
В этой статье я хочу поделиться некоторыми наработками, которые мы используем в своих проектах, в частности, тем, как отправлять и обрабатывать HTTP-запросы непосредственно из/в PostgreSQL.
Сразу оговорюсь, Вам не придется устанавливать в базу данных дополнительные расширения и вызывать функции, написанные на отличном от PL/pgSQL языке программирования. Более того, все запросы будут выполняться асинхронно, а обработка полученных данных будет происходить через функции обратного вызова.
Pgweb
Для демонстрации понадобится предварительно настроенная база данных, доступ к которой можно получить или на нашем сайте по адресу https://apostoldevel.com/pgweb, или локально, запустив Docker контейнер.
При переходе по ссылке откроется pgweb - веб-обозреватель для PostgreSQL. В pgweb можно выполнять SQL-запросы, которые будут приведены ниже, а также ознакомиться с содержимым таблиц и программным кодом функций, написанных на PL/pgSQL.
Docker
Скачиваем образ Docker:
docker pull apostoldevel/apostol
Запускаем:
docker run -p 8080:8080 -p 8081:8081 -p 5433:5432 --name apostol apostoldevel/apostol
Ждём, когда контейнер загрузится, и открываем pgweb по ссылке http://localhost:8081 в браузере.
Теперь у нас есть всё необходимое для того, чтобы выполнить HTTP-запрос непосредственно из PostgreSQL.
Вместо pgweb можно использовать любой другой инструмент для работы с базами данных. PostgreSQL из контейнера будет доступен на порту 5433.
HTTP клиент
В качестве первого примера выполним HTTP-запрос к самому себе (внутри локального хоста):
SELECT http.fetch('http://localhost:8080/api/v1/time', content => null::text);
Выполнение HTTP-запроса будет происходить асинхронно, поэтому в ответ мы получим не данные HTTP-запроса, а uuid идентификатор.
Исходящие HTTP-запросы будут записаны в таблицу http.request, а результат выполнения HTTP-запроса будет сохранён в таблице http.response.
Для просмотра исходящих HTTP-запросов и полученных на них ответов воспользуемся представлением http.fetch:
SELECT * FROM http.fetch ORDER BY datestart DESC;
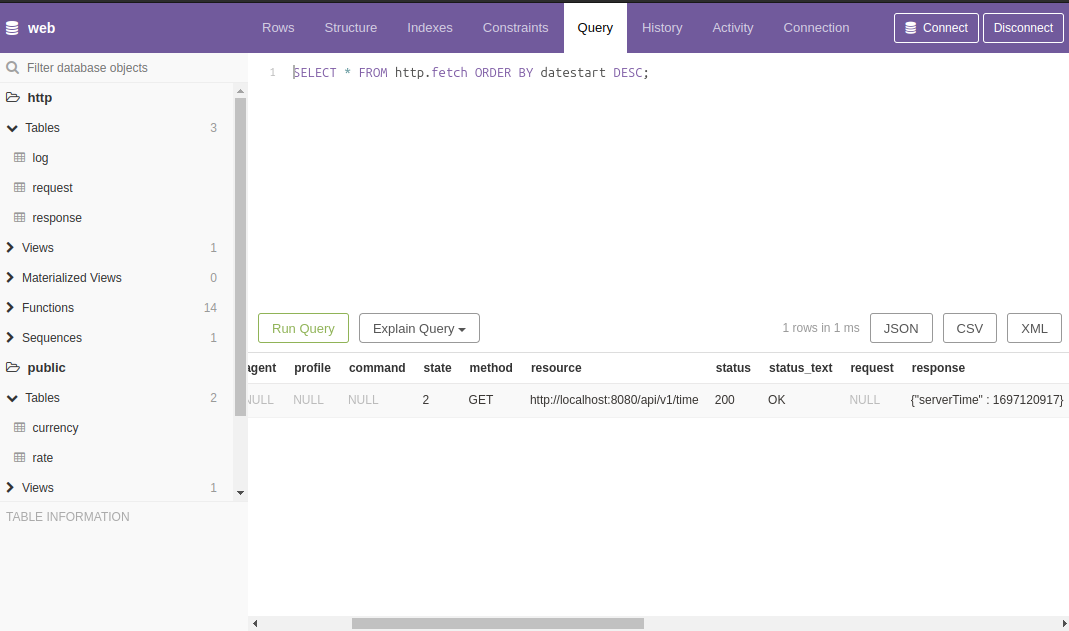
В поле status будет код HTTP-ответа (HTTP response status codes) на наш HTTP-запрос, а в поле response - ответ.
В качестве следующего примера запросим данные с JSONPlaceholder:
SELECT http.fetch('https://jsonplaceholder.typicode.com/posts/1', 'GET', content => null::text, type => 'curl');
И в поле response представления http.fetch обнаружим:
{
"userId": 1,
"id": 1,
"title": "delectus aut autem",
"completed": false
}
Здесь дополнительно указан тип
curl, данный параметр необходим для запросов к серверам, которые поддерживают только HTTP/2 протокол (выполнение таких запросов происходит через библиотеку cURL).
HTTP сервер
Входящие HTTP-запросы фиксируются в таблице http.log:
SELECT * FROM http.log ORDER BY id DESC;

Для обработки входящих HTTP-запросов в нашем распоряжении есть две PL/pgSQL функции http.get и http.post.
В качестве входящих параметров они принимают:
path- Путь;headers- HTTP заголовки;params- Строка запроса (query string), преобразованная в формат JSON;body- Тело запроса, если это POST запрос.
В качестве ответа функции возвращают множество (SETOF) json строк.
Возвращаемое значение в виде множества позволяет нам более эффективно работать с данными, обрабатывая каждую строку в отдельности. Подробнее тут.
Пример кода из http.get:
WHEN 'log' THEN
FOR r IN SELECT * FROM http.log ORDER BY id DESC
LOOP
RETURN NEXT row_to_json(r);
END LOOP;
Задействовать приведённый выше код можно так:
SELECT http.fetch('http://localhost:8080/api/v1/log', content => null::text);
Функции обратного вызова
В начале статьи я упомянул, что обработка полученных данных будет происходить через функции обратного вызова.
Для лучшего понимания того, как это будет происходить, давайте решим конкретную задачу, например, получение курсов валют с разбором полученного ответа и сохранением данных в таблицу курсов.
Чтобы было понятно, как это работает в связке с HTTP-сервером, я добавил в функцию http.get следующий код:
WHEN 'latest' THEN
FOR r IN SELECT * FROM jsonb_to_record(params) AS x(base text, symbols text)
LOOP
IF r.base = 'USD' THEN
RETURN NEXT jsonb_build_object('success', true, 'timestamp', trunc(extract(EPOCH FROM Now())), 'base', r.base, 'date', to_char(Now(), 'YYYY-MM-DD'), 'rates', jsonb_build_object('RUB', 96.245026, 'EUR', 0.946739, 'BTC', 0.000038));
ELSIF r.base = 'BTC' THEN
RETURN NEXT jsonb_build_object('success', true, 'timestamp', trunc(extract(EPOCH FROM Now())), 'base', r.base, 'date', to_char(Now(), 'YYYY-MM-DD'), 'rates', jsonb_build_object('RUB', 2542803.2, 'EUR', 25012.95, 'USD', 26420.1));
ELSE
RETURN NEXT jsonb_build_object('success', false, jsonb_build_object('code', 400, 'message', format('Base "%s" not supported.', r.base)));
END IF;
END LOOP;
На запрос «самых последних» (latest) курсов мы будем возвращать статические данные в формате API курсов валют. Если у Вас есть доступ к службам курсов валют, Вы можете запросить данные через их API.
Обрабатывать полученные данные мы будем с помощью функции обратного вызова public.exchange_rate_done, с программным кодом которой можно ознакомиться в pgweb, а сами запросы будут следующими:
Из контейнера:
SELECT http.fetch('http://localhost:8080/api/v1/latest?base=USD', 'GET', null, null, 'public.exchange_rate_done', 'public.exchange_rate_fail', 'api.exchangerate.host', null, 'latest');
SELECT http.fetch('http://localhost:8080/api/v1/latest?base=BTC', 'GET', null, null, 'public.exchange_rate_done', 'public.exchange_rate_fail', 'api.exchangerate.host', null, 'latest');
Через наш сервер:
SELECT http.fetch('https://apostoldevel.com/api/v1/latest?base=USD', 'GET', null, null, 'public.exchange_rate_done', 'public.exchange_rate_fail', 'api.exchangerate.host', null, 'latest');
SELECT http.fetch('https://apostoldevel.com/api/v1/latest?base=BTC', 'GET', null, null, 'public.exchange_rate_done', 'public.exchange_rate_fail', 'api.exchangerate.host', null, 'latest');
Через службу курсов валют (при наличии доступа):
SELECT http.fetch('https://api.exchangerate.host/latest?base=USD&symbols=BTC,EUR,RUB', 'GET', null, null, 'public.exchange_rate_done', 'public.exchange_rate_fail', 'api.exchangerate.host', null, 'latest', null, 'curl');
SELECT http.fetch('https://api.exchangerate.host/latest?base=BTC&symbols=USD,EUR,RUB', 'GET', null, null, 'public.exchange_rate_done', 'public.exchange_rate_fail', 'api.exchangerate.host', null, 'latest', null, 'curl');
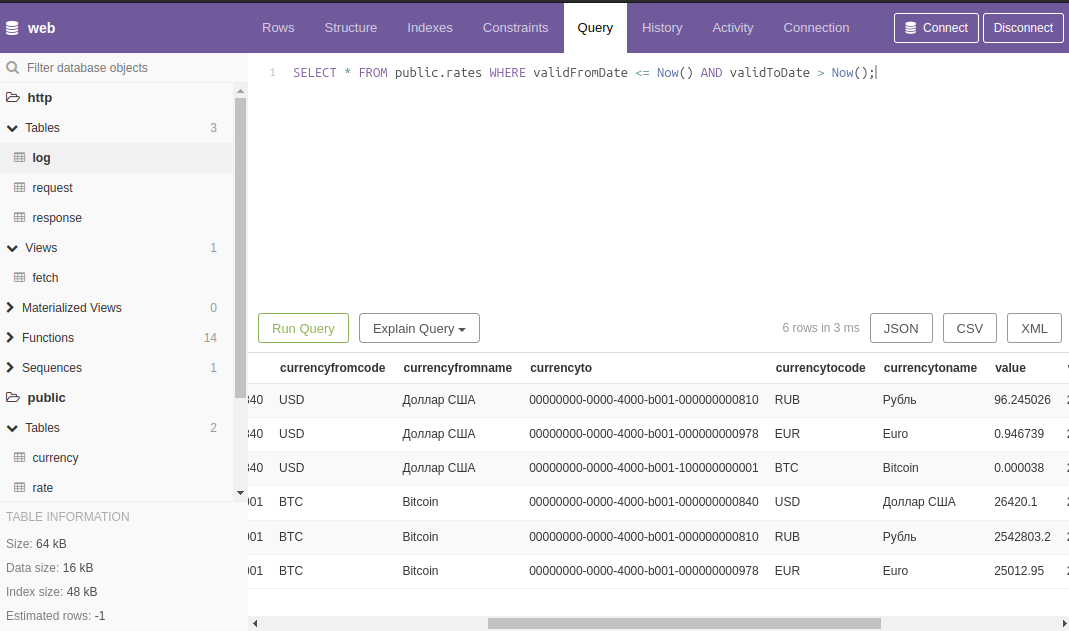
Результатом этих действий станет заполненная данными таблица public.rate.
Посмотреть актуальные на данный момент курсы можно через представление public.rates:
SELECT * FROM public.rates WHERE validFromDate <= Now() AND validToDate > Now();
Асинхронное уведомление
Прежде чем подробно разобрать, как же это всё работает, обратимся к документации PostgreSQL:
34.9. Асинхронное уведомление
PostgreSQL предлагает асинхронное уведомление посредством команд
LISTENиNOTIFY. Клиентский сеанс работы регистрирует свою заинтересованность в конкретном канале уведомлений с помощью командыLISTEN(и может остановить прослушивание с помощью командыUNLISTEN). Все сеансы, прослушивающие конкретный канал, будут уведомляться в асинхронном режиме, когда в рамках любого сеанса командаNOTIFYвыполняется с параметром, указывающим имя этого канала. Для передачи дополнительных данных прослушивающим сеансам может использоваться строкаpayload.
Как Вы уже, наверное, догадались, именно этот механизм лежит в основе взаимодействия PostgreSQL с неким клиентским приложением, но не будем забегать вперёд.
Подробно
Рассмотрим более подробно, что происходит на стороне PostgreSQL после вызова функции http.fetch:
PL/pgSQL функция http.fetch является оберткой для функции http.create_request, в которой происходит запись в таблицу http.request с последующим вызовом команды NOTIFY через триггер добавления новой записи. На этом, собственно, всё.
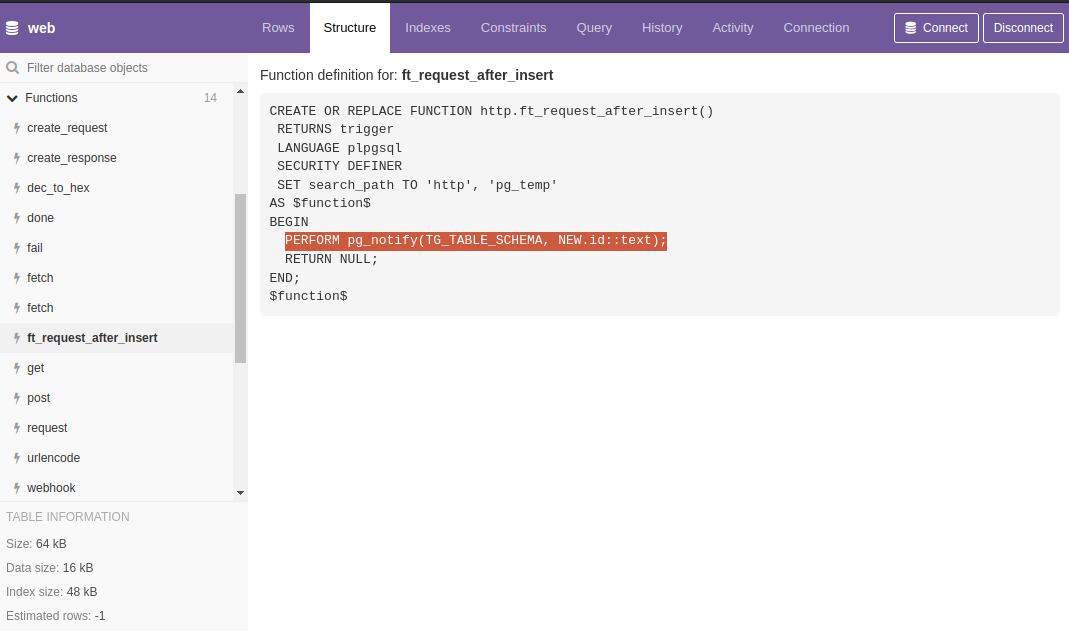
Далее в ход вступает некое клиентское приложение, которое подключено к PostgreSQL и готово принимать асинхронные уведомления, и именно оно выступает в качестве HTTP-клиента и сервера, отправляет HTTP-запрос и сохраняет результат в таблицу http.response.
Клиентское приложение
Клиентское приложение — отдельная программа, в задачу которой входит по сигналу от сервера выполнять те или иные действия, в данном случае выполнять HTTP-запросы на основе тех данных, которые содержатся в таблице http.request.
Если Вы или Ваша команда достаточно опытны, то разработать подобное приложение не должно составить труда. Мы же используем свою собственную open source разработку — Апостол.
Заключение
Я продемонстрировал простой в использовании, но в то же время очень гибкий механизм коммуникации с внешними системами непосредственно из PostgreSQL.
Если говорить о практическом применении, то представьте, что в вашей системе формируется счёт на оплату, по которому должно произойти автоматическое списание денег с заранее привязанной карты клиента. Все необходимые данные для реализации этой задачи находятся в базе данных. Следовательно, то приложение (микросервис), которое будет взаимодействовать с платежной системой, должно быть подключено к базе данных и каким-то образом оповещено о наличии нового счета. Приложение должно получить необходимые данные, обработать их, сформировать запрос к платежной системе, сохранить результат в БД. После успешного списания необходимо сформировать электронный чек, а это уже взаимодействие с другим сервисом, а ещё было бы неплохо уведомить клиента по e-mail, в виде СМС или через мобильное приложение (FCM) о наличии счёта и статусе выполнения операции.
Иными словами, мы получаем каскад задач на взаимодействие с внешними системами через их API, при этом оперируя теми данными, которые находятся в СУБД.
Так если данные в СУБД и у нас есть механизм коммуникации с внешними системами из PostgreSQL, то почему бы не формировать запросы к API внешних систем в той же среде, где и данные? Вопрос риторический.
Приведённый выше пример не из разряда теоретических выкладок, а вполне практическая и рабочая реализация.
Если нужен более наглядный пример, то вот: Talking to AI это чат-бот в Telegram для общения с искусственным интеллектом (ChatGPT), который реализован на PL/pgSQL.
Есть пример Telegram бота на PL/pgSQL с исходным кодом, ссылка ниже.
Ссылки на исходные коды:
Комментарии (57)

Rive
14.10.2023 10:31По духу похоже на встроенный вебсервер в TarantoolDB.
Может быть перспективно для увеличения быстродействия.

apostoldevel Автор
14.10.2023 10:31Спасибо!
Да, именно ради совмещения роли базы данных и сервера приложений всё и задумывалось (вопреки устоявшемуся мнению, что так делать нельзя).
Цитата с их сайта:
Поскольку код и база данных находятся в одном адресном пространстве, то приложениям не нужно ходить по сети, а значит, вы избегаете latency — задержки в исполнении операций.
Лучше и не скажешь. Только вместо Lua PL/pgSQL.

hVostt
14.10.2023 10:31+2Так делать не нельзя, так делать неудобно. О, смотрите, есть библиотека, которая приложение на Python/Java/Go/.NET превращает в БД, зачем нам теперь СУБД? :) Я помню времена приложений, построенных на СУБД, и это были времена тёмные и беспощадные. Очередной виток, с разработкой приложений и логики в БД, к которому возвращаться бы не хотелось. До сих пор из легаси систем выковыриваем логику из БД в приложения. Да, оно работает, да оно работает быстро, но на этом преимущества заканчиваются, начинаются проблемы. Понимаю, вопрос до сих пор спорный и дискуссионный, но хороший инструмент должен решать одну задачу и решать её максимально хорошо. Комбайны, не наш путь.
apostoldevel Автор
14.10.2023 10:31О! Я ждал этого «Так делать нельзя», бизнес логику в БД хранит нельзя :).
Казалось бы задумка простая: HTTP сервер (который на node.js можно реализовать в пару строк кода) принимает запрос и вызывает get или post функцию в СУБД для дальнейшей обработки. Звучит дико, согласен :). Тогда ради чего всё это?
Вся проблема, тех систем где пришли к выводу, что так делать нельзя в способе взаимодействия с СУБД.
Попытаюсь объяснить на примере кода: https://github.com/ufocomp/libdelphi/blob/425e39472f76e6a3602d1f61adc955b4fd6f1a34/src/Sockets.cpp#L4422C54-L4422C54 — это основной цикл обработки событий (event loop). В этом месте операционная система передаёт управление программе в тот момент когда данные поступили на Socket. В том или ином виде он (цикл) есть у всех приложений, в том числе и упомянутых Вами Python/Java/Go/.NET, но все эти приложения разработаны таким образом, что они изолированны от СУБД.
На низком уровне взаимодействие с PostgreSQL происходит тоже через Socket. Так вот у нас есть сокеты по которым поступают HTTP-запросы и у нас есть сокеты от СУБД и для того, что бы достичь максимальной производительности от связки HTTP-сервера с базой данных нужно эти сокеты поместить в один и тот же цикл обработки событий. Их нужно превратить в единую связку, так как это реализовано в Апостол и реализовано специально.
Поступивший HTTP запрос уже при выходе из цикла обработки событий будет находится в PostgreSQL. Останется только его обработать. Можно было бы обработать и на C++ но на PL/pgSQL скриптовей :)
В той четвёрке, что Вы упомянули, добавим туда ещё и node,js так делать не будут, потому, что там это не нужно. И поэтому их производительность, при работе с PostgreSQL будет ниже.
hVostt
14.10.2023 10:31+2Я и не говорил, что нельзя. Но о какой такой "максимальной производительности" вы рассказываете, если у вас HTTP в связке? И сколько же вы там выигрываете, если отправим запрос напрямую в БД? При чём тут цикл обработки событий, если операции с БД являются i/o операциями?
Реальные приложения несколько сложнее, чем тупо весь запрос с потрохами отправить в БД, а результат с потрохами вернуть юзеру. При чём намного сложнее. Начиная от циклов разработки, поддержки, до наблюдаемости, отказоустойчивости, масштабируемости и безопасности.
Ну или речь идёт о каких-то совсем примитивных вещах, весьма далёких от реальных задач.
Когда инструмент начинают применять не по назначению, на выходе получается сразу жуткое легаси. Проведя сотни собеседований я часто сталкивался с вопросами "надеюсь у вас нет логики в БД? потому что если, есть нам с вами не по пути", и я их прекрасно понимаю. Так как имею и имел дело с логикой в БД.
Действительно бывают случаи, когда хранимка может серьёзно решить узкое горлышко. Но такие случаи редки, а при близком и внимательном рассмотрении, оказывается, что небольшой рефакторинг устраняет потребность размещения логики в БД. Сама такая возможность является ценным помощником и затычкой. Но целенаправленно пихать логику в БД, такое может прийти в голову только очень большому любителю и фанату БД :) Ни один ДБА с кем я общался, не видит в этом никаких проблем :)))
apostoldevel Автор
14.10.2023 10:31Хранить код только в БД и вести там разработку - да так делать нельзя! Но мы так и не делаем. Об этом я уже написал тут: https://habr.com/ru/articles/767442/#comment_26058754.
При правильной организации процесса разработки хранимая в БД процедура не является головной болью как и реализуемая ею бизнес логика.
Ответить на Ваши вопросы коротко не получится. Придётся обсудить очень много базовых вещей, объяснить, как это работает на низком уровне.
Я лишь хочу сказать, что если, при разработке информационной системы, использование PostgeSQL неизбежно, то куда эффективнее будет задействовать встроенный в саму СУБД инструмент разработки. Правда придется решить ряд технических вопросов. Обычно эти вопросы закрываются с помощью скриптовых языков программирования. Но меня такое решение не устроило.
Каким бы сложным не было Ваше приложение в его основе лежат базовые вещи - протоколы, технологии, стандарты и чем ближе вы к базовым вещам тем меньше задаетесь вопросом: "Какого черта оно не работает".
apostoldevel Автор
14.10.2023 10:31По поводу неудобно.
Вы пишите код на Python, код храниться в файле. Далее помещаете файл в контейнер в котором запускается бинарный файл python и выполняет код из файла. При выполнении кода с операционной системой взаимодействует процесс python.
Я пишу код на PL/pgSQL, он храниться в файле, далее скриптами «проливаю» (помещаю) этот код в PostgreSQL т. е. в БД (своего рода контейнер), а БД это что — правильно файл, т. е. код храниться тоже в файле, который выполняется бинарным файлом postgres. При выполнении кода с операционной системой взаимодействует процесс postgres.
Ну есть пару отличий, а так с точки зрения операционной системы всё одинаково.

igor_suhorukov
14.10.2023 10:31Недавно показывал тут идею для прототипов приложений с PostgreSQL + PostgREST "Генерируем простой web интерфейс для просмотра таблиц PostgreSQL". Вы пошли еще дальше и внедрили HTTP сервер)

sshikov
14.10.2023 10:31+1Ну, на самом деле тут основной вопрос (на мой взгляд) в том, рационально ли писать свое приложение на таких языках, как PL/pgSQL. Потому что язык-то этот не самый лучший выбор на сегодня.
Ну то есть, плюсы, и достаточно очевидные, у такого подхода есть, быстродействие — потенциально один из них. Но и очевидные минусы тоже есть. Например, если вы таки хотите полноценный REST API наружу выставить, с какой-то сложной логикой обработки запросов, эта логика рано или поздно станет жрать ресурсы (потому что задача сложная, или потому что REST кто-то специально пытается завалить в диком интернете). Достаточно ли хороши средства планирования ресурсов постгреса, чтобы процессор, память и прочее таким обработчикам выделять, и запросы продолжать выполнять эффективно?
igor_suhorukov
14.10.2023 10:31Согласен! Но для прототипов вокруг БД и внутренних админок самое то. Где проще "все в одном", а когда нужна масштабируемость - добавляются компоненты, разработчики и реализуется по канонам жанра...
apostoldevel Автор
14.10.2023 10:31Достаточно ли хороши средства планирования ресурсов постгреса, чтобы процессор, память и прочее таким обработчикам выделять, и запросы продолжать выполнять эффективно?
Достаточно. Ресурсы жрут процессы (со всеми вытекающими), а не код. Каждое подключение к PostgeSQL это отдельный процесс. Каждый запущенный скрипт на Python или node.js это отдельный процесс, плюс контейнер в котором он "живет". От процессов PostgeSQL избавится сложно, от остальных можно.
Вот полноценное RESTful API. Вот ресурсы сервера на котором всё это крутится:

Процессов много, памяти мало, но при этом её достаточно.
sshikov
14.10.2023 10:31Достаточно.
Вообще говоря, ваших слов недостаточно.
Вот полноценное RESTful API.
Из этого вот пока совершенно непонятно, какую нагрузку оно там внутри создает. И какие ресурсы потребляет.Как бы это попроще сформулировать… дело в том, что очень давно внутри Oracle DB можно было писать код на Java. Да и сегодня можно. И мы, было дело, писали. Иногда хочется, чтобы код внутри базы мог получить доступ к API и ресурсам, которые обычному PL/SQL недоступны. Или скажем запустить какой-то долгоживущий процесс (да хоть бы и HTTP-сервер, слушающий сокеты, или там message broker). Как я сразу и сказал, плюсы у такого решения есть. Только вот проблема в том, что оно приносит с собой и кучу проблем, из которых управление ресурсами лишь одна, не самая сложная. Просто обычная СУБД недостаточно хорошая платформа для выполнения произвольных приложений. Никто ни оракл ни постгрес для такой цели не проектировал, и многие вещи там делать неудобно.
Ну т.е. вашей идее — ей не сто лет в обед конечно, но у нас в проекте все это было году так в 2004. И сейчас, через почти 20 лет, я бы сначала сто раз подумал, и скорее всего так делать не стал бы. Что в общем совершенно не означает, что для вашего конкретного случая она вполне может оказаться неплохой.
apostoldevel Автор
14.10.2023 10:31Целью было не сделать так, что бы все запросы обрабатывались в БД, Целью было создать HTTP-сервер, который максимально быстро взаимодействует с PostgreSQL и на базе него создать сервер приложений.
Изначально планировалось взять за основу nginx, написать к нему модуль взаимодействия с PostgreSQL. Но по ходу изучения и кода nginx и документации к PostgeSQL возникла более интересная реализация. Повторятся не буду писал об этом выше отвечая на "Так делать не нельзя".
Когда Вы пишите приложение на языках большой пятёрки Python/Java/Go/.NET/node.js вы уже накладываете на себя ограничение в виде их библиотек, правил, инструментов. Да, бесспорно, в замен Вы получаете тоже не мало и скорость разработки ПО и стабильность в работе с памятью и кроссплатформенность. Но когда у вас есть возможность балансировать между кодом на C/C++ и PL/pgSQL то вопрос производительности остро не стоит. Не справляется PostgreSQL выносим в отдельный процесс (поток) пишем на С++. Благо архитектура Апостол позволяет это сделать легко и быстро.
igor_suhorukov
14.10.2023 10:31А как apostol будет работать в кластерном варианте, совместно с расширением Citus, за балансировщиком http/s?
apostoldevel Автор
14.10.2023 10:31+1Если это расширение, то одно другому не должно мешать. На практике не сталкивался. Админы в любом случае не позволят Апостол смотреть портом наружу, поэтому как минимум nginx перед Апостол должен быть.
igor_suhorukov
14.10.2023 10:31Да, расширение превращающее PostgreSQL в том числе в шардированную базу. Вам идея в копилку масштабируемости, проверить на нескольких узлах ;-)
apostoldevel Автор
14.10.2023 10:31+1Спасибо! Интересное решение, изучу повнимательнее. Я то по привычке изобретаю свои велосипеды.
igor_suhorukov
14.10.2023 10:31Eсли с велосипедами и C++ вам в Яндекс устроиться, это может быть плюсом!
Citus не про репликацию совсем, а про шардирование и распределенные запросы по шардам(+ есть колоночное хранилище).
igor_suhorukov
14.10.2023 10:31Ну т.е. вашей идее — ей не сто лет в обед конечно, но у нас в проекте
все это было году так в 2004. И сейчас, через почти 20 лет, я бы сначала
сто раз подумал, и скорее всего так делать не стал бы.Точно! Классические признаки таких приложений - это отсутствие тестов всех видов и сложность с масштабированием, массовыми утечами данных в случае уявзвимостей, а также сложности с поддержкой и расширением функционала.


Greenback
14.10.2023 10:31Если Notify почему-то не сработало, то как это обработать? Есть ли гарантия доставки хотя бы at least once?
apostoldevel Автор
14.10.2023 10:31NOTIFY — это реакция на добавление данных в таблицу. Если по каким-то причинам извещение не было доставлено (внешнее приложение остановлено), данные то остались. Когда внешнее приложение будет запущено оно отберет по статусу те записи которые следует обработать, обработает и сменит статус. Теряется крайне редко.

ptr128
14.10.2023 10:31Тогда возникает резонный вопрос. Чем NOTIFY в данном случае выигрывает у REPLICATION SLOT?
apostoldevel Автор
14.10.2023 10:31Асинхронное уведомление, это не про репликацию. Это разные вещи.
Например Вам нужно отследить некие изменения в БД и отреагировать на эти изменения некими действиями. Вы подключаетесь к БД и в бесконечном цикле отслеживаете изменения в требуемой таблице т.е. закидываете БД не нужными SQL запросами.
Асинхронное уведомление позволяет от этого избавится. Сама СУБД известит ваше приложение о том, что произошли требуемые изменения.
ptr128
14.10.2023 10:31REPLICATION SLOT и есть асинхронное уведомление средствами штатного расширения pgoutput.
Вы подключаетесь к БД и в бесконечном цикле отслеживаете изменения в требуемой таблице т.е. закидываете БД не нужными SQL запросами.
Вы явно не в теме. Почитайте, например, как этим пользуется Debezium https://debezium.io/documentation/reference/stable/connectors/postgresql.html
Принципиальная разница с NOTIFY в том, что через REPLICATION SLOT данные Вы точно не пропустите.
apostoldevel Автор
14.10.2023 10:31Ещё раз. Асинхронное уведомление, это не про репликацию. Это разные вещи.
ptr128
14.10.2023 10:31Я знаю, что NOTIFY и REPLICATION SLOT - разные вещи. Вы сами пишете:
Когда внешнее приложение будет запущено оно отберет по статусу те записи которые следует обработать, обработает и сменит статус.
А в случае использования REPLICATION SLOT внешнему приложению ничего делать не надо, так как сама технология логической репликации предоставит ему только те записи, которые следует обработать и "сменит статус", пометив их в WAL на удаление.
Поэтому и вопрос. Зачем изобретать велосипед через NOTIFY, если REPLICATION SLOT без дополнительных усилий, автоматически обеспечит доставку внешнему приложению любого "запроса", как только он будут вставлен в таблицу, подключенную к REPLICATION SLOT?
Если еще раз на пальцах:
PL/pgSQL функция
http.fetchявляется оберткой для функцииhttp.create_request, в которой происходит запись в таблицуhttp.requestс последующим вызовом командыNOTIFYчерез триггер добавления новой записи.Вместо триггера на таблицу http.request, достаточно было включить на ней логическую репликацию, добавить ее в нужны слот репликации и штатными средствами получать оттуда все новые записи в этой таблице. Причем с ГАРАНТИРОВАННОЙ доставкой, вне зависимости от перебоев в работоспособности сервиса.
apostoldevel Автор
14.10.2023 10:31Мне не нужно передавать данные, мне нужно передать сигнал от одного процесса другому. Известить Апостол о том, что нужно отправить HTTP-запрос. Сам Апостол подключен к PostgeSQL через libpq.
Приложения, использующие libpq, отправляют серверу команды
LISTEN,UNLISTENиNOTIFYкак обычные SQL-команды. Поступление сообщений от командыNOTIFYможно впоследствии отследить с помощью функцииPQnotifies.Я использую то, что есть в этой библиотеке: https://postgrespro.ru/docs/postgresql/16/libpq-async
// Так, мне неудобно и не нужно... select * from pg_replication_slots;И мне не нужна гарантированная доставка, если сигнал не будет доставлен то ни чего страшного не произойдет.
NOTIFY - тоже штатный механизм включенный в библиотеку libpq.
ptr128
14.10.2023 10:31Мне не нужно передавать данные, мне нужно передать сигнал от одного процесса другому.
То есть сам запрос Вы не передаете? То есть это ложь:
PL/pgSQL функция
http.fetchявляется оберткой для функцииhttp.create_request, в которой происходит запись в таблицуhttp.requestНичего в таблицу не пишется?
А если пишется, то сам факт записи в таблицу уже является сигналом от одного процесса другому. И никаких дополнительных сигналов не требуется.
NOTIFY - тоже штатный механизм включенный в библиотеку libpq.
Но с той принципиальной разницей, что он не гарантируется доставку сигнала клиенту. А REPLICATION SLOT - гарантирует.
apostoldevel Автор
14.10.2023 10:31Всё происходит так как описано.
то сам факт записи в таблицу уже является сигналом от одного процесса другому.
Это как? Каким образом внешний процесс будет извещён о том, что в таблицу добавлена запись? Непрерывно сканируя её, закидывая БД ненужными запросами? Кажется мы уже это обсуждали.
Задача передать управление внешнему процессу, для этих целей NOTIFY и создан.
Может так будет понятнее.
В любом случае за комментарий спасибо, почитать про REPLICATION SLOT было полезно :)
ptr128
14.10.2023 10:31Каким образом внешний процесс будет извещён о том, что в таблицу добавлена запись?
Если напрямую внутри собственного кода, то вызовом PostgreSQL блокирующей функции pg_logical_slot_get_changes() или pg_logical_slot_get_binary_changes(), которые не вернут управление до тех пор, пока в WAL не появится хотя бы одна новая подходящая запись.
Если без излишнего кодирования и с горизонтальным масштабированием, то чтением топика Кафки, куда Debezium сам отправит сообщения о новых записях в таблице. А уж количеством секций в топике можете легко нарастить количество внешних процессов, обрабатывающих эти запросы.
Непрерывно сканируя её, закидывая БД ненужными запросами? Кажется мы уже это обсуждали.
И я Вам даже дал ссылку, которую Вы явно не открывали. И где написано, что никаких сканирований и ненужных запросов при этом не происходит.
Задача передать управление внешнему процессу, для этих целей NOTIFY и сознан.
Судя по статье, задача передать асинхронно данные внешнему сервису, а не только управление. И Вы как раз грузите БД, запросами по таблице http.request. Хотя эти запросы не нужны, так как все новые записи и без того пишутся в WAL. Достаточно их просто оттуда считать через REPLICATION SLOT.
apostoldevel Автор
14.10.2023 10:31Судя по статье, задача передать асинхронно данные внешнему сервису, а не только управление.
Задача выполнить HTTP-запрос по данным из http.request. Вместе с NOTIFY передается идентификатор записи в таблице http.request, далее происходит запрос данных по этому идентификатору и выполнение HTTP-запроса с сохранением результата в http.request. Всё.
И как раз благодаря NOTIFY я не атакую запросами БД в ожидании новой записи в http.request. Я просто жду уведомление и по факту его получения выполняю описанное выше.
Достаточно их просто оттуда считать через REPLICATION SLOT.
Зачем таки сложности? Всё, что нужно для выполнения задачи уже в http.request.
ptr128
14.10.2023 10:31Сами себе противоречите.
происходит запрос данных по этому идентификатору
после чего
я не атакую запросами БД
То есть, Вы сначала посылаете NOTIFY через очередь СУБД, а затем еще посылаете запрос данных по идентификатору, полученному через NOTIFY. Вместо того, чтобы вообще без запроса к очередям или таблицам БД просто получить данные из WAL и их обработать.
Зачем таки сложности? Всё, что нужно для выполнения задачи уже в http.request.
Вот я и спрашиваю. Зачем такие сложности? Ведь можно просто посадить хоть сотню сервисов на сотню секций Кафки в k8s и пусть они эти запросы асинхронно обрабатывают, вообще не обращаясь БД. Лишь возвращая результат через другой топик и синк.
с сохранением результата в http.request
Тем более. Еще и VACUUM грузите, вместо того вставлять ответы в другую таблицу.
apostoldevel Автор
14.10.2023 10:31после чего
После того так внешний процесс получит извещение :) которое будет обработано на уровне libpq.
Хорошо, как приложение подключенное к СУБД через libpq "просто получит данные из WAL"?
ptr128
14.10.2023 10:31которое будет обработано на уровне libpw
Сначала оно попадет в очередь сервера и будет там находится до фиксации транзакции. А только после фиксации будет рассылаться всем клиентам, подписанным на эту очередь. А потом Вы еще лезете в БД, отыскивая по индексу данные, читая их из таблицы, да еще и обновляя статус там. Что явно на порядок большая нагрузка на сервер, чем последовательное чтение WAL.
Хорошо, как приложение подключенное к СУБД через libpq "просто получит данные и WAL"?
Вы издеваетесь? Я Вам и ссылку давал и указывал функции блокирующего чтения, которые предоставляют данные из WAL без обращения к очередям или таблицам БД. Это если в лом поднимать соединение репликации и явно выполнять
START_REPLICATIONSLOTslot_nameLOGICAL ...Суть в том, что если взять Ваш проект на гитхабе, когда запросы идут на один и тот же сервер, то это делается вообще без кодирования, исключительно средствами Confluent. Таблица запросов -> Source connector к PostgreSQL -> топик запросов -> HTTP Sink -> топики ответов (успешный, ошибка и dlq) -> PostgreSQL Sink -> таблицы ответов. Всё. Только настройка.
apostoldevel Автор
14.10.2023 10:31Вызов:
SELECT * FROM pg_logical_slot_get_changes('test_slot_1', NULL, NULL, 'include-xids', '0');Заблокирует намертво одно из соединений, что уже неприемлемо при асинхронной обработке данных.
Тот механизм который предоставляет библиотека libpq в среде C/C++ выглядит белее привлекательно. Так как работает на уровне кода, а не SQL запросов.
Если Вы хотите продолжить обсуждение то найдите меня в телеграм по тому же нику. Готов показать как это работает в отладчике C++.
ptr128
14.10.2023 10:31+1Заблокирует намертво одно из соединений, что уже неприемлемо при асинхронной обработке данных.
А породить нить/процесс, который и будет заниматься только чтением данных религия не позволяет?
Тот механизм который предоставляет библиотека libpq в среде C/C++
Я Вам на пальцах объяснял, как это можно легко запросами сделать. Но если бы Вы соизволили почитать по ссылке, как это делается в продуктивных системах, то обнаружили бы, что в соединении репликации после выполнение команды START_REPLICATION, данные попрут через CopyData. То есть, по тому же потоку, что и при выполнении команды COPY.
Если Вы хотите продолжить обсуждение
Не хочу. Столько принципиальная позиция не читать пруфы по ссылкам говорит о том, что дискутировать с Вами бессмысленно. Пишу здесь не столько Вам, сколько тем, кто читают статью и могут тоже попытаться изобретать велосипед там, где уже есть проверенное, хорошо масштабируемое и эффективное решение из коробки.
apostoldevel Автор
14.10.2023 10:31Во первых читал, а чтиво там не на пять минут. Во вторых я не спорю и более того соглашусь, что REPLICATION SLOT более производительное решение. Но и более сложное в реализации: помимо отдельной нити нужно ещё решить вопрос с разбором данных. Текущая реализация уже на NOTIFY и она проще в применении.
REPLICATION SLOT, благодарю ещё раз за предоставленный материал, я возьму за основу при переработке своего модуля репликации, там это, то, что нужно.
ptr128
14.10.2023 10:31более сложное в реализации
В рамках того, что выложено на гитхабе, все делается вообще без программирования, исключительно настройками. И чем это сложнее?
помимо отдельной нити нужно ещё решить вопрос с разбором данных.
Не изобретайте велосипед. CDC connect их сам разберет и разложит по нужным топикам. Остается только или воспользоваться готовым HTTP Sink, или написать свой Sink для более специфичных задач.

Helltraitor
14.10.2023 10:31+6Можно? Можно!
Интересно? Интересно!
Стоит ли так делать? Не стоит
apostoldevel Автор
14.10.2023 10:31Не стоит хранить код в БД как единственную копию и вести разработку непосредственно в БД. Тут, да и я скажу, что так делать нельзя.
Сейчас, у нас по крайней мере, процесс разработки на PL/pgSQL особо ни чем не отличается от JavaScript.
Весь код хранится в репозиторий, при фиксации изменений отрабатывают механизмы CI/CD. Отрабатывают скрипты и код обновляется в БД (во всех копиях) с полной заменой всех функций. Да есть особенности в виде написания патчей для удаления старых функций или изменений структур таблиц, но это SQL что поделаешь.
Сам код находится в отдельной от таблиц (данных) схеме и если уж так получилось, что кто-то полез туда руками и код в БД стал не соответствовать тому, что в исходных файлах, то смело можно удалить всю схему в которой хранится только код и перезалить скриптами по новой.
Вопрос же не в можно или нельзя, а в том кому как удобно и кто как знает, умеет, может :)
ptr128
14.10.2023 10:31Если возможность посылать HTTP запросы из кода на pl/pgsql еще понятна (сам таким балуюсь, когда необходима синхронность в получении результатов из REST/gRCP сервисов), то нагружать PostgreSQL веб-серверной логикой - выглядит недальновидно, с точки зрения масштабирования. Все же сервисы в k8s масштабируются легко и просто, тогда как масштабирование PostgreSQL - тяжело и сложно.
P.S. Когда синхронность не нужна, то коммуникацию между PostgreSQL и сервисами в обе стороны выполняет Kafka
apostoldevel Автор
14.10.2023 10:31Вы по любому нагружаете PostgreSQL запросами из вне, а если бизнес логика тесно связана с этими данными, то отработка кода бизнес логики внутри СУБД будет эффективнее, чем таскать данные по сети между разными процессами и отрабатывать логику за пределами СУБД.
Сделать контейнер на подобии того, что в этой статье задача не сложная. Развернуть несколько таких контейнеров (с одинаковым кодом) тоже не проблема. Проблема обеспечить идентичность данных в разных базах данных. Но в моём случае она решаема.
ptr128
14.10.2023 10:31Вы по любому нагружаете PostgreSQL запросами из вне
Естественно нагружаю. У меня тоже много бизнес-логики на СУБД. Но в сервисах можно кешировать результаты, например в Redis, существенно снижая нагрузку на СУБД. И это не считая снятия с СУБД нагрузки на десериализацию/сериализацию, включая конвертации чисел из десятичного представления в двоичное и обратно.
Например, кешируя в Redis всего лишь справочники, удалось снизить загрузку на СУБД в несколько раз. Например, там, где раньше в запросе сервер возвращал "Код станции", "Наименование станции", "Код участка", "Наименование участка", "Код отделения", "Наименование отделения", "Код дороги", "Наименование дороги" и т.п., теперь достаточно вернуть ID станции, а все остальные атрибуты будут взяты из Redis, поддерживаемой в актуальном состоянии из топиков Кафки. Я думаю видно, что с СУБД были сняты еще и четыре JOIN с справочниками (Станции, Участки, Отделения, Дороги). Для ряда запросов, например по дислокации, это уже два десятка JOIN!
Проблема обеспечить идентичность данных в разных базах данных. Но в моём случае она решаема.
До тех пор, пока мастер справляется. И это очень серьезное ограничение.
apostoldevel Автор
14.10.2023 10:31Это всё верно, если мы исходим из ситуации когда кэширование становится необходимым. А если в этом нет необходимости, если запросы и так отрабатываются достаточно быстро:

API Log В любом случае одно другому не мешает. Можно кэшировать запросы на уровне HTTP-сервера, на этом же уровне можно задействовать и Redis. Правда это уже будет код на C++ :).
apostoldevel Автор
14.10.2023 10:31До тех пор, пока мастер справляется. И это очень серьезное ограничение.
:) так в том-то и дело, что можно каждый узел сделать мастером.
ptr128
14.10.2023 10:31Давайте не будем погружаться в проблемы мульти-мастер репликации. Это огромная и сложная тема. Может на досуге почитать и тогда поймете, почему мульти-мастер репликация не часто используется, да и то, преимущественно, для multi-tenent. Когда, например, в БД уже все транзакционные данные разделены на разные tenants. Например, компании (юр. лица).
А в Вашем случае, когда приложение даже не поддерживает tenants, толк от такой мульти-мастер скорее умозрительный. Сужу по своим БД, где таблица, на которую не ссылаются другие - редкость, а перекрестных ссылок - множество.
ptr128
14.10.2023 10:31если запросы и так отрабатываются достаточно быстро
Поверьте, в начале на любой системе запросы отрабатываются быстро. И если архитектура изначально не предусматривала горизонтальное масштабирование, то потом внедрять его очень трудоемко.
Вот только на этой неделе заработал проблему, только потому, что пропустил когда-то PR с кривой архитектурой, не посчитав, что прирост в таблице по 5 миллионов записей в день, вылезет боком уже через девять месяцев, на запросах по ней.


vagon333
14.10.2023 10:31Вопросы по реализации и использованию:
- отладка проблемных запросов - как траблушить проблемы?
- тяжелые запросы, потребляющие проц и память - как будет работать обработчик, когда на сервере тяжелая нагрузка?
Например ETL с подгрузкой и обработкой больших объемов данных.
- балансировка нагрузки - в случае роста нагрузки, как масштабироваться горизонтально, если данные и обработка в одной точке и неделима?
- командная разработка - как реализовать стандартный для команд SDLC?
- SLA - как гарантировать время ответа, если бешенный запрос может нагрузить сервер по самые тапочки?Краткий текст статьи (после GPT):
Рассматривается способ отправки и обработки HTTP-запросов непосредственно из базы данных PostgreSQL.
Автор предлагает использовать функции http.fetch, http.get и http.post для отправки запросов, а также функции обратного вызова для обработки полученных данных.
Он также показывает, как можно настроить HTTP-сервер в PostgreSQL для обработки входящих запросов.
Для демонстрации примеров автор использует инструмент pgweb, который позволяет выполнять SQL-запросы и просматривать содержимое таблиц и функций на PL/pgSQL. В статье также представлен пример использования асинхронных уведомлений PostgreSQL для взаимодействия с клиентским приложением, которое выполняет HTTP-запросы и сохраняет результаты в базе данных.
Автор приводит практический пример использования этого механизма для автоматического списания денег с карты клиента.
В целом, статья предлагает простой и гибкий способ взаимодействия с внешними системами из PostgreSQL.
atshaman
14.10.2023 10:31Краткий ответ на все вопросы - "с трудом".
Чуть менее краткий - "Существует немало классов задач, для которых вот это все - нафиг не нужно." Впрочем, обычно для их решения есть более простые средства.
Классический троллейбус-из-буханки - на вид как настоящий и даже наверное работает - но решительно непонятно "зачем"?
apostoldevel Автор
14.10.2023 10:31- отладка проблемных запросов - как траблушить проблемы?
Через журналы событий. Через внутренние и внешние инструменты анализа производительности PostgeSQL.
- тяжелые запросы, потребляющие проц и память - как будет работать обработчик, когда на сервере тяжелая нагрузка?
Это очень обобщенный вопрос который можно адресовать любому программному продукту. Есть сервера на которых происходит разработка и тестирование, в том числе и нагрузочное есть определённое понимание пределов железа и системы в целом.
- балансировка нагрузки - в случае роста нагрузки, как масштабироваться горизонтально, если данные и обработка в одной точке и неделима?
Так у вас же не один процесс запущен и не только он занимается обработкой входящих данных: https://habr.com/ru/articles/767442/#comment_26058162
В настройках Апостол можно указать как количество рабочих процессов (аналогично nginx), так и пул подключений к СУБД. Если железо позволяет можно одновременно держать сотни готовых подключений. Обработка запросов асинхронная через epoll поэтому запас прочности большой, но да, всему есть предел. На самом деле вопрос отрытый :)
Например ETL с подгрузкой и обработкой больших объемов данных.
Если объем данных большой и есть четкое понимание, что пихать это всё в одну ячейку таблицы, с последующей обработкой на PL/pgSQL не самая удачная затея. То на помощь приходит C++. Апостол это не только про PostgreSQL- это фреймворк для разработки серверного программного обеспечения. Можно создать отдельный модуль или процесс который будет заниматься разбором данных.
- командная разработка - как реализовать стандартный для команд SDLC?
Да всё как и у всех. Упоминал об этом тут: https://habr.com/ru/articles/767442/#comment_26059064
- SLA - как гарантировать время ответа, если бешенный запрос может нагрузить сервер по самые тапочки?
Бывает, может "призадуматься" один из процессов, но как я уже упомянул их не мало, да и это уже повод задуматься, что не так.
На синтетических тестах грузили так, что количество запросов превышало в разы количество клиентов (которые вряд ли ринутся все разом в одну секунду) и результат заказчика устроил.
apostoldevel Автор
14.10.2023 10:31Вопросы по реализации и использованию:
Реализация на примере.
Один из текущий проектов предполагает активное взаимодействие с ИИ. Это не только ChatGPT, много сервисов для работы с изображениями.
Midjourney один из них. Но так как было четкое понимание, что из-за проблем с коммерческой эксплуатацией этот сервис нам не подходит, создали временное решение на node.js, не входящее в основную сборку. На выходе получится микросервис со своим не большим API. Взаимодействие с ним происходило так же как описано в этой статье. Обратная связь через webhook.
Hidden text
Со временем перешли на RunPod, а с него на Replicate.
Я к тому, что ни кто не отменяет микросервисную архитектуру, а наоборот. При этом СУБД как источник данных превращается в центр управления, дережируюя микросервисами.

lazy_val
Как в этом сценарии работает авторизация и проверка полномочий внешнего пользователя, обращающегося с HTTP-запросом к БД? Тоже средствами СУБД?
apostoldevel Автор
Благодарю за комментарий. Да, средствами СУБД. Создается пользователь PostgreSQL, в данном примере это http и клиентское приложение подключается к СУБД от его имени.
apostoldevel Автор
Если речь идет о логическом (web) пользователе, то через HTTP-заголовок Authorization, доступ к нему имеется. При входящем запросе внешний пользователь не имеет как такового доступа к данным. Вы сами определяете кому и какие данные будут в итоге возвращены, как и механизм авторизации, будь то пара login/password, API key или JWT-токен.