
Предыдущая статья серии была посвящена теории парсинга исходников с использованием ANTLR и Roslyn. В ней было отмечено, что процесс сигнатурного анализа кода в нашем проекте PT Application Inspector разбит на следующие этапы:
- парсинг в зависимое от языка представление (abstract syntax tree, AST);
- преобразование AST в независимый от языка унифицированный формат (Unified AST, UAST);
- непосредственное сопоставление с шаблонами, описанными на DSL.
Данная статья посвящена второму этапу, а именно: обработке AST с помощью стратегий Visitor и Listener, преобразованию AST в унифицированный формат, упрощению AST, а также алгоритму сопоставления древовидных структур.
Содержание
- Обход AST
- Типы узлов унифицированного AST
- Тестирование конвертеров
- Упрощение UAST
- Алгоритм сопоставления древовидных структур
- Заключение
Обход AST
Как известно, парсер преобразует исходный код в дерево разбора (в дерево, в котором убраны все незначимые токены), называемом AST. Существуют различные способы обработать такое дерево. Простейший — заключается в обработке дерева с помощью рекурсивного обхода потомков в глубину. Однако данный способ применим только для совсем простых случаев, в котором существует немного типов узлов и логика обработки простая. В остальных случаях, необходимо выносить логику обработки каждого типа узла в отдельные методы. Это осуществляется с помощью двух типовых подходов (паттернов проектирования): Visitor и Listener.
Visitor и Listener
В Visitor для посещения потомков узла необходимо вручную вызывать методы обхода дочерних узлов. При этом если родитель имеет три потомка, и вызвать методы только для двух узлов, то часть поддерева вообще не будет обработана. В Listener (Walker) же методы посещения всех потомков вызываются автоматически. В Listener существует метод, вызываемый в начале посещения узла (enterNode) и метод, вызываемый после посещения узла (exitNode). Эти методы также можно реализовать с помощью механизма событий. Методы Visitor, в отличие от Listener, могут возвращать объекты и даже могут быть типизированными, т.е. при объявлении CSharpSyntaxVisitor каждый метод Visit, будет возвращать объект AstNode, который в нашем случае является общим предком для всех остальных узлов унифицированного AST.
Таким образом, код преобразования дерева с помощью Visitor получается более функциональным и лаконичным за счет того, что в нем нет необходимости хранить информацию о посещенных узлах. На рисунке ниже можно увидеть, что, например, при преобразовании языка PHP, ненужные узлы HTML и CSS отсекаются. Порядок обхода обозначен числами. Listener обычно используется при агрегации данных (например из файлов типа CSV), преобразовании одного кода в другой (JSON -> XML). Подробнее об этом написано в The Definitive ANTLR 4 Reference.
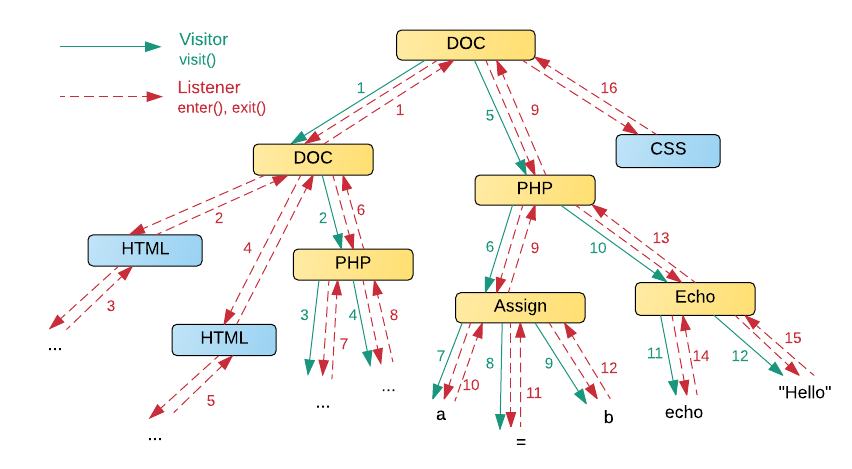
Различия в Visitor в ANTLR и Roslyn.
Реализация Visitor и Listener может различаться в библиотеках. Например, в таблице ниже описаны классы и методы Visitor и Listener в Roslyn и ANTLR.
| ANTLR | Roslyn | |
|---|---|---|
| Visitor | AbstractParseTreeVisitor< Result > | CSharpSyntaxVisitor< Result > |
| Listener | IParseTreeListener | CSharpSyntaxWalker |
| Default | DefaultResult | DefaultVisit(SyntaxNode node) |
| Visit | Visit(IParseTree tree) | Visit(SyntaxNode node) |
И ANTLR и Roslyn имеют методы для возвращения результата по умолчанию (если метод Visitor для какой-то синтаксической конструкции не переопределен), а также обобщенный метод Visit, который сам определяет, какой специальный метод Visitor должен вызываться.
В ANTLR визиторе для каждого синтаксического правила грамматики генерируется собственный Visitor. Также существуют специальные типы методов:
VisitChild(IRuleNode node); используется для реализации обхода узла по-умолчанию.VisitTerminal(IRuleNode node); используется при обходе терминальных узлов, т.е. токенов.VisitErrorNode(IErrorNode node); используется при обходе токенов, полученных в результате парсинга кода с лексическими или синтаксическими ошибками. Например, если в утверждении пропущена точка с запятой в конце, то парсер вставит такой токен и укажет, что он является ошибочным. Подробнее об ошибках парсинга написано в предыдущей статье.AggregateResult(AstNode aggregate, AstNode nextResult); редко используемый метод, предназначенный для агрегации результатов обхода потомков.ShouldVisitNextChild(IRuleNode node, AstNode currentResult); редко используемый метод, предназначенный для определения того, нужно ли обрабатывать следующего потомкаnodeв зависимости от результата обхода узлаcurrentNode.
Roslyn визитор имеет специальные методы для каждой синтаксической конструкции и обобщенный метод Visit для всех узлов. Однако методов для обхода "промежуточных" конструкций в нем нет, в отличие от ANTLR. Например, в Roslyn не существует метода для утверждений VisitStatement, а только существуют специальные VisitDoStatement, VisitExpressionStatement, VisitForStatement и т.д. В качестве VisitStatement можно использовать обобщенный Visit. Еще одним отличием является то, что методы обхода тривиальных (SyntaxTrivia) узлов, т.е. узлов, которые можно удалить без потери информации о коде (пробелы, комментарии), вызываются наряду с методами обхода основных узлов и токенов.
Недостатком ANTLR визиторов является то, что названия сгенерированных методов-Visitor напрямую зависят от стиля написания правил грамматики, поэтому они могут не вписываться в общую стилистику кода. Например, в sql-грамматиках принято использовать так называемый Snake case, в котором для разделения слов используются символы подчеркивания. Roslyn методы написаны в стилистике C#-кода. Несмотря на различия, методы обработки древовидных структур в Roslyn и ANTLR с новыми версиями все больше и больше унифицируются, что не может не радовать (в ANTLR версии 3 и ниже не было механизма Visitor и Listener).
Грамматика и Visitor в ANTLR.
В ANTLR для правила
ifStatement
: If parenthesis statement elseIfStatement* elseStatement?
| If parenthesis ':' innerStatementList elseIfColonStatement* elseColonStatement? EndIf ';'
;будет сформирован метод VisitIfStatement(PHPParser.IfStatementContext context) в котором context будет иметь следующие поля:
parenthesis– единичный узел;elseIfStatement*– массив узлов. Если синтаксис отсутствует, то длина массива равна нулю;elseStatement?– опциональный узел. Если синтаксис отсутствует, то принимает значение null;If,EndIf— терминальные узлы, начинаются с большой буквы;':',';'— терминальные узлы, не содержатся в context (доступны только через GetChild()).
Стоит отметить, что чем меньше правил существует в грамматике, тем легче и быстрее писать Visitor. Однако повторяющийся синтаксис также нужно выносить в отдельные правила.
Альтернативные и элементные метки в ANTLR
Часто возникают ситуации, в которых правило имеет несколько альтернатив и было бы логичнее обрабатывать эти альтернативы в отдельных методах. К счастью, в ANTLR 4 для это существуют специальные альтернативные метки, которые начинаются с символа # и добавляются после каждой альтернативы правила. При генерации кода парсера, для каждой метки генерируется отдельный метод-Visitor, что позволяет избежать большого количества кода в случае, если правило имеет много альтернатив. Стоит отметить, что помечаться должны либо все альтернативы, либо ни одной. Также для обозначения терминала, принимающего множество значений, можно использовать элементные метки (rule element label):
expression
: op=('+'|'-'|'++'|'--') expression #UnaryOperatorExpression
| expression op=('*'|'/'|'%') expression #MultiplyExpression
| expression op=('+'|'-') expression #AdditionExpression
| expression op='&&' expression #LogicalAndExpression
| expression op='?' expression op2=':' expression #TernaryOperatorExpression
;Для этого правила ANTLR сгенерирует визиторы VisitExpression, VisitUnaryOperatorExpression, VisitMultiplyExpression и пр. В каждом визиторе будет существовать массив expression, состоящий из 1 или 2 элементов, а также литерал op. Благодаря меткам, код визиторов будет более чистым и лаконичным:
public override AstNode VisitUnaryOperatorExpression(TestParser.UnaryOperatorExpressionContext context)
{
var op = new MyUnaryOperator(context.op().GetText());
var expr = (Expression)VisitExpression(context.expression(0));
return new MyUnaryExpression(op, expr);
}
public override AstNode VisitMultiplyExpression(TestParser.MultiplyExpressionContext context)
{
var left = (Expression)VisitExpression(context.expression(0));
var op = new MyBinaryOpeartor(context.op().GetText());
var right = (Expression)VisitExpression(context.expression(1));
return new MyBinaryExpression(left, op, right);
}
public override AstNode VisitTernaryOperatorExpression(TestParser.TernaryOperatorExpressionContext context)
{
var first = (Expression)VisitExpression(context.expression(0));
var second = (Expression)VisitExpression(context.expression(1));
var third = (Expression)VisitExpression(context.expression(2));
return new MyTernaryExpression(first, second, third);
}
...Без альтернативны меток, обработка Expression находилась бы в одном методе и код выглядел так:
public override AstNode VisitExpression(TestParser.ExpressionContext context)
{
Expression expr, expr2, expr3;
if (context.ChildCount == 2) // Unary
{
var op = new MyUnaryOperator(context.GetChild<ITerminalNode>(0).GetText());
expr = (Expression)VisitExpression(context.expression(0));
return new MyUnaryExpression(op, expr);
}
else if (context.ChildCount == 3) // Binary
{
expr = (Expression)VisitExpression(context.expression(0));
var binaryOp = new MyBinaryOpeartor(context.GetChild<ITerminalNode>(0).GetText());
expr2 = (Expression)VisitExpression(context.expression(1));
return new MyBinaryExpression(expr, binaryOp, expr2);
...
}
else // Ternary
{
var first = (Expression)VisitExpression(context.expression(0));
var second = (Expression)VisitExpression(context.expression(1));
var third = (Expression)VisitExpression(context.expression(2));
return new MyTernaryExpression(first, second, third);
}
}Стоит отметить, что альтернативные метки существуют не только в ANTLR, но и других средствах для описания грамматик. Например, в Nitra метка со знаком присваивания ставится слева от альтернативы, в отличие от ANTLR:
syntax Expression
{
| IntegerLiteral
| BooleanLiteral
| NullLiteral = "null";
| Parenthesized = "(" Expression ")";
| Cast1 = "(" !Expression AnyType ")" Expression;
| ThisAccess = "this";
| BaseAccessMember = "base" "." QualifiedName;
| RegularStringLiteral;Типы узлов унифицированного AST
При разработке структуры унифицированного AST и типов узлов, мы руководствовались структурой AST из проекта NRefactory в виду того, что она является для нас достаточно простой, а получение достоверного дерева (fidelity, обратимое в исходный код с точностью до символа) не требовалось. Любой узел является наследником AstNode и имеет собственный тип NodeType, который также используется на этапе сопоставления с шаблонами и при десериализации из JSON. Структура узлов выглядела примерно следующим образом:
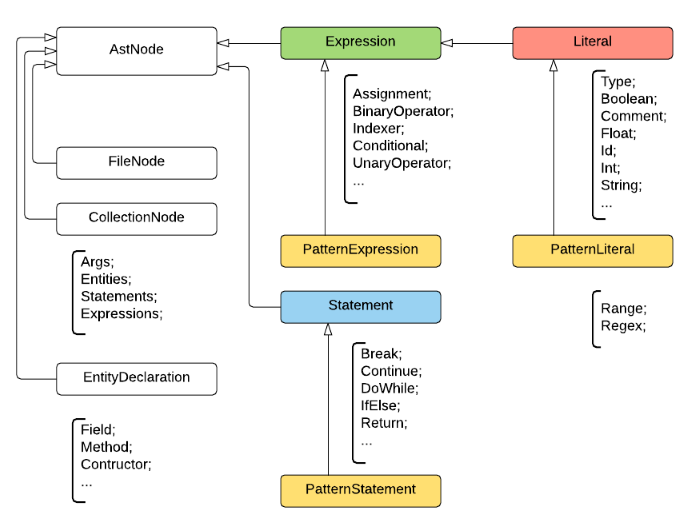
Помимо типа, каждый узел имеет свойство, хранящее расположение в коде (TextSpan), которое используется для его отображения в исходный код при сопоставлении с шаблоном. Нетерминальный узел хранит список дочерних узлов, а терминальный — числовое, строковое или другое примитивное значение.
Для того, чтобы сопоставить узлы AST различных языков, была составлена таблица, в которой строками являлся синтаксис определенных узлов, а столбцами — их реализация в языках C#, Java, PHP, что выглядело следующим образом:
| Node | Args | C# | Java | PHP | MCA | MDA |
|---|---|---|---|---|---|---|
| While | cond:Expression; stmt:Statement | while (cond) stmt | while (cond) stmt | while (cond) stmt | While(cond, stmt) | While(cond, stmt) |
| BinaryOp | l,r:Expression; op:Literal | l op r | l op r | l op r | BinaryOp(l, op, r) | BinaryOp(l, op, r) |
| ... | ... | ... | ... | ... | ... | ... |
| Checked | checked:Expression | checked(checked) | - | - | checked | Checked(checked) |
| NullConditional | a:Expression,b:Literal | a?.b | - | - | a != null? a.b: null | a?.b |
В этой таблице:
- Expression; выражение, имеет возвращаемое значение.
- Statement; утверждение (инструкция), не имеет возвращаемого значения.
- Literal; терминальный узел.
- Most Common Ast (MCA) наиболее унифицированное AST. Данный узел строится, если все три языка содержат в себе тип такого или подобного узла (например, IfStatement, AssignmentExpression);
- Most Detail Ast (MDA) наиболее детализированное AST. Данный узел строится, если хотя бы один язык содержит в себе такой тип узла (например, FixedStatenemt
fixed (a) { }для C#). Данные узлы более актуальны для SQL подобных языков, из-за того что последние декларативные языки и между T-SQL и C# разница гораздо больше, чем, например, между PHP и C#.
Кроме узлов, представленных на рисунке (и "узлов-паттернов", которые описаны в следующем разделе), существуют еще искусственные узлы для того, чтобы все же построить узел Most Common Ast, "потеряв" при этом как можно меньше синтаксиса. Такими узлами являются:
- MultichildExpression; имеет тип Expression, но при этом содержит в себе коллекцию других Expression;
- WrapperExpression; имеет тип Expression, но при этом содержит в себе любой AstNode;
- WrapperStatement; имеет тип Statement, но при этом содержит в себе любой AstNode.
В императивных языках программирование основными конструкциями является выражения Expression и утверждения Statement. Первые имеют возвращаемое значение, вторые же используются для совершения каких-либо операций. Поэтому в нашем модуле мы также сконцетрировались по большей части на них. Они являются базовыми "кирпичиками" для реализации CFG и других представлений исходного кода, необходимых для реализации taint-анализа в будущем. Стоит добавить, что знания о синтаксическом сахаре, дженериках и других специфичных для конкретного языка вещей поиска уязвимостей в коде не требуется. Поэтому синтаксический сахар можно раскрывать в стандартные конструкции, а информацию о специфичных вещах вообще удалять.
Паттерн-узлами являются искусственные узлы, представляющие пользовательские шаблоны. Например, в качестве паттернов-литералов используются диапазоны чисел, регулярные выражения.
Тестирование конвертеров
Для анализатора кода приоритетной задачей является тестирование всего кода, а не отдельных его частей. Для решения этой задачи было решено перегрузить методы-визиторы для всех типов узлов. При этом, если визитор не используется, то он генерирует исключение new ShouldNotBeVisitedException(context). Такой подход упрощает разработку, поскольку IntelliSense учитывает, какие методы перегружены, а какие — нет, поэтому легко определить, какие методы визиторы уже были реализованы.
Также мы имеем некоторые соображения на тему того, как улучшить тестирование покрытия всего кода. Каждый узел унифицированного AST хранит в себе координаты соответствующего ему исходного кода. При этом все терминалы связаны с лексемами, т.е. определенными последовательностями символов. Так как все лексемы по возможности необходимо обработать, то общий коэффициент покрытия можно выразить следующей формулой, в которой uterms — терминалы унифицированного AST, а terms — терминалы обычного Roslyn или ANTLR AST:

Данная метрика выражает покрытие кода с помощью одного коэффициента, который должен стремиться к единице. Конечно, оценка по этому коэффициенту является приблизительной, однако его можно использовать при рефакторинге и улучшении кода визиторов. Для более достоверного анализа также можно использовать графическое представление покрытых терминалов.
Упрощение AST
После преобразования обычного AST в UAST, последнее нужно упростить. Наиболее простой и полезной оптимизацией является свертка констант (constant folding). Например, существует отдельный класс недостатка кода, связанный с установкой слишком большого времени жизни для cookie: cookie.setMaxAge(2147483647); Аргумент в скобках может быть записан как одним числом, например 86400, так и каким-то арифметическим выражением, например 60 * 60 * 24. Другой пример связан с конкатенацией строк при поиске SQL-инъекций и других уязвимостей.
Для реализации этой задачи был реализован собственный интерфейс и сам Visitor только уже для UAST. Так как упрощение AST просто уменьшает количество узлов дерева, то Visitor являлся типизированным, принимающим и возвращающим один и тот же тип. Благодаря поддержке рефлексии в .NET, получилось реализовать такой Visitor с небольшим количеством кода. Так как каждый узел содержит в себе другие узлы или терминальные примитивные значения, то с помощью рефлексии возможно извлечь все члены определенного узла и обработать их, вызывая другие визиторы рекурсивно.
Алгоритм сопоставления AST и шаблонов
При обходе унифицированного AST каждый шаблон "пытается" наложиться на кусочек AST текущего узла. В начале сравнивается тип узла, а затем, в зависимости от типа, производятся следующие операции:
- Рекурсивное сравнение потомков.
- Сравнение простых литеральных типов (идентификатор, строки, числа).
- Сравнение расширенных литеральных типов (регулярные выражения, диапазоны). Комментарии входят в эту группу.
- Сравнение сложных расширенны типов (выражения, последовательность Statement).
В основе данного алгоритма лежат простые принципы, позволяющие достичь высокой производительности при сравнительно небольшом количестве реализующего их кода. Последнее достигается за счет того, что метод CompareTo для сравнения узлов реализован для базового класса, терминалов и небольшого числа других узлов. Более продвинутые алгоритмы сопоставления для улучшения производительности, основанные на конечных автоматах, реализовывать пока не потребовалось. Однако данный алгоритм проблематично (или даже невозможно) использовать для более продвинутого анализа, например, учитывающего связи между Statement.
Заключение
В данной статье мы рассмотрели паттерны Visitor и Listener для обработки деревьев, а также рассказали о структуре унифицированного AST. В следующих статьях мы расскажем:
- о подходам к хранению шаблонов (Hardcoded, Json, DSL);
- разработке и использовании DSL для описания шаблонов;
- примерах реальных шаблонов и их поиске в открытых проектах;
- построении CFG, DFG и taint-анализе.
geekmetwice
Ребят, у вас столько лишних деталей в статье, что непонятно, зачем её вообще было писать (здесь). Для людей, работающих внутри вашего проекта, слишком много тривиальщины и мало деталей по «внутренней кухне». Для местных читателей — наоборот, слишком много несущественных деталей реализации и мало объяснений общих вещей. Постарайтесь писать без дебрей и так, чтобы люди вынесли что-то полезное, а не «у нас тут узел называется AbcVisitor». Я сам немного вращаюсь в этой теме и чтение статьи было как катание на костылях по льду в лунках — спотыкание на деталях и в итоге ни покатался, ни рыбы наловил. :)
KvanTTT
Изначально я хотел подробно описать про Visitor, Listener, ANTLR и Roslyn и в общих чертах про "внутреннюю кухню". Но, видимо, получилось все равно слишком много деталей. Но спасибо за замечание, будет учтено.