

Всем привет!
На связи Георгий Бредис, Deep Learning Engineer из команды Intelligent Document Processing в SberDevices. Наша команда занимается задачами автоматизации бизнес-процессов путем извлечения информации из неструктурированного контента и созданием сервисов суммаризации и поиска на основе LLM. В данный момент мы исследуем новые способы извлечения информации из интерфейсов, что открывает новые возможности для автоматизации процессов в сфере RPA.
В этой статье речь пойдет об использовании больших языковых моделей для работы с браузером, как одного из самых распространенных примеров интерфейса.
В первой части я расскажу, как такие модели строятся, чем отличаются разные подходы и какие проблемы они решают.
Во второй части проведу обзор существующих бенчмарков и подходов для данной задачи.
Наконец, в заключении, я поделюсь нашими собственными разработками. Это:
Мультимодальный инструктивный бенчмарк на скриншотах на русском языке;
Domain-based LLM, решающая подобные задачи.
Базовая идея
При правильной подготовке большие языковые модели, работающие в браузере, способны автоматически выполнять задачи в интернете, имитируя действия человека. Подобные модели могут переходить по веб-страницам, заполнять формы, кликать по ссылкам и собирать данные, и всё это без прямого участия пользователя. Основная идея заключается в том, чтобы автоматизировать рутинные задачи. Далее мы обсудим, как эту задачу можно решить, и проведём обзор возможных подходов.
Основные подходы
Веб-страницы можно описать несколькими способами:
HTML (а также CSS и JavaScript) — используется для создания и структурирования контента на веб-страницах, включая текст, изображения и ссылки.
DOM-структура — графовое (более точно — древовидное) представление веб-страницы. Служит для более эффективного взаимодействия со структурой страницы.
Изображение — в конечном итоге пользователь, как правило, взаимодействует только с визуальным отображением веб-сайтов, что представляется в виде наборов изображений.
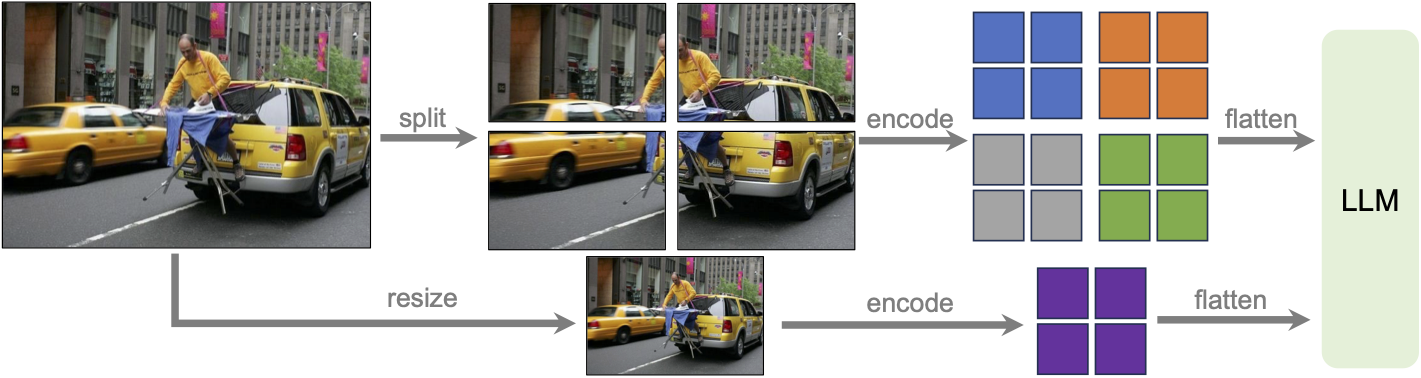
Каждый из описанных выше способов может представлять входные данные для модели. На выходе ожидается текст, который нужно использовать для совершения действий и планирования. Так что базово любая модель представляет собой комбинацию энкодера (кодировщика) определённой модальности (или нескольких модальностей, например HTML и изображения) и текстового декодера.
В зависимости от выбора входных данных будет меняться и структура модели, а также формат и процедура сбора данных для дообучения. Модели на веб-домене можно разбить на две группы: те, что работают на изображениях (image-based), и те, что работают с текстом в виде HTML (text-based). Ниже мы более подробно рассмотрим каждый из видов моделей, обсудим их сильные и слабые стороны, а после перейдём к конкретным подходам.
Image-Based Models (скриншоты)
Модели, работающие с изображениями, нарезают изображения на мелкие кусочки (патчи, англ. patches), которые затем подаются в визуальный энкодер или в текстовую модель (через проекцию). У данных подходов есть несколько ограничений. Среди них основные следующие.
Ограниченность контекста на одном изображении. Это вводит дополнительную ось взаимодействия с прокруткой страницы (scroll).
Так как подобным моделям нужно оперировать с признаками низких уровней (веб-элементы, текст на изображении), то необходимо использовать энкодеры высоких разрешений. Чем больше разрешение у энкодера, тем больше токенов поступят на вход модели. Это сильно ограничивает возможность общаться с моделью и задавать дополнительные вопросы. При использовании энкодеров на маленьком разрешении модель не может найти правильные элементы для взаимодействия. Вдобавок к предыдущим проблемам, энкодеры на маленьком разрешении больше и имеют более качественные фичи.
Способ идентификации. По идее, каждый элемент веб-страницы имеет уникальный идентификатор, но при использовании исключительно изображения мы должны предсказывать координаты элементов без возможности использовать идентификатор напрямую. Это приводит к ряду проблем, таких как способ определения элемента (центр или ограничивающую рамку) и вложенность.
Text-Based Models (HTML)
Модели, работающие на HTML-страницах, как правило, обрабатывают HTML-код страницы перед тем, как отдать её декодеру (LLM). Это нужно, чтобы ненужная информация из HTML не забивала контекст, так как очень часто код страницы содержит большое количество шума. Часть подходов основывается на фильтрации HTML-документа, другие используют сложные механизмы внимания и эвристики, чтобы обходить сложность обработки HTML. Среди основных ограничений выделим следующие.
Шум. как упоминалось выше, HTML-код одной страницы наполнен большим количеством ненужной информации. Так что его необходимо дополнительно обрабатывать.
Неподходящие стандартные способы обучения моделей. Поскольку для анализа HTML необходимо ориентироваться в иерархической структуре страницы (модель должна понимать отношения между элементами дерева и текстами внутри них), обучение таким задачам, как span corruption или fill-in-the-middle с относительно короткими спанами не позволяет добиться появления желаемых свойств.
Ограниченность на домене. HTML-код встречается только в браузере. Несмотря на изначально поставленную задачу, мы хотим получить обобщаемую модель, которая сможет взаимодействовать не только с веб-страницами, но и с мобильными интерфейсами, десктопными приложениями, документами. Также HTML-код плохо передает визуальные свойства изображения.
Mixed Models
Помимо упомянутых способов обработки веб-страниц, существуют комбинированные подходы, а также есть возможность добавлять токены от DOM-структуры страницы. Из-за слишком узкой направленности и сложного инференса подобных моделей мы не будем останавливаться на них в этой статье. Если вам интересно узнать больше о таких подходах, напишите об этом в комментариях.
Далее перейдём к обсуждению бенчмарков, ведь ни одна модель машинного обучения не строится без правильных метрик.
Бенчмарки
Среди бенчмарков можно выделить несколько категорий:
web VQA — вопросы для одной страницы (очень похожие по домену на DocVQA. Кстати, DocVQA наша команда тоже занималась, ссылка1, ссылка2);
single-hop взаимодействие со страницей (например, нажать на нужную кнопку);
multi-hop взаимодействия. Которые, в свою очередь, подразделяются на оффлайн и онлайн. Первые предполагают оценку модели на изображениях и заранее отобранной стратегии взаимодействия с сайтом. Вторые предполагают оценку в среде, то есть оценку качества достижения цели, а не следования конкретному маршруту.
Ниже мы обсудим основные на данный момент англоязычные бенчмарки и способы их перевода. Основной фокус будет сделан на десктопных сайтах, с некоторыми отсылками на мобильные приложения. Также, несмотря на полноту работы, будут упущены некоторые знакомые многим бенчмарки (такие как MiniWob++), так как они не позволяют оценить качество модели на реальной задаче.
Web VQA
В данном разделе обсудим основные способы оценки качества понимания веб-страниц, возможность извлечения информации и связь с похожими доменами. Во избежание громоздкости этого раздела упустим бенчмарки общего VQA, так или иначе имеющие пересечения с веб-доменом.
Основной бенчмарк по извлечению информации для моделей на веб-домене по формату очень похож на DocVQA, ChartQA и т. д. Фокус в работе сделан на нахождение информации на веб-странице и создании базовых моделей для решения этой задачи. Это главный бенчмарк для оценки возможности моделей извлекать информацию из веб-страниц.
Web Navigation
Рассмотрим несколько базовых (иногда совсем новых) работ по оценке различных аспектов веб-навигации у моделей.
ScreenSpot
Довольно новый датасет, представленный в работе SeeClick. Представляет из себя single-hop вопросы на составление пары координата-действие по заданной инструкции. Подобный бенчмарк позволяет оценить базовое качество модели, не переходя к более сложным офлайновым бенчмаркам.

В данный момент ключевой бенчмарк для любых систем, стремящихся автоматизировать взаимодействие с браузером. Он представляет из себя офлайн-среду для оценки ряда действий возвращаемых моделью. Включает качество оценки определения элемента взаимодействия, определения типа взаимодействия и их сочетание. Покрывает довольно большое кол-во доменов и хорошо задокументирован.
Этот multi-hop бенчмарк является примером офлайновой оценки модели, что не позволяет действительно оценить качество последней и является только прокси-метрикой, так как на реальных сайтах достичь цели можно множественными траекториями. Для решения этой проблемы используются так называемые онлайн-бенчмарки, но их невозможно использовать без среды, что также ограничивает их применение.
В последнее время появляется все больше бенчмарков наподобие Mind2Web, среди которых можно выделить довольно примечательный OmniACT, оценивающий качество понимания моделью среды при помощи генерации кода (что в будущем может стать основным способом взаимодействия с интерфейсами!).
Open-Source and Papers
Среди всех работ по взаимодействию с веб-страницами можно выделить два основных направления, первый — на основе GPT4V (возможно, в скором времени к ним добавятся и новые модели с возможностью вызова по API, но пока не позволяет качество), второй — создание отдельных доменных моделей.
API-Based модели
Эта категория подходов использует API GPT4V (пока только эта модель), подаёт изображения или отфильтрованный HTML-текст на вход модели, а получает действие и какой-то способ определить элемент. Основной проблемой является необходимость определения элементов взаимодействия, поэтому используются различные способы граундинга (от англ. grounding — приземление) предсказаний модели на интерфейс. Далее пройдёмся более подробно по каждому из них:
Image Annotation (Set-of-Marks)
В данном случае на вход модели поступают скриншоты с подсвеченными элементами для возможного взаимодействия. Это можно сделать через инструменты управления браузером (playwright) или при помощи расширений (например, через vimium, как это делает VimGPT, что, по сути, очень похоже на предыдущий подход). В таком случае изображение выглядит так (в примере использован vimium), а модель должна вернуть выбор элемента (в виде набора символов) и тип действия.
Из довольно известных данный подход использован в работах WebVoyager, VimGPT и SeeAct (оставшиеся два метода предложены в этой же работе и ее предшественнике).

Element Attributes
В данном подходе модели предлагается сгенерировать детальное описание элемента для взаимодействия, после чего происходит поиск по данной DOM-структуре на наличие подобных элементов. Этот метод также рассматривался как один из основных в работе SeeAct.
Textual Choices
Подход, берущий идею из Mind2Act. Основная идея — возьмём возможные кликабельные элементы из HTML-страницы, выберем лучшие (например при помощи энкодера по типу DeBERTa) и подадим на вход LLM с просьбой выбрать лучшие. В результате из подходов на основе API модель показывает лучшее качество. Ограничением является многостадийность и необходимость создания отдельной модели ранжирования.
Несмотря на кажущуюся простоту использования подходов на основе API, у них есть существенные недостатки: необходимость эвристик для правильной подачи данных в LLM. Так что существует желание сделать отдельную веб-модель, которую можно будет эффективно и несложно использовать.
Standalone-модели
Среди standalone-моделей также существует некоторая дихотомия на модели, работающие с изображениями, и на модели, работающие с текстом.
На данный момент одна из самых интересных работ по созданию модели, работающей на интерфейсе. Как упоминалось выше, при стандартном кодировании изображения и подаче его в текстовый декодер посредством эмбеддингов патчей (фактически токенов изображения) мы сталкиваемся с двумя фундаментальными ограничениями:
невозможно эффективно использовать высокое разрешение (забьётся контекст);
невозможно использовать энкодеры только маленького разрешения: на вход декодеру будет поступать малое количество полезной информации для низкоуровневых действий.
CogAgent решает обе проблемы посредством создания энкодера высокого разрешения и добавления его в модель посредством кросс-внимания (англ. cross-attention) со слоями декодера. Это позволяет эффективно использовать контекст и одновременно с этим обрабатывать изображения высокого разрешения. Архитектура модели представлена ниже.

Основным ограничением такого подхода является долгое предобучение модели на большом количестве данных, чтобы слои кросс-внимания правильно встроились в декодер. CogAgent показывает лучшее качество на Mind2Web из числа image-based моделей, а также хорошее качество на стандартных text-rich VQA-бенчмарках.
Можно сказать, что данная работа является CogAgent на минималках. В ней авторы используют стандартный подход в стиле LLaVA к подаче изображения в декодер (а если быть точнее, то используют уже готовую QWEN-VL), кодируют изображение среднего разрешения (448×448) и подают напрямую в декодер. Несмотря на простоту модельного подхода, авторы собирают качественный датасет, направленный на понимание скриншота и координат, что в конечном счета и даёт основной прирост. В него входят такие задачи, как text2point, point2text (где модель просят восстановить координаты по тексту и текст по координатам). Модель показывает не очень высокое качество на бенчмарке Mind2Web, но довольно хорошо справляется с задачей ScreenSpot, где нужно найти элемент и действие, а не понимать, на какой стадии выполнения задачи находится модель.
В данной работе используется довольно простая идея от схожих моделей для обработки скриншотов (pix2struct) и документов (UDOP). Нарезаем изображение с учётом отношения сторон (pix2struct patching), представляем патчи в виде эмбеддингов, конкатенируем с текстом и отправляем в мультимодальную T5. Модель учится на нескольких задачах восстановления структуры изображения на большом количестве разнообразных веб-данных и изображениях графиков. В результате модель показывает хорошее качество на классических DocVQA-бенчмарках и WebSRC.
Текстовая T5-модель, работающая на HTML, на данный момент имеет самые высокие метрики на бенчмарке Mind2Web. Из предположения о двух проблемах при работе с HTML: семантической сложностью соотношения тегов с текстом и необходимостью специфически понимать контекст (так как структура вложенная) — авторы применяют два основных подходы для их решения. Для решения первой проблемы авторы увеличивают длину спанов для денойзинга. Это позволяет модели лучше понимать структуру HTML. Для решения второй — комбинируют глобальное и локальное внимание для обработки вложенной структуры в HTML.
Cуществует ещё несколько работ, созданных для работы с веб-страницами, но они либо неинтересные (например, DualVCR) в рамках данной статьи, либо устарели и имеют преемников (Mind2Act → SeeAct).
Связанные и достойные упоминания
Работы выше создавались для взаимодействия с интерфейсным доменом, поэтому их важно было рассмотреть отдельно. Но помимо них есть ряд идей из других работ, достойных обсуждения.
Работа от Adept.ai (основатели — авторы статьи «Attention Is All You Need»). Изображения нарезаются на патчи, обрабатываются линейным слоем и отдаются на вход авторегрессионному декодеру. Основной плюс — можно использовать изображение любого разрешения.
LLaVA-Next (изначально LLaVA-1.6)
Продолжение линейки модели LLaVA, в этот раз нарезаем изображение на кропы (например, 800×800 → 672×672 → 4×(336×336)), и каждый из кропов обрабатываем моделью типа ViT. Модель не разрабатывалась непосредственно для веб-домена, но является важной вехой в обработки text-rich изображений.
Открытая текстовая модель для взаимодействия с браузером. Авторы используют Gemma-7b для непосредственных взаимодействий, а решают проблему зашумленности HTML-документа посредством RAG. В итоге решение работает, и довольно неплохо.
Фреймворк из последнего батча YC, в котором большое внимание уделяется возможности конфигурировать пайплайн. Основное достоинство работы — это грамотная инженерная смесь разных практик. Взаимодействие происходит благодаря комбинации из подходов image annotation и textual choices с многоэтапной обработкой. В конечном итоге фреймворк способен совершать сложные действия.
Closed-Source
Помимо большого количества академических и открытых работ, выделим несколько компаний, которые занимаются подобными задачами автоматизации. Несмотря на растущее число подобных стартапов, на текущий момент, хочется отметить несколько наиболее интересных. Также не включены стартапы, на продукты которых (на данный момент) нельзя посмотреть, например в виде демо-видео или небольшого приложения.
Adept.AI
Компания от авторов «Attention Is All You Need», подарила нам работу Fuyu-8B, а также несколько других открытых моделей для работы с интерфейсами, пока не релизили продукт, но обещает быть очень интересным.
HyperWrite.AI
Ребята делают «Self-Operating-Computer» и даже готовят свою модель. Помимо интересного демо, есть возможность записаться в waitlist. Есть обертки над разными LVLM-моделями и даже возможность поднять всё локально (тут конечно LLaVA-модели).
Induced.AI
Интересная работа с красивым демо, но с малым количеством технических деталей. По результатам сильно напоминает VimGPT, хотя авторы на своем дискорд сервере говорят, что решение построено на отдельных моделях и не привязано напрямую к GPT4V. Интересно посмотреть что получится у них дальше, компания уже подняла раунд у солидных инвесторов.
Проделанная работа
Как было сказано ранее, мы разработали модель на базе текстового декодера GigaChat и собрали бенчмарк. Далее расскажем подробнее о самой модели и бенчмарке, а также покажем демо взаимодействия текущей модели с реальным веб-интерфейсом.
Бенчмарк
Для разработки веб-моделей (как, в общем-то, и для разработки любого рода моделей машинного обучения) необходим валидационный сет. Задачи, решаемые в браузере, требуют оценивать точность взаимодействия и качество планирования, для этого мы разработали два способа оценки.
Первый наподобие ScreenSpot, в котором наибольшее внимание уделяется нахождению элемента взаимодействия и способа взаимодействия с ним. Данный сет был собран при помощи рендеринга скриншотов и выделения кликабельных элементов. Также данный бенчмарк можно улучшить посредством добавления человеческих описаний элементов (для перехода модели в домен естественного языка).
Для оценки возможности модели работать в веб-среде мы разработали фреймворк WebFollower для сбора offline multi-hop взаимодействия с сайтами. Основная идея заимствована из Mind2Web. Пример разметки сайта можно найти ниже:
В рамках данного демо было решено отключить возможность оставлять комментарии. Но в общем случае они предполагаются на каждом действии — такая возможность необходима для простого перехода из multi-hop в single-hop. В итоге мы собрали около 500 демонстраций на различных доменах и сайтах и в скором времени собираемся опубликовать их.
Мы планируем выложить часть бенчмарков в открытый доступ (некоторые из них можно будет найти в MERA) и опубликовать код для создания разметки своего сайта в формате Mind2Web.
Подход и сбор данных
Представляем разработанную модель. В процессе разработки мы опробовали несколько разных подходов. В данной статье решили представить метод с координатами как наиболее интересный для визуализации.
Для непосредственного обучения модели мы адаптировали подход из LLaVA и обучили модель на двух задачах: планирование взаимодействия с интерфейсом и нахождение подходящего элемента. Для улучшения понимания моделью высокого разрешения использовали подход с нарезкой изображения, как в LLaVA-Next.
Архитектура:
Во время обучения модели мы активно взаимодействовали с научной группой FusionBrain Института искусственного интеллекта AIRI под руководством Андрея Кузнецова, благодаря чему нам удалось добиться лучшего качества модели, за что им большое спасибо. Кстати ребята разрабатывают свой фреймворк для мультимодального обучения, а недавно у них состоялся релиз OmniFusion 1.1.
Для задачи ориентирования на веб-странице мы подготовили обучающий набор данных на понимание веб-страницы. Во многом опирались на работы коллег и опыт команды в разработке мультимодальных text-rich моделей. В результате были включены четыре задачи:
описание веб-элемента;
нахождение координат веб-элемента по описанию;
нахождение веб-элемента по координатам;
перевод изображения в HTML-код.
В будущем мы планируем расширить сет данными из классических OCR-задач, но на веб-домене, а также добавить задачи на суммаризацию информации. Подобную работу проделывали коллеги в статье Enhancing Vision-Language Pre-training with Rich Supervisions.
Для сбора скриншотов мы использовали playwright, где с каждого сайта собирали изображение, HTML и VDOM (DOM c координатами). После, изображения были нарезаны и отфильтрованы для грамотного соотношения с веб-элементами. Также данные такого формата можно использовать и для создания Set-of-Marks на изображении, что было сделано в части экспериментов.
Примеры обучающих данных:
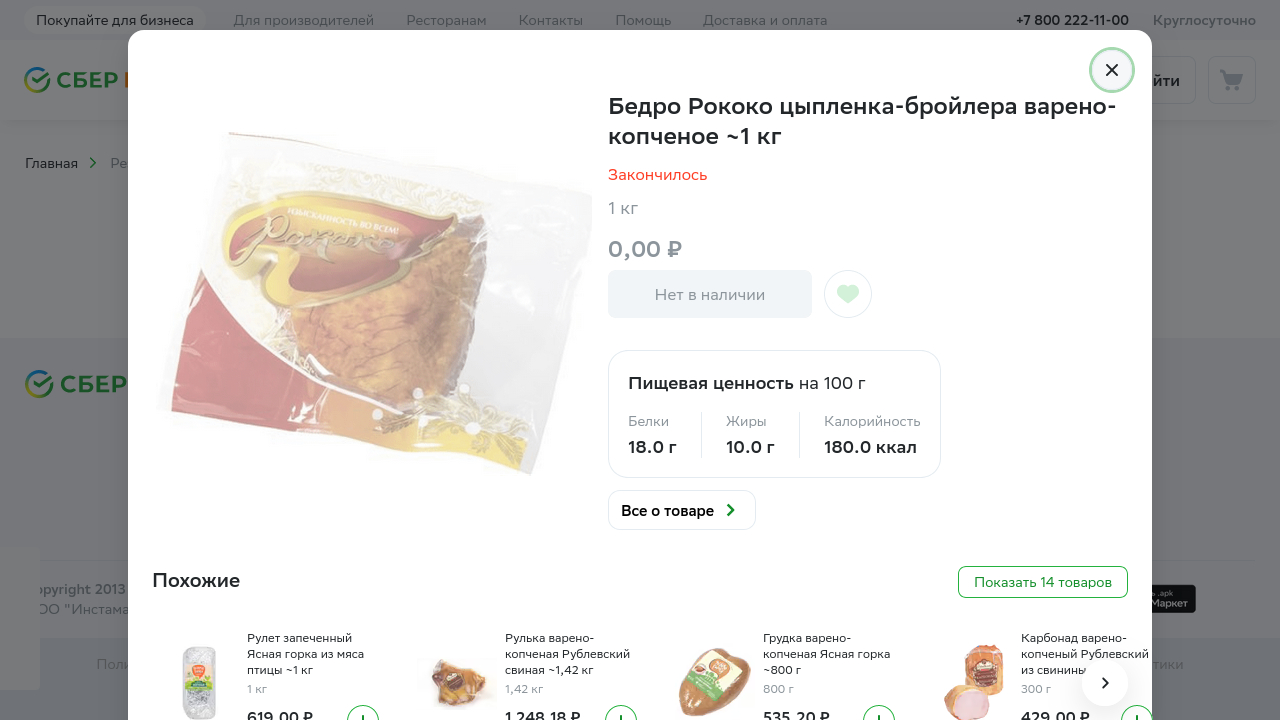
{
"tag_name": "button",
"text": "Все о товаре",
"bbox": {
"x": 608,
"y": 490,
"width": 148.16668701171875,
"height": 40
},
"center": {
"x": 682.0833435058594
"y": 510
}
"segment": 0
}
В итоге нам удалось добиться понимания моделью координат. Это позволило перейти к следующим этапам и опробовать несколько гипотез.
Навыки извлечения информации (как в стандартных экстрактивных VQA-задачах).
Навыки чтения веб-страницы.
Понимание координат элементов и умение соотнести информацию об элементе и изображении.
Далее пришло время инструктивных данных для планирования. Для этого мы использовали внутренние данные, собранные в формате Mind2Web, а также перевели Mind2Web в multi-hop парадигме. После обучения на итоговых инструкциях у модели появились базовые возможности к планированию и соотношению действий с необходимым элементом.
Демо работы итоговой модели:
Что дальше?
Качество модели складывается из многих составляющих. Из них можно выделить те, на которые мы сделаем упор в ближайшее время:
Качество извлечения информации из изображений. Это необходимо для лучшего нахождения элементов и out-of-domain возможностей модели.
Навыки модели к планированию. Для этого нужно собрать больше качественных инструктивных данных, которые описывают декомпозицию комплексной задачи на простые действия.
Возможности рефлексии, чтобы на каждом шаге взаимодействия модель смогла перестроить план, согласно текущему состоянию среды.
Помимо этого мы планируем опубликовать бенчмарк, сравнение разных моделей на нем, а также больше информации о нашей модели и процессе обучения. Для большего количества технических деталей следите за будущими новостями.
На связи с вами
Такжы мы сейчас активно нанимаем! Откликайтесь на вакансию для специалистов с уже с глубокой экспертизой или на позицию для стажеров, если вы начинаете свой путь в DS.
Статью подготовил: Георгий Бредис. Помогали в редакции: Даниил Водолазский, Дмитрий Головин, Максим Брегеда, Игорь Галицкий, Сергей Марков. Обложку подготовила: Александра Гаскевич. За помощь в технической части спасибо Елизавете Гончаровой.
Также напомню о том, что в Telegram-канале Salute AI мы с коллегами начали делиться наработками в области машинного обучения и другими рабочими моментами. А в соответствующем чатике Salute AI Community можно пообщаться с нами лично.
Комментарии (5)

dimnsk
16.04.2024 06:27Как автоматизирует рутинные задачи где прочитать в каком абзаце?

Natyren Автор
16.04.2024 06:27+1Про то как это происходит в проде, пока нигде, но мы работаем над этой задачей.
Про возможность использования языковых моделей для автоматизации можно прочитать в абзаце про базовую идею и далее.
ArtyomO
Сама по себе технология RPA + LLM очевидно хорошая и перспективная связка, но в итоге как пример этой технологии выбрана странная задача поиска на сайте с использованием стандартных фильтров, которая была решена вот уже более 20 лет назад. Достаточно в гугле набрать sberdevices qled 4k uhd и вот они ваши телевизоры. Всё же фишка RPA + LLM это не по сайтам лазить, а например выполнить запрос "Найди телевизор на sberdevice, чтобы подходил для ниши 100 на 150 см в нашей переговорной и создай заявку на нашем портале на его покупку". Ну или хотя бы "Собери все qled телевизоры менее 10 кг в Excel файл, укажи данные о количестве HDMI портов их должно быть более двух"
AigizK
Для себя увидел хороший кейс автоматизировать sbermarket. чтоб заранее система подготовила скрины со страницами товаров и в ТГ просто отправлял с запросом "Купить? Да/Нет". Пришел, сфоткал холодильник, отправил тг боту, через некоторое время минуты за 2-3 подтвердил все позиции из корзины и свободен. а то сейчас на это по 20-30 минут у жены уходит :(
Natyren Автор
В текущий момент ботлнеком для перехода к реальным продуктовым кейсам является возможность планирования. Мы работаем над тем чтобы модель лучше показывала себя на длинных цепочках рассуждения/планирования (с возможностью рефлексировать ответы), это позволит решать более сложные задачи, как, например, описанные вами.