
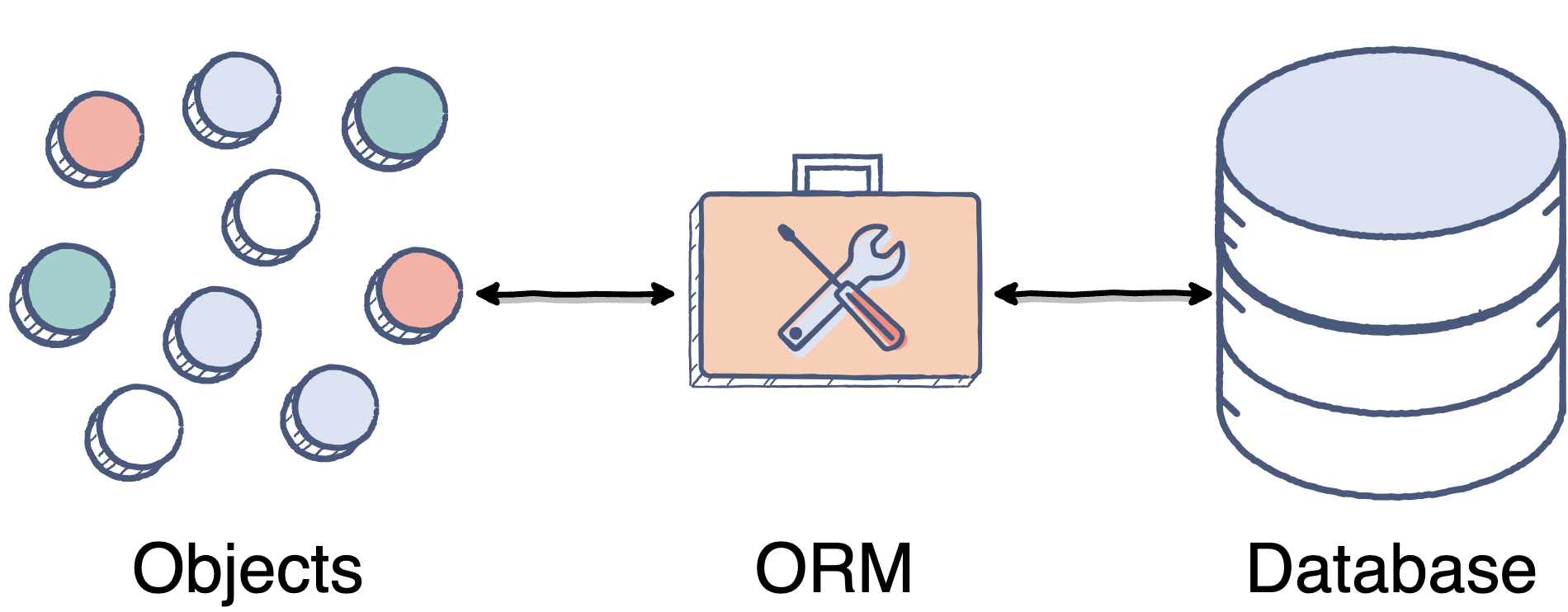
Идея упростить или абстрагировать код с помощью ORM, возможно, имеет очень ограниченный контекст применимости. По сути ORM хорош для приложений уровня простого CRUD, а дальше начинает только мешать. А CRUD-приложений в реальной жизни очень мало.
Проблемы
- При использовании ORM мы обычно прописываем в коде сущности и их взаимосвязи, и по сути это — проектирование БД ещё раз (дублирование логики!) прямо в коде.
- Борьба с проблемами производительности никуда не денется всё равно, как ни абстрагируй. Ты просто не можешь не знать, что у тебя под капотом происходит. Какие там делаются джойны и группировки.
- Язык запросов в виде цепочки объектов и методов читается хуже, чем SQL, по сути это — особый язык, который надо учить. За себя скажу, что когда писал на PHP (Laravel), длинные запросы на Eloquent меня иногда изумляли своей сложностью чтения:
$query = Ad::
select(array('ads.*', DB::raw('COUNT(DISTINCT clicks.id) as clicks_count'), DB::raw('COUNT(DISTINCT shows.id) as shows_count'), DB::raw('(COUNT(DISTINCT clicks.id) * COUNT(DISTINCT shows.id))/100 as CTR')))
->leftJoin('clicks', function($join) use($date){
$join->on('ads.id', '=', 'clicks.ad_id')->where(DB::raw('DATE(clicks.created_at)'), '=', $date);
})
->leftJoin('shows', function($join) use($date){
$join->on('ads.id', '=', 'shows.ad_id')->where(DB::raw('DATE(shows.created_at)'), '=', $date);
})
->groupBy('ads.id')->with('devices', 'platforms');В итоге, кстати, некоторые производители ORM даже пытаются прикрутить свой собственный абстрактный недоSQL на объектах бизнес логики, например, как в DOCTRINE:
$query = $em->createQuery('
SELECT u
FROM Doctrine\Tests\Models\Company\CompanyPerson u
WHERE u INSTANCE OF Doctrine\Tests\Models\Company\CompanyEmployee');
или Hibernate:
IQuery q = s.CreateQuery("from foo in class Foo where foo.Name=:Name and foo.Size=:Size");В итоге непонятно, для чего козе боян, ведь обычный SQL — это и так абстракция над бизнес-сущностями и их взаимосвязями, и обвешивать это ещё одним слоем с птичьим языком (или тем более с птичьим SQL-языком), игнорируя все проблемы перформанса — это просто странно. А под капотом ORM делает иногда такое, что волосы дыбом.
Странная абстракция
Есть ещё такое мнение, что ORM — это слой, абстрагирующий от способа хранения. Мол, сегодня ты пишешь на MySQL, завтра на Postgres, после завтра вообще в файлах хранишь — и тебе пофиг, код остаётся тем же. Чистая архитектура.
Ну это вообще обычно ерунда, конечно. Уродовать код и замедлять разработку, чтобы с вероятностью 0.01% захотеть переехать на другую базу — ну такое.
Про чистоту архитектуры тоже можно вставить 5 копеек, чтобы два раза не вставать. Очень часто слои пересекаются. Как ни крути, но делать абсолютно 100% независимый слой бизнес-логики (юзкейсы, сервисы) иногда бывает очень дорого. Например, если тебе надо построить хитрый отчёт, ты будешь использовать SQL с группировками, оконными функциями, фильтрами и джойнами, выжимая из базы данных всё, что можно, включая грязные хаки. Там будет не до абстракций. Да просто сделать group by и посчитать количество тех, у кого count больше одного — это ведь уже бизнес-логика, вшитая в SQL.
НО
С другой стороны, писать совсем простейшие запросы вручную задалбывает, конечно, поэтому какой-то гибридный подход, наверно, может и подойти в некоторых ситуациях. Но даже в простых вещах нужно быть осторожным: на практике встречал удивление а-ля "а почему у нас при формировании этой страницы к базе уходит 254 запроса, мы ж только табличку вывели?"
В мире Go
На данный момент в Go хоть и существуют ORM (например, gorm.io/gorm), но большинство команд ими не пользуется. Просто потому, что в языке Go на любую магию традиционно смотрят с подозрением. По задумке авторов Go простой как дрова.
При этом проблемы сырых запросов решаются точечно. Где-то просто пишется SQL, но, например, если нужно запрос составлять из частей по определённым условиям (например, фильтры, прилетающие из формы), можно использовать squirrel (query builder):
users := sq.Select("*").From("users").Join("emails USING (email_id)")
if onlyActive{
users = users.Where(sq.Eq{"deleted_at": nil})
}
sql, args, err := active.ToSql()Это безопаснее и проще, чем конкатенировать из частей. Тем не менее это именно queryBuilder, а не ORM, т.е. нет отображения сущностей на реляции, нет магических неявных джойнов под капотом.
Если же надо получать из запроса структуру данных, не перечисляя каждый раз поля, то можно это сделать с помощью sqlx:
people := []Person{}
db.Select(&people, "SELECT * FROM person ORDER BY first_name ASC")Здесь есть немного магии, так как библиотека используется reflection, но это чисто технический, не особо принципиальный момент.
Выводы
Тема БД всегда очень сложна и холиварна. В проектах Каруны есть разные языки и разные команды, и подходы к работе с БД тоже сильно отличаются. На Руби ORM используется в основном очень плотно, на Go его почти нет, и т.д. Поэтому выражу только своё персональное мнение: в реальных (не CRUD) проектах абстрагироваться от данных в базе бывает слишком дорого (читабельность и производительность), а ценности такое абстрагирование даёт очень мало, ведь SQL сам является абстракцией над бизнес сущностями.
Самое забавное, что использовать или нет — это скорее вопрос традиций в конкретном стеке.
Кстати, часто слышал, что в C# какой-то особенный подход к ORM, и там всё супер. Буду рад, если поделитесь реальными впечатлениями в комментариях. К сожалению, мало что знаю про этот язык.
Статья является компиляцией идей из канала Cross Join
Комментарии (210)

aslepov78
04.12.2023 11:34+16А CRUD-приложений в реальной жизни очень мало.
Почему то у меня каждый новый проект - CRUD как минимум

varanio Автор
04.12.2023 11:34+1Т.е. без джойнов, группировок и условий having? Что ж за проекты такие

lair
04.12.2023 11:34+8...а в чем проблема сделать джойны или группировки или даже having на ORM?
varanio Автор
04.12.2023 11:34+4А то, что там начинается магия по автоматической генерации запросов, эти запросы бывают весьма странны. Видел на своей практике запросы вида
where id in (...1000500 разных id... ) и много другого весёлого.
Или когда программист в цикле пишет user->posts, то получает много-много запросов, потому что при магическом взаимодействии очень просто ошибиться.lair
04.12.2023 11:34+14А то, что там начинается магия по автоматической генерации запросов, эти запросы бывают весьма странны.
Пишите простые запросы, избегайте магии.
Видел на своей практике запросы вида
where id in (...1000500 разных id... ) и много другого весёлого.Какое это имеет отношение к джойнам, группировкам или having?
Или когда программист в цикле пишет user->posts, то получает много-много запросов, потому что при магическом взаимодействии очень просто ошибиться.
Не используйте магию. ORM != магия, ORM - инструмент.
varanio Автор
04.12.2023 11:34+2а главное, синтаксис становится жутковат, гораздо хуже SQL
lair
04.12.2023 11:34+9"жутковат" - вкусовщина. Я не вижу проблем в синтаксисе
orders.GroupBy(o => o.OrderDate.Year), особенно учитывая, что он консистентен с другими местами в системе, где делаются такие же запросы без учета БД. Более того, некоторые вещи, типаHAVING, который превращается в.GroupBy().Where(), лично мне понятнее.

ritorichesky_echpochmak
04.12.2023 11:34+10После того как насмотришься на бизнеслогику в БД, тонны монструозных хранимок и триггеров, которые в сезон распродаж "совершенно непонятно почему" превращают БД в тыкву, на их синтаксис, а так же на попытки найти какой же волшебной задницей записи попадают вооооон в те три таблицы, которые из кода только читаются - синтаксис нагенеренный ORM становится приятным и шелковистым. А логи - вообще наше всё. На рукоблудные запросы логов с параметрами зачастую никто не пишет - всем лень, им некогда, они строят из себя DBA

Kergan88
04.12.2023 11:34+1Если в орм есть джойны в явном виде - это вообще не орм.

pbatanov
04.12.2023 11:34+4почему, дать ORMке явное указание подгрузить связи (те же ленивые например) - вполне себе частый юзкейс джоинов. просто там не надо писать ни условие, ни сущности, просто указываешь какую связь заджоинить.
lair
04.12.2023 11:34Это утверждение нуждается в формализации и доказательстве.
Если у меня базовая библиотека фреймворка умеет джойны между объектами (НЕ на уровне БД, а в памяти), почему использование мной этого же синтаксиса к объектам ORM делает ORM не-ORM?
Kergan88
04.12.2023 11:34джойны между объектами
А что такое "джойны между объектами" (или графами)? "джойны между отношениями" - это я понимаю. А вот как определить операцию джойна между объектами, да так, чтобы она была осмысленна, согласована с джойнами на отношениях, и при том не требовала введения эквивалентной отношениям конструкции - я не представляю.
lair
04.12.2023 11:34А почему она должна быть согласована с джойнами на отношениях? Мы говорим об ORM, и действия пользователь ORM (программист) совершает над объектами.
Вот, скажем, я хочу получить, не знаю, сумму продаж по менеджеру, и число обработанных им заявок. Группируем заявки по менеджеру, группируем продажи по менеджеру, получившиеся объекты групп джойним по менеджеру.
Мне совершенно все равно, согласовано ли это с джойнами на отношениях, или ввел ли я сущность, эквивалентную отношению - я решил поставленную задачу с помощью конструкции, которая в моем фреймворке называется Join, и нижележащий ORM не превратился от этого в тыкву.

PuerteMuerte
04.12.2023 11:34А почему она должна быть согласована с джойнами на отношениях?
Если она не согласована с джойнами на отношениях, то работать ваши суммы продаж по менеджеру будут. Но если ваша компания торгует не яхтами, а смартфонами, молоком или там мебелью, т.е. в таблице "продажи" количество записей измеряется не пальцами одной руки, а хотя бы пальцами тысячи рук, нижележащий ORM надолго займёт ещё более нижележащую СУБД такой нескучной работой, как объединение отношений без индексов, с полным сканом.

Kerman
04.12.2023 11:34ВНЕЗАПНО может оказаться, что in-memory join работает на порядки быстрее, чем тот же джоин в базе. Особенно, если этот случай учтён при проектировании.
lair
04.12.2023 11:34А что вы понимаете под «согласована»? Из вашего комментария кажется, что «преобразовываться в» - тогда да, хороший orm умеет преобразовывать джойны на объектах в джойны в БД. Непонятно, почему это делает его не ORM в этот момент.
PuerteMuerte
04.12.2023 11:34Из вашего комментария кажется, что «преобразовываться в»
Именно так, причём с учётом внешних ключей
lair
04.12.2023 11:34Ммм, при чем тут внешние ключи? Между указанными сущностями (продажи и кейсы) нет связей, я сам указываю, как их связать.
lair
04.12.2023 11:34Косвенных связей, очевидно, может быть больше одной; именно поэтому я явно указываю, какое объединение я хочу. В этот момент ORM должен в первую очередь учитывать то, что я ему сказал, а уже дальше все остальное, если оно ему зачем-то нужно.
Kergan88
04.12.2023 11:34А почему она должна быть согласована с джойнами на отношениях?
Потому что если она с джойнами на отношениях не согласована, то это не "джойн", а "просто операция, которая в силу непонятного стечения обстоятельств называется Join".
Давайте я тогда несколько уточню свой изначальный пост:
Если в орм есть в явном виде операция, согласованная с джойнами на отношениях (как бы она ни называлась) - это вообще не орм.
При этом, конечно, операция, которая называется по каким-то неизвестным причинам "Join" или "hurdur" там вполне может быть, да.
получившиеся объекты групп джойним по менеджеру.
Я все еще не понимаю, что значит "джойним объекты".
lair
04.12.2023 11:34Если в орм есть в явном виде операция, согласованная с джойнами на отношениях (как бы она ни называлась) - это вообще не орм.
Почему?
Я все еще не понимаю, что значит "джойним объекты".
https://learn.microsoft.com/en-us/dotnet/api/system.linq.enumerable.join?view=net-8.0
Берем два множества объектов, А и Б, находим такие пары объектов (принадлежащих разным множествам), которые удовлетворяют определенному критерию, на этих парах выполняем какое-то преобразование, чтобы получить финальный объект.

da_normalny_ya
04.12.2023 11:34+9В шарпах подход схож с описанным для GO только ответ БД мапится на объект из коробки, проблему из 1 пункта решает подход CodeFirst, 3 пункт очень сильно зависит от языка, и я бы посмотрел на хорошо читаемый SQL View из 380 полей и кучей джойнов, такое, как не описывай будет ужас
Kerman
04.12.2023 11:34+33Кто-то не очень понимает, что ORM в первую очередь - маппер. Да, и называется он Object-Relational Mapper. Отвечает за взаимосвязь между реляционными данными и объектно-ориентированным миром.
Тот, кто хотя бы раз сталкивался с опечаткой при загрузке поля в объект, уже не задаёт вопросы, оправдан ли ORM. Когда за тебя связку делает кодогенератор с нулевой возможностью ошибки на любой сложности схеме - начинаешь ценить надёжность такого решения.
Что касается SQL. ORM не может в принципе покрыть весь синтаксис SQL. И не должен, это не его задача. Его задача - сделать простым синтаксис 95% случаев, когда дальше джойна и WHERE ничего не надо. ORM не мешает использовать чистый SQL, а чаще всего может его дополнить, переводя результат сложного запроса в набор объектов.
C# действительно немного особняком стоит, благодаря рефлекшену. Рефлекшен позволяет в рантайме распарсить expression tree и понять "чего хотел программист". К примеру:
Orders.Where(o => o.IsCompleted && o.CreatedDate.Year > 2020).OrderBy(o.ID)Превращается в рантайме в SQL:
SELECT * FROM db.Orders a WHERE a.IsCompleted = 1 AND YEAR(a.CreatedDate) > 2020 ORDER BY a.IDА потом результат преобразует в массив типизированных объектов с полями, поведением и состоянием.

ImagineTables
04.12.2023 11:34+1Тот, кто хотя бы раз сталкивался с опечаткой при загрузке поля в объект, уже не задаёт вопросы, оправдан ли ORM. Когда за тебя связку делает кодогенератор с нулевой возможностью ошибки на любой сложности схеме - начинаешь ценить надёжность такого решения.
Я постоянно слышу такую же аргументацию за TypeScript против родного ES. Мол, опечатаешься где-нибудь — а тебе компилятор сразу укажет! А что всё-таки будет, если опечататься? В ES или в названии поля? Вылетит
птичкаисключение, вот и всё. И мне каждый раз очень хочется спросить: а вы уверены, что у вас с процессами разработки всё в порядке? Если такая копеечная проблема как исключение (а от них всё равно не защитишься, это норма при разработке) заставляет переживать и перекладывать работу на компилятор/ORM.Хуже всего, что это самоподдерживающийся процесс. От введения в пайплайн компилятора/ORM дела действительно становятся запутаннее, а ловля исключения с последующим исправлением перестаёт быть такой простой.
Kerman
04.12.2023 11:34+18А вы в данном случае не понимаете разницу между статически типизированными языками и динамически типизированными.
Да, конечно, и там и там "вылетит птичка". Только в динамически типизированном языке вы эту "птичку" получите в рантайме. А в статически типизированном - на этапе компиляции. И на этапе компиляции вам не нужно отлавливать условия возникновения ошибки и изучать стек в попытке узнать, откуда это взялось. Компилятор просто не даст вам сделать такую ошибку.
И не надо называть исключения копеечной проблемой. Это может быть прод на миллионы запросов в час. Это может быть две недели попыток воспроизведения бага. Не надо недооценивать ошибки.
Статическая типизация - это один из инструментов управления сложностью проекта. Точно так же, как и ORM. Та технология, что позволяет сгрузить риск ошибки на неё. В ущерб кривой вхождения, да.
Если для вас внедрение в пайплайн компилятора или ORM делает проекты запутаннее, то у вас недостаточно сложные проекты. Или же вы не умеете ими пользоваться. Или у вас редкий случай, когда это просто невыгодно.
Все свои большие проекты я делал с ORM. Кроме последнего, где ORM не нужен. Вот просто у проекта другая идеология. Но вот придумать условия, где было бы оправданно использовать язык с динамической типизацией для действительно большого проекта я не могу.
ImagineTables
04.12.2023 11:34-2И не надо называть исключения копеечной проблемой. Это может быть прод на миллионы запросов в час.
Не надо на меня нагонять жути! Если это прод с миллионом запросов, значит к нему написаны тесты, проверяющие диапазоны и прочее на все лады. И эти тесты так или иначе прогоняются перед выкаткой. (Если автоматические тесты не написаны, то это несерьёзный разговор). Можно даже CI настроить так, чтобы отлуп от билд-сервера был в точности, как при ошибках компиляции. И в чём разница? Кроме того, что в цепочке появляется (не)нужный компилятор.
Но чтобы найти опечатку в названии поля, миллион запросов и не нужен. Нужен всего один релевантный, потому что исключение вылетит сразу. Конечно, если процессы построены так, что пишешь, сразу запускаешь и видишь результат, повторяешь. К чему, я думаю, и надо стремиться. (Любимое присловье моего бывшего проджект-менежера, ковыряющегося в пушах: «Ты что ж, это даже НЕ ЗАПУСКАЛ?!»).

loltrol
04.12.2023 11:34+4Ой, та ладно. typescript и typing модуль в python появились именно потому, что большой софт с командами в 500 человек и с 100 mr в день вы ну никак не сможете осилить. Вероятность 100% что так или иначе будут ломать код...

doctorw
04.12.2023 11:34+3Тесты часто пишут весьма посредственно, а ещё из-за тестов нередко приходится менять код, и сами тесты тоже нередко ломаются в результате доработок по коду и/или архитектуре. Имхо, юнит-тесты из-за этого можно сразу в утиль, если речь о сложных и больших проектах. Имеет смысл реализовать только интеграционные тесты для критически важных сценариев, в остальном, гораздо лучше полагаться на статическую типизацию и технологии вроде ORM. В шарпе мне нравится работать с linq2db, он невероятно облегчает работу и в большинстве случаев мне даже нет необходимости запускать код, чтобы быть уверенным, что он будет работать как мне нужно.
Я вообще не понимаю вот этого тесты тесты тесты, обмажутся юнит-тестами с ног до головы, а на проде всё равно баг на баге. Вероятно, конечно, что это предвзятое мнение на основе частного опыта, но уж больно часто приходилось подобное слышать/видеть.
ritorichesky_echpochmak
04.12.2023 11:34+1а ещё из-за тестов нередко приходится менять код
Который был изначально плохо спроектирован. И это хорошо. Юнит-тесты от этого свою ценность ни разу не теряют. Тем более что их ценность именно и состоит в том чтобы прямо из IDE наравне с "собрать" быстро проверить кучку отдельных мелких юнитов, что после очередного рефакторинга или доработки не стало решительно хуже.
Баги на проде не потому что юнит-тесты, а потому что люди плохо понимают как это должно работать и не прописали тест на этот кейс вообще, никакой. А сложность больших проектов дополнительно усложняет это понимание. Понимали бы как должно быть - писали бы сразу идеальный код без всяких юнит-тестов, а сопровождающие бы ничего не ломали в старом коде)))
doctorw
04.12.2023 11:34Плохо спроектированный код видно и без юнит-тестов, либо взглядом опытного разработчик либо по тому, что на проде стреляет. И может быть стоит просто рефакторить с умом, чем прибегать к юнит-тестам? Банально, проектировать контракты так, чтобы либо недопускать несогласованных состояний системы либо ловить их как можно раньше и что-то с ними делать.
>>Баги на проде не потому что юнит-тесты, а потому что люди плохо понимают как это должно работать и не прописали тест на этот кейс вообще, никакой.
Вот именно поэтому, юнит-тесты и не решают проблемы, можно приучить себя задумываться о сценариях работы и без написания юнит-тестов, а необходимость писать юнит-тесты никак не гарантирует отсутствие плохого понимания требований, не говоря уже о том, что нередко и сам постановщик задачи плохо понимает, что же он хочет.
ritorichesky_echpochmak
04.12.2023 11:34+3либо по тому, что на проде стреляет
В sales season некоторым компаниям, у которых один заказ может стоить тысячи баксов, это стоит просто жесть сколько. Может ещё и релизы вечером в пятницу накатывать?
Проектирование контрактов... если вы не можете натянуть юнит-тест на ваш спроектированный контракт, то проблема не в юнит-тесте, а в том что ваш "опытный разработчик" беглым взглядом уже всё продолбал и оно стреляет на проде.
Юнит-тесты вынуждают улучшать контракты и качество кода, что приближает к решению проблемы. Вы никогда в жизни не сможете держать в голове одновременно все сценарии работы хоть сколь-нибудь сложного продукта, а в сложном продукте вас таких будет много. И каждый что-то да продолбает - и вот здесь опять нормально составленные юнит-тесты (которые ваш "опытный разработчик" должен быть в состоянии писать и поддерживать) подстрахуют вас от "стрельбы на проде"doctorw
04.12.2023 11:34Ситуация "стреляет на проде" неизбежна, если Ваш проект живёт дольше недели. Вопрос только в том, как часто такое будет происходить. И юнит-тесты Вас от этого не спасут, потому что также зависят от того, как хорошо разработчики понимают требования. E2E тесты здесь куда лучше, пусть и дороже.
>>И каждый что-то да продолбает - и вот здесь опять нормально составленные юнит-тесты (которые ваш "опытный разработчик" должен быть в состоянии писать и поддерживать) подстрахуют вас от "стрельбы на проде"
Не подстрахует, а потенциально снизит вероятность стрельбы на проде. Тесты тоже нужно уметь писать так, чтобы от них была польза.
ritorichesky_echpochmak
04.12.2023 11:34+1Неожиданный факт: написание юнит-тестов позволяет улучшить понимание системы и требований разработчиком. Полностью не спасают, но ситуацию в целом улучшают. E2E тесты тоже нужны, но они не заменяют, а дополняют

ruslan_sverchkov
04.12.2023 11:34Плохо спроектированный код видно и без юнит-тестов
будь это так, у нас бы не было плохо спроектированного кода) никто из тех, кто писал плохо спроектированный код, не думал, что он пишет плохо спроектированный код, все думали, что пишут хорошо спроектированный код, и опытные инженеры, которые это добро ревьювили, тоже так думали. Юнит тесты это точно такой же клиентский код как любой другой клиентский код, необходимость из-за них переписывать классы это всегда следствие ошибок проектирования классов (как правило несоблюдение DI или просто огромные методы с большой цикломатической сложностью)
Kergan88
04.12.2023 11:34необходимость из-за них переписывать классы это всегда следствие ошибок проектирования
Нет, это не так. Очень часто необходимость сделать код тестируемым кардинально снижает его качество.
lair
04.12.2023 11:34+3Ни разу не видел, чтобы код становился вот прямо радикально хуже, когда его делают тестируемым. У вас есть хотя бы, не знаю, пяток примеров, если это часто происходит?
Kergan88
04.12.2023 11:34-2Собственно, практически любой кейз при котором код меняют для повышения тестируемости - существенно снижает качество этого кода.
lair
04.12.2023 11:34+1Я бы хотел все-таки увидеть конкретные примеры с объяснением, почему это плохо. А то я регулярно это делаю, и может не вижу, где я хуже делаю?..
PuerteMuerte
04.12.2023 11:34-1У вас есть хотя бы, не знаю, пяток примеров, если это часто происходит?
Пяток примеров, наверное, нет, но вот самый очевидный: тестируемость кода предполагает описание контрактов через интерфейсы, чтобы можно было в тестовой среде подменять реальные зависимости моками. Таким образом, вы удваиваете количество сущностей в вашей кодовой базе, и портите возможность быстрой навигации по коду, т.к. ссылка на метод в коде ведёт на интерфейс, а не на реализацию метода.
К слову, это вторая причина, по которой я использую в основном интеграционные тесты, и стараюсь минимизировать покрытие юнит-тестами.
lair
04.12.2023 11:34+1Во-первых, это не кардинальное снижение качества кода. (Btw, быстрая навигация у меня прекрасно работает, просто клавишу другую нажимать надо).
Во-вторых, это не обязательно применять ко всем зависимостям.
Ну и в-третьих, я регулярно эти же интерфейсы использую не только для тестирования, так что они все равно уже есть.

micronull
04.12.2023 11:34стараюсь минимизировать покрытие юнит-тестами
С помощью unit тестов удобно проверять пограничное состояние.
Таким образом, вы удваиваете количество сущностей в вашей кодовой базе, и портите возможность быстрой навигации по коду, т.к. ссылка на метод в коде ведёт на интерфейс, а не на реализацию метода.
Подсовывая вместо интерфейса конкретную реализацию, вы нарушаете принцип инверсии зависимостей. Это чревато высокой связанностью кода, из-за чего любые изменения во внешних слоях могут потянуть изменения по всей цепочке во внутрь.
https://habr.com/ru/articles/269589/
Так же стоит учитывать что моки можно (и желательно) не писать самостоятельно, а использовать готовые инструменты.

michael_v89
04.12.2023 11:34Единственное изменение, которое пойдет по цепочке внутрь - это если вы переименовали класс с реализацией. В остальных случаях класс ничем не отличается от интерфейса.
micronull
04.12.2023 11:34Абстракции стабильны. Реализации нестабильны. Строить зависимости необходимо на основе стабильных компонентов.
Можно строить зависимости от класса, если он предельно стабилен. Например, класс String.
michael_v89
04.12.2023 11:34Что значит "стабильны"? Вот у меня есть код
private Something something; this.something.method(a, b);Почему он вдруг становится более стабильным, если Something это интерфейс? Это один и тот же код, он вызывает тот же метод с той же сигнатурой и передает те же аргументы. Если мы поменяем сигнатуру публичного метода, нам надо менять вызывающий код в обоих случаях. Если мы поменяем реализацию, нам не надо менять вызывающий код в обоих случаях. В каком сценарии есть разница?
micronull
04.12.2023 11:34Если класс никогда не изменит свой метод, то можно.
Однако с этим подходом не очень удобно писать тесты.И у класса может быть много зависимостей, что тоже тянет за собой связанность.
ruslan_sverchkov
04.12.2023 11:34Есть разные мнения, мой опыт показывает что подавляющее большинство кода либо не меняется вообще, либо меняется исключительно редко, и реальная нужда в интерфейсах это большая редкость. В общем-то я бы даже сказал, что необходимость систематически менять один и тот же класс это отличный признак его плохого качества (привет OCP), но холиварить на эту тему в комментах про юнит тесты смысла не вижу) Охотно верю, что ваш опыт может говорить что-то другое.
ruslan_sverchkov
04.12.2023 11:34Ничего такого юнит тесты не предполагают, для DI интерфейсы не нужны, достаточно не final классов, и, как и о любом другом приеме, затрудняющем написание юнит тестов, это кое-что говорит о final классах - сталкивались когда-нибудь с ситуацией когда вам кровь из носу надо переопределить поведение библиотечного кода, а там афтар заботливо раскидал final’ы?)
ImagineTables
04.12.2023 11:34Я согласен со многим из написанного. Действительно, тесты часто пишут весьма посредственно. (Но зачем тогда пугать миллионами запросов в час? Если такой крутой… сервер — сделай качественные тесты!) И я тоже считаю, что конкретно юнит-тесты перехайплены, поэтому я и написал: автотесты. (Но когда продукт носит характер библиотеки, микро- или макросервиса, их трудно отделить от интеграционных). И против linq2*, в частности linq2db я ничего против не имею. LINQ — вообще прелесть. (Но… Нет, тут не будет никаких «но»!)
А спорю я с конкретными сомнительными утверждениями. Типа того, что ORM — хорошее лекарство от опечаток в именах колонок.
michael_v89
04.12.2023 11:34+1значит к нему написаны тесты, проверяющие диапазоны и прочее на все лады
То есть вы предлагаете вместо использования ORM использовать кучу дополнительных тестов на то, правильно ли загружаются данные из базы? Тратить время на их написание и поддержку при переименовании/удалении полей? И на написание SQL вручную? А где профит?
И в чём разница?
В том, что поддерживать это сложнее, и все возможные комбинации все равно не проверить.
ImagineTables
04.12.2023 11:34Пардон, какие ещё дополнительные тесты, если прод на миллион запросов в час? Как такой высоконагруженный сервер вообще менять, если автотестов нет?
michael_v89
04.12.2023 11:34+1Я не говорил, что тестов нет. Слово "дополнительные тесты" означает, что основные тесты есть, а вы предлагаете писать еще другие тесты дополнительно к ним.
ImagineTables
04.12.2023 11:34Если есть хотя бы один тест, связанный с изменяемой функциональностью, как можно не заметить такую ошибку, как опечатка в названии поля? Он же сразу упадёт с исключением.
michael_v89
04.12.2023 11:34+2CREATE TABLE product ( id INT, name VARCHAR(100), category_id INT, status INT, )$result = $db->getRow('SELECT * FROM product WHERE id = :id', ['id' => $id]); $product = new Product(); $product->setId($result['id']); $product->setName($result['name']); $product->setCategoryId($result['category_id']); $product->setStatus($result['category_id']);Опечатка? Да. Будет исключение? Нет. ORM поможет в этой ситуации? Да.
Причем такой код запросто может на тестах работать нормально, так как тестовые данные для int обычно в диапазоне от 1 до 10, и упадет он только на проде, когда придет id категории больше, чем максимальный номер статуса. И то не факт, что упадет, может просто эти товары зависнут в статусе с непонятным id. Потом команда будет 2 часа искать причину, а потом еще 2 дня править некорректные данные в базе.
А еще с большой вероятностью для тестов, которые тестируют статусы, есть свой код загрузки данных в
$productсо своим набором полей, и там status устанавливается правильно. Потому что если код создания$productодин, то это уже будет ORM, а у нас его по условиям нет.ImagineTables
04.12.2023 11:34Это не опечатка. С тем же успехом можно две переменные местами перепутать — и тут уже ORM ничем не поможет. Вот, например, так:
$product1 = …; // ORM-generated $product2 = …; // ORM-generated $newCategory = $business_logic->get_new_category($id1); $newStatus = $business_logic->get_new_status($id1); … $product1->setCategoryId($newCategory); $product2->setStatus($newStatus); // Whoopsie-daisy!Хуже того, точно такую ошибку (
$product->setStatus($result['category_id']);) можно допустить и при использовании ORM — если вручную замаппить на неправильное поле.И если внимательно прочитать то, что я написал, а не заниматься nit-picking'ингом, можно увидеть, что я предлагаю выстраивать процессы так, чтобы сразу после написания подобного кода его запускать и смотреть, как он отработал. Включая (не)правильный статус. Вот это поможет и против опечаток, и против перепутанных местами индексов.
А автотесты — просто вспомогательный инструмент для подобной практики. Чтобы глаз не замылился, когда в сотый раз за день смотришь на все эти статусы и категории. Тем более, когда программируешь сервер с миллионами запросов.
michael_v89
04.12.2023 11:34+1С тем же успехом можно две переменные местами перепутать
Да. Но с ORM такого не будет хотя бы в коде загрузки из базы. Которого без ORM довольно много. Нет волшебной палочки, большое складывается из малого. Тут улучшили, там улучшили, и в целом стало лучше. Это значит меньше багов.
Опечатки это тоже не единственный случай, когда ORM упрощает поддержку, а один из многих.сразу после написания подобного кода его запускать и смотреть, как он отработал
Вот это и означает дополнительные тесты. Кроме собственно логики конкретного сценария использования product вы предлагаете тестировать еще и все загруженные поля всех участвующих сущностей. Причем проверка их в одном сценарии ничего не гарантирует для другого сценария, так как там свой код загрузки полей, и там тоже надо делать эти проверки.

Spiritschaser
04.12.2023 11:34+1А если не проверять типы, то птичка может и не вылетить. Никогда. А ошибка остаться.
doctorw
04.12.2023 11:34А если это ещё и опечатка в каком-нибудь merge into или большом update, то это уже и не птичка, а здоровый такой птеродактиль.
ImagineTables
04.12.2023 11:34Вот поэтому динамическая типизация должна быть строгой. И я не понимаю, почему до сих пор в ES не ввели новый режим для этого. Они потихоньку разгребают старые конюшни, var задепрекейтили, ввели strict, а вот это пока не сделали. Загадаем желание на 2025 год (и мир во всём мире).

includedlibrary
04.12.2023 11:34-3Такой себе аргумент. Давайте тогда вместо языков программирования писать на машинных кодах, а то что это мы работу на компиляторы и интерпретаторы перекладываем?
ImagineTables
04.12.2023 11:34компиляторы и интерпретаторы
Вообще-то, в своём комментарии я их противопоставляю.

kasthack_phoenix
04.12.2023 11:34Вылетит птичка исключение, вот и всё.
Проблема в том, что оно как раз не вылетит, а вполне себе отработает с неожиданными последствиями.
!param.readOnlyдля объекта без свойстваreadOnlyвычислится какtrue, не кидая ошибок, хотя строготипизированный рантайм такого бы сделать не позволил.И мне каждый раз очень хочется спросить: а вы уверены, что у вас с процессами разработки всё в порядке? Если такая копеечная проблема как исключение (а от них всё равно не защитишься, это норма при разработке) заставляет переживать и перекладывать работу на компилятор/ORM.
Во-первых, как показал выше, может некорректно отрабатывать бизнес-логика, а это чревато серьёзными потерями.
Во-вторых, прод, лежащий с исключением -- это тоже дыра с утекающими деньгами бизнеса. Отказываться от инструмента, который часть ошибок убирает как класс, не добавляя особых накладных расходов -- жечь деньги компании.
В-третьих, в системе хоть какой-то сложности, где вложенный объект неправильного типа может пройти через полдюжины медиаторов и коммандхэндлеров, искать причину пропавшего поля невероятно увлекательно.
ImagineTables
04.12.2023 11:34+1Проблема в том, что оно как раз не вылетит, а вполне себе отработает с неожиданными последствиями
Не вылетит, если ошибиться в названии поля? Мы же всё ещё про это говорим?
Тот, кто хотя бы раз сталкивался с опечаткой при загрузке поля в объект, уже не задаёт вопросы, оправдан ли ORM.
Вообще, это зависит от языка и платформы, но я погуглил, и даже в PHP есть PDOStatement::execute вместо mysql_query.
varanio Автор
04.12.2023 11:34-1Я видел разные приколы с ORM в реальной жизни. Например, SQL получается WHERE id IN (123,14152,1231,12312... и так 100500 штук), потому что ORM почему-то решил, что там будет мало этих id или фиг знает, что он там подумал

shasoftX
04.12.2023 11:34А как на SQL выбрать по 100500 id? Т.е. ORM генерит страшный код. А какой не страшный код должен получиться?
ritorichesky_echpochmak
04.12.2023 11:34+1Магия в том, что ORM должна была получить эти 100500 id откуда-то чтобы вписать в запрос и даю 10 из 10 попугаев, что юзверь их успешно сам выгреб, а потом сам обратно их пульнул

Ivan22
04.12.2023 11:34на SQL эти 100500 id должны лежать в другой таблице(можно временной) и фильтр заменяется джоином.

GeorgeII
04.12.2023 11:34Но это не ответ на вполне разумный вопрос. Вы описали архитектурное решение проблемы. Автор же говорит, что запрос построен неоптимально, т.е. его якобы можно переписать на лучший вариант на имеющийся таблице
Ivan22
04.12.2023 11:34+1ну юзая ORM практически никогда и не поймешь что тут не так. А пользуясь SQL уже понимаешь где надо и архитектурное решение поменять
ritorichesky_echpochmak
04.12.2023 11:34А пользуясь SQL уже понимаешь где надо и архитектурное решение поменять
Далеко не всегда люди понимают что делают и пишут вот прям идеальные архитектурные решения. Далеко не всегда то что им кажется что выглядит лучше по факту лучше работает. Особенно не на тестовом наборе данных, а на живых

TimsTims
04.12.2023 11:34Есть несколько способов в механике sql как такое делается. Самое простое в лоб - вставлять вложенный запрос в конструкцию Where id IN ( select id from table...). Хотя бы этого ждёшь от orm.
Посложнее но оптимальнее - делать left join / inner join таблицы, и уже там по-хитрому это все фильтруешь. Получается ещё оптимальнее но нужно понимать что с чем соединяешь.
Перечислять идшники в where in - это самый последний и самый худший вариант из возможных.
GeorgeII
04.12.2023 11:34+1Я, может, упускаю что из виду, но это не сработает.
В оригинальном запросеWHERE id IN (123,14152,1231,12312... и так 100500 штук)все числа в IN -- константы. То есть они не хранятся в таблице, а приходят извне.
Поэтому ваш вариантWhere id IN ( select id from table...)он никак не эквивалентен изначальному запросу.
Посложнее но оптимальнее - делать left join / inner join таблицы
Можно, но это другая архитектура ERM и не проблема ормок / библиотек. Автор же говорит, что можно сделать оптимальнее прямо на этой таблице.
Да и вообще, пруф скинуть не готов, но подозреваю, что операция IN (1, ..., N) в современных БД должна быть оптимизирована и работать куда лучше джоинов, потому что список констант можно перегнать в сет один раз в начале запроса и дальше за константу проверять каждый айдишник на вхождение в сетIvan22
04.12.2023 11:34операция in - это будет в лучше случае поиск по индексу N раз.
GeorgeII
04.12.2023 11:34Точно, про индексы не подумал, согласен.
Надо будет посмотреть на досуге explain таких запросов. Но по факту же ормка сгенерировала оптимальный запрос для такой таблицы? Никуда здесь не денешься от IN (id1, ..., idN)
TimsTims
04.12.2023 11:34+1подозреваю, что операция IN (1, ..., N) в современных БД должна быть оптимизирована
В mssql например можно передавать не более 2100 параметров в where in: https://stackoverflow.com/questions/21178390/in-clause-limitation-in-sql-server
все числа в IN -- константы. То есть они не хранятся в таблице, а приходят извне.
Нет. Там самый прикол орм в том, что ты просишь его сделать именно вложенный запрос: Where id IN ( select id from table...)
Но орм решает так не делать, а сначала выполнить вложенный запрос, получить 100500 идшников, и потом подставляет их во второй запрос через запятую. Вместо одного запроса он делает два гигантских, один хуже другого, и БД тратит кучу цпу на парсинг огромного sql запроса, и затраты на лишнюю пересылку данных туда-сюда тратятся. В общем жуть.
michael_v89
04.12.2023 11:34Вместо одного запроса он делает два гигантских, один хуже другого
Вместо одного гигантского запроса он делает 2 поменьше.
и БД тратит кучу цпу на парсинг огромного sql запроса
Парсинг 1000 id занимает крайне мало времени по сравнению с чтением с диска.
и затраты на лишнюю пересылку данных туда-сюда
Давайте посчитаем. Допустим, у нас есть 3 контент-менеджера, которые пишут статьи, и страница со списком статей на 20 штук.
В вашем варианте мы делаем:SELECT * FROM articles ar INNER JOIN authors a ON ar.author_id = a.id WHERE ar.category_id = :category_id OFFSET :offset LIMIT 20;Возвращается 10 полей articles, 10 полей authors, 20 записей, итого 400 ячеек.
Данные автора дублируются в среднем 6 раз.В варианте с ORM мы делаем:
SELECT * FROM articles a WHERE a.category_id = :category_id OFFSET :offset LIMIT 20; -- authorIds = array_unique(array_column($result, 'author_id')) SELECT * FROM authors WHERE id IN (1, 2, 3);Возвращается 10 полей articles, 20 записей, 200 ячеек в первом запросе.
И 10 полей authors, 3 записи, 30 ячеек во втором запросе.
Итого 230.
Данные автора не дублируются.В этом примере данных передается больше в вашем варианте. И таких сценариев на самом деле довольно много. Число констант там обычно по размеру страницы, много их бывает разве что в коде для массовой обработки.
lair
04.12.2023 11:34Там самый прикол орм в том, что ты просишь его сделать именно вложенный запрос: Where id IN ( select id from table...)
Это, очевидно, не концептуальное ограничение ORM как технологии, а баг в конкретной реализации.
varanio Автор
04.12.2023 11:34+1если нет тестов, то опечатка - не самое страшное. Если есть тесты, то опечатка не проблема

microuser
04.12.2023 11:34Только это не благодаря рефлекшену, а благодаря expression trees, рефлекшн для этого не особо то и нужен, в дереве вся необходимая информация и так имеется

Arm79
04.12.2023 11:34+1И такой код просто отключает индекс по полю CreatedDate.
Логичный и ясный запрос в orm не всегда является таковым с точки зрения оптимальности запроса sql.
Актуальность orm продается под соусом избавления программиста от знания sql. Но по факту программист должен знать и sql, и особенности orm. Двойная работа.
Поэтому мне больше по душе легковесные orm типа dapper, которые занимаются именно маппингом объектов, оставляя логику написания запроса программисту

ColdPhoenix
04.12.2023 11:34На SQL человек ровно так же напишет скорее всего тогда.
Я в таком случае готовлю дату которая нам нужна, и уже делаем стандартное Where(c=>c.CreatedDate >= minDate)

cross_join
04.12.2023 11:34При опечатке птичка вылетает на первом же тесте. Встроенный сиквел умеет проверять синтаксис во время компиляции. Наверное, опечататься при заполнении и отсылки очередного джейсона чем-то приниципиально отличается в лучшую сторону.

devel-avg
04.12.2023 11:34+2CQRS - в commands используем репозитории на основе orm для работы с доменными агрегатами/сущностями, в queries - пишем запросы любой сложности использую любую технологию доступа к БД.
varanio Автор
04.12.2023 11:34это интересная мысль
devel-avg
04.12.2023 11:34тут я немного опечатался - имел ввиду CQS (Command query separation)
этот подход неоднократно встречал и использовал на разных проектах, из плюсов домен (а также сущности и репозитории/да и все остальное из тактических шаблонов ddd) максимально привязаны к предметной области (никаких generic репозиториев и прямого использования ORM в логике и т.п. мути), конкретная реализация репозиториев может быть разная, но если есть хороший ORM, который умеет из хранилища воссоздавать сложные агрегаты/сущности (не знаю как в Java мире - в .net EF core научился наконец-то творить чудеса просто), то можно внутри репозитория использовать ORM.
Ну и важно следить чтобы конкретный ORM не протёк в app layer. Я несколько раз сталкивался с полной заменой ORM в проекте, а также переходом на другие БД - uhe,грубо говоря раз в год подобного рода задачи возникают. И вот тут репозитории очень сильно помогают.
Ну и важно иметь хорошее покрытие тестами, без этого возникнут приколы что на новой версии ORM начал генериться другой SQL
А на счёт сложных запросов - для большинства сценариев пишутся query где хоть чистый sql запросы пиши (тоже дикий антипаттерн, в .net часто dapper используем)
Главный плюс ORM - его использование в разы сокращает время поставки продукта рынку, увеличивая качество и снижая стоимость, особенно на крупных проектах.

TrueRomanus
04.12.2023 11:34+3При использовании ORM мы обычно прописываем в коде сущности и их взаимосвязи, и по сути это — проектирование БД ещё раз (дублирование логики!) прямо в коде.
Очень странная логика. Вот Вы например когда хотите передать сложный JSON объект наверно создаете набор классов/структур которые его описывают, создаете его экземпляр, заполняете поля значениями а потом скармливаете сериализатору который из Вашего сложного объекта превратит в строку. Бесспорно Вы можете сформировать JSON в виде строки без использования всего этого но согласитесь что поддерживать первый вариант будет намного проще как Вам так и людям после Вас. Тоже самое и с ORM, по факту он обычный (де)сериализатор неких объектов в запрос и обратно. Вы можете использовать например odbc или драйвер базы напрямую но удобно ли это поддерживать? ORM это больше про удобство поддержки кода чем про удобство работы с базой. А если Вам не хочется ручками в базе что-то делать то как вариант можно использовать тулинг миграций например такой https://github.com/davedevelopment/phpmig
Борьба с проблемами производительности никуда не денется всё равно, как ни абстрагируй. Ты просто не можешь не знать, что у тебя под капотом происходит. Какие там делаются джойны и группировки.
Странно но это относиться к абсолютно любой вещи в разработке, просто замените заголовок на любой другой. Обычно ORM позволяет использовать сырые запросы на манер odbc, да даже просто никто не мешает использовать odbc в местах где требуется работать с сырыми запросами. Т.е. вполне можно комбинировать для простых CRUD-ов использовать ORM для всего остального сырые запросы. Если сырые запросы сложные то да библиотеки для генерации sql помогают.
Есть ещё такое мнение, что ORM — это слой, абстрагирующий от способа хранения. Мол, сегодня ты пишешь на MySQL, завтра на Postgres, после завтра вообще в файлах хранишь — и тебе пофиг, код остаётся тем же. Чистая архитектура.
Это слой абстрагирующий от использования драйвера базы данных или odbc напрямую. И да он полностью решает эту задачу. Способность перехода с базы на базу зависит не от ORM а от Вашего проекта и его потребностей, например использовали Вы gis модуль в бд а потом попытались перейти на другую бд в которой этого модуля нет или он работает как-то не так.
varanio Автор
04.12.2023 11:34для простых CRUD можно что угодно использовать, но редко бывают приложения из простых CRUD
TrueRomanus
04.12.2023 11:34+1Хорошо исключим из CRUD операцию R, выборка действительно может быть сложной. CUD у Вас как-то по особенному работает? Вы не через INSERT, UPDATE, DELETE его выполняете?

Areso
04.12.2023 11:34Если бы за каждый раз, когда ORM отправлял в UPDATE все поля таблицы, и (опционально, но гораздо хуже) всех связанных таблиц, мне бы давали бы 10 рублей, я бы себе купил бы мотоцикл.
Третий.
На самом деле, это конечно не ORM виноват, но на голом SQL-е такую дичь представить сложно
ritorichesky_echpochmak
04.12.2023 11:34Легко представляю на голом SQL такую дичь. Любой справочник в котором из 40 полей юзверь поменяет одно поле (или не поменяет, а нажмёт Save) в случае с ручным Update без совершенно безумного оверхеда гарантированно выполнит обновление всего. Любой один такой кейс с лихвой оправдывает наличие ORM. А вот отсутствие ORM я даже не представляю что должно оправдать при работе с СУБД. Даже те немногие "супердофигакак-то оптимизированные" запросы проще выполнить через ORM чтобы не плодить простыни аля "создай коннекшн, создай транзакцию, выполни запрос, как-нибудь приведи результат к нужному классу, закрой транзакцию, закрой коннекшн"
Areso
04.12.2023 11:34т.е. программист обновил условной
client.balance = client.balance+payment.value
а потом такой - ну, надо зафикисировать в БД:UPDATE client
SET
name=$(name)s,
surname=$(surname)s,
address=$(address)s,
...
254 поля
...
balance=$(balance)s
where client_id = $(client_id)s
Вы так себе это представляете? Потому что в профилировщике запросов я вижу это так =)ritorichesky_echpochmak
04.12.2023 11:34Именно так, потому что пока не засвербит, он не будет ручками для 254 полей прописывать логику проверки, обновились они или нет. И это актуально как для полей, так и для сущностей в целом. Так же при выгребании каких-то запросов руками гарантированно не работает локальный кэш и всё каждый раз тащится с сервера БД, что куда сильнее бьёт по перфомансу, чем оверхед на ORM и Change-tracking
Areso
04.12.2023 11:34+1А зачем прописывать? Я бы сделал так:
client.balance=client.balance+payment.valueчто изменил, то и обновил.
dbcon.execute("update client set balance=$(balance)s where client_id=$(client_id)s")
dbcon.commit()
ColdPhoenix
04.12.2023 11:34Простые ORM так сделают, у ORM с трекингом уже будет иначе
UPDATE "Table" SET "ChangedField" = @p0 WHERE "Id" = @p2;
TrueRomanus
04.12.2023 11:34-1Ну допустим мы используем голый SQL. Завтра меняется структура и что требуется сделать? Найти по поиску все места где использовались измененные таблицы и поменять заменой или руками и так каждый раз, так удобней работать?
ritorichesky_echpochmak
04.12.2023 11:34И находить такие места, где что-то переделать нужно, спустя месяцы после релиза. И хорошо ещё если это делает один человек с отменной памятью, который помнит что как и почему поменялось) "Приключений на 20 минут, туда и обратно"

1CUnlimited
04.12.2023 11:34для простых CRUD можно что угодно использовать, но редко бывают приложения из простых CRUD
Как Вам такая задача - есть база на mysql и приложение на Delphi - код утерян, но логика там несложная а база открыта для изменений. Нужно создать дополнительное приложение, которое расширяет функционал старого. По сути это Crud к базе данных
На чем сейчас можно быстро накидать интерфейс и логику для такой базы?
PuerteMuerte
04.12.2023 11:34+1На чем сейчас можно быстро накидать интерфейс и логику для такой базы?
На Delphi, например :)

VladimirFarshatov
04.12.2023 11:34Хорошая статья, несколько подталкивает к холивару, но тем не менее.
ОРМ как выше заметили - маппер в первую очередь. Полезен и нужен там, где бэкендер - специалист в своем языке (PHP,Go, etc) и не очень шарит в SQL, т.к. вообще не просто бизнесу находить универсалов, в силу того, что SQL вообще не алгоритмический язык (как конечный ЯВУ), а язык реляционной алгебры. Чтобы написать полноценный запрос к ""отчету" часто надо собрать половину таблиц БД с правильными вхождениями и для этого алгоритмисту требуется вывернуть мозги наизнанку. Сам очень долго с этим мучался, пока не дошла сия простая истина.
Далее, как-бы данные в таблички БД надо как-то вставлять и зачастую транзакционно и не в одну. Вот Вам Create часть из CRUD уже нарисовалась. Аналогично и с другими местами то же самое. CRUD это настолько "базовое" ядро любой СУБД, что оно должно писаться на автомате, а желательно (для GO) ещё и автописателем по набору SQL create table.. скормили описание таблиц - получили готовый CRUD. Примерно как генерация GRPC по protobuf описанию. Почему последнее не вызывает вопросов, а первое в 90% пишут "ручками"? (что надоедает конечно же). Вот поэтому и запилил себе небольшой автопостроитель CRUD за одно и с моками, так чтобы было удобно писать unit-тесты, а не пилить обрамление интеграционника. Удобно.
Далее. Squirrel да - это query builder, и под капотом .. а точно также содержит рефлексию. Кроме того, он точно также по сути является той же самой "прослойкой" как построитель запросов из .. собственных методов по типу doctrine. Тут можно оспорить, но его применение (то что видел сам) ничем не отличалось. А вот сам билдер уже на чистой рефлексии. Всё это становится не нужным, как только у вас CRUD автогенерируется в виде кода билдером как выше.
Ну и про "отчетные" приложения, где часто и очень часто требуется не типовая выборка, а применение сложных и составных запросов: наличный авто-CRUD легко дополняется прямой сборкой запроса на SQL. Тут - полностью согласен, есть готовый уровень абстракции, незачем плодить обертки, мапперы и сущности. Проще иметь в команде одного или пару "гуру". И вопросы оптимизации работы с БД решаются если не на "раз", то на "два-три". ;)
Статья полезна, т.к. поднимается больной список вопросов, начиная с фантазий "а вот мы захотим переехать" (знакомо - sql-адаптеры к БД в разных Zend на PHP в частности).. ни разу не видел, чтобы кто-то переезжал имея развитый прод с мало-мальски приличной полезной нагрузкой. Зато обратное видел не единожды: "Почто тут всё ещё Перкона 5.7, можно же уже давно на 8-й мускуль мигрировать?" .. "ну, панимаите.. у нас тут стока легаси.." . Не-а, не панимаю. Переход описан даже в доках, особенно когда есть связки мастер-слейв.
Сорри за многа букв..
varanio Автор
04.12.2023 11:34а зачем squirrel рефлексия?
VladimirFarshatov
04.12.2023 11:34Там под капотом применяется иной пакет - билдер. Рефлексия в нем, а не самом squirrel. Но это два сильно связанных пакета.
github.com/lann/builder - тут билдер:
package builder
import (
"github.com/lann/ps"
"go/ast"
"reflect"
)В нем же применен пакет structurable и тоже с рефлексией:
package structurable
import (
"fmt"
"reflect"
"strings""github.com/Masterminds/squirrel")

CrushBy
04.12.2023 11:34+2Про чистоту архитектуры тоже можно вставить 5 копеек, чтобы два раза не вставать. Очень часто слои пересекаются. Как ни крути, но делать абсолютно 100% независимый слой бизнес-логики (юзкейсы, сервисы) иногда бывает очень дорого. Например, если тебе надо построить хитрый отчёт, ты будешь использовать SQL с группировками, оконными функциями, фильтрами и джойнами, выжимая из базы данных всё, что можно, включая грязные хаки. Там будет не до абстракций. Да просто сделать group by и посчитать количество тех, у кого count больше одного — это ведь уже бизнес-логика, вшитая в SQL.
Так чего уж там - бизнес-логика часто бывает и на фронте. Например, вот вводится у вас заказ - вам нужно посчитать и вывести пользователю его сумму. Проще всего сделать на JS на стороне браузера. И многие так и делают (ну можно конечно на сервер делать запросы, но это дополнительный round trip + дополнительный api). А потом в каком-нибудь отчете те же суммы подсчитываются через SUM() GROUP BY. В итоге логика тонким слоем размазана от самого верха до самого низа. И любое изменение логики потребует изменение всего.

Gadd
04.12.2023 11:34+1Мне кажется, что в ORM очень многое зависит от языка, для которого он реализован. К примеру, на SQLAlchemy можно построить очень понятные и при этом сложные запросы, во многом благодаря тому, что Python очень многое себе позволяет.
Кстати, частенько натыкался в интернете на вопросы типа "посоветуйте для языка N какой-нибудь ORM похожий на SQLAlchemy"varanio Автор
04.12.2023 11:34да, от языка точно зависит, очень много хорошего слышал про c#

Heggi
04.12.2023 11:34Я вот давно пишу на c#, но периодически посматриваю на другие языки, типа go, rust и т.п. И одно из первых на что я смотрю - это какие есть ORM, какой там функционал и удобство использования.
На текущий момент я не нашел настолько же сильного и удобного ORM как в шарпах (EF Core, но и он не идеален). Вполне возможно я что-то пропустил, тогда подскажите, обязательно посмотрю.
doctorw
04.12.2023 11:34Heggi
04.12.2023 11:34Глянул доку по диагонали. Нашел только одну фичу, которая перебила EF Core - это отсутствие глобального ChangeTracker и можно апдейтить/вставлять записи по одной (в редких случаях так надо, в EF Core для такого надо немного постараться, но тоже можно)
В общем киллер-фичи не нашел.


debagger
04.12.2023 11:34+7После .net-овского Orm'а всё, с чем приходилось работать на других языках и платформах - это какое-то детское недоразумение.

dtkbrbq
04.12.2023 11:34По 1 пункту не понятно, я всегда использую automap_base()(в SQLAlchemy) и никакой логики/связей/сущностей воспроизводить не приходится. Правда я работал только с маленькими и простыми базами, может не везде такой подход срабатывает.

konstantingreat9
04.12.2023 11:34-1О мой Бог, наконец-то! Спасибо тебе, человеческое, просто камень с души, я какой год думаю, что за маразм пихать этот ORM везде и всюду и убеждать всех и себя, что это самое правильное решение, да это панихида твоих продуктивности!, это тык мык и уже с базой работать не хочется.
PS: ради коммента зарегался по новой (добрые хабровчане заминусовали когда-то), спасибо за инфу по Go, может еще раз надо посмотреть на него ближе, раз концепция, что магия - это плохо.TrueRomanus
04.12.2023 11:34+2Просветите нас какой же способ не "панихида продуктивности"?
ritorichesky_echpochmak
04.12.2023 11:34+4Это люди просто не разобрались как работает ORM (которая умеет, кэшировать, подписываться на изменения в БД и оптимизировать некоторые сложные выборки, как Entity Framework), как у них будет работать их клёвый маппинг `select всё` после того как порядок полей поменяется, как отслеживаются изменения (чтобы не делать update всё для всех если поменялось только одно поле или реальные данные вообще не изменились), как нормально экранировать это всё от всяких скрипткиддисов (особенно если проект должен работать не с одной единственной СУБД на свете). Я не представляю себе ни один более-менее крупный активный проект без нормальной ORM.
Сырые запросы иногда можно использовать в каких-то ну крайне специфичных кейсах... но мне давно не приходилось (последний раз кажется это вообще был SphinxSearch). Вся эта "панихида" выглядит как истерика джунов у которых на курсах только-только начали проходить ORM

AgentFire
04.12.2023 11:34Соглашусь, ни в комменте выше, ни даже в статье не даны хоть какие либо сильные аргументы против ORM.
Слабо прослеживалась "концентрация на частностях", как прием демагогии.

Didntread
04.12.2023 11:34+1ну вот написали вы sql скрипт для генерации схемы бд, написали запросы на голом sql. Что одно другому соответствует вы будете в рантайме валидировать? Orm валидирует при компиляции.
konstantingreat9
04.12.2023 11:34я не против абстракций, но мне не нравиться писать условия через них, но например в битриксе, когда используются инфоблоки, я пользуюсь их getlist-ом, но она не позиционируется как orm, хотя если докопаться таковой является;
получается orm может вносить порядок и простоту, но для быстрых вещей я бы использовал чистые запросы через оболочку query('SELECT ...')

MaxPro33
04.12.2023 11:34+2Вы утверждаете, что ORM хорош для простых CRUD-приложений, но может стать препятствием при более сложных сценариях. Какие, по вашему мнению, являются наиболее распространенными сценариями, где ORM проявляет свои ограничения?
varanio Автор
04.12.2023 11:34более сложный для чтения язык запросов, подкапотная магия по построению SQL-запросов

Shiko_Siberia
04.12.2023 11:34+1spring.jpa.show-sql: true в application и jpa из магии превращается в sql-код.
ColdPhoenix
04.12.2023 11:34Ты просто не можешь не знать, что у тебя под капотом происходит. Какие там делаются джойны и группировки.
Разве во всех уважающих себя ORM нет логирования? где можно посмотреть что там делается.
AgentFire
04.12.2023 11:34Возможно, что смотреть лог или разок сделать .ToQueryString() при отладке - значит не уважать себя.
kasthack_phoenix
04.12.2023 11:34А это даже не при отладке. По-хорошему, метрики снимаются с сэмпла всех запросов от аппки и зажигаются алерты по долгим запросам и висит дэшборд запросов с наибольшим общим временем выполнения / временем выполнения одного.
varanio Автор
04.12.2023 11:34ну вот увидел я в логе какую-то дичь, что дальше делать?
Kerman
04.12.2023 11:34+3Для начала больше не использовать аргумент "не можешь знать, что под капотом происходит".
ritorichesky_echpochmak
04.12.2023 11:34Видимо не увидели, потому что там будет запрос который упал, его аргументы и стэк-трейс откуда это всё успешно вальнулось. В отличие от рукописных запросов, которые "сразу идеально написаны, поэтому можно это всё не логать, я слишком занят чтобы обмазывать это логами и ORMами"
ColdPhoenix
04.12.2023 11:341)Иногда EF сама может подсказать что запрос получился ужасным и его приходится вычислять на клиенте.
2)Узнать где проблема, у вас будет уже представление куда рыть, какой синтаксис повёл себя не так как Вы думали должен себя вести(в 90% случаев достаточно нажать F1 и все станет ясно)
3)На крайний случай всегда можно перейти в RAW запросы.
На практике я не сталкивался с тем чтоб EF вёл себя

Ant80
04.12.2023 11:34ИМХО для задач типа редактирования и вывода карточек чего угодно без ORM всё равно придётся делать самописный аналог ORM. и никто же не запрещает комбинировать ORM и прямые SQL-запросы.

fransua
04.12.2023 11:34Проблему 1 и 3 может решить хороший ORM, например вышеупомянутый EF. Приведенные в статье примеры действительно выглядят жутко. Проблема 2 не решается даже написанием SQL - часто нельзя предугадать какой план построит БД, да и он может меняться от запуска к запуску.
Когда запрос является бутылочным горлышком надежнее использовать SQL, сохраненный на сервере в виде табличной функции или процедуры.
Переход на другую БД у меня был, с MS на Postgres, из-за политики. Без ORM было бы очень больно, так что матожидание усилий от 0.1% получается значительным.
PaulIsh
04.12.2023 11:34+1Для проблемы 2 можно сделать view, которая будет использовать что нужно, в том числе табличные функции, а в приложении сделать модель на view.
michael_v89
04.12.2023 11:34При использовании ORM мы обычно прописываем в коде сущности и их взаимосвязи, и по сути это — проектирование БД ещё раз (дублирование логики!) прямо в коде.
Ну так на то он и маппинг. Это больше следствие наличия двух концов канала связи. "Здесь" должно быть то же самое, что "там".
Аналогично на фронтенде делают классы, которые есть на бэкенде. Или в клиенте к API делают классы, которые предоставляет сервис с этим API.Ты просто не можешь не знать, что у тебя под капотом происходит
Мне кажется, аргумент "Не надо знать, что там происходит" используется только в SEO-оптимизированных статьях, чтобы воды было побольше.
длинные запросы на Eloquent меня иногда изумляли своей сложностью чтения:
Выглядит как запрос для внутренней админки или отчета, тем более используется
DATE(created_at) = ..., значит производительность тут не главное.Можно сделать так.
$dates = [$date->format('Y-m-d'), $date->modify('+1 day -1 second')->format('Y-m-d')]; $subq1 = Click::select(Db::raw('COUNT(id)'))->where('ad_id', '=', Db::raw('ads.id')) ->whereBetween('created_at', $dates)->groupBy('ad_id'); $subq2 = Show::select(Db::raw('COUNT(id)'))->where('ad_id', '=', Db::raw('ads.id')) ->whereBetween('created_at', $dates)->groupBy('ad_id'); $query = Ad::select(DB::raw(" ads.*, {$subq1->toSql()} as clicks_count, {$subq2->toSql()} as shows_count, ")) ->with('devices', 'platforms');Или так.
$query = Ad::select(DB::raw(' ads.*, SUM(IF(DATE(clicks.created_at) = $date, 0, 1)) as clicks_count, SUM(IF(DATE(shows.created_at) = $date, 0, 1)) as shows_count ')) ->leftJoinRelationship('clicks') ->leftJoinRelationship('shows') ->groupBy('ads.id') ->with('devices', 'platforms');Eloquent вроде бы не умеет join по связи, надо ставить расширение, что означает, что это фиговый ORM.
CTR лучше вычислять в приложении. Вообще не очень красиво грузить эти дополнительные поля в объект Ad, лучше сделать какой-нибудь AdReportRow с нужными полями, и там можно сделать связь с Ad. Или использовать toArray().
1CUnlimited
04.12.2023 11:34-1Да просто проектировщики ORM на "нормальных языках" , почему-то проектируют библиотеки ORM не для работы с наборами записей, а для работы с отдельными записями (типа FindById) , в лучшем случае дают Recordset. И каждую таблицу инкапсулируют в один объект\класс. Например в Java JPA так.
А соединение таблиц тогда в лучшем случае выглядит как соединение разных объектов с заклинаниями, т.е. менее читаемо чем в SQL .
В 1С, например, делают ORM который отражает бизнес сущности как Документ, регистр бухгалтерии, Справочник. И это уже удобно и реально себя чувствуешь независимым от СУБД а скорость разработки 100% окупается
А прямая связь ORM 1C с интерфейсом это вообще кайф в отличии от Java, Net, где это нужно каждый раз руками прописывать
Правда в 1С сама ORM библиотека ориентирована на операции в рамках одного экземпляра объекта - например можно записать один документ,а не сразу несколько подготовленных.
К чему это приводит проверено тут Концепция ORM как двигатель прогресса – выявит слабое место Вашей СУБД / Хабр (habr.com)
Поэтому проблема не в концепции, а в проектировщиках библиотек ORM которые кроме дополнительной абстракции , не думают о простоте применения
ritorichesky_echpochmak
04.12.2023 11:34+2Т.е. вы нормальных ORM не видели, либо не разобрались, пришли просто попиарить свою статью и 1С? FoxPro когда-то с точно таким же апломбом и связью таблиц с интерфейсом... закопали и славненько
1CUnlimited
04.12.2023 11:34-2А вы нормальный ORM видели, на языках класса Java или .Net ? Приведите пример
я посмотрю чем они от JPA или Hibernate или Spring data отличаются. Или Вы считаете что в Java нормальный удобный ORM?
Foxpro насколько я помню клиент сервером был чистым всегда. А 1С трехзвенка, и эту связь таблиц с интерфейсом она сразу и в Web может отразить, без особых усилий.
ritorichesky_echpochmak
04.12.2023 11:34+2Тот же максимально попсовый EF Core с подходом code first прекрасно работает и с наборами записей и с множественными связанными объектами и с представлениями собранными из нескольких таблиц. Хранить один Entity в одной таблице - это вообще-то нормально. В отличие от размазывания связи чего-то к чему-то через что-то в справочнике справочника справочников к справочнику. Про FoxPro - он вообще-то раньше научился в запросы к другим БД и веб, чем 1С, которая до 7.7 включительно не умела вообще ничего кроме того же dBase который ранее использовал FoxPro, только с максимально отвратной структурой таблиц и вечно ломающимися индексами
1CUnlimited
04.12.2023 11:34-2Это пример хорошего ORM ? Entity Framework Core | Соединение и группировка таблиц (metanit.com) т.е. это считается проще чем Join на SQL написать?
По ссылке видно что ради
SELECT[c].[Name] AS[Key], COUNT(*) AS[Count]FROM[Users] AS[u]INNERJOIN[Companies] AS[c] ON[u].[CompanyId] = [c].[Id]GROUPBY[c].[Name]приходится думать как это выразить в классах и объектах.
Одно дело когда вы написали класс Документ, который может управлять пятью таблицами не опускаясь на их уровень, а другое дело когда Вы эти таблицы тупо отображаете в классы, чтобы соединять их как запросы.
Даже в любой стоящей СУБД есть View есть Materialized view для урощения работы с набором таблиц
В том же 1С для своих ORM метаданных сделаи язык запросов - он не похож на SQL , но он удобен именно для их метаданных. Это еще раз показывает что ORM можно проектировать удобно, а не пытаться просто натянуть реляционную структуру на классы
ColdPhoenix
04.12.2023 11:34Естественно вещь в своём кружке может быть лучше.
Только вот в 1C вы создали таки этот тип, пусть и в интерфейсе, но сделали.
А давайте поставим .NET и 1C на равне?
Вы сейчас противопоставляете database first для .Net против code first(а конфигурация это именно code first по факту)
А вы можете в 1C запихнуть произвольную БД?
1CUnlimited
04.12.2023 11:34В 1С уже запихнули - называется внешние источники данных . Внешний источник данных (1c.ru) чтото по мотивам MS ADO . А кстати ADO считать ORM или нет ? :)
ColdPhoenix
04.12.2023 11:34Ах да, scaffolding сторонних БД, вы серьёзно думаете что такое есть только в 1С?
Ну если я верно понимаю то основной аргумент за крутость 1С это то что у нее язык и IDE и БД связано воедино?
1CUnlimited
04.12.2023 11:34Ах да, scaffolding сторонних БД, вы серьёзно думаете что такое есть только в 1С?
Откуда такой вопрос - я вроде их образец для подражания привел MS ADO, правда у 1С для внешних источников всеравно получился аналог регистра сведений :) , что не дает работать с фильтрам по нескольким ключам. 1С всегда заимствует технологии, поскольку разработчики платформы сами пишут на C++ и сейчас уже много Java
Ну если я верно понимаю то основной аргумент за крутость 1С это то что у нее язык и IDE и БД связано воедино?
Вот тут ответ на конкретном примере
https://habr.com/ru/companies/karuna/articles/774478/comments/#comment_26231852
ritorichesky_echpochmak
04.12.2023 11:341 Класс = 1 сущность. То что не все 1С-ники разобрались какие сущности и как они хранят и какая там в БД помойка... не моя проблема. Нормальные БД в 1С пришли сравнительно недавно и то в небольшом количестве. Хуже 1С и Битрикс в плане инфраструктуры хранения данных нужно очень сильно постараться что-то найти. Но в Битрикс есть хоть какие-то интеграции, когда же нужно организовать обмен с 1С есть только один работающий кое-как вариант - xml, который ещё и отличаться будет от кастомера к кастомеру...
Удобство ORM для 1С звучит как насмешка. Я бы не называл это ORM, оно не отражает реальное состояние дел в БД примерно никак.
И да, это
var groups = from u in db.Users group u by u.Company.Name into g select new { g.Key, Count = g.Count() };проще, короче (120 знаков против 150) и более безопасно чем
SELECT [c].[Name] AS [Key], COUNT(*) AS [Count] FROM [Users] AS [u] INNER JOIN [Companies] AS [c] ON [u].[CompanyId] = [c].[Id] GROUP BY [c].[Name]Есть защита и от опечаток, и от выборки поля не того типа. Читается по итогу легче. И использование нужных полей легко ищется по коду потом (внезапно, поддерживаемость софта капец как важна).
А главное отлично логируется, бенчмаркается и т.д. т т.п. без лишней лапши
1CUnlimited
04.12.2023 11:34-2Когда создатели SQL делали язык "Авторы надеялись, что после небольшой практики даже пользователи-неспециалисты (например, бухгалтеры, инженеры, архитекторы, градостроители[6]) смогут читать запросы так, словно последние написаны на обычном английском языке. "
А вот то что тут в 120 знаках это шаг назад в сторону языка удобного для компилятора (интерпретатора) но человека.
То что не все 1С-ники разобрались какие сущности и как они хранят и какая там в БД помойка... не моя проблема. Нормальные БД в 1С пришли сравнительно недавно и то в небольшом количестве. Хуже 1С и Битрикс в плане инфраструктуры хранения данных нужно очень сильно постараться что-то найти. Но в Битрикс есть хоть какие-то интеграции, когда же нужно организовать обмен с 1С есть только один работающий кое-как вариант - xml, который ещё и отличаться будет от кастомера к кастомеру...
Сколько лжи в одной фразе Вы бы хоть посмотрели на сайт своего врага
Проблемы в ORM 1С есть на более высоком уровне, но Вам это знать не обязательно - сочините сами
ritorichesky_echpochmak
04.12.2023 11:34+1А почему вы не написали что шаг в сторону машинных кодов? ЯПВУ же делались не для людей, ага. Вот это действительно ложь, как, впрочем, и некое превосходство ORM 1С над другими.
То что на оф.сайте пытаются продать тёплое как мягкое очень плохо соотносится с опытом реальных интеграций который я имел ещё несколько лет назад. Выгрести данные из этой помойки за адекватное время и адекватный прайс было невозможно. Писать полноценный API для 1С-ника - это какая-то дичь) Формошлёпить - это да, это они готовы. Потом только при экспорте БД иногда прогрессивная ORM досила, но это ж не проблемы формошлёперов, а проблемы тех, кому приходится с этим цирком жить, нужно просто сервер помощнее, версию поновее, да интеграцию подороже и "кааааак заживёёём"...

Naf2000
04.12.2023 11:34почему не похож? Просто перевели оператор SELECT и надстроек добавили:
ВЫБРАТЬ СпрНоменклатура.Ссылка КАК Ссылка, ПродажиОбороты.КоличествоОборот КАК КоличествоПродано, ТоварыНаСкладахОстатки.КоличествоОстаток КАК КоличествоОстаток ИЗ Справочник.Номенклатура КАК СпрНоменклатура ЛЕВОЕ СОЕДИНЕНИЕ РегистрНакопления.ТоварыНаСкладах.Остатки(&ДатаОкончания, Номенклатура В ИЕРАРХИИ (&СписокГрупп)) КАК ТоварыНаСкладахОстатки ПО (ТоварыНаСкладахОстатки.Номенклатура = СпрНоменклатура.Ссылка) ЛЕВОЕ СОЕДИНЕНИЕ РегистрНакопления.Продажи.Обороты(&ДатаНачала, &ДатаОкончания, , Номенклатура В ИЕРАРХИИ (&СписокГрупп)) КАК ПродажиОбороты ПО (ПродажиОбороты.Номенклатура = СпрНоменклатура.Ссылка) ГДЕ СпрНоменклатура.Ссылка В ИЕРАРХИИ(&СписокГрупп)1CUnlimited
04.12.2023 11:34Похожесть тут как у Лайки и СенБернара. Если в ORM Java Net приходится делать заклинания для перевода классов в SQL как выше https://habr.com/ru/companies/karuna/articles/774478/comments/#comment_26230676
для генерации SQL
А у 1С наоборот, есть метаданные (типа классов) и язык запросов он оперирует именно метаданными. Собственно SQL уже генерится платформой
Вот тут например РегистрНакопления.ТоварыНаСкладах.Остатки(&ДатаОкончания, Номенклатура В ИЕРАРХИИ (&СписокГрупп)) КАК ТоварыНаСкладахОстатки
Идет обращение к итогам регистра накопления, и там может быть ситуация когда за прошлые периоды можно взять данные по итогам, а за текущий только по оборотам . А платформа это все разрулит
В языках типа .Net или Java есть ощущение, что удобный ORM можно получить если построить его на Лямда выражениях . Всетаки СУБД основан на реляционной алгебре . Концепция реляционных баз поэтому и живучая такак изначально была основана на проработанной теории.
Вот например кто то уже поэкспериментировал на Pyton
Queries — Pony ORM documentation
на первый взгляд кажется красиво
michael_v89
04.12.2023 11:34Вы пишете какую-то ерунду, которая не связана со сценариями применения ОРМ в обычных языках программирования. SQL в ORM тоже генерится платформой. Давайте рассмотрим конкретный код.
Вот у меня есть веб-интерфейс, по запросу от пользователя нужно поменять сущность в базе, предварительно проверив условия.class ProductController { public function actionSave(string $id, SaveProductDto $inputData) { $product = $this->productRepository->find($id); if ($product === null) { return $this->jsonRepsonse(404, 'Product not found'); } if ($product->status === ProductStatus::Published) { return $this->jsonRepsonse(400, 'Cannot edit published product'); } $this->productService->save($product, $inputData); } } class ProductService { public function save(Product $product, SaveProductDto $inputData) { $product->setTitle($inputData->title); $product->setDescription($inputData->description); $this->entityManager->save($product); $this->entityManager->flush(); $this->sendEventToAnotherSystem($product); } private function sendEventToAnotherSystem(Product $product) { $this->queue->send(Event::ProductChanged, [ 'id' => $product->getId(), 'title' => $product->getTitle(), 'description' => $product->getDescription(), ]); } } class SaveProductDto { public string $title; public string $description; } #[ORM\Entity] class Product { #[ORM\Column] private ?int $id; #[ORM\Column] private string $title; #[ORM\Column] private string $description; #[ORM\Column] private ProductStatus $status; // ... } enum ProductStatus: int { case Hidden = 0; case Published = 1; }Важный момент тут это типизация в аргументах функций и описание структуры данных.
Покажите пожалуйста аналогичный код на 1С.
asmm
04.12.2023 11:34Михаил, Михаил, столько времени прошло, а Вы тут с настолько позорным кодом выступаете в его поддержку....
michael_v89
04.12.2023 11:34У вас есть что сказать по теме обсуждения? То приложение я написал, а вы нет.
asmm
04.12.2023 11:34Конечно, конечно. Код не выдерживает никакой критики, особенно в рамках обсуждения СУБД.Первая строка кода выглядит многообещающе. Вторая, уже подозрительно. Глядя на третью, уже всё понимаешь: приложение даже не пробует получить какую-то блокировку на запись, оно просто читает, хотя из второй строчки кода складывается впечатление что мы будем писать "...Save... ...inputData". Смотришь дальше и волосы на голове начинают шевелиться, тем более что у Ларавеле есть метод что бы эти строки не писать - findOrFail. А пока мы над всем этим переживали, прилетевшие данные подлетели, посмотрели насчёт published статуса и перепрыгнули на сохранение, на 12 строке... Но сохранения никого не произошло, т.к. другая сессия уже удалила эти данные. Вот и сказочке конец, а один единственный UPDATE решил бы все эти проблемы чуть более чем полностью.
P.S. слава богу что не я
michael_v89
04.12.2023 11:34Я возможно открою вам секрет, но примеры в комментариях нужны чтобы проиллюстрировать конкретные моменты, связанные с темой обсуждения, и могут не содержать всего кода, который будет в продакшене. Или вы серьезно думаете, что в товаре может быть всего 3 поля? И это мы ещё не начинали про систему контроля доступа.
Если вас это настолько беспокоит, можете представить, что в методе find есть второй аргумент со значением по умолчаниюneedLock = true. Вот так лёгким движением руки ваши рассуждения становятся бессмысленными.тем более что у Ларавеле есть метод что бы эти строки не писать - findOrFail
1. Это не Laravel.
2. findOrFail это ужасное архитектурное решение. Это мое дело решать когда какой код ответа отправлять и с каким сообщением, а не фреймворку.слава богу что не я
Я имел в виду приложение, в котором вы хотели показать, насколько проще становится код с логикой в БД. Мы договаривались его оба написать. Я свой вариант написал, вы нет. Вот когда напишете, тогда и будем обсуждать. Здесь обсуждается использование ORM в приложении, поэтому мой пример показывает использование ORM в приложении.
lair
04.12.2023 11:34В языках типа .Net или Java есть ощущение, что удобный ORM можно получить если построить его на Лямда выражениях .
Все известные мне удобные ORM в .net (это, кстати, не язык) построены на лямбда-выражениях, которые трансформируются в дерево запроса. И?..
ColdPhoenix
04.12.2023 11:34Одно дело когда вы написали класс Документ, который может управлять пятью таблицами не опускаясь на их уровень, а другое дело когда Вы эти таблицы тупо отображаете в классы, чтобы соединять их как запросы.
Пропустил этот момент. А почему у вас в 1С создание класса для хранения в БД это хорошо, а в .NET создание класса для того же это плохо?
1CUnlimited
04.12.2023 11:34Потому что в 1С Вы проектируете метаданные с нужными полями (класс Документ) с нужными реквизитами и если нужно табличными частями и уже потом платформа сама создает не только все таблицы но и оптимальные индексы под это. Кстати Документ в 1С это достаточно универсальный объект его можно применять не только для документов. 1С это пожет потому что у нее есть стандартизированная среда исполнения (грубо говоря контейнер)
В .Net насколько помню можно делать похожее но только на уровне создаем класс, держим в уме таблицу которой он будет соотвествовать. А так чтобы сделать класс , а Net. отразил бы это в несколько таблиц? Вот для XML Java сделали JAXB Examples (The Java™ Tutorials > Java Architecture for XML Binding (JAXB) > Introduction to JAXB) (oracle.com)
а для СУБД я похожего не видел, только на уровне класс-в-одну таблицу
ColdPhoenix
04.12.2023 11:34Потому что в 1С Вы проектируете метаданные с нужными полями (класс Документ) с нужными реквизитами и если нужно табличными частями и уже потом платформа сама создает не только все таблицы но и оптимальные индексы под это.
В .Net тоже самое, только кодом. честно не вижу разницы(разделять там тоже можно).
Посмотрел я на ваши индексы, любые доп индексы надо так же ставить флаг Индексировать.
В .Net насколько помню можно делать похожее но только на уровне создаем класс, держим в уме таблицу которой он будет соотвествовать.
А зачем держать в голове это? Вы в 1С это делаете?
А так чтобы сделать класс , а Net. отразил бы это в несколько таблиц?
Есть разделение таблиц там.
Я вот не вижу глобально разницы, вот серьезно.
Создание метаданных в данном случае равноценно созданию классов. Это именно code-first по факту.
1CUnlimited
04.12.2023 11:34Создание метаданных в данном случае равноценно созданию классов. Это именно code-first по факту.
Есть разделение таблиц там.
Если потратил один раз время на описание классов в Net а потом быстро едешь, это нормально.
А вот когда на ООП а не декларативном языке
Расширенное сопоставление таблиц — EF Core | Microsoft Learn
нужно написать это
modelBuilder.Entity(
dob =>
{
dob.ToTable("Orders");
dob.Property(o => o.Status).HasColumnName("Status");
});modelBuilder.Entity(
ob =>
{
ob.ToTable("Orders");
ob.Property(o => o.Status).HasColumnName("Status");
ob.HasOne(o => o.DetailedOrder).WithOne()
.HasForeignKey(o => o.Id);
ob.Navigation(o => o.DetailedOrder).IsRequired();
});Я понимаю что Индусы которым платят за строчки кода будут счастливы, а вот если работаешь на результат затраты уже будут влиять на профит
Какой то разрыв получается, для СУБД есть куча дизайнеров структуры данных со связями
Для ООП куча кода которым это можно сделать, а может быть есть ORM с дизайнером?
lair
04.12.2023 11:34А вот когда на ООП а не декларативном языке нужно написать это
Когда я последний раз пробовал это делать, это было необязательно. Хочешь точный контроль над БД - используешь, не хочешь - не используешь.
ColdPhoenix
04.12.2023 11:34А вот когда на ООП а не декларативном языке
Такое нужно только для расширенных вещей как раз.
или у вас в 1С табличные части сами себя объявляют?
Вы делаете тоже самое, только другим способом.
Кстати пример там не на разбитие на части, а наоборот, чтоб два класса были в одной таблице.
Я понимаю что Индусы которым платят за строчки кода будут счастливы, а вот если работаешь на результат затраты уже будут влиять на профит
Это пишется один раз как бы.
У вас аргумент на уровне, кошмар, тут надо чуть больше написать. Это какое-то передергивание просто уже.
Я понимаю что в 1С это все спрятано за интерфейсом, но все же аналогичные действия нужно делать так или иначе.
а может быть есть ORM с дизайнером?
Для EF есть дизайнеры.
Поймите, то что у вас чуть меньше одноразовых действий, не делает 1С прям офигенной, да на спорю, это неплохо. Но чтоб прям уберфича? нет.
Поэтому предлагаю закончить обсуждение одноразовых действий.
michael_v89
04.12.2023 11:34-1Человек явно не работал с ORM в других языках кроме 1С, что вы хотите) Плохо что вместо нормальных вопросов он проявляет воинствующее невежество.
1CUnlimited
04.12.2023 11:34или у вас в 1С табличные части сами себя объявляют?
Табличная часть в документе это просто дополнительная возможность например впихнуть туда справочник товаров, в добавок к шапке документа. Я могу их сколько угодно сделать. .Записать() сразу записывает и шапку и табличную часть если она есть.
Для EF есть дизайнеры.
Поймите, то что у вас чуть меньше одноразовых действий, не делает 1С прям офигенной, да на спорю, это неплохо. Но
чтоб прям уберфича? нет.
А можно пример EF дизайнера , это очередной генератор сырого кода или что то более интересной?
Причем тут одноразовые действия. Тут две уберфичи
Визуальный дизайнер готового приложения, и язык запросов который заточен на метаданные (с итогами я пример приводил выше) , а не на эмуляцию SQL
В 1С документ нарисовал и он уже рабочий , его можно вводить руками. Он уже полнофункциональный его можно вводить, удалять, заполять. Если специально не посмотреть как формируются SQL операторы трассировкой , так никогда и не узнаешь.
Но ладно, что я тут про Low coding когда сравниваемся с .Net
Раньше был Access был в моде, где почемуто Не предлагали сразу наделать много кода. А делали когда уже задизайнили форму и таблички. А сейчас ради полностью разделенного фронт, и бэкэнд и СУБД сразу все уезжает в Code first. То что можно хранить с в XML как статическую информацию со связями, переезжает в код. И его становится еще больше и больше
michael_v89
04.12.2023 11:34и язык запросов который заточен на метаданные (с итогами я пример приводил выше)
Покажите пожалуйста, как с вашим языком, который заточен на метаданные, сохранить товар в базу (пример я тоже приводил выше). ORM нужен именно для этих кейсов - сохранить данные из приложения в базу и потом загрузить их обратно в приложение с сохранением типизации и структуры данных. То есть чтобы в приложении можно было работать не с array произвольного размера, а с объектом класса Product на 10 известных полей. Визуальный интерфейс для этих целей низачем не нужен.
ColdPhoenix
04.12.2023 11:34А давайте интерфейс сюда впихивать не будем? мы про ORM говорили.
Табличная часть в документе это просто дополнительная возможность например впихнуть туда справочник товаров, в добавок к шапке документа. Я могу их сколько угодно сделать. .Записать() сразу записывает и шапку и табличную часть если она есть.
Так же и в EF. SaveChanges и все. Бегло посмотрел, табличные части напоминает доп связи, это все можно сделать в EF.(и нет, это не будет тысячи строк кода)
Если специально не посмотреть как формируются SQL операторы трассировкой , так никогда и не узнаешь.
Что ровно аналогично тому что есть в других ORM.
а не на эмуляцию SQL
Если мы не берем SimpleORM, например Dapper, но мы не пишем SQL. в EF используется LINQ, он же используется и просто в коллекциях. у LINQ есть 2 синтаксиса, 1 это SQL-подобный(я лично его не люблю), и второй это методы на коллекциях, db.Users.Where() и я просто пишу стандартный C#. можно даже не задумываться об SQL.
и язык запросов который заточен на метаданные
Вы про тот синтаксис что выше показывали(ВЫБРАТЬ, ИЗ, ГДЕ) ?
Если да, то мне в EF не нужно на такой почти-SQL переходить чтоб получить такой результат. Я просто работаю с объектами, и могу получить результат любого типа, а не весь документ.
Пример с переводом вашего SQL в LINQ-SQL синтаксис приводили. Но я бы предпочел через методы
db.Users.GroupBy(u=>u.Company.Name).ToDictionary(g=>g.Key, g=>g.Count());Это вернет мне готовый словарь [Имя компании] => [Количество пользователей в ней].
Как видите на уровень SQL опускать не приходится. И такой же код используется при работе со списками и в целом любым итерируемым.
А можно пример EF дизайнера , это очередной генератор сырого кода или что то более интересной?
А что вам нужно? вы просили визуальный дизайнер БД, а не генератор приложений.
LLBLGen Pro, DevArt Entity Developer Entity Framework Visual Editor.
Есть и генераторы CRUD WebApi.
Раньше был Access был в моде, где почемуто Не предлагали сразу наделать много кода. А делали когда уже задизайнили форму и таблички.
И где сейчас этот Access?
И его становится еще больше и больше
Без ORM его меньше не станет.
То что можно хранить с в XML как статическую информацию со связями, переезжает в код.
Hibernate вполне любит XML, И далее, у вас все равно по факту есть классы, только за вас их генерирует 1С.
В случае EF Code-First у нас код генерирует метаданные.
А сейчас ради полностью разделенного фронт, и бэкэнд и СУБД сразу все уезжает в Code first.
А что всем клиентам надо ставить тонкий клиент 1С чтоб Вам не пришлось разделять фронт и бэк?
Реальным клиентам нужен веб сайт, который будет работать, потом мобильное приложение и тп. а не формочки в 1С.(и чтоб они выглядели как им надо, а не как разработчики 1С решили)
Возьмите реальное веб-приложение, да тот же хабр или StackOverflow, почему он не на 1С написан тогда? раз там все так круто.
1С ограничена своей предметной областью, как бы то не было. Это ограничение дает ей преимущество внутри этой области, но вне нее, сразу начинаются проблемы.
Я не говорю что 1С плохая, да фичи, как я сказал прикольные, но вне 1С мира, они не нужны. мне не нужны визуальный редактор документов, когда мне нужно написать вебсайт по заказу услуг(возьмем например любую VDS), от этого все и идет. Я понимаю что все кажется гвоздем когда в руках молоток, но все же всему свое место.
lair
04.12.2023 11:34То что можно хранить с в XML как статическую информацию со связями, переезжает в код.
Я хорошо помню, как первые реализации EF хранили метаданные в xml. Так вот, в коде мне удобнее - я программист, я с кодом работаю, зачем мне еще одно отдельное хранилище?
PuerteMuerte
04.12.2023 11:34+1А вот когда на ООП а не декларативном языке
Расширенное сопоставление таблиц — EF Core | Microsoft Learn
нужно написать это
В общем случае можно и на вполне себе декларативном, если хотите, прямо в модели данных:
[Table("Orders")] public class dob { //хотя нафига задавать маппинг, если имена совпадают... [Column("Status")] public SomeType Status { get; set; } }Настройки через modelBuilder нужны, только если совсем уж странненького хочется
michael_v89
04.12.2023 11:34А так чтобы сделать класс , а Net. отразил бы это в несколько таблиц?
В обычных приложениях такие сценарии не нужны. Можно считать приложение аналогом движка 1С, который отражает документ в несколько таблиц. Если бы вы писали саму реализацию сохранения в несколько таблиц, вы бы работали с каждой таблицей отдельно. Приложение это и есть такая реализация, специфичная для каждого бизнеса. В интерфейсе пользователя одна кнопка, а внутри приложения данные могут сохраняться в несколько таблиц.


ebt
04.12.2023 11:34+1Основной теоретический аргумент против ORM — это проблема объектно-реляционного разрыва.

MaslovRG
04.12.2023 11:34+3Комментарий по пунктам, со стороны шарписта конечно
Используешь Code First: описываешь сущности классами, схема базы создается и меняется сама через миграции под нужную базу. Если что-то не устроило можешь ручками аккуратно поправить. Или даже неаккуратно вписать в миграцию какой-нибудь sql-скрипт. Нужно сложное получение - можно написать и пролить представление, замаппить его через ToView
В sql для сложных запросов вполне возможно сильно накосячить и получить снижение производительности. Был анекдотичный случай. Сложный, загруженный расчёт на sql-процедурах, куча join-ов, insert-ов и всего такого. Потребовалось переписать на Code First (чтобы несколько баз поддерживало), перенесли все вычисления и логику чисто на c#, к базе через EF Core чисто за данными лезли (получить/записать), ожидали просадки скорости работы. Результат? Стало работать в 100 раз быстрее... Похоже куча сложных join-ов к одним и тем же не столь большим таблицам ели производительности и сильно, получить один раз в словарики оказалось быстрее. Вероятнее всего причиной такой ситуации стала не особо высокая квалификация команды, но факт остается фактом.
В шарпе есть linq, который постоянно с любыми коллекциями используется, ничего доучивать и придумывать не надо (почти)

FanatPHP
04.12.2023 11:34+5TL;DR: Red jacket guy meme.JPG
Квери билдер на Ларавле - спасибо не надо
Квери билдер на Го - со всем нашим уважением!
Я тоже иногда в полемическом задоре несу чушь и не замечаю, что соседние абзацы статьи противоречат друг другу. Но для этого и существует вычитка.
Пример "плохого" кода на Ларавле - "это именно queryBuilder, а не ORM". А никакого "отображения сущностей на реляции и магических неявных джойнов под капотом" в этом примере кода может и не быть. При этом внезапно точно такой же "язык запросов в виде цепочки объектов и методов" на Го - образец для подражания.
Реальные же проблемы ORM, в частности печально известный Object–relational impedance mismatch вообще никак не затронуты.
Негодная статья, больше похоже на наброс.
PuerteMuerte
04.12.2023 11:34+3В итоге непонятно, для чего козе боян
Козе боян нужен, например, для того, чтобы иметь и развивать одну модель данных в приложении, а не две и синхронизировать их между собой.
Конечно, это вот так себе
$query = Ad:: select(array('ads.*', DB::raw('COUNT(DISTINCT clicks.id) as clicks_count'), DB::raw('COUNT(DISTINCT shows.id) as shows_count'), DB::raw('(COUNT(DISTINCT clicks.id) * COUNT(DISTINCT shows.id))/100 as CTR'))) ->leftJoin('clicks', function($join) use($date){ $join->on('ads.id', '=', 'clicks.ad_id')->where(DB::raw('DATE(clicks.created_at)'), '=', $date); }) ->leftJoin('shows', function($join) use($date){ $join->on('ads.id', '=', 'shows.ad_id')->where(DB::raw('DATE(shows.created_at)'), '=', $date); }) ->groupBy('ads.id')->with('devices', 'platforms');Ну а если как-нибудь так?
var ads = dbcontext.ads .Include(ads => ads.clicks.Where(c => c.created_at == show_date)) .Include(ads => ads.shows.Where(s => s.created_at == show_date)) .Where(ads => ads.clicks.count > 0 && ads.shows.count > 0) .GroupBy(ads => new { ads.devices, ads.platforms }});Может, то просто смотря какой у вас ORM?
ORM здорового человека позволяет иметь только модель данных в приложении и работать только с ней, максимально избегая написания заковыристых запросов к базе данных, и тем более не заставляя их писать на SQL или полу-SQL.

LeshiyUrban
04.12.2023 11:34Для Го порекомендую
если нужно много запросов и не хочется писать типы: SQLC https://github.com/sqlc-dev/sqlc
если хочется чего-то быстро прикрутить но с атомаперром и типами: микро обертку над sqlx https://github.com/reddec/gsql

RikkiMongoose
04.12.2023 11:34+1Текст пестрит такими мощными аргументами как "возможно", "вероятно" и "скорее всего". Ну и вероятность в 0.01% - взята, очевидно, из головы.

AlexOrlov_KG
04.12.2023 11:34-3ORM создан для преодоления разрыва между объектными языками программирования и реляционными базами. Это лишнее звено, если использовать тру объектную базу, например, Versant. 16 лет используем Versant и вспоминаем реляционные базы как страшный сон. Написал про это статью, про ORM в ней тоже есть. https://vc.ru/263279 по моему мнению, ORM в современном мире, для новых проектов - не нужен. Это легаси, наследие царского режима. ))

vsting
04.12.2023 11:34+1Следует в названии статьи уточнять, о ОРМ в реализации какого языка программирования идёт речь. Но судя потому, как оно выглядит на PHP, то да, в этом случае лучше уж на чистом SQL писать.

kivan_mih
04.12.2023 11:34+2Кажется автор тонко тролит, чтобы собрать побольше комментариев :) Но мне не лень, я напишу. ORM + type safe querries (querydsl, hibernate criteria api, jooq) позволили сэкономить сотни тысяч долларов на поддержке проектов, в которых мне посчастливилось участвовать. Как я это прикинул? В тех же проектах по различным причинам было много нативных sql запросов. И проблемы в том числе в продакшене, в том числе с даунтаймами возникали именно с ними. Это была постоянная головная боль у всех. Всё что было связано с ORM/type safe querries работало как часы, практически не требовало поддержки, разрабатывалось быстрее за счет нативных подсказок в IDE для соответствующего языка и за счет всего этого добавляло морали команде разработки.
varanio Автор
04.12.2023 11:34-1Признаюсь, элемент наброса есть. Дело в том, что скучную взвешенную душноту никто не читает. А так, на наезд набежало много народа, кучу ценных мыслей накинули. Я очень много почерпнул из обсуждений.
Т.е. мне правда голые запросы нравятся больше, но я готов подвинуться во мнении, если будут аргументы. И сегодня прям есть о чем подумать.

Glembus
04.12.2023 11:34Проблема не в ОРМ а в том кто ее использует. Если нет понимания про лази лоад и и что будет при дергании в цикле релейшенов, то тут причем ОРМ. По поводу разных БД. Есть проекты код база которых долдна работать на разных движках БД. ОРМ позволяет вкорячить что угодно. Напиши свой драйвер и генератор запросов и все, готово. По поводу репортов и выборки больших объемом, так, наример доктрина в документации прямиком говорит что не стоит строить запросы с возвращением сущностей. Непонятен смысл статьи. Перечисление очевидных плюсов минусов? Так они известны. Вообще для конкретной задачи всегда выбирается инструмент. Если вам надо данных много вытянуть и вы ограничены в памяти то накой вам абстракция которая выжрет ресурс. Но если вам надо описать логику в которой инкапсулировпть работу с набором данных, то зачем изобреиать велосипед?

saaivs
04.12.2023 11:34По честному, в большинстве случаев нужен не столько ORM, сколько CrUD.
Для сложных случаев всё-равно эффективнее чистого SQL(зачастую специфичного для конкретной СУБД) не придумать. А простые insert/update/delete вручную кодить лениво и не нужно. Вдобавок хочется типобезопасности (типа "безопасно" :) )
Для остальных случаев, где и модель данных относительно проста, и операции данных стандартны, и тот факт, что ORM тут выглядят и эффективно и выигрышно и создаёт ложное ощущение, что с ним можно и нужно пускаться во все тяжкие. Это, конечно, не так. Не во все. Но, класс приложений, где ORM прекрасно работают и экономят кучу времени на разработку, несомненно, чрезвычаной широк.
В общем, "по Сеньке шапка":)

Dominux
04.12.2023 11:34ORM, хоть и кажутся похожими на первый взгляд, на самом деле бывают совершенно разные. Взять например Django ORM - более чем подходит для больших проектов. А как она прекрасно встраивается в остальные компоненты джанги, тот же DRF с сереализатором.
ORM призваны решать вопросы четко и в сроки, не углубляясь в тонкости реализации конкретной СУБД. И я даже не говорю о переезде проекта или необходимости держать несколько видов СУБД одновременно. Я говорю, например о том, что мне нужно иметь в целом разные проекты на разных СУБД, для чего достаточно знать только ORM. Ну и проще писать на твоём языке, чем форматировать/конкетинировать разные части сырых запросов, ну и переиспользовать код проще, чем писать супер длинные sql с похожими условиями и подзапросами.
Никто и не говорит о каком-то бусте перформанса, код на гошке/расте тоже может быть хуже, чем если писать сразу на ассемблере, т.к. контроля больше, но почему-то так почти никогда не делают, и даже не знаю почему)))
Как-то недальновидно для автора статьи забывать о том, что разработка - это не про максимум перформанса, а про скорость и удобство масштабирования, читаемости, внесения изменений, дебагинга и т.д.

DrNiklas
04.12.2023 11:34EF в C# далеко не только маппер. Например, трекер, первую очередь. Производительность тяжёлых, с точки зрения времени исполнения на сервере, запросов EF и чистого SQL равны. Для сложных запросов, для которых EF требуется больше, чем нужно трипов на сервер или избыточное количество информации локально, используем stored procedures, которые тоже замечательно мапятся EF. "Обычные", средние со всех сторон запросы, EF делает более чем оптимально, нет причин заботиться о том, что там под капотом. Наоборот, я иногда подглядываю, как это сделала EF. Для очень лёгких запросов, когда скорость их исполнения важна, да, у сырого SQL преимущество, но в реальности такие ситуации встречаются крайне редко. Короче , имхо дискуссия ни о чем. И ORM и чистый SQL имеют право на жизнь. Это как спорить, что лучше , if или switch
ritorichesky_echpochmak
04.12.2023 11:34Преимущество сырого SQL очень иллюзорно и на живых базах выясняется что это не только не быстрее, но и зачастую костылизм оказывается существенно медленнее для большинства запросов, каких-то кривых маппингов к ним. А есть ещё создание и миграция БД, которые EF Core превращают просто в праздник какой-то по сравнению со всеми этими "дофига задизайненными" самоделками разных версий на каждом энвайрменте

yrub
04.12.2023 11:34вроде как всем известная истина, если у вас логическая модель взаимодействия по типу DDD то вам подойдет ORM, к CRUD это не имеет никакого отношения, такое чувство, что автор сел писать статью не понимая что значат эти 4 буквы
cross_join
04.12.2023 11:34... а DDD, в свою очередь, подойдет для систем симуляции, в отличие от информационных систем, где модель 100% анемичная по определению
https://blog.arbinada.com/ru/category/01705-clean-architecture.html
cross_join
04.12.2023 11:34Про CRUD-ошлёпство и Митрофанушек: ttps://blog.arbinada.com/ru/category/01704-crud.html

Pavel1114
04.12.2023 11:34+1Мне наверно чуть больше повезло и я пользуюсь отличной ORM django. Там всё выглядит не так страшно как у автора в примерах. И довольно сложные запросы можно написать красивым и понятным кодом. А, главное, предсказуемым. Конечно, если не понимать sql и то как работает конкретная ORM, то можно иногда сильно удивляться результатам(inner join так где нужен left join или лишние значения в group by). Но если понимать, то никаких проблем, а только удобства. Выше уже отметили, что ORM это не только query builder, а ещё и object mapper.
А пример про select по id может и выглядит страшным, но, если задача стоит именно такая, то для БД большой разницы, я уверен, нет идти по списку или по пром таблице. Но опять же, если знать возможности ORM, то это не проблема - всё предсказуемо. Например django такое генерирует при указании prefetch_related для m2m и реверс foreignkey и это именно то что я её прошу - предзагрузить связанные данные.
При этом django orm позволяет писать как часть запроса (extra) так и весь запрос (raw) на чистом sql, оставляя за собой мэппинг, если нужен.

fire_engel
04.12.2023 11:34+2При использовании ORM мы обычно прописываем в коде сущности и их взаимосвязи, и по сути это — проектирование БД ещё раз (дублирование логики!) прямо в коде.
Борьба с проблемами производительности никуда не денется всё равно, как ни абстрагируй. Ты просто не можешь не знать, что у тебя под капотом происходит. Какие там делаются джойны и группировки.
Язык запросов в виде цепочки объектов и методов читается хуже, чем SQL, по сути это — особый язык, который надо учить. За себя скажу, что когда писал на PHP (Laravel), длинные запросы на Eloquent меня иногда изумляли своей сложностью чтения:
reflections специально для этой проблемы придумали.
в чем проблема посмотреть, например, получившуюся query в sqlalchemy? да, будет не наглядно, но по ней можно понять, что происходит.
-
особенности библиотеки. в той же sqlalchemy код в разы понятнее чем голые sql запросы.
поставил бы диз, если мог бы.

september669
04.12.2023 11:34Для котлина есть такая штука как Sqldelight, подход с другой стороны, так сказать
PaulIsh
Да, для сложных запросов (подзапросы, функции) ORM не подходит, но такие случаи можно как-то особо обработать. Зато, если всё-таки ORM используется, то обычно перейти между разными СУБД довольно просто, как и поддерживать несколько СУБД в проекте.
varanio Автор
Из моей практики, обычно не требуется переходить между разными СУБД
PaulIsh
А на моей такое случается довольно часто. Особенно сейчас для разработки в РФ это актуально если были не на постгрес.
varanio Автор
Если переход на другую БД очень вероятен, то конечно надо использовать ORM
LaRN
У нас модульный монолит. Без orm, для работы с PG написали конвертер запросов, который на лету конвертирует запрос с mssql в pgsql.
PaulIsh
Безусловно, в разных реализациях верны разные решения. Я всецело за гибкость в разработке. И у меня был опыт когда мне нужно было писать свой построитель запросов (во времена Delphi и отсутствия ORM). И сейчас есть проекты с БД, в которых никакой фиксированной схемы данных нет и нет ORM.
Я лишь утверждаю, что позиция, что "раз у меня негативный опыт с ORM, то и вам он не нужен" не верна. Для каждой задачи свой инструмент.
ritorichesky_echpochmak
Ага, переходить не нужно. Нужно поддерживать несколько, как всякие Zabbix, Redmine, вагон всяких CRM, интеграций и т.д. и т.п.. Ну или, например, прод на полноценной СУБД, автотесты на SQLite in memory.
Borz
опыт (мой) показывает, что можно накушаться в проде проблем, если тестировали не на такой же СУБД, что в проде. Лучше уже в том же Docker запустить СУБД и погонять автотесты на ней
ritorichesky_echpochmak
Если использовать какую-то нестандартную белиберду даже для классического CRUD, то можно много чего накушаться в проде даже с одной БД. Автотесты не должны тестировать интеграцию во внешние системы как таковую, они должны тестировать поведение вашего юнита. После автотестов обязательно есть ещё интеграционные тесты и затем тестовый сервер для QA без проверки которого в прод не уходит ничего.
Borz
вы путаете "автотесты" и "юнит-тесты". Или вы интеграционные тесты всегда руками запускаете?
ritorichesky_echpochmak
Да, но не совсем, это не только юнит-тесты. Как правильно эти отдельные части называть немного подразмылось и в терминологии я могу плавать. С моей колокольни юнит-тесты должны покрывать ровно одну единицу работы и делать это максимально быстро. Выше них идут как бы интеграционные тесты, которые тестируют взаимодействие ваших компонент между собой, но не тестируют внешние компоненты. Внешние компоненты при этом мокаются, либо в случае с БД их проще заменить на SQLite чтобы была возможность проверить что данные легли правильно. Этот скоуп автотестов разработчик может и должен выполнять каждый раз перед тем как что-то закоммитать, ему это почти ничего не стоит.
А вот поднять вагон докеров - чего-то уже стоит. Это тоже можно выполнять автоматом, но лучше в пайплайнах CI по коммиту. Это уже не вот те лёгкие автотесты которые разраб у себя запускает, но и не end2end (которые тоже могут быть автотестами, но могут и не быть). В разных "пирамидах тестирования" эту часть проверки интеграции с внешними системами через раз то объединяют в интеграционные тесты, то выделяют в системные. Они уже тестируют окружение близкое к пользователю.
Я имел ввиду тот скоуп автотестов, который разраб может выполнить у себя прямо из IDE (юнит-тесты и часть интеграционных тестов которая не требует внешнего энвайрмента)
Borz
И вот тут-то как раз и возникает засада, так как данные в SQLite не всегда по типу совпадает с тем же PostgreSQL. Как и логика работы, например те же триггеры на уровне БД
ritorichesky_echpochmak
Триггеры БД тестируются на реальном энвайрменте, без проблем. Типы... а что у вас там такое волшебное, чтобы вот никак не пролезло? Вектора и классы, как у 2GIS? Если ничего уберспецифичного для вычисления прямо в БД, то и проблем быть не должно. Мы используем этот подход уже достаточно долго и без проблем
Buzzzzer
Переходили два раза. Сначала на mssql и при переходе потеряли некое подобие orm, а затем на psql.
Это было очень больно, да.
xm4dn355x
Из моей практики приходится переходить между разными СУБД. Например в апреле прошлого года полностью переехать надо было 16 микросервисов с Oracle на PostgreSQL. И когда у тебя все запросы написаны с использованием ORM, то переписывать надо только лишь те маленькие участки где используется голый SQL. В моём случае это были рекурсивные оракловые запросы, которые я на орм переписывал под постгрес. Если бы не ORM, то переезд бы явно сильно затянулся. Да и ORM и читать, и писать, и валидировать и проверять проще, чем полотно текста. Плюс автокомплит из коробки.
talbot
Из моей практики полный отказ от ORM (Hibernate)—единственная возможность перейти на другую БД, и использовать несколько БД (Oracle и Postgres) одновременно в процессе миграции.
Про наш опыт миграции можно почитать или посмотреть тут.
breninsul
а зачем переходить между СУБД?
фичи PostgreSQL как-то важнее теоретического перехода (куда и зачем?)
PaulIsh
Вы исторически сидели на Oracle, но он взял и ушел из РФ
Вы продаете продукт, который может работать в локальных установках и используете для простоты установки SQLite/Firebird, а может работать для крупняка, где не сложно и заморочиться с настройкой и установкой серьезной СУБД
nermiabh
Если орм не подходит для сложных , зачем тогда использовать его на простых ? Разве намного дольше будет писать простые запросы ? Единственный плюс что в орм с миграциями по проще , но думаю это не такой сильный плюс