
Привет! Меня зовут Артем. Я работаю Data Scientist'ом в компании МегаФон (платформа для безопасной монетизации данных OneFactor). Мы строим скоринговые (credit scoring), лидогенерационные (lead generation) и антифрод (anti-fraud) модели на телеком данных, а также делаем гео-аналитику (geo-analytics).
В предыдущей статье я поделился материалами для подготовки к этапу по классическому машинному обучению.
Давайте вспомним из каких секций состоит процесс собеседований на позицию Data Scientist:
Специализированное машинное/глубокое обучение
Дизайн систем машинного обучения (middle+/senior)
Поведенческое интервью (middle+/senior)

В этой статье рассмотрим материалы, которые можно использовать для подготовки к секции по специализированному машинному обучению.
Замечания
Я буду указывать ссылки на материалы не только на русском языке, но и на английском. Если у одного и того же ресурса есть версия на русском и на английском языке, то я буду указывать обе, чтобы читатель сам смог выбрать подходящий вариант.
Большое количество ресурсов будет на английском, поэтому знание английского это must have не только для работы по IT специальности, но и для подготовки к собеседованию. Зачастую оригинальная версия (на английском) проще читается, чем перевод, потому что содержит в себе много терминов и названий, которые устоялись и при плохом переводе только путают читателя.
Для книг я буду прикладывать ссылки на издательства (по возможности), чтобы вы сами смогли выбрать где их приобрести. Для технической литературы рекомендую использовать электронные версии книг, потому что в них всегда можно выделить важный отрывок, оставить комментарий и быстро найти нужную информацию.
По умолчанию, ресурсы на русском языке идут раньше ресурсов на английском (там, где они есть).
Большинство материалов в этой статье - бесплатные, но есть несколько платных (помечены paid). Рекомендую покупать их только, если четко понимаете, что не хотите или не можете тратить свое личное время на самостоятельный поиск информации.
Свои любимые материалы я выделил ⭐.
Содержание
Материалы
Кроме основ машинного обучения (полезные материалы мы рассмотрели в предыдущей статье), во многих задачах требуются также специфические знания, которые у вас наверняка проверят в рамках одного из этапов собеседования.
Давайте перечислим самые популярные направления ML в данный момент:
Обработка естественного языка (Natural Language Processing / NLP)
Компьютерное зрение (Computer Vision / CV)
Распознавание речи (Automated Speech Recognition (ASR) / speech-to-text (STT))
Синтез речи (Speech Synthesis / text-to-speech (TTS))
Обучение с подкреплением (Reinforcement Learning / RL)
Временные ряды (Time Series / TS)
Рекомендательные системы (Recommender System / RecSys)
Во всех этих направлениях в данный момент активно используются методы глубокого обучения (Deep Learning / DL), хотя изначально, во многих из них использовались классические ML подходы над вручную созданными признаками (hand-crafted features). Поэтому сначала мы рассмотрим материалы для изучения теории глубокого обучения, а затем погрузимся в более прикладные области.
Глубокое обучение
Нейросетевые подходы сейчас доминируют в решении задач, где требуется анализ неструктурированных данных (текст, речь, видео, изображение). Ниже рассмотрим материалы, которые помогут в изучении теории и практики глубокого обучения.
Книги
⭐ Шолле Ф. Глубокое обучение на Python / Deep Learning with Python by François Chollet

Отличная книга, которая послужит идеальным введением в глубокое обучение. Кстати, первое издание этой книги есть у меня в печатном формате и пригодилось мне не раз, когда я только начинал заниматься DL.

Интерактивная книга по глубокому обучению с кодом (на PyTorch, NumPy/MXNet, JAX и TensorFlow) и математикой. Каждая секция в книге является отдельным Jupyter notebook'ом, код в котором можно запускать и менять по своему усмотрению. Используется в 500 университетах в 70 странах мира.
Understanding Deep Learning by Simon J.D. Prince

Эта книга посвящена идеям, лежащим в основе глубокого обучения. В первой части книги представлены модели глубокого обучения и обсуждается, как их обучать, измерять их производительность и улучшать ее. В следующей части рассматриваются архитектуры для работы с изображениями, текстом и графами. Эти главы требуют только вводных знаний по линейной алгебре, математическому анализу и теории вероятностей и должны быть доступны любому студенту второго курса технического университета. Последующие части книги посвящены генеративным моделям и обучению с подкреплением. Эти главы требуют дополнительных знаний в области вероятностей и математического анализа, и предназначены для более продвинутых студентов.
The Little Book of Deep Learning by François Fleuret
Здесь кратко (но содержательно) рассматриваются многие важные темы: метод обратного распространения ошибки, дропаут, нормализация, функции активации, слои внимания и тд. При этом, книга подойдет даже новичкам: в начале автор раскрывает базовые понятия, и даже рассказывает про GPU и тензоры. Стоит также отметить, что данная версия адаптирована под чтение на телефоне.
⭐ What are embeddings by Vicki Boykis
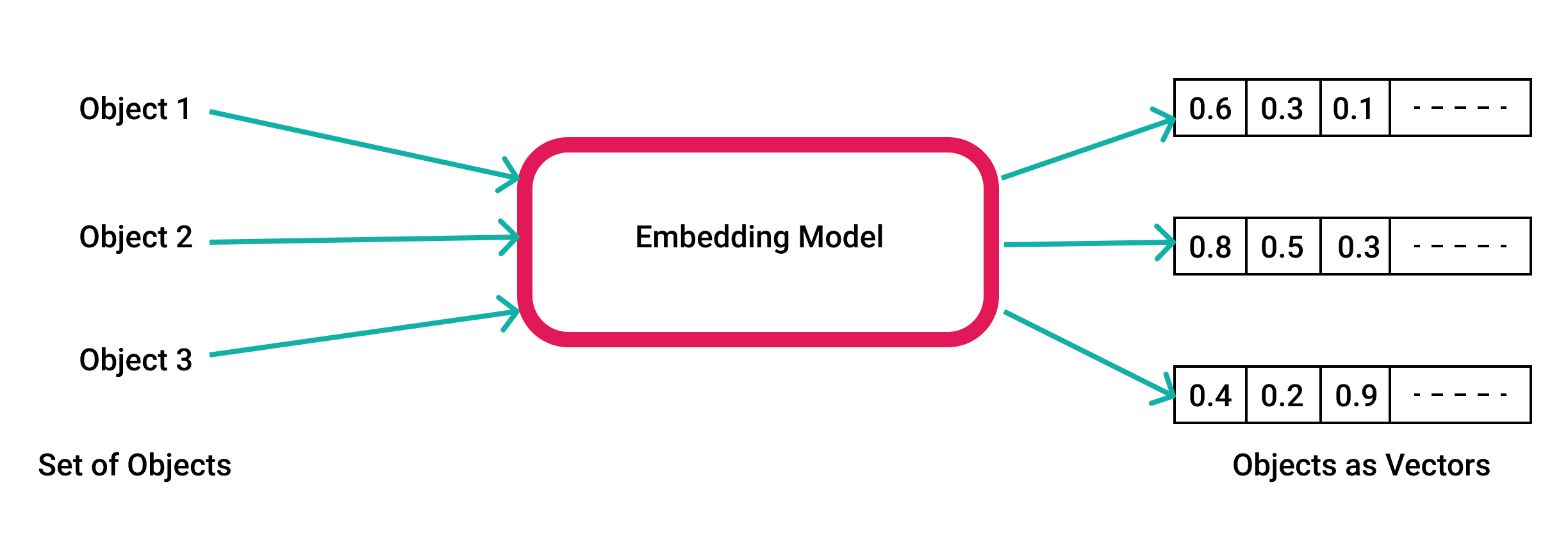
Данная книга посвящена эмбеддингам:
Объясняется что такое эмбеддинги (на примере рекомендательной системы)
Рассматриваются классические и современные подходы к созданию эмбеддингам
Обсуждается использование эмбеддингов в production (как их получать, хранить, оценивать и тд)
Курсы
⭐ Школа глубокого обучения ФПМИ МФТИ

Школа глубокого обучения — это образовательный проект Физтех-школы прикладной математики и информатики МФТИ. Обучение нейросетям происходит с самых основ и до продвинутого уровня. Занятия ведут выпускники ФПМИ МФТИ, имеющие опыт разработки и исследований в области AI.
Программа 1-ой части курса (Введение в ML, DL и CV):
Введение в искусственный интеллект
Основы машинного обучения
Линейные модели
Композиции алгоритмов МО и выбор модели
Введение в нейронные сети
Сверточные нейросети (CNN)
Продвинутое обучение нейросетей
Архитектуры CNN и Transfer Learning
Семантическая сегментация
Детекция объектов на изображении
Автоэнкодеры
Генеративное-состязательные сети (GAN)
Итоговый проект
Программа 2-ой части курса (NLP, Audio):
Введение в NLP. Эмбеддинги слов
Рекуррентные нейросети (RNN)
Языковое моделирование
Машинный перевод, архитектура encoder-decoder
Механизм Attention и архитектура Transformer
Предобучение и дообучение языковых моделей
GPT, GPT-2, GPT-3, ChatGPT, Zero-shot Learning
Задачи NLP и методы их решения
Суммаризация текста и диалоговые системы
Дистилляция больших моделей
Введение в обработку аудио
Введение в распознавание речи
Итоговый проект
Deep Learning Specialization paid

Хорошая специализация по глубокому обучению на Coursera. Подойдет, как вводный курс, но на момент ее прохождения (2019 год), практика не была сильной стороной этой специализации (можете почитать отзывы).
Я бы порекомендовал посмотреть лекции и не платить за нее.
MIT 6.S191. Introduction to Deep Learning

Вводная программа Массачусетского технологического института по методам глубокого обучения с применением к обработке естественного языка, компьютерному зрению, биологии и многому другому! На ней вы узнаете об алгоритмах глубокого обучения, получите практический опыт построения нейронных сетей и освоите новейшие темы, включая большие языковые модели и генеративный искусственный интеллект.
⭐ Practical Deep Learning for Coders от fast.ai
Бесплатный курс, предназначенный для людей, которые хотят научиться применять глубокое обучение и машинное обучение для решения практических задач:
Обучение DL моделей для компьютерного зрения, обработки естественного языка, решения табличных задач и задач коллаборативной фильтрации
Развертывание моделей
Использование PyTorch, а также популярных библиотек, таких как fastai и Hugging Face
Отлично дополняет курс бесплатная книга Deep Learning for Coders with Fastai and PyTorch: AI Applications Without a PhD.
⭐ Learn PyTorch for Deep Learning: Zero to Mastery
Этот курс научит вас основам машинного обучения и глубокого обучения с помощью PyTorch:
Fundamentals
Neural Network Classification
Computer Vision
Custom Datasets
Going Modular
Transfer Learning
Experiment Tracking
Paper Replicating
Model Deployment
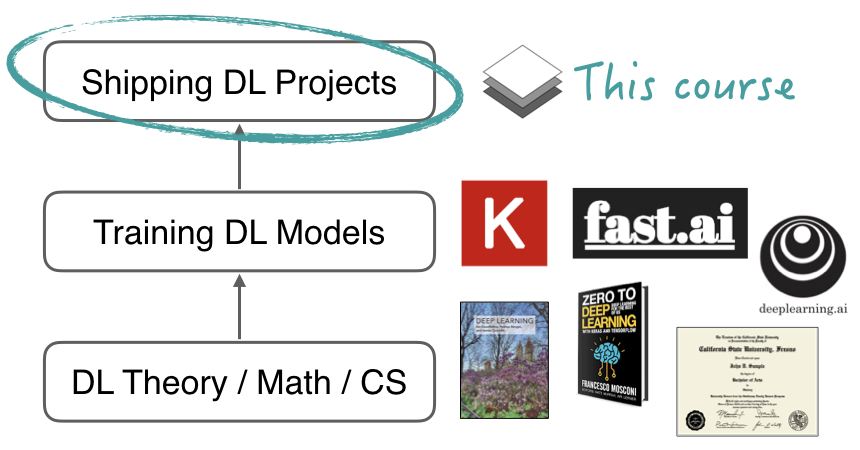
Курс подойдет людям, которые уже знают основы DL и хотели бы лучше разобраться, как применять DL в реальных задачах:
Постановка задачи и оценка стоимости проекта
Поиск, очистка, обработка, разметка, синтез и аугментация данных
Выбор подходящей платформы и вычислительной инфраструктуры
Устранение неполадок в обучении и обеспечение воспроизводимости результатов
Развертывание модели в production
Мониторинг и постоянное улучшение развернутой модели
Как работают ML-команды и как управлять ML-проектами
Использование больших языковых моделей (LLM) и других Foundation моделей
Efficient Deep Learning Systems
Данный курс, как и предыдущий, больше направлен на продукционализацию и оптимизацию DL моделей:
Introduction
Experiment tracking, model and data versioning, testing DL code in Python
Training optimizations, profiling DL code
Basics of distributed ML
Data-parallel training and All-Reduce
Training large models
Python web application deployment
LLM inference optimizations and software
Efficient model inference
⭐ Neural Networks: Zero to Hero by Andrej Karpathy
Курс Андрея Карпати по построению нейронных сетей с нуля - с основ обратного распространения ошибки до современных глубоких нейронных сетей, таких как GPT.
По мнению автора, языковые модели — отличное место для изучения глубокого обучения, даже если вы намерены в конечном итоге перейти к другим областям, таким как компьютерное зрение, потому что большую часть того, что вы изучите, можно будет сразу же применить и в новой для вас области.
Шпаргалки
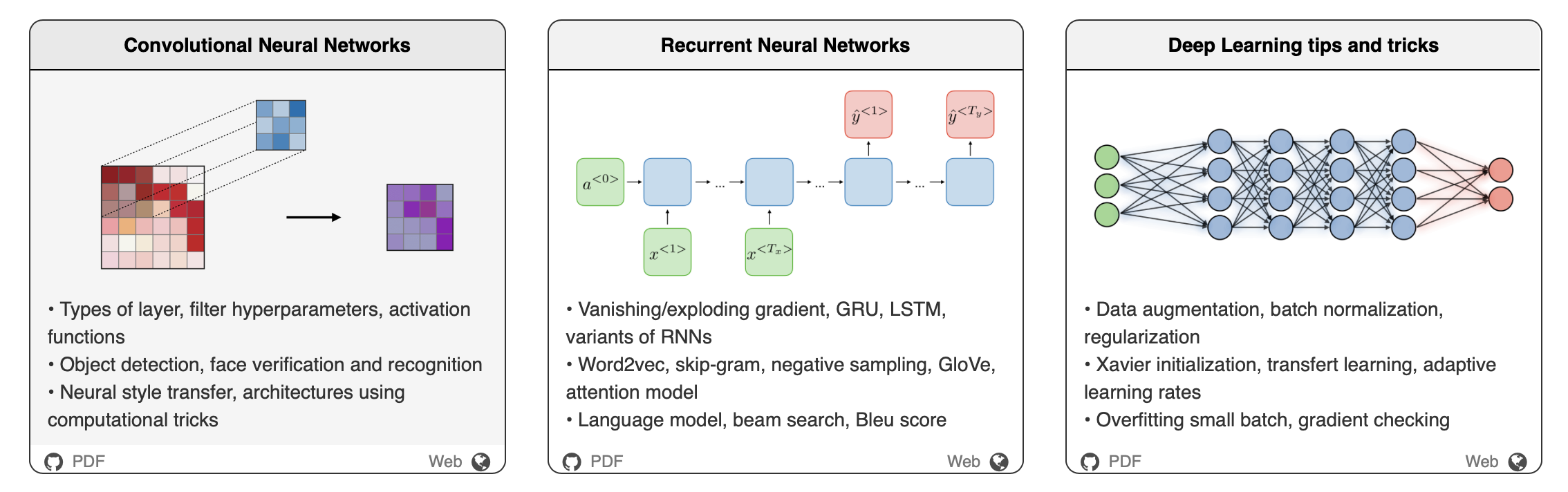
Братья Афшин и Шервин Амиди подготовили гайды, в которых подчеркиваются важные моменты каждого предмета, которые Шервин преподавал в Стэнфорде.
Данные материалы подойдут, когда нужно за короткое время, например, перед собеседованием, вспомнить основные моменты в определенной теме.
Не забывайте, что про похожие шпаргалки, но уже по классическому ML, я писал в этом разделе второй статьи.
Типы слоев, гиперпараметры для фильтров, функции активации
Обнаружение объектов (Object Detection), распознавание лиц (Face Verification and Recognition)
Перенос нейростиля (Neural Style Transfer); архитектуры, использующие вычислительные трюки
Исчезающий/расширяющийся градиент (vanishing/exploding gradient), GRU, LSTM, разновидности RNNs
Word2vec, skip-gram, негативное сэмплирование (negative sampling), GloVe, модель внимания (attention model)
Языковая модель (language model), beam search, Bleu скор
Аугментация данных (data augmentation), пакетная нормализация (batch normalization), регуляризация
Инициализация Ксавье (Xavier initialization), трансферное обучение (transfer learning), адаптивная скорость обучения (adaptive learning rates)
Переобучение на маленьких батчах (overfitting small batch), проверка градиента (gradient checking)
Разное
⭐ Deep Learning Models by Sebastian Raschka
Коллекция различных архитектур глубокого обучения, моделей и советов для обучения (TensorFlow и PyTorch) в Jupyter Notebooks.
Руководство по настройке гиперпараметров для моделей глубокого обучения.

Это тщательно подобранный список туториалов, проектов, библиотек, видео, статей, книг и всего, что связано с PyTorch.
Обработка текстов на естественном языке
В данном разделе рассмотрим материалы (в основном курсы) по обработке текстов на естественном языке.
Материалы (40+ ссылок), целиком посвященные большим языковым моделям (Large Language Models / LLM) и Prompt Engineering не влезают в статью, поэтому их вы сможете найти в репозитории Data Science Resources.
Курсы
⭐ Курс по NLP от ШАД (Елена Войта)
Отличный курс, покрывающий одновременно и классические подходы, и современные темы:
Word Embeddings
Text Classification
Language Modeling
Seq2seq and Attention
Transfer Learning
LLMs and Prompting
Transformer architecture & training tricks
Conversation systems, instruction fine-tuning & RLHF
Efficient inference of NLP models
В дополнение к курсу Елена Войта (автор) подготовила замечательные интерактивные материалы NLP Course | For You.
Нейронные сети и обработка текста

Давно не обновляемый (2019 год), но все еще хороший курс для изучения основ NLP от специалистов Samsung AI Center:
Введение
Векторная модель текста и классификация длинных текстов
Базовые нейросетевые методы работы с текстами
Языковые модели и генерация текста
Преобразование последовательностей: 1-к-1 и N-к-M
Transfer learning, адаптация моделей
Финальное соревнование на kaggle и заключение
Курс по NLP от Валентина Малых

В курсе покрываются следующие топики:
Introduction to Natural Language Processing
Machine Learning Basics and Text Classification
Word Embeddings
Convolutional Neural Networks
Hidden Markov Models and Tagging
Recurrent Neural Networks
Topic Modeling
Statistical Machine Translation
Transformers
Conversational AI
Курсы от Стенфорда

-
⭐ Stanford CS224N: NLP with Deep Learning + Video + Notes
Классический курс по NLP от Стенфорда, не требующий представления:
Word Vectors
Word Vectors and Language Models
Backpropagation and Neural Network Basics
Dependency Parsing
Recurrent Neural Networks
Sequence to Sequence Models and Machine Translation
Transformers
Pretraining
Post-training (RLHF, SFT)
Efficient Adaptation
Question Answering
Security and Privacy
Benchmarking and Evaluation
Code Generation
Multimodal Language Models
Human Centered NLP
Deployment and Efficiency
Open Questions in NLP 2024
Stanford CS 224V: Conversational Virtual Assistants with Deep Learning

Этот курс научит вас обработке естественного языка с использованием библиотек из экосистемы Hugging Face — ? Transformers, ? Datasets, ? Tokenizers и ? Accelerate, а также Hugging Face Hub:
Главы с 1 по 4 знакомят с основными понятиями библиотеки ? Transformers. К концу этой части курса вы познакомитесь с тем, как работают модели, основанные на архитектуре Transformer, и будете знать, как запускать их из Hugging Face Hub, дообучать на своем наборе данных и делиться своими результатами в Hub!
Главы с 5 по 8 обучают основам ? Datasets и ? Tokenizers, прежде чем погрузиться в классические задачи NLP. К концу этой части вы сможете самостоятельно решать наиболее распространенные проблемы NLP.
Главы с 9 по 12 выходят за рамки NLP и исследуют, как модели с архитектурой Transformer можно использовать для решения задач в области обработки речи и компьютерного зрения. Попутно вы узнаете, как создавать и публиковать демо-версии своих моделей, а также оптимизировать их для production. К концу этой части вы будете готовы применить ? Transformers для решения (почти) любой задачи машинного обучения!
Linguistics for Language Technology
Данный курс будет полезен тем, кто хочет не только решать NLP задачи с помощью машинного обучения, но и понимать основы лингвистической теории: слова, морфология, синтаксис, межъязыковые вариации, семантика (значения слова, значения предложения), дискурс и прагматика.
Книги
⭐ Speech and Language Processing by Dan Jurafsky and James H. Martin

Учебник, который покрывает и классические, и современные подходы от Daniel Jurafsky - это бессмертная классика, к которой постоянно выходят обновления.
В качестве дополнения можно также посмотреть на курс LSA 311: Computational Lexical Semantics от этого же автора.
⭐ Natural Language Processing with Transformers by Lewis Tunstall, Leandro von Werra adn Thomas Wolf

С момента своего появления в 2017 году Transformers быстро стала доминирующей архитектурой для достижения самых лучших результатов в различных NLP задачах. Эта практическая книга поможем вам:
Создавать, отлаживать и оптимизировать модели Transformers для основных задач NLP, таких как классификация текста (Text Classification), распознавание именованных сущностей (Named Entity Recognition / NER / Token Classification) и ответы на вопросы (Question Answering).
Узнать, как Transformers можно использовать для межъязыкового трансферного обучения (cross-lingual transfer learning).
Применить Transformers в реальных задачах, где недостаточно размеченных данных.
Делать модели Transformers эффективными для развертывания, используя такие методы, как distillation, pruning и quantization.
Обучать Transformers с нуля и узнать, как это делать на нескольких GPU.
Transformers for Natural Language Processing by Denis Rothman

Данная книга научит вас обучать и настраивать архитектуры глубоких нейронных сетей (для NLP) с помощью Python, Hugging Face и OpenAI (GPT-3, ChatGPT и GPT-4).
Статьи
За список статей благодарю Илью Гусева:
Word2Vec, Mikolov et al., Efficient Estimation of Word Representations in Vector Space
FastText, Bojanowski et al., Enriching Word Vectors with Subword Information
Attention, Bahdanau et al., Neural Machine Translation by Jointly Learning to Align and Translate
Transformers, Vaswani et al., Attention Is All You Need
BERT, Devlin et al., BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
GPT-2, Radford et al., Language Models are Unsupervised Multitask Learners
GPT-3, Brown et al, Language Models are Few-Shot Learners
LaBSE, Feng et al., Language-agnostic BERT Sentence Embedding
CLIP, Radford et al., Learning Transferable Visual Models From Natural Language Supervision
RoPE, Su et al., RoFormer: Enhanced Transformer with Rotary Position Embedding
LoRA, Hu et al., LoRA: Low-Rank Adaptation of Large Language Models
InstructGPT, Ouyang et al., Training language models to follow instructions with human feedback
Scaling laws, Hoffmann et al., Training Compute-Optimal Large Language Models
FlashAttention, Dao et al., FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
NLLB, NLLB team, No Language Left Behind: Scaling Human-Centered Machine Translation
Q8, Dettmers et al., LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
Self-instruct, Wang et al., Self-Instruct: Aligning Language Models with Self-Generated Instructions
Alpaca, Taori et al., Alpaca: A Strong, Replicable Instruction-Following Model
LLaMA, Touvron, et al., LLaMA: Open and Efficient Foundation Language Models
Прочее
Список из 100 вопросов (по классическому и современному NLP, а также по большим языковым моделям) поможет вам структурировать свой процесс изучения NLP и подготовки к собеседованиям.
Русскоязычный чат по NLP в телеграм с 6000+ участниками, в котором:
Задают на вопросы (и иногда отвечают)
Публикуют новости
Анонсируют соревнования, семинары и конференции
Размещают вакансии
Компьютерное зрение
В данном разделе рассмотрим материалы по компьютерному зрению.
Компьютерное зрение объединяет под собой подходы к обработке и анализу изображений, где главная цель - научить компьютер воспринимать изображения как человек. Технологии на основе компьютерного зрения сейчас активно используются в промышленности, медицине, автомобильной и многих других отраслях.
Нейронные сети и компьютерное зрение
В этом курсе вы сделаете первые шаги в области компьютерного зрения с методами машинного обучения:
Нейрон и нейронная сеть
Строим первую нейронную сеть
Задачи, решаемые при помощи нейронных сетей
Методы оптимизации
Свёрточные нейронные сети
Регуляризация и нормализация
Метод максимального правдоподобия и большой финал
⭐ CS231n: Deep Learning for Computer Vision + Videos

Классический курс по CV от Стенфорда, не требующий представления:
Deep Learning Basics
Image Classification with Linear Classifiers
Regularization and Optimization
Neural Networks and Backpropagation
Image Classification with CNNs
CNN Architectures
Training Neural Networks
Recurrent Neural Networks
Attention and Transformers
Video Understanding
Object Detection and Image Segmentation
Visualizing and Understanding
Self-supervised Learning
Robot Learning
Generative Models
3D Vision
EECS 442: Computer Vision + Videos
Вводный курс о компьютерном зрении.
Привожу названия тем на английском, чтобы не искажать терминологию переводом:
Image formation / projective geometry / lighting
Practical linear algebra
Image processing / descriptors
Image warping
Linear models + optimization
Neural networks
Applications of neural networks
Motion and flow
Single-view geometry
Multi-view geometry
Applications
Графовые нейронные сети
В данном разделе рассмотрим материалы по графовым нейронным сетям.
Графовые нейронные сети - это тип архитектуры нейронных сетей, который позволяет обучаться на графовых данных. В самом общем смысле граф — это множество точек (вершин, узлов), которые соединяются множеством линий (рёбер, дуг). Графовые нейронные сети применяются в рекомендательных системах, комбинаторной оптимизации, компьютерном зрении, физике и химии, разработке лекарств и в других отраслях.
CS224W: Machine Learning with Graphs + Video

Этот курс посвящен вычислительным и алгоритмическим задачам, а также задачам моделирования, характерным для анализа больших графов. Посредством изучения базовой структуры графа и ее особенностей учащиеся знакомятся с методами машинного обучения и инструментами интеллектуального анализа данных, которые позволяют получить представление о различных сетях.
Вводный туториал по графовым нейронным сетям.
Graph Neural Networks for RecSys
Туториал по использованию графовых нейронных сетей в рекомендательных системах.
Обучение с подкреплением
В данном разделе рассмотрим материалы по обучению с подкреплением.
Обучение с подкреплением — это метод машинного обучения, при котором происходит обучение модели, которая не имеет сведений о системе, но имеет возможность производить какие-либо действия в ней. Действия переводят систему в новое состояние и модель получает от системы некоторое вознаграждение.
Это не такая популярная область, как NLP или CV, но сейчас она "набирает обороты" и используется в автономных автомобилях, финансах, медицине, а также для автоматизации промышленности и в других областях.

Это образовательный ресурс, созданный OpenAI, который упрощает изучение глубокого обучения с подкреплением (deep RL).
Этот модуль содержит множество полезных ресурсов, в том числе:
Краткое введение в терминологию RL, виды алгоритмов и базовую теорию
Эссе о том, как стать исследователем в RL
Тщательно подобранный список важных статей, организованный по темам
Хорошо документированный репозиторий кода с короткими standalone реализациями ключевых алгоритмов
Несколько упражнений для разминки
? Deep Reinforcement Learning Course

Этот курс научит вас глубокому обучению с подкреплением от новичка до эксперта.
В этом курсе вы:
? Изучите Deep Reinforcement Learning в теории и на практике.
?? Научитесь использовать известные библиотеки Deep RL, такие как Stable Baselines3, RL Baselines3 Zoo, Sample Factory и CleanRL.
? Обучите агентов в уникальных средах, таких как SnowballFight, Huggy the Doggo ?, VizDoom (Doom), а также в классических средах, таких как Space Invaders, PyBullet и других.
? Поделитесь своими обученными агентами с помощью одной строки кода в Hub, а также загрузите мощные агенты от сообщества.
? Примете участвуйте в соревнованиях, в которых вы будете сравнивать своих агентов с другими командами. Вы также сможете играть против агентов, которых будете обучать.
? Получите сертификат об окончании, выполнив 80% заданий.
Reinforcement Learning Textbook

Современные алгоритмы глубокого обучения с подкреплением способны решать задачи искусственного интеллекта методом проб и ошибок без использования каких-либо априорных знаний о решаемой задаче.
В этом конспекте собраны принципы работы основных алгоритмов, достигших прорывных результатов во многих задачах от игрового искусственного интеллекта до робототехники. Вся необходимая теория приводится с доказательствами, использующими единый ход рассуждений, унифицированные обозначения и определения. Основная задача этой работы — не только собрать информацию из разных источников в одном месте, но понять разницу между алгоритмами различного вида и объяснить, почему они выглядят именно так, а не иначе.
Предполагается знакомство читателя с основами машинного обучения и глубокого обучения.
Рекомендательные системы
Рекомендательные системы являются довольно популярным направлением в ML и используются повсеместно, начиная от стриминговых сервисов и заканчивая маркетплейсами, то есть применяются там, где нужно порекомендовать покупателю/клиенту что-то на основании истории взаимодействия с системой всех ее пользователей.
Курсы

За 5 занятий вы разберетесь, как правильно поставить задачу, какие данные нужно собирать, освоите полезные приемы, попробуете популярные фреймворки для построения рекомендательных систем, создадите собственный прототип и узнаете, как довести его до продакшена:
Введение в рекомендательные системы
Методы валидации, метрики и бейзлайны
Фильтрация на основе контента и коллаборативная фильтрация
Градиентный бустинг на деревьях и задача ре-ранжирования
Более продвинутые методы анализа данных и моделей в рекомендациях
⭐ Your Second RecSys (продолжение Your First RecSys)

На этом курсе более подробно затрагиваются проблемы оценки эффекта влияния рекомендательной модели на продукт и способы измерения этого влияния, строится production система (от файла в ноутбуке до real-time микросервисной архитектуры), и используются более сложные модели, а именно: двухуровневые и нейросетевые.
Вас ждут лекции от разных экспертов, примеры с кодом и соревнование на реальных данных в конце курса:
-
Your first money / experiment
Бизнес-эффект от рекомендаций
Дополнительные методы оценки качества рекомендаций
-
Your first prod
Рекомендации в production
Ускорение рекомендаций в production
-
Your second model
Двухэтапная модель
Нейросетевая матричная факторизация и DSSM
Цель курса — обеспечить всестороннее введение в область рекомендательных систем:
Первая часть курса посвящена общим подходам RecSys
Во второй части кратко рассказывается о многоруких бандитах и контрфактической оценке.
Книги
⭐ К. Фальк. Рекомендательные системы на практике / Practical Recommender Systems by Kim Falk

В данной книге объясняется, как работают рекомендательные системы:
Поймете, как собирать пользовательские данные и создавать персонализированные рекомендации.
Узнаете, как использовать самые популярные алгоритмы рекомендаций.
Увидите их примеры в действии на таких сайтах, как Amazon и Netflix.
Рассмотрите проблемы масштабирования и другие проблемы, с которыми вы можете столкнуться на практике.
Personalized Machine Learning by Julian McAuley

Довольно большой раздел этой книги (страницы 79-214) посвящен рекомендательным системам, поэтому я решил ее порекомендовать.
Разное
Рекомендательные системы в Учебнике по машинному обучению от ШАД

Этот репозиторий содержит примеры и лучшие практики по созданию систем рекомендаций, представленные в виде Jupyter notebooks. В примерах подробно описана информация по пяти ключевым задачам:
Подготовка данных: Подготовка и загрузка данных для каждого алгоритма рекомендаций.
Создание модели: Построение моделей с использованием различных рекомендательных алгоритмов, таких как Alternating Least Squares (ALS) или eXtreme Deep Factorization Machines (xDeepFM).
Оценка качества: Оценка алгоритмов с помощью оффлайновых метрик.
Выбор модели и оптимизация: Поиск гиперпараметров для рекомендательных моделей.
Операционализация: Вывод моделей в production с помощью Azure.

Лекция К.В. Воронцова про коллаборативную фильтрацию и матричные разложения.
Рекомендательные системы: идеи, подходы, задачи

Подробная статья на Хабре, которая поможет разобраться в рекомендательных системах.
Временные ряды
В данном разделе рассмотрим материалы по временным рядам. Материалов не очень много, поэтому, как и в нескольких предыдущих разделах, здесь не будет деления по типам.
Временные ряды используются в статистике, обработке сигналов, распознавании образов, эконометрике, финансах, прогнозировании погоды, предсказании землетрясений, электроэнцефалографии, астрономии, а также в любой области, в которой показатели меняются с течением времени.
Статья по временным рядам из учебника по машинному обучению от ШАД, в которой сначала вводится понятие временных рядов и приводятся примеры, а затем рассказывается о сведении задачи предсказания временного ряда к задаче регрессии. Заканчивается статья разделом о декомпозиции временных рядов.
⭐ Topic 9. Time Series Analysis with Python

В Open Machine Learning Course, про который мы говорили во второй статье есть 9 глава, посвященная анализу временных рядов.
В ней рассказывается как с ними работать в Python, какие возможные методы и модели можно использовать для прогнозирования; что такое двойное и тройное экспоненциальное взвешивание; что делать, если стационарность — это не про вас; как построить SARIMA и не умереть; и как прогнозировать xgboost-ом.
Прогнозирование временных рядов

Лекция К.В. Воронцова про временные ряды.
Вводный курс от Kaggle Learn по временным рядам.
Forecasting time series with gradient boosting: Skforecast, XGBoost, LightGBM, Scikit-learn and CatBoost by Joaquín Amat Rodrigo, Javier Escobar Ortiz

В этом гайде показано как использовать методы библиотеки skforecast для прогнозирования временных рядов с использованием моделей из библиотек XGBoost, LightGBM, Scikit-learn и CatBoost.
Груздев А.В., Рафферти Г. Прогнозирование временных рядов с помощью Prophet, sktime, ETNA и Greykite paid

Прогнозирование – одна из задач науки о данных, которая является центральной для многих видов деятельности внутри организации. Книга посвящена популярным библиотекам прогнозирования временных рядов Prophet, Sktime, ETNA и Greykite. Разбирается математический аппарат и API каждой библиотеки. Показаны примеры решения задач прогнозирования, классификации и кластеризации временных рядов, проиллюстрированы темы конструирования и отбора признаков для временных рядов.
В качестве примеров прогнозирования используются данные из самых разных областей – уровень углекислого газа в атмосфере, циклы солнечных пятен, количество местных осадков, число лайков в популярных соцсетях и др. Издание будет интересно специалистам по data science, регулярно решающим задачи с временными рядами.
У себя в telegram автор дополнительно предлагает "Прикладной анализ временных рядов в Python в 4 томах", в котором в дополнении к данной книге есть еще набор материалов "Классика бессмертна" (предварительный анализ ряда, простые модели, конструирование признаков, стратегии валидации, AR, MA, (S)ARIMA(X), ETS, VAR, TBATS/BATS, градиентный бустинг, кластеризация рядов, иерархические ряды). 1200-страничное пособие".
Big Data
Данное направление немного выбивается из подборки, потому что характеризует не задачу, которую мы решаем, а инструмент, с помощью которого мы это делаем, но так как компании, имеющие в своем распоряжении большое количество данных, часто требуют знания этих инструментов (а именно, Spark), и спрашивают про них на собеседованиях, я решил включить этот раздел в статью.

Анализируем данные с помощью фреймворка Spark от VK

Отличное поверхностное руководство по пользованию API Spark.
Знакомство с Apache Spark от DataLearn

В 7-ом модуле курса Введение в Инжиниринг Данных и Аналитику происходит знакомство с open source решением для аналитики и инжиниринга данных - Apache Spark и его коммерческой версией Databricks и аналогами Amazon Glue и Azure Synapse. Вы узнаете о примерах использования Spark в индустрии и популярные use cases. Автор расскажет о своем опыте с Apache Spark в Amazon и Microsoft и научит вас работать с данными с помощью PySpark и Spark SQL, а также поделится лучшими книгами и материалы по этой теме.
⭐ Перрен Ж.Ж. Spark в действии / Spark in Action by Jean-Georges Perrin

Анализ корпоративных данных начинается с чтения, фильтрации и объединения файлов и потоков из многих источников. Механизм обработки данных Spark способен обрабатывать эти разнообразные объемы информации как признанный лидер в этой области, обеспечивая в 100 раз большую скорость, чем например Hadoop. Благодаря поддержке SQL, интуитивно понятному интерфейсу и простому и ясному многоязыковому API вы можете использовать Spark без глубокого изучения новой сложной экосистемы.
Эта книга научит вас создавать полноценные аналитические приложения. В качестве примера используется полный конвейер обработки данных, поступающих со спутников NASA.
Learning Spark by Jules S. Damji, Brooke Wenig, Tathagata Das & Denny Lee

В этой книге предлагается структурированный подход к изучению Apache Spark, охватывающий новые разработки в проекте.
⭐ Data Analysis with Python and PySpark by Jonathan Rioux

Это ваш путеводитель по реализации успешных проектов обработки данных на основе Python. Эта практическая книга, наполненная соответствующими примерами и методами, научит вас создавать пайплайны для формирования отчетов, машинного обучения и других задач. Упражнения в каждой главе помогут вам попрактиковаться в изученном и быстро начать использовать PySpark.
Подведем итоги
Если вы еще не читали, то рекомендую прочитать блоки Learning How to Learn и Подведем итоги из первой статьи, так как все сказанное там применимо и для подготовки к секции по специализированному машинному обучению.
Собранные в этой статье материалы будут полезны при подготовке к собеседованиям на различные позиции в Big Data МегаФон.
А если вы только начинаете свою карьеру в Data Science, то обратите внимание на стажировки в крупных компаниях, на которых вы сможете не только прокачать свои знания, но также получить крутой опыт применения теории на практических задачах бизнеса. В МегаФоне пример такой стажировки - это акселератор (пишите на почту с темой письма "стажировка в big data"), с помощью которого ежегодно находят свою первую работу специалисты по работе с данными (Data Scientists), аналитики (Data Analysts) и дата инженеры (Data Engineers).
Что дальше?
В следующей статье разберем материалы для подготовки к дизайну систем машинного обучения.
Актуальные ресурсы для этой серии статей вы сможете найти в репозитории Data Science Resources, который будет поддерживаться и обновляться. В этот раз в репозиторий выложено больше материалов, чем попало в эту статью (потому что их очень много), поэтому советую зайти туда и найти то, что вам нужно.
Также вы можете подписаться на мой телеграм-канал Data Science Weekly, в котором я каждую неделю делюсь интересными и полезными материалами.
Если вы знаете какие-нибудь классные ресурсы, которые я не включил в этот список, то прошу написать о них в комментариях.
P.S. Благодарю Дарью Шатько за редактуру и вычитку этого поста!
vova_sam
Артем, я еще задачи по алгоритмам не решил. Еще год точно решать ...
у вас очень повышенные требования к датасантистам: и алгоритмист, и оптимизатор, и математик, и сисадмин, и архитектор, и специалист по БД и многое другое. Это плюсом к непосредственно специалисту по ML :) В мегафон резюме высылать не буду.
Но спасибо за статьи: обещаю все изучить!!!
Extremesarova Автор
Я просто предлагаю материалы, которые можно использовать для изучения Data Science и подготовки к собеседованиям.
На собеседованиях спрашивают только маленькую часть от того, что можно узнать, если работать с этими ресурсами.