
В больших распределённых системах многое зависит от эффективности запросов: если на гигабайте данных неоптимальный запрос может выполняться за миллисекунды, то при увеличении массива в тысячи раз, сервер начнёт кряхтеть, пыхтеть и жаловаться. Чтобы избежать этого, помогут знания о работе распределённых систем и их частей, а именно — планировщиков.
Меня зовут Алексей Шишкин. Ещё с университетских времён исследую распределённые системы, а последние два года в Яндексе адаптирую Apache Spark к внутренней инфраструктуре. Эта статья посвящена Apache Spark, а именно: как мы в рамках YTsaurus делали его ещё эффективнее. Написана она по мотивам моего доклада для «Онтико».
Поговорим про:
Apache Spark и YTsaurus.
Обзор планирования запросов.
Выявление просторов для оптимизации.
Внедрение знаний о сортировке в план исполнения.
Тесты производительности.
Что нам дают Apache Spark и YTsaurus
Apache Spark — опенсорс‑фреймворк, который сегодня позиционируется как «самый часто используемый движок для масштабируемых вычислений». Это популярный стандарт ETL/ELT‑процессов, на котором реализуют бизнес‑задачи и обработки машинных моделей. Он поддерживает огромное число форматов и самые разные источники. Исполнение запросов происходит в оперативной памяти, из‑за чего всё работает очень быстро. Мощный встроенный оптимизатор запросов делает даже плохо написанные запросы оптимальными.
YTsaurus — платформа для распределённого хранения и обработки больших данных с открытым исходным кодом. У неё надёжное хранилище, она масштабируется на огромные кластеры и располагает множеством инструментов, включая Apache Spark.
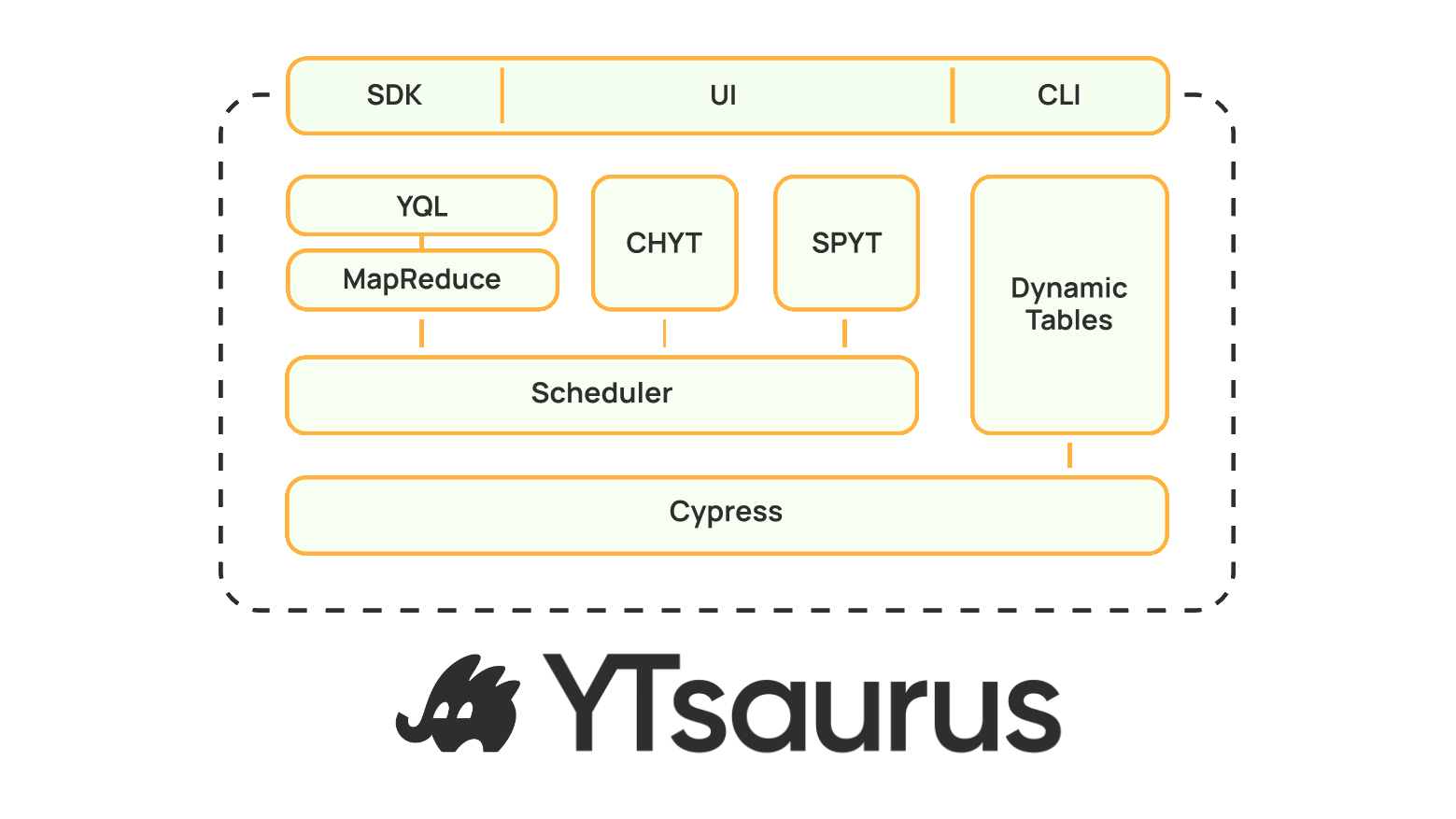
Все данные и таблицы BigData‑системы находятся в хранилище Cypress. Оно хорошо масштабируется: буквально экзабайты жестких дисков, миллионы CPU. Поверх хранилища доступны аналитические инструменты: ClickHouse, Yandex Query Language и Spark. SPYT — это прослойка между Spark и YTsaurus, которая берёт сильные стороны этих технологий, чтобы эффективно исполнять ETL‑процессы.
В YTsaurus все таблицы имеют сильную схематизацию, то есть мы знаем, из каких колонок состоит таблица, как она отсортирована. Благодаря этому можно пропустить лишние шаги на этапе исполнения запроса, сэкономив время, деньги и ресурсы.
Перейдём к конкретным запросам и посмотрим, как эти системы работают вместе.
Как планировщик Spark помогает с неоптимальными запросами
К нам приходит дата‑инженер, пишет свой запрос, часто неэффективный.
Далее включается планировщик и видоизменяет этот запрос, чтобы он работал эффективно (но результат был бы абсолютно такой же), — и выдаёт готовый план.

То, что получилось в итоге, называется физическим планом.
Физический план — это финальный результат планирования, готовая инструкция к исполнению.
Возьмём пример запроса, который написал дата‑инженер: он почитал логи, затем достал колонку, преобразовал её и записал назад.
spark.read.yt('logs')
.map(row -> row.ts)
.map(ts -> date(ts))
.write.yt('dates')Внутри планировщика план хранится в виде графа, который выполняется сверху вниз:
Scan — чтение данных;
Project — проекция, оставляем одну колонку;
Map — преобразование данных;
Save — сохранение в итоговую таблицу.
Поскольку мы имеем дело с движком для распределённых вычислений, то дело обстоит ещё чуть сложнее: внутри все таблицы поделены на кусочки, которые называются партициями (англ. Partition).
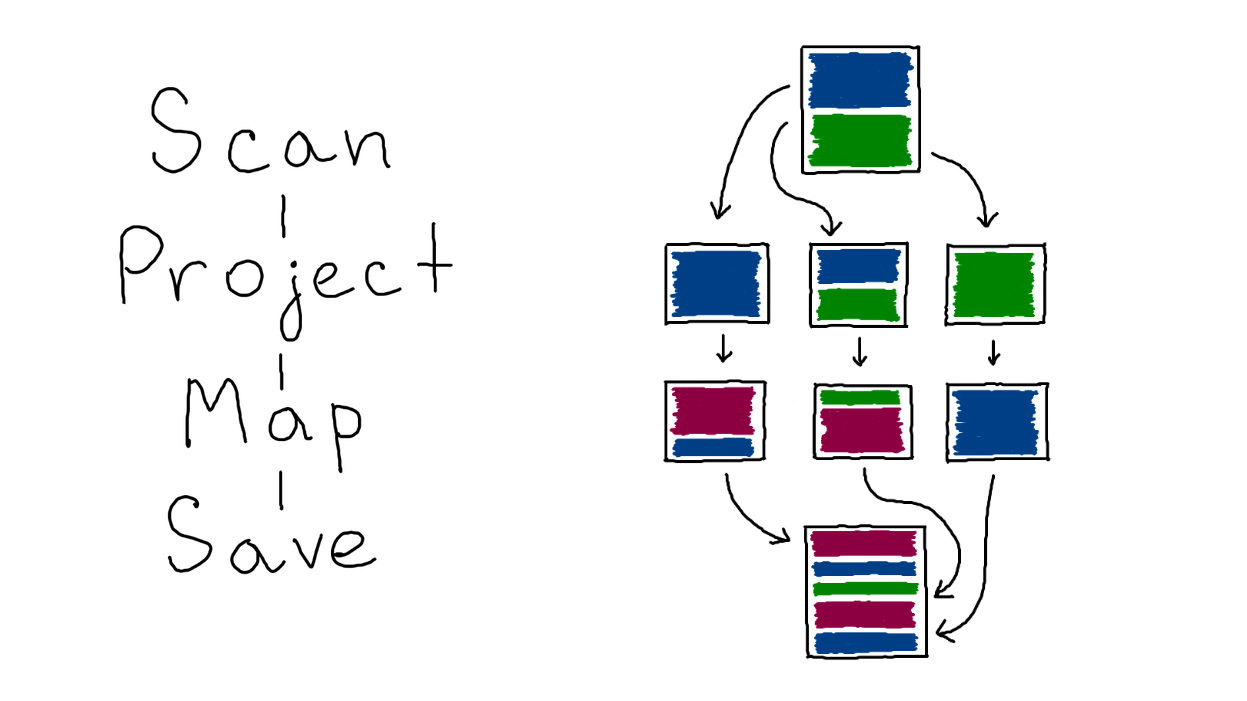
Изначально Spark читает таблицу, и она делится на примерно равные части. Далее все эти части можно независимо обрабатывать. Можно выполнить map, filter, много чего ещё — уровень параллельности зависит от наличия денег и ресурсов. Затем партиции снова собираются в единую таблицу и записывается в хранилище, например, в YTsaurus.
Наш первый запрос был простой, но бывают случаи пострашнее:
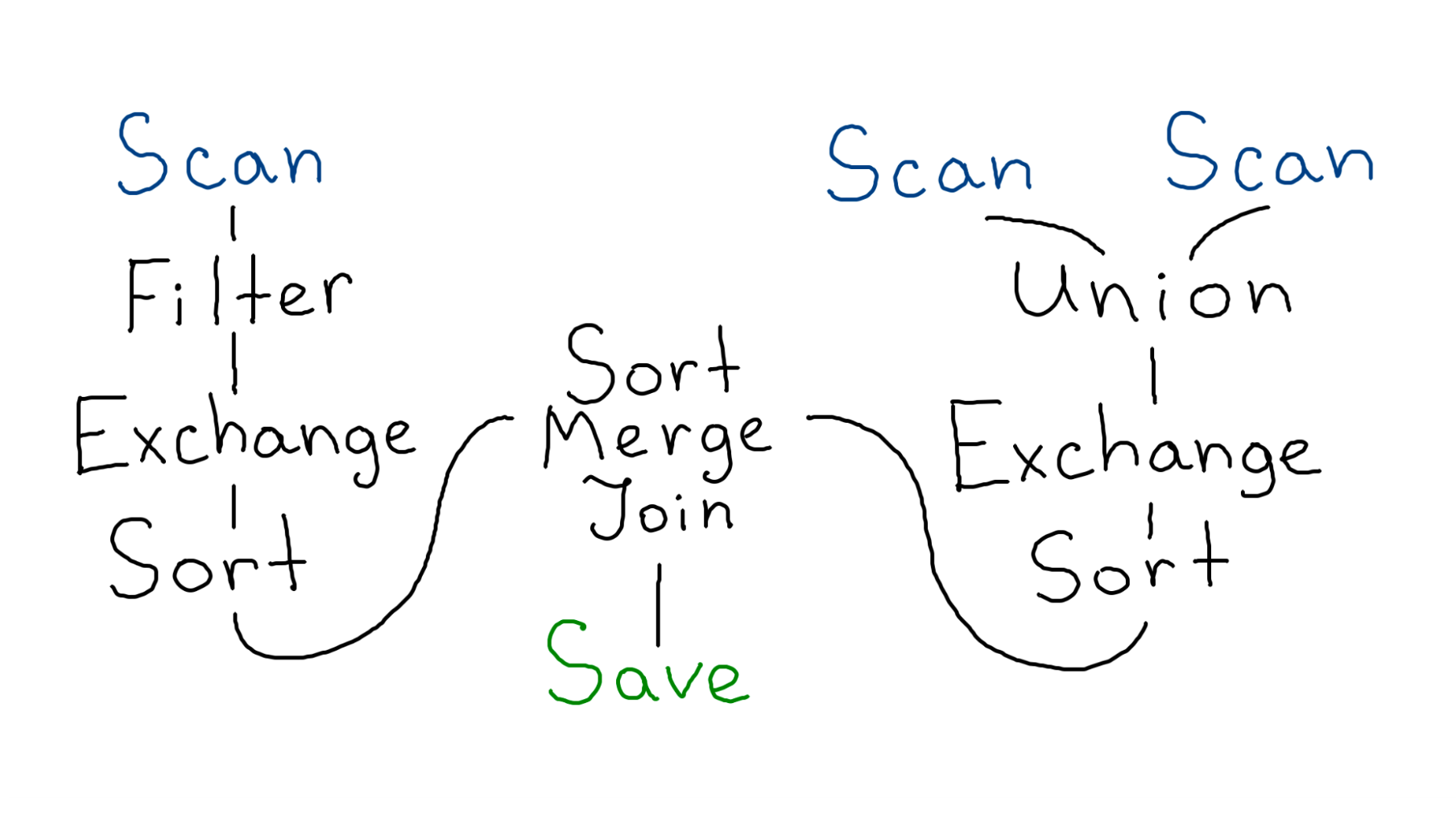
Это физический план настоящего запроса. Здесь есть:
привычное чтение 3 таблиц;
фильтр;
Union, который склеивает таблицы;
сортировка;
объединение — Join;
запись результата;
загадочный Exchange.
Почти все представленные операции эффективны. Как говорилось ранее, мы можем поделить таблицу на мелкие кусочки и отправить каждый на свою машинку, чтобы она преобразовала эти данные.
Но только не в случае с Exchange, второе имя которого — шаффл.
Это очень тяжёлая операция, потому что она перемещает все данные между партициями.

Шаффл бывает двух типов:
RangePartitioning. Делает так, чтобы данные с наименьшими ключами оказались в первой партиции. Потом из оставшихся снова выбираются данные с наименьшими ключами и кладутся во вторую, и т.д. По итогу данные у нас разбиты на упорядоченные блоки.
HashPartitioning. Для каждой строки считается хэш, и далее она перекладывается в партицию с номером, равным посчитанному хэшу. По итогу, если у нас есть одинаковые строчки, они обязательно попадут в одну и ту же партицию.
Когда таблица изначально отсортирована, мы можем аккуратно нарезать её на части. Тогда данные между кусочками уже упорядочены, при этом каждый кусочек ещё и отсортирован сам по себе. Получается, что исполнять шаффл и сортировку на таких данных не требуется, можно смело убрать их из плана, тем самым ускорив наши запросы.

Внедряем полученные знания о сортировке в план исполнения
При написании запросов обычно операцию шаффл явно не используют. Exchange возникает сам собой, например, когда пишутся агрегации.
Агрегация — это процесс, при котором у нас выделяется ключ (подмножество колонок), по которому группируются данные. А затем происходит общее вычисление над строками с одним ключом.
Например, есть таблица с заказами. Мы группируем её по пользователю. Далее считаем сумму его покупок, и записываем в конечную таблицу. В итоге для каждого пользователя мы знаем, сколько денег он потратил в сервисе.
spark.read.yt('orders')
.groupBy('uid')
.agg(sum('price'))
.write.yt('sums')Физический план будет выглядеть так:
Scan — чтение;
Aggregate — предварительная агрегация;
Exchange — хэш‑шаффл, который положит покупки одного пользователей в один кусочек;
Aggregate — агрегация;
Save — запись.
За счет шаффла в каждой партиции будет уникальный набор пользователей. На каждом таком кусочке можно запустить независимую агрегацию и получить конечный результат. Aggregate перед шаффлом заранее посчитает частичные суммы, за счет чего чуть-чуть сожмет данные до того, как их шаффлить.
Что будет, если таблица уже отсортирована? Что нам может предложить Spark?
spark.read.yt('orders')
.sort('uid')
.groupBy('uid')
.agg(sum('price'))
.write.yt('sums')Когда мы добавили сортировку, ничего не произошло. Spark выкинул её из плана (будто мы её не добавляли), и неспроста. Он увидел, что у нас есть сортировка, а сразу затем группировка, и потому сэкономил ресурсы: выкинул лишнюю операцию, результат же при этом не меняется.
В следующем примере посмотрим, что будет, если данные всё‑таки отсортированы. Для этого мы прибегнем к трюку с кэшированием.
Проведём эксперимент: трюк с кэшированием
Cache сбрасывает данные на жёсткий диск в процессе вычисления. Spark не может влиять на результат, на видимый эффект от наших операций. Поэтому он не может выбросить то, что было до операции Cache.
spark.read.yt('orders')
.sort('uid').cache()
.groupBy('uid')
.agg(sum('price'))
.write.yt('sums')
Как можно заметить, шаффл исчез. Spark понял: данные уже приходят отсортированные, значит шаффл не нужен — всё и так лежит как надо.
Посмотрим, что такого есть в классе сортировки, что позволяет ей сообщать о состоянии данных. Для этого подглядываем в исходный код:
class SortExec {
outputOrdering: Seq[SortOrder]
outputPartitioning: Partitioning
requiredChildOrdering: Seq[Seq[SortOrder]]
requiredChildDistribution: Seq[Distribution]
}Есть 4 основных поля — выходное упорядочивание и партиционирование, а также требуемое упорядочивание и партиционирование. Схематично это выглядит так:

Партиционирование (англ. Partitioning) — это то, как данные будут разбиты на блоки, а упорядочивание (англ. Ordering) — это то, в каком порядке данные будут храниться внутри каждого блока. Каждая операция описывает в каком виде она передаст данные следующей. В свою очередь следующая операция может выставлять свои требования.
Когда Spark видит, что следующая операция требует отсортированные входные данные, но предыдущая этого не гарантирует, он добавляет промежуточные шаги. Именно поэтому мы видим шаффл и сортировку в плане, хотя сами их не писали.
Глядя на это, хочется создать в дереве плана свою вершину, которая будет присоединяться к вершине чтения и проецировать информацию о сортировке данных подобно SortExec, но при этом не выполнять никакой реальной работы. Spark обнаружит её и поймёт, что шаффлить не надо. Осталось разобраться, как такое реализовать.
Не только физический: другие виды планов
Для этого поговорим, какие вообще виды планов бывают:
Сырой логический.
Проверенный логический.
Оптимизированный логический.
Физический.
Мы уже видели физический план — это конечный результат. Перед этим запрос проходит несколько стадий.
По написанному запросу, в случае отсутствия синтаксических ошибок, сначала строится сырой логический план.
После этого подгружаются метаданные таблиц, проверяется корректность используемых функций. Известная информация о типах вносится в сырой план и получается проверенный логический план.
Далее Spark начинает применять свою магию оптимизаций.
Оптимизированный план
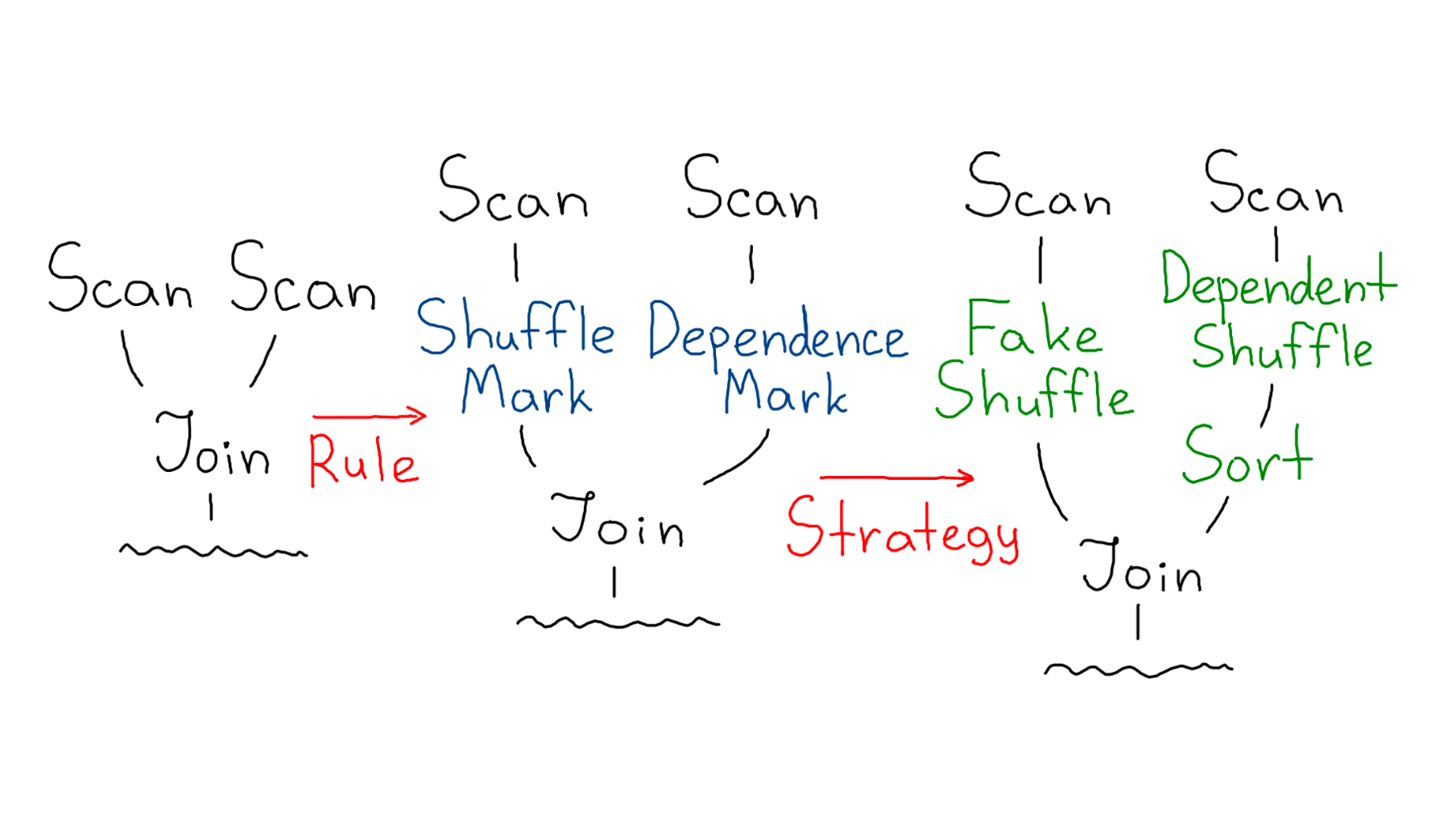
В код Spark’а зашиты паттерны оптимизаций, по которым ускоряются запросы — правила (англ. Rule).

Как работают правила: Spark видит дерево слева и понимает — если переставить операции в области, помеченной фиолетовым цветом, то это будет работать эффективней. А операции, помеченные синим, вообще выполнять не надо, они бесполезные. Пока Spark находит ситуации для применения правил — этап оптимизации продолжается.
Рождение физического плана
Физический план строится из оптимизированного с помощью стратегий (англ. Strategy).

Планировщик проходит снизу вверх и заменяет каждую вершину логического плана на вершину физического плана — буквально от Save до «листьев» (обычно это Scan). Промежуточно он может добавлять свои вершины, если замечает несостыковки в требуемых и предоставляемых гарантиях у физических вершин в графе. В такие моменты и создаются вершины шаффлов и сортировок. В результате мы получаем финальный красивый план, который будет исполняться.
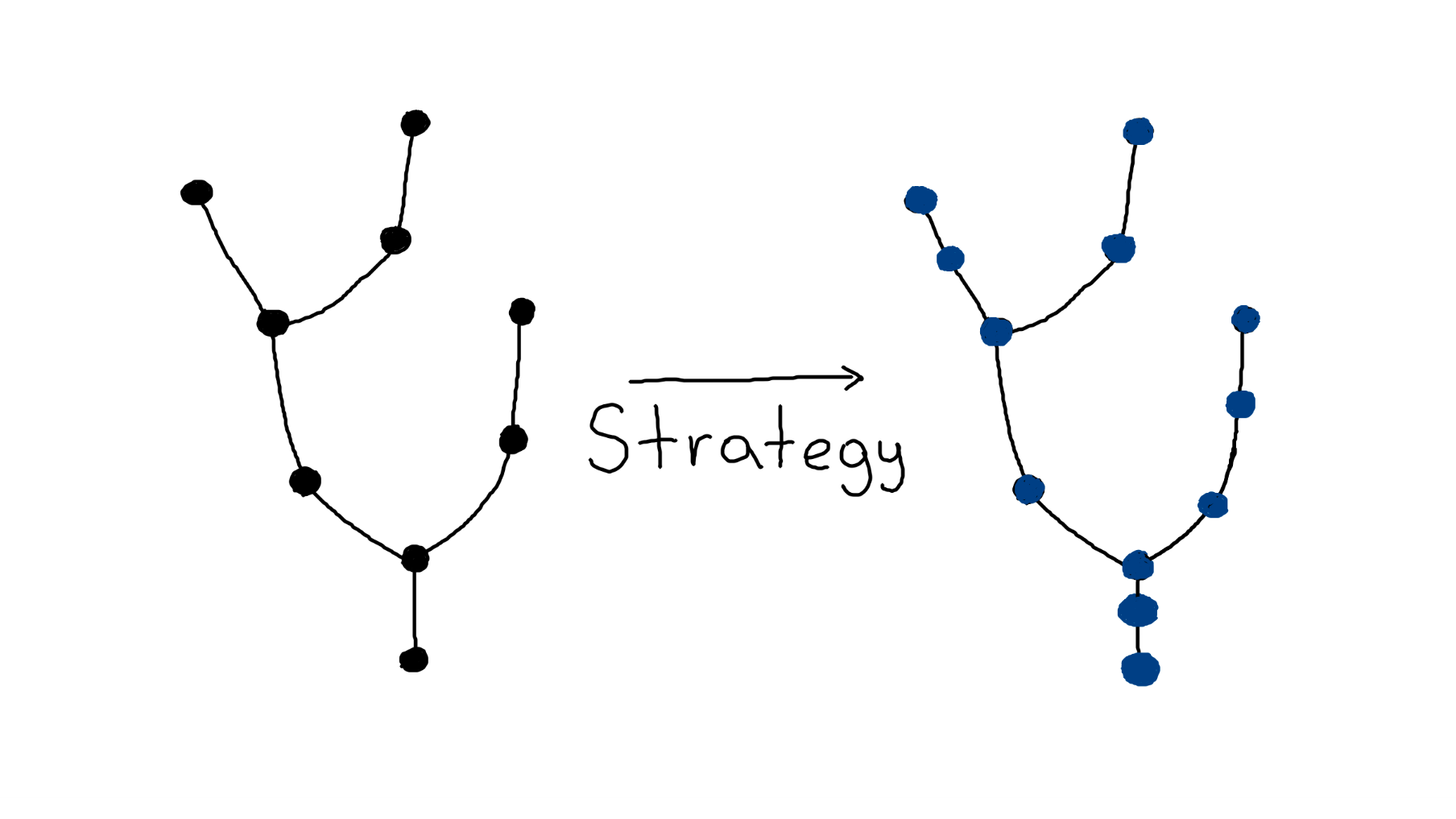
Наивное решение
С первого взгляда, будет достаточно встроиться в этот этап — добавить стратегию, которая среагирует на отсортированный Scan и добавит перед ним вершину FakeSort (подобную SortExec, но без реальной работы), а Scan оставит в исходном виде, оставляя его преобразование Spark’у.
Грабли: зацикливание событий
После добавления вышеописанной стратегии наблюдается следующее поведение. Spark при создании физического плана заметит Scan и обратится ко всем стратегиям для поиска возможного преобразования логической вершины в физическую. Воспользовавшись нашей стратегией, Spark добавит в план FakeSort, оставляя Scan в исходном виде.
На следующем шаге Spark снова обнаружит непреобразованный Scan.

Просмотрев доступные стратегии, Spark снова воспользуется нашей новой стратегией и добавит ещё одну вершину FakeSort. И так будет продолжаться бесконечно…
По итогу мы зациклили планировщик, из-за чего не работает абсолютно ничего.
Добавляем правило
Чтобы это обойти, нужно вспомнить, что чуть раньше мы говорили о правилах. Давайте создадим своё правило, которое будет встраивать некую пометку сортированности SortMark (placeholder для FakeSort) на этапе оптимизации.
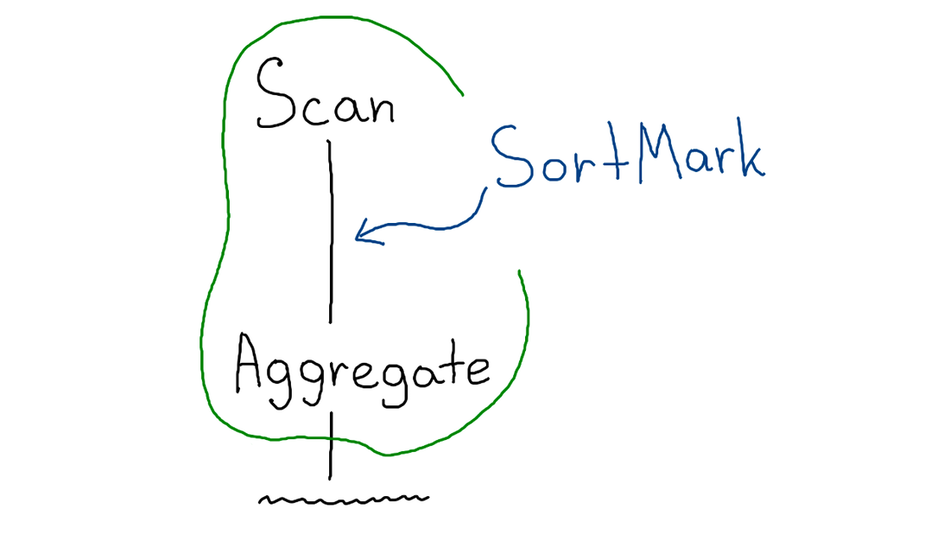
Правило ищет чтение, последующую агрегацию и добавляет пометку между ними. После чего стратегия материализует её в виде FakeSort.
Итоговый алгоритм выглядит так:
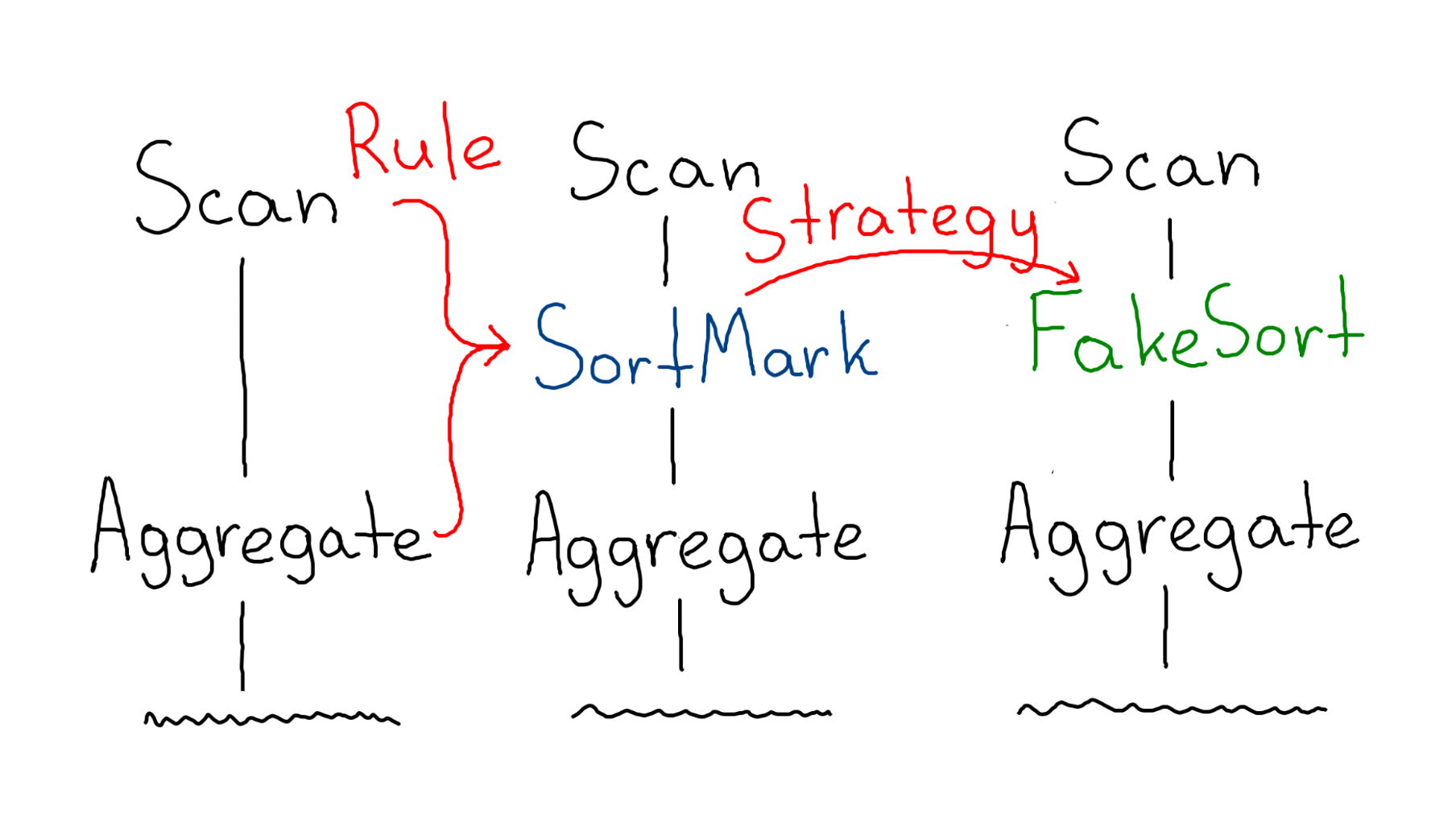
Так мы помогли планировщику, смогли вставить, что хотели, и это даже сработало. Но тут есть ещё одни грабли.
Грабли: дублирование
Мы обещали Spark, что данные будут поделены очень аккуратно, и мы отдадим их в том виде, в котором он хочет их представлять после шаффла. В частности вершина FakeSort декларировала гарантии, что строки с одинаковыми ключами попадут в одну партицию. Spark полностью доверяет обещанным гарантиям, и невыполнение ведет к неожиданному поведению.
Допустим, мы написали снова тот же запрос на сумму покупок пользователей. В начале, как я уже говорил, таблица делится на примерно одинаковые части. Если у нас есть 4 строчки, они поделятся пополам, и будут преобразованы на двух машинах независимо.

Spark посчитает сумму на обеих половинах и вернёт итог как объединение двух результатов. Получилось дублирование пользователя с id = 0. Для исправления этого бага нужно чуть‑чуть доработать чтение.
Обходим грабли
Изначально наша таблица делилась на примерно равные части. Но из‑за того, что ключи могут быть большими, в разные кусочки может попасть один и тот же пользователь. Тогда мы и видим дублирование результата.
Поэтому сделаем следующее: подвинем каждый желаемый распил партиций до ближайшей границы между ключами. К счастью, YTsaurus умеет это делать. Мы говорим ему читать от начала таблицы до первого упоминания зелёного ключа, потом от него до первого упоминания красного и т. д.
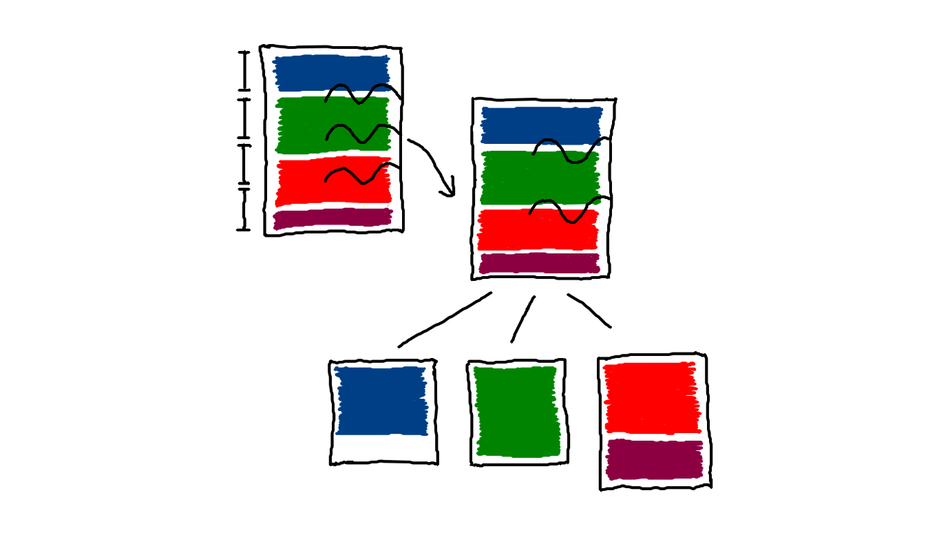
По итогу у нас каждый ключ лежит строго в одном кусочке таблицы. Агрегацию на этих кусочках можно проводить независимо.
Так мы победили агрегацию и превратили тяжеловесный шаффл в лёгкую операцию сортировки, которая на самом деле ничего не делает.

Join: правильное партиционирование
Мы уже обсудили, что возможность организовать себе шаффл появляется, когда пишутся агрегации, но это не единственный случай.
Join — это операция, которая объединяет две таблицы на основе общей колонки.
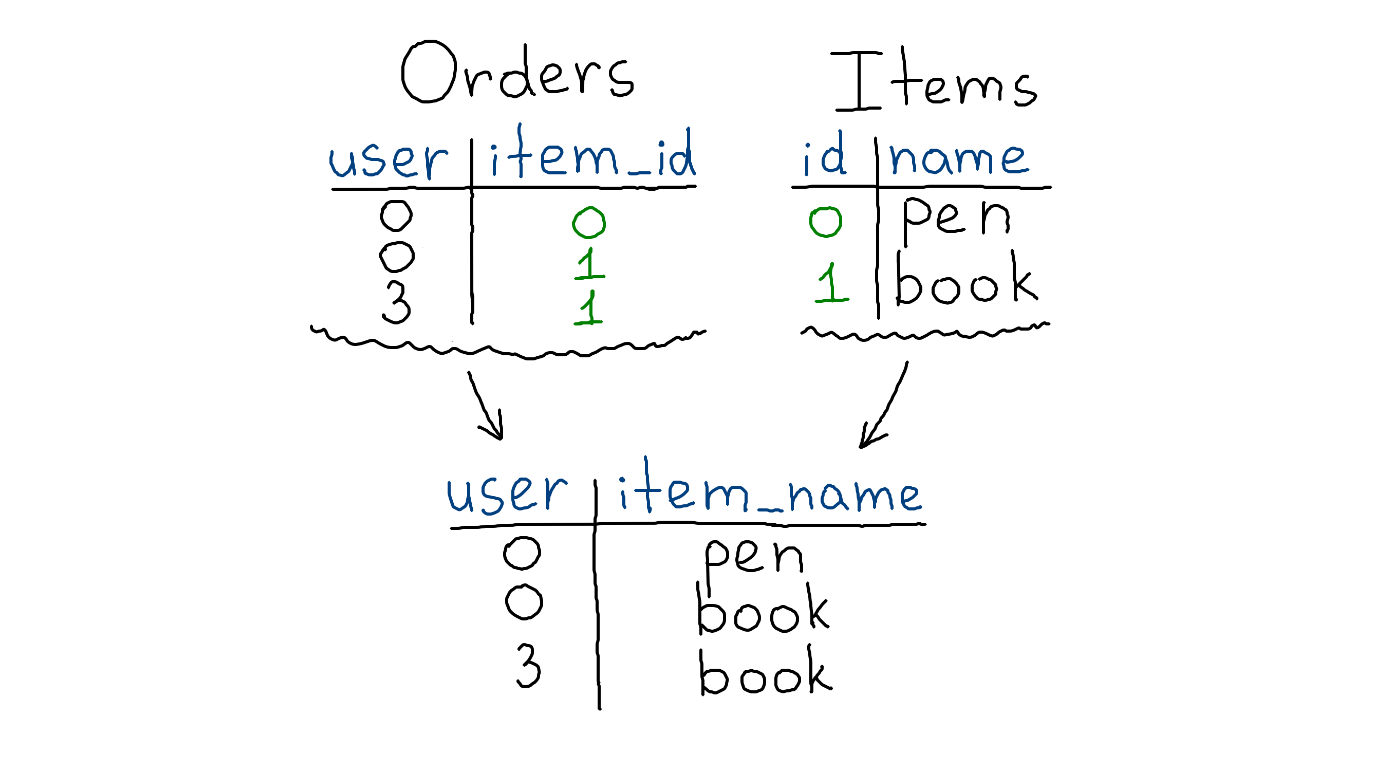
У нас есть заказы, где пользователь купил предмет с определенным id, а ещё есть таблица, где предмет с этим id имеет имя. Делаем Join и получаем информацию о том, какой пользователь какой предмет купил.
orders = spark.read.yt()
items = spark.read.yt()
orders
.join(items, item_id=id)
.write.yt()Физический план для такого случая получается непростым.

Мы написали всего один Join, а в плане видим множество всего.
В Join двух таблиц для каждой строки первой таблицы мы хотим искать соседа из второй. Если не сделать предобработку, то для поиска пары каждой строке первой таблицы будет осуществляться полный проход по второй таблице.
Spark добавил шаффл и сортировку каждой таблицы. Таблицы сначала шаффлятся по хэшу, после чего строки с одним ключом двух таблиц попадут в партицию с одним и тем же номером. Тогда соседа для каждой строки первой таблицы можно будет искать только в маленьком кусочке второй таблицы. А если мы добавим ещё и сортировку, тогда поиск можно делать ещё эффективнее с помощью продвинутых алгоритмов, например, алгоритма двух указателей.

Рассмотрим, как устроен Join.
class SortMergeJoinExec {
requiredChildOrdering: Seq[Seq[SortOrder]] =
leftKeys.map(SortOrder(_, Ascending)) ::
rightKeys.map(SortOrder(_, Ascending)) :: Nil
requiredChildDistribution: Seq[Distribution] =
HashClusterDistribution (leftKeys) ::
HashClusterDistribution (rightKeys) :: Nil
}Join хочет, чтобы левая и правая таблицы были отсортированы одинаково. Также он выдаёт требование на распределение, чтобы каждая таблица была нарезана по одинаковому хэшу.
И тут мы понимаем, что случаев у нас может быть много.

Агрегация — это что‑то более‑менее простое. Таблица всего одна и она либо не отсортирована, и тогда мы не пользуемся своей оптимизацией, либо отсортирована, тогда мы применяем оптимизацию.
Пускай одна таблица Join'а уже отсортирована, как нам надо. Вторая может быть тоже отсортирована тем же удовлетворительным способом, либо по совсем иным ключам, либо не отсортирована вовсе. Поэтому логично разбить дальнейшее повествование на две части:
Таблицы отсортированы одинаково, мы можем использовать оптимизацию для обеих таблиц.
Остальные случаи, когда нужно изобретать что‑то иное.
Join: таблицы отсортированы одинаково
Создадим вершину FakeShuffle, которая будет проецировать метаинформацию о партиционировании и порядке подобно FakeSort. Будем добавлять её к обеим таблицам.

Но мы опять чуть‑чуть слукавили в том, что таблицы должны быть поделены одинаково. Мы обещаем Join, что в кусочке с одним номером у первой таблицы и у второй будут одинаковые данные, поэтому нам нужно поделить обе таблицы синхронно.
Для этого мы смотрим, как делится первая таблица и как делится вторая, а затем объединяем набор ключей и говорим обеим таблицам: «делитесь вот так». Деление таблиц станет более мелким, но при этом — одинаковым.
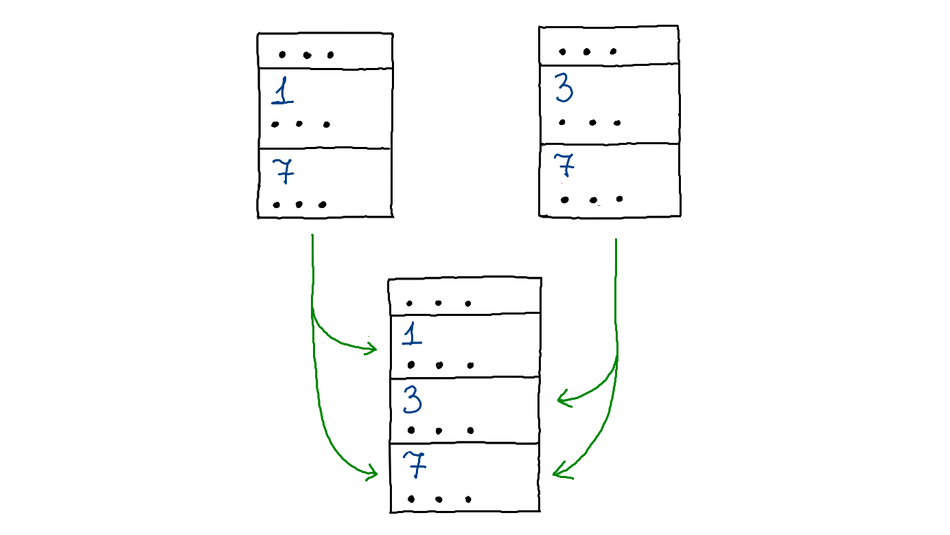
Тогда наши правило и стратегия выглядят так: с помощью правила находим Join источников данных, синхронизируем их чтение и добавляем пометку ShuffleMark. Затем стратегия превратит пометку в FakeShufle.
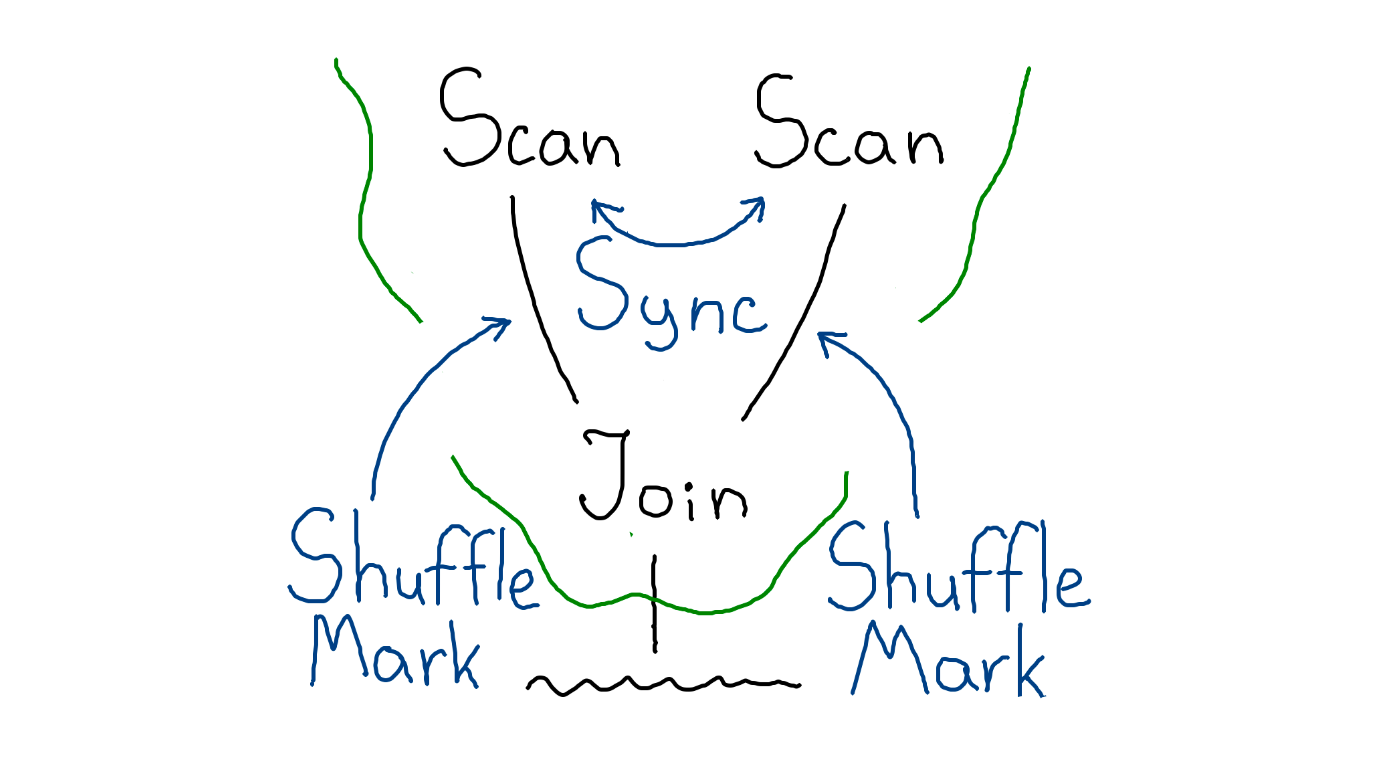
Join: остальные случаи
Остался ещё один случай, когда отсортирована необходимым образом только одна таблица, а вторую всё же необходимо пошаффлить. При этом шаффл должен опираться на деление первой таблицы, то есть быть «зависимым».

Зависимый шаффл
В общих словах зависимый шаффл работает так: проходим по строчкам второй таблицы, из каждой извлекаем ключ, по которому происходит Join. Далее узнаём, в какой партиции первая таблица содержит строки с таким ключом, и возвращаем полученный номер. Spark перераспределяет данные в указанные партиции.
class DependentHashShuffleExchangeExec {
def prepareShuffleDependency = {
return rdd.map {
row =>
key = getKey(dependentPartitioning, row)
partId = dependentPartitioner.getPart(key)
return (partId, row)
}
}
}Мы разобрались с шаффлом, то есть с тем, как поделить данные на кусочки. Но данные внутри каждой партиции ещё должны быть отсортированы. Однако здесь Spark сделает всё за нас, если мы честно укажем, что данные из нашего DependentShuffle выходят несортированные. И тогда на этапе построения физического плана произойдёт добавление SortExec вершины.

Весь алгоритм выглядит так:
Тесты производительности
Теперь нужно протестировать, как всё работает, для этого напишем несколько простых запросов.
# Sorted by [c1, c2, c3]
table1 = spark.read.yt()
table1
.groupBy('c1','c2')
.count()# Sorted by [c1, c2, c3]
table1 = spark.read.yt()
# Sorted by [c1, c2]
table2 = spark.read.yt()
table1.join(table2,
table1.c1==table2.c1 &
table1.c2==table2.c2)# Sorted by [c1, c2, c3]
table1 = spark.read.yt()
# Sorted by [c1, c2]
table2 = spark.read.yt()
table1.join(table2,
table1.c1==table2.c1 &
table1.c2==table2.c2 &
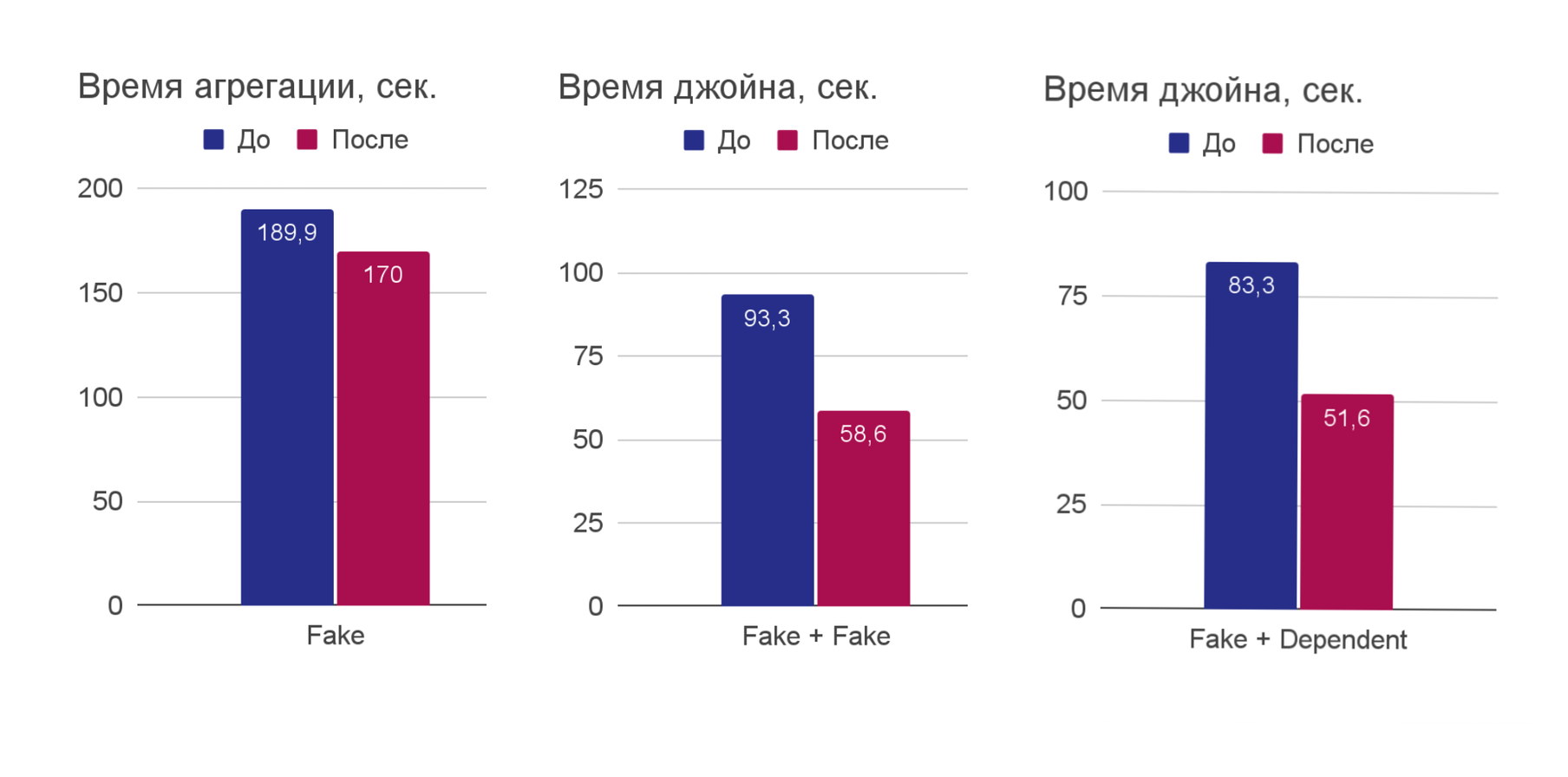
table1.c3==table2.c3)Время исполнения агрегации упало на 10% — неплохой результат, когда дело касается больших данных. Время исполнения обоих типов Join'a снизилось примерно на треть, а ведь в бизнес‑задачах соединять таблицы приходится часто.
Подведём итоги
Оптимизации позволили уменьшить время исполнения агрегаций на 10%, а Join — на 35% в некоторых кейсах!
Выжимайте из инструментов максимум, смотрите, как они устроены, что можно оптимизировать и как им помогать.
Попробуйте YTsaurus и SPYT, исходный код доступен в публичном репозитории YTsaurus.
Пишите свои вопросы здесь или мне в телеграм: @Alex2_000
iboltaev
По-моему, это имеет много общего с hyperspace : https://youtu.be/ofn53mT7H6c?si=AECulwQfvDVIygWL