
* * *
Когда я был маленьким, то мечтал стать волшебником. Когда немного подрос, выбрал наиболее близкую к колдовству профессию — стал программистом. В процессе разработки всяких веб-приложений разной степени сложности оказалось, что тешатся не только любопытство и любовь к экспериментам, но и простое человеческое тщеславие.
Ох уж это сладкое чувство, когда ты приходишь весь в белом, шевелишь пальцами над клавиатурой неделю или две (возможно, час или день) — и решаешь какую-то проблему, с которой много людей долго и безуспешно боролись.
Вводная
История началась с того, что меня попросили провести подробный аудит довольно популярного интернет-магазина. Всё приложение вертелось на двух балансировщиках, нескольких бэкэндах и двух серверах БД. Нагрузка — 1-4 тысячи запросов в минуту. Стек близок к классическому: PHP(-fpm), Mysql, Memcached, Sphinx, Nginx. Иногда обстоятельства складывались так, что вся система вставала колом, при этом прямой корреляции с нагрузкой не было. И даже с выкладкой нового кода (и соответствующими перезапусками демонов) — не всегда.
Приятно, что, похоже, разработчики читали разные полезные статьи, когда создавали это всё. Потом, правда, потихоньку люди менялись, и текущая команда в основном пилила новый функционал, а периодическими падениями занималась по остаточному принципу (т.е. положили болт: “быстро поднятое не считается упавшим”).
Ретроспектива (забегая вперед)
Когда проект уже завершился, мне самому кажется странным, что я так долго копался: проблемный метод мелькал в первых же отчетах New Relic, а заметить запрос к внешнему хранилищу данных внутри цикла можно было сразу.
В итоге мне потребовалось несколько десятков часов на чтение кода и эксперименты, чтобы “почувствовать” проект и выловить наконец-то проблему.
Переписать, отладить и подготовить патч — полдня, может, чуть больше. Надеюсь, когда-нибудь я смогу с гордостью сказать что-то вроде “никто бы не смог найти этот косяк быстрее”. Но пока пишу заметки, чтобы позволить коллегам набивать меньше шишек:)
Исследования
Основной корень проблем (на самом деле, нет) я нашел довольно быстро. С момента запуска магазина таблица товаров разрослась до более чем 10ГБ, и вертелась с определенными трудностями. Особенно когда на ней обновлялись индексы. С табличкой заказов было нечто подобное, но к ней не было массовых обращений. При этом бэкофис сайта на Magento исключал хоть какой-нибудь шардинг. Та часть, на которую приходилась основная нагрузка, написана на Yii, и в ней мне и нужно было что-нибудь раскопать с помощью New Relic и непечатных выражений.
Первым делом, конечно, я пробежался по ТОП-20 самых “времяёмких” контроллеров. Проверил, как там с кэшированием (почти везде всё было), проверил, что кэши работают. Заодно прошелся по коду автоматическим анализатором, нашел несколько ошибок вроде “в PHP так нельзя”, да и только.
Пока разработчики доделывали кэширование в тех местах, где его не хватало, я продолжал копаться в приложении. Пытался набросать балансировщик SQL-запросов для Magento, потратил кучу времени, пал духом, бросил.
В какой-то момент пришло в голову здравое решение. Если кэширование везде есть, “горячий старт” вообще не требует запросов в базу, то, может быть, кэшей слишком много? Ключи разные, данные одинаковые? Косвенно на эту мысль меня навела статистика — для одного запроса веб-страницы триста memcached-get — многовато, явно есть простор для оптимизации.
Провести исследование по использованию мемкешей оказалось не так уж сложно. Главное — не делайте так на продакшене. Всё сломать — пара пустяков. Будем патчить ядро Yii.
Эксперимент
В классе memcached нужно добавить переменную, допустим, $debagger. Если вызов идет через Singleton или что-нибудь подобное — необязательно даже объявлять переменную статической.
Потом в методе get() добавляем статистику.
public function get($id)
{
if (isset($this->debugger['ids_count'][$id])) {
$this->debugger['ids_count'][$id]++;
if (
$this->debugger['ids_count'][$id] > 10
&& !isset($this->debugger['much'][$id])
) {
$backtrace = debug_backtrace(DEBUG_BACKTRACE_IGNORE_ARGS);
$this->debugger['much'][$id] = $this->debugger['ids_count'][$id];
$this->debugger['much'][$id] = $backtrace;
}
} else {
$this->debugger['ids_count'][$id] = 0;
}
if (isset($this->debugger['all'])) {
$this->debugger['all']++;
} else {
$this->debugger['all'] = 0;
}
if(($value=$this->getValue($this->generateUniqueKey($id)))!==false)
{
$data=$this->autoSerialize ? $this->unserializeValue($value) : $value;
if(!$this->autoSerialize || (is_array($data) && (!($data[1] instanceof ICacheDependency) || !$data[1]->getHasChanged())))
{
Yii::trace('Serving "'.$id.'" from cache','system.caching.'.get_class($this));
if (isset($this->debugger['success'][$id])) {
$this->debugger['success'][$id]++;
} else {
$this->debugger['success'][$id] = 0;
}
return $this->autoSerialize ? $data[0] : $data;
}
}
if (isset($this->debugger['fail'][$id])) {
$this->debugger['fail'][$id]++;
} else {
$this->debugger['fail'][$id] = 0;
}
return false;
}
Мы считаем общее количество уникальных ключей (ids_count). Если ключ не уникален — считаем, сколько раз он вызывается. Потом фиксируем попадания и промахи. И, наконец, для самых популярных ключей фиксируем трейс, чтобы найти концы.
Где-нибудь в конце страницы всю эту переменную можно вывести. Аккуратисты, конечно, положат это всё в логфайл и будут смотреть туда.
Я прошелся по основным страницам, собрал логи и полез смотреть. Удивительно — но нашлось несколько методов, которые по 20 раз запрашивали одни и те же данные. Переделал — и количество запросов упало примерно в полтора-два раза, что, правда, не сильно-то сказалось на производительности (закономерно).
Не прокатило
Копаем больше, дальше и глубже… Я начал подозревать (на самом деле, были жалобы на падения), что есть проблемы с использованием Sphinx. Приложение общалось и с ним, и с Mysql через HandlerSocket, поэтому New Relic их в своей статистике не разделял — этим пришлось заниматься самому.
Применив вышеизложенный способ сбора статистики, я увидел фантастические 600 запросов к Sphinx на главной странице при “холодном старте”, и ни одного — при “горячем”. Правда, все запросы разные. Записал в логи сам запрос и получил что-то типа:
select id1, id2 from table where cat_id IN (N); -- N -- целое число.
Тут я начал что-то подозревать. Заглянул в код. И, конечно, увидел правильный кэш (правильно), в случае отсутствия которого выполнялся foreach, в котором делался запрос к Sphinx (неправильно).
Сфинкс быстрый и классный. Но он не может (и не должен) работать с такой же интенсивностью, как мемкеш. У него другой принцип работы и, прямо скажем, другие задачи. Не надо так.
Переписал весь метод на использование одного большого запроса вместо пачки маленьких. Запрос стал выглядеть вот так:
select id1, id2 from table where cat_id IN (X1, X2, ... XN);
Проверил, что всё работает. С замиранием сердца дождался выкладки.
Прокатило
Общий прирост производительности, конечно, получился не кратным. Может, 10%, может, чуть больше. Но насколько легче стали даваться сбросы Memcache! 600 простых и быстрых запросов превратились в один сложный и долгий. Но он всё равно делался в два раза быстрее! Зато сервер задышал полной грудью и перестал падать при каждой выкладки.
Вот на этих графиках вертикальными линиями отмечена выкладка кода на серверы (отмечу, что по нашему совету код стали выкладывать не одновременно, а с небольшим интервалом). Рваный график запросов сразу превратился в плавную линию. Минимальное время отработки страницы выросло, но зато экстремумы исчезли вовсе. И, главное, число запросов стало стабильно низким.
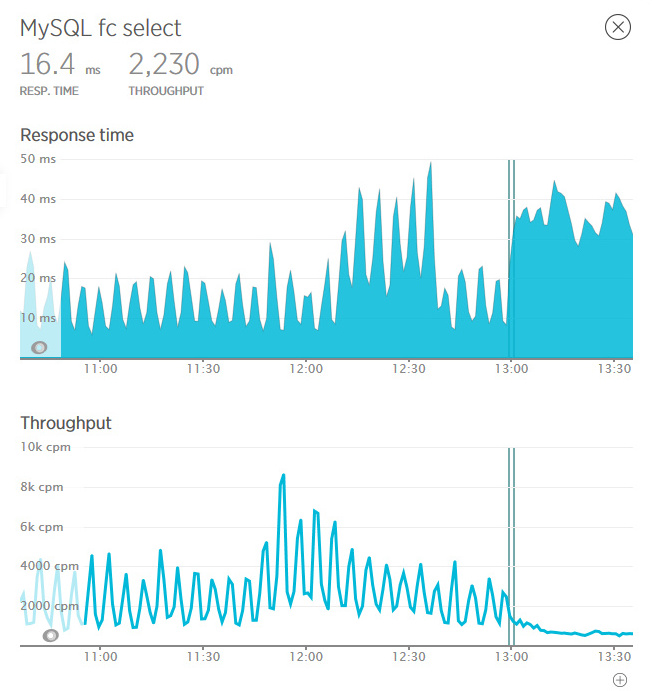

Участники событий наснимали еще красивых картинок в New Relic, нарисовали оптимистичный отчет и с удовольствием пропили солидный гонорар.
Комментарии (11)

maxru
09.03.2016 18:39+1> Провести исследование по использованию мемкешей оказалось не так уж сложно. Главное — не делайте так на продакшене. Всё сломать — пара пустяков. Будем патчить ядро Yii.
Есть много более простых способов замерить количество и разнообразие запросов к memcache, нежели патчинг ядра Yii (но патчинг ядра звучит красивее, если не знать, о чём речь) 8)
Andrewus
09.03.2016 23:27+1Так расскажи же про них!
На самом деле, если с мемкешом в моем конкретном случае еще были варианты, то для разборок со сфинксом пришлось встраиваться в SphinxAPI, и там никаких легитимных альтернатив не было точно.maxru
10.03.2016 12:551. Логирование memcache запросов (на dev сервере, конечно)
2. Профилирование (XDebug на dev, либо phpdbg на prod)
3. Анализ searchd лога (на dev)
Вышеупомянутого вполне достаточно, чтобы найти упомянутые в статье проблемы без модификации исходников.Andrewus
10.03.2016 13:55-3. Вот анализ лога я по факту и совместил с его сбором, попутно выяснив, где именно он вызывается.
Так-то запрос еще надо отследить в коде.
-2. Да. Всё было. Но как первый этап.
-1. А как ты предоставляешь себе этот лог? get 238f5632304123b958d26d521763f730093b0b65, set 238f5632304123b958d26d521763f730093b0b67?maxru
10.03.2016 14:09+3
> Так-то запрос еще надо отследить в коде.
Ну ключ-то ты знаешь
+1
Представляю, активно работал с ним. И что такого страшного в этом? )
zizop
Следствие ведут колобки) А по теме — очень интересны такие вот посты про реальные интересне проблемы и поиск их решения.
Andrewus
У меня по этому проекту, конечно, очень много баек.
Начать с того, что искать концы в Magento можно вечно:)