |
|
1 |
0.364 |
0.063 |
0.484 |
0.091 |
0.432 |
0.082 |
0.570 |
0.121 |
||
4 |
0.522 |
0.087 |
0.419 |
0.031 |
0.580 |
0.124 |
0.508 |
0.042 |
||
persian |
0 |
0.012 |
0.006 |
0.013 |
0.007 |
0.027 |
0.005 |
0.259 |
0.068 |
|
1 |
0.037 |
0.009 |
0.215 |
0.101 |
0.092 |
0.014 |
0.470 |
0.203 |
||
4 |
0.091 |
0.017 |
0.080 |
0.036 |
0.113 |
0.016 |
0.305 |
0.107 |
||
romanian |
0 |
0.495 |
0.070 |
0.148 |
0.024 |
0.609 |
0.118 |
0.350 |
0.102 |
|
1 |
0.588 |
0.118 |
0.597 |
0.263 |
0.592 |
0.136 |
0.680 |
0.344 |
||
4 |
0.562 |
0.124 |
0.622 |
0.232 |
0.568 |
0.135 |
0.587 |
0.210 |
||
tajik |
0 |
0.277 |
0.038 |
0.389 |
0.059 |
0.354 |
0.064 |
0.502 |
0.144 |
|
1 |
0.494 |
0.124 |
0.498 |
0.138 |
0.528 |
0.161 |
0.555 |
0.202 |
||
4 |
0.510 |
0.126 |
0.421 |
0.045 |
0.548 |
0.172 |
0.518 |
0.058 |
||
tatar |
0 |
0.426 |
0.052 |
0.414 |
0.063 |
0.481 |
0.082 |
0.522 |
0.107 |
|
1 |
0.467 |
0.057 |
0.488 |
0.111 |
0.511 |
0.095 |
0.571 |
0.163 |
||
4 |
0.493 |
0.079 |
0.447 |
0.044 |
0.539 |
0.119 |
0.510 |
0.050 |
||
turkmen |
0 |
0.216 |
0.018 |
0.134 |
0.016 |
0.218 |
0.029 |
0.130 |
0.020 |
|
1 |
0.254 |
0.035 |
0.433 |
0.095 |
0.364 |
0.072 |
0.397 |
0.084 |
||
4 |
0.350 |
0.058 |
0.363 |
0.078 |
0.395 |
0.078 |
0.343 |
0.073 |
||
ukranian |
0 |
0.276 |
0.065 |
0.434 |
0.089 |
0.341 |
0.074 |
0.497 |
0.119 |
|
1 |
0.332 |
0.083 |
0.601 |
0.263 |
0.383 |
0.088 |
0.744 |
0.284 |
||
4 |
0.459 |
0.108 |
0.564 |
0.199 |
0.511 |
0.118 |
0.568 |
0.107 |
||
uzbek |
0 |
0.423 |
0.041 |
0.142 |
0.017 |
0.392 |
0.058 |
0.208 |
0.038 |
|
1 |
0.311 |
0.046 |
0.373 |
0.079 |
0.366 |
0.079 |
0.442 |
0.129 |
||
4 |
0.508 |
0.141 |
0.228 |
0.058 |
0.472 |
0.136 |
0.270 |
0.079 |
||
english |
armenian |
0 |
0.292 |
0.005 |
0.359 |
0.003 |
0.397 |
0.042 |
0.423 |
0.040 |
1 |
0.361 |
0.004 |
0.372 |
0.004 |
0.413 |
0.042 |
0.396 |
0.045 |
||
4 |
0.399 |
0.002 |
0.327 |
0.000 |
0.442 |
0.047 |
0.361 |
0.008 |
||
azerbaijani |
0 |
0.434 |
0.053 |
0.237 |
0.030 |
0.502 |
0.101 |
0.516 |
0.133 |
|
1 |
0.523 |
0.105 |
0.521 |
0.132 |
0.541 |
0.140 |
0.572 |
0.208 |
||
4 |
0.515 |
0.092 |
0.507 |
0.101 |
0.537 |
0.142 |
0.399 |
0.061 |
||
bashkir |
0 |
0.353 |
0.028 |
0.081 |
0.012 |
0.457 |
0.072 |
0.459 |
0.069 |
|
1 |
0.432 |
0.037 |
0.465 |
0.048 |
0.472 |
0.081 |
0.512 |
0.100 |
||
4 |
0.449 |
0.036 |
0.145 |
0.012 |
0.496 |
0.084 |
0.191 |
0.015 |
||
belarusian |
0 |
0.056 |
0.008 |
0.107 |
0.014 |
0.144 |
0.018 |
0.403 |
0.069 |
|
1 |
0.147 |
0.016 |
0.480 |
0.103 |
0.237 |
0.032 |
0.585 |
0.180 |
||
4 |
0.215 |
0.019 |
0.472 |
0.082 |
0.338 |
0.043 |
0.288 |
0.025 |
||
bulgarian |
0 |
0.051 |
0.010 |
0.125 |
0.030 |
0.134 |
0.030 |
0.391 |
0.102 |
|
1 |
0.197 |
0.037 |
0.378 |
0.150 |
0.236 |
0.050 |
0.518 |
0.235 |
||
4 |
0.169 |
0.043 |
0.468 |
0.248 |
0.227 |
0.051 |
0.542 |
0.270 |
||
georgian |
0 |
0.210 |
0.027 |
0.031 |
0.005 |
0.389 |
0.056 |
0.366 |
0.071 |
|
1 |
0.420 |
0.060 |
0.520 |
0.158 |
0.452 |
0.074 |
0.584 |
0.192 |
||
4 |
0.438 |
0.090 |
0.515 |
0.119 |
0.488 |
0.113 |
0.554 |
0.136 |
||
kazakh |
0 |
0.217 |
0.021 |
0.277 |
0.030 |
0.357 |
0.060 |
0.468 |
0.092 |
|
1 |
0.478 |
0.053 |
0.495 |
0.067 |
0.475 |
0.091 |
0.552 |
0.142 |
||
4 |
0.497 |
0.055 |
0.407 |
0.030 |
0.540 |
0.117 |
0.275 |
0.021 |
||
kyrgyz |
0 |
0.169 |
0.020 |
0.127 |
0.016 |
0.471 |
0.068 |
0.457 |
0.074 |
|
1 |
0.462 |
0.053 |
0.497 |
0.076 |
0.509 |
0.075 |
0.566 |
0.125 |
||
4 |
0.512 |
0.061 |
0.461 |
0.058 |
0.536 |
0.092 |
0.434 |
0.052 |
||
mongolian |
0 |
0.102 |
0.013 |
0.069 |
0.008 |
0.344 |
0.054 |
0.470 |
0.076 |
|
1 |
0.500 |
0.058 |
0.496 |
0.060 |
0.530 |
0.098 |
0.551 |
0.102 |
||
4 |
0.513 |
0.058 |
0.308 |
0.018 |
0.554 |
0.105 |
0.386 |
0.036 |
||
persian |
0 |
0.027 |
0.008 |
0.101 |
0.024 |
0.076 |
0.013 |
0.331 |
0.081 |
|
1 |
0.183 |
0.032 |
0.323 |
0.144 |
0.321 |
0.064 |
0.515 |
0.244 |
||
4 |
0.363 |
0.080 |
0.447 |
0.226 |
0.439 |
0.095 |
0.507 |
0.244 |
||
romanian |
0 |
0.557 |
0.078 |
0.504 |
0.119 |
0.621 |
0.115 |
0.577 |
0.201 |
|
1 |
0.601 |
0.110 |
0.726 |
0.336 |
0.613 |
0.130 |
0.747 |
0.395 |
||
4 |
0.595 |
0.123 |
0.719 |
0.315 |
0.602 |
0.148 |
0.697 |
0.301 |
||
tajik |
0 |
0.073 |
0.012 |
0.118 |
0.017 |
0.257 |
0.062 |
0.480 |
0.135 |
|
1 |
0.486 |
0.086 |
0.505 |
0.101 |
0.509 |
0.147 |
0.552 |
0.182 |
||
4 |
0.503 |
0.092 |
0.374 |
0.037 |
0.528 |
0.156 |
0.431 |
0.058 |
||
tatar |
0 |
0.248 |
0.018 |
0.155 |
0.017 |
0.435 |
0.063 |
0.475 |
0.080 |
|
1 |
0.414 |
0.028 |
0.494 |
0.070 |
0.473 |
0.077 |
0.546 |
0.142 |
||
4 |
0.476 |
0.047 |
0.431 |
0.033 |
0.518 |
0.098 |
0.425 |
0.030 |
||
turkmen |
0 |
0.446 |
0.046 |
0.292 |
0.036 |
0.464 |
0.076 |
0.369 |
0.068 |
|
1 |
0.431 |
0.057 |
0.113 |
0.016 |
0.488 |
0.089 |
0.358 |
0.075 |
||
4 |
0.475 |
0.078 |
0.470 |
0.093 |
0.524 |
0.110 |
0.568 |
0.140 |
||
ukranian |
0 |
0.132 |
0.017 |
0.087 |
0.015 |
0.223 |
0.041 |
0.428 |
0.087 |
|
1 |
0.295 |
0.045 |
0.586 |
0.193 |
0.349 |
0.062 |
0.676 |
0.278 |
||
4 |
0.484 |
0.094 |
0.484 |
0.119 |
0.531 |
0.117 |
0.456 |
0.076 |
||
uzbek |
0 |
0.530 |
0.072 |
0.320 |
0.044 |
0.500 |
0.075 |
0.377 |
0.073 |
|
1 |
0.527 |
0.081 |
0.153 |
0.035 |
0.541 |
0.111 |
0.217 |
0.060 |
||
4 |
0.590 |
0.141 |
0.380 |
0.110 |
0.583 |
0.167 |
0.613 |
0.222 |
||
Мы видим, что для большого числа языков моноязычные модели показывают лучшее качество, чем оригинальная mGPT, причем зачастую превосходство проявляется в zero- и 4-shot формате, а для ряда языков (например, узбекского, туркменского и азербайджанского) моноязычный чекпоинт с английскими затравками превосходит оригинал во всех форматах. Однако, здесь нет такого единства, как при оценке перпрексии на отложенной выборке и, например, для болгарского, качество перевода после моноязычного дообучения даже снизилось. Это может быть связано с тем, что при моноязычном файнтьюне модель забывает язык оригинала, с которого идет перевод (в данном случае это английский и русский), поэтому данный эффект не может свидетельствовать об ухудшении знания целевого языка как такового. И для более глубокого изучения данного вопроса мы в дальнейшем планируем проанализировать способности моноязычных моделей на других прикладных (downstream) задачах на соответствующих языках.
Использование
Что ж, мы рассказали вам про новые моноязычные чекпоинты mGPT, теперь у вас есть возможность их использовать и тестировать на своих задачах.
Работа с моделью ничем не отличается от работы с обычной моделью mGPT. Ниже приведен базовый пример генерации, а еще больше примеров использования можно найти в репозитории mgpt.
Пример, для татарского языка с использованием библиотеки HuggingFace
from transformers import GPT2LMHeadModel, GPT2Tokenizer
import torch
device = torch.device("cuda")
model.to(device)
tokenizer = GPT2Tokenizer.from_pretrained("ai-forever/mGPT-1.3B-tatar")
model = GPT2LMHeadModel.from_pretrained("ai-forever/mGPT-1.3B-tatar")
text = "Казан илдә урнашкан "
input_ids = tokenizer.encode(text, return_tensors="pt").cuda(device)
out = model.generate(
input_ids,
min_length=100,
max_length=100,
eos_token_id=5,
pad_token=1,
top_k=10,
top_p=0.0,
no_repeat_ngram_size=5
)
generated_text = list(map(tokenizer.decode, out))[0]
print(generated_text)
Казан илдә урнашкан һәм Татарстан Республикасының Кукмара районына керә.
Вместо заключения: мы открыты для новых горизонтов и новых языков
Итак, сегодня мы рассказали про 23 новые модели на основе mGPT, дообученные для языков стран СНГ и малых народов России. Мы открыты для коллаборации и готовы продолжать исследования в данной области и дообучение модели и на других языках. Если у вас есть идея, на каком языке еще стоит дообучить mGPT, есть данные, на которых её можно дообучать, и желание с нами коллаборировать, пишите, пожалуйста, нам в SaluteAI Community.
Полезные сcылки:
Модель mGPT-XL на Hugging Face и академическая статья модели
Статья про тестирование моделей от контент-менеджера "Модель-полиглот: как мы учили GPT-3 на 61 языке мира"
Модель mGPT3-13B доступна в виде AI Service Cloud.
Моноязычные модели в AI Service Cloud.
Команда разработчиков: SberDevices, AGI NLP
<3 Игорь Чурин @Gscraid, Маша Тихонова @mashkka_t, Настя Козлова @nkozlova, Таня Шаврина @Rybolos, Олег Шляжко, Сергей Аверкиев @averkij, Алёна Феногенова @alenusch, Влад Михайлов и co.
Комментарии (8)

rPman
22.08.2023 12:31+1Подскажите пожалуйста, почему исследователи обучают и малые и большие модели вместо одной большой сразу? Как можно переиспользовать результат обучения малых моделей (в вашем случае моноязыковые) для обучения большой (мультиязыковой)? Использовалась ли генерация текстов (в т.ч. перевод через промежуточный язык) для расширения обучающей выборки?

averkij
22.08.2023 12:31+1Подскажите пожалуйста, почему исследователи обучают и малые и большие модели вместо одной большой сразу?
Во-первых, чем больше модель, тем она потенциально умнее, но тем сложнее и дороже её учить и труднее использовать (понадобится много видеопамяти, чтобы запустить и ещё больше, чтобы дообучить).
Во-вторых, для решения многих задач вовсе не обязательно иметь большую модель на много миллиардов весов.
Конкретно эти модели вполне можно дообучить на пользовательских GPU. Например, на болталку или какие-то утилитарные задачи. Если бы они были большие (100B, например), вы бы уже так просто их не доучили и даже не запустили бы.
Как можно переиспользовать результат обучения малых моделей (в вашем случае моноязыковые) для обучения большой (мультиязыковой)?
Они не для этого, они как раз для задач, связанных с одним конкретным языком. Мультиязычная модель побольше уже есть — mGPT-13B.
Использовалась ли генерация текстов (в т.ч. перевод через промежуточный язык) для расширения обучающей выборки?
Cинтетические данные вообще надо использовать с осторожностью, а под малые языки ещё и в принципе нет качественных переводчиков. В этом случае модель будет усваивать ошибки машинного перевода. А для более популярных языков в задачах машинного перевода, например, так да, делают (back translation).

MajorMotokoKusanagi
22.08.2023 12:31+1Модели с диалектами вроде мишарского татарского или горного марийского и лугового марийского?
averkij
22.08.2023 12:31+1Пока нет. Если у вас есть тексты на этих диалектах или вы знаете, где их найти, то делитесь.



AigizK
Спасибо большое за такой подарок.
Кто нибудь еще бы выложил скрипты для обучения под nstruct,chat и тд :)
alenusch Автор
Вообще примеров много должно быть, так как модели в HF формате. Посмотрю.
Тут скорее трудность в том, что инструкции надо на нужном языке найти в достаточном количестве.