
 Привет, Хаброжители!
Привет, Хаброжители!Генеративное моделирование — одна из самых обсуждаемых тем в области искусственного интеллекта. Машины можно научить рисовать, писать и сочинять музыку. Вы сами можете посадить искусственный интеллект за парту или мольберт, для этого достаточно познакомиться с самыми актуальными примерами генеративных моделей глубокого обучения: вариационными автокодировщиками, генеративно-состязательными сетями, моделями типа кодер-декодер и многим другим.
Дэвид Фостер делает понятными и доступными архитектуру и методы генеративного моделирования, его советы и подсказки сделают ваши модели более творческими и эффективными в обучении. Вы начнете с основ глубокого обучения на базе Keras, а затем перейдете к самым передовым алгоритмам.
Изменения во втором издании
Спасибо всем, кто прочитал первое издание этой книги. Мне очень приятно, что многие из вас нашли ее полезной и высказали свое мнение о том, что хотели бы видеть во втором издании. Область глубокого генеративного обучения значительно продвинулась в развитии с 2019 года — момента публикации первого издания, поэтому я не только обновил содержимое книги, но и добавил несколько новых глав, чтобы привести материал в соответствие с современным состоянием дел.
Далее кратко изложено, в чем заключаются основные обновления отдельных глав и общее улучшение книги.
Далее кратко изложено, в чем заключаются основные обновления отдельных глав и общее улучшение книги.
- Глава 1 теперь включает раздел, посвященный различным семействам генеративных моделей, их классификации и взаимосвязям между ними.
- Глава 2 содержит улучшенные диаграммы и более подробные объяснения ключевых понятий.
- Глава 3 дополнена новым проработанным примером и сопровождающими его пояснениями.
- Глава 4 теперь включает объяснение условных архитектур GAN.
- В главу 5 включен раздел, посвященный моделям авторегрессии для изображений, например PixelCNN.
- Глава 6 — совершенно новая, в ней описывается модель RealNVP.
- Глава 7 тоже новая, в ней рассматриваются такие методы, как динамика Ланжевена и контрастивная дивергенция.
- Глава 8 написана недавно и посвящена диффузионным моделям удаления шума, лежащим в основе многих современных приложений.
- Глава 9 — это расширение материала, представленного в заключении первого издания. В ней более глубоко рассматривается архитектура различных моделей StyleGAN и представлен новый материал о VQ-GAN.
- Глава 10 — новая, в ней подробно говорится об архитектуре Transformer.
- Глава 11 включает современные архитектуры Transformer, заменяющие модели LSTM из первого издания.
- Глава 12 включает обновленные диаграммы и описания, а также раздел о влиянии этого подхода на современное обучение с подкреплением.
- Глава 13 — новая, в ней подробно объясняется, как работают такие потрясающие модели, как DALL.E 2, Imagen, Stable Diffusion и Flamingo.
- Глава 14 обновлена, чтобы отразить выдающийся прогресс в этой области, произошедший со времени выхода в свет первого издания, и дать более полное и подробное представление о том, куда движется генеративный ИИ.
- Были учтены все комментарии к первому изданию и исправлены выявленные опечатки.
- В начало каждой главы добавлен список ее целей, чтобы вы могли увидеть, какие ключевые темы в ней затронуты.
- Некоторые аллегорические истории были переписаны, чтобы сделать их более краткими и ясными. Я рад тому, что, судя по отзывам, многим читателям эти истории помогли лучше понять ключевые понятия!
- Заголовки и подзаголовки всех глав реорганизованы так, чтобы было понятно, какие их части посвящены объяснениям, а какие — построению собственных моделей.
PixelCNN
В 2016 году ван ден Оорд (van den Oord) с коллегами [Oord et al., 2016] представили модель, которая генерирует изображения попиксельно, прогнозируя вероятность появления следующего пиксела по предшествующим. Модель называется PixelCNN, и ее можно обучить генерировать изображения авторегрессионным способом.
Чтобы разобраться с PixelCNN, нам нужно познакомиться с двумя новыми концепциями: маскированными сверточными слоями и остаточными блоками.

Маскированные сверточные слои
Как мы видели в главе 2, сверточный слой можно использовать для извлечения признаков из изображения путем применения последовательности фильтров. Результатом слоя для конкретного пиксела является взвешенная сумма весов фильтра, умноженная на значения из предыдущего слоя для небольшой квадратной окрестности с центром в пикселе. Этот метод позволяет обнаруживать края и текстуры, а в более глубоких слоях — формы и объекты
высокого уровня.
Сверточные слои очень эффективно выявляют признаки, но их нельзя использовать напрямую в авторегрессионном смысле, поскольку пикселы не упорядочены. Они полагаются на тот факт, что все пикселы обрабатываются одинаково — ни один из них не рассматривается как начало или конец изображения. Это отличает их от текстовых данных, которые мы уже видели в этой главе, где лексемы четко упорядочены, благодаря чему есть возможность применять
рекуррентные модели, такие как LSTM.
Чтобы получить возможность задействовать сверточные слои для генерации изображений в авторегрессионном смысле, нужно сначала упорядочить пикселы и гарантировать, что фильтры увидят только те из них, которые предшествуют рассматриваемому. Затем мы можем генерировать изображения пиксел за пикселом, применяя к текущему изображению сверточные фильтры, которые будут предсказывать значение следующего пиксела на основе предшествующих.
Сначала выберем порядок расположения пикселов, например, слева вправо сверху вниз, перемещаясь сначала по горизонтали, а затем по вертикали. После этого наложим маску на сверточные фильтры, чтобы на выходные данные слоя в каждом пикселе влияли только значения предшествующих ему пикселов. Этого можно добиться умножением маски из единиц и нулей на матрицу весов фильтра, чтобы обеспечить обнуление значений любых пикселов, следующих за целевым.
На самом деле в PixelCNN используются маски двух типов (рис. 5.13):
- тип A маскирует значение центрального пиксела;
- тип B не маскирует значение центрального пиксела.

В примере 5.12 показано, как создать MaskedConvLayer с помощью Keras.

- Слой MaskedConvLayer основан на обычном слое Conv2D.
- Маска инициализируется нулями.
- Пикселы в предыдущих строках демаскируются единицами.
- Пикселы в предыдущих столбцах, находящиеся в одной строке, демаскируются единицами.
- Если маска имеет тип B, центральный пиксел демаскируется единицей.
- Веса фильтра умножаются на маску.
Остаточные блоки
Теперь, увидев, как замаскировать сверточный слой, приступим к созданию PixelCNN. Основным строительным блоком будет остаточный блок.
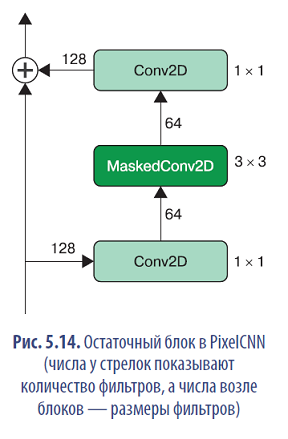
Остаточный блок (residual block) — это набор слоев, которые добавляют выходные данные к входным перед передачей в остальную часть сети. Другими словами, входные данные могут передаваться по короткому пути на выход без прохождения через промежуточные слои — это называется пропускающим соединением (skip connection). Суть приема заключается в следующем: если оптимальное преобразование состоит в том, чтобы сохранить входные данные неизменными, этого можно достичь, просто обнулив веса промежуточных слоев. Без пропускающего соединения сети пришлось бы отыскивать в промежуточных слоях отображения, сохраняющие идентичность, что гораздо сложнее.
На рис. 5.14 показано, как устроен остаточный блок в нашей сети PixelCNN.
В примере 5.13 показано, как создать ResidualBlock.

- Начальный слой Conv2D уменьшает количество каналов вдвое.
- Слой MaskedConv2D типа B с размером ядра 3 использует информацию только из пяти пикселов — трех пикселов в строке над целевым пикселом, одного слева и самого целевого пиксела.
- Последний слой Conv2D удваивает количество каналов, чтобы снова соответствовать входной форме.
- Выходные данные сверточных слоев добавляются к входным — это пропускающее соединение.
Обучение PixelCNN
В примере 5.14 мы собрали всю сеть PixelCNN, примерно следуя структуре, изложенной в оригинальной статье. В той статье выходным является слой Conv2D с 256 фильтрами и функцией активации softmax. Другими словами, сеть пытается воссоздать входные данные, предсказывая значения пикселов подобно автокодировщику. Разница заключается в том, что PixelCNN ограничена так, что никакая информация из более ранних пикселов не может пройти и повлиять на прогноз для каждого пиксела из-за особенностей архитектуры сети — наличия
слоев MaskedConv2D.
Проблема этого подхода в том, что сеть не может понять, что значение пиксела, скажем, 200 очень близко к значению 201. Она должна изучить выходные значения всех пикселов независимо, а это значит, что обучение может протекать очень медленно даже для самых простых наборов данных. Поэтому в своей реализации мы пошли на упрощение, согласно которому каждый пиксел может принимать только одно из четырех значений. Благодаря этому можем использовать выходной слой Conv2D с четырьмя фильтрами вместо 256.

- Входные данные модели — это черно-белое изображение размером 16 х 16 х 1 с входными значениями, масштабированными в диапазон от 0 до 1.
- Первый слой MaskedConv2D типа A с размером ядра 7 использует информацию из 24 пикселов — 21 пиксела в трех рядах над целевым пикселом и трех слева от него (сам целевой пиксел не применяется).
- Далее друг за другом следуют пять групп слоев ResidualBlock.
- Два слоя MaskedConv2D типа B с размером ядра 1 действуют как слои Dense по количеству каналов в каждом пикселе.
- Последний слой Conv2D уменьшает количество каналов до четырех — количества значений пикселов в этом примере.
- Создается модель, принимающая и возвращающая изображения тех же размеров.
- Обучение модели — входные данные input_data масштабируются в диапазон [0, 1] (числа с плавающей точкой), выходные данные output_data масштабируются в диапазон [0, 3] (целые числа).
Анализ PixelCNN
Попробуем обучить свою модель PixelCNN на изображениях из набора Fashion-MNIST, с которым мы встречались в главе 3. Чтобы сгенерировать новые изображения, нужно попросить модель предсказать каждый следующий пиксел на основе всех предыдущих. Это очень медленный процесс по сравнению с такой моделью, как вариационный автокодировщик! Для черно-белых изображений 32 х 32 нужно последовательно получить 1024 прогноза. Сравните это с получением одного прогноза при использовании VAE. Это один из основных недостатков таких моделей авторегрессии, как PixelCNN, — они работают очень медленно из-за последовательного характера процесса выборки.
Чтобы ускорить создание новых изображений, мы применяем размер изображения 16 х 16, а не 32 х 32. Класс обратного вызова, генерирующий изображения, показан в примере 5.15.


- Процесс начинается с партии пустых изображений (значения всех пикселов равны нулю).
- Цикл по строкам, столбцам и каналам текущего изображения с прогнозированием распределения значения следующего пиксела.
- Получение значений пикселов из прогнозируемого распределения (в нашем примере —значений из диапазона [0, 3]).
- Преобразование значений пикселов в диапазон [0, 1] и подстановка значения пиксела в текущем изображении для подготовки к следующей итерации цикла.
а также сгенерированные моделью PixelCNN.

Модель прекрасно воссоздает общую форму и стиль исходных изображений! Но самое удивительное, что теперь мы можем рассматривать изображения как серию лексем (значений пикселов) и применять модели авторегрессии, такие как PixelCNN, для создания реалистичных изображений.
Как упоминалось ранее, один из недостатков авторегрессионных моделей — низкая скорость выборки, поэтому в книге представлен простой пример их применения. Однако, как будет показано в главе 10, можно создавать более сложные формы авторегрессионных моделей и применять их к изображениям для получения более впечатляющих результатов. В таких случаях низкая скорость генерации является неизбежной платой за результаты исключительно
высокого качества.
С момента публикации оригинальной статьи в архитектуру и процесс обучения PixelCNN было внесено несколько улучшений. В следующем разделе представлено одно из этих изменений — использование смешанных распределений — и показано, как обучить модель PixelCNN с помощью этого улучшения, задействуя TensorFlow.
Об авторе
Дэвид Фостер (David Foster) — специалист по данным, предприниматель и преподаватель, специализирующийся на применении искусственного интеллекта в области творчества. Как соучредитель Applied Data Science Partners (ADSP) помогает организациям использовать преобразующую силу данных и искусственного интеллекта. Имеет степень магистра математики, полученную в Тринити-колледже (Кембридж), степень магистра операционного анализа, полученную в Уорикском университете, и преподает в институте машинного обучения, специализируясь на практическом применении искусственного интеллекта
и решении реальных задач. В круг его исследовательских интересов входит повышение прозрачности и интерпретируемости алгоритмов искусственного интеллекта. Он также опубликовал несколько статей по объяснимому машинному обучению в здравоохранении.
и решении реальных задач. В круг его исследовательских интересов входит повышение прозрачности и интерпретируемости алгоритмов искусственного интеллекта. Он также опубликовал несколько статей по объяснимому машинному обучению в здравоохранении.
Более подробно с книгой можно ознакомиться на сайте издательства:
» Оглавление
» Отрывок
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Для Хаброжителей скидка 25% по купону — Глубокое обучение