
Это был AlphaGo от компании Google
Подразделение DeepMind компании Google заявило о том, что искусственный интеллект компании смог победить европейского чемпиона по настольной игре го. Система AlphaGo обыграла человека в 5 из 5 игр. До этого го была одной из немногих логических игр, профессиональные игроки в которую выигрывали у компьютеров.
Одним из наглядных показателей развития искусственного интеллекта является победа в логических играх. ИИ может обыграть чемпиона по какой-либо логической игре, что продемонстрирует, что алгоритм умеет решать задачу лучше человека. С годами число покорённых игр растёт: сдались и шашки, и шахматы. В 1996 году алгоритм впервые выиграл у лучшего игрока в шахматы: это был поединок компьютера Deep Blue против Каспарова. А уже в 2005 году человек в последний раз выиграл у лучшего алгоритма. С тех пор компьютерные программы могут обыграть любого игрока в шахматы. Поддаются и другие игры: айбиэмовский Watson играл и выигрывал в Jeopardy, а в 2014 году искусственный интеллект поискового гиганта Google самостоятельно освоил 49 старых аркадных игр Atari.
Но некоторые игры ещё не покорены. Одной из невзятых долгое время оставалась го. Это настольная игра, зародившаяся в Древнем Китае несколько тысяч лет назад. Прямоугольная доска 19?19 линий заполняется чёрными и белыми камнями. Перед каждым из игроков стоит задача отгородить на игровой доске камнями территорию большего размера, чем противник. Игра обладает несколькими правилами, которые осложняли создание эффективной системы искусственного интеллекта для победы над человеком. К примеру, возможных позиций камней на стандартной доске более, чем в гугол (10100) раз больше, чем в шахматах. Число возможных позиций больше, чем атомов во Вселенной. Просто так просчитать все ходы невозможно, и пока что лучшие компьютерные системы играют на уровне любителей.
Многие ходы в го диктуются простой интуицией, а подобное трудно уложить в алгоритм. Именно эта сложность привлекает внимание специалистов по искусственному интеллекту. DeepMind — это разработчик систем искусственного интеллекта, которого компания Google приобрела в 2014 году. В DeepMind смогли создать программное обеспечение, которое в состоянии обыграть чемпионов.
Составление дерева поиска здесь не подходит, поэтому была создана система AlphaGo. Она основана на поиске Монте-Карло и глубоких нейросетях. Нейросети пропускают описание состояния доски го через 12 различных слоёв, состоящих из миллионов нейроподобных соединений. Одна из сетей, «сеть политики», выбирает следующий ход. Другая, «сеть ценности», предсказывает победителя.
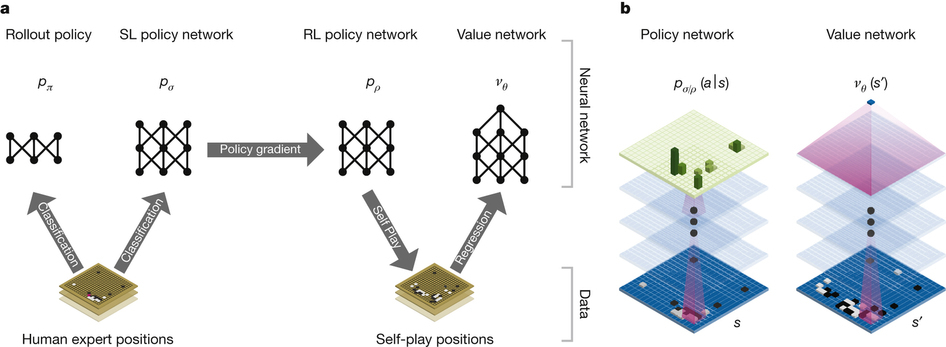
Нейросеть обучали на 30 млн ходов партий реальных людей. Был достигнут результат корректного предсказания следующего хода в 57 % случаев. До AlphaGo лучший результат составлял 44 %. Но целью была победа, а не просто подражание человеку. AlphaGo научилась этому путём тысяч партий между собственными нейросетями и с помощью улучшения соединений в процессе обучения с подкреплением. При этом весь процесс требовал немалой вычислительной мощи, поэтому всё запускалось в облаке Google Cloud Platform.
Сначала полученный продукт протестировали с другими лучшими решениями. AlphaGo выиграла 499 матчей из 500. Затем были приглашёны судья из Британской федерации го, редактор журнала Nature и трёхкратный чемпион Европы Фань Хуэй. Этот профессиональный игрок занимается азиатской настольной игрой го с 12 лет. Матч за закрытыми дверями проводился в лондонском офисе Google в октябре прошлого года.
Чтобы запустить алгоритм, потребовался вычислительный кластер из 170 видеокарт и 1200 процессоров (вероятно, имелись в виду отдельные ядра). Фань с удивлением обнаружил, что он проиграл компьютеру в первой игре. Чемпион списал поражение на собственный неагрессивный стиль. Он посчитал, что это была лишь разминка, и начал играть агрессивнее. Но Фань проиграл все из четырёх последующих партий. Алгоритм AlphaGo выиграл в пяти из пяти игр.
Как говорят в Google, это первый случай, когда программа смогла победить профессионального игрока в го. Следует отметить, что Фэнь имеет титул чемпиона 2013, 2014 и 2015 годов только в Европе, где уровень владения го не очень высок. Следующим логическим шагом является матч в Сеуле в марте против легендарного корейского го-профессионала Ли Седоля — лучшего игрока в го за последнее десятилетие. Уровень игры этого человека будет гораздо выше. Для этого матча производительность системы улучшат, чтобы её можно было запускать на более скромном оборудовании.
В го играют десятки миллионов человек по всему миру. Постепенное покорение ещё одной логической игры — это важно. Но также интересно, что AlphaGo не была создана с помощью заданных вручную правил. Выигрывать помогло машинное обучение.
В Google надеются использовать полученный опыт для решения проблем реального мира. Факт использования методов общего назначения означает, что подобные алгоритмы смогут найти применение во многих системах: от климатического моделирования и анализа заболеваний до торговли акциями на бирже.
В среду результаты исследования были опубликованы в научном журнале Nature. Запись ходов игр с Фэнем можно скачать с сайта DeepMind, также их можно посмотреть в веб-виджете.
Подобной разработкой занимаются и в Facebook. Марк Цукерберг сообщил в среду, что его исследователи близки к покорению китайской игры. Цукерберг в буквальном смысле пристально следит за процессом разработки: автор проекта сидит в шести метрах от стола исполнительного директора Facebook.
Исследование Facebook: arXiv:1511.06410 [cs.LG]
Комментарии (98)

yse
28.01.2016 08:36+16Заголовок слегка желтушный. алгоритм победил чемпиона Европы. Стоило бы прояснить, как проводятся европейские чемпионаты. В них ещё играют азиаты. Так вот чемпионом Европы считается тот, кто в списке победителей первый Европеец. То есть сильнейший игрок Европы — это средний, даже начальный, профессионал в Азии. Смотрим дан Фань Хуэя — 2 профессиональный дан. А у Ли Сидоля — 9 дан. 2 и 9 дан — это две разные планеты.

Baron_aka_avs
28.01.2016 09:13-2Вопрос времени на обучение.

Nerevar_soul
28.01.2016 10:12+3Не согласен. И до этого были программы обыгрывающие сильных европейских любителей. Теперь обыгран сильнейший, но ему очень далеко даже до средних по уровню профи, не говоря уже о топ уровне. Так что это время может растянуться на довольно долгий срок.
Nerevar_soul
28.01.2016 10:00Ну не в данах конечно дело, но уровень Фана конечно не сопоставим с уровнем большинства азиатских профи. У него уровень сильного не азиатского любителя. Будет интересно посмотреть на матчи с Ли Седолем или еще с кем из топ игроков. Ли кстати сейчас не самый сильный в мире, но по известность/сила он конечно лучший выбор.

Kain_Haart
28.01.2016 11:40Вики пишет что 2p
Nerevar_soul
28.01.2016 12:01Дело же не в дане, а уровне игры. Его уровень не сравним с уровнем тех профи кто сейчас активно играет в турнирах.
Сейчас бы он наверняка бы не смог пройти отбор на профи, причем дело не только в возрасте, но и в том что уровень игроков Го в Китае очень сильно вырос за последнее время.
И даны могут присваивать не только за спортивные достижения, а например еще за популязацию Го.ankh1989
28.01.2016 20:212p это где то уровень корейского пацана 11-ти лет который решил, что будет всю жизнь заниматься этой игрой. Другое дело, что 2p это даже теоретически недостижимый уровень для большинства любителей го.



xma
28.01.2016 09:15по сути нейросеть вычисляет определённые правила которые приводят к победе в изучаемых её партиях го. поскольку связей миллионы, то правила эти вычленить (человеку из нейросети) очень сложно либо вообще невозможно (тем более, за разумный промежуток времени). в связи с этим можно говорить о достижении начала точки технологической сингулярности, когда понимание (человеческое) перестаёт успевать за прогрессом.
vadi_polu
28.01.2016 10:13Технологическая сингулярность — достаточно размытый термин. Да и система всё еще написана человеком и устройство ее понятно.
Для меня сингулярность наступит, когда созданное человеком создаст что-то, что ни один человек не сможет понять.xma
28.01.2016 10:24Да и система всё еще написана человеком и устройство ее понятно.
ну так и устройство искусственного интеллекта будет написано человеком и будет ему понятно.
Для меня сингулярность наступит, когда созданное человеком создаст что-то, что ни один человек не сможет понять.
ну так данная нейросеть создаёт последовательность ходов которая ведёт к победе (в го), которую человек (ни один) не в состоянии понять.
eugzol
28.01.2016 12:07Вы используете, на мой взгляд, какое-то бессмысленное значение слово «понимать». Если человек способен обыграть машину, то разумно было бы сказать наоборот — его понимание игры более глубокое!
Ну или с другой стороны. Способен ли мастер го понять сам себя? Наверное, если долго будет разбираться, будет способен — но основные «вычисления» он наверняка делает вне сознания — ментальные процессы идут, получается, в свёрнутом/скрытом виде, недоступном без специальных усилий для рефлексии.
Так что скорее имело бы смысл говорить о том, способна ли «машина» эффективнее _обучаться_, а не способна ли она иметь некую особенно вычурную внутреннюю структуру.xma
28.01.2016 12:29Если человек способен обыграть машину, то разумно было бы сказать наоборот — его понимание игры более глубокое!
так человек и не способен
Способен ли мастер го понять сам себя? Наверное, если долго будет разбираться, будет способен
далеко не факт, иначе давно бы раскусили оптимальный (-ые) алгоритм (-ы) игры (в го) и не понадобилась бы тогда нейросеть.
Так что скорее имело бы смысл говорить о том, способна ли «машина» эффективнее _обучаться_, а не способна ли она иметь некую особенно вычурную внутреннюю структуру.
ну так вся фишка в том, что чтобы обыграть машину нужно вычленить все закономерности которые она нашла в уже сыгранных партиях (в го) и иметь возможность применять их. а закономерностей этих могут быть миллионы, что человеческий разум не в силах постичь.
а чтобы написать более эффективную и «умную» нейросеть, нужны инструменты для анализа находимых нейросетями решений. при этом непосредственный анализ самих этих решений навсегда останется за гранью человеческого понимания (в виду их огромного количества).
аналогично, если программы научат находить новые сложные математические доказательства, то возможно результат такой их деятельности будет не доступен для анализа (/разбора) человеком ввиду чрезмерного их объёма. и начало таких решений уже положено этой нейросетью для игры в го, как бы вам не хотелось в это верить.eugzol
28.01.2016 12:44+1> так человек и не способен
Ну, посмотрим, судя по тому, что не сразу бросились на азиатах тестировать, уверенности в этом нет :)
> далеко не факт, иначе давно бы раскусили оптимальный (-ые) алгоритм (-ы) игры (в го) и не понадобилась бы тогда нейросеть.
Ну т.е. отсутствие алгоритма (полной рефлексии) при наличествующей способности к эффективной деятельности не является чем-то необычным и не является свидетельством неких особых свойств/сложности этой деятельности. Поэтому не понятно, почему надо беспокоиться о том, чтобы машина превзошла человека именно в способности генерировать такие схемы поведения, которые сложно рефлексировать — люди и сами по себе с этим прекрасно справляются!
> ну так вся фишка в том, что чтобы обыграть машину нужно вычленить все закономерности которые она нашла в уже сыгранных партиях (в го) и иметь возможность применять их. а закономерностей этих могут быть миллионы, что человеческий разум не в силах постичь.
Это очень сомнительный тезис, хотя бы по тому, что до машины эти закономерности уже нашли откуда-то люди, сыгравшие те самые партии, на которых машина обучалась. То есть скорее уместно обратное утверждение: это машине, пока что, нужно проанализировать все закономерности, которые люди до неё выявили. А человеку машина вовсе не нужна для эффективного обучения.
И я совсем не понимаю некоей мистификации феномена того, что сложный навык зачастую не поддаётся полной рефлексии — это совершенно обыденная вещь. Например, вы не сможете написать алгоритм вашей ходьбы, однако делаете это без каких-либо проблем. Таким образом, если машина будет иметь внутреннюю структуру, которая будет непостижима человеком, это не будет доказательством никаких свойств полезности или некоей эстетической ээ «совершенности» такой машины.
> а чтобы написать более эффективную и «умную» нейросеть, нужны инструменты для анализа находимых нейросетями решений. при этом непосредственный анализ самих этих решений навсегда останется за гранью человеческого понимания (в виду их огромного количества).
Это противоречит конкретному примеру с Го. Отдельные люди способны проанализировать партии Го своих соперников, получив на выходе алгоритм, который гораздо лучше того, что могут (пока что) современные машины.
Опять же, если сравниваем человека и машину — а почему партия, которую ведёт машина, должна в анализе как-то отличаться от партий, которую ведёт человек?
Если некоему мастеру Го подсунуть некую сложную партию, которую он сочтёт полезным проанализировать, то ему ведь будет совершенно всё равно, кто там её играл: дядя Ли с соседней улицы, ИИ на квантовом компьютере, или рептилоиды. Игра-то такая же будет.
Если человек способен проанализировать партию другого человека, то уж конечно он будет способен и проанализировать партию ИИ. Пока что. Пока не сделали ИИ, который играет на недостижимом для человека уровне.
> аналогично, если программы научат находить новые сложные математические доказательства, то возможно результат такой их деятельности будет не доступен для анализа (/разбора) человеком ввиду чрезмерного их объёма. и начало таких решений уже положено этой нейросетью для игры в го, как бы вам не хотелось в это верить.
Да это вам хочется верить в какую-то чудодейственность критерия «понимание».
Почитайте доказательство великой теоремы Ферма, а затем расскажите, насколько хорошо вы его поняли. Я уверен, даже рецензенты журнала, в которых оно было изначально отправлено, не очень-то в целом его поняли, хотя смогли проследить и верифицировать логику каждого отдельного шага.
Так что очередной натянутый пример, основанный на игнорировании того простого факта, что люди и без всяких машин сами не способны понимать, что на самом деле они делают, как только дело касается вещей чуть более сложных чем элементарные.xma
28.01.2016 13:08-1> Это очень сомнительный тезис, хотя бы по тому, что до машины эти закономерности уже нашли откуда-то
> люди, сыгравшие те самые партии, на которых машина обучалась.
ну так раз люди (в частности чемпион мира по го) поголовно проигрывают машине, то значит нихера они не нашли. к тому же люди могли чисто случайно играть (выигрывать).
> Например, вы не сможете написать алгоритм вашей ходьбы, однако делаете это без каких-либо проблем
гуглите роботы Petman и Atlas от Boston Dynamics, вполне себе ходят на заложенных алгоритмах
>Таким образом, если машина будет иметь внутреннюю структуру, которая будет непостижима человеком, >это не будет доказательством никаких свойств полезности или некоей эстетической ээ «совершенности» >такой машины.
про это речи и не идёт
>Это противоречит конкретному примеру с Го. Отдельные люди способны проанализировать партии Го >своих соперников, получив на выходе алгоритм, который гораздо лучше того, что могут (пока что) >современные машины.
пруф в студию, пока что речь шла в статье о том что признанный лучший игрок мира в го не смог ни разу обыграть машину.
>Пока не сделали ИИ, который играет на недостижимом для человека уровне.
вы статью вообще читали? «Алгоритм AlphaGo выиграл в пяти из пяти игр» у «трёхкратный чемпион Европы Фань Хуэй»eugzol
28.01.2016 13:12> ну так раз люди (в частности чемпион мира по го) поголовно проигрывают машине
Так в комментариях пишут, что не проигрывают.
> гуглите роботы Petman и Atlas от Boston Dynamics, вполне себе ходят на заложенных алгоритмах
При этом любой ребёнок может это делать без всякой рефлексии. И у него это получается как минимум не хуже :) Уж про акробатические трюки взрослых спортсменов и не говорю :)
> пруф в студию, пока что речь шла в статье о том что признанный лучший игрок мира в го не смог ни разу обыграть машину.
Лучший игрок среди европейцев. Полистайте комменты, пишут, что это игра на уровне рядового середнячка из Азии.
> вы статью вообще читали? «Алгоритм AlphaGo выиграл в пяти из пяти игр» у «трёхкратный чемпион Европы Фань Хуэй»
Вы так загорелись идеями ИИ, что ухватив некие подходящие под шаблон ключевые фразы уже никакой сопровождающей их информацией из контекста вокруг не интересуетесь? :)xma
28.01.2016 13:30>Так в комментариях пишут, что не проигрывают.
из статьи «Сначала полученный продукт протестировали с другими лучшими решениями. AlphaGo выиграла 499 матчей из 500.»
что как бы намекает на большую оптимальность полученного решения, а также на то что оно всё же находит определённые закономерности (при том что качество этих закономерностей выше чем явно заданных в конкурирующих решениях, т.е. по сути это означает что программа ии нашла больше закономерностей чем смогли вычленить люди). конечно их может оказаться недостаточно чтобы сразить лучших игроков мира, но это не значит что у последних есть чёткое понимание алгоритмов успешной игры (если они их конечно не скрывают), иначе бы их давно внедрили в явно заданном виде в соответствующие программы (без нейросетей) и стали бы эти программы столь же давно лучшими в мире игроками по го, чего мы не наблюдаем.eugzol
28.01.2016 13:36> что как бы намекает на большую оптимальность полученного решения, а также на то что оно всё же находит определённые закономерности (при том что качество этих закономерностей выше чем явно заданных в конкурирующих решениях, т.е. по сути это означает что программа ии нашла больше закономерностей чем смогли вычленить люди)
А, кажется я вас понял. Но утверждение не корректно. Правильное было бы таким: машина ИСПОЛЬЗУЕТ больше закономерностей, чем люди РЕФЛЕКСИРУЮТ (не доказано, но вероятно). Ну т.е. вы смешали использование (комптенецию) и рефлексию («понимание»). Надо сравнивать использование с использованием, а рефлексию с рефлексией.
Тогда такие корректные пары сравнений получаются:
— программисты «обычного порошка», пардон, программ для Го — рефлексируют Го лучше некоторых мастеров (не доказано, но возможно)
— люди используют БОЛЬШЕ закономерностей, чем машины (пока что — поскольку пока что обыгрывают машин)
— люди РЕФЛЕКСИРУЮТ больше закономерностей, чем машины (машины вообще не рефлексируют — в т.ч. нет доказательств, что нейросеть что-то там рефлексирует)
> конечно их может оказаться недостаточно чтобы сразить лучших игроков мира, но это не значит что у последних есть чёткое понимание алгоритмов успешной игры (если они их конечно не скрывают), иначе бы их давно внедрили в явно заданном виде в соответствующие программы (без нейросетей) и стали бы эти программы столь же давно лучшими в мире игроками по го, чего мы не наблюдаем.
Это, несомненно, верный тезис.

KvanTTT
28.01.2016 13:57ну так раз люди (в частности чемпион мира по го) поголовно проигрывают машине, то значит нихера они не нашли. к тому же люди могли чисто случайно играть (выигрывать).
Вы не поверите, но машина тоже может случайно выиграть (при расчете используется генератор случайных чисел).xma
28.01.2016 14:16+1>Вы не поверите, но машина тоже может случайно выиграть (при расчете используется генератор >случайных чисел).
т.е. 499 побед из 500 партий с лучшими конкурирующими решениями — это случайность? чё ж «случайно» не выигрывают конкурирующие решения? может просто побаще генератор случайных чисел сделать порекомендуете им? :D

Nulliusinverba
28.01.2016 12:35Для меня сингулярность наступит, когда созданное человеком создаст что-то, что ни один человек не сможет понять.
Что это значит? Если не сможет понять, то как мы поймем, что это нечто осмысленное и логичное, но при этом невероятно сложное, но не наоборот — такое же сложное, но бессмысленное и нелогичное? Вы же подспудно подразумеваете, что это нечто создаст что-то осмысленное и логичное, что трудно (но не невозможно) будет понять; иначе утверждение теряет смысл.
А если мы сможем отличить одно от другого, тогда и не будет никакой сингулярности.xma
28.01.2016 12:46если результат можно будет проверить экспериментально, но доказательство будет в недоступном для человечества объёме, то вполне можно будет говорить об технологической сингулярности.
например если в качестве результата ии представит алгоритм быстрой факторизации числа или получения простых чисел по их порядковому номеру.Nulliusinverba
28.01.2016 13:16будет в недоступном для человечества объёме
это сколько?
если мы не можем проверить доказательство, то тогда не выполняется условие: мы не проверили доказанность, но бегаем вокруг точных результатов, как туземцы вокруг ружья. но без понимания того, как получены эти результаты, мы не поймем, можем ли мы доверять им как доказанным.
кстати, данные, полученные машиной, может обработать другая машина, другая программа.
а модные нынче big data хороший пример того, что такие массивы данных давным давно обрабатываются машинами и нас не спрашивают, доступен нам такой объем или нет. Например, БАК. Сырых данных там петабайты крутятся, но ПО уже настроено на то, чтобы часть хранить и обрабатывать дальше, а часть «забыть» как ненужное. и тут все зависит от тех, кто работает над БАК — не так настроили, не то ПО насчитает. В этом плане бозон Хиггса частица еще более далекая от обнаружения непосредственного органами чувств, чем электрон в свое время. Так что в этом смысле мы уже в сингулярности живем — устройства, запрограммированные нами, делают что-то такое, что вроде бы и верно, как мы считаем, но во многом уже ПО не меньше «понимает» в элементарных частицах и молекулярной биологии, чем физики и биологи с этим ПО работающие. Часть «понимания» доверена машинам, та часть — которую можно формализовать и отследить, насколько верна и работает такая формализация.
Nulliusinverba
28.01.2016 13:35кстати проблему четырех красок решали при помощи компьютера и поместилось все это на 138 страницах ( Appel K. et al. Every planar map is four colorable. Part I: Discharging //Illinois Journal of Mathematics. – 1977. – Т. 21. – №. 3. – С. 429-490. и Appel K. et al. Every planar map is four colorable. Part II: Reducibility //Illinois Journal of Mathematics. – 1977. – Т. 21. – №. 3. – С. 491-567. ). Это недоступный человечеству объем?
Nulliusinverba
28.01.2016 13:43и вот Robertson N. et al. The four-colour theorem //journal of combinatorial theory, Series B. – 1997. – Т. 70. – №. 1. – С. 2-44. пишут: «Unfortunately, the proof by Appel and Haken (briefly, A6H) has not
been fully accepted. There has remained a certain amount of doubt about
its validity, basically for two reasons:
(i) part of the A6H proof uses a computer and cannot be verified
by hand, and
(ii) even the part of the proof that is supposed to be checked by
hand is extraordinarily complicated and tedious, and as far as we know, no
one has made a complete independent check of it.»
Получается, мы уже, следуя такой логике, живем в сингулярности, ведь программы доказывают теоремы, а мы не можем доказать или опровергнуть такие доказательства в силу их сложности.
xma
28.01.2016 13:44>Это недоступный человечеству объем?
очевидно же, что всё что создал человек имеет по определению доступный для него объём.
думаю о точно недоступном объёме можно говорить например при миллионе страниц.Nulliusinverba
28.01.2016 13:55«миллионы страниц» уже выдает БАК и тут же лишь часть сохраняет в постоянной памяти — настолько большие объемы информации приходится обрабатывать. В чем принципиальна разница между «миллионами страниц» сырых экспериментальных данных и такими же объемами доказательств?
И почему эти миллионы страниц доказательств нельзя проверить теми же программными средствами (в смысле вообще ПО, а не тем же ПО)? И найти или не найти ошибку в доказательстве?
А если мы можем проверять эти доказательства другими программами, как мы можем здесь говорить о каком-либо непонимании?
Математики уже давно доказывают такие теоремы, что для перепроверки нужно использовать штаб оплачиваемых независимых математиков (по свежим следам — как проверяли доказательство, проведенное Григорием Перельманом) и/или мощный компьютер/профессиональное ПО. Получается, мы живем в такой вот экспертной сингулярности, в которой единицы способны какие-то вещи обсуждать с друг другом, а доходит до того, что без особой кропотливой работы понимания не добиться.

atomlib
28.01.2016 12:45+3по сути нейросеть вычисляет определённые правила которые приводят к победе в изучаемых её партиях го.
Да, то, о чём вы говорите, уже описывалось. Подобное носит название «эффект искусственного интеллекта». Каждый раз, когда ИИ делает что-то новое, хор критиков повторяет одно и то же: это всего лишь расчёт, это не обдумывание решения. Так было и когда Deep Blue обыграл Каспарова: все взвыли, что это всего лишь навсего перебор ходов. Между тем компьютер обыграл чемпиона по шахматам, то есть решил крайне высококлассную задачу.
Искусственный интеллект — это то, что ещё не было создано. Если компьютер чего-то добивается, то методы решения быстро теряют магию неизведанности, и скептики объявляют созданное сухим расчётом.xma
28.01.2016 13:14>и скептики объявляют созданное сухим расчётом.
весь вопрос сейчас в том насколько далеко может зайти такой «сухой» расчёт ии. слышал что в части автоматизации математических доказательств сейчас проблема в оперировании машиной понятиями бесконечности.

Hamper
28.01.2016 09:15В данном случае начальное обучение проводилось на очень большом числе партий, сыгранных когда-то людьми. Еще интереснее было бы, если бы ИИ смог научиться находить выигрышные стратегии, основываясь только на правилах.

CrazyViper
28.01.2016 09:38+2В таком случае просто пришлось бы провести гораздо больше партий, обучая алгоритм играть против себя же. Выборка из человеческих партий просто сэкономила время на обучение.

Raytheon
28.01.2016 12:02+1Не только. Я читал мемуары Ботвинника, который помимо всяких там шахмат был инженером и занимался созданием первой советской шахматной программы. Так вот, он говорил, что некоторые алогичные вещи, вроде этюда Рети или стандартных комбинаций приходилось вбивать вручную, потому что железка до конца не просчитывала, а позиция к нестандартным решениям не располагала.
Подозреваю, что в го тоже есть стандартные решения и комбинации, которые практически невозможно посчитать, но на практике они приводят к преимуществу или потерям. Без уже наигранной базы тут не обойтись, иначе роботы будут тысячи раз делать один и тот же дебютный ход, а потом придет человек и сыграет по другому, стартуя неочевидный переход в другую ветку вариантов, которая раньше отбрасывалась как неперспективная.CrazyViper
29.01.2016 11:08Все-таки надо отличать алгоритмическое решение задачи с построением дерева возможных ходов и заложенными метриками и нейросети, которые «сами» путем балансировки связей между нейронами находят удачное решение.
По этому поводу есть хороший пример, правда он из области эволюционных алгоритмов, но принцип похожий.
Вот такое не стандартное решение нашел эволюционный алгоритм:
Подробнее про саму задачу лучше почитать по ссылке, иначе будет длинный комментарий.
Coriander
28.01.2016 09:15Люди ещё способны нанести ответный удар. Достаточно расширить доску до 21х21. А если компьютер и в это научится играть, то можно и до 23х23 довести. Чем хороша экспоненциальная сложность, так это тем, что сервера у гугла закончатся раньше.
Nerevar_soul
28.01.2016 10:08+3Людям тоже надо будет переучиваться. Человек при игре в го опирается в том числе и на опыт как свой так и других игроков. При увеличении доски надо понять как изменилась ценность угловых точек с которых начинается партия, переоценить все джосеки(стандартные розыгрыши в углу). Не факт что люди смогут сделат это быстрее программы, которая играет лучше их на стандартной доске.

barmaley_exe
28.01.2016 11:01Эта система не занимается полным перебором, поэтому эффект от увеличения доски будет не столь значимым. Думаю, что даже если увеличить доску до 101x101, то за год система гугла прокачается до гораздо больше уровня, чем любой человек (или группа людей).
Хотя отсутствие истории партий на такой доске процесс обучения для системы, конечно же, усложнит.ankh1989
28.01.2016 20:41Думаю, что не прокачается она никуда, в настоящем её виде. Причину вы указали — отсуствие уже сыгранных партий и заведомо сильных партий. Программе придётся эти партии генерировать самостоятельно, методом тыка, и тут то проявит себя эта самая экспоненциальность.
barmaley_exe
28.01.2016 20:49Я не знаю правил Го, но, думаю, можно как-нибудь использовать игры на текущей сетке для «разогрева» системы. А добить уже можно будет за счёт игры с собою.
3lnc
28.01.2016 12:02+1Экспоненциальная сложность не «хороша», потому что если она действительно экпоненциальна, то в т.ч. и для человеческого мозга, который в отличии от гуглооблака слабо масштабируется. В противном же случае (и так и есть, скорее всего) – DeepMind продолжат оптимизировать алгоритм.
ankh1989
28.01.2016 20:38-1Не всё так просто, имхо. Для игрока среднего уровня вообщем то всё равно какого размера доска, а для всяких там Ли Седолов очень важно, что доска именно 19x19 потому что они знают прорву разных дебютов и разных хитрых ходов которым важно расстояние не только до соседних углов доски, но иногда и до противоположного угла. То есть играть такой 9-й дан будет всё равно очень хорошо, но уже не сможет воспользоваться существенной частью своих знаний о го.

Ogra
29.01.2016 05:12+1Как-раз таки и нет =) Это для среднего игрока важен размер доски — он знает дзёсэки, и завязан на них. Игроки уровня Седоля играют не по дзёсэкам, а по ситуации. Да, они их знают, но не используют «вслепую», в отличие от средних игроков.
Morganall
28.01.2016 09:15+3Надо отметить, что писал статью человек далёкий от мира го. Прости, друг, но это так.
gokifu.com/player/Gu+Li так выглядит история официальных матчей чемпиона
gokifu.com/player/Wu+Guangya так выглядит история всё тех же официальных матчей среднего профессионального игрока
gokifu.com/index.php?q=Fan+Hui так выглядит история нашего героя. Для справедливости, — gokifu.com/other.php?p=1&q=Fan%20Hui, — история игры с европейскими ноунэймами.
Во-вторых, меня немножко смущают партии. В истории противостояния человека и компьютера уже были договорные матчи ради сенсации. И некоторые ходы вызывают вопросы. Да, программа безусловно сильна и наконец-то, после стольких лет, в гошный ai вливают деньги, когда-нибудь компьютер точно победит, вопрос лишь в том не является ли всё это очередным пиаром.
С уважением, чемпион по го Буркина-Фасо.

sillywilly
28.01.2016 09:16Последним рубежом будет старерафт.

neomedved
28.01.2016 10:41+1Условия ведь не равны, компьютер без проблем превзойдёт любого корейца по apm, а ещё может одновременно следить за разными частями карты. В го и шахматах реакция не важна.

faiwer
28.01.2016 12:14Можно ввести подобные ограничения:
1. лимитировать apm до вменяемого
2. не предоставлять доступ к данным игрового поля, а предоставлять только саму картинку и возможность её перемещать (как у и игрока). При всём при этом лимитировать скорость перемещения.
Варианты есть ;)
naneri
28.01.2016 22:51О том же подумал. Особенно если первый старкрафт взять. В игре очень часто тяжело правильно оценить своё положение по отношению к сопернику (то есть выигрываешь ты или нет). Плюс в отличие от игр с полной информацией — можно банально проиграть по БО. Если машина будет каждый раз играть в стандарт — то это заведомо проигрышная стратегия. Даже сейчас АИ с неограниченным АПМом проигрывают крайне средним игрокам, причём их действия выглядят абсолютно глупо.
Уверен проблема в том, что АИ неспособен правильно оценить взаимодействие юнитов обеих сторон между собой (например один юнит забегает к нему на базу, и стоит вдалеке от его зданий\юнитов. Для АИ юнит за пределами базы в 90% в приоритете для атаки если он стоит ближе к его зданиям, чем юнит внутри базы. Причём в ситуациях когда даже начинающим игрокам ясно, что от юнита внутри базы надо избавляться быстрее).
Всех проблем которые надо решить даже не перечислить. Но хотелось бы посмотреть на игру АИ против человека. Надеюсь когда-нибудь такое произойдёт.
tundra
28.01.2016 09:16Ещё недавно ИИ только с форой в несколько камней выигрывал ведь…
ankh1989
28.01.2016 20:49И пока что ничего не изменилось, вроде как. Когда то давно Такемия Масаки (9-й дан, легенда го, но уже не в форме) играл с программой Zen (самой сильной программой, но нейросетей там никаких нет) и как то раз даже проиграл на 20 очков дав фору всего в 4 хода, чему очень удивился. Сейчас нейросеть от фейсбука (там точность 52% всего), может взять фору в 4 хода и играть на равных (половина побед) с корейским 6p (это, конечно, не 9p, но всё равно очень круто). Подтасовок там точно никаких нет, потому что ФБ запустил свою нейросеть в виде бота на КГС и там с ней играют по 200 партий в день все кому не лень.

Arxitektor
28.01.2016 09:16А ресурсы весьма скромные по меркам имеющихся супер компьютеров.
Как я понимаю эта нейросеть способна победить любой классический алгоритм который не использует нейросеть. И ведь есть спец нейропроцессоры от IBM.
И какие будут возможности у нейросеть запущенной на лучьше супер компьютере?
Интересно сколько времени осталось до онлайн игр с миром который управляется нейросетью? И интересует возможность можно ли в теории сделать игру на пк где поведение ботов будет управлять нейросеть? Какой-нибудь ИИ движок унифицированный который интегрируется в игровой.
Взять тот же старкрафт материала для анализа море. Вот будет новость победа над лучшим про геймером. Только слегка отраничить чтобы не могла действовать быстрее человека. Или вообще управление мышью и клавой промышленными манипуляторами.neomedved
28.01.2016 11:09Проблема как раз в том, что придётся искусственно ограничивать. «Чтобы не могла действовать быстрее человека» — понятие растяжимое. Поэтому интересны именно те игры, в которых не важна реакция.
Кстати, я всё чаще слышу жалобы на ИИ в стратегиях (HoMM7, TW:Rome 2). C чего бы это?Xaliuss
28.01.2016 14:27Просто ИИ часто не уделяют достаточно времени — дедлайн горит, багов разных очень много и т.п. В тех же героях он крайне не оптимизирован, и тратит очень много времени даже на хороших компьютерах. Часто фанаты делают его намного лучше, просто потому что намного серьёзнее к нему относятся, и это уже представляет интерес.

aelimill
28.01.2016 15:19ИИ делают изначально таким, чтобы его могли побеждать любые игроки. Какой интерес играть в игру, если ты постоянно проигрываешь? :) А вот сделать хорошо адаптированный под разных игроков ИИ действительно сложно (если не решать действием в лоб как в героях — завышением ресурсов для ИИ, уменьшением для игрока и настройке агрессивности) да и выхлоп будет сомнительным, так как если игра не играется в мультиплеере, то от ИИ толка мало.
Xaliuss
28.01.2016 16:21ИИ должен быть таким, чтобы против него было интересно играть. Большую сложность несложно ослабить, но когда ИИ выбирает следующие действия абсолютно не логично, почти случайным образом это плохо. Когда ИИ в 7 героях намного хуже чем в пятых и третьих это печально, и говорит о многом. К тому же продолжительность хода компьютера на больших картах очень расстраивает. Почему на хорошем core i5 это занимает намного больше времени чем у пятых героев на одноядерном атлоне при видимо не возросшем объёме расчетов и логика его действий при этом хуже?
Бои против ИИ должны приносить удовольствие от своих тактических и стратегических заготовок, а не производить впечатление борьбы с умственно отсталым. К сожалению как минимум в седьмых героях об этом не задумались вовремя.
mbeloborodov
28.01.2016 10:00Казалось только недавно видел статью про го и сложности создания для нее ИИ. И вот, оказывается, уже есть вполне успешный проект! Насколько я понял, игра с Ли Седоль еще только в планах?
Finder15
28.01.2016 11:11+16Очень понравилась байка, прочитанная на другом ресурсе и связанная с данной новостью:
Во всех интервью к предыдущей новости разработчики говорят, что возможно они «решили го». Это настолько круто что я тут вспомнил отличную байку якобы от кубинского гроссмейстера Хосе Рауля Капабланки
«Однажды я участвовал в турнире в Германии, когда ко мне подошел мужчина. Решив, что ему нужен всего лишь автограф, я потянулся за ручкой, но тут мужчина сделал поразительное заявление… «Я решил шахматы!» Я стал благоразумно отступать, на случай, если мужчина был столь же опасен, сколь и безумен, но он продолжил: «Спорим на 50 марок, что если вы пойдете со мной в мой гостиничный номер, я смогу это доказать» Что же, 50 марок есть 50 марок, так что я решил быть снисходительным, и проводил мужчину к его номеру. Оказавшись в номере, он уселся за шахматную доску. «Я все понял, белые ставят мат на 12 ходу независимо ни от чего» Я играл черными возможно чересчур осторожно, но обнаружил, к своему ужасу, что белые фигуры координируются как–то странно, и что я получу мат на 12 ходу! Я попробовал снова, разыграв на этот раз совершенно иной дебют, из которого в принципе невозможно было попасть в такое положение, но после серии очень странно выглядящих ходов, я снова обнаружил своего короля окруженным, и мат должен был прийтись на 12 ход. Я попросил мужчину подождать, а сам сбегал вниз и позвал Эммануэля Ласкера, который был чемпионом мира до меня. Он был настроен крайне скептично, но согласился хотя бы придти и сыграть. По пути мы наткнулись на Алехина, который был текущим чемпионом мира, и вот все трое мы вернулись в тот номер.
Ласкер не рисковал, но играл настолько осторожно, насколько это вообще возможно, и тем не менее, после причудливой, бессмысленно выглядящей серии маневров, обнаружил себя зажатым в матовой сети, из которой не было выхода. Алехин тоже попробовал, но опять же не преуспел.
Это был какой–то кошмар! Вот они мы, лучшие игроки в мире, люди, посвятившие все свои жизни игре, и вот теперь все кончено! Турниры, состязания, все — шахматы решены, белые побеждают»
Тут один из друзей Капабланки вмешивается, со словами: «Погодите минутку, я никогда ни о чем таком не слышал! Что случилось?»
«Как что, мы его убили, конечно»

ZlodeiBaal
28.01.2016 13:48+3Мой друг, 4д по Го на " KGS Go Server" (что очень круто, таких людей в России несколько десятков, как я понимаю) по этому поводу скептичен. Он посмотрел партии указанные. Говорит что «чемпион» дико косячит, делает совершенно неадекватные ходы периодически.
А на счёт того, насколько крут выбранный гуглом «чемпион Европы»:
вот это чемпион мира — gokifu.com/player/Gu+Li
Вот это средний игрок мирового уровня — gokifu.com/player/Wu+Guangya
вот это «чемпион» который играл с гуглом — gokifu.com/index.php?q=Fan+Hui (международный зачёт) gokifu.com/other.php?q=Fan+Hui (европейский зачёт)
Уверяет, что это — очень слабо.
При этом по поводу игры говорит, что видно что программа — сильна, даже очень. Но не на уровне данного игрока её показывать.
По количеству ошибок игрока предположил что играли блиц.Ogra
28.01.2016 14:0160 минут + 30 секунд бёёми (1 период, как я понял). Это как-то несерьезно.
К тому же игры проходили каждый день.
Не выиграть этому АИ даже японского титула =)ZlodeiBaal
28.01.2016 14:47Так как комментарий друга почему-то не пропустила модерация, выложу ещё это — gooften.net/2016/01/28/the-future-is-here-a-professional-level-go-ai
Разбор партии и игры каким-то профессионалом
Nerevar_soul
28.01.2016 15:34Фан кстати в самой начале выбрал устаревший вариант при розыгрыше в левом нижнем углу. Сейчас это вариант не считается равным.

a2v
28.01.2016 14:54Профессиональные игроки (не только в го) знают всех своих сильных соперников «в лицо» — знают их стиль игры, типичные ошибки или приемы, да и во время игры могут «читать» по лицу, замечать эмоции. Это тоже составляющая игры. В игре с компьютером они лишены всего этого.
Ogra
28.01.2016 15:42В играх с полной информацией, без случайностей «эмоции» и «стиль игры» не являются составляющей игры.
Raytheon
28.01.2016 16:08Еще как являются. Особенно, когда ты сидишь на каком-нибудь чемпионате города на второй-третьей доске, на часах осталось минуты по три, а вокруг стоит человек тридцать участников/зрителей и молча смотрят, как вы стучите фигурами по доске. Причем тебе для призов нужно сыграть вничью, а противнику выиграть, и он давит на тебя уже второй час в незнакомом варианте староиндийки.
Nerevar_soul
28.01.2016 16:25Ну мы тут все же более высокий уровень обсуждаем. Где около доски не тусуется куча народа.
Потом в большинстве правил по Го нет ничьи и есть байоми, так что на флаг играть нельзя. А про эмоции посмотрите записи партий на Ютубе. В большинстве своем лица игроков не выражают никаких эмоций.
И опять же профи знают/могут быстро просчитать все основные варианты. Для них незнакомый вариант не такая критичная проблема как для любителя.
Ogra
29.01.2016 05:14Лучший ход в шахматах совершенно не зависит от того, кто сидит перед вами, он зависит только от позиции.
Вничью или выиграть — имеет значение, конечно же.
faiwer
28.01.2016 15:46знают их стиль игры, типичные ошибки или приемы
Тоже самое и с AI. У него будет свой стиль. А вот эмоции они прочитать уже не смогут, хотя так даже честнее :)
barabanus
28.01.2016 15:55Между прочим, в 2000х годах произошел прорыв в ИИ для логических игр, когда венгерский ученый изобрел алгоритм UCT. Это весьма интересный алгоритм, ведущий поиск по Монте-Карло, но с выставлением веса для каждой ветви вычислений по особой формуле. В связи с изобретением этого алгоритма ИИ для го впервые мог играть на уровне любителя.

wild_one
28.01.2016 18:44Есть также Arimaa. Насколько я помню, она специально создавалась для того, чтобы ИИ не могли эффективно играть.
Nulliusinverba
28.01.2016 19:06… и при этом был прост и интуитивно понятен для людей. Создатель обещал $10,000 создавшему программу, которая обыграет человека. И, если верить эту сайту, это случилось в прошлом году.

amarao
29.01.2016 00:03Всё устарело. Игра выиграна компьютером, а инструкция по игре на флеше, который человек на современном компьютере и посмотреть-то не может.
Cr558
29.01.2016 00:06Небольшая поправочка к статье, называть ИИ программы для игры в шахматы, мягко говоря опрометчиво. Deep Blue просто очень быстрый в свое время компьютер, с огромной базой и хорошо составленной оценкой позиции. Но никакого ИИ там нет и близко. В шахматах грамотная стратегия перебора с удачной оценкой позиции гораздо проще и эффективнее.
KvanTTT
29.01.2016 01:38+2Нормально так называть, это устоявшийся термин. Более того, это уже обсуждалось.
lizarge
Интересно узнать какие еще популярные игры плохо подаются стандартным решениям с поиском в дереве решений и поиске с возвратом.
Nulliusinverba
Например, сёги
KvanTTT
Игра Точки.
SelenIT2
Разве точки — не лайтовое Го по сути?
LoadRunner
Размер поля игры в точки вроде ничем не ограничен? Я имею в виду, о размере поля можно договориться перед матчем.
Хотя в Го камни убираются с поля, а в точках — нет, что добавляет сложности Го.
И главное — это ограниченное пространство поля Го, что упрощает эту самую сложность.
Но тут уже встаёт другой вопрос — является ли размер поля усложняющим фактором для работы нейросети?
Hamper
На самом деле, размер поля в Го ограничен только традициями и балансом между сложностью и временем игры. Стандартными являются 9x9 (часто используется для обучения), 13x13 (для быстрых игр) и 19x19 (классический и самый распространенный размер), но никто не запрещает использовать другие размеры, например 37x37 или даже 22x23 (неквадратные поля и четные размерности используются очень редко, но тоже возможны).
По поводу второго вопроса: скорее всего, от размера поля зависит число нейронов во входном и выходном слоях сети, так же может потребоваться увеличение количества нейронов внутри сети, что потребует увеличения требуемых ресурсов.
tishur
А разве точки — это не упрощенная версия го?
KvanTTT
Из-за особенностей правил, эти игры можно сравнивать разве как футбол и баскетбол. Точки — это другая игра.
ramzai
В xkcd была хорошая подборка. Если дополнять нашими играми, то «Мафия», «Поеду на север», «Бутылочка»…
KvanTTT
Как бы это шуточная картинка. Не совсем корректно сравнивать игры с полной информацией и игры, зависящей от психологии и случайности.
Minhir
«Что? Где? Когда?»
omican
Мне кажется, как раз эта игра довольно легко «решается» компьютером широкой базой данных, ибо основана на эрудиции и анализе контекста.
Minhir
Хороший вопрос решается цепочкой ассоциативных связей. Таких вот ассоциативных переходов может быть достаточно много (для этого нужен мозговой штурм). И для компьютера количество вариантов ответа будет расти экспоненциально. Плюс если на один ассоциативный переход вероятность того, что он в нужную сторону == x, то для n переходов это x^n. Всё же «Что? Где? Когда?» очень отвязана от просто игры на эрудицию.
retrograde
habrahabr.ru/post/241531
Тут есть интересная табличка.