
В честь 30-летия OCR мы продолжаем вспоминать, как появились первые отечественные технологии распознавания текста. На прошлой неделе мы рассказали про самую первую такую программу – OCR Tiger, предназначавшуюся для оцифровки книг с целью их дальнейшего переиздания.
Сегодня речь пойдёт про другую OCR-систему – CuneiForm. Она была более продвинутой и умела гораздо больше: распознавала символы различных алфавитов на основе латиницы и кириллицы для европейских языков и языков стран СНГ, работала со смешанными русско-английскими текстами. Самое главное – CuneiForm отличалась впечатляющей по меркам того времени производительностью: 1 страницу она распознавала примерно за 10 секунд. Разберемся, какие алгоритмы использовались в OCR, где применялась CuneiForm и какое дальнейшее развитие получили системы распознавания.

Предыстория
Напомним (об этом мы подробнее рассказали здесь), что на стыке 80-х и 90-х годов – после того, как появились высокопроизводительные компьютеры и сканеры – отечественные ученые принялись решать задачу по созданию промышленных OCR-программ. Так, команда ученых РАН под руководством пионера в области искусственного интеллекта и всемирно известного ученого Владимира Львовича Арлазарова, который сегодня руководит в нашей компании Smart Engines наукой, создала по заказу издательства “Художественная литература” первую программу для оцифровки книг.
Программа получила название OCR Tiger, а ее продажей занялась организованная Владимиром Львовичем Арлазаровым в 1993 году компания "Когнитивные технологии". Вместе с ним управление компанией осуществляла Ольга Ускова, дочь коллеги и одного из разработчиков первого чемпиона мира среди шахматных программ "Каиссы" Анатолия Ускова. Владимир Львович Арлазаров координировал в компании разработку, а Ольга Ускова сосредоточилась на продажах и продвижении продукта.
CuneiForm: функционал
Несколько сотрудников ИСА РАН уехали в США и организовали там компанию Cognitive Technologies Inc, которая начала разработку англоязычной программы под Windows. Так, в 1992 году и появилась на свет англоязычная программа CuneiForm. Именно на ее базе в Москве сотрудники ИСА РАН и "Когнитивных технологий" вскоре разработали многоязычную версию CuneiForm.

Система OCR Cuneiform создавалась для омнифонтового распознавания, то есть в нем не использовались знания о шрифтах. Для этого были разработаны и применены новые алгоритмы, позволившие анализировать структуру сложных страниц с несколькими шрифтами и несколькими кеглями, в том числе в пределах одной строки. Система позволяла распознавать символы различных алфавитов на основе латиницы и кириллицы для европейских языков и языков государств-участников СНГ – суммарно она “понимала” 18 языков. Была реализована возможность распознавать и двуязычные тексты – например, русско-английские.
Обновленная версия CuneiForm 1992-1993 годов была встроена в известнейший на тот момент графический редактор CorelDRAW.
Интересно, что команда Владимира Львовича Арлазарова реализовала тогда еще один крайне любопытный проект – распознавание анкет налогоплательщиков для налоговой инспекции Башкирии. Сложность задачи заключалась в том, что адаптировать OCR предстояло под Macintosh. Так впервые российская OCR заработала на технике Apple.

Среднее время распознавания книжной страницы не превышало 10 секунд – это по тем меркам поразительный результат. Количество ошибок распознавания на книжной странице хорошего качества не превышало 1-2. И быстродействие, и точность обеспечивались алгоритмами распознавания.
Расскажем, какими именно.
Алгоритм бинаризации
В системе OCR Cuneiform для распознавания используется черно-белое изображение и, соответственно, первая задача состоит в бинаризации, то есть в выборе порога яркости, при котором черно-белое изображение было бы наиболее качественным.
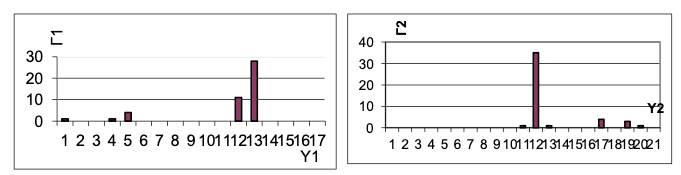
Статистический метод бинаризации основан на построении гистограммы яркостей области изображения. Типичная гистограмма приведена на рисунке ниже. По оси абсцисс отложены яркости 1 (О - абсолютно белое, 255 - абсолютно черное), а по оси ординат - количество точек N, в которых эта яркость зафиксирована на некотором участке, например, странице. Слева на графике – пик, соответствующий белым областям страницы, а справа пик, соответствующий черным областям. Ясно, что порог должен быть между ними, и можно найти выражения, позволяющие определить после соответствующего сглаживания подходящий порог. Например, это может быть минимальное значение, лежащее между максимумами.

Однако точность, которая достигается на основе исследования гистограммы яркостей, недостаточна, и обычно применяется какое-либо уточнение. Одно из них основано на исследовании внутри локальных областей изображения контуров компонент связности, получаемых при различных порогах бинаризации участка. Если рассмотреть количество компонент связности на некотором участке в зависимости от порога бинаризации, то увидим, что это число почти постоянно, а начиная с некоторого значения порога начинает резко возрастать, т.е. символы начинают «рассыпаться». Очевидно, что идеальный порог должен быть несколько ниже этой «критической точки».
Этот способ дает наилучшие результаты, если яркость страницы неравномерна, но требует существенно большего времени.
В OCR Cuneiform применялся алгоритм адаптивной бинаризации, разработанный М. А. Кронродом. Этот алгоритм основывался на определении дисперсии и среднеквадратичного отклонения яркости в окрестности каждой точки. При этом к точкам окрестности применялся фильтр Лапласа. Этот метод, в среднем сравним с методом Ниблака, но параметры алгоритма выбирались таким образом, чтобы оптимизировать не визуальное восприятие человеком бинаризованного изображения, а качество распознавания после бинаризации.
Методы распознавания символов
Для OCR Cuneiform сотрудником компании Cognitive Technology Ltd А. А. Талалаем был разработан алгоритм Эвент (событийный алгоритм), основанный на линейном представлении буквы. В бинарном растре образ символ представляется набором интервалов черных пикселей. Во время анализа растра интервалы извлекаются построчно (слева направо), сверху вниз. Два интервала в смежных строках, имеющие пересекающиеся горизонтальные проекции, называются сцепленными. Набор сцепленных интервалов образует линию. В процессе извлечения интервалов возможны следующие ситуации:
черный интервал не имеет соседей в предыдущей строке растра (соседними считаются точки, граничащие по одному из восьми направлений). Соответствует началу линии со свободным началом (интервалы 1, 2 на рисунке ниже);
черный интервал не граничит ни с одним интервалом из следующей строки. Линия закончилась, и этот конец – свободный (интервалы 3,4 на рисунке ниже);
черный интервал граничит с черным интервалом в предыдущей строке, и этот интервал первый из всех интервалов, граничащих с интервалом предыдущей строки. Интервал является продолжением линии (интервалы, продолжающие линии, заданные свободными началами 1,2 на рисунке ниже);
существует несколько интервалов, сцепленных с одним интервалом из предыдущей строки. Первый (самый левый) из них относится к продолжению линии, а остальные являются началами новых линий с несвободными началами (пересечение линий 5 на рисунке ниже);
у двух или более линий имеется общий соседний интервал в следующей строке. Первая (самая левая) линия продолжается, а остальные имеют несвободные концы (пересечение линий 5 на рисунке ниже).
, свободных концов (3,4) и линий с несвободными началами и концами")
Данная процедура выделения интервалов и линий позволяет получить линейное представление образа символа (пример разбиения растра символа на линии представлен на рисунке выше), состоящее из набора линий
где - число линий, описывающих растр,
- признак наличия свободного начала и свободного конца в
-ой линии,
- номер строки в растре первого интервала
-ой линии,
-
-ый интервал
-ой линии, состоящей из начальной и конечной координат.
Огрубим линейное представление следующим образом. Для каждой линии определим ее начало
и конец
как координаты середин первого и последнего из интервалов линии, после чего отмасштабируем координаты начала и конца на сетке
. Отмасштабированную линию со своими координатами и свойствами начал и концов назовем прямым событием.

Набор событий сохраняет информацию о структуре буквы (количество и свойства линий) и, в то же время, вариативность линий ограничивается грубостью сетки . Повернув растр на 90 градусов по часовой стрелке и проделав процедуры выделения линий и определения событий с повернутым растром, получим набор событий, называемых поворотными.
Событийный алгоритм распознавания символов, базирующийся на событийном представлении образа, использует два набора эталонов прямых и поворотных событий. Эталонные наборы представляют собой набор записей, олицетворяющих классы эквивалентности, порожденные событиями. Каждый из эталонов содержит коды символов, начертания которых обладают данным массивом событий.
Для обучения алгоритма были использованы тестовые выборки примерно из 1 000 000 символов для кириллицы и латиницы. Из одного миллиона образов кириллицы был получен набор прямых и поворотных событий объемом около 400 КБ.
При распознавании растр символа пересчитывается в прямое и поворотное событийное описания. Каждому из описаний сопоставляется эталонный класс букв. Результирующая коллекция распознавания образуется пересечением двух классов букв из прямой и поворотной баз эталонов. Пустое пересечение или отсутствие какого-либо из классов порождает отказ, что свидетельствует о незнании событийным алгоритмом образа с данной структурой.
Фрагментация страницы и формирование строк
Важным этапом анализа страницы перед распознаванием символов является декомпозиция страницы и выделение в ней текстовых фрагментов с целью отделения текста от картинок и сохранения структуры многоколоночного текста в результатах распознавания. Самый простой и очевидный путь декомпозиции страницы – использование в качестве разделяющих линий "белых коридоров" (горизонтальных и вертикальных просветов между черными компонентами). Если задать достаточно большую длину и ширину коридора, этот метод дает отличные результаты для разделения многоколоночных текстов, отделения прямоугольных рисунков и т.п. Однако подбор универсальных констант для порога длины и ширины коридора (или их соотношения) - практически невозможен. Один и тот же по размерам коридор может быть в одних случаях разделяющим фрагменты, в другом – нет (рисунок ниже).
На рисунке видно, что некоторые «белые коридоры» между строками сравнимы по высоте или ширине с разделяющими колонками. Поэтому приходится усложнять условия, используя такие понятия, как средний кегль (высота буквы) фрагмента, среднее расстояние между буквами в строке и т.п. Метод "белых коридоров" принципиально неприменим там, где иллюстрации (или другие "врезные" фрагменты) не являются прямоугольными. В этом случае часто успешно применяется другой метод – "заливки". Суть его в том, что компоненты, лежащие на расстоянии друг от друга меньшем порога, соединяются в один компонент, после чего для каждого компонента строится оболочка и как бы заливается черным.
Таким образом, вся страница (или ее часть) распадается на компоненты связности, причем каждая их пара либо не пересекается, либо содержится одна в другой. Отдельно может быть решен вопрос, является ли компонент текстом, но, во всяком случае, разные компоненты принадлежат разным сегментам текста. Зависящий от констант, которые не могут быть подобраны раз и навсегда, "метод заливки" не может быть единственным. В OCR Cuneiform оба метода применялись итеративно с использованием меняющихся пороговых констант. Найденные фрагменты классифицировались по типу: текст или иллюстрация.

Поиск текстовых строк проводился в границах каждого из найденных текстовых фрагментов. Алгоритм базировался на найденных и предварительно распознанных компонентах связности. Проводилась кластеризация методом ближайшего соседа, примененного к рамкам компонент связности. В некоторых случая, например, попадание одной компоненты связности в две строки, требовалась ректификация набора компонент и дополнительные итерация.
Определение базовых линий
В распознавании с помощью алгоритмов омнифонтовой классификации имеется ряд особенностей. Прежде всего, в один класс распознавания попадают образы, соответствующие неразличимым прописным и строчным буквам кириллицы и латиницы, таким как Cc, Oo, Pp, Вв, Гг, Дд, Жж, Зз и т.п. Однако от результата распознавания страницы ожидается надежно различение таких случаев. Решить проблему может применение базовых линий, понятие о которых известно из полиграфии. В стандартной строке определены четыре базовые линии, обозначенные на рисунке ниже:
b1 – прямая, на которой начинаются заглавные буквы;
b2 – прямая, на которой начинаются строчные буквы (в русском алфавите, кроме «б» и «ф»);
b3 – основная база, на которую опираются большинство букв, кроме опущенных («у», «р», «ф») и полуопущенных («Д», «Ц», «Щ»);
-
b4 – база, на которую опираются опущенные буквы.

Схема базовых линий
Расстояние между b2 и b3 определяет кегль (высоту маленькой неопущенной буквы). В полиграфии англоязычных документов иногда используется многокегельность, когда в рамках одной строки разные фрагменты написаны разными кеглями, и вообще не существует общих для всей строки базовых линий, за исключением b3.
Для определения базовых линий был разработан статистический метод.
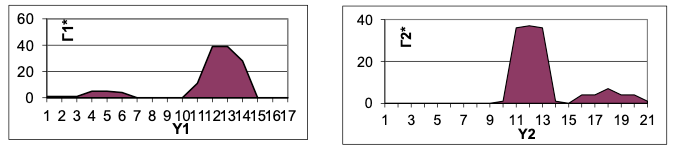
В нем строились гистограммы и
верхних и нижних границ символов строки. Гистограммы сглаживались сверточным фильтром и для сглаженных гистограмм
и
определялись максимумы (примеры рисунках ниже). Из общих соображений ясно, что максимумы
должны соответствовать b1 и b2, а максимумы
– b3 и b4.
В предположении, что существуют независимые для каждого символа вероятности:
– вероятность того, что символ опирается на b3;
– вероятность того, что символ опирается на b4;
-
- вероятность того, что символ не опирается на b3 и b4 ,
пренебрежем вероятностью того, что символы, не опирающиеся на b3 и b4, могут сгруппироваться и дать абсолютный максимум гистограммы.Рассмотрим два первых по величине максимума гистограммы
,
, где
- значения
в максимумах, а
- значения максимума. Вычислим вероятность
того, что
, т.е. вероятность того, что абсолютный максимум гистограммы
определяет
.
Пусть общее число символов строки, участвующих в построении гистограммы равно
И пусть число символов, опирающихся на
равно
, а число символов, опирающихся на
равно
. Очевидно, что если
, то абсолютный максимум определяет
.
А общая вероятность нахождения b3 в абсолютном значении равна .
Адаптивное распознавание
Одним из путей уточнения ненадежно распознанных символов является подключение альтернативного метода распознавания. В OCR CuneiForm такой путь был реализован. Для этого был создан метод адаптивного распознавания, в некотором смысле аналогичный шрифтовому методу в OCR Tiger. Технология была разработана сотрудником НИИСИ РАН Н. В. Котовичем и сотрудниками ИСА РАН О. А. Славиным, В. Троянкером.
Предложенный метод адаптивного распознавания включал в себя следующие этапы:
формирование обучающей выборки;
кластеризация распознанных символов;
анализ кластеров и поиск шрифтов;
построение эталонов (обобщенных портретов символов);
повторное распознавание ненадежно распознанных слов и символов (второй проход).
В результате распознавания текста (например, страницы) все надежно распознанные символы использовались как обучающая выборка для построения эталонов шрифта (или шрифтов). Правда, в отличие от Tiger, где формирование эталонов делалось «off line», здесь оно производилось «на лету» и без участия человека. Это привело к важным изменениям.
Формирование обучающей выборки производится здесь на основании оценок, порождаемых алгоритмами распознавания. С помощью механизма словарного подтверждения обучающая выборка пополняется символами с не самыми высшими оценками надежности. При использовании корпуса словоформ объемом более 1200000 словоформ русского языка число
ошибок подтверждения составило 19 ошибок в тестовом наборе объемом 25020 слов, причем отсутствовали ошибки подтверждения слов с длиной, большей 8.
Далее проводилась кластеризация бинарных образов надежно распознанных символов. Целью кластеризации являлось извлечение из обучающей выборки символов присутствующих шрифтов для последующего повторного распознавания.
Для обеспечения кластеризации было необходимо решить несколько проблем:
построение функции для оценки близости отсканированных символов для отнесения их к одному кластеру образов;
стабильное определение образа кластера;
определение идеальных образов кластера.
Как OCR была признана второй по значимости программой?
Пока ученые “Когнитивных технологий” корпели над созданием OCR Tiger и CuneiForm, параллельно собственную OCR развивали в компании BIT Software (потом была переименована в ABBYY).В 1992-1993 году BIT Software внедрила корректор орфографии, а затем презентовала еще одну свою знаменитую программу FineReader для распознавания электронного текста, работающую на 189 языках. Наряду с Cuneiform, FineReader, хотя и появилась на полгода позднее, является старейшей российской программой распознавания текста.
Надо сказать, что противостояние между “Когнитивными технологиями” и ABBYY, завязавшееся в начале 90-х, продлилось почти 10 лет и приобрело небывалый размах. По сути, две компании поделили между собой весь рынок. Газеты пестрили статьями о том, как крупнейшие российские компании тестировали FineReader и CuneiForm, запускали проекты с ABBYY и “Когнитивными технологиями”. Благодаря соревнованию этих компаний, постоянно наращивавших мощь, тема OCR оказалась одной из самых обсуждаемых разработок.
В 1994 технологию распознавания символов на легендарной компьютерной выставке того времени Comtek назвали второй по значимости разработкой. Она уступила лишь операционным системам, зато – хотя и занимала совсем небольшую долю рынка софта – обошла базы данных, производственные системы и другие программы.
OCR: настоящее
В 2000-х "Когнитивные технологии", выпустила freeware-версию программы CuneiForm и опубликовала исходный код своей OCR, ушла от распознавания документов к созданию роботизированных систем для различных машин и комбайнов. А коллектив, который занимался непосредственно документами, принял решение засучить рукава и двигаться дальше.
Внук Владимира Львовича Арлазарова Владимир Викторович Арлазаров основал собственную компанию Smart Engines. В ней Владимир Львович курирует научную работу. Сейчас компания специализируется на разработке алгоритмов для распознавания документов и развивает свою собственную OCR нового поколения. На ее базе уже созданы программные продукты для распознавания удостоверяющих документов свыше 220 стран и юрисдикций, деловых документов и форм (счет-фактуры, акты, счета, справки, УПД, …), банковских карт и баркодов.

Мощь современных отечественных систем распознавания впечатляет. Сегодня OCR-решения работают не только на компьютерах, но и на мобильных телефонах любых, в том числе самых бюджетных, моделей. Они могут распознавать не только сканы или фотографии, но и справляться с задачей распознавания текстов в видеопотоке.
В 2015 году именно коллектив Smart Engines первым показал распознавание российского паспорта в видеопотоке. Созданная учеными OCR была способна в реальном времени на обычном мобильном телефоне за 1-3 секунды извлекать данные документа. За это время система успевает распознать несколько подряд идущих кадров и выполнить межкадровую интеграцию распознанных полей документа. И все это на телефоне. Конечно, разработка Smart Engines позволила расширить сферы применимости OCR - теперь для точного результата не нужно было сканировать документ, пользователю достаточно сделать фотографию документа. Стало возможным распознавать даже фотографии с обычной веб-камеры.
Вместо заключения
30 лет совершенствования алгоритмов позволили увеличить точность и скорость распознавания. В конце 90-х скорость распознавания – 1 страница за 10 секунд – выглядела впечатляющей. Сегодня современная OCR, разработанная учеными Smart Engines с применением нейросетей, способна распознавать 15 страниц печатного текста за 1 секунду, причем делать это более чем на 100 языках.
“О том, что скоро бумажные документы исчезнут, говорят столько, сколько я работаю над OCR. Но бумаг с каждым годом становится только больше. Конечно, сейчас на первый план вышла не задача распознавания символов, а задача распознавания всевозможных документов, которые имеют сложную структуру, таблицы и рукописный текст. Много на этом пути мы уже сделали, но и новые научные вызовы впереди еще есть”, – отмечал Владимир Львович Арлазаров.
В мире где есть бумажные документы, роботизация и автоматизация процессов их обработки без качественной технологии OCR невозможна. Кроме этого вокруг нас появляются и новые задачи для OCR. Так, буквально в прошлом году возникла потребность распознавать рукописный номер телефона при оплате товаров и услуг. Это значит, что работа разработчиков OCR продолжается.
Настоящая публикация создана на основе научной статьи Slavin, O. A., Arlazarov,V. L.: Algorithms of the Tiger and CuneiForm Optical Character Recognition Software. Pattern Recognition and Image Analysis. Special Issue: Scientific schools of the Federal Research Center “Computer science and control” of the Russian Academy of Sciences, V.L. Arlazarov’s Scientific School. (2023)
Комментарии (6)

wofs
12.12.2023 13:12А что сегодня народ использует для распознавания документов оффлайн? Иди все с концами ушли в онлайн инструменты?

SmartEngines Автор
12.12.2023 13:12После публикации в открытом доступе CuneiForm и Tesseract OCR вопрос полнотекстового офлайн распознавания для бытовых нужд фактически стал закрытым. Эти движки встроены в десятки прикладных инструментов для ПК, позволяющих решить возникающие мелкие бытовые задачи, сведя на "нет" необходимость в коммерческом софте.
Другой вопрос - промышленное распознавание документов, где и постановка задачи отличается, и требования к ПО совершенно другие, и программные решения полноценно отечественные (читай - наши).


FilimoniC
Как произносится "CuneiForm" ?
dartraiden
Кьюниформ