
Привет! Меня зовут Артем. Я работаю Data Scientist'ом в компании МегаФон (платформа для безопасной монетизации данных OneFactor). Мы строим скоринговые (credit scoring), лидогенерационные (lead generation) и антифрод (anti-fraud) модели на телеком данных, а также делаем гео-аналитику (geoanalytics).
В предыдущей статье я поделился материалами для подготовки к одному из самых волнительных (для многих) этапов - Live Coding.
Давайте вспомним из каких секций состоит процесс собеседований на позицию Data Scientist:
Классическое машинное обучение
Специализированное машинное/глубокое обучение
Дизайн систем машинного обучения (middle+/senior)
Поведенческое интервью (middle+/senior)

В этой статье рассмотрим материалы, которые можно использовать для подготовки к секции по классическому машинному обучению.
Замечания
Я буду указывать ссылки на материалы не только на русском языке, но и на английском. Если у одного и того же ресурса есть версия на русском и на английском языке, то я буду указывать обе, чтобы читатель сам смог выбрать подходящий вариант.
Большое количество ресурсов будет на английском, поэтому знание английского это must have не только для работы по IT специальности, но и для подготовки к собеседованию. Зачастую оригинальная версия (на английском) проще читается, чем перевод, потому что содержит в себе много терминов и названий, которые устоялись и при плохом переводе только путают читателя.
Для книг я буду прикладывать ссылки на издательства (по возможности), чтобы вы сами смогли выбрать где их приобрести. Для технической литературы рекомендую использовать электронные версии книг, потому что в них всегда можно выделить важный отрывок, оставить комментарий и быстро найти нужную информацию.
По умолчанию, ресурсы на русском языке идут раньше ресурсов на английском (там, где они есть).
Большинство материалов в этой статье - бесплатные, но есть несколько платных (помечены paid). Рекомендую покупать их только, если четко понимаете, что не хотите или не можете тратить свое личное время на самостоятельный поиск информации.
Свои любимые материалы я выделил ⭐.
Содержание
Классическое машинное обучение
Секция по классическому машинному обучению встречается в каждом Data Science интервью (в том или ином виде), потому что позволяет проверить базовые знания ML, без которых не имеет смысла проводить секцию по специализированному ML/DL (RecSys, NLP, Time Series, CV, RL, ASR/TTS и т.д.).
В рамках данной секции ожидайте вопросов на следующие темы:
Классы задач
Обучение с учителем (supervised learning), обучение без учителя (unsupervised learning), обучение с частичным привлечением учителя (semi-supervised learning), обучение с подкреплением (reinforcement learning) и тд.Модели
Линейные, "деревянные", метрические, ансамбли, бустинги, нейронные сети.Данные
Разновидности данных, типы переменных, представление данных, качество данных и тд.Обучение и оценка качества моделей
Критерии качества: бизнес метрики, онлайн (online) метрики, офлайн (offline) метрики, функции потерь. Валидация: leave-p-out cross-validation, k-fold cross-validation, holdout method и т.д. Переобучение (overfitting) vs. недообучение (underfitting), bias-variance trade-off, подбор гиперпараметров, параметры vs. гиперпараметры, выбор лучших признаков, регуляризация, дисбаланс классов и тд.
Материалы
После того как мы разобрались с тем, какие темы нужно изучить/освежить, самое время перейти к материалам, которые нам в этом помогут.
Книги
⭐ Учебник по машинному обучению от ШАД
Онлайн-учебник по машинному обучению от ШАД — для тех, кто не боится математики и хочет разобраться в технологиях ML. Вы изучите классическую теорию и тонкости реализации алгоритмов, пройдя путь от основ машинного обучения до тем, которые поднимаются в свежих научных статьях. В учебник будут добавляться новые главы, поэтому следите за обновлениями, а ещё лучше подписывайтесь на новости.
Лучший ресурс на русском языке для того, чтобы быстро "освежить" знания по теории ML.
An Introduction to Statistical Learning by Gareth James, Daniela Witten, Trevor Hastie, Rob Tibshirani + The Elements of Statistical Learning by Trevor Hastie, Robert Tibshirani, Jerome Friedman
Аналоги учебника по ML от ШАД на английском языке с более глубоким погружением в избранные темы.
Первая книга (An Introduction to Statistical Learning) подойдет для начинающих, а вторую (The Elements of Statistical Learning) легче будет читать подготовленным читателям.
Machine Learning Simplified: A gentle introduction to supervised learning by Andrew Wolf
Основная цель Machine Learning Simplified — развить у вас интуицию в области машинного обучения. В ней используются интуитивные примеры для объяснения сложных концепций, алгоритмов и методов, а также верхнеуровнево объясняется вся необходимая математика.
⭐ The Kaggle Book
Внутри книги подробно описан анализ соревнований, примеры кода, end-to-end пайплайны, а также все идеи, предложения, лучшие практики, советы и рекомендации, которые Лука Массарон с Конрадом Банахевичом собрали за годы соревнований на Kaggle (более 22 лет).
Interpreting Machine Learning Models With SHAP: A Guide With Python Examples And Theory On Shapley Values
Эта книга станет вашим всеобъемлющим руководством по освоению теории и практики применения SHAP. Она начинается с весьма интересных истоков теории игр и исследует, как разделение затрат на такси (между пассажирами) связано с объяснением предсказаний моделей машинного обучения. Начиная с использования SHAP для объяснения простой модели линейной регрессии, книга постепенно знакомит с SHAP для более сложных моделей. Вы узнаете все тонкости самого популярного метода интерпретации моделей и способы его применения с помощью пакета shap.
Interpretable Machine Learning. A Guide for Making Black Box Models Explainable by Christoph Molnar
Эта книга о том, как сделать модели машинного обучения интерпретируемыми.
Изучив концепции интерпретируемости, вы узнаете о простых интерпретируемых моделях, таких как деревья решений и линейная регрессия. Основное внимание в книге уделяется независимым от модели методам интерпретации "black box" моделей, как важность признаков (feature importance) и накопленные локальные эффекты (accumulated local effects), а также объяснению отдельных прогнозов с помощью значений Шепли (Shapley values) и LIME. Кроме того, в книге представлены методы, специфичные для глубоких нейронных сетей.
Все методы интерпретации подробно объясняются и критически обсуждаются. Как они работают под капотом? Каковы их сильные и слабые стороны? Как можно интерпретировать их результаты? Эта книга позволит вам выбрать и правильно применить метод интерпретации, наиболее подходящий для вашего проекта машинного обучения. Книгу рекомендуется прочитать специалистам по машинному обучению, специалистам по данным, статистикам и всем, кто заинтересован в том, чтобы сделать модели машинного обучения интерпретируемыми.
Feature Engineering and Selection: A Practical Approach for Predictive Models by Max Kuhn and Kjell Johnson
Процесс разработки предиктивных моделей включает в себя множество этапов. Большинство материалов (книг, блог-постов и т.д.) сосредоточены на алгоритмах, при этом другие важные аспекты процесса моделирования игнорируются.
В этой книге описываются методы поиска лучшего подмножества признаков для улучшения качества модели. Для иллюстрации методов используются различные наборы данных, а также программы (на R) для воспроизведения результатов.
Clean Machine Learning Code by Moussa Taifi paid
Книга содержит "рецепты" по написанию "чистого" кода для обучения и инференса ML моделей:
Основы "чистого" кода машинного обучения
Оптимизация имен
Оптимизация функций
Стиль
"Чистые" классы машинного обучения
Архитектура программного обеспечения в машинном обучении
Машинное обучение через тестирование
Курсы
⭐ Open Machine Learning Course by Yury Kashnitsky
Курс был создан Юрием Кашницким и сообществом ods.ai в 2017 году.
Это сбалансированный по теории и практике курс, дающий как знания, так и навыки (необходимые, но не достаточные) машинного обучения уровня Junior Data Scientist. Вы нечасто встретите и подробное описание математики, стоящей за используемыми алгоритмами, и соревнования Kaggle Inclass, и примеры бизнес-применения машинного обучения в одном курсе. С 2017 по 2019 годы Юрий Кашницкий и большая команда ODS проводили живые запуски курса дважды в год – с домашними заданиями, соревнованиями и общим рейтингом участников (имена героев запечатлены тут и здесь даже есть я, автор этой статьи). Сейчас курс в режиме самостоятельного прохождения на английском языке.
Инструкция по тому, как "пройти" этот курс на русском языке есть здесь.
Новый запуск курса на русском языке планировался, но "заглох".
Машинное обучение (курс лекций, К.В.Воронцов)
В курсе рассматриваются основные задачи обучения по прецедентам: классификация, кластеризация, регрессия, понижение размерности. Изучаются методы их решения, как классические, так и новые, созданные за последние 10–15 лет. Упор делается на глубокое понимание математических основ, взаимосвязей, достоинств и ограничений рассматриваемых методов. Теоремы в основном приводятся без доказательств.
⭐ Прикладные задачи анализа данных (курс лекций, А.Г.Дьяконов)
Целями курса являются:
-
Решение реальных задач, например, взятых с соревновательных платформ (Kaggle), либо задачи от бизнеса ("small data" ~ до 200 гб):
Максимально удобно для новичков
Простые форматы данных
Можно решать на ПК
-
Изучение теории (в том числе и продвинутое машинное обучение):
Оценки среднего, вероятности и плотности; весовые схемы
CASE: Прогнозирование визитов покупателей супермаркетов и сумм их покупок
CASE: Задача о пробках
-
Искусство визуализации:
Часть 1 - Историческая
Часть 2 - Одномерный анализ
Часть 3 - Многомерный анализ
Метрики качества
-
Часть 1. Функции ошибки в задаче регрессии
Часть 2. Чёткая бинарная классификации
Часть 3: Скоринговые функции и кривые в машинном обучении
Часть 4: Многоклассовые задачи, ранжирование, кластеризация
Часть 5: Задачи и кейсы
Подготовка данных
Генерация признаков
Ансамбли
Анализ социальных / сложных сетей
Прогнозирование появления ребра в динамическом графе (Link Prediction Problem)
Выделение сообществ (Community Detection)
Случайный лес
Важность признаков в ансамблях деревьев
Градиентный бустинг
Алгоритмы Машинного обучения с нуля
В данном курсе вы реализуете с нуля все основные алгоритмы классического машинного обучения на чистом Python, Pandas и NumPy.
В отличие от других курсов по машинному обучению, в данном курсе основной упор в подаче материала будет сделан именно на алгоритм с т.з. программирования, а не с т.з. математики. Хотя основные математические концепции и будут даны.
Для успешного прохождения курса вам понадобится понимание основ машинного обучения: для чего делить выборку на train и test, что такое target и feature, и прочие базовые концепции, а также профессиональный жаргон. Помимо этого, вам необходимо относительно неплохо разбираться в языке Python, его алгоритмах и структурах данных.
Stanford CS229: Machine Learning by Andrew Ng
Культовый курс по основам машинного обучения.
Темы, изучаемые на курсе:
Обучение с учителем (генеративное/дискриминационные модели, параметрические/непараметрические модели, нейронные сети, метод опорных векторов);
Обучение без учителя (кластеризация, уменьшение размерности, ядерные методы);
Теория обучения (bias/variance trade-off, практические советы);
Обучение с подкреплением и адаптивное управление.
⭐ Kaggle Learn
Kaggle бесплатно предоставляет доступ к своим коротким, но интересным курсам. Вот лишь некоторые из них:
Google Machine Learning Courses
-
Базовые курсы (основные концепции машинного обучения):
Введение в машинное обучение
Ускоренный курс машинного обучения
Формулировка проблемы
Подготовка данных и признакового пространства
Тестирование и отладка
-
Продвинутые курсы (инструменты и методы решения различных задач):
Леса решений (Decision Forests)
Рекомендательные системы
Кластеризация
Генеративно-состязательные сети
Классификация изображений
Справедливость в Perspective API
-
Гайды (пошаговые инструкции по решению проблем с использованием лучших практик):
Правила ML
Гайд «Люди + ИИ»
Классификация текста
Хороший анализ данных
Пособие по настройке глубокого обучения
Сайты
Машинное обучение для людей. Разбираемся простыми словами
Большое введение для тех, кто хочет наконец разобраться в машинном обучении — простым языком, без формул-теорем, зато с примерами реальных задач и их решений.
Подойдет для тех, кто только начал разбираться с машинным обучением.
⭐ Анализ малых данных
Интересный блог Александра Дьяконова (автора курса "Прикладные задачи анализа данных"), в котором новые посты выходят не так часто (автор теперь пишет в свой телеграм канал), зато в архиве есть полезные статьи, например:
Kaggle Competitions
На Kaggle есть несколько видов соревнований:
-
Getting Started
Самые простые соревнования на Kaggle, предназначенные для тех, кто только начинает заниматься машинным обучением.Так как за победу в этих соревнованиях не платят деньги, другие пользователи охотно делятся своими решениями в разделе code (например) — это именно то, что нужно для начинающих, чтобы "вкатиться". -
Playground Competitions
Эти соревнования по сложности на один шаг выше уровня "Getting Started".Они ориентированы на новичков или "кагглеров", заинтересованных в решении новых задач. Здесь за победу уже могут давать небольшие денежные призы. -
Research
В исследовательских соревнованиях представлены более экспериментальные задачи. Победа в таких соревнованиях обычно не награждается призами или баллами, но они дают возможность поработать над проблемами, которые не имеют четкого или легкого решения и которые являются неотъемлемой частью конкретной предметной области. -
Featured
Это серьезные задачи, как правило, коммерческого характера. Такие соревнования привлекают самых выдающихся экспертов и предлагают призовые фонды, достигающие миллиона долларов. Тем не менее, они остаются доступными для всех и каждого. Независимо от того, являетесь ли вы экспертом в этой области или полным новичком, тематические соревнования - это ценная возможность научиться навыкам и техникам у самых лучших специалистов в этой области.
Machine Learning Mastery
Сайт Jason'а Brownlee содержит:
-
Гайды (поэтапные руководства разделенные на несколько уровней):
Основы (Foundations)Как начать изучать машинное обучение, вероятность, статистические методы, линейная алгебра, оптимизация, математический анализ.
Новичок (Beginner)Python, понимание ML алгоритмов, введение в sklearn, предсказание временных рядов, подготовка данных.
Средний (Intermediate)Бустинги, дисбаланс классов, глубокое обучение, ансамбли.
Продвинутый (Advanced)LSTM, NLP, CV, GANs, механизм внимания (attention) и трансформеры
Туториалы (блог-посты на сайте на различные темы)
Электронные книги
paid(расширенные материалы с сайта, объединенные в книги по темам)
Признаюсь, я не изучал эти материалы в полном объеме, но по моему опыту, если в результатах поиска есть выбор между этим сайтом и medium, analytics vidhya и т.д., лучше идти сюда.
The Illustrated Machine Learning
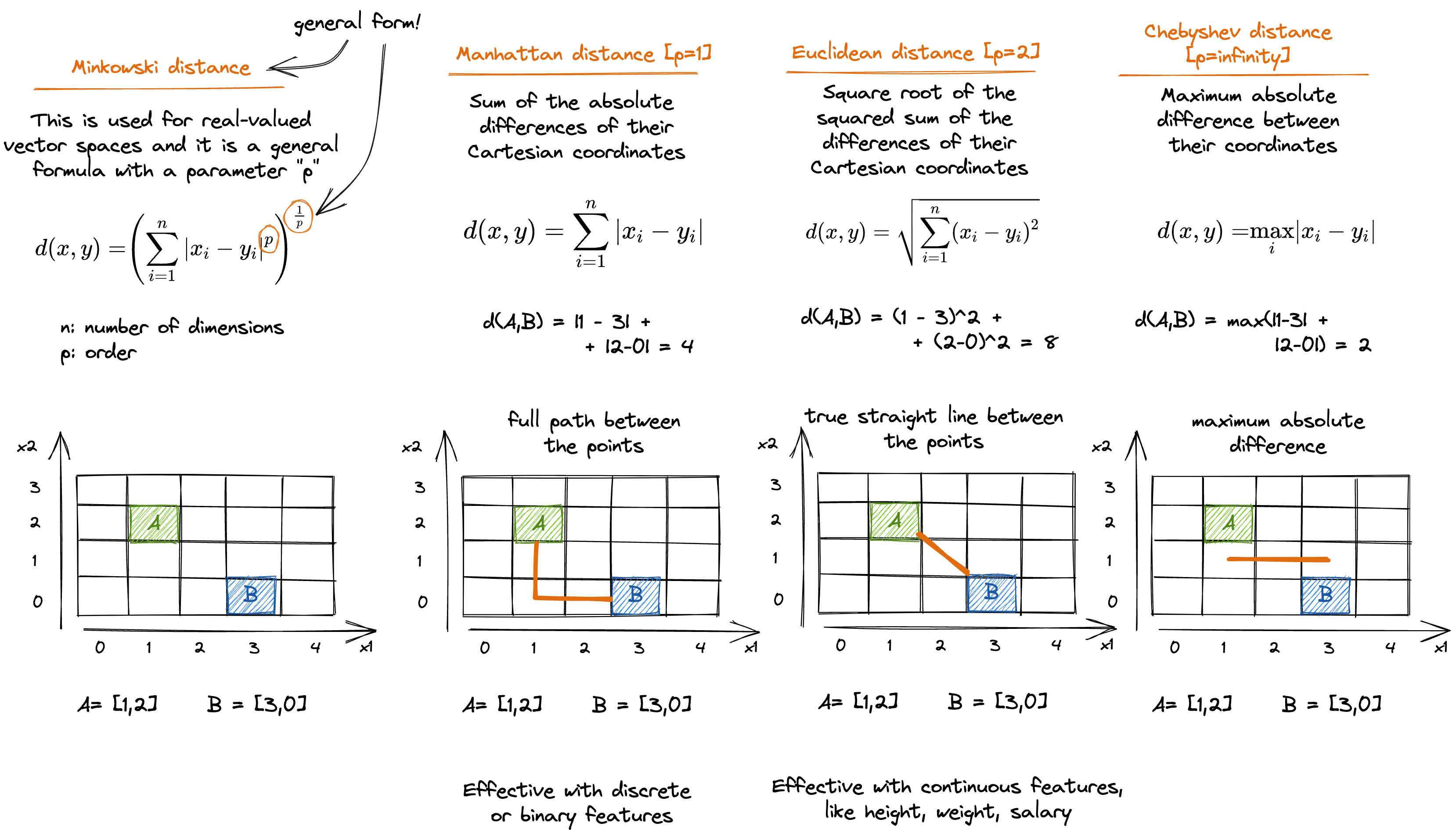
Идея сайта состоит в том, чтобы сделать сложный мир машинного обучения более доступным с помощью четких и кратких иллюстраций. Цель — предоставить студентам, специалистам и всем, кто готовится к техническому собеседованию, наглядное пособие, позволяющее лучше понять основные концепции машинного обучения. Независимо от того, новичок ли вы в этой области или опытный профессионал, желающий освежить свои знания, эти иллюстрации станут ценным ресурсом на вашем пути к пониманию машинного обучения.
MLU-EXPLAIN
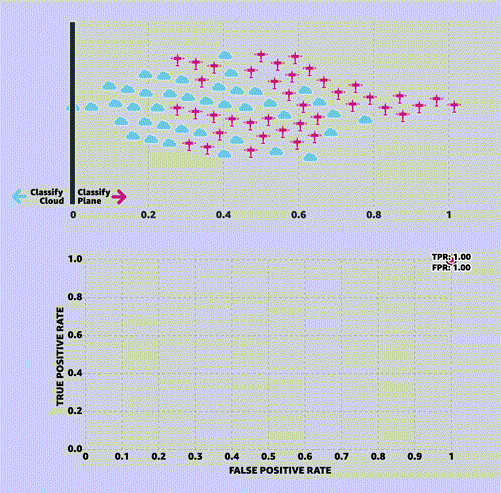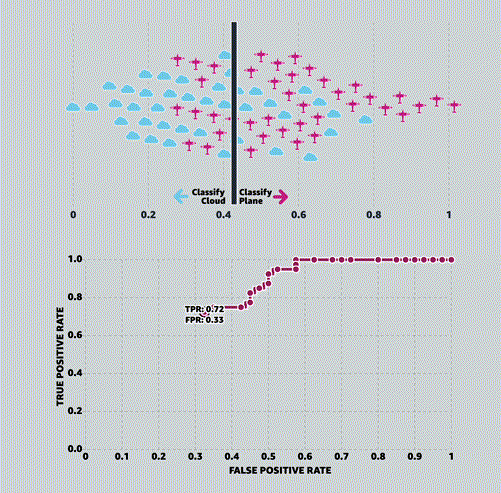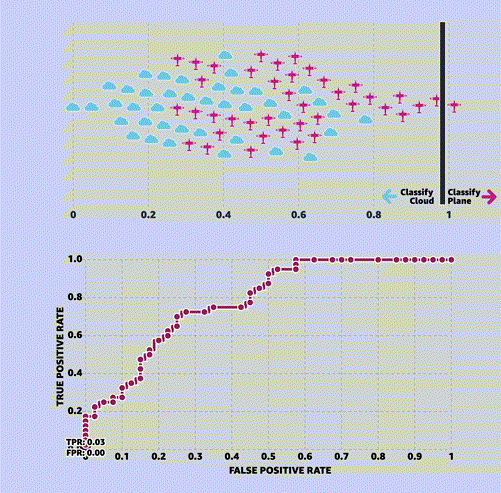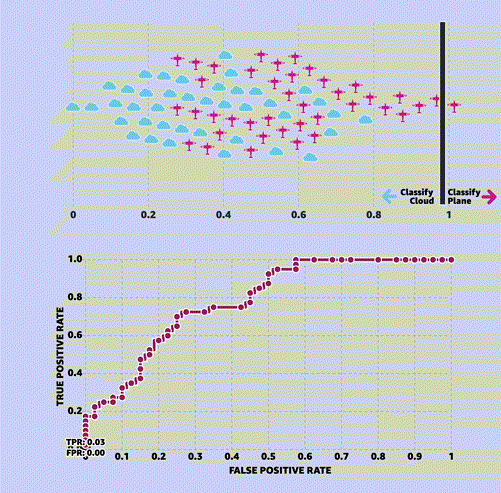
Визуальные объяснения основных концепций машинного обучения.
Университет машинного обучения (Machine Learning University, MLU) — это образовательная инициатива Amazon, предназначенная для изучения теории и практики машинного обучения.
MLU-Explain существует [в рамках этой инициативы] для изучения важных концепций машинного обучения с помощью визуальных эссе в веселой, информативной и доступной форме.
Шпаргалки
Функции потерь, градиентный спуск, правдоподобие
Линейные модели, метод опорных векторов (Support Vector Machine, SVM), генеративный подход к обучению
Деревья и ансамбли, метод k-ближайших соседей (K-Nearest Neighbors, KNN), теория обучения (learning theory)
EM-алгоритм (Expectation Maximization), k-средних (k-means), иерархическая кластеризация
Метрики для оценки качества кластеризации
Метод главных компонент (Principal Component Analysis, PCA), анализ независимых компонент (Independent Component Analysis, ICA)
Матрица ошибок (confusion matrix), accuracy, precision, recall, F1-score, ROC
R2, Mallows's Cp, информационный критерий Акаике (Akaike information criterion, AIC), Байесовский информационный критерий (Bayesian information criterion, BIC)
Перекрестная проверка (cross-validation), регуляризация, bias/variance trade-off, анализ ошибок
Разное
StatQuest with Josh Starmer
Канал, на котором Joshua Starmer объясняет различные алгоритмы и понятия в ML простым языком, подкрепляя свои слова визуализацией и примерами. Данные видео подойдут для первого знакомства с материалом и для повторения.
Для поиска необходимого видео можно использовать функцию поиска по каналу.
Model Evaluation, Model Selection, and Algorithm Selection in Machine Learning by Sebastian Raschka
Правильное использование методов оценки качества модели и выбора алгоритма имеет жизненно важное значение в академических исследованиях в области машинного обучения, а также во многих реальны бизнес задачах. В этой статье рассматриваются различные методы, которые можно использовать для каждой из этих подзадач, и обсуждаются основные преимущества и недостатки каждого метода со ссылками на теоретические и эмпирические исследования. Кроме того, даются рекомендации по поощрению лучших, но осуществимых практик в исследованиях и применении машинного обучения.
⭐ How to avoid machine learning pitfalls: a guide for academic researchers by Michael A. Lones
В этой статье описаны распространенные ошибки, возникающие при использовании машинного обучения и что можно сделать, чтобы их избежать. Она охватывает пять этапов процесса разработки модели машинного обучения: что делать перед построением модели, как надежно (reliably) строить модели, как надежно (robustly) оценивать модели, как справедливо (fairly) сравнивать модели и как сообщать о результатах.
A new perspective on Shapley values: Part I: Intro to Shapley and SHAP + Part II: The Naïve Shapley method
Эти два блог-поста (1, 2) помогут вам в изучении SHAP/Shapley values для интерпретации моделей.
Подведем итоги
Если вы еще не читали, то рекомендую прочитать блоки Learning How to Learn и Подведем итоги из первой статьи, так как все сказанное там применимо и для подготовки к секции по машинному обучению.
Собранные в этой статье материалы будут полезны при подготовке к собеседованиям на различные позиции в Big Data МегаФон.
А если вы только начинаете свою карьеру в Data Science, то обратите внимание на стажировки в крупных компаниях, на которых вы сможете не только прокачать свои знания, но также получить крутой опыт применения теории на практических задачах бизнеса. В МегаФоне пример такой стажировки - это акселератор (пишите на почту с темой письма "стажировка в big data"), с помощью которого ежегодно находят свою первую работу специалисты по работе с данными (Data Scientists), аналитики (Data Analysis) и дата инженеры (Data Engineers).
Что дальше?
В следующей статье разберем материалы для подготовки к секции по специализированному машинному/глубокому обучению.
Актуальные ресурсы для этой серии статей вы сможете найти в репозитории Data Science Resources, который будет поддерживаться и обновляться. Также вы можете подписаться на мой телеграм-канал Data Science Weekly, в котором я каждую неделю делюсь интересными и полезными материалами.
Если вы знаете какие-нибудь классные ресурсы, которые я не включил в этот список, то прошу написать о них в комментариях.
P.S. Благодарю Дарью Шатько за редактуру и вычитку этого поста!