
Добрый день, уважаемые ИТ-ники. На связи Михаил Голованов. В этом сезоне нашего Kafka шоу В статье я расскажу о реализации tiered storage в Apache Kafka. Теория будет перемежаться практикой.
Tiered storage в Кафка
Что такое tiered storage и зачем это Кафке
Концепция многослойного хранения данных довольно давно известна. Поступающие данные располагаются в первом "горячем" слое для онлайн обработки, постепенно вытесняясь в слой "холодных" данных. Как правило, слой холодных данных имеет более низкую стоимость за гигабайт, менее производителен,чем "горячий" слой, и может выступать в качестве хранилища для оффлайн обработки (операций с данными,не имеющих критичных требований к длительности выполнения).
До версии 3.6 брокера Kafka могли сохранять данные только в файлы на примонтированные к хосту дисковые массивы. Каждый брокер сохранял свои данные отдельно от других брокеров. Надежность хранения данных обеспечивалась репликацией между брокерами кластера.
В версии 3.6 Apache Kafka добавлена в режиме Early Access возможность использования tiered storage.
Реализация tiered storage в Apache Kafka 3.6 не является полнофункциональной и будет развиваться в последующих версиях.
Полнофункциональная реализация tiered storage была доступна в Confluent Kafka Enterprise (платная подписка) еще задолго до выхода Apache Kafka 3.6.Также и для Redpanda функциональность доступна только в платной версии продукта.
Каждый из брокеров кластера имеет возможность перенести "холодные" данные в tiered storage. Для всех брокеров tiered storage на логическом уровне является единой точкой записи/чтения данных. В качестве tiered storage может, например, использоваться S3 или другие распределенные хранилища.

При подключении нового брокера в кластер Kafka начинается процесс репликации данных партиций топиков на подключенный брокер. Аналогичный процесс происходит, если брокер становится лидером или фолловером партиции топика и на нем до этого не было данных партиции.При больших размерах данных в партиции процесс первоначальной "проливки" данных может занимать значительное время, что приводит к неудобствам эксплуатации больших кластеров с длительным хранением данных.Наличие tiered storage способно улучшить ситуацию, так как логически имеет одну точку входа для всех брокеров кластера и вместо создания локальной копии данных достаточно сменить брокера-владельца данных.
Наличие tiered storage позволяет:
организовать долговременное хранение данных во внешних хранилищах
разделить передачу данных онлайн читателям и обработку данных "batch" читателями
упростить эксплуатацию больших кластеров Kafka с длительным хранением данных
В дальнейшем в статье будут использоваться следующие термины и определения (если вы знакомы с терминологией Kafka, раздел можно пропустить):
Tiered storage: Многослойное хранение. Концепция разделения персистентного слоя хранения информации на несколько последовательно расположенных слоев.
Kafka: Брокер сообщений Apache Kafka
Topic (Топик): Именованный канал публикации информации в кластер Kafka. Состоит из разделов (partition).
Partition (раздел): Топик состоит из разделов, т.е всегда содержит хотя бы один раздел. Разделы нумеруются, начиная с 0.Раздел является элементом масштабирования и репликации топика.Разделы управляются брокерами Kafka.
Segment (сегмент): Часть партиции, отвечающая за физическое хранение сообщений. При хранении данных в локальной файловой системе представляет собой файл с сообщениями. При поступлении сообщений брокер Kafka записывает их в текущий сегмент. При достижении предельного размера сегмента брокер Kafka создает новый сегмент. При истечении времени жизни сообщений и/или достижении максимального размера партиции топика брокер удаляет старые сегменты.
Index (индекс): Файл или набор файлов для организации быстрого поиска сообщений по какому-либо признаку, например, по времени записи или смещению в разделе топика.
Message offset (смещение сообщения): Сообщения в разделе топика записываются в виде лога (последовательности). Каждое сообщение в разделе топика идентифицируется числом, называемым смещением сообщения (message offset). При записи смещения сообщений непрерывно нарастают.
Start topic partition offset (начальное смещение раздела топика): Смещение первого хранящегося в разделе сообщения.
-
End topic partition offset (конечное смещение раздела топика): Смещение последнего хранящегося в партиции сообщения.
Архитектура подсистемы tiered storage
Цель реализации
Реализация разработчиками Apache Kafka велась в рамках проработки KIP-405. Продолжение разработки ведется в рамках задачи KAFKA-15420.
Goals
Extend Kafka's storage beyond the local storage available on the Kafka cluster by retaining the older data in an external store, such as HDFS or S3 with minimal impact on the internals of Kafka. Kafka behavior and operational complexity must not change for existing users that do not have tiered storage feature configured.
Цель реализации
Расширить возможности подсистемы хранения данных Kafka за пределы локального хранения данных в кластере обеспечив вытеснения более старых данных во внешнее хранилище, такое как HDFS или S3 с минимальным влиянием на внутреннее устройство Kafka. Поведение Kafka и сложность сопровождения не должны ухудшиться для текущих пользователей, не использующих многослойное хранение.
Высокоуровневый дизайн

Для реализации tiered storage появляются новые компоненты:
Remote Log Manager (RLM)
Remote Log Metadata Manager (RSM)
Remote Storage Manager
Remote Log Manager расширяет функционал существующего в Kafka Log Manager
следит за поведением лидеров партиций на брокере, обеспечивая работу с локально хранящимися данными (аналогично Log Manager)
делегирует копирование, чтение и удаление сегментов партиций топика во внешнем хранилище (remote storage) подключаемой реализации RemoteStorageManager
делегирует поддержку метаданных сегментов партиций топика во внешнем хранилище RemoteLogMetadataManager-у.
RemoteLogManager внутренний компонент и не имеет публичного API.
Remote Storage Manager интерфейс для реализации жизненного цикла **сегментов и индексов** во внешнем хранилище. В будущем разработчики Apache Kafka могут предоставить простую реализацию RSM для целей лучшего понимания API. Реализация HDFS и S3 планируются вне репозитария кода Kafka, т.е во внешних репозитариях. Подход будет аналогичен используемому для Kafka connectors.
RemoteLogMetadataManager интерфейс для реализации жизненного цикла метаданных сегментов во внешнем хранилище с семантикой строгой консистентности. Предоставляется по умолчанию реализация, использующая внутренний топик. Пользователи могут подключать собственные реализации, использующие другие механизмы хранения.
Реализация Remote Storage Manager
Итак, в составе Apache Kafka 3.6 имеются реализации Remote Log Manager и RemoteLogMetadataManager. Реализация Remote Storage Manager на момент выхода версии 3.6 присутствует только как пример хранения "холодных" данных в локальной файловой системе. Такая реализация пригодна лишь для начального учебного ознакомления.
Обратимся к волшебной силе opensource.
На Github имеется реализация для Azure Blob Storage, а также репозиторий Avien Open, содержащий реализации для локальной файловой системы (для непромышленного использования) и S3 в вариантах Google Cloud, AWS и Minio, а также Azure Blob Storage.
В дальнейшем для экспериментов будут использоваться реализации Avien Open для локальной файловой системы и Minio, так как они пригодны для развертывания на локальной машине (ноутбуке) и не требуют доступа к внешним облачным провайдерам, при этом позволяют достаточно подробно ознакомиться с подходами к реализации tiered storage.
Пора запускать код
Пререквизиты
Проводить смелый инженерный эксперимент будем на Manjaro Linux, так как я пользуюсь именно этой версией Linux. Для скачивания дистрибутива Apache Kafka и исходных текстов реализации Remote Storage Manager от Avien Open понадобится доступ к интернет.
Шаг 1. Разворачиваем одноузловой кластер Кафка
1. Скачиваем дистрибутив Kafka 3.6.0 для Linux с сайта Apache Kafka.
2. Разархивируем дистрибутив. Папку можно выбрать по своему усмотрению. В терминале запускаем команду tar xvzf kafka_2.13-3.6.0.tgz
3. В папке kafka_2.13-3.6.0 создаем папки для хранения данных Zookeeper, Kafka и remote storagemkdir -p ./data/zk
mkdir -p ./data/kafka
mkdir -p ./data/fs_storage
4. Настраиваем и запускаем zookeeper.
В подпапке ./config в файле zookeeper.properties прописываем путь для хранения файлов dataDir=./data/zk
Файл ./config/zookeeper.properties
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# the directory where the snapshot is stored.
dataDir=./data/zk
# the port at which the clients will connect
clientPort=2181
# disable the per-ip limit on the number of connections since this is a non-production config
maxClientCnxns=0
# Disable the adminserver by default to avoid port conflicts.
# Set the port to something non-conflicting if choosing to enable this admin.enableServer=false
# admin.serverPort=8080
Запускаем zookeeper из терминала из корневой папки установки Kafka./bin/zookeeper-server-start.sh -daemon ./config/zookeeper.properties
5. Настраиваем и запускаем Kafka.
В подпапке ./config в файле server.properties прописываем путь для хранения файловlog.dirs=./data/kafka
Запускаем Kafka брокер./bin/kafka-server-start.sh -daemon ./config/server.properties
6. Проверяем список топиков./bin/kafka-topics.sh --bootstrap-server localhost:9092 --list
Команда должна выдать пустой список топиков.
Шаг2. Собираем код реализации Remote Storage Manager Aiven Open для работы с локальной файловой системой
Необходимо клонировать git repo Aiven-Open/tiered-storage-for-apache-kafka
git clone https://github.com/Aiven-Open/tiered-storage-for-apache-kafkaСкомпилировать код
./gradlew build
И тут меня ждали небольшие приключения.
Первое приключение - для сборки на Linux хосте должен быть развернут Docker. Решилось довольно просто: погуглил, почитал, развернул Docker, заработало.
Второе приключение посложнее. E2E (End-to-End) тесты требуют наличия в DockerHub базового образа aivenoy..., а его там нет. Решил долго не разбираться, а отключить E2E тесты. Для этого в файле settings.gradle, который находится в корневой папке исходных текстов, закомментировал строку:// include 'e2e'
Далее проблем не было и сборка завершилась успешно.
Шаг 3. Добавляем библиотеки с Remote Storage Manager в Kafka.
После завершения сборки комплект библиотек для RSM локальной файловой системы расположен в подпапке build/distributions в виде архивов tiered-storage-for-apache-kafka-0.0.1-SNAPSHOT.tgz и tiered-storage-for-apache-kafka-0.0.1-SNAPSHOT.zip.
Необходимо разархивировать файл tiered-storage-for-apache-kafka-0.0.1-SNAPSHOT.tgz и скопировать результат в подпапку ./libs брокера Kafka.
Далее необходимо остановить брокер Кафка и перейти к следующему шагу включению поддержки tiered storage в брокере.
Остановка брокера выполняется командой из корневой папки установки Kafka./bin/kafka-server-stop.sh
Шаг 4. Включаем в Kafka поддержку tiered storage.
Необходимо модифицировать файл ./config/server.properties в брокере Kafka.
Hidden text
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# This configuration file is intended for use in ZK-based mode, where Apache ZooKeeper is required.
# See kafka.server.KafkaConfig for additional details and defaults
# ############################# Server Basics #############################
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=0
############################# Socket Server Settings #############################
# The address the socket server listens on. If not configured, the host name will be equal to the value of
# java.net.InetAddress.getCanonicalHostName(), with PLAINTEXT listener name, and port 9092.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
#listeners=PLAINTEXT://:9092
# Listener name, hostname and port the broker will advertise to clients.
# If not set, it uses the value for "listeners".
#advertised.listeners=PLAINTEXT://your.host.name:9092
# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
#listener.security.protocol.map=PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
# The number of threads that the server uses for receiving requests from the network and sending responses to the network
num.network.threads=3
# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8
# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400
# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400
# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600
############################# Log Basics #############################
# A comma separated list of directories under which to store log files
# Changed line
log.dirs=./data/kafka
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=1
# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1
############################# Internal Topic Settings #############################
# The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"
# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
# Changed block start
offsets.topic.num.partitions=1
# Changed block end
# Disable auto create topics
# Changed line
auto.create.topics.enable=false
############################# Log Flush Policy #############################
# Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# 1. Durability: Unflushed data may be lost if you are not using replication.
# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis.
# The number of messages to accept before forcing a flush of data to disk #log.flush.interval.messages=10000
# The maximum amount of time a message can sit in a log before we force a flush #log.flush.interval.ms=1000
############################# Log Retention Policy #############################
# The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens # from the end of the log.
# The minimum age of a log file to be eligible for deletion due to age
#Changed line
log.retention.hours=1
# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
#log.segment.bytes=20000
#log.segment.delete.delay.ms=1000
#log.index.size.max.bytes=200
#log.roll.hours=1
#log.roll.ms=10000
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
# Changed line
log.retention.check.interval.ms=10000
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=localhost:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=18000
############################# Group Coordinator Settings #############################
# The following configuration specifies the time, in milliseconds, that the GroupCoordinator will delay the initial consumer rebalance.
# The rebalance will be further delayed by the value of group.initial.rebalance.delay.ms as new members join the group, up to a maximum of max.poll.interval.ms.
# The default value for this is 3 seconds.
# We override this to 0 here as it makes for a better out-of-the-box experience for development and testing.
# However, in production environments the default value of 3 seconds is more suitable as this will help to avoid unnecessary, and potentially expensive, rebalances during application startup. group.initial.rebalance.delay.ms=0
# Changed block start
############################# Remote log Settings #############################
# Enable Tiered Storage
remote.log.storage.system.enable=true
remote.log.manager.task.interval.ms=5000
# Remote metadata manager configs
remote.log.metadata.manager.class.name=org.apache.kafka.server.log.remote.metadata.storage.TopicBasedRemoteLogMetadataManager
remote.log.metadata.manager.impl.prefix=rlmm.config.
remote.log.metadata.manager.listener.name=PLAINTEXT
rlmm.config.remote.log.metadata.topic.replication.factor=1
rlmm.config.remote.log.metadata.topic.num.partitions=1
# Remote storage manager configs
remote.log.storage.manager.class.name=io.aiven.kafka.tieredstorage.RemoteStorageManager
remote.log.storage.manager.impl.prefix=
rsm.config. rsm.config.chunk.size=100
rsm.config.chunk.cache.class=io.aiven.kafka.tieredstorage.chunkmanager.cache.InMemoryChunkCache
rsm.config.chunk.cache.size=20000
rsm.config.chunk.cache.retention.ms=1000
rsm.config.custom.metadata.fields.include=REMOTE_SIZE
# Storage backend configs
rsm.config.key.prefix=tiered-storage-demo/
rsm.config.storage.backend.class=io.aiven.kafka.tieredstorage.storage.filesystem.FileSystemStorage
rsm.config.storage.root=./data/fs_storage
# Changed block end
Внесенные изменения можно найти поиском по `# Changed`
Ниже приведено подробное описание изменений конфигурации Kafka.
offsets.topic.num.partitions=1
Устанавливаем количество партиций внутреннего топика смещений групп читателей (__offsets). Просто меньше создаетсяфайлов в папке data/kafka при подключении читателейНапрямую не относится к RSM.
Настройка для удобства отслеживаниячеловеком создаваемых брокером Kafka файлов.auto.create.topics.enable=false
Запрет на автоматическое создание топиков при попытках записи/чтения.
Хорошая практика для поддержания порядка в кластере, топики явно создаются только командами.log.retention.hours=1
Время хранения данных в топиках по умолчанию. Может переопределяться для каждого топика индивидуально. Напрямую не относится к RSM.
Значение по умолчанию равно 168 часов. По моему мнению, для задач разработки и исследований 1 часа вполне достаточно. Хорошей практикой является задание параметров длительности хранения индивидуальнопри создании каждого топика.log.retention.check.interval.ms=10000
Интервал проверки устаревания данных в сегментах разделов топиков.Напрямую не относится к RSM.
Значение в 10 секунд слишком мало для нагруженного кластера с большим количеством топиков, разделов и сегментов. Значение 10 секунд требуется для наблюдения работы RSM в ходе нашего исследования.Важные для работы tiered storage настройки. Включения поддержки tiered storage
# Enable Tiered StorageВключают на уровне брокера Kafka поддержку tiered storage (использование RLM) и устанавливают интервал запуска задач RLM равным 5 секундам для наблюдения в ходе нашего исследования.
remote.log.storage.system.enable=true remote.log.manager.task.interval.ms=5000Настройки Remote Log Metadata Manager
# Remote metadata manager configs remote.log.metadata.manager.class.name=org.apache.kafka.server.log.remote.metadata.storage.TopicBasedRemoteLogMetadataManager remote.log.metadata.manager.impl.prefix=rlmm.config. remote.log.metadata.manager.listener.name=PLAINTEXT rlmm.config.remote.log.metadata.topic.replication.factor=1 rlmm.config.remote.log.metadata.topic.num.partitions=1
remote.log.metadata.manager.class.name подключает встроенную реализацию RLMM на базе топиков
remote.log.metadata.manager.impl.prefix префикс настроек, специфичных для реализации Remote Log Metadata Manager
Специфичные для Remote Metadata Manager на базе внутреннего топика Kafka настройки:
rlmm.config.remote.log.metadata.topic.replication.factor фактор репликации топика Remote Metadata Manager
rlmm.config.remote.log.metadata.topic.num.partitions количество партиций топика Remote Metadata Manager-
Настройки Remote Storage Manager
# Remote storage manager configs remote.log.storage.manager.class.name=io.aiven.kafka.tieredstorage.RemoteStorageManager remote.log.storage.manager.impl.prefix=rsm.config. rsm.config.chunk.size=100 rsm.config.chunk.cache.class=io.aiven.kafka.tieredstorage.chunkmanager.cache.InMemoryChunkCache rsm.config.chunk.cache.size=20000 rsm.config.chunk.cache.retention.ms=1000 rsm.config.custom.metadata.fields.include=REMOTE_SIZE # Storage backend configs rsm.config.key.prefix=tiered-storage-demo/ rsm.config.storage.backend.class=io.aiven.kafka.tieredstorage.storage.filesystem.FileSystemStorage rsm.config.storage.root=./data/fs_storageНаиболее важные настройки:
rsm.config.storage.root путь к папке размещения данных tiered storage Настраиваем логирование работы RSM в отдельный файл
Для чего в файл ./config/log4j.properties в конец добавляем строки#Tiered storage configs log4j.appender.tieredStorageAppender=org.apache.log4j.DailyRollingFileAppender log4j.appender.tieredStorageAppender.DatePattern='.'yyyy-MM-dd-HH log4j.appender.tieredStorageAppender.File=${kafka.logs.dir}/tiered_storage.log log4j.appender.tieredStorageAppender.layout=org.apache.log4j.PatternLayout log4j.appender.tieredStorageAppender.layout.ConversionPattern=[%d] %p %m (%c)%n log4j.logger.io.aiven.kafka.tieredstorage=DEBUG, tieredStorageAppender log4j.additivity.io.aiven.kafka.tieredstorage=falseЗапускаем брокер Kafka
./bin/kafka-server-start.sh -daemon ./config/server.properties
Если все сделано правильно, то в файлах лога работы брокера ./logs/server.log не будет записей уровня ERROR и будет присутствовать запись '[KafkaServer id=0] started (kafka.server.KafkaServer)'Проверяем, что RLMM создал внутренний топик
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --list__remote_log_metadata
Появился топик __remote_log_metadata.
Просмотрим параметры топика../bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic __remote_log_metadataTopic: __remote_log_metadata
TopicId: 9vsdpBeVT2qjo39a49JPTw PartitionCount: 1
ReplicationFactor: 1 Configs: cleanup.policy=delete,retention.ms=-1
Topic: __remote_log_metadata Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Шаг 5. Создаем топик для чтения/записи данных
./bin/kafka-topics.sh --create --topic tieredTopic --bootstrap-server localhost:9092 \Появился топик tieredTopic.
--config remote.storage.enable=true \
--config local.retention.ms=1000 \
--config retention.ms=300000 \
--config segment.bytes=200
Created topic tieredTopic.
* Параметр remote.storage.enable=true указывает, что для топика необходимо включить поддержку tiered storage.
* Параметр local.retention.ms=1000 указывает, что Кафка должна хранить "горячие" данные одну секунду, после чего вытеснять их после ротации сегмента в "холодное хранилище".
* Параметр retention.ms=300000 указывает суммарное время хранения данных 300 секунд (5 минут)
* Параметр config segment.bytes=200 устанавливает размер сегмента в 200 байт. Не стоит так делать в промышленной эксплуатации. Но для эксперимента нужно обеспечить частую ротацию сегментов при записи в топик.
Шаг 6. Пишем/читаем сообщения, осторожно наблюдаем работу tiered storage
Записываем сообщения в топик tieredTopic./bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --sync --topic tieredTopic
>m1
>m2
>m3
>m4
>m5
>m6
>^C
И на фоне звучит победная мелодия наблюдаем, что появилась папка (с содержимым) ./data/fs_storage/tiered-storage-demo
Это значит, что мы настроили все правильно (но это не точно) и сообщения после хранения в течение 1 секунды начали перемещаться в local fs tiered storage, где будут храниться до истечения 5 минут.
Более того, сообщения могут быть прочитаны.
kafka_2.13-3.6.0_local_fs./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic tieredTopic --from-beginninging
m1
m2
m3
m4
m5
m6
^C
Processed a total of 6 messages
Краткие промежуточные итоги
Практический результат
Подсистема tiered storage запустилась и начала работать в варианте хранения в локальной файловой системе.
Функциональность
Текущая реализация имеет уровень зрелости Early Access со следующими ограничениями
Не поддерживается режим сохранения данных в множественные папки (JBOD feature)
Не поддерживается работа с компактыми топиками (compacted topics)
Невозможно отключить режим tiered storate после включения на уровне топика
Перед отключением tiered storage на уровне брокера Kafka небходимо удалить топики с поддержкой tiered storage
Действия, связанные с администрированием tiered storage в Kafka, доступны клиентам версии 3.0 и выше.
Более полная информация https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Tiered+Storage+Early+Access+Release+Notes
Заходим поглубже в реализацию
Попробуем поподробнее разобраться с работой Remote Log Manager и понять зачем было произведеноразделение на Log Segment Store и Log Metadata Store.
Данные сегмента партиции топика
Заглянем в папку хранения локального сегмента партиции (топик был настроен так, что имеет одну партицию) топика tieredTopic.
ls ./data/kafka/tieredTopic-0

Данные сегмента хранятся в файлах с расширением log.
В имени файла сегмента зашита метаинформация о message offset начального сообщения - segment start offset.
Имя файла с данными следующего сегмента позволяет легко понять message offset последнего сообщения предыдущего полностью заполненного данными сегмента (отняв единичку) - segment end offset.
Для каждого сегмента существует еще два файла (имена файлов совпадают с именем файла данных сегмента):
с расширением index - индекс данных по message offset
с расширением timeindex - индекс данных по времени записи сообщения
Таким образом на скриншоте выше в файле с именем 00000000000000000000.log хранятся сообщения со смещениями 0 и 1.В файле 00000000000000000000.index хранится индекс по смещению, а в файле 00000000000000000000.timeindex индекс по времени.
Наличие индексов по смещениям и времени записи позволяет Kafka consumer быстро перемещать указатель чтения на нужное сообщение (методы seek и offsetsForTimes).
Более подробно про файлы сегмента (на английском)
Чтобы не поломать механизм поиска сообщений в партиции при
реализации tiered storage нужно сохранять не только данные, но и индексы,
вытесняемых в удаленное хранилище сегментов.
Метаданные сегмента партиции топика.
Помимо данных необходимо консистентно сохранять и метаданные:
Список и координаты переданных в удаленное хранилище сегментов (данных и индексов)
Для сегментов, находящихся в процессе вытеснения в удаленное хранилище, состояние процесса передачи
Разделение хранения данных и метаданных
Далее приведу свой немного вольный перевод части KIP-405, касающейся Remote Log Manager (RLM) и выделения отдельного компонента Remote Log Metadata Manager.
RLM создает задания для каждого лидера и фолловера партиции.
RLM Leader Task
Отслеживает ротацию сегмента (который имеет last message offset меньше, чем last stable offset партиции) и копирует сегмент с индексами offset/time/transaction/producer-snapshot и информацией о leader epoch cache в удаленное хранилище. Также обслуживает запросы на получение вытесненных в удаленное хранилище данных Локальные данные с брокера Kafka не удалятся пока не завершится перенос в удаленное хранилище даже если время жизни данных уже истекло.RLM Follower Task
Наблюдает за файлами данных и индексов в удаленном хранилище с помощью Remote Log Metadata Manager. Также при необходимости осуществляет вычитку данных из удаленного хранилища.
RLM поддерживает кэш ограниченного размера (возможно, LRU) индексных файлов удаленного хранилищадля избежания многочисленных чтений из удаленного хранилища. Файлы кеша хранятся в подпапке remote-log-index-cache папки хранения данных брокером Kafka. Эти индексы используются таким же образом как индексы локальных сегментов (не вытесненных в удаленное хранилище).
Пользователь может сконфигурировать общий размер файлов кэша индексных файлов удаленного хранилища, установив параметр remote.log.index.file.cache.total.size.mb.
В первых реализациях метаданные сегментов сохранялись вместе с данными в удаленном хранилище. Такой подход хорошо работает для хранилищ на базе, например, HDFS.
Одной из проблем такой реализации является необходимость поддерживать в удаленном хранилищестрогую консистентность данных и метаданных. Это влияет не только на операции с метаданными(LIST in S3), но и на операции с данными (GET после DELETE в S3). Так же необходимо принять во внимание стоимость хранения метаданных в удаленном хранилище. В случае S3 частое использование LIST API влечет за собой высокие затраты.
По вышеуказанным причинам хранение метаданных было отделено от данных в удаленном хранилищепутем выделения Remote Log Metadata Manager.
Верхнеуровневый взгляд на процесс записи/удаления данных в удаленное хранилище
Процесс представлен в виде sequence диаграммы ниже.

RLM - Remote Log Manager
RLLMM - Remote Log Metadata Manager
RSM - Remote Storage Manager
Удаление данных из хранилища происходит по аналогичному сценарию.
За счет того, что процесс работы с Remote Log Metadata Manager асинхронный, RLMM может менять состоянияследующим образом:

Процесс удаления локального сегмента выполняется асинхронно после копирования сегмента в удаленное хранилище.
Соответственно, некоторое время часть данных партиции топика находится одновременно и в локальном и вудаленном хранилище, как показано на рисунке.
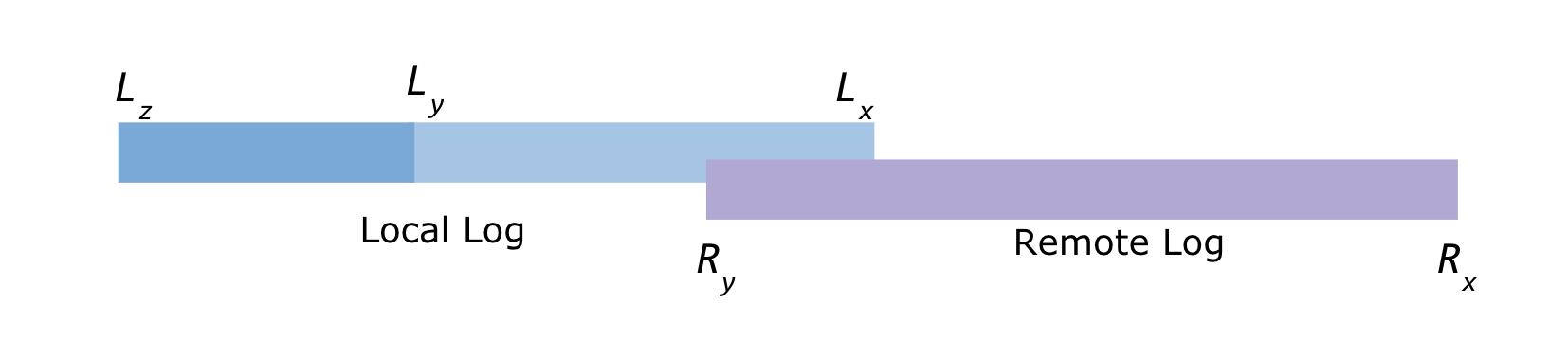
Lx = Local log start offset
Lz = Local log end offset
Ly = Last stable offset(LSO)
Ry = Remote log end offset
Rx = Remote log start offset
Lz >= Ly >= Lx and Ly >= Ry >= Rx
Чтение данных из удаленного хранилища
При запросе на чтение данных от consumer-aброкер Kafka понимает находятся ли читаемые данные в локальном или удаленном хранилище.
Если все или часть читаемых данных расположены в удаленном хранилище, то происходит вычитка в память брокера необходимых сегментов данных из удаленного хранилища. Вычитанные сегменты кешируются брокером.
Далее формируется пакет с запрошенными данными для отправки consumer-у. Consumer не подозревает о том взяты ли данные из локального или удаленного хранилища.
Ныряем в реализацию Remote Log Metadata Manager
Слова дешевы, покажите ваш код
Любая реализация RLMM должна имлементироватьинтерфейс org.apache.kafka.server.log.remote.storage.RemoteLogMetadataManager.
Apache Kafka 3.6.0 предоставляет реализацию Remote Log Metadata Manager на базе топика. Реализация в исходном коде расположена вклассе org.apache.kafka.server.log.remote.metadata.storage.TopicBasedRemoteLogMetadataManager.
Как мы уже видели ранее, при старте кластера Kafka с включенным tiered storage былсоздан топик __remote_log_metadata. В топике хранятся метаданные процесса переноса сегментов в удаленное хранилище.
Конечно, же первым делом, мне захотелось посмотреть на содержимое топика.
Тук-тук, кто в топике живет?
Нет ничего сложного в чтении данных из топика. Запустим консольного читателя Kafka.
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic __remote_log_metadata \
--from-beginning
В терминал посыпались вычитываемые сообщения вида tieredTopic$�8��4MB�+�7���i��D��aN8a/_Ą��*��. Читать и понимать такое по силам только легендарным хакерам. И это не мой случай.
Слегка изучив код, становится понятно, что в топик сериализуются наследники класса org.apache.kafka.server.log.remote.storage.RemoteLogMetadata:
RemoteLogSegmentMetadata - описывает состояние метаданных сегмента. Новые экземпляры создаются с состоянием COPY_SEGMENT_STARTED
RemoteLogSegmentMetadataUpdate - описывает обновление состояния метаданных сегмента.
RemoteLogSegmentMetadataSnapshot - снимок состояния метаданных сегмента
RemotePartitionDeleteMetadata - описывает состояние метаданных удаления партиции топика.
Все наследники имеют реализацию метода toString с выводом информации об их полях.
Запись/чтение топика происходит с помощью инкапсулированных в TopicBasedRemoteLogMetadataManager продьюсера и консьмера.
Очень хочется посмотреть на содержимое топика в человекочитаемом формате. Поскольку для продюсера и консьюмера можно с помощью конфигов подгрузить свою реализацию serializerи deserializer, именно так я решил и поступить. Но если повнимательнее посмотреть на реализацию метода initializeProducerConsumerProperties класса org.apache.kafka.server.log.remote.metadata.storage.TopicBasedRemoteLogMetadataManagerConfig, которая приведена ниже.
private void initializeProducerConsumerProperties(Map<String, ?> configs) {
Map<String, Object> commonClientConfigs = new HashMap<>();
Map<String, Object> producerOnlyConfigs = new HashMap<>();
Map<String, Object> consumerOnlyConfigs = new HashMap<>();
for (Map.Entry<String, ?> entry : configs.entrySet()) {
String key = entry.getKey();
if (key.startsWith(REMOTE_LOG_METADATA_COMMON_CLIENT_PREFIX)) {
commonClientConfigs.put(
key.substring(
REMOTE_LOG_METADATA_COMMON_CLIENT_PREFIX.length()),
entry.getValue()
);
} else if (key.startsWith(REMOTE_LOG_METADATA_PRODUCER_PREFIX)) {
producerOnlyConfigs.put(
key.substring(
REMOTE_LOG_METADATA_PRODUCER_PREFIX.length()),
entry.getValue()
);
} else if (key.startsWith(REMOTE_LOG_METADATA_CONSUMER_PREFIX)) {
consumerOnlyConfigs.put(
key.substring(
REMOTE_LOG_METADATA_CONSUMER_PREFIX.length()),
entry.getValue()
);
}
}
commonProps = new HashMap<>(commonClientConfigs);
HashMap<String, Object> allProducerConfigs = new HashMap<>(commonClientConfigs);
allProducerConfigs.putAll(producerOnlyConfigs);
producerProps = createProducerProps(allProducerConfigs);
HashMap<String, Object> allConsumerConfigs = new HashMap<>(commonClientConfigs);
allConsumerConfigs.putAll(consumerOnlyConfigs);
consumerProps = createConsumerProps(allConsumerConfigs);
}
то мы видим, что для продюсера из конфига прогружаются общие свойства, затем специфичные для записи и в конце следует вызов метода createProducerProps.
private Map<String, Object> createProducerProps(HashMap<String, Object> allProducerConfigs) {
Map<String, Object> props = new HashMap<>(allProducerConfigs);
props.put(
ProducerConfig.CLIENT_ID_CONFIG,
clientIdPrefix + "_producer"
);
props.put(ProducerConfig.ACKS_CONFIG, "all");
props.put(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION, 1);
props.put(
ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
ByteArraySerializer.class.getName()
);
props.put(
ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
ByteArraySerializer.class.getName()
);
return Collections.unmodifiableMap(props);
}
Метод createProducerProps незатейливо устанавливает сериализацию ключа и значения в бинарный вид.
Аналогичная ситуация и с настройкой читателя.
Вывод: старайся - не старайся прислать конфиг, а в топик данные экземпляров записываемых классов будут записываться в байтовом виде с помощью Java сериализации.
Мотивация разработчиков при этом понятна. Они не хотят, чтобы можно было запустить свои очумелые ручкив конфигурационные файлы и установить несогласованные сериализатор и десериализатор, тем самым сломав работу брокера Kafka.
Все равно я тебя увижу
Раз не удалось в сконфигурировать запись/чтение Remote Log Metadata Manager в топик __remote_log_metadata, то мы установим десериализатор при вычитке данных топика консольным консюмером kafka-console-consumer.sh.
Но сначала надо разработать десериализатор. Придется пописать код.
Создим Java проект со Gradle-сборкой и одним классом ru.mg.RsmmMetadataDeserializer.
build.gradle.kts
plugins {
id("java")
}
group = "ru.mg"
version = "1.0-SNAPSHOT"
repositories {
mavenCentral()
}
dependencies {
implementation("org.apache.kafka:kafka-clients:3.6.0")
implementation("org.apache.kafka:kafka-storage:3.6.0")
implementation("org.apache.kafka:kafka-storage-api:3.6.0")
}
RsmmMetadataDeserializer.java
package ru.mg;
import org.apache.kafka.common.serialization.Deserializer;
import org.apache.kafka.server.log.remote.metadata.storage.serialization.RemoteLogMetadataSerde;public class RsmmMetadataDeserializer implements Deserializer<String> {
private RemoteLogMetadataSerde serde = new RemoteLogMetadataSerde();
@Override
public String deserialize(String topic, byte[] data) {
return serde.deserialize(data).toString();
}
}
Собираем код в jar файл (gradlew build) и копируем в подпапку lib установки Kafka.
Попробуем теперь прочесть содержимое топика __remote_log_metadata установив необходимые параметры. Для этого создадим в попдапке configs файл remote-metadata-formatter.properties со следующим содержимым:
print.timestamp=true
print.offset=true
print.key=true
key.separator= \ |
print.headers=true
Наконец, запускаем консольного читателя.
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic __remote_log_metadata \
--from-beginning \
--formatter-config=./config/remote-metadata-formatter.properties \
--value-deserializer=ru.mg.RsmmMetadataDeserializer \
--timeout-ms=1000
Теперь записи выводятся в виде
CreateTime:1699124091830 | Offset:260 | NO_HEADERS | null | RemoteLogSegmentMetadata{remoteLogSegmentId=RemoteLogSegmentId{topicIdPartition=JN44_qs0TUKBK6U3nr-ZaQ:tieredTopic-0, id=TWPRUYY7QXWZE9X7c0yCrw}, startOffset=14, endOffset=15, brokerId=0, maxTimestampMs=1699123865714, eventTimestampMs=1699124091829, segmentLeaderEpochs={0=14}, segmentSizeInBytes=140, customMetadata=Optional.empty, state=COPY_SEGMENT_STARTED}
где колонки CreateTime, Offset, Headers, Message key, Message value разделены символом |.
Анализируем содержимое топика
С помощью grep можно поискать наличие в сообщениях различные статусы метаданных сегмента. Нашлись статусы COPY_SEGMENT_STARTED, DELETE_SEGMENT_STARTED, DELETE_SEGMENT_FINISHED, в вот статусаCOPY_SEGMENT_FINISHED не нашлось.
Посмотрев содержимое лога ./logs/server.log становится понятна причина отсутствия статуса COPY_SEGMENT_FINISHED.В логе присутствует ошибка
org.apache.kafka.server.log.remote.storage.RemoteStorageException: java.lang.IllegalStateException: Not enough indexes have been added. At least 4 required at io.aiven.kafka.tieredstorage.RemoteStorageManager.copyLogSegmentData(RemoteStorageManager.java:232) at kafka.log.remote.RemoteLogManager$RLMTask.copyLogSegment(RemoteLogManager.java:736) at kafka.log.remote.RemoteLogManager$RLMTask.copyLogSegmentsToRemote(RemoteLogManager.java:687) at kafka.log.remote.RemoteLogManager$RLMTask.run(RemoteLogManager.java:790) at java.base/java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:515) at java.base/java.util.concurrent.FutureTask.runAndReset(FutureTask.java:305) at java.base/java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:305) at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128) at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628) at java.base/java.lang.Thread.run(Thread.java:829) Caused by: java.lang.IllegalStateException: Not enough indexes have been added. At least 4 required at io.aiven.kafka.tieredstorage.manifest.SegmentIndexesV1Builder.build(SegmentIndexesV1Builder.java:39) at io.aiven.kafka.tieredstorage.RemoteStorageManager.uploadIndexes(RemoteStorageManager.java:309) at io.aiven.kafka.tieredstorage.RemoteStorageManager.copyLogSegmentData(RemoteStorageManager.java:225) ... 9 more
Посмотрев код реализации Remote Storage Manager место возникновения ошибки легко локализуется. Исключение поднимается в методе `build()` класса io.aiven.kafka.tieredstorage.manifest.SegmentIndexesV1Builder
public SegmentIndexesV1 build() { if (indexes.size() < 4) { throw new IllegalStateException("Not enough indexes have been added. At least 4 required"); } if (indexes.size() == 4 && indexes.containsKey(IndexType.TRANSACTION)) { throw new IllegalStateException("OFFSET, TIMESTAMP, PRODUCER_SNAPSHOT, " + "and LEADER_EPOCH indexes are required"); } return new SegmentIndexesV1( indexes.get(IndexType.OFFSET), indexes.get(IndexType.TIMESTAMP), indexes.get(IndexType.PRODUCER_SNAPSHOT), indexes.get(IndexType.LEADER_EPOCH), indexes.get(IndexType.TRANSACTION) ); }
Разработчики кода проекта Aiven Open/tiered-storage-for-apache-kafka считают, что у каждого сегмента должно быть обязательно не менее четырех видов индексов.
А сколько есть сейчас? Попробуем побороть или обойти эти грабли.
Прыгаем на граблях с индексом нулевой длины
Для начала добавим в метод build логирование имеющихся индексов. И вот что мы видим - индекса по offset нет. Всего в indexes на момент вызова метода build лежит три индекса TIMESTAMP, PRODUCER_SNAPSHOT, LEADER_EPOCH. Посмотрев в файлы локального хранилища мы видим, что для сегментов партиции топика tieredStorageфайлы с расширением index присутствуют, но имеют нулевую длину.
Попытки поправить код в Aiven Open/tiered-storage-for-apache-kafka для корректной обработки пустых индексов по смещению не увенчались успехом. Код перестал ругаться исключением, но проблема протекла выше в RemoteLogManager (а это уже часть ядра Kafka).
Мы пойдем другим путем и попробуем обойти грабли. Создадим топик tieredStorage с такими настройками, которые не приводят к пустым индексам.
Для этого остановим брокер Kafka и Zookeeer, затем удалим файлы из ./data/fs_storage, ./data/kafka, ./data/zk. После чистки данных запустим Zookeeer и брокер Kafka. Пересоздадим топик tieredTopic с бОльшими значениями local.retention.ms и размером сегмента 1 000 000 байт.
./bin/kafka-topics.sh --create --topic tieredTopic --bootstrap-server localhost:9092 \
--config remote.storage.enable=true \
--config local.retention.ms=10000 \
--config retention.ms=300000 \
--config segment.bytes=1000000
Смотрим в папку ./data/kafka/tieredTopic-0 (там хранятся файлы единственной партиции топика).Видим, что файл с расширением index имеет теперь размер 10 МБ. Получилось.
Однако теперь для того, чтобы файл сегмента наполнился данными и ротировался отправка единичных сообщений в топик будет недостаточной. Нужно насыпать много данных и желательно не вбивая их руками.Для этой цели воспользуемся скриптом ./bin/kafka-producer-perf-test.sh.
./bin/kafka-producer-perf-test.sh --topic tieredTopic \
--producer-props bootstrap.servers=localhost:9092 \
--num-records 10000 --record-size 1024 --throughput -1
После завершения работы сккрипта, подождав истечения времени local.retention.ms равного 10 секунд,читаем консольным консьмером все содержимое топика RemoteLogMetadataManager.
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic __remote_log_metadata \
--from-beginning \
--formatter-config=./config/remote-metadata-formatter.properties \
--value-deserializer=ru.mg.RsmmMetadataDeserializer \
--timeout-ms=1000
Воспользовавшись grep для поиска в вычитанных сообщениях убеждаемся, что появились записи со статусом COPY_SEGMENT_FINISHED. Записи COPY_SEGMENT_STARTED, DELETE_SEGMENT_STARTED, DELETE_SEGMENT_FINISHED тоже есть. В логах брокера ошибки отсутствуют.
Обход грабли с выгрузкой сегментов в удаленное файловое хранилище успешно завершен.
Новые грабли с чтением
Для завершения тестирования остается попробовать вычитать записанные в топик tieredTopic сообщения.В том числе и вытесненные в удаленное хранилище.
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic tieredTopic \
--from-beginning
На чтение файловая реализация Remote Storage Manager от Aiven Open пока не работает. Разбираться с chunk-ами желания нет. Возможно, сделаем это позже.
Заменяем реализацию RSM на пример из Apache Kafka
Итак, на текущий момент заставить корректно работать реализацию Remote Storage Manager от Aiven Open не получилось.
Когда уже ничего не помогает, прочтите же, наконец, документацию.
В документации Apache Kafka есть Quick Start Example для tiered storage. Разработчики Kafka реализовали пример файлового RSM org.apache.kafka.server.log.remote.storage.LocalTieredStorage. Попробуем эту реализацию.
Собираем исходники и настраиваем реализацию RSM от Kafka
Здесь все делаем согласно Quick Start Example для tiered storage. Без лишних подробностейпоследовательность действий следующая:
Качаем исходники Kafka 3.6 с сайта https://kafka.apache/org
Запускаем сборку gradle с параметрами clean :storage:testJar
Собранный jar файл kafka-storage-3.6.0-test.jar копируем в подпапку ./lib корня установки брокера Kafka
В файле ./config/server.properties заменяем настройки RSM на специфичные для LocalTieredStorage
remote.log.storage.manager.class.name=org.apache.kafka.server.log.remote.storage.LocalTieredStorage remote.log.storage.manager.class.path=./libs/kafka-storage-3.6.0-test.jar remote.log.storage.manager.impl.prefix=rsm.config. rsm.config.dir=./data/fs_storageЗапускаем (перезапускаем) брокер Kafka
Создаем (если не создан) топик tieredStorage
Скриптом ./bin/kafka-producer-perf-test.sh пишем в топик tieredStorage сообщения
Консольным консьюмером читаем топик
Быстрое тестирование показывает, что запись и чтение работает, ошибки в логах отсутствуют.
Структура файлового удаленного хранилища повторяет структуру локального. Никаких chunk, в отличие от реализации RSM от AivenOpen.
Однако, опять все не так хорошо. При рестарте брокера в логе появляется ошибка работы RLMM
RemoteLogManager=0 partition=NHrudFqRSz6kJPczeOA0cQ:tieredTopic-0] Error occurred while copying log segments of partition: NHrudFqRSz6kJPczeOA0cQ:tieredTopic-0 (kafka.log.remote.RemoteLogManager$RLMTask) java.lang.IllegalStateException: This instance is in invalid state, initialized: false close: false at org.apache.kafka.server.log.remote.metadata.storage.TopicBasedRemoteLogMetadataManager.ensureInitializedAndNotClosed(TopicBasedRemoteLogMetadataManager.java:507) at org.apache.kafka.server.log.remote.metadata.storage.TopicBasedRemoteLogMetadataManager.listRemoteLogSegments(TopicBasedRemoteLogMetadataManager.java:253) at kafka.log.remote.RemoteLogManager.findLogStartOffset(RemoteLogManager.java:1438) at kafka.log.remote.RemoteLogManager$RLMTask.maybeUpdateLogStartOffsetOnBecomingLeader(RemoteLogManager.java:610) at kafka.log.remote.RemoteLogManager$RLMTask.copyLogSegmentsToRemote(RemoteLogManager.java:661) at kafka.log.remote.RemoteLogManager$RLMTask.run(RemoteLogManager.java:790) at java.base/java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:515) at java.base/java.util.concurrent.FutureTask.runAndReset(FutureTask.java:305) at java.base/java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:305) at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128) at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628) at java.base/java.lang.Thread.run(Thread.java:829)
Значит и в TopicBasedRemoteLogMetadataManager не все гладко, но это же Early Access Release.
Проверку работы `org.apache.kafka.server.log.remote.storage.LocalTieredStorage` на настройках топика, приводящих к созданию индексов по смещению с нулевым размеров оставлю для пытливых читателей.
Подводим итоги, намечаем следующие цели
Реализация tiered storage позволяет упростить построение кластеров Kafka с большими объемами и глубиной хранения данных.
Мы погрузились в детали реализации tiered storage в Kafka и смогли настроить работу файловой реализации удаленного хранилища. Пришлось повозиться и походить по граблям. Файловое удаленное хранилище от разработчиков Kafka заработала.
Альтернативная реализация от Aiven Open не может успешно вычитать записанные ей в удаленное хранилище данные. Для попытки починки необходимо более детально исследовать механизм chunk-ов.
В следующей статье я хотел бы разобрать устройство кода Remote Storage Manager Aiven Open и постараться заставить работать удаленное хранилище на базе файлов и на базе S3 Minio.