
Довольно часто пользователи смотрят видео с субтитрами, и тому есть разные причины. Например, кто‑то хочет посмотреть видео там, где нужно соблюдать тишину или, наоборот, где слишком шумно. Или пользователь включает субтитры, когда ему непонятно, что говорит спикер. Для слабослышащих людей субтитры — это один из немногих способов ознакомиться с содержанием видеороликов.
Но чаще всего включить субтитры в видеоплеере сайта доступны, только когда владелец веб‑ресурса предусмотрел такую возможность. Яндекс Браузер решил эту проблему: он научился самостоятельно генерировать субтитры для видео на русском языке. Новая функция работает на любых сайтах: видеохостинги, социальные сети, страницы телеканалов. Также субтитры работают для роликов, которые доступны только после авторизации или загружены в облачные хранилища. Это стало возможным благодаря нейросети, встроенной в десктопную версию Браузера.
В этой статье я расскажу, как мы построили модель для генерации субтитров и на что нам пришлось пойти, чтобы она стала потреблять в 5 раз меньше оперативной памяти. А ещё поговорим про квантизацию свёрток и трансформеров и почему fp16 не так прост, как кажется.
Основные идеи алгоритма
Предсказание
С базовыми концепциями обработки звука с помощью нейросетей можно познакомиться в статье про командные споттеры. А ещё можно посмотреть доклад Петра Жижина и Степана Каргальцева о том, как работает CTC‑трансформер для распознавания речи.
За основу мы взяли архитектуру VGGTransformer и немного видоизменили её. Если кратко, то это transformer encoder со свёрточным фронтендом без позиционных эмбеддингов и transformer decoder. Свёрточный фронтенд помогает собрать локальные признаки, а также уменьшить размерность входа. В нашем случае мы уменьшили её в 4 раза (например, если 5 секунд — это 500 признаков, то до трансформера доходят 125).
 и свёрточный блок (справа)")
Но такую модель невозможно запустить на всём звуке сразу, потому что у нас и нет всего звука заранее. Да и вычислительно это дорого. Поэтому мы обучили нейросеть на блочное применение. Это когда предсказание работает с помощью скользящего окна со сдвигом. Мы выбрали окно в 5 секунд, а сдвиг — 600 мс (для простоты в схемах будем использовать 1 секунду). В итоге запись любой длины можно обработать как набор кусочков по 5 секунд (иногда неполных).
Для обучения на такое применение модифицируются маски attention-слоя, чтобы он не видел далеко назад (имитация ограниченного контекста).
Полученные кусочки можно склеить следующим образом:
Выровнять окна по времени, учитывая сдвиг.
Найти пересечение (общую часть) и его середину.
-
Всё, что по левую сторону, оставить, а остальное взять из свежих предсказаний.

Декодирование
На полученной последовательности из вероятностей идёт поиск лучшей гипотезы. В самом простом случае мы можем брать самый вероятный звук, однако качество выбора можно улучшить, используя алгоритм CTC Prefix Beam Search. Из текущих гипотез он генерирует комбинации с новыми наиболее вероятными звуками (токенами) и оставляет N лучших — в нашем случае 10. И так каждый шаг.

На гифке — пример для классического Beam Search из NLP, так как акустический гораздо сложнее визуализировать. Разница в том, что CTC Prefix Beam Search в нашей задаче оперирует гораздо бо́льшей последовательностью (3 секунды — это 75 шагов поиска, а 2 минуты — 3000) и смешивает скоры акустической и лингвистической моделей. Также из-за изменения хвоста логитов (картинка выше, из предыдущего раздела) нужно откатывать поиск назад и передекодировать изменённый хвост (из-за наличия только лингвистической модели в иллюстрации это нельзя показать в анимации).
Первый MVP комом
Написать MVP было не так сложно: похожий код есть в соседних сервисах, а значит, его можно было переиспользовать. Но мы приняли решение перейти на TF Lite — мобильный фреймворк от Google. Он хорошо поддерживается на всех платформах и обеспечивает соизмеримое время работы на каждой из них, а также оптимизирован под процессор. К сожалению, после этого перехода мы столкнулись с другой проблемой: модель потребляла слишком много памяти.
Внутри движка субтитров было ограничение: если аудио длится больше двух минут, то следующий двухминутный кусок будет обрабатываться с нуля. Такое решение изначально было принято для экономии памяти. Но когда мы заканчивали обрабатывать первые две минуты аудио, память уже съедала больше 800 Мб. На сервере это не проблема, но это абсолютно не подходит для обычных устройств. И особенно для такой маленькой модели, которая была у нас.
Три волны оптимизаций
Сокращаем время и поиск гипотезы
Наш взгляд сразу упал на накапливающиеся буферы: входные данные, вероятности токенов и ноды Beam Search.
Просто взять и оставлять только последние выходы нейросети мы не могли как раз из-за алгоритма поиска лучшей гипотезы: декодирование гипотезы требует полного контекста и декодирования от конца к началу. Но, по сути, если у всех гипотез есть общее начало, которое можно назвать общим префиксом, то мы можем один раз продекодировать его, сохранить и использовать в дальнейшем.
Но, к сожалению, общий префикс у гипотез может появляться достаточно далеко в прошлом, да и найти его — тоже нетривиальная задача. Кроме того, постоянно изменяющийся текст, где бы он ни был, ухудшал восприятие. Хотя чем дальше в прошлом текст, тем меньше вероятность, что он изменится.
Было решено выделять общий префикс в явном виде, а не ждать, когда он появится сам, и оставлять изменяемыми только последние секунды. Для этого в момент передекодирования последних логитов (когда отрезаем хвост поиска) мы оставляем единственный узел из самой вероятной гипотезы, в котором также храним результат декодирования всего префикса. Раз узел единственный, то он есть во всех гипотезах, а это значит, что там и хранится общий префикс. А из-за того, что результат в нём уже продекодирован, новый поиск будет смотреть на последние 2–3 секунды вместо всей записи на 120 секунд.
Вот так происходит декодирование с сохранением общего префикса и передекодированием последних логитов (по аналогии с классическим Beam Search):

Это решение позволило оставить буферы длиной пару секунд, а не несколько минут. А ещё мы бонусом получаем неизменяемую часть текста, что помогает восприятию, рендеру и общению между процессами (можно передавать только обновление фиксированной части, а изменяемую — полностью).
Это должно было сохранить более 400 Мб, но дьявол кроется в деталях.
Исследуем потребление памяти
Дальнейший поиск узких мест был достаточно проблематичен, поэтому настало время обратиться к старому другу — heaptrack. Это профайлер памяти, который позволяет оценить её потребление в разных частях программы. Он помогает находить узкие места и оптимизировать именно их.
Примеры анализа памяти до и после преобразования Beam Search. Он содержит как общую статистику...
total runtime: 102.03s.
calls to allocation functions: 232764 (2281/s)
temporary memory allocations: 24150 (236/s)
peak heap memory consumption: 810.25M [-> 221.11M v1]
peak RSS (including heaptrack overhead): 802.50M [-> 381.08M v1]
total memory leaked: 227.20K… так и с разбиением по вызовам функций со стектрейсом.
PEAK MEMORY CONSUMERS
527.04M [-> 71.19M v1] peak memory consumed over 154468 calls from
void* std::__y1::__libcpp_operator_new<>(unsigned long)
at /-S/contrib/libs/cxxsupp/libcxx/include/new:245
in /home/ntsuranov/.ya/build/symres/e8b5027c8cb16a18e963627811a6f37d/cli
std::__y1::__libcpp_allocate(unsigned long, unsigned long)
at /-S/contrib/libs/cxxsupp/libcxx/include/new:271
std::__y1::allocator<>::allocate(unsigned long)
at /-S/contrib/libs/cxxsupp/libcxx/include/__memory/allocator.h:105
std::__y1::allocator_traits<>::allocate(std::__y1::allocator<>&, uint32_t)
at /-S/contrib/libs/cxxsupp/libcxx/include/__memory/allocator_traits.h:262
std::__y1::__split_buffer<>::__split_buffer(uint32_t, uint32_t, std::__y1::allocator<>&)
at /-S/contrib/libs/cxxsupp/libcxx/include/__split_buffer:322
void std::__y1::vector<>::__push_back_slow_path<>(std::__y1::pair<>&&)
at /-S/contrib/libs/cxxsupp/libcxx/include/vector:1570
std::__y1::vector<>::push_back(std::__y1::pair<>&&)
at /-S/contrib/libs/cxxsupp/libcxx/include/vector:1602
. . . . . . . . . . . . . . . . . . . . . . . .
16.80M [-> 33.58M v1] [-> 1.77M v2] consumed over 1 calls from:
TMemoryPool::AddChunk(unsigned long)
at /-S/util/memory/pool.cpp:18
in /home/ntsuranov/.ya/build/symres/e8b5027c8cb16a18e963627811a6f37d/cli
TMemoryPool::RawAllocate(unsigned long, unsigned long)
at /-S/util/memory/pool.h:287
in /home/ntsuranov/.ya/build/symres/e8b5027c8cb16a18e963627811a6f37d/cli
TMemoryPool::Allocate(unsigned long, unsigned long)
at /-S/util/memory/pool.h:155Итак, почему же фиксирование префикса и последующая обрезка всех буферов (v1) не помогли настолько, насколько ожидалось?
С помощью Heaptrack мы нашли ответ на этот вопрос: оказывается, у нас были неочевидные серверные оптимизации, которые раздували память в обмен на ускорение большого количества вычислений.
Одной из них как раз была оптимизация Beam Search. Память аллоцировалась большими кусками, и очистка происходила только в деструкторе, а из-за дополнительных операций сохранения выделялся следующий большой кусок памяти. То есть у нас не происходил полноценный сброс буфера при сохранении префикса.
Когда есть большая задача по сокращению потребления памяти, важен каждый мегабайт. Ухудшение ещё на 16 Мб было недопустимо и отодвигало заветную цель. После уменьшения буферов для декодирования и проведения полноценной очистки (v2) экономия стала ещё заметнее.
Уменьшением всех описанных буферов, отключением оптимизаций для большого сервера и очисткой памяти на заморозке префикса мы выиграли 450 Мб памяти. Из-за такой оптимизации мы были готовы потерять немного качества, но по нашим метрикам оно даже незначительно выросло.
Меняем архитектуру сети
TF Lite и fp16
В нашем алгоритме мы использовали модели в fp16 (числа с плавающей запятой половинной точности). Мы полагали, что за счёт этого мы должны улучшить показатели памяти и времени. Реальность оказалась суровее: CPU-делегаты (бэкенды) TF Lite не поддерживают fp16-инференс, хотя и умеют работать с такими моделями. Внутри они распаковывают fp16 в fp32, что только увеличивает потребление памяти в 1,5–2 раза. Поэтому нам пришлось отказаться в пользу fp32, пожертвовав местом на диске: модель стала занимать не 50, а 100 Мб.
Разделение архитектуры
Как я писал выше, наша архитектура состоит из двух очень разных частей: свёрточной и трансформеной. Они обладают очень разными свойствами, и почему бы этим не воспользоваться в целях оптимизации.
Мы решили разделить нашу модель на две независимые части. Трансформер смотрит на все данные сразу, поэтому здесь мы оставили всё как есть. А вот у свёрток очень ограниченный контекст. В нашем случае значение receptive field всего 16, что эквивалентно 160 мс, а значит, нет смысла пересчитывать все 5 секунд — можно перевести свёртки в стриминговый режим. То есть мы можем считать свёртки не на окне, а только на новых данных с небольшим пересечением. Это сокращает размер входа с 500 фреймов до 76 (600 мс сдвиг окна + 16 receptive field), что экономит и память, и время.
На этом моменте мы получаем ускорение свёрток больше чем в 5 раз и экономию оперативной памяти больше чем в 3 раза (30 Мб → 8 Мб). Также это положительно сказалось на качестве, потому что у свёрток больше не было швов на границах окон.

К сожалению, для дальнейших улучшений памяти нам пришлось пожертвовать скоростью.
Сравнение разных TF Lite-делегатов
В ходе экспериментов стало видно, что оптимизированный бэкенд (XnnPack) потребляет в среднем в 1,5–2 раза больше памяти. В итоге мы решили отказаться от него ценой потери производительности (110 мс → 150 мс и один поток), но с приличным выигрышем по памяти.
Но с инференсом в полной точности нужно что-то делать, потому что 100 Мб на диске и в памяти — это очень много.
Время квантизации
Квантизация — это подход, при котором веса нейросети конвертируются из fp32 (4 байта) в int8 (1 байт). Обычно этой точности достаточно для применения с небольшим ухудшением по качеству.
Есть два подхода:
Статическая квантизация. Конвертируются и веса, и активации. На этапе конвертации на репрезентативном датасете считаются все статистики (скейл и сдвиг), позволяющие сжать диапазон значений в [0, 255] с минимальными потерями. Время инференса и потребление памяти — лучше, но это сложнее, а потери качества — больше.
Динамическая квантизация. Во время конвертации квантизуются только веса и не нужен репрезентативный датасет. Скейл для активаций подбирается в рантайме, что позволяет сохранить больше точности. Улучшает потребление памяти, но немного замедляет, с меньшими потерями.
Мы поняли, что для решения нашей задачи будет достаточно частичной динамической квантизации. Почему частичной? Основной вычислительный слой у трансформера — полносвязный (простое перемножение матриц). Если квантизовать только такие слои, а остальные оставить неизменными (в fp32), то можно получить 95% теоретического профита без попыток конвертировать сложные для квантизации слои, такие как softmax. Также динамическая квантизация не требует ни дообучения, ни датасета.
Вдобавок хотелось использовать не per-tensor-квантизацию (один скейл на все веса), а per-channel (у каждого канала свой). К сожалению, TF Lite не умеет в per-channel (PC) квантизацию для fullyconnected слоёв (FC), поэтому мы своими руками нормализовали веса, а после денормализовывали выходы с помощью предпросчитанных коэффициентов.
Это позволило сохранить качество, а потери главной метрики Edit Distance были незначительны. Правда, таким манёвром мы получили просадку скорости — со 150 до 330 мс. Но она всё ещё укладывалась в реал-тайм.
Свёртки мы оставили без квантизации, но перевели в честный fp32. На диске и в памяти они занимали достаточно мало места, а значит, больше не были проблемой, после отделения.
Но и на этом мы не остановились. В экспериментах нашлось неожиданное ускорение: TF Lite легко конвертирует свёртки сразу с PC-квантизацией, а значит, можно заменить самописный FC на свёртку 1×1. Эти операции абсолютно эквивалентны, но так можно получить поканальную квантизацию из коробки и заменить четыре операции на одну. Такое преобразование дало ускорение в среднем в 1,5 раза на всех платформах.
Сравнительные результаты:
Setup, TF Lite 2.12, Linux |
RAM, mB |
Inference, ms |
Drive space, mB |
XNNPack delegate, fp16 conv + fp16 transformer |
300 |
110 |
50 |
XNNPack delegate, fp32 conv + fp32 transformer |
250 |
110 |
100 |
fp16 conv + fp16 transformer |
214 |
150 |
50 |
fp32 conv + fp32 transformer |
165 |
150 |
100 |
fp32 conv + dynamic int8 FC PC transformer |
56 |
330 |
25 |
fp32 conv + dynamic int8 conv2d PC transformer |
60 |
200 |
25 |
Бонус: 3 секунды в будущее
Несмотря на все оптимизации, у нас было над чем ещё поработать. Дело в том, что при работе модели у нас были небольшое отставание от звука в видео и меняющийся текст — выглядело это не очень хорошо. Такое происходило из-за того, что у нашей модели есть изменяемые 2 последние секунды, и к тому же мы ждали, пока соберётся окно в 600 мс.
Но ребята из команды Браузера тоже не сидели сложа руки и сделали буфер в будущее. То есть сам Браузер декодирует звук из видео на 3 секунды вперёд, что позволяет скрыть задержку нашей модели и меняющийся текст без дополнительных затрат.
Что в итоге
Оптимизация буферов (450+ Мб) и моделей (200+ Мб) позволили дойти до целевой отметки 150 Мб. Другими словами, наш процесс стал потреблять меньше памяти примерно в 5 раз. Ещё нам удалось значительно уменьшить место на диске, которое занимала модель. При этом мы оставили realtime-on-device-инференс с обновлением раз в 600 мс в одном потоке.
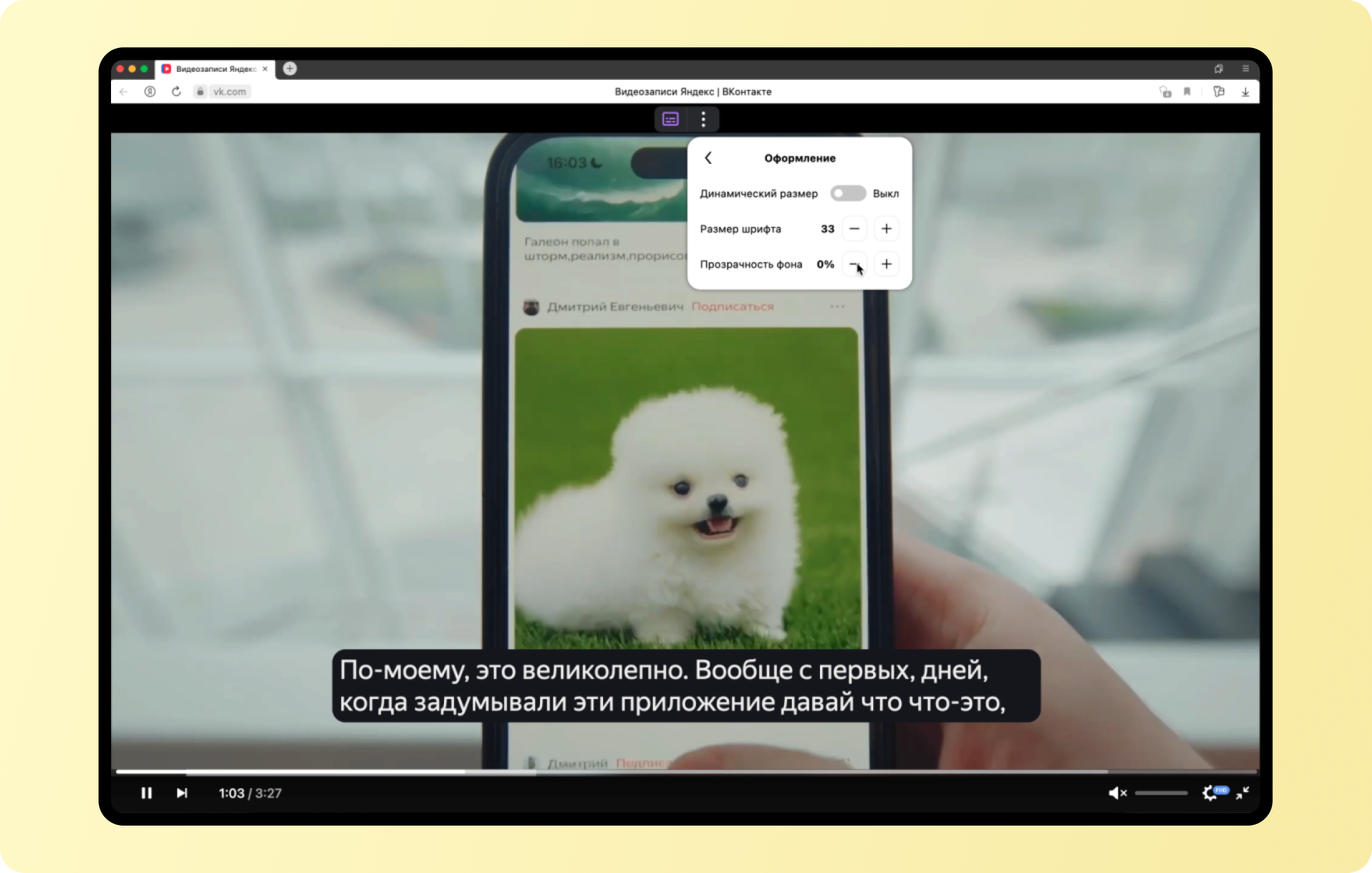
Генерация субтитров работает в десктопном Яндекс Браузере для Windows и Linux. В macOS новая функция появится до конца сентября. Чтобы включить субтитры, нажмите на кнопку в окне с видео — она вверху. В настройках можно выбрать размер шрифта и изменить прозрачность фона, чтобы субтитры не сливались с изображением на заднем плане.
Пока Яндекс Браузер генерирует субтитры только для видео и стримов на русском, но мы уже работаем над тем, чтобы добавить больше языков. А ещё мы хотим оптимизировать эту модель для мобильной версии Браузера, учитывая тот факт, что железо в телефонах не такое мощное, как в компьютерах.
Комментарии (15)

Kristaller486
15.09.2023 07:05+1А есть какие-нибудь сравнения с другими моделями, типа whisper?

N1kSt4r Автор
15.09.2023 07:05+1Whisper и большая часть текущих SOTA моделей совершенно не влазят в наши ограничения по drive / ram, так еще и не приспособлены к стриминговому режиму работы, а это один из наиболее важных критериев для нас из-за длины записей.
Плюс почти все такие бейслайны хорошо работают на английском, но далеко не на русском.Kristaller486
15.09.2023 07:05Про ограничения понимаю, мне скорее интересно про точность.
N1kSt4r Автор
15.09.2023 07:05+3Да, я понимаю.
Просто точность может зависеть от домена и датасета, поэтому с большими моделями без обучения на наших датасетах сравнение не валидно.
Если сравнивать с моделью перевода видео, то у нас отставание на 10-15% (относительные) по WER на нашем русском датасете.

Zara6502
15.09.2023 07:05-2Довольно часто пользователи смотрят видео с субтитрами, и тому есть разные причины
Не смотрю, потому что тогда видео длинной в час я буду смотреть часа 3-4. Как только в ЯБ появился перевод в ютубе - стал им пользоваться.
Например, кто‑то хочет посмотреть видео там, где нужно соблюдать тишину или, наоборот, где слишком шумно
Странная причина, для этого есть наушники.
Яндекс Браузер решил эту проблему
Меня бы больше заинтересовало приложение для андроида, которое озвучивало бы потоковые сервисы через себя. Сейчас ЯБ ставить нужно и запускать внутри браузера видео чтобы получить доступ к переводу, а на ТВ и телефоне это неудобно делать. Для монетизации сервиса его бы можно было внедрить в Кинопоиск по подписке Плюс.

dimnsk
15.09.2023 07:05+3Вы скажите не к вам, но... мне кажется, вы этими плюшками не затянете пользоваться очень-очень назойливым браузером который лезет в систему и пользователю куда его совсем не просят!
Помните IE 15 лет назад?
частный кейс: слушаю видео и закрываю
s207883
15.09.2023 07:05Видел варианты, по прикручиванию перевода от Яндекса к любым други браузерам.

farrow
15.09.2023 07:05+1Было бы здорово добавить и английские субтитры. Когда увидел заголовок, то сразу подумал об использовании для учебы: смотреть без субтитров, где нужно — включать английские, а для новых слов — английские субтитры менять на русские.
N1kSt4r Автор
15.09.2023 07:05+2Английские субтитры в браузере уже есть на YouTube и Coursera, где работает функция перевода видео с иностранных языков. Субтитры интерактивные - по клику на незнакомое слово браузер покажет его перевод.
Субтитры будут доступны сразу, если видео раньше было переведено другим пользователем. Если интерактивных субтитров нет, нужно сначала перевести видео - тогда появятся и субтитры. При этом вы сможете слушать ролик в оригинале и читать субтитры на английском (фича работает для 6 языков).
Если говорить о создании английских субтитров для любого видео в интернете по технологии, которая описана в этой статье, - у нас есть такая идея, но о сроках пока говорить рано


lexmirnov
15.09.2023 07:05Спасибо, полезная вещь. Ещё пригодился бы функционал выгрузки субтитров в текстовый файл, раз уж они есть.
(Тестирую — к публичному видео, выложенному на облако Mail.ru, не генерирует, пишет «недоступны»).

dimnsk
15.09.2023 07:05аа еще очень важный момент
RLHF ?
когда модель будет дообучаться? прикрутить отзывы или что-то типа фидбэка
устал уже слушать
перевод first - первый, а не сначала,
github - джитаб
chatgpt -чет-чтото там гэпэте
серьезно? год уже нарицательному имени...


Orngali65
15.09.2023 07:05Что-то это работает только на канале youtube. Пробовал проделать в одноклассниках не сработало.

BarakAdama
15.09.2023 07:05Точно ли последняя версия Браузера (можно в меню в «О браузере» проверить обновления)? Если да, то можно ещё разок перезапустить и проверить.
Sarjin
насколько сложно сделать перевод на выбранный язык с голосами используемыми в видео?
N1kSt4r Автор
Клонирование голоса сложно сделать, тем более локально. Моя статья в первую очередь про распознавание речи на устройстве пользователя, когда язык субтитров совпадает с языком видео. Я говорю только про генерацию текста.
Но команда перевода видео исследует эту задачу