
Казалось бы, в посгресе и так есть неплохой полнотекстовый поиск (tsvector/tsquery), и вы из коробки можете проиндексировать ваши тексты, а потом поискать по ним. Но на самом деле это не совсем то, что нужно — такой поиск работает лишь по чётким совпадениям слов. Т.е. postgres не догадается, что "кошка гонится за мышью" — это довольно близко к "котёнок охотится на грызуна". Как же победить такую проблему?
TLDR:
- Преобразовываем наши тексты в наборы чисел (векторы) при помощи API openAI.
- Сохраняем векторы в базе с помощью pgvector.
- Легко ищем близкие друг к другу векторы или ищем их по вектору-запросу.
- Ускоряем индексами.
Делаем вектор из текста
Итак, разберёмся с преобразованием текста в вектор (это называется embedding). Необязательно закапываться глубоко в теорию, на практике всё делается очень просто — можно тупо использовать API OpenAI. На текущий момент это стоит от 2 до 13 центов за миллион токенов. Почти даром.
На входе берём набор слов (одно слово или много сразу), а на выходе получаем вектор.
Что вообще это за вектор такой? Это просто набор чисел, по сути — координаты в 1500-мерном пространстве. Причём преобразование из текста в embedding происходит на заранее обученной модели так, чтобы близкие по смыслу тексты имели схожее направление векторов.
Получается, что мы работаем как бы с пространством смыслов и пытаемся вычислить, где в этом пространстве наш текст. После этого можно просто смотреть, какие тексты ближе к какому, чисто геометрически.
Немного практики:
Получить embeddings можно, просто послав запрос на API OpenAI (токен можно получить на их сайте, закинув 10 баксов)
curl https://api.openai.com/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"input": "Your text string goes here",
"model": "text-embedding-3-large"
}'Но вообще, конечно же, есть библиотеки-обёртки, например, github.com/sashabaranov/go-openai
strings := []string{"котик гонится за мышкой", "кошка ловит грызуна"}
client := openai.NewClient("your-token")
ctx := context.Background()
response, err := client.CreateEmbeddings(ctx, openai.EmbeddingRequestStrings{
Input: strings,
Model: "text-embedding-3-large",
Dimensions: 2000,
})По умолчанию модель text-embedding-3-large выдаёт вектор с размерностью 3072, а text-embeddng-3-small — 1536. Но в запросе можно указать, если хочешь поменьше (параметр dimensions)
Пихаем это в посгрес
Несколько месяцев назад Каруна послала меня на конференцию по базам данных, где рассказали про pgvector.
В общем, в посгресе есть расширение, которое предоставляет тип данных vectorи ряд операций: сложение, вычитание, умножение (поэлементное), косинусное расстояние, евклидово расстояние, скалярное произведение. А также функции sum(), avg(), и два типа индексов.
Способы установки расширения смотрите на их страничке, а для того, чтобы пощупать, можно просто использовать докер образ pgvector/pgvector:pg16 — это постргес 16 с pgvector.
Перед использованием расширение надо активировать
CREATE EXTENSION IF NOT EXISTS vectorСоздадим таблицу для хранения текстов и их embeddings
CREATE TABLE embeddings (
id SERIAL PRIMARY KEY,
text TEXT UNIQUE,
embedding vector(2000) NOT NULL
);и запишем туда эмбединги для описаний таких товаров:
"котик гонится за мышкой"
"котик гонится за мышками"
"собака лает, караван идёт"
"однажды в студёную зимнюю пору"
"кошка охотится на грызуна"
"котёнок ловит крысу"
"на марсе не растут грибы"
"умирает конь"Вот, накидал на коленке программу на Go, которая получает эмбеддинги для фраз и записывает в базу. Кстати, есть библиотека https://github.com/pgvector/pgvector-go, упрощающая взаимодействие с типом vector, но в таком простом примере можно обойтись и без неё:
package main
import (
"context"
"log"
"github.com/jackc/pgx/v4/pgxpool"
"github.com/sashabaranov/go-openai"
)
func main() {
strings := []string{
"котик гонится за мышкой",
"кошка охотится на грызуна",
"котёнок ловит крысу",
"котик гонится за мышками",
"собака лает, караван идёт",
"однажды в студёную зимнюю пору",
"на марсе не растут грибы",
"умирает конь",
}
ctx := context.Background()
embeddings := getEmbeddingsFromStrings(ctx, strings)
db := initDb(ctx)
if _, err := db.Exec(ctx, "CREATE EXTENSION IF NOT EXISTS vector"); err != nil {
log.Fatalf("couldn't create extension: %v", err)
}
if _, err := db.Exec(ctx, `
CREATE TABLE IF NOT EXISTS embeddings (
id SERIAL PRIMARY KEY,
text TEXT UNIQUE,
embedding vector(2000) NOT NULL
)`); err != nil {
log.Fatalf("couldn't create table: %v", err)
}
for str, embedding := range embeddings {
_, err := db.Exec(ctx,
`INSERT INTO embeddings
(text, embedding) VALUES
($1, $2::float4[]::vector)`, str, embedding)
if err != nil {
log.Fatalf("couldn't insert: %v", err)
}
}
}
func getEmbeddingsFromStrings(ctx context.Context, strings []string) map[string][]float32 {
client := openai.NewClient("your-token")
response, err := client.CreateEmbeddings(ctx, openai.EmbeddingRequestStrings{
Input: strings,
Model: "text-embedding-3-large",
Dimensions: 2000,
})
if err != nil {
log.Fatalf("error: %v", err)
}
result := make(map[string][]float32)
for _, data := range response.Data {
embedding := data.Embedding
result[strings[data.Index]] = embedding
}
return result
}
func initDb(ctx context.Context) *pgxpool.Pool {
db, err := pgxpool.Connect(ctx, "postgres://pgvector_test:pgvector_test@localhost:5432/pgvector_test?sslmode=disable")
if err != nil {
log.Fatalf("couldn't connect to database: %v", err)
}
return db
}
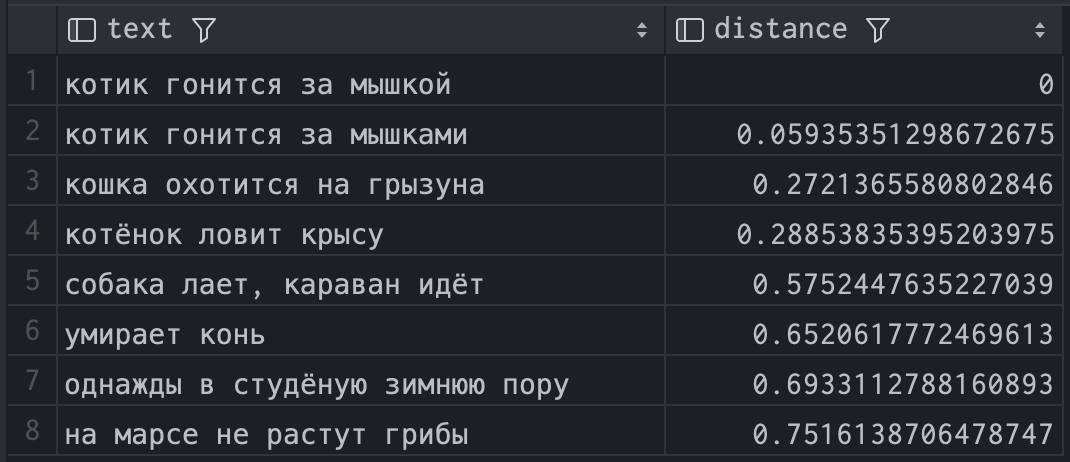
После чего возьмём вектор для фразы "котик гонится за мышкой" и поищем, какие вектора ближе всего в смысле косинусного расстояния <=>:
select
text,
embedding <=> (
select embedding
from embeddings
where text = 'котик гонится за мышкой'
) distance
from embeddings
order by distance;и получаем такой результат:
| text | distance |
|---|---|
| котик гонится за мышкой | 0 |
| котик гонится за мышками | 0.05935351298672675 |
| кошка охотится на грызуна | 0.2721365580802846 |
| котёнок ловит крысу | 0.28853835395203975 |
| собака лает, караван идёт | 0.5752447635227039 |
| умирает конь | 0.6520617772469613 |
| однажды в студёную зимнюю пору | 0.6933112788160893 |
| на марсе не растут грибы | 0.7516138706478747 |
Видно, что расстояние до самого себя равно нулю, а дальше postgres нашёл вполне близкие по смыслу фразы. Результат, кстати, сильно зависит от размерности векторов. При 1500 "умирает конь" поднимается довольно высоко в списке. Не знаю, возможно, конь тоже в каком-то смысле грызун, а умирает он не хуже, чем мышь в зубах кошки. Но при 2000 всё выглядит немного логичнее.
Так или иначе, в любом случае результаты намного интереснее, чем мог бы найти на этих данных встроенный полнотекстовый поиск посгреса.
В примере я ищу, насколько один существующий текст похож на другой, но можно сделать и поиск произвольной фразы: просто взять текст поисковой строки, преобразовать его в вектор и сунуть в запрос.
Ускоряем с помощью индексов
В экстеншене есть 2 индекса:
HNSW — медленно индексирует, использует больше памяти, но запросы работают быстрее. Создаёт многослойный граф.
-- пример индекса для ускорения расчёта косинусного расстояния
CREATE INDEX ON items USING hnsw (embedding vector_cosine_ops);IVFFlat работает по другому принципу, он делит векторы на списки, а затем ищет подмножество этих списков, наиболее близкое к вектору запроса.
CREATE INDEX ON items USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);Индекс IVFFlate можно строить только после того, как таблица наполнена данными.
Нюансы и заключение
Так как в посгресе лежат уже просто векторы определённой размерности, то, как мне кажется, никто не помешает в них добавить ещё пару измерений. Например, если мы ищем похожие товары в интернет-магазине, то, наверно, можно попробовать добавить в вектора такие числа как "длина", "ширина", "цвет", и т. д.
Понятно, что зависимость от API чужого сервиса — это плохо, поэтому можно попробовать сделать свою систему для получения embeddings. Я нагуглил пару способов, как это сделать на языке Go, но глубоко в эту сторону не копал.
При использовании индексов результат может чуть-чуть отличаться от запроса без индексов. Это компромис для скорости работы.
Подписывайтесь на мой канал Cross Join, если вам интересен подобный контент.
Комментарии (8)

cross_join
23.04.2024 13:54Подобное достаточно просто реализовалось на N-gram лет 20 назад (поиск дубликатов в CRM). Можно даже на реляционных таблицах. Строка, переведенная в N-gram-ы по сути тот же вектор.
https://blog.arbinada.com/ru/category/00020.html

osp2003
23.04.2024 13:54+1Зависимости от API как и от стоимости за OpenAI можно избежать, если использовать для генерации векторов одну из предобученных бесплатных моделей, например эту https://huggingface.co/cointegrated/rubert-tiny2. Основная проблема здесь в другом. Точность оценки сходства сильно снижается когда тексты существенно отличаются по количеству токенов. Так что от игрушечного примера до реального проекта этот кейс еще пилить и пилить. А так да, классная подмога FTSу

CitizenOfDreams
23.04.2024 13:54Это круто, конечно, что программисты научили поиск понимать, что "котик гонится за мышкой" и "кошка охотится на грызуна" это близкие понятия. Но что делать пользователю, который хочет найти именно "котик гонится за мышкой"? К сожалению, современные интеллектуальные поисковые системы этого не позволяют - не найдя "котика", они с чувством выполненного долга выдают пользователю "кошек" и "котят". А если и "кошек" не найдется - то есть "катет" и "Ниссан Кашкай", это же семантически близко, верно?

Aizz
23.04.2024 13:54Это уже не проблема программистов, а проблема бизнес анализа/архитектора/дизайнера. Как пользователь, я хочу контролировать возможность поиска точных значений или "приближенных", значит мне нужно дать возможность управлять этим. К примеру поиск в гугле пользуется двойными кавычками.
Очевидно, в этой ситуации можно пользоваться аналогичным способом и это не изменит логики и не усложнит разработку.

calculator212
23.04.2024 13:54Но что делать пользователю, который хочет найти именно "котик гонится за мышкой"?
Можно использовать специальные возмоности в поисковике, чтобы он нашел именно котика, почти все системы позволяют искать именно то, что хочет пользователь, но пользователю придется освоить нужные инструменты

Cheypnow
Просто добавить числа не получится, их тоже надо как-то кодировать. Например, нужно понимать должны ли мы учитывать близость чисел друг к другу. Когда мы говорим о длине или ширине, то логично считать 99 более близким и похожим на 100, чем число 1. Но если это будут, например, номера категорий товара, то близость их номеров скорее всего не будет говорить о схожести.
Ещё при добавлении других признаков надо не забывать приводить фичи к одной размерности. Если у одной фичи диапазон значений от -10000 до 10000, а у другой от 0 до 1, то первая будет сильнее влиять на рассчет расстояния, чем вторая.
Как альтернатива, использовать word2vec. Вроде для Go тоже завезли https://pkg.go.dev/code.sajari.com/word2vec
Было бы интересно сравнить результаты pgvector с решениями вроде FAISS и Qdrant. Дают ли они какое-то преимущество или наоброт проигрывают постгре.
varanio Автор
Специализированные фичи обычно лучше. Но если уже есть посгрес, добавить к одной из ее таблиц возможность семантического поиска - это проще в поддержке. Зависит от требований, короче