

Источник изображения: ai.plainenglish.io
Stack Overflow, о котором, вероятно, знают на Хабре все, сейчас проигрывает неожиданному конкуренту — нейросетям. Пессимисты даже считают, что может завершиться без малого 20-летняя история проекта. Проблема в том, что все больше разработчиков предпочитают задавать свои вопросы не людям, а искусственному интеллекту. Так быстрее и во многих случаях эффективнее. Давайте разберемся, что там происходит.
Так что случилось?
То, что и говорится в лиде к статье. Проблемы Stack Overflow, крупнейшего форума для разработчиков программного обеспечения со всего мира, вполне реальны. Он очень быстро теряет популярность и посетителей. Причина проста — все больше программистов вместо него обращаются к генеративным нейросетям. Разработчик Теодор Смит (Theodore Smith), известный под псевдонимом hopeseekr, в своем профиле на GitHub привел статистику: количество новых вопросов на Stack Overflow сокращается с каждым месяцем.
Смит подсчитал, что если текущая тенденция сохранится, сайт может прекратить существование уже в течение нескольких месяцев. По его оценке, до полного закрытия Stack Overflow осталось менее года. Конечно, все это может быть простым нагнетанием обстановки, но анализ Смита выглядит вполне реалистично. Да и среди разработчиков действительно очень многие обращаются к нейросетям чаще, чем к сторонним ресурсам.
Но обратимся к той самой статистике, а она неутешительна для Stack Overflow. С момента появления ChatGPT, способной отвечать на вопросы практически любой тематики, количество новых вопросов на сайте упало на 76,5% за два года. Если в ноябре 2022 года пользователи задали около 108,57 тысяч вопросов, то в декабре 2024 года их число снизилось на 83 тысячи.
Согласно данным Смита, в марте 2023 года на Stack Overflow пользователи опубликовали 87,1 тысячи новых вопросов. Но ситуация крайне быстро изменилась, и не в пользу форума. Так, уже в марте 2024 года этот показатель упал до 58,8 тысячи — сокращение составило 32,5% за год. Тенденция продолжилась: в июне 2024 года количество вопросов упало на 34,8% по сравнению с июнем предыдущего года (с 63,8 до 41,6 тысячи), а в декабре 2024 года снижение достигло 40,2% год к году (с 42,7 до 25,6 тысячи). В общей сложности с марта 2023 года по декабрь 2024 года количество новых вопросов уменьшилось на 70,7%.
Эти цифры демонстрируют серьезный спад популярности ресурса, который на протяжении почти 17 лет был незаменимым инструментом для программистов со всего мира. Программисты находили ответы на самые сложные и заковыристые вопросы. Теперь же, по словам Теодора Смита, сайт по количеству новых вопросов откатился на уровень 16-летней давности, а это серьезная проблема.
«Сайт действительно умирает и устарел. В последний раз так мало вопросов было в мае 2009 года, всего через 10 месяцев после его запуска», — написал Смит.

Знал бы прикуп, жил бы в Сочи
Администрация самого ресурса всегда шла навстречу создателям нейросетей. Возможно, именно это тесное сотрудничество и оказалось тем критическим фактором, который повлиял на падение посещаемости Stack Overflow. Яркий пример совместной работы — договоренность между Stack Overflow с компанией OpenAI, создателем и оператором ChatGPT.

Источник: cnews.ru.
К слову, впервые подробно о падении популярности Stack Overflow рассказали еще в 2023 году. Тогда появился пост под названием The Fall of Stack Overflow («Падение Stack Overflow»). Вот график падения трафика из той статьи.
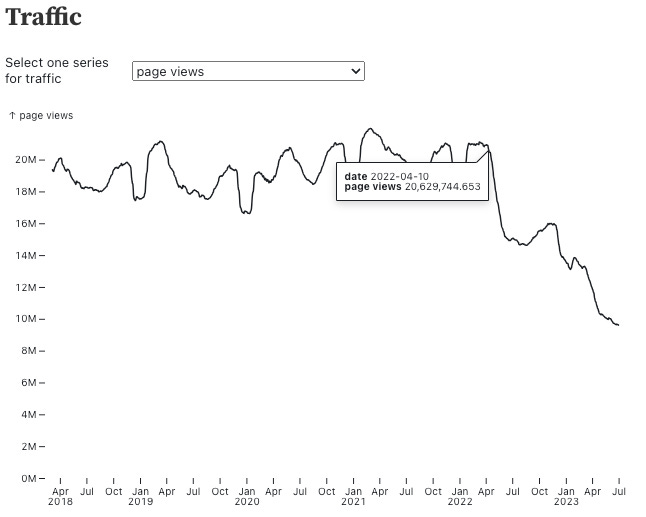
Источник: Хабр.
Автор поста объяснял падение популярности ресурса не только нейросетями, тогда они были далеко не так совершенны, как сейчас. Причина банальна — токсичная атмосфера, падение ресурса в выдаче Google и еще несколько факторов. Ну а сейчас, по мере совершенствования ChatGPT и других нейронок, разработчики предпочитают обращаться именно к ним. Вся эта совокупность факторов и повлияла на популярность ресурса.
Подробнее о нейронках
Возможно, то самое сотрудничество стало «соломинкой, сломавшей спину верблюду». Весной 2024 года стороны достигли соглашения, согласно которому ответы программистов, размещённые на страницах Stack Overflow, станут доступными для обучения ChatGPT. Цель — улучшить качество советов по разработке программного обеспечения, предоставляемых пользователям нейросети.
Согласно договору, OpenAI получит доступ ко всей базе Stack Overflow через интерфейс OverflowAPI. База знаний, накопленная за почти 17 лет существования портала, станет основой для дальнейшего обучения одной из крупнейших и известнейших нейросетей в мире. Примечательно, что на основе ChatGPT работает виртуальный помощник программиста Copilot, встроенный в GitHub — платформу, принадлежащую Microsoft. Напомним, Microsoft ранее инвестировала значительные средства в OpenAI.
Подобная стратегия не нова для Stack Overflow. Весной 2023 года, за год до подписания соглашения с OpenAI, руководство портала объявило о планах взимать плату с компаний, которые используют базу ответов для обучения своих нейросетей. Полученные средства планировалось направить на развитие проекта. Однако доступ к своей базе данных для владельцев ИИ полностью ограничивать не стали.
Что будет дальше — пока неясно. Возможно, ресурс вернет определенную часть посетителей благодаря снижению токсичности, а также появлению новых возможностей. Если нет — то форуму грозит постепенное падение популярности с угрозой полного закрытия в конечном итоге.
Комментарии (135)

Oceanshiver
12.01.2025 09:45Не понимаю - ведь на StackOverflow ответы, проверенные не одним и не двумя разрабами, о чем можно понять по комментариями и голосам за ответы, а ГПТ хрен пойми что тебе выдаст. Неужели не страшно это использовать?

UnknownUser
12.01.2025 09:45А почему должно быть страшно ? Берёшь и проверяешь. Тут есть хитрый лайфхак - не надо изменения делать сразу в продуктивной системе )))
Oceanshiver
12.01.2025 09:45Зависит от. Можно проверить, и оно мб даже заработает, но свалится на каком-то граничном кейсе, или не так на нем отработает. На SO можно почитать что пишут по этому поводу, какие-то советы и схожие кейсы, а ГПТ ультимативно отдаст какой-то вариант и всё - пользуйся если хочешь
UnknownUser
12.01.2025 09:45Дарю ещё один лайфхак - смотреть на получившийся код самому и понимать что он делает ))).
Если что, я уже пишу с помощью чатгпт простенькие скрипты для разных надобностей. Выходит сильно быстрее чем руками, но в итоге я всё равно смотрю что там написано и как работает прежде чем запускать, а также тестирую ( в общем, тут применим тот же самый подход, что и в обычной разработке руками).

rostislav-zp
12.01.2025 09:45Всегда скептически относился к решениям,которые нейросети дают.неделю пытался формулу массива специфическую сделать для google sheets.получил ответ от copilot,он был неверен,но сама логика в нем была правильной и помогла с ответом, и он заработал.но для этого,нужно не бездумно повторять все действия,а разбираться в вопросе.сам ответ натолкнул на то,что ему было около пяти лет.как раз тогда гугл изменил правила написания формул.будто ответ взят со старого форума.но при этом он явно не присутствовал на нем в том виде,котором был задан

Kanut
12.01.2025 09:45А к решениям которые вы находите где-то в сети, даже если и на stackoverflow, вы не относитесь скептически?

DarkPyDoor
12.01.2025 09:45Всегда пишите какую именно версию использовать, иначе он будет использовать ту которую чаще всего слышал, а именно старую версию google sheets :/

iskateli
12.01.2025 09:45но свалится на каком-то граничном кейсе
ну так и не надо бездумно использовать ответ, есть регрессионное тестирование и др. приёмы позволяющие минимизировать возможные ошибки при изменениях
Wesha
12.01.2025 09:45ну так и не надо бездумно использовать ответ,
в общем, нужно делать всё хорошее и не делать ничего плохого!

Hardcoin
12.01.2025 09:45Доверять чужим кускам кода, не понимая, что они делают, всегда странно. Откуда бы ты их не взял.
От ChatGPT можно получить более прицельный ответ под стиль проекта, даже переменные переименовывать не требуется, это проще и приятнее.

ingrain
12.01.2025 09:45Неужели не страшно
Статистика в данном случае как бы намекает
ведь на StackOverflow ответы, проверенные не одним и не двумя разрабами
Дело не в том, что такое SO и в чём его ценностт. А в том, что в таком виде он выглядит для возможного инвестора/покупателя неперспективным дигитал проектом. И скорее всего для владельцев тоже
Kanut
12.01.2025 09:45Проблема Stackoverflow что нужный тебе ответ там ещё надо найти. И это далеко не всегда удаётся сделать быстро. И допускаю даже что часто я нужный ответ просто не находил.
Плюс часто ответ раскидан по разным статьям на Stackoverflow. Или ещё где-то.
А ИИ это всё для тебя сами ищут, да ещё и обрабатывают. Не всегда хорошо,но в целом это часто быстрее чем искать самому.

gfiopl8
12.01.2025 09:45А даже если найдешь какое то решение не факт что поймешь как его применить. И вот тут гпт вообще бесценен, показываешь ему и он всегда делает вид что понимает.

smx_ha
12.01.2025 09:45Эх, вот если бы ИИ действительно искали, читали ответы на stackoveflow, и потом выдавали что то типа: "ну вот тут в статье в принципе есть что тебе надо". Но ведь нет, порой они сами всё придумывают.
Kanut
12.01.2025 09:45А кто мешает вам попросить ссылки на источники?
Wesha
12.01.2025 09:45Ну, например, то, что оно точно так же выдумывает источники?
Kanut
12.01.2025 09:45Ну так в чём проблема проверить существование источника и его содержание? Особенно если речь идёт о ссылке?
Wesha
12.01.2025 09:45Ну так в чём проблема проверить существование источника и его содержание?
Наверное, в том же, в чём проблема самому почитать источники и самому придумать решение?
Kanut
12.01.2025 09:45В том что использование ИИ, цитирую, "в целом часто быстрее чем искать самому."
Но если у вас много лишнего времени, то можете и сами все источники искать и фильтровать.

ropblha
12.01.2025 09:45Ну так работа с GPT - итеративный процесс, пока ты убедишь ее/его в том что тебе РЕАЛЬНО требуется. Я тут на днях пытался заставить GPT сделать фильтр верних частот на питоне, вроде простая вещь - он заюзал scipy - и надо же ...вместо АЧХ ФВЧ выдал АЧХ ФНЧ (я ему скармливал аналоговую передаточную функцию, что бы он сам ее как то там дискретизировал). Я ему пишу - дядя, ты дурак? Как у тебя АЧХ может заваливаться на высоких частотах, если я прошу ФВЧ. Он извиняется и продолжает строить дурку. В итоге я ему говорю - так, не используй библиотеку scipy, а давай сам разностную формулу для фильтра накидай согласно такому-то правилу - и только в таком варианте этот прощелыга сделал корректный фильтр.

Vytian
12.01.2025 09:45Гхмёпрст.
Вы точно уверены, что используете разумный подход? Даже ясно понимая, как применять filtfilt, можно настрелять себе в ноги до полной неработоспособности приложения. А уж БИХ-фильтр, сконструированный в лоб по неудачно заданной передаточной функции -- это просто гарантия артефактов, особенно на шумных данных.
Понятно, что иногда надо просто "давить верхи", но может просто старый добрый экспоненциальный фильтр.

playermet
12.01.2025 09:45ChatGPT идеально подходит, когда нужно получить направление, стартовую точку, или пример. Особенно когда вопрос такой специфичный, что его либо сложно сформулировать, либо понимаешь что ответа может не быть, или не найтись из-за слишком общих слов.
Например, недавно я изучал Java по учебнику Шилдта. В главе про лябмды было сказано, что обычно указывать тип параметров лямдбы не обязательно. Соответственно, мне стало интересно, а в каких случаях становится "необычно", и сходу сам пример придумать не смог. На SO самый заплюсованный и принятый ответ на этот вопрос говорит что никакой разницы вообще нет (хотя ниже его и поправляют). При том что это единственная релевантная страница в выдаче гугла и яндекса которую я нашел.
А вот ChatGPT мне сходу выдал пример где перегружены два метода которые могут принимать лямдбы с разными типами параметров. Соответственно без указания типов код даже не скомпилируется из-за неоднозначности.
И подобных случаев было множество.
Самая главная проблема которую я заметил - он плохо дружит с числами. Наверное в половине случаев он неверно указывал версию Java, в которой была добавлена какая-то фича. И ошибся когда назвал результат компиляции кода с арифметикой. В остальном он разносил поисковики с SO в пух и прах. Но главное, что с ним как с репетитором можно в реалтайме уточнить любую деталь, поспорить, попросить переформулировать, привести аналогию, спросить плюсы и минусы, альтернативные способы решения, и т.д. и т.п.
Ну а если не проверяя просить его писать жирные куски кода - тут ССЗБ.



mikhanoid
12.01.2025 09:45Мутная логика, что впрочем не удивительно, она всегда мутная в продвижении нейросетей. Считать надо не количество новых вопросов, а количество просмотров. За 17 лет SO накопил огромную базу решений, в большинстве случаев достаточно поискать, чтобы найти необходимое. Естественно, со временем количество новых вопросов будет уменьшаться.

justmara
12.01.2025 09:45ну так во второй части как раз про трафик, упавший в 2 раза ещё в 2023 году и явно обратно не отскочивший.
но вообще получается довольно дурная рекурсия: сети обучатся по SO -> юзеры обращаются к ним вместо SO -> информация на SO стремительно устаревает и дообучать сети нечем. все в проигрыше.
ingrain
12.01.2025 09:45дообучать сети нечем
Почему же нечем: ugc есть? — Есть. Значит есть пища для дообучения. А то, что цепочка становится сложнее — это эволюционный процесс, нормальное явление. Но вот как это они на самом деле будут решать, мне интересно узнать. Думаю, что тупо будут во все ide внедрять своих копилотов. Всё это будет жрать память, 128 Гб ОЗУ уже не будет хватать для нормальной работы девелопера. И всё пойдёт по той же спирали на следующий виток
Hardcoin
12.01.2025 09:45Сети дообучать по документации. Это текущее поколение обучали на миллионах однотипных примеров (если таковые нашлись в интернете), ситуация стремительно меняется.



adeshere
12.01.2025 09:45А как быть со сложными или редкими вопросами, для которых в базе нет готовых (или хотя бы близких) ответов? Что-то мне не хочется оказаться в мире, где все сервисы типа SO или Q&A вымерли...
ingrain
12.01.2025 09:45Никому не хочется. Но платить за so или q&a столько, сколько на самом деле это стоит — тоже никто не хочет. IT это убыточная история, чья-то мечта, ради которой выжимают соки со всего мира
gfiopl8
12.01.2025 09:45У хабра есть аналогичный ресурс - tos и там уже давно почти все вопросы можно было бы поделить на ноль с помощью гпт. Причем гпт не требуется оформлять пост по сложным правилам этого ресурса, можно даже скриншотами и голосовухами спрашивать, и в ответ получать нормальные ответы а не типичное людское фи.

adeshere
12.01.2025 09:45У хабра есть аналогичный ресурс - tos и там уже давно почти все вопросы можно было бы поделить на ноль с помощью гпт.
Вот только что постом выше я как раз намекал, что нет ;-)
Например, на мой недавний хабровопрос там отвечал целый консилиум высококлассных профи. После целой серии вопросов-ответов (история в два года длиной!) я наконец-то получил ключевой совет, который и
привел к решению
И Вы еще учтите, что половина нашей тогдашней переписки в архивированном вопросе (как он виден на данный момент) удалена. А другая часть раскидана по комментам к разным статьям. А без нее может и ключевого совета бы не было. А еще учтите, что нужный для обсуждения контекст (который я подготовил после первых наводящих вопросов и потом много раз дополнял, разбираясь с разными версиями причин глюка) в итоге вылился в 30 страниц текста-описания бага со вставками моего кода и дизассемблера (сейчас я этот файл с Я-диска убрал, но у меня в архивах он есть, - если кому-то интересен ретро-BDSM, могу опять выложить ;-)
Так что Ваша идея про деление на ноль с помощью гпт если и применима, то прежде всего к несложным запросам. А вот насчет менее тривиальных есть большие сомнения.
P.S. Но вообще было бы интересно задать тот мой вопрос гпт и глянуть, что ответит AI. Запретив ему при этом пользоваться материалами с Хабра ;-)


AVX
12.01.2025 09:45Пока не поздно, нужно выкачать весь SO, обязательно с комментариями. Уже было немало случаев, когда крупные порталы просто закрывались, информация была утеряна.

diversenok
12.01.2025 09:45Kiwix делает периодические оффлайн дампы Stack Overflow (а также Википедии и т.п.). Там и комментарии, и поиск работает.
https://kiwix.org/en/
https://library.kiwix.org/#lang=eng&category=stack_exchange&q=stack+overflow

xHeAVeNx
12.01.2025 09:45В web archive все сохранено. Но почему-то вопросы там не открываются... Смысл тогда в этих снимках, если можно только на страницу со списком вопросов глянуть. Или может я чего-то не понимаю.

DaneSoul
12.01.2025 09:45В web archive все сохранено. Но почему-то вопросы там не открываются...
Потому что web archive шикарная идея с плохо работающей реализацией.
Несколько раз пытался найти в нем информацию потерянную на сайтах и каждый раз сталкивался с тем, что индексные страницы сайтов есть на несколько уровней, а вот сами статьи с них не открываются.
В итоге, вроде как бэкап сайта есть, а на деле только шелуха от него...

Lord_of_Rings
12.01.2025 09:45Просто новички всякие глупые вопросы стали у ЧатГПТ задавать, а не в so бегать. "Падение" SO - чушь. На нём задавали и будут задавать вопросы, но не из разряда "погуглите за меня", а настоящие вопросы, которые будут нужны сотням людям спустя десятилетия. Даже если SO перейдёт в архивный режим им будут пользоваться тысячи и будут пользоваться очень долго.


begemot_cat
12.01.2025 09:45ну так поисковики тоже подвинутся. не только SO

Goron_Dekar
12.01.2025 09:45Продвинуться то они продвинулись, только вот чаще назад, а не вперёд.
Я перестал пользоваться гуглом по it вопросам. Или встроенный поиск SO, или чатгпт.
xHeAVeNx
12.01.2025 09:45Гугл и так выдает по it вопросам SO. Так еще и cyberforum, на котором бывает полезная инфа. Ну и бывают изредка другие полезные ответы. А остальное просто сайты-копии SO. Гуглом все-таки еще стоит пользоваться.
Goron_Dekar
12.01.2025 09:45Вот сейчас проверил. Запрос про обновление в винде, убивающее эксплорер.
Гугл вообще ничего внятного не ответил, SO поиск дал намёк, ChatGPT описал проблему и метод решения.


StunIsLove
12.01.2025 09:45Немного переживаю за будущие поколения разрабов. С одной стороны, процесс обучения и проблем с помощью нейросетей становится проще. С другой стороны, эта простота убивает гибкость мышления. Как минимум умение самостоятельно найти причину, следствие и решение. А это основополагающий навык в нашей профессии, я считаю

Flux
12.01.2025 09:45Зря переживаете, лучше по абсолютно тем же причинам радуйтесь за себя на их фоне, потому что рыночек порешает.
Kanut
12.01.2025 09:45Если они при этом будут дешевле вас и справляться с работой, то рыночек порешает совсем не их.
П.С. То есть скорее всего действительно останутся ниши для высокооплачиваемых специалистов, которые реально понимают что они делают. Но эти ниши могут оказаться не особо большими...
adeshere
12.01.2025 09:45останутся ниши для высокооплачиваемых специалистов, которые реально понимают что они делают
Так а откуда эти специалисты возьмутся, если на всех предыдущих уровнях будет рулить AI? Напрочь отбивая потребность думать (писать что-то) самостоятельно? Ибо любая такая попытка при работе с простыми задачами будет снижать эффективность, что повлечет проигрыш в конкуренции?
UPD: сомнительная аналогия
Еще вот что подумал. Промышленное производство дешевой и функциональной мебели не убило профессию краснодеревщиков - есть ниша эксклюзивной мебели, где их услуги востребованы. Или "деревенские" экопродукты vs сельхозфабрики. Вы можете представить себе аналогичную нишу для, например, сайтов? И соответствующую рекламу:
"Наш магазин написан вручную, без помощи гпт! Пользуйтесь продукцией кожаных!"
Kanut
12.01.2025 09:45Люди вполне себе любознательны. Может не все, но какая-то часть точно.
То есть даже если вы сейчас возьмёте специалистов, которые работа с высокоуровневыми ЯП, то какая-то небольшая часть из них всё равно разбирается и в том, что творится на более низких уровнях абстракций. Вплоть до электротехники-физики. Хотя необходимости в этом у них в общем-то нет.
adeshere
12.01.2025 09:45Люди вполне себе любознательны. Может не все, но какая-то часть точно.
Верно. Но меня пугают тенденции. Я знаю приличное количество таких "любознательных" (даже надеюсь, что сам немного такой). Но практически все они либо зрелого возраста, либо вообще из СССР с его творческими кружками и преподавателями "по призванию". Я сам в такой секции вырос. А когда повзрослел, десять лет на общественных началах вел такой же кружок для "своих и соседских" детей, пока они не выросли и не разъехались. Сейчас такие учителя и секции тоже, конечно остались... но вот технические, по моим впечатлениям, исчезают. А тех гениальных само-активных детей, которые собрались в нашем клубе в конце 90-х, уже днем с огнем не найдешь. У меня сейчас подрастает еще одна дочка, и я хотел бы с ней повторить прошлый опыт. Увы, вместо толпы желающих заниматься (как тогда) теперь вообще никого.
Kanut
12.01.2025 09:45Но практически все они либо зрелого возраста, либо вообще из СССР с его творческими кружками и преподавателями "по призванию"
Среди тех кого я знаю это не так.
Goron_Dekar
12.01.2025 09:45Сейчас есть хакспейсы, каналы на ютубе и прочий инфопоток для таких вот детей. И я знаю немало молодёжи, лет по 20-25, которые искренне интересуются и изучают. Правда, им сложнее в плане доверия к информации. Когда ты ходишь в кружок для тебя препод - 100% авторитет. Тут нет 100%.

Doctor_IT
12.01.2025 09:45Разрабатываю проект. Вообще перестал использовать Stackoverflow подобные сервисы. Нужно что-то — пишешь четвертой ChatGPT, получаешь ответ. Нужно протестировать? Ctrl-C + Ctrl-V — чекаешь. Нужно исправить ошибку? Пишешь ChatGPT, в чем ошибка, а он исправляет.
Единственная проблема — актуальность данных, на которых ChatGPT обучают. Например, недавно бился c API Yandex Map. Задаю ответ нейросети, а она выдает решение для API v2, когда как карты недавно обновились до v3. Впрочем, на форумах ответы на мои вопросы тоже не было, пришлось решать вопросы методом тыка:)

peacemakerv
12.01.2025 09:45Вот вы уже раньше большинства доказали, как будут деградировать разработчики. Использующие только сетки, которые тоже будут деградировать на деградированных источниках...

bak
12.01.2025 09:45"Разрабатываю проект. Вообще перестал писать код на ассемблере. Нужно что-то написать - пишу понятными командами на С, компилятор сам переводит в ассемблер"
"Вот вы уже раньше большинства доказали как будут деградировать разработчики..."playermet
12.01.2025 09:45Аналогия неверная, а проблема реальная. Если регулярно не напрягать мозг над решением задач, то и соответствующие навыки никогда не вырастуют. Только вырастет энциклопедический запас информации увиденный в ответах, что особой ценностью не обладает, как раз потому что это может быть получено из ChatGPT в любой момент. В англоязычном интернете уже дико негодуют, что дети всю домашку по математике через чатботы делают.
Ну и не нужно особо надеяться на самостоятельную любознательность. Капитализм любит решение проблем, а не любознательность. Если есть два равных специалиста, из которых один любознательный и получив готовый ответ подробно разбирается, а второй за это время просто решает больше задач, то удачи первому специалисту здесь и сейчас объяснить что он будет очень классным когда-то потом.
bak
12.01.2025 09:45"Если регулярно не напрягать мозг вручную разрабатывая в ассемблере и машинных кодах, то соответствующие навыки никогда и не вырастут."
Я не вижу вообще никакой проблемы. Программирование совершает очередную ступень эволюции, начиналось всё с разработки в машинных кодах, затем придумали ассемблер (ужас ужас, разучились руками команды транслироват), затем языки низкого уровня (ужас ужас, разучились руками писать на ассемблере), затем языки высокого (ужас ужас, разучились руками выделять / удалять память).
Теперь вот следующий этап, часть задач по кодированию можно выполнять с помощью промптов.
Навыки возникают от решения реальных задач. Как именно вы их будете решать - не важно. Если в какой-то момент большая часть условной веб разработки передет с условного js на условные gpt промты - все только выиграют.playermet
12.01.2025 09:45Навыки возникают от решения реальных задач.
Вот именно, а в предельном случае сам процесс решение задачи человеком полностью отсутствует. Он лишь вводит ее постановку, спущенную ему сверху в готовом виде, возможно даже целиком копирует. Особенно это касается детей, которым нужно выстроить все необходимые абстракции и нейронные связи.
все только выиграют
А вот это еще нужно будет доказать. Дешевизна и скорость разработки это не единственные факторы, и уж тем более не все от них выигрывают.
bak
12.01.2025 09:45Если у вас основная часть работы - кодирование постановки спущенной сверху, то у меня для вас плохие новости.
Обычно люди занимаются решением проблем. То что появился инструмент который часть решения автоматизирует не значит что люди отупеют. Просто проблемы станут масштабнее / сложнее.

Cheddar1789
12.01.2025 09:45Так ведь реально деграднули. Теперь программы занимают не килобайты, а гигабайты памяти, даже условно калькулятор. А раньше так нельзя было...

rPman
12.01.2025 09:45Проблема не в самих гигабайтах и неэффективных реализациях (типа что бы взять второй минимальный элемент, сначала сортируют весь массив, а потом берут второй) а в оверинженеринге. Задачи решают максимально сложным способом (который уже кто то реализовал и оформил как библиотеку), навернув поверх на пару порядков лишних зависимостей, которые по отдельности вроде бы нужны, но по факту - хлам.

Hivemaster
12.01.2025 09:45Я не вижу вообще никакой проблемы.
А я вижу, что программисты, писавшие когда-то на ассемблере, намного лучше работают и с самыми высокоуровневыми современными языками. Приложения жрут всё больше ресурсов и всё хуже работают в том числе потому, что пишут их всё более глупые программисты.

Alexey2005
12.01.2025 09:45Приложения жрут всё больше ресурсов и всё хуже работают потому, что инженеры наплодили целый зоопарк несовместимых устройств.
Легко было сделать калькулятор в 15 Кб, когда весь мир состоит исключительно из x86 под виндой. А теперь попробуйте написать маложрущую программу, которая успешно запустится на десктопных ARM, x86, на iPhone, на андроидофонах, на планшетах и чтоб работала на всём зоопарке ОС.
Всё в итоге сведётся к тому, что на асме вы будете под каждый девайс писать полностью с нуля.
Ресурсоёмкость программ - это плата за свободу, за отсутствие единого жёсткого стандарта оборудования и окружения.

sergey-gornostaev
12.01.2025 09:45Дело не только в этом. Я очень часто сталкиваюсь с программистами, которые даже не задумываются о производительности. Кто-то не хочет, а кто-то даже не понимает, что можно лучше при тех же трудозатратах. Люди "подключают left-pad", мажут рефлексии в три слоя, бомбят СУБД N+1 запросами и тому подобное. Цитата одного знакомого тимлида: "Ой, да кому нужна эта многопоточность?! Просто закажем серваков побольше." Тимлид важного проекта серьёзной организации, между прочим!

kma21
12.01.2025 09:45А теперь попробуйте написать маложрущую программу, которая успешно запустится на десктопных ARM, x86, на iPhone, на андроидофонах, на планшетах и чтоб работала на всём зоопарке ОС.
я конечно не разработчик, но у меня впечатление, что современная разработка взяла худшее из двух вариантов. жирные приложения, не работающие даже на разных версиях одной платформы. не то, чтобы на разных платформах.
Wesha
12.01.2025 09:45Приложения жрут всё больше ресурсов и всё хуже работают в том числе потому, что пишут их всё более глупые программисты.
Сейчас их ещё ИИ начнёт писать — и Вы будете с грустью вспоминать те времена...
Hardcoin
12.01.2025 09:45Сетки не будут деградировать. Никто не перейдет на сетку хуже текущей, зачем?

theonevolodya
12.01.2025 09:45Сетки деградируют. Старые можели будут содержатьуже неактуальную информацию. А новые будут обучатся на контенте, созданном нейросетями. Падает качество данных для обучения - падает качество сетки. И с этой проблемой уже сталкнулись

vilox
12.01.2025 09:45Если ChatGPT уничтожит источник своей заёмной мудрости, где она будет брать новую?
Flux
12.01.2025 09:45Вы сейчас предлагаете корпорациям принести прибыль и капитализацию в жертву общественному благу в долгосрочной перспективе?
Kanut
12.01.2025 09:45Будут платить специалистам за "мудрость" и обучение их ИИ. Вопрос только в том сколько таких специалистов будет нужно.
Wesha
12.01.2025 09:45И не повымрем ли мы к тому времени.
Учитель! — почтительно произнес маленький Ник.— Я выполнил всё, что вы велели, и пришел заниматься. Какой у нас будет сегодня урок?
— Последний, малыш,— Старый Тэн повернул к нему своё кресло — Сегодня у нас будет последний урок по истории цивилизации планеты Кальрун. А потому садись поближе и будь внимателен: я расскажу тебе... о шпаргалке. Помнишь ли ты, что это такое?
— «Шпаргалка,— охотно процитировал Ник,— это бумажка, на которой нерадивый ученик записывает то, что должен был запомнить, а потом подглядывает, отвечая учителю».
— Верно, малыш. Вначале это действительно был безобидный клочок бумаги — гармошкой, спиралькой, трубочкой... Многие поколения школьников и студентов Кальруна изощряли свою изобретательность, совершенствуя шпаргалку. Тогда это была больше игра, чем проступок. Игра в риск, в находчивость... Ведь чтобы разместить на крохотной площади максимум информации и незаметно для бдительных экзаменаторов прочесть её в нужный момент, требовались и талант миниатюриста, и навыки фокусника.
Игра кончилась, когда к созданию шпаргалок была привлечена фотография. Она не только решила задачу миниатюризации «тайных конспектов», но и позволила легко их размножать. В результате родилось новое ремесло — производство шпаргалок.
Некоторое время развитие шпаргалки шло по пути совершенствования маскировочных средств: её монтировали в авторучки, пуговицы, часы... Такие «шпоры» были очень популярны у школьников и не сразу исчезли даже с появлением электронной шпаргалки.
— Электронной? — удивился Ник.
— Да, малыш. Успехи микроэлектроники рано или поздно должны были натолкнуть «шпаргальщиков» на эту мысль. Правда, сначала это был всего лишь крохотный приёмник-передатчик в виде специальной ушной пробочки. Второй передатчик находился у подсказывающего. Схема, как видишь, была ещё довольно громоздкой и предполагала, что на десять лоботрясов найдется хотя бы один прилежный ученик, который станет за них думать. Но уже на следующем этапе «шпаргализации» образования передатчик подключили к стационарной ЭВМ, а со временем создали и отдельные микрокомпьютеры, которые каждый мог носить с собой замаскированными под привычные предметы.
Новые шпаргалки нашёптывали ответы с учетом новейших открытий в данной области знаний. Стоила такая шпаргалка денег немалых, но с её помощью можно было выдержать самый строгий экзамен. Целое поколение слушателей средних и высших учебных заведений Кальруна окончило их, не зная специальности.
Эти люди и после учёбы не расстались со своими шпаргалками. На заводах, в институтах, в лабораториях бывших студентов ждали новые испытания, и, чтоб хоть как-то их выдержать, нужны были «кибернетические шептуны». Так из учебных аудиторий «электронная шпаргалка» шагнула в жизнь. Подпольный промысел «шпаргальщиков» разрастался. Кальрунцам требовались универсальные шпаргалки, способные решать широкий круг задач. Электронщики и кибернетики, посвятившие себя этому бизнесу, создали и такие аппараты.
Легко получая дипломы и продвигаясь по службе, человек почти ничего не знал, поэтому многие и со шпаргалкой стали попадать в неловкое положение. Тогда «шпаргальщики» придумали звуковую приставку, которая в виде коронки крепилась на зуб и отвечала на вопросы голосом владельца,— тому достаточно было шевелить губами в такт словам.
Новинка разошлась мгновенно.
Поскольку кальрунцы желали выглядеть умными и компетентными не только на работе, то этими приставками стали пользоваться везде. С их помощью вели интеллектуальные беседы в гостях, в театрах, на улице. Со стороны казалось, что люди спорят, высказывают мнения, сомневаются, тогда как они просто открывали рот, а беседовали за них электронные шпаргалки.
Тщеславные родители поспешили приобрести «говорящие шпаргалки» своим неразумным чадам, и повсюду один за другим стали появляться шестилетние, пятилетние и даже трёхлетние вундеркинды. Несчастные дети с малых лет отучались мыслить — за них думал электронно-кибернетический мозг, упрятанный в висящую на шее безделушку. Мода на вундеркиндов распространилась по всему Кальруну, и вот уже вослед за поколением неучей росло поколение дебилов.
Все эти события начинали самым плачевным образом сказываться на самих электронике и кибернетике. Роботизированная промышленность остро нуждалась в специалистах, а их становилось всё меньше, да и те, последние, переключались на производство шпаргалок, потому что это было прибыльно.
Развитие электроники, как и других отраслей, остановилось. Действовало только подпольное шпаргалочное производство, но и оно скоро стало угасать...
— Почему? — спросил Ник.
— Потому что «шпаргальщики» старели и умирали, а новым было неоткуда браться. Да, «шпаргальщиков» становилось всё меньше, но они не бросали своё ужасное дело. Кальрунцы продолжали высокоинтеллектуальные разговоры, часто уже не понимая того, что раздавалось из их собственного рта. Иногда они забывали шевелить губами в такт словам, но, так как к этому времени все уже имели шпаргалки и знали их секрет, никого это не удивляло.
— А потом, учитель?.. Что было потом?
— Потом? — Старый Тэн нахмурил щётки бровей.— Потом умер последний из «шпаргальщиков». Делать шпаргалки стало некому. Но Кальрун был уже так наводнён ими, что никого это не огорчило. Люди продолжали, не разжимая зубов, беседовать, руководить и давать советы.
Но вот шпаргалки начали ломаться. Они ломались и раньше, но тогда их чинили. Теперь чинить их было некому, потому что никто уже толком не помнил, что такое электроника.
Поломка шпаргалки оборачивалась для её владельца настоящей катастрофой — он не мог больше принимать участие в умных беседах и вынужден был сторониться общества. Такие люди собирались в отдельные группы и общались мычанием. Остальные ещё разговаривали, но шпаргалки портились одна за другой, и постепенно мычащих стало больше, чем говорящих.
Давно были забыты ремёсла, утрачена письменность. Роботизированная промышленность ещё кое-как работала, обеспечивая кальрунцев пищей и одеждой,— ею управляли сложные электронно-кибернетические комплексы, запрограммированные на десятилетия. Но и они нуждались в уходе и ремонте.
Наконец застыло всё. Дольше всех функционировал наш Координационный Центр, но он не мог оживить умирающие заводы и только констатировал их остановку. Как умирал он сам, ты видел, малыш. Это и был конец цивилизации планеты Кальрун.
До сих пор нас было двое в этом мёртвом храме кибернетики, и я учил тебя всему, что знал. Но мне уже не подняться из операторского кресла — мой энергозапас на исходе. Так что скоро ты останешься один. Твоя урановая батарея протянет ещё лет десять, поэтому постарайся не пропасть раньше срока. Ещё раз проверь, хорошо ли заперты двери лифта. Бойся сырости, и пока лето, отыщи и заделай все щели на этаже. Почаще меняй смазку в суставах — в шестой лаборатории её целый бак. Там же батарейки для фонаря, на большом стеллаже вни...— старый робот умолк на полуслове, и голова его медленно опустилась на стальную грудь.
— Учитель!.. Учитель!!! — Маленький Ник всеми шестью манипуляторами тряс старика Тэна, пока не понял, что тот уже не ответит. Постояв возле неподвижного гиганта, маленький робот отправился выполнять его последние наставления.
В коридоре было выбито стекло. Прежде чем закрыть отверстие снятым с пола пластиком, робот выглянул наружу.
Внизу, в зелёном колодце двора, на разорванном буйной порослью асфальте возились три грязных, волосатых человека. Двое вертели палочку в углублении деревянной колоды, а третий что-то туда подкладывал. Скоро над колодой закурился сизый дымок. Люди издали торжествующий вопль.
Рождалось новое знание.
— Александр Лесь. "Шпаргалка". "Пионер" №8 за 1990 год.

AngusMetall
12.01.2025 09:45Так вся польза от gpt в том, что начиная с каких-то объёмов оно само генерирует мудрость. По крайней мере есть достаточно количество исследований, которое это утверждают.


oYASo
12.01.2025 09:45Проблема-то глобальнее.
Во-первых, сломался поиск. Гуглом сейчас искать что-то кратно тяжелее, чем, скажем, 10 лет назад. Попадается либо вода, либо SEO-говно, либо ИИ-контент. Тот же медиум в поисковой выдачи в основном перечисленное выше и выдает. За крайне редким исключением, если чего-то нет на SO, то и дальше искать смысла нет. В этом плане Хабр еще неплохо держится, даже с учетом обилия корпоративных блогов и их статей уровня "мы перешли с Jira на МойБизнесТрекер".
Во-вторых, качество ответов ChatGPT стало действительно довольно высоким. Если нужно решить бизнес-задачу, то с ней намного быстрее приходишь к работающему решению, чем если искать это все в поисковике.
В-третьих, SO - это скорее коллекция типичных ответов к типичным проблемам. По действительно сложным вопросам мало кто может ответить (и мало кто их задает). Именно поэтому существует либо коммерческая поддержка какие-то продуктов, либо общение с разработчиками (но это в основном про open source и не про SO, а про местные форумы/борды). И вот типичных ответов как будто уже достаточно. И их просто научились воспроизводить нейросетки.
В-четвертых, люди токсичны. Их тоже можно понять, когда в один день по 10 раз задается один и тот же вопрос. И тут как раз бизнес-проблема: клиент хочет получить ответ на вопрос, а не разбираться в правилах форума, оформления поста, поиска дубликатов и т.д.; а эксперт хочет какого-то разнообразия, а не строчить одно и тоже как дятел. И вот SO не предлагает для этого никаких решений, а ChatGPT предлагает. И это большой промах SO, потому что они могли бы сделать своего AI по SO, который бы и сам ответы давал, и посты искал и, если нужно было бы, помогал оформлять пост. А так они все это просрали, и теперь не очень понятно, что может исправить ситуацию (ну как будто бы ничего).
Но, народ, это же просто очередная трансформация/революция. Вот автомобили заменили лошадей. А компьютеры заменили счетные машины. Телефоны для 99% кейсов заменили фотоаппараты и т.д. Так что норм, посмотрим на новый интернет, будем ностальгировать по старому, всё как во все времена.

TheDreamsWind
12.01.2025 09:45В-третьих, SO - это скорее коллекция типичных ответов к типичным проблемам
Рекомендую к ознакомлению тэг language-lawyer на SO. Там и вопросы нетипичные и ChatGPT на них по моему опыту никогда ответить не в состоянии
oYASo
12.01.2025 09:45Я вбил этот тег, и последние вопросы на момент написания была там были такие:
`sizeof ((struct X *)0)->field` -- conformance in C1999 specifically?
Copying virtual base class results in losing shared_ptr owned object
Using the address of a dangling variable without dereferencing it
и т.д. Вопросы не выглядят как сложные.
Мой опыт подсказывает, что по действительно сложным вопросам, мало кто может помочь. Зачастую даже на форумах/чатах разработчиков. Безусловно, шанс получить качественный ответ на сложный вопрос на SO сильно выше, чем у ChatGPT. Но мой поинт был в том, что не так-то много сложных вопросов реально задают. И текущая тенденция только подтверждает этот тезис.
JBFW
Ну так-то это разного уровня вещи.
Если мне надо пример скрипта, который я не помню и искать лень - я спрошу у ЧатГПТ, это быстрее.
Если мне надо найти решение, которое может быть неоднозначным - лучше посмотрю на SO, потому что там можно найти ответ даже в чужом вопросе, не говоря уже о предлагаемых вариантах решения.
С точки зрения SO посещаемость падает, количество мусорных вопросов типа "напомни пример SetTimeout" резко уменьшается.