
В конце прошлой статьи Максим maxf75 немного коснулся особенностей расположения разъёмов памяти. Сегодня я расскажу в целом про то, как мы пришли к тому варианту архитектуры и компоновки, над которыми работаем сейчас.
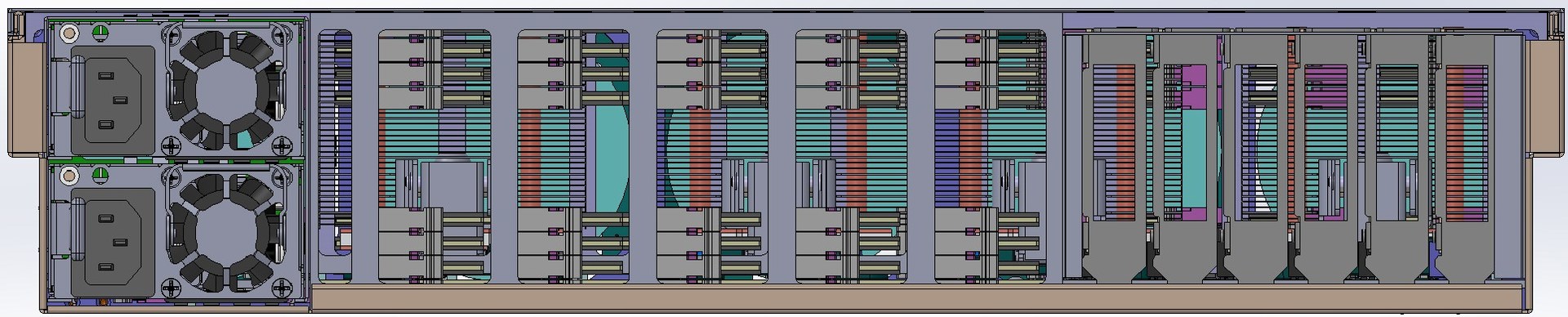
Вид проектируемого сервера сзади со снятой задней решёткой.
При проектировании мы исходили из ключевого требования: обеспечить максимальный объём памяти. Вообще это тема отдельной статьи, как компания занялась разработками на основе OpenPOWER, определила целевые задачи для сервера и пришла к этому требованию. Между остальными публикациями мы расскажем и эту историю. А пока примем за отправную точку проектирования: сервер на основе OpenPOWER с максимальным объёмом памяти.
Надо отметить, что решения, которые доступны на рынке сейчас и которые позволяют обеспечить действительно большой объём памяти, обладают одним существенным недостатком – стоимость сервера в разы превышает стоимость установленной в нём памяти. Именно поэтому мы приняли решение создать сервер, который сломает эту традицию и позволит предоставить в одной машине до 8 ТБ памяти при сохранении низкой общей (насколько это возможно вообще учитывая стоимость собственно 8 ТБ DDR4) стоимости решения.
Вместе с целью максимизации объёма памяти сразу возникло стремление обеспечить высокую плотность – иногда это оказывается важным фактором, определяющим конкурентное преимущество при сравнении с другими серверами. После пары недель размышлений и прикидок на бумажках у меня возникло ощущение, что мы сможем уложить все это в стандартное 19” шасси высотой 2U.
Память
Учитывая целевой объём памяти и общее количество планок, её размещение — определяющий фактор при построении компоновки сервера. Понятно, что разместить 128 модулей DIMM на системной плате просто невозможно как исходя из банальной геометрии (плата будет гигантских размеров), так и исходя из требований Signal Integrity. Очевидно, что для упихивания нашего количества памяти нужно делать вертикально размещаемые в шасси райзеры, которые подключаются к системной плате. На райзерах необходимо разместить коннекторы под DIMM’ы и буфер памяти Centaur, который содержит кэш и обеспечивает доступ процессора к памяти (один процессор поддерживает до 4-х буферов памяти).
Первая идея компоновки райзера подразумевала размещение модулей с одной стороны, а буфера памяти сбоку рядом с ними, как на картинке. Но, во-первых, мы уперлись в ограничение по длине трасс от буфера к DIMM’ам, а во-вторых поняли, что будут проблемы с их выравниванием.

Первоначальная схема компоновки райзера памяти
Пришлось делать иначе — размещать чип буфера памяти между двумя группами DIMM’ов. Сначала было немножко неочевидно, пройдет ли такое решение по высоте, но аккуратно посчитав высоту райзера, мы поняли, что при размещении компонентов с минимальными допусками получившаяся плата как раз по высоте проходит между дном и крышкой 2U-корпуса. Таким образом, коннектор для подключения к системной плате необходимо было вынести вбок, и райзер получился таким:

Плата сложная, 18 слоев.
Локальное хранилище и вентиляторы охлаждения
Дальше занялись построением общей компоновки сервера. Традиционно в передней части шасси располагаются диски для локального хранилища. Для шасси высотой 2U наиболее стандартными вариантами являются либо 24 ? 2.5”, либо 12 ? 3.5”. Мы выбрали первый – 3.5” диски нас в данном проекте не сильно интересуют, поскольку мы ориентируемся скорее на SSD.
Позади дисков классически размещаются вентиляторы — тут тоже не было особенных вопросов: поставили 5 вентиляторов распространённого размера 80 ? 38 мм – собственно, максимум, который помещался по ширине. Тут тоже были задачи, с которыми пришлось повозиться – при размещении пяти вентиляторов практически не остается места под коннекторы (необходимо же обеспечить возможность их замены на ходу). Выкрутились, найдя очень компактные коннекторы и разместив их фактически в объёме, занимаемом самими вентиляторами.
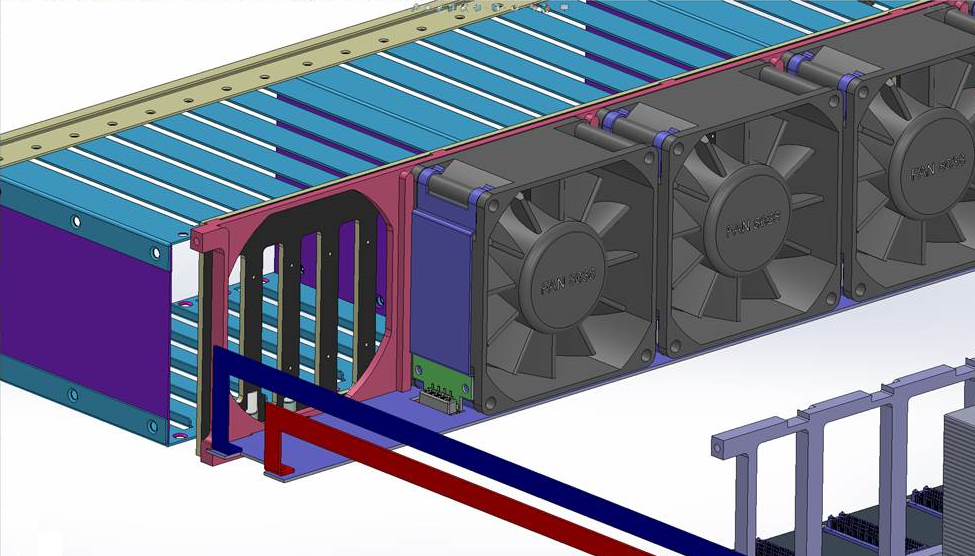
Подключение вентиляторов. Для удобства отображения скрыт ближний вентилятор и ближняя направляющая рамка.
Вентиляторы подключаются к лежащей под ними плате, которая разводит линии питания и управления оборотами. У каждого вентилятора свой канал управления. На картинке видны шины питания, ведущие к плате — они проходят вдоль левой стороны сервера, если развернуть его блоками питания к себе. По правой стороне проходит шлейф для передачи управляющих сигналов ШИМ от системной платы.
С подключением локальных дисков тоже все не так просто. Нам очень нравится стандарт NVMe, и мы в целом считаем, что за ним будущее. Какие бы новые типы памяти не появились в обозримом периоде (тот же 3D-XPoint от союза Intel и Micron), скорее всего они найдут применение и в варианте NVMe дисков, поскольку PCI Express сегодня является наиболее коротким путем подключить что бы то ни было к процессору (да, мы знаем про NV-DIMM, но это очень дорогой компромисс, который к тому же отъедает ценные для нас слоты под память). С другой стороны, нам бы не хотелось окончательно и бесповоротно отказываться от поддержки SAS/SATA. Эти соображение достаточно логичным образом привели нас к решению о том, что на системной плате мы будем размещать коннекторы, позволяющие нам вывести шину PCI Express кабелем к дисковым контроллерам, будь то коммутатор PCI Express или SAS HBA/RAID контроллер.
В качестве наиболее подходящей для нас пары разъём-кабель было выбрано решение NanoPitch от Molex (на самом деле это просто реализация активно продвигаемого PCI SIG стандарта OCuLink). Кабели для внутренних подключений достаточно компактны и позволяют по одному кабелю прокидывать до 8 лэйнов PCIe Gen3.
Дальше возник вопрос о том, а где собственно размещать дисковые контроллеры. На бэкплэйне, к которому подключаются диски, сделать это просто невозможно (чипы что SAS-контроллеров, что PCIe коммутаторов слишком большие для этого). После внимательного изучения размеров дисков, максимально допустимой высоты шасси и проработки разных вариантов конструкции дисковых треев стало понятно, что в целом есть возможность разместить плату с контроллерами над дисками. Такое размещение, во-первых, упрощает её подключение к дисковому бэкплейну (можно применить стандартные CardEdge коннекторы), а во-вторых, позволяет снизить высоту дисковых треев за счет отказа от световодов и размещения всей индикации на плате контроллера.
В итоге получилась такая схема подключения:
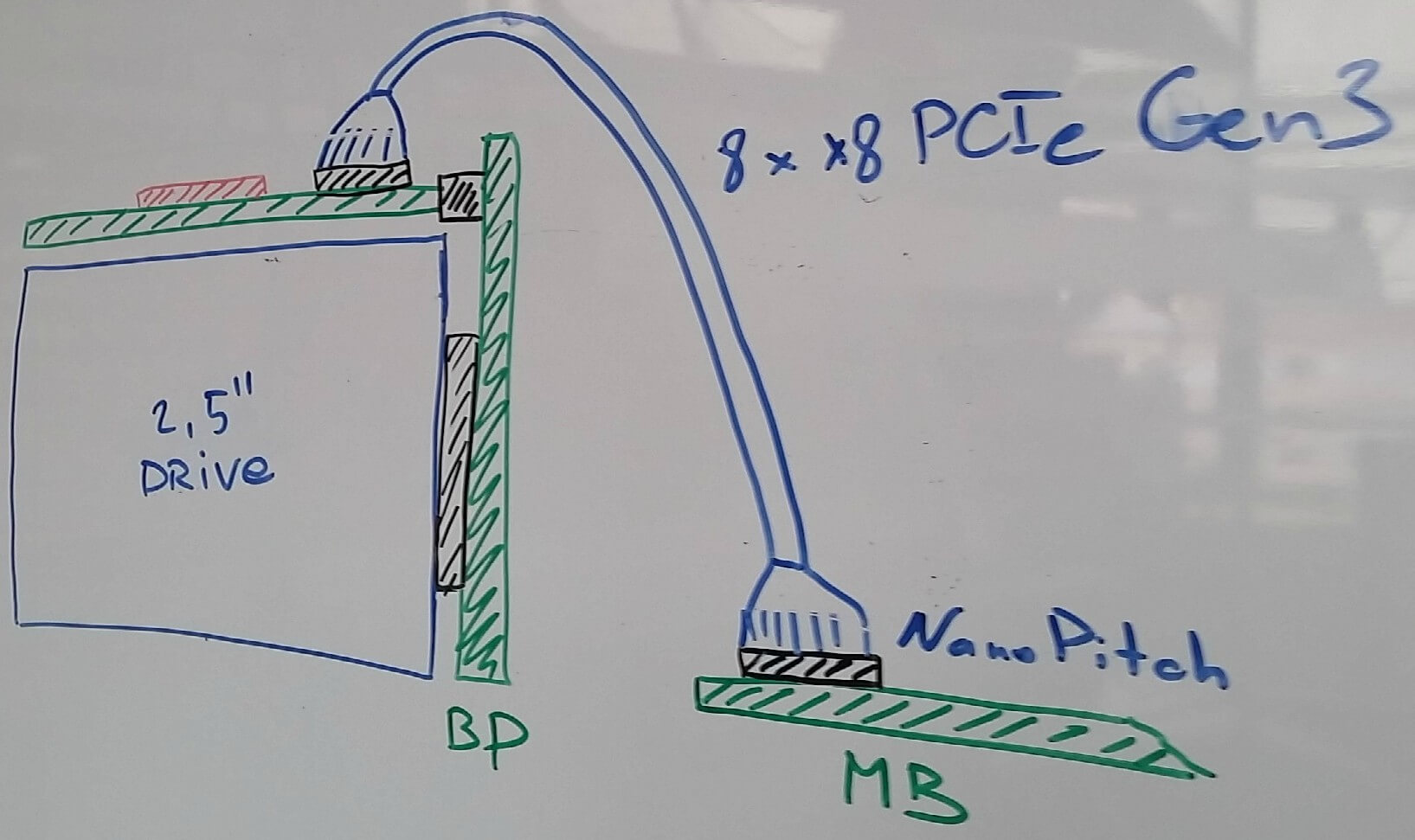
Для разнообразия — художества от руки. Схема подключения дисков. Магнитная доска, маркеры, 2016 год.
Плата с PCIe-коммутатором или SAS-контроллером располагается над дисками, подключается к системной плате кабелем. Сама плата подключена к дисковому бэкплейну, в который воткнуты диски.
Блоки питания
Блоки питания обычно ставят в левом или правом заднем углу корпуса. Нам было удобнее, исходя из дизайна PDB (Power Distribution Board), расположить их в левом (если смотреть сзади). Блоки питания решили использовать стандарта CRPS, основными преимуществами которого являются высокая удельная мощность блоков питания (2 кВт уже сегодня, до 2,4 – почти завтра), высокий КПД, а самое главное — это не какой-то проприетарный стандарт одного вендора, а стандарт, инициатором которого был в свое время Intel и который был поддержан значительным количеством компаний. Два двухкиловаттных блока питания в нашем случае расположены друг над другом.
Ещё немного про память
Поскольку на каждом райзере мы размещаем по одному буферу памяти и по 8 DIMM’ов (максимально поддерживаемое Centaur’ом количество), то получается, что нам требуется четыре райзера на процессор, то есть всего 16 в шасси. Исходя из высоты стандартных модулей DDR4 RDIMM в ширину таких райзеров в шасси можно разместить не более 11 (да и то, приходится использовать Ultra-low seating DIMM-сокеты и ужиматься, считая десятые доли миллиметров). Поэтому ещё 5 райзеров пришлось поставить в другое место, на заднюю часть системной платы. Собственно, это и привело в итоге к разворачиванию одного процессора на 180 градусов (последняя Ктулху-картинка в прошлой статье). Учитывая высоту наших райзеров памяти от дна до крышки сервера, к ограничениям формы системной платы добавился ещё один вырез.
После этого осталось только разместить разъёмы для стандартных карт PCI Express, количество которых однозначно определилось свободным местом. Получилось разместить 5 слотов, плюс отдельный коннектор для платы менеджмента (для разгрузки системной платы мы решили вынести на отдельную карту BMC, USB и Ethernet — всё это поместили на отдельную небольшую плату, которая устанавливается в тот самый шестой разъём).
Общая схема
В итоге получилась такая картина расположения компонентов (вид сверху, плата с контроллерами над дисками не показана, чтобы диски не заслонять):
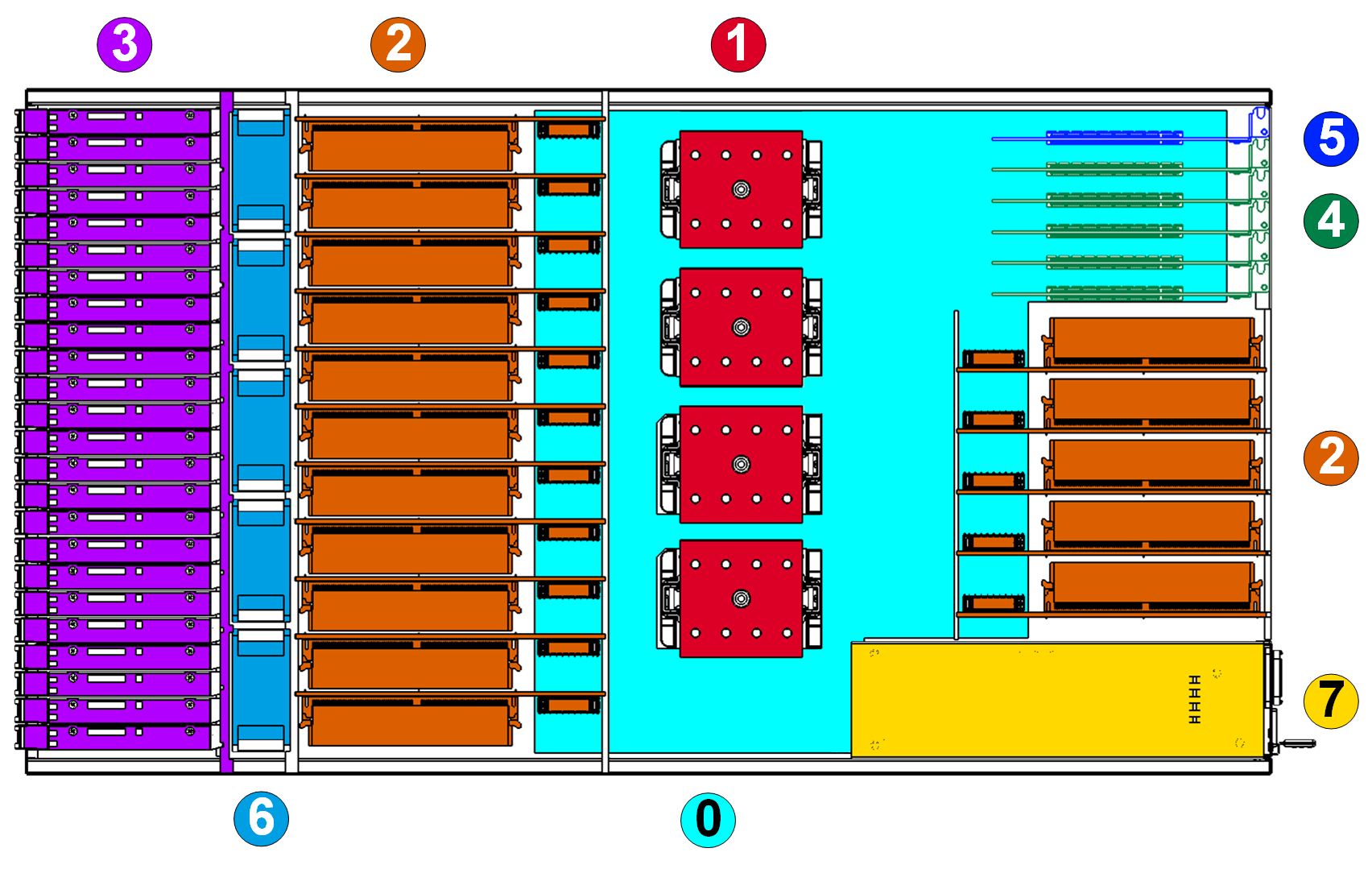
Легенда:
0. Системная плата.
1. Процессоры IBM POWER8 SCM Turismo.
2. Райзеры памяти с DIMM’ами.
3. 24 ? 2.5” диска и дисковый бэкплейн
4. Слоты для карт расширения (поддерживаются только HHHL, то есть низкопрофильные карты).
5. Плата управления.
6. Вентиляторы системы охлаждения.
7. Блоки питания.
Вот эти соображения, которые я описал, и определили облик сервера. Итого: стандартное 19” шасси высотой 2U, 4 сокета для процессоров POWER8, 16 разъёмов для райзеров с планками памяти (всего до 128 модулей DIMM во всём сервере, по 8 на каждом райзере), 5 стандартных PCI Express слотов для карт расширения и одна карта управления.
Комментарии (55)

Paging
02.09.2016 13:52Да, конструкция конечно плотная. Моделирование по теплу для этой системы не делали, а в прошлом для этих целей обычно пользовались SolidWorks Flow Simulation.
Насчет охлаждения — сдували и больше, к тому же тут на нас работает то, что все источники тепла очень равномерно распределены по объему шасси. Пока верхняя оценка реального потребления где-то порядка 800Вт на 1U (1.6кВт на систему).

Nordicx86
02.09.2016 15:19+1обслуживание моделировали? тк то что я вижу модули памяти висят на коннекторе
дальний блок памяти он не сгорит от перегрева?
блок PCIe — тоже не понятно что вы туда предлагаете ставить? 10G/40G/100G платы? а охлаждение то хватит на них? а питания? просто там ОЧЕНЬ узко и например FPGA или SSD там будут жарится — и да вы туда доп. питание заложили?
на плате есть возможность подключение дополнительных нагрузок(5v и 12v)?
Радиатор Процессора — продувка «поперек» термотрубок?(последняя пара будет работать хуже первой из-за другой «дельты») я бы повернул и сделал термотрубки разного диаметра ну или сильно увеличил «теплорассеиватель»прилегающий к процессору.Paging
02.09.2016 15:27+1Модули не висят на коннекторах, у них есть опора на дно полки (сразу же скажу, что дно провисать не будет — есть силовые элементы к которым оно крепится). От перегрева ничего не сгорит, хотя конечно дальний блок памяти действительно будет иметь режим гораздо хуже, чем передний.
В PCIe предполагаются адаптеры, ограниченные 25Вт мощности — сетевые контроллеры, SAS HBA/RAID или наш собственный адаптер для вывода PCIe через кабель (про него наверное отдельно напишем статью вскорости, там много интересных заморочек).
Нет, плата не предполагает подключение дополнительных нагрузок — сервер рассчитан на вполне определенный спектр применений, и GPU туда ставить никто не будет конечно же.
Для радиатора такое расположение, как на иллюстрации, является штатным, более того, на 90 градусов его разворачивать просто нельзя — боковые поверхности у него закрыты.Nordicx86
02.09.2016 15:46в этот сервак так и просятся FPGA типа таких http://www.nallatech.com/solutions/fpga-cards/
да и сетевки и RAID сейчас ОЧЕНЬ не плохо греютсяPaging
02.09.2016 16:11Карты на FPGA можно ставить, просто надо тесты проводить, и, возможно, придется ставить на них пассивные радиаторы двойной высоты (занимая тем самым одной картой два слота). Встроенные в полку вентиляторы позволяют обеспечить приличный продув, мы надеемся что не потребуется разгонять их на 100% (шумно очень будет).
Nordicx86
05.09.2016 14:54не свосем правильное предложение, но что в нем есть:
1. разделить пару блоков питания и разнести на разные стороны сервера
2. сместить «задний» блок памяти к середине сервера
3. разделить блок PCIe на два блока по три слоат и поставить посторонам от блока памяти
просто вот мне так кажется что с теплом будет у вас проблема… просто представляю эту гирлянду из проводов состороны PCI-e — даже при ОЧЕНЬ аккуратном монтаже продувка сильно осложнится.
может и наоборот стоит сделать PCI-e в середину им не так критично — память «побокам»…Paging
05.09.2016 15:21На самом деле такой вариант можно сразу же отклонить по одной причине — блоки питания в шасси лежат горизонтально и ширина каждого меньше чем удвоенная высота, то есть с точки зрения использования объема разделять их и ставить вертикально по сторонам шасси не имеет смысла (если даже не брать все остальные неприятности которые это вызовет).
Кстати, а что за гирлянда из проводов, пардон?
lelik363
04.09.2016 22:32Контроллер(плату) SAS HBA/RAID свою делать будите или готовое решение?
Paging
04.09.2016 22:39Свою (если мы про внутренние диски) — готовое там сложно уложить. Но приоритет за NVMe, так что SAS чуть позже.
lelik363
04.09.2016 22:44Про внутренние. На чем будите делать?
Paging
04.09.2016 22:56Пока не скажу однозначно — это еще вопрос к обсуждению. Серийность у нас не сильно большая, поэтому с LSI/Avago/Broadcom работать тяжело. Adaptec/PMCS/Microsemi в этом плане ребята гораздо более гибкие. NVMe сейчас в дизайне на PCIe свичах от PMCS/Microsemi.


Greendq
02.09.2016 15:44Это же сколько времени память тестировать, даже если она ECC? Сколько «взлетает» сервер?

SemenovNV
02.09.2016 15:46+1Разминулись с Вами в комментариях на несколько минут — чуть выше написал только что. In-Memory вычисления и базы данных — очень актуальная и полезная тема. :) На Хабре про них довольно много писали.
Greendq
02.09.2016 15:52Я прочитал ваш комментарий буквально секунду спустя после публикации своего. Поэтому отредактировал свой :)
Paging
02.09.2016 15:50Долго :) А еще можно прикинуть например сколько база такого объема будет подниматься в память — и сразу становится понятно, почему мы так активно за NVMe. Есть такие базы, у людей есть реальная потребность. Можно например посмотреть презентации с In-Memory Computing Summit этого года.
Greendq
02.09.2016 15:53И я так понимаю, что спрашивать о стоимости полностью нафаршированного оперативкой и SSD сервера будет неприлично? Ну порядок хотя бы намекните — чтобы пооблизываться, не покупать. :)
Paging
02.09.2016 16:27Про конкретную стоимость я ничего не скажу — я техникой занимаюсь, возможно кто-то из коллег и прокомментирует. Но светлый (для нас) момент во всем этом заключается в том, что стоимость альтернатив, судя по всему, гораздо выше.
FpcFrag
02.09.2016 16:55Что бы освободить 6-й слот PCI вынесите всякий USBm BMC и прочие разъёмы на выносную планку (жестко закреплённую) позади заднего юлока памяти. Хоть поперёк. И да, прямо за пределы корпуса сервера.
Или же можно сдвинуть пару слотов память поглубже внутрь и разместить на ними но уже внутри корпуса.
Enjoy!Paging
02.09.2016 16:58Мы много вариантов рассматривали, предложенный плох тем, что во-первых мы будем иметь проблемы с подключением (для подключения этого райзера требуется приличное количество сигналов), и во-вторых — будет портить продуваемость всей конструкции.
На самом деле все проще — шестой слот нам ставить смысла нет поскольку даже с пятью все возможности процессоров по PCIe уже утилизированы на 100%. Для шестого слота пришлось бы ставить PCIe-свич где-то, чего совсем не хочется (да и места откровенно нет).FpcFrag
02.09.2016 18:42использование слота не всегда означает его утилизацию на 100%
для нормальной отказоустойчивости все платы в PCI должны дублироваться.
итого вы можете разместить только 2 типа плат (FC + Ethernet, например) и 1 слот останется свободным.
а если вам нужно FC + Ethernet оптический + медный, то нужно уже 6 слотов.Paging
02.09.2016 20:04На самом деле для случая когда надо подключить много всего и с полным дублированием у нас тоже есть решение, про него позже будем рассказывать.
Ну и невозможно же объять необъятное, т.е. сделать совершенно универсальную машину. По PCIe мы сильно ограничены возможностями по бифуркации портов которые есть у процессоров — и там в общем-то небогато очень, или два порта x16 или один x16 + два x8 на каждый сокет.
czed
02.09.2016 20:05+1Дублирование обычно делают на уровне серверов а не плат в шасси. Это более рационально, так как вероятность падежа целого шасси намного выше отказа какой-то конкретной PCIe платы расширения (который как правило тоже приводит к падежу системы).
lelik363
03.09.2016 21:58Как будет реализована плата менеджмента? Интересует аппаратное и протокольное решение.
Paging
03.09.2016 22:00В текущий момент (я думаю вопрос же именно про BMC, а не про то, какой именно там GBE или USB контроллер будет стоять) там стоит AST2400 плюс FW стек на базе OpenBMC, который будем сильно допиливать (и коммитить в OpenBMC по мере реализации интересного функционала).
lelik363
03.09.2016 23:09Да, речь о BMC.
Какие функции на него будут возложены, если не секрет?Paging
03.09.2016 23:37Все достаточно стандартно для серверов — мониторинг всего и всея, менеджмент системы (управление питанием, системой охлаждения и т.п.), ведение логов, консольный доступ к системе.
Более детально мог бы подсказать мой коллега, но он в отпуске в ближайшие две недели.
Вас какие-то конкретные вещи интересуют? Думаю на конкретные вопросы будет проще ответить, чем в целом описывать весь функционал.

lostinfuture
02.09.2016 19:15+2Интересный способ организации модулей памяти применен в пятьсот восьмидесятых пролиантах. Там используются
картриджи
Paging
02.09.2016 20:05Да, про что-то подобное мы тоже думали. Но победил в итоге именно тот вариант на котором остановились.
Arxitektor
02.09.2016 20:26Жаль что IBM не делает дескопные чипы.
Думаю интелу бы нес утёрли.
Ведь у них вроде уже вышел 9 чип (IBM POWER8)?Paging
02.09.2016 20:33+2POWER9 только готовят к релизу. Я думаю что с десктопами все было бы очень неоднозначно — да и кому сегодня сильно интересен процессор в десктопе, разве что фанатам-геймерам. Перфа современных процессоров более чем достаточно для большей части бытовых применений.

Wicron
02.09.2016 21:23Если не секрет, кто будет заниматься мануфактурингом и как прошел процесс согласования поставок IBM процессоров?
Paging
02.09.2016 21:31Сервер состоит из множества компонентов (шасси, шины питания, несколько типов плат, стандартные компоненты — блоки питания, вентиляторы и т.п.) — соответственно и контрактных производителей много. Даже разные платы будут делаться в разных местах (обусловлено ценой, нет смысла просить фабрику которая качественно делает материнские платы произвести примитив типа PDB или fan midplane). Сборка — в РФ.
С поставками процессоров в рамках OpenPOWER нет никаких проблем.
Wicron
02.09.2016 23:11С чем связан выбор именно такого поля действий — openPOWER, сборка в РФ и контрактники за пределами страны по всему миру? Как достигается бизнес-превосходство? Это что-то для внутреннего потребителя?
Paging
02.09.2016 23:40+1В РФ тяжело собирать сложные платы. Во-первых, сами PCB нужного качества у нас пока не делают за вменяемые деньги, во-вторых, никто не держит стоки тех компонентов что нам нужны, а это значит закупку под каждый заказ, в третьих — монтаж плат это не просто станок для установки компонентов и печка, это еще и тулинг для специфических компонентов, пайка в азотной среде и т.п. Это к вопросу почему пока не все делается у нас. Кстати, простые платы вполне может быть и здесь будем собирать.
Превосходство достигается техническими преимуществами решения, которые в свою очередь дают коммерческие преимущества перед аналогичными решениями.
Wicron
02.09.2016 23:57Что касается бизнеса, откуда ноги растут? Вы раньше занимались контрактной разработкой, а теперь хотите попробовать стать вендором? Мне очень нравится то, что вы пишете и как делаете. Есть ли шанс просто пересечься в Москве и поговорить? Стройте свое дело вокруг политики и желаю попасть вам под крыло влиятельной компании, если хотите продавать тут. На вашем пути груда бюрократии, несправедливости, которую если проигнорить, она затмит то, что собираетесь делать.
То, что описано здесь, очень дорого в малых партиях, скорее всего все завязано на серию от 1000 штук и выше. Было бы интересно узнать, какой уровень цен соответствует выпуску именно прототипа.SemenovNV
03.09.2016 00:14Мы среди прочих тем отдельно расскажем про компанию некоторое время спустя (ближайшие несколько недель многие ключевые сотрудники будут в разъездах, и писать будем менее регулярно, скорее всего). А чтобы это лучше соответствовало специфике Хабра, заодно расскажем и про приход в OpenPOWER, и придём к определению требований к серверу (с которых и начали эту статью). Тем более, что эти вопросы связаны между собой.
Насчёт возможности встретиться и поговорить — можно будет посмотреть где-то ближе к началу октября, когда упомянутый период разъездов будет позади. А Вы на решении каких задач специализируетесь?Wicron
04.09.2016 11:09В своем вопросе я больше имел в виду, где вас можно увидеть физически, выставка, выступление — в этом плане.
Мы занимаемся робототехникой, но мои вопросы не связаны с нашей деятельностью. Мне было интересно понять, как у вас планируется организация продаж здесь, ведь судя по бизнес-плану, вы хотите как-то хитро решить задачу появления тут альтернативного серверного оборудования, которое будучи локализованным по сборке тут, будет дешевле в силу планируемого повышения пошлин. Если у вас нет политических тылов и вы хотите из R&D вендором победить с помощью технологий, особенно в этой стране, ваш ждет глубочайшее в жизни разочарование.lelik363
04.09.2016 14:22Это конечно не мое дело, но стоит погуглить словосочетание «Национальная компьютерная корпорация» (НКК), а затем посмотреть ее структуру, то много становится понятным.
Wicron
04.09.2016 20:09Я упрощу остальным и дам сразу ссылку, откуда ноги растут:
www.ncc.ruWicron
04.09.2016 20:16Ходят слухи, что делаете под Сбербанк, расскажите, как удалось реально продать сберу.
lelik363
04.09.2016 22:03Как в этой большой конструкции будет происходить соединение шасси и сигнальной «земли»?
czed
04.09.2016 22:14Скорее всего также как и в любой другой компьютерной технике — монтажными винтами и рамками плат расширения.
Paging
04.09.2016 22:19Есть две религии. Первая говорит соединять шасси только с PE и нигде гальванически не соединять с низковольтным питанием внутри. Вторая же за обратное — соединять с сигнальной землей везде, где только можно. Мы адепты второго пути — начиная с PDB везде где только можно шасси соединяется с сигнальной землей, в основном конечно через винты и пэды на платах. Соединение с PE реализуется естественным образом через контакт корпусов источников питания с корпусом.
murz165
Спасибо за интересную статью. Создается впечатление, что очень плотненькая конструкция и ее будет тяжело охлаждать. Производился ли расчет теплового режима, если да, то какие инструменты вы используете, если не секрет?
Paging
Пардон, случайно ответил ниже, не в треде.