
Это ответ на статью «Сколько строк на C нужно, чтобы выполнить a + b в Python?» где количество строк так и не указано. Сразу оговорюсь покрывать все сценарии для python по количеству строк я не собираюсь — слишком много вариантов, слишком лень. Но вот вопрос, сколько питону нужно строк, что бы сложить 2 числа? Будет ли разница, если сохранять эти числа в переменные или разницы нет?
Постановка задачи
Я решил что буду сравнивать разницу не в интерактивном режиме, а при чтении из файла. Потому что в это случае, можно избавиться от лишних процедур ввода вывода для интерактивного режима. Соответственно питон будет исполнять файл. И вот будем сравнивать разницу между выполнением пустого файла и файла где это самое сложение надо будет произвести. И так определимся с тем что нам для этого нужно:
узнать сколько строк питону нужно вообще, что бы исполнить пустой файл и выйти без ошибок
узнать сколько строк питону нужно, что бы исполнить файл где надо сложить два числа не сохраняя никуда результат
узнать сколько строк питону нужно вообще, что бы исполнить файл где идет сложение двух переменных содержащих числа
Содержимое файлов для сравнения.
Сравнивать будем пустой файл с двумя случаями
4+5и
a=4
b=5
a+bИсходный код пустого файла выставлять не буду =)
Что для этого нужно?
Собрать дебажный питон, в котором будет включен code coverage, после чего запустить генерацию отчета. Я очень хотел сделать это всё на Windows, но покрытие кода доступно только в версии Visual Studio Enterprise, а у меня Community Edition. Так что время устанавливать виртуалку с Linux (выбрал Ubuntu 22.04 LTS, потому что не люблю работать только из консоли). Дальше пошаговая инструкция как это сделать. Если интересны только результаты, можно смело переходить в конец статьи.
Как получить билд.
Идем на официальную страницу, как нам собрать билд сюда. Находим нужную нам операционную систему и идём по шагам. Ставим зависимости:
vim /etc/apt/sources.list
// вставляем в конец файла
deb-src http://archive.ubuntu.com/ubuntu/ jammy main
//сохраняемся.
sudo apt-get update
sudo apt-get build-dep python3
sudo apt-get install pkg-config
sudo apt-get install git
//вот это уже не обазательно, но уберем лишние варнинги при сборке,
//что питону чего то не хватает
sudo apt-get install build-essential gdb lcov pkg-config \
libbz2-dev libffi-dev libgdbm-dev libgdbm-compat-dev liblzma-dev \
libncurses5-dev libreadline6-dev libsqlite3-dev libssl-dev \
lzma lzma-dev tk-dev uuid-dev zlib1g-devОк, теперь можно качать питон.
git clone https://github.com/python/cpython
cd cpythonНам нужен дебажный питон, соответственно:
./configure --with-pydebug
make -j8
// где 8 количество ядер, которые нам нужны для компиляции, по умолчанию будет 2Итак сборка прошла успешно и в корне появился волшебный файлик "python". Запустим и проверим, что мы загружаемся и выходим без ошибок, а ещё что 4+5 всё еще 9.Теперь надо собрать сборку с code coverage. По логу сборки видим, что python собирается в gcc с ключом оптимизации "-Og", не смотря на нашу конфигурацию с --with-pydebug (она конечно никакая, но лучше совсем без неё, иначе репорт станет ещё менее точным. Открываем configure в текстовом редакторе и смотри, где выставляется флажок "-Og". В моем случае это:
PYDEBUG_CFLAGS="-O0"
if test "x$ac_cv_cc_supports_og" = xyes
then :
PYDEBUG_CFLAGS="-Og"
fiУбирем -Og, оставлем кавычки пустыми.
Ключ для gcc "--coverage" включает code coverage. Что бы эти ключи gcc увидел во время сборки, понадобится установить два environment variable(переменные окружения). Об это написано в справке скрипта configure:
./configure --help
// вот эти строчки
CFLAGS C compiler flags
LDFLAGS linker flags, e.g. -L<lib dir> if you have libraries in a
nonstandard directory <lib dir>На Linux это:
export СFLAGS="--coverage"
export LDFLAGS="--coverage"
env
// проверяем что они поставилисьЗапускаем configure и make, как уже один раз сделали. Запускаем питон, и проверяем, что всё работет и ничего не крешится. Если всё прошло правильно, то у нас должено быть в папке куча файлов с раширением gcno и gcda.
Проверяем.
find . | grep gcda
find . | grep gcnoФайлики gcno содержат статическую информацию. А вот gcda указывают, какие строки во время вызова были пройдены. Соотвественно, перед каждым отчетом и запуском питона в с тремя разными скриптами их было бы не плохо удалить.Делается это так.
find . |grep gcda |xargs rmТеперь gcda файлов нет и можно запускать наши файлы.
Генерируем отчет о покрытии
Итак, перед каждым отчетом, надо избавлятся от gcda файлов.Первый прогон идет просто с пустым файлом:
./python empty.py
mkdir report_empty
gcovr --html-details report_empty/index.html
// генерируем отчетУдаляем gcda файлы, и повторяем процедуру по кругу с другими папками для отчетов и файлами.
Типичный отчёт выглядит вот так:
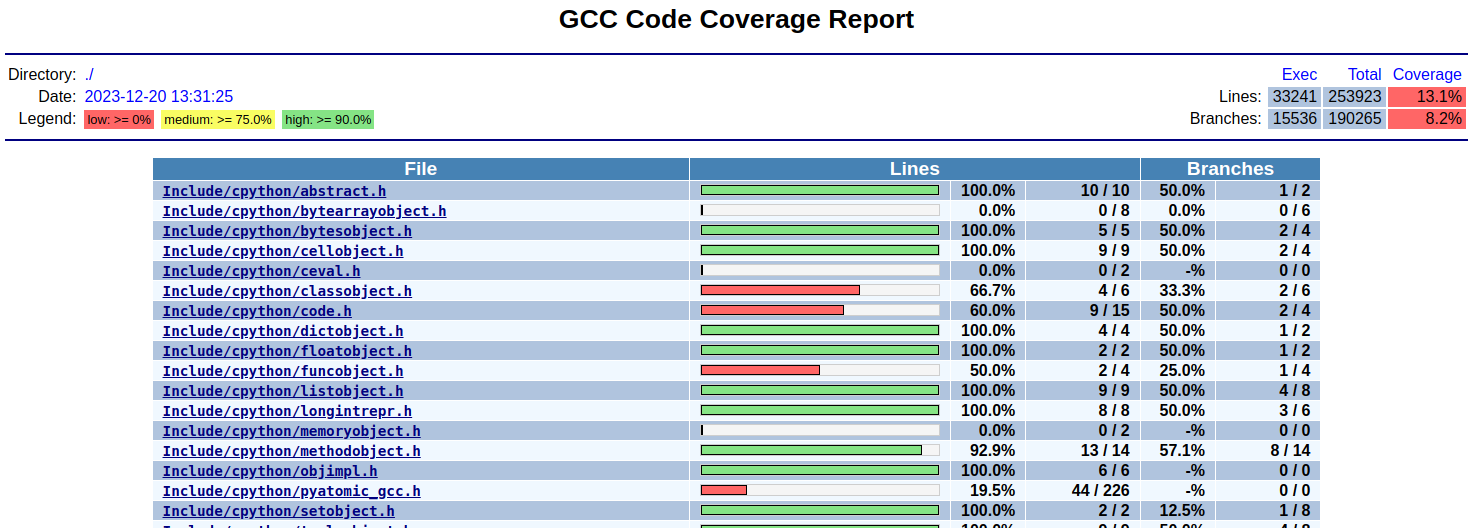
Итоги
Открываем index.html из каждой папочки с отчетами и видим сколько строк было запущено из каждого прогона. Мои результаты следующие.
Пустой файл:
Exec |
Total |
Coverage |
|
|---|---|---|---|
Lines: |
33241 |
253928 |
13.1% |
Branches: |
15536 |
190265 |
8.2% |
4+5
|
Total |
Coverage |
|
|---|---|---|---|
Lines: |
34261 |
253928 |
13.5% |
Branches: |
16136 |
190265 |
8.5% |
a=4
b=5
a+b
Exec |
Total |
Coverage |
|
|---|---|---|---|
Lines: |
34724 |
253928 |
13.7% |
Branches: |
16483 |
190265 |
8.7% |
Осталось только сделать операцию минус и получаем что:
4+5 стоит 1020 строк
сохранение в переменную стоит 1480 строк
Послесловие
Что говорят эти цифры, много это или мало? Я бы сказал это нормально, это питон. Если для вас это дорого, то есть молотилки чисел оптом, типа scipy или numpy. Там такие процедурки могут стоить один такт процессора или ещё меньше. Да и вообще, результаты эксперимента с реальной жизнью ничего общего не имеют. Потому что это всё собрано без оптимизации. С оптимизацией строк, конечно, меньше не станет, а вот ассемблер может очень прилично сбросить в весе.
Более того, я рассматривал только сложение обычных целых чисел. Сложение классов уже будет стоить по другому, причем для каждого класса по разному. Да и каждая строка в программирование имеют разную цену и сложность. Потому куда корректнее было бы сравнивать сколько ассемблерных инструкций бы ушло на это. Но беда в том, что в зависимости от платформы, ключей компиляции, типа и размера складываемых данных а так же положения луны и игривости настроения меркурия результат может варьировать и очень сильно. Я уже молчу о том, что числодробилки, вообще могут и используют совсем другой ассемблер.
Комментарии (13)

ihouser
21.12.2023 09:04Чтобы узнать сколько строк, понадобились две статьи. Есть вероятность, что будет еще.


Jury_78
21.12.2023 09:04Интересно, сколько строк понадобится в Си, что б сложить два любых объекта? :)

idimus Автор
21.12.2023 09:04Минимально?
int main(int, char**) { int a = 4; int b = 5; int c = a + b; return 0;}Jury_78
21.12.2023 09:04Это понятно, А хотя бы с чем то посложней? С проверкой типов, например.

MiyuHogosha
21.12.2023 09:04В Си нет необходимости складывать два любых объекта. Он статически типизирован. В случае же позднего связывания - завмсит от кода операции сложения и объектов. 30 килострок - это уже большая программа )
ShashkovS
Классная идея и реализация!
Было бы любопытно сравнить этот результат с каким-нибудь Javascript-движком.
idimus Автор
Процедура приблизительно та же, кроме того-что надо собирать node.js =)