
Проблемы роста — обычное дело, и базы данных в этом смысле не исключение. Полтора года назад команда Loki задумалась о том, как на порядок повысить кардинальность (cardinality), производительность запросов (query throughput) и надежность (reliability). Работа над новым индексным слоем почти закончена — время остановиться и посмотреть: что же мы делаем, чтобы оставаться на пике прогресса.
Новый индекс Loki основывается на модифицированной версии TSDB (time series database, база данных временны́х рядов) — одном из компонентов в основе Prometheus, оптимизированном для маршрутизации множества лейблов ({job="api", cluster="us-central", environment!="prod"}) и привязки их к соответствующим данным.
Архитектура
Head’ы и write-ahead-журналы в TSDB
Давайте посмотрим, как устроены эти новые элементы Loki. Сперва о том, как в Loki строятся индексы.
TSDB — это высокопроизводительные базы данных, которые позволяют запрашивать стримы и чанки по их лейблам. Однако они неизменяемы (immutable) и должны быть собраны до того, как к ним можно будет обращаться. Это не соответствует нашей модели потребления (ingestion), в которой логи могут быть выгружены в любое время, а чанки сбрасываются по мере готовности.
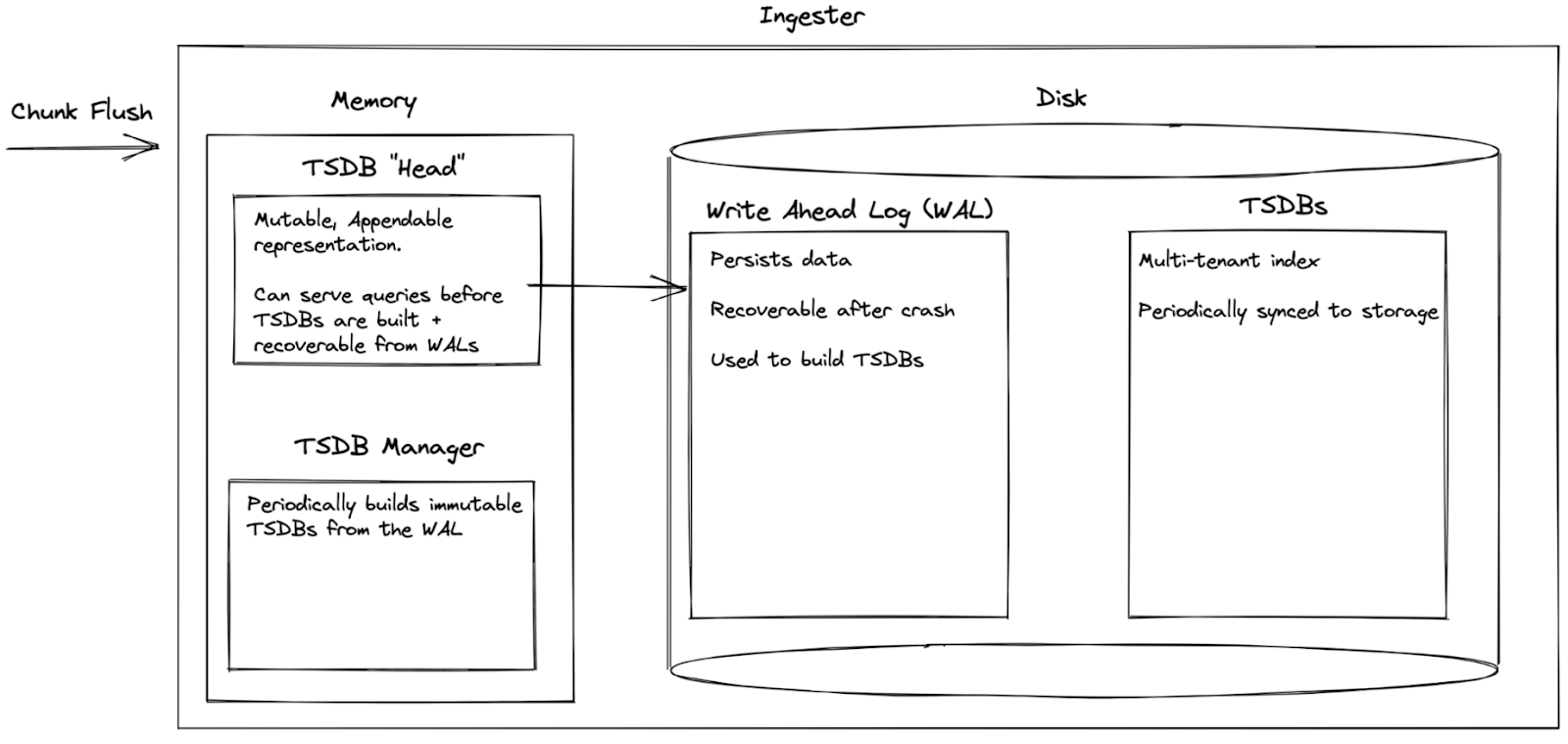
Для решения этой проблемы мы используем изменяемую (mutable) TSDB’шную Head, в которую можно инкрементально добавлять данные и сразу же делать запросы. Да, не особо эффективно — но так надо лишь для обслуживания новых данных, которые еще не успели попасть в TSDB. С помощью write-ahead-журнала (WAL) мы отслеживаем выгрузку чанков на диск, что в случае сбоя позволяет восстановить данные простым воспроизведением WAL.
Сборка и ротация в TSDB
Менеджер TSDB используется для периодической (раз в 15 минут) сборки индексов TSDB из накопившихся WAL’ов. В случае успеха он ротирует старые TSDB Head и WAL, удаляя их для освобождения диска с памятью и заменяя пустышками, — это предотвращает неограниченный рост менее эффективных блоков и замещает их на свежесобранную TSDB.
Новые индексы TSDB производительны, мультитенантны и готовы к немедленному использованию. Они отправляются в удаленное хранилище для дальнейшей работы с индексными шлюзами (index-gateways) или квериерами (queriers), но при этом временно хранятся локально, позволяя тем временем инжестерам (ingesters) обрабатывать запросы.
Тенантность и уплотнение
Индексы TSDB, собранные на инжестерах, мультитенантны, часто собираются (каждые 15 минут на инжестер), поэтому нецелесообразно строить индексы для каждого тенанта в условиях, когда инжестер может содержать тысячи тенантов. Мы используем компактор, чтобы превратить множество краткосрочных мультитенантных индексов в более долгосрочные однотенантные. Поскольку это происходит постоянно, индексные шлюзы и квериеры должны иметь возможность запрашивать как мультитенантные индексы до уплотнения, так и однотенантные индексы после него.
Поскольку компактор технически относится к неосновным средствам повышения эффективности, вполне допустима временная неработоспособность компактора. Однако его вклад весьма существенен. Давайте сравним окружение до и после уплотнения для запроса, охватывающего 24 часа, в кластере с 4000 тенантами и 100 инжестерами:
24 часа * 15-минутный интервал сборки tsdb * 100 инжестеров
= 24 * 4 * 100
= 9600 индексных файлов с данными 4000 тенантов в каждомпротив
1 из 4000 индексов на одного тенанта, каждый из которых охватывает суткиПосле уплотнения достаточно запросить один индексный файл с интересующим тенантом вместо того, чтобы запрашивать 9600 индексных файлов, содержащих данные от всех 4000 тенантов!
Примечание
Здесь не учитываются преимущества дедупликации, поскольку уплотненные индексы удаляют повторные ссылки на одни и те же чанки, созданные из-за фактора репликации Loki.
Планирование запросов
Следующий элемент TSDB, который мы рассмотрим, — планирование запросов. Значительная часть производительности Loki обязана своим существованием различным этапам планирования запросов, таким как:
разбиение — параллельный запрос временны́х диапазонов (например, интервалов в 1 час) и объединение результатов;
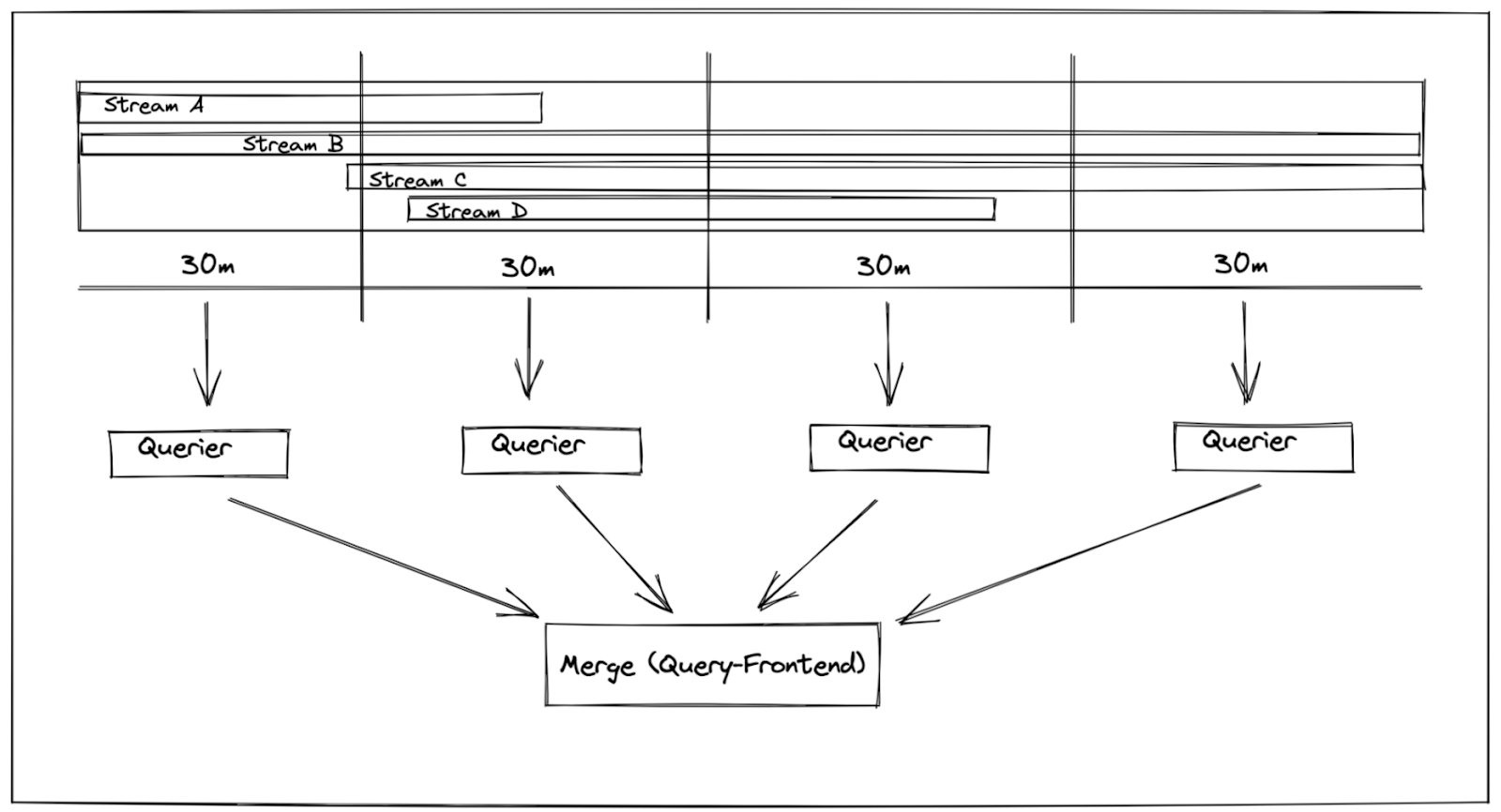
шардинг — набор оптимизаций, позволяющих делать лучшую параллелизацию запросов, чаще всего путем построения независимых запросов к непересекающимся подмножествам (шардам) данных и их последующего слияния — еще одно «измерение», которое можно распараллелить, объединив с предыдущим разбиением по времени.

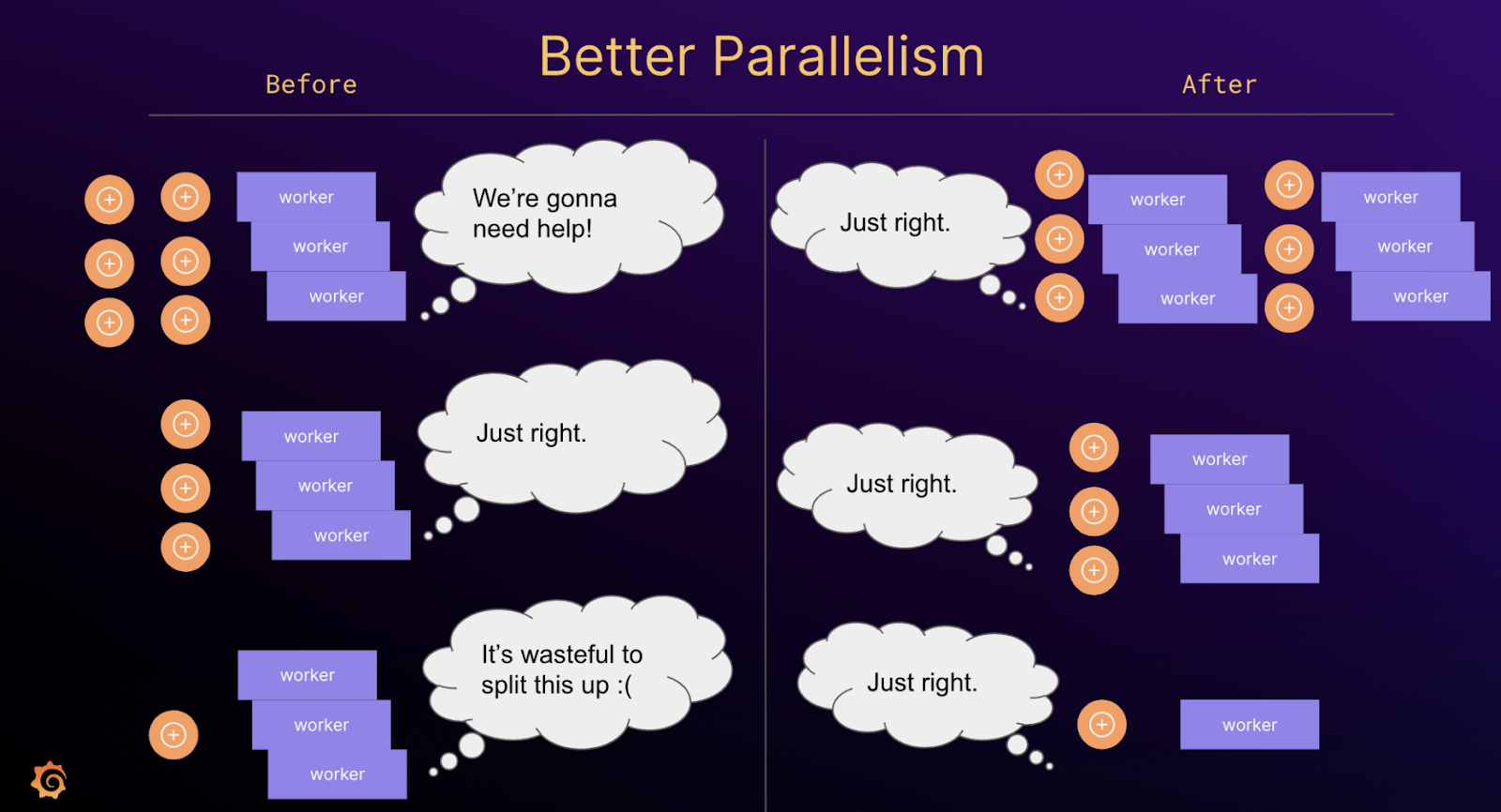
Для лучшей параллелизации за отдельный период можно настроить разбиение времени для каждого тенанта в отдельности: мелкому тенанту выделить 1 час, крупному — 30 минут. Исторически сложилось, что шардинг не меняется в течение всего срока существования конфигурации в кластере, а это затрудняет поиск оптимального фактора параллелизма. Чтобы его подобрать, необходимо для каждого тенанта постоянно переоценивать взаимосвязь между разделением по времени, коэффициентами шардинга в кластере и объемом обрабатываемых данных. Но даже в этом случае небольшие запросы от крупных тенантов будут распараллеливаться чрезмерно, тогда как большие запросы от мелких тенантов — недостаточно! Такая система не годится — она слишком негибкая и требует постоянной подстройки.
Новый индекс Loki поддерживает и выборку индексов (index sampling), и динамическое шардирование (dynamic sharding).
Выборка индексов
Выборка индексов позволяет прикинуть объем данных до запроса — можно запрашивать топологию данных из одного только индекса, основываясь на новой статистике чанков, встроенной в сам индекс. Кроме того, есть новый эндпоинт API, который позволяет собирать кастомные инструменты!
Становится возможным сделать следующее:
{job="foo", env!="dev"} =>
{
"streams": 100,
"chunks": 1000,
"entries": 5000,
"bytes": 100000,
}Теперь фронтенд-компонент запросов определяет, сколько данных требуется каждому запросу для нахождения его оптимального коэффициента параллелизма. Запросы отрабатываются быстрее, формируются более гибко, не перегружают параллелизм квериера и не оставляют его недозагруженным.
Динамическое шардирование

Наша модифицированная TSDB также поддерживает динамическое шардирование. Раньше шард-фактор был жестко закодирован во внутреннюю структуру старого индекса. Поэтому приходилось либо обходиться без шардирования запросов, либо шардировать их с тем же фактором, который использовал индекс. TSDB же позволяет шардировать по степеням двойки — можно опуститься до ближайшего оптимального числа байтов на запрос.
Планирование
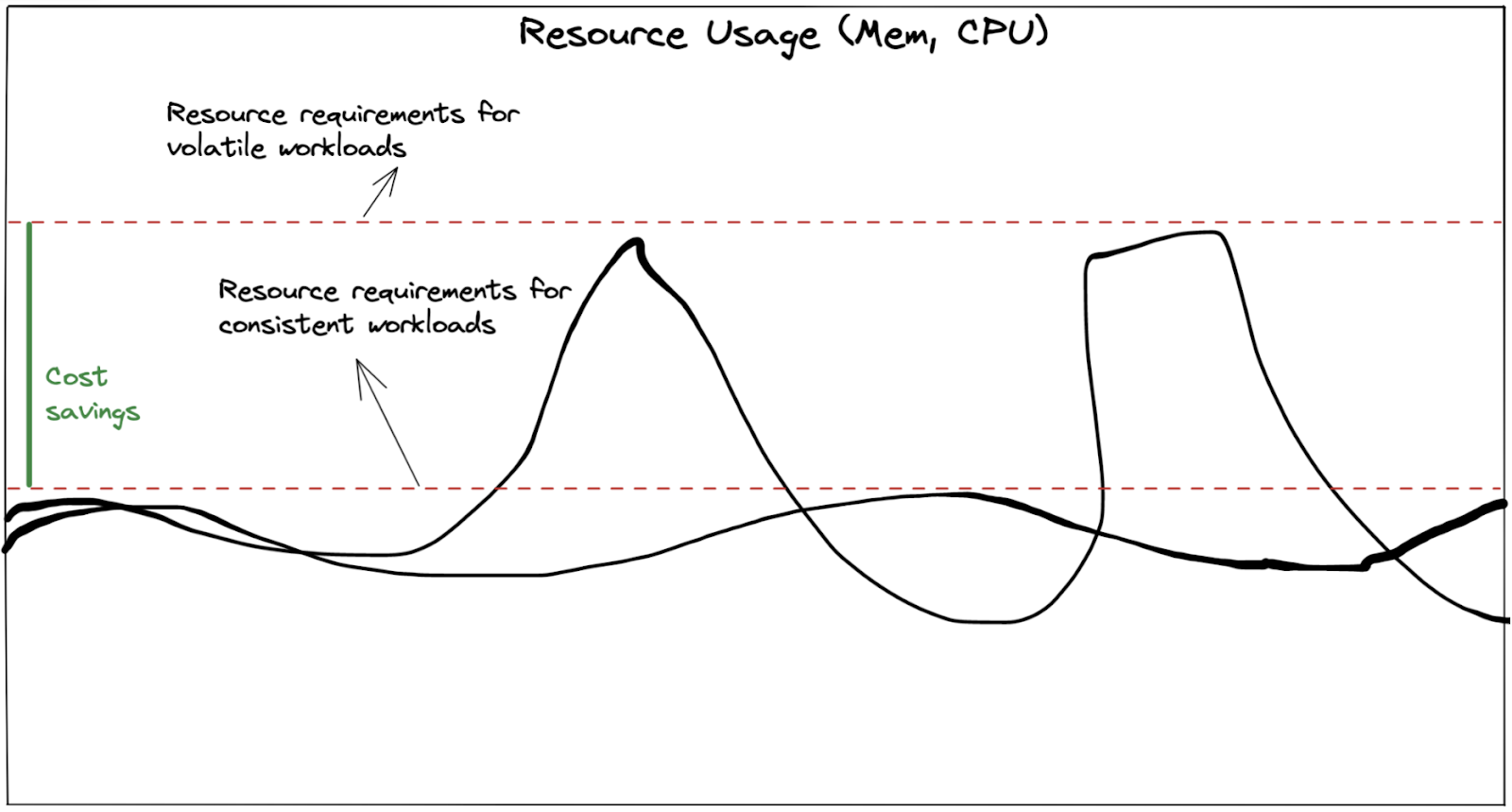
Такой метод планирования с гибким шардированием по степеням двойки имеет ряд преимуществ. Он позволяет добиться ранее недостижимой производительности запросов и, что более важно, лучше распределяет нагрузки. Если шардировать запрос на 16 частей независимо от размера данных, то небольшие запросы могут напрасно загрузить воркеры квериеров, а значит, потратить ресурсы впустую. И наоборот, большие запросы могут распараллеливаться недостаточно, а это серьезная проблема. Крупные запросы могут стать узким местом или привести к падению квериеров по ООМ из-за отправки им слишком больших объемов работы. Поэтому необходимо выделять квериерам ресурсы с запасом, чтобы те могли пережить периодические всплески нагрузки на память или процессор.
Меньшие, более стабильные подзапросы позволяют снизить TCO (Total Cost of Ownership) и улучшить SLO (Service Level Objective):
TCO: меньше запас ресурсов — это значит более экономичный режим работы с меньшим объемом нерационально используемых ресурсов;
SLO: меньше «запросов смерти» — стабильная нагрузка и меньше шансов вывести квериер из строя, а также «убить» по ООМ его соседа (когда на того будет перепланирован запрос) и т. д.
Структура TSDB
Этот раздел можно смело пропустить, если только не интересно, как работает наша TSDB и что в ней изменилось по сравнению с TSDB Prometheus.
В простейшем виде индекс TSDB хранит в бинарном формате набор серий, связанные с ними чанки и инвертированный индекс (в этом разделе о нем речь не идет, так как наши правки его не коснулись).
Серии
Таблица серий в TSDB хранит набор серий. В качестве идентификатора серии используется ее байтовое смещение в таблице серий. TSDB Prometheus сортирует их по набору лейблов лексикографически — у нас же они сортируются по хэшу набора лейблов (причины изложены ниже в разделе о шардинге).
Чанки
Каждая серия хранит список связанных с ней чанков. Используется массив ChunkMeta:
// Мета содержит информацию о чанке данных.
type ChunkMeta struct {
Checksum uint32
MinTime, MaxTime int64
// Число хранимых байтов, округленное до ближайшего КБ
KB uint32
Entries uint32
}Шардинг
TSDB Loki нативно поддерживает шардинг. Что это означает? Давайте посмотрим. Сначала цифры:
// фактор 2 работает 1/2 времени
Query_GetChunkRefsSharded/match_ns-2 33.9ms ± 1% 17.1ms ± 1% -49.66% (p=0.000 n=19+17)
// фактор 4 работает 1/4 времени
Query_GetChunkRefsSharded/match_ns-4 47.7ms ± 2% 11.8ms ± 3% -75.33% (p=0.000 n=20+19)
// фактор 8 работает 1/8 времени
Query_GetChunkRefsSharded/match_ns-8 72.3ms ± 2% 9.2ms ± 2% -87.34% (p=0.000 n=20+18)
// фактор 16 работает 1/16 времени
Query_GetChunkRefsSharded/match_ns-16 119ms ± 3% 7ms ± 1% -93.84% (p=0.000 n=18+20)
// фактор 32 работает 1/30 времени
Query_GetChunkRefsSharded/match_ns-32 212ms ± 1% 7ms ± 1% -96.64% (p=0.000 n=20+19)30 раз⁈ Правда⁈ Ладно, ладно, вы нас подловили! На самом деле мы ускорили запрос отдельного шарда данных в TSDB линейно-пропорционально выбранному размеру шарда. Обработка запросов по всем шардам занимает прежнее время. Кроме того, «30» — это не верхняя граница, а самый большой фактор шардинга, который применялся в данном случае.
Раньше, чтобы ограничить TSDB-запрос определенным шардом, необходимо было запросить весь индекс и отфильтровать все лишние шарды. Для фактора 16 это означало, что обрабатывалось в 16 раз больше данных, чем нужно, а затем все ненужные данные отбрасывались.
Как все это работает?
Членство
Для определения, к какому шарду принадлежит серия, использовался hash(labelset) % shard_factor. Этот подход работает, но отсортированный список хэшей не соответствует отсортированному списку шардов. Следующая таблица иллюстрирует соотношение хэшей и шардов (фактор 16):
хэш (base10) |
хэш (бинарный) |
шард |
0 |
0 |
0_of_16 |
5 |
101 |
5_of_16 |
16 |
10000 |
0_of_16 |
17 |
10001 |
1_of_16 |
Это означает, что для нахождения всех элементов с определенным шард-фактором нужно просканировать все значения и отфильтровать все результаты с несовместимыми шардами.
Вместо того чтобы использовать модуль, давайте воспользуемся битовыми префиксами. При факторе 2 все хэши, начинающиеся с бита 0, принадлежат первому шарду, а все хэши, начинающиеся с бита 1, — второму. Это работает для любой степени двойки, просто приходится проверять больше старших битов! Давайте вместо этого рассмотрим фактор 4:
бит-префикс |
шард |
00 |
0_of_4 |
01 |
1_of_4 |
10 |
2_of_4 |
11 |
3_of_4 |
Такой алгоритм позволяет получить отсортированный список хэшей, который соответствует отсортированному списку шардов для любого шард-фактора!
хэш (бинарный) |
шард (фактор 2) |
шард (фактор 4) |
000 |
0_of_2 |
0_of_4 |
010 |
0_of_2 |
1_of_4 |
100 |
1_of_2 |
2_of_4 |
101 |
1_of_2 |
2_of_4 |
110 |
1_of_2 |
3_of_4 |
111 |
1_of_2 |
3_of_4 |
С помощью двоичного поиска Loki теперь может быстро находить релевантную часть индекса и пропускать нерелевантные части:

Вот и всё!
Однако без нюансов не обошлось:
все шард-факторы должны быть степенью двойки;
итераторы по TSDB теперь возвращаются в порядке отпечатков, а не лексикографически.
Тем, кто хочет следить за развитием событий, рекомендуем обратиться к соответствующему issue.
Планы
Индексные запросы
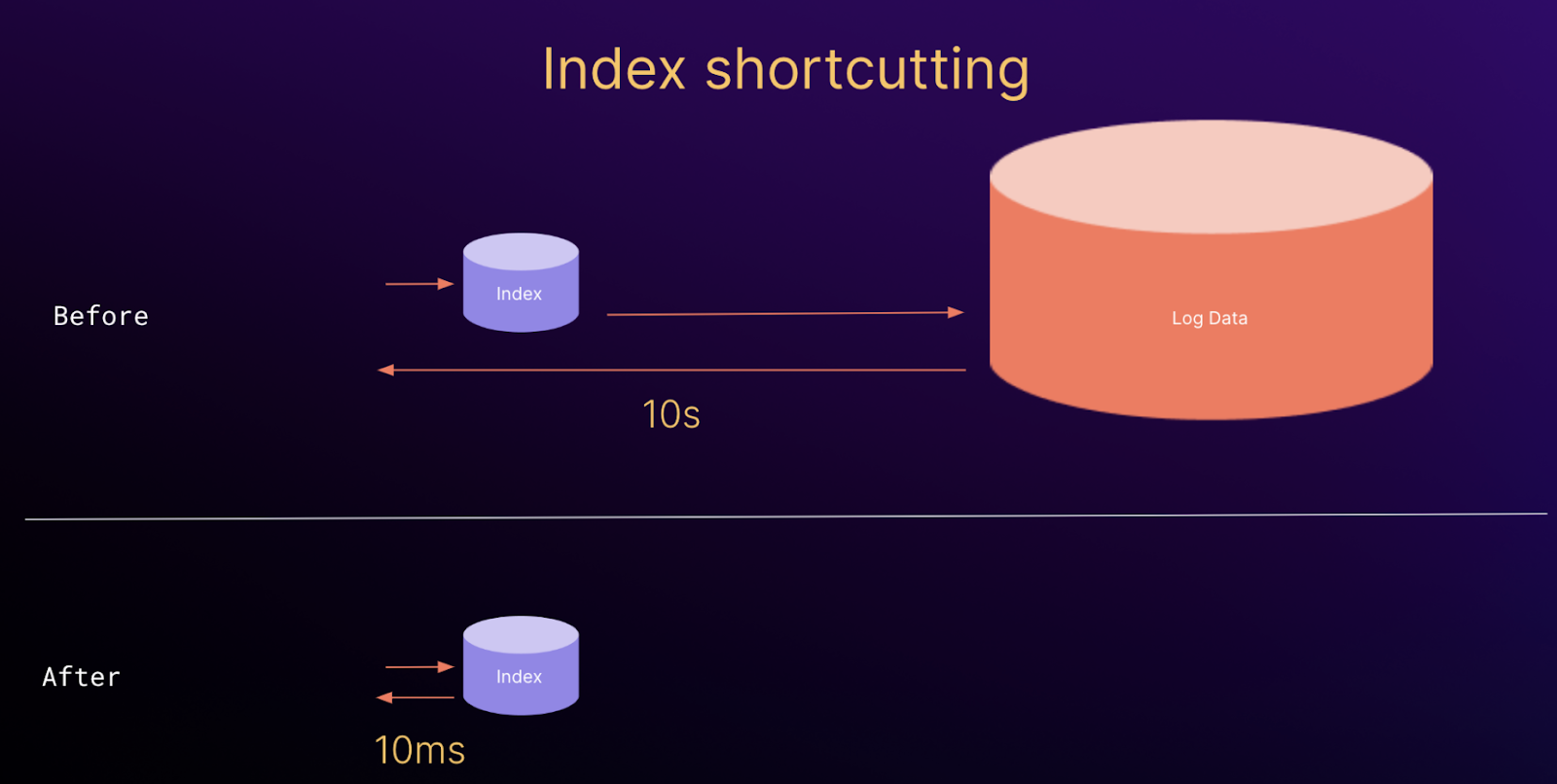
Данные чанков, встроенные в TSDB, открывают дорогу для дальнейших улучшений в запросах, которые выполняются только по индексам или с ускорением с омощью индексов. Эти запросы не требуют обращения к нижележащим данным лога и могут выполняться только с помощью статистической информации из индекса. Сейчас такой подход применяется для планирования запросов и для работы с эндпоинтом /series в новом индексе Loki, но есть и множество других возможных применений, в том числе:
получение информации о размере запроса перед его выполнением;
анализ потоков, пропускной способности и кардинальности;
мягкий даунгрейд больших запросов к индексным приближениям.
Эти усовершенствования увеличивают надежность работы с более высокой кардинальностью и байтовым масштабом путем повышения пропускной способности при выполнении запросов и оптимизации TCO.
P. S.
Читайте также в нашем блоге:
Экспорт метрик в Prometheus из логов PostgreSQL с помощью Vector
Подключаем VictoriaMetrics в Deckhouse и настраиваем уведомления в Telegram
Смотрите на нашем YouTube-канале: