
Нормальное взаимодействие участников Netflix обеспечивается архитектурой микросервисов и привязано персонально к каждому из наших более чем 80 миллионов участников. Сервисы принадлежат разным командам (группам), каждая из которых имеет свой собственный цикл разработки и релиза. Это означает, что необходимо иметь постоянно действующую и компетентную группу тестирования интеграции, обеспечивающую выполнение сквозных стандартов качества в ситуации, когда микросервисы вводятся в действие каждый день децентрализованно.
В качестве группы тестирования интеграции разрабатываемых продуктов мы обязаны не снижать скорость введения нового, обеспечивая в то же время контроль качества и быструю обратную связь для разработчиков. Каждая группа разработчиков отвечает за качество поставляемого ею продукта. Нашей задачей является бесперебойная работа с различными техническими группами с упором на сквозную функциональность и координацию деятельности групп. Мы представляем собой небольшую группу специалистов по тестированию интеграции в организации, насчитывающей более 200 разработчиков.
Быстрый ввод новых разработок при необходимости обеспечении требуемого качества создаёт интересные задачи для нашей команды. В настоящей статье мы рассмотрим три такие задачи:
1. Тестирование и мониторинг высокорейтинговых показов (High Impact Title = HIT = хит)
2. A/B-тестирование
3. Глобальный запуск
Имеется множество высокорейтинговых показов — как, например, телесериал «Оранжевый — хит сезона», которые регулярно появляются на Netflix. Форма и размер этих показов — самые разные. Некоторые являются сериалами, некоторые — отдельными картинами; есть ориентированные только на детей; какие-то выстреливают все серии сезона сразу, а другие выпускают по несколько серий каждую неделю. Часть этих показов запускается со сложными A/B-тестами, в которых каждый элемент теста имеет различное взаимодействие с участником.
Эти показы имеют высокую популярность у наших участников и поэтому должны подвергаться всесторонней проверке. Тестирование начинается за несколько недель до запуска и идёт по нарастающей до самого запуска. После запуска мы отслеживаем эти показы на разных аппаратных платформах во всех странах.
Стратегия тестирования зависит от её фазы. На разных фазах действует разная стратегия продвижения, что делает задачу тестирования/автоматизации довольно сложной. В основном, можно выделить две фазы:
1. До запуска показа. До запуска необходимо обеспечить нахождение метаданных показа в требуемом месте, чтобы в день запуска всё прошло безукоризненно. Поскольку в запуске хита участвует множество групп (команд), то необходимо убедиться, что стыковка всех внутренних (серверных) систем друг с другом и с клиентской частью пользовательского интерфейса происходит безупречно. Продвижение показа осуществляется через Spotlight (большое окно, похожее на доску объявлений, в верхней части главной страницы Netflix), через тизеры и трейлеры. Но поскольку на каждом уровне Netflix имеется персонализация, то необходимо создавать сложные тестовые наборы, чтобы обеспечить соответствие типа показа профилю участника. Поскольку система постоянно изменяется, то автоматизация становится трудной. Основное тестирование на этой фазе происходит вручную.
2. После запуска показа. Наша работа не заканчивается в день запуска. Мы должны постоянно контролировать запущенные показы, чтобы ни в коем случае не допустить ухудшения взаимодействия с участником. Показ становится частью расширенного каталога Netflix, и это само по себе создаёт проблему. Мы должны теперь написать тесты, проверяющие, продолжает ли показ находить свою аудиторию согласованным образом и сохраняется ли целостность данных у этого показа (например, некоторые проверки выясняют, не изменилось ли общее количество серий после запуска; другая проверка контролирует, продолжают ли результаты поиска возвращать показ в надлежащие поисковые строки). Но, имея 600 часов оригинального программирования на Netflix, идущего онлайн только в этом году, дополнительно к лицензированному контенту, мы не можем положиться здесь на ручное тестирование. Также, когда показ запущен, существуют общие предположения, которые мы можем сделать о нём, поскольку данные для этого показа и логика продвижения не будут меняться — например, количество серий больше 0 для ТВ-выпусков, показ доступен для поиска (действительно как для кинофильмов, так и для ТВ-выпусков) и т.д. Это позволяет нам автоматически мониторить, продолжают ли те или иные операции, связанные с каждым показом, работать правильно.
Тестирование хитов является сложной задачей, и оно привязано ко времени. Но участие в запуске показа, отслеживание того, что все связанные с показом функции, серверная логика работают правильно во время запуска, даёт волнующий опыт. Просмотр фильмов со знаменитостями и крутые промо-материалы от Netflix представляют собой также приятную добавку. :)
Мы осуществляем множество A/B-тестов. В каждый момент времени работает много A/B-тестов с различным уровнем сложности.
В прошлом основная часть проверки в A/B-тестах представляла собой комбинацию автоматизированного и ручного тестирования: автоматика использовалась для индивидуальных компонентов (тестирование методом белого ящика), а сквозное тестирование (тестирование методом чёрного ящика) происходило, большей частью, вручную. Когда объём A/B-тестов у нас заметно увеличился, оказалось невозможным вручную осуществлять все требуемые сквозные тесты, и мы начали наращивать автоматизацию.
Одной из главных проблем при введении сквозной автоматизации A/B-тестов стало огромное количество компонентов, подлежащих автоматической обработке. Наш подход состоял в рассмотрении автоматизации тестирования как поставляемого продукта и в сосредоточенности на поставке продукта с минимальным функционалом (minimum viable product = MVP), состоящего из частей, допускающих многократное использование. Нашим требованием к MVP было обеспечение подтверждения базового взаимодействия с участником путём проверки правильности данных от конечных REST-точек различных микросервисов. Это давало нам возможность итерационно двигаться к решению вместо поиска наилучшего решения сразу при старте.

Существенной отправной точкой для нас было создание общей библиотеки, обеспечивающей возможность многократного использования и переназначения модулей для любого автоматизированного теста. Например, у нас был A/B-тест, модифицировавший «Мой список» участника, — при его автоматизации мы написали скрипт, добавлявший показ(ы) в «Мой список» участника или удалявший показ(ы) из этого списка. Эти скрипты были спараметрированы так, чтобы их можно было многократно использовать в любом будущем A/B-тесте, имевшем дело с «Моим списком». Такой подход позволил нам быстрее автоматизировать A/B-тесты благодаря большему количеству многократно используемых компоновочных блоков. Эффективность работы была повышена путём максимально возможного применения уже существующей автоматизации. Например, вместо написания нашей собственной программы автоматизации пользовательского интерфейса мы смогли использовать Netflix Test Studio для переключения между сценариями тестирования, требующими действий со стороны пользовательского интерфейса для различных устройств.
При выборе языка/платформы для внедрения нашей автоматизации мы исходили из необходимости обеспечения быстрой обратной связи для команд разработчиков продукта. Это требовало действительно быстрой работы тестового комплекса — выполнения буквально за секунды. Мы также стремились сделать наши тесты как можно более лёгкими для внедрения и распространения. Имея в виду эти два требования, мы отказались от нашего первого выбора — Java. Наши тесты оказались бы зависимыми от использования множества взаимосвязанных jar-файлов, и пришлось бы заниматься управлением зависимостями, контролем версий, будучи подверженными воздействиям изменений в различных версиях файлового формата JAR. Всё это значительно увеличило бы длительность тестов.
Мы решили ввести нашу автоматизацию, получая доступ к микросервисам через их конечные REST-точки, благодаря чему мы могли бы настраивать использование jar-файлов и не писать какую-либо бизнес-логику. Чтобы обеспечить простоту внедрения и распространения нашей автоматизации, мы решили использовать комбинацию параметризированной оболочки и python-скриптов, которая может быть выполнена из командной строки. Это должен был быть отдельный скрипт оболочки для управления исполнением тестового сценария, в ходе которого должны вызываться другие скрипты оболочки и python-скрипты, действующие как многократно используемые утилиты.

Такой подход имеет несколько положительных моментов:
1. Мы смогли получить длительность теста (включая время на установку и отсоединение) 4-90 секунд; медиана времени работы — 40 секунд. При использовании автоматизации на базе Java медиана времени работы оценочно могла бы быть 5-6 минут.
2. Непрерывная интеграция была упрощена. Всё, что нам требовалось, это система Jenkins Job, которая осуществляет нисходящую загрузку из нашего репозитария, выполняет требуемые скрипты и регистрирует результаты. Встроенный в Jenkins консольный анализ записей оказался достаточным для получения статистики тест «прошёл / не прошёл».
3. Лёгкий запуск. Чтобы сторонний специалист запустил наш тестовый комплекс, требуется только доступ к нашему гит-репозитарию и терминал.
Один из наших самых больших проектов в 2015 году состоял в том, чтобы удостовериться, что мы имели достаточное тестирование интеграции, обеспечивающее гладкий одновременный запуск Netflix в 130 странах. Фактически нам требовалось автоматизировать, как минимум, тестовый комплекс на общую работоспособность для каждой комбинации страны и языка. Это заметно осложнило функциональность нашего продукта автоматизации.
Наши тесты работали довольно быстро, поэтому мы первоначально решили, что достаточно будет запускать тестовую программу в цикле для каждой комбинации страны и языка. Результатом стало то, что тесты, которые проходили примерно за 15 секунд, начали работать по часу и более. Требовалось найти более приемлемый подход к этой проблеме. В дополнение к этому каждый протокол тестирования вырос примерно в 250 раз, что сделало более трудным анализ неудач. Чтобы справиться с этими проблемами, мы сделали два дела:
1. Мы использовали плагин Jenkins Matrix для запараллеливания наших тестов, благодаря чему тесты для каждой страны начали выполняться параллельно. Мы также должны были настроить наши ведомые устройства Jenkins на такое использование разных исполнителей, чтобы другие задания не стояли в очереди, когда наши тесты сталкивались с любой состязательной ситуацией или с бесконечными циклами. Это было выполнимо для нас, потому что у нашей автоматизации были только затраты, связанные с работающими скриптами оболочки, и не было необходимости предварительной загрузки двоичных файлов.
2. Мы не хотели осуществлять рефакторинг каждого теста, написанного до этого момента, и мы не хотели, чтобы каждый тест работал с каждой отдельной комбинацией страна/язык. В результате мы решили использовать модель «по запросу», при которой мы могли продолжать писать автоматизированные тесты так, как мы это делали раньше, а для выведения его на глобальную готовность к нему добавлялась бы надстройка. Эта надстройка должна содержать идентификатор тестового набора и комбинацию «страна/язык» в качестве параметров, а затем должна выполнять тестовый набор с этими параметрами, как показано ниже:
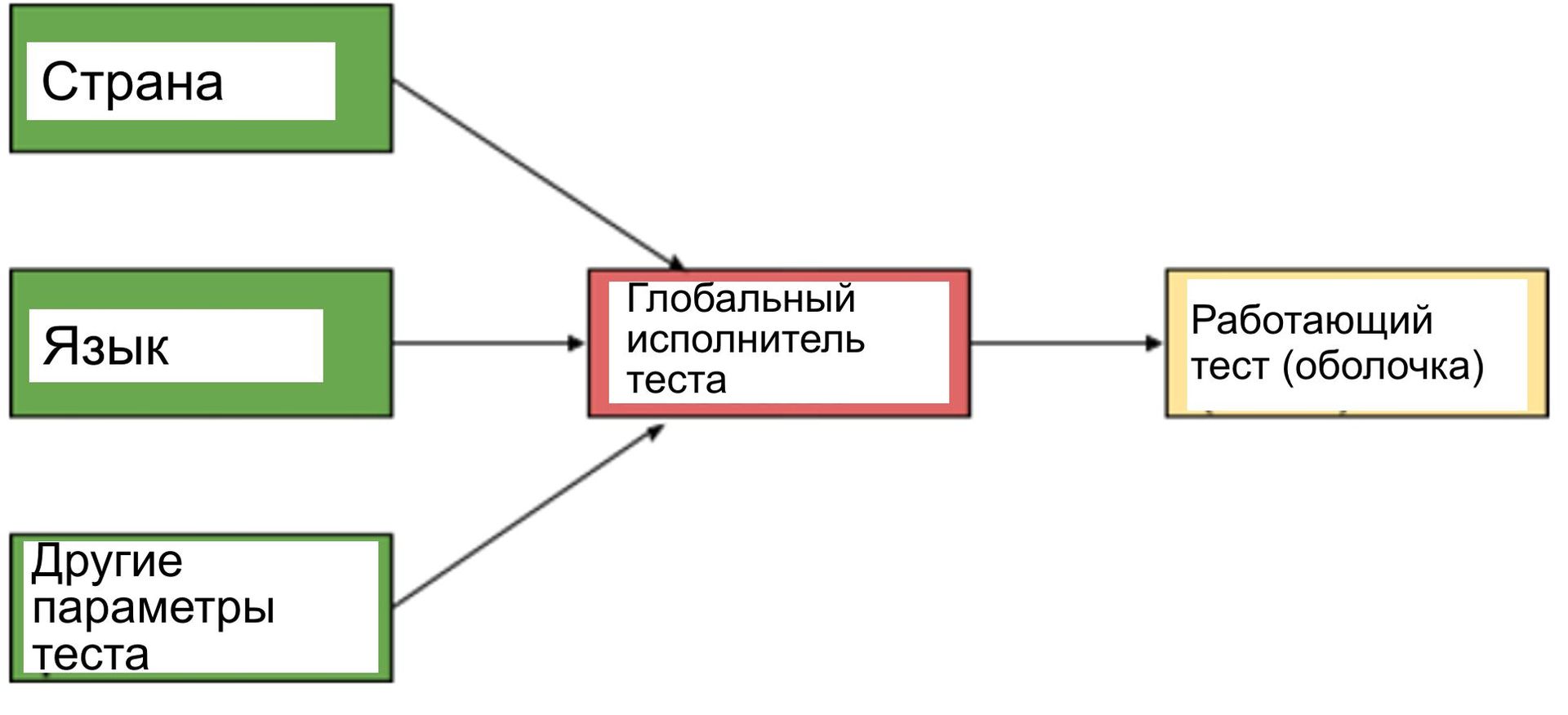
В настоящее время автоматизированные тесты работают глобально, закрывая все высокоприоритетные тестовые наборы интеграции, в т.ч. мониторинг хитов во всех регионах, где такой показ имеется.
Темп введения нового не замедляется на Netflix — он только растёт. Поэтому наш продукт автоматизации продолжает развиваться. Вот некоторые из проектов на нашей дорожной карте:
1. Тесты, основанные на потоке операций. Они должны включать в себя представление тестового набора в виде потока операций или в виде серии шагов, чтобы смоделировать поток данных через воронку услуг Netflix. Побудительным мотивом для этого является снижение затрат на анализ неудач тестов благодаря лёгкой идентификации шага, на котором тест не прошёл.
2. Встраивание предупреждений. В Netflix имеется несколько систем предупреждений. Но включение определённых предупреждений оказывается иногда не имеющим отношения к выполнению соответствующих тестовых комплексов. Это вызывается тем, что тесты зависят от сервисов, которые могут не функционировать на 100% и могут быть вообще неисправными, давая неприменимые для нас результаты. Необходимо создать систему, которая может анализировать эти предупреждения и затем определять, какие тесты должны быть запущены.
3. Учёт беспорядка. Наши тесты в настоящее время предполагают, что среда Netflix функционирует на 100%, но такое не всегда имеет место. Команда специалистов по надёжности постоянно выполняет испытания на разупорядоченность, чтобы тестировать полную целостность системы. В настоящее время результаты автоматизации тестирования в деградировавшей среде показывают интенсивность отказов более 90%. Мы должны улучшить нашу автоматизацию тестирования, чтобы обеспечить соответствующие результаты при работе в деградировавшей среде.
В качестве группы тестирования интеграции разрабатываемых продуктов мы обязаны не снижать скорость введения нового, обеспечивая в то же время контроль качества и быструю обратную связь для разработчиков. Каждая группа разработчиков отвечает за качество поставляемого ею продукта. Нашей задачей является бесперебойная работа с различными техническими группами с упором на сквозную функциональность и координацию деятельности групп. Мы представляем собой небольшую группу специалистов по тестированию интеграции в организации, насчитывающей более 200 разработчиков.
Быстрый ввод новых разработок при необходимости обеспечении требуемого качества создаёт интересные задачи для нашей команды. В настоящей статье мы рассмотрим три такие задачи:
1. Тестирование и мониторинг высокорейтинговых показов (High Impact Title = HIT = хит)
2. A/B-тестирование
3. Глобальный запуск
Тестирование и мониторинг высокорейтинговых показов
Имеется множество высокорейтинговых показов — как, например, телесериал «Оранжевый — хит сезона», которые регулярно появляются на Netflix. Форма и размер этих показов — самые разные. Некоторые являются сериалами, некоторые — отдельными картинами; есть ориентированные только на детей; какие-то выстреливают все серии сезона сразу, а другие выпускают по несколько серий каждую неделю. Часть этих показов запускается со сложными A/B-тестами, в которых каждый элемент теста имеет различное взаимодействие с участником.
Эти показы имеют высокую популярность у наших участников и поэтому должны подвергаться всесторонней проверке. Тестирование начинается за несколько недель до запуска и идёт по нарастающей до самого запуска. После запуска мы отслеживаем эти показы на разных аппаратных платформах во всех странах.
Стратегия тестирования зависит от её фазы. На разных фазах действует разная стратегия продвижения, что делает задачу тестирования/автоматизации довольно сложной. В основном, можно выделить две фазы:
1. До запуска показа. До запуска необходимо обеспечить нахождение метаданных показа в требуемом месте, чтобы в день запуска всё прошло безукоризненно. Поскольку в запуске хита участвует множество групп (команд), то необходимо убедиться, что стыковка всех внутренних (серверных) систем друг с другом и с клиентской частью пользовательского интерфейса происходит безупречно. Продвижение показа осуществляется через Spotlight (большое окно, похожее на доску объявлений, в верхней части главной страницы Netflix), через тизеры и трейлеры. Но поскольку на каждом уровне Netflix имеется персонализация, то необходимо создавать сложные тестовые наборы, чтобы обеспечить соответствие типа показа профилю участника. Поскольку система постоянно изменяется, то автоматизация становится трудной. Основное тестирование на этой фазе происходит вручную.
2. После запуска показа. Наша работа не заканчивается в день запуска. Мы должны постоянно контролировать запущенные показы, чтобы ни в коем случае не допустить ухудшения взаимодействия с участником. Показ становится частью расширенного каталога Netflix, и это само по себе создаёт проблему. Мы должны теперь написать тесты, проверяющие, продолжает ли показ находить свою аудиторию согласованным образом и сохраняется ли целостность данных у этого показа (например, некоторые проверки выясняют, не изменилось ли общее количество серий после запуска; другая проверка контролирует, продолжают ли результаты поиска возвращать показ в надлежащие поисковые строки). Но, имея 600 часов оригинального программирования на Netflix, идущего онлайн только в этом году, дополнительно к лицензированному контенту, мы не можем положиться здесь на ручное тестирование. Также, когда показ запущен, существуют общие предположения, которые мы можем сделать о нём, поскольку данные для этого показа и логика продвижения не будут меняться — например, количество серий больше 0 для ТВ-выпусков, показ доступен для поиска (действительно как для кинофильмов, так и для ТВ-выпусков) и т.д. Это позволяет нам автоматически мониторить, продолжают ли те или иные операции, связанные с каждым показом, работать правильно.
Тестирование хитов является сложной задачей, и оно привязано ко времени. Но участие в запуске показа, отслеживание того, что все связанные с показом функции, серверная логика работают правильно во время запуска, даёт волнующий опыт. Просмотр фильмов со знаменитостями и крутые промо-материалы от Netflix представляют собой также приятную добавку. :)
A/B-тестирование
Мы осуществляем множество A/B-тестов. В каждый момент времени работает много A/B-тестов с различным уровнем сложности.
В прошлом основная часть проверки в A/B-тестах представляла собой комбинацию автоматизированного и ручного тестирования: автоматика использовалась для индивидуальных компонентов (тестирование методом белого ящика), а сквозное тестирование (тестирование методом чёрного ящика) происходило, большей частью, вручную. Когда объём A/B-тестов у нас заметно увеличился, оказалось невозможным вручную осуществлять все требуемые сквозные тесты, и мы начали наращивать автоматизацию.
Одной из главных проблем при введении сквозной автоматизации A/B-тестов стало огромное количество компонентов, подлежащих автоматической обработке. Наш подход состоял в рассмотрении автоматизации тестирования как поставляемого продукта и в сосредоточенности на поставке продукта с минимальным функционалом (minimum viable product = MVP), состоящего из частей, допускающих многократное использование. Нашим требованием к MVP было обеспечение подтверждения базового взаимодействия с участником путём проверки правильности данных от конечных REST-точек различных микросервисов. Это давало нам возможность итерационно двигаться к решению вместо поиска наилучшего решения сразу при старте.
Существенной отправной точкой для нас было создание общей библиотеки, обеспечивающей возможность многократного использования и переназначения модулей для любого автоматизированного теста. Например, у нас был A/B-тест, модифицировавший «Мой список» участника, — при его автоматизации мы написали скрипт, добавлявший показ(ы) в «Мой список» участника или удалявший показ(ы) из этого списка. Эти скрипты были спараметрированы так, чтобы их можно было многократно использовать в любом будущем A/B-тесте, имевшем дело с «Моим списком». Такой подход позволил нам быстрее автоматизировать A/B-тесты благодаря большему количеству многократно используемых компоновочных блоков. Эффективность работы была повышена путём максимально возможного применения уже существующей автоматизации. Например, вместо написания нашей собственной программы автоматизации пользовательского интерфейса мы смогли использовать Netflix Test Studio для переключения между сценариями тестирования, требующими действий со стороны пользовательского интерфейса для различных устройств.
При выборе языка/платформы для внедрения нашей автоматизации мы исходили из необходимости обеспечения быстрой обратной связи для команд разработчиков продукта. Это требовало действительно быстрой работы тестового комплекса — выполнения буквально за секунды. Мы также стремились сделать наши тесты как можно более лёгкими для внедрения и распространения. Имея в виду эти два требования, мы отказались от нашего первого выбора — Java. Наши тесты оказались бы зависимыми от использования множества взаимосвязанных jar-файлов, и пришлось бы заниматься управлением зависимостями, контролем версий, будучи подверженными воздействиям изменений в различных версиях файлового формата JAR. Всё это значительно увеличило бы длительность тестов.
Мы решили ввести нашу автоматизацию, получая доступ к микросервисам через их конечные REST-точки, благодаря чему мы могли бы настраивать использование jar-файлов и не писать какую-либо бизнес-логику. Чтобы обеспечить простоту внедрения и распространения нашей автоматизации, мы решили использовать комбинацию параметризированной оболочки и python-скриптов, которая может быть выполнена из командной строки. Это должен был быть отдельный скрипт оболочки для управления исполнением тестового сценария, в ходе которого должны вызываться другие скрипты оболочки и python-скрипты, действующие как многократно используемые утилиты.
Такой подход имеет несколько положительных моментов:
1. Мы смогли получить длительность теста (включая время на установку и отсоединение) 4-90 секунд; медиана времени работы — 40 секунд. При использовании автоматизации на базе Java медиана времени работы оценочно могла бы быть 5-6 минут.
2. Непрерывная интеграция была упрощена. Всё, что нам требовалось, это система Jenkins Job, которая осуществляет нисходящую загрузку из нашего репозитария, выполняет требуемые скрипты и регистрирует результаты. Встроенный в Jenkins консольный анализ записей оказался достаточным для получения статистики тест «прошёл / не прошёл».
3. Лёгкий запуск. Чтобы сторонний специалист запустил наш тестовый комплекс, требуется только доступ к нашему гит-репозитарию и терминал.
Глобальный запуск
Один из наших самых больших проектов в 2015 году состоял в том, чтобы удостовериться, что мы имели достаточное тестирование интеграции, обеспечивающее гладкий одновременный запуск Netflix в 130 странах. Фактически нам требовалось автоматизировать, как минимум, тестовый комплекс на общую работоспособность для каждой комбинации страны и языка. Это заметно осложнило функциональность нашего продукта автоматизации.
Наши тесты работали довольно быстро, поэтому мы первоначально решили, что достаточно будет запускать тестовую программу в цикле для каждой комбинации страны и языка. Результатом стало то, что тесты, которые проходили примерно за 15 секунд, начали работать по часу и более. Требовалось найти более приемлемый подход к этой проблеме. В дополнение к этому каждый протокол тестирования вырос примерно в 250 раз, что сделало более трудным анализ неудач. Чтобы справиться с этими проблемами, мы сделали два дела:
1. Мы использовали плагин Jenkins Matrix для запараллеливания наших тестов, благодаря чему тесты для каждой страны начали выполняться параллельно. Мы также должны были настроить наши ведомые устройства Jenkins на такое использование разных исполнителей, чтобы другие задания не стояли в очереди, когда наши тесты сталкивались с любой состязательной ситуацией или с бесконечными циклами. Это было выполнимо для нас, потому что у нашей автоматизации были только затраты, связанные с работающими скриптами оболочки, и не было необходимости предварительной загрузки двоичных файлов.
2. Мы не хотели осуществлять рефакторинг каждого теста, написанного до этого момента, и мы не хотели, чтобы каждый тест работал с каждой отдельной комбинацией страна/язык. В результате мы решили использовать модель «по запросу», при которой мы могли продолжать писать автоматизированные тесты так, как мы это делали раньше, а для выведения его на глобальную готовность к нему добавлялась бы надстройка. Эта надстройка должна содержать идентификатор тестового набора и комбинацию «страна/язык» в качестве параметров, а затем должна выполнять тестовый набор с этими параметрами, как показано ниже:
В настоящее время автоматизированные тесты работают глобально, закрывая все высокоприоритетные тестовые наборы интеграции, в т.ч. мониторинг хитов во всех регионах, где такой показ имеется.
Проблемы будущего
Темп введения нового не замедляется на Netflix — он только растёт. Поэтому наш продукт автоматизации продолжает развиваться. Вот некоторые из проектов на нашей дорожной карте:
1. Тесты, основанные на потоке операций. Они должны включать в себя представление тестового набора в виде потока операций или в виде серии шагов, чтобы смоделировать поток данных через воронку услуг Netflix. Побудительным мотивом для этого является снижение затрат на анализ неудач тестов благодаря лёгкой идентификации шага, на котором тест не прошёл.
2. Встраивание предупреждений. В Netflix имеется несколько систем предупреждений. Но включение определённых предупреждений оказывается иногда не имеющим отношения к выполнению соответствующих тестовых комплексов. Это вызывается тем, что тесты зависят от сервисов, которые могут не функционировать на 100% и могут быть вообще неисправными, давая неприменимые для нас результаты. Необходимо создать систему, которая может анализировать эти предупреждения и затем определять, какие тесты должны быть запущены.
3. Учёт беспорядка. Наши тесты в настоящее время предполагают, что среда Netflix функционирует на 100%, но такое не всегда имеет место. Команда специалистов по надёжности постоянно выполняет испытания на разупорядоченность, чтобы тестировать полную целостность системы. В настоящее время результаты автоматизации тестирования в деградировавшей среде показывают интенсивность отказов более 90%. Мы должны улучшить нашу автоматизацию тестирования, чтобы обеспечить соответствующие результаты при работе в деградировавшей среде.
Поделиться с друзьями
Viktor_D
Спасибо за статью. У меня есть вопрос: как вы решали проблему с глобальным тестированием?
В свое время, работая с восточными рынками, мы столкнулись с проблемой, когда местное законодательство, проблемы локализации или местных мобильных операторов, внезапно привносили большую головную боль при работе приложений на каждом конкретном рынке. Мы тогда обращались к crowdtesting-сервисам ( те же Ubertesters, uTest, Moolya) чтобы найти проблему. И сколько, ориентировочно, вам это обошлось?
LukinB
От переводчика: уважаемый «Viktor_D», спасибо за вопрос, но обратите, пож-та, внимание, что это — перевод.