

Городская библиотека Стокгольма. Фото minotauria.
В этой статье я хочу рассказать о том, что оценивать время обращения к памяти как O(1) — это очень плохая идея, и вместо этого мы должны использовать O(vN). Вначале мы рассмотрим практическую сторону вопроса, потом математическую, на основе теоретической физики, а потом рассмотрим последствия и выводы.
Введение
Если вы изучали информатику и анализ алгоритмической сложности, то знаете, что проход по связному списку это O(N), двоичный поиск это O(log(N)), а поиск элемента в хеш-таблице это O(1). Что, если я скажу вам, что все это неправда? Что, если проход по связному списку на самом деле O(NvN), а поиск в хеш-таблице это O(vN)?
Не верите? Я вас сейчас буду убеждать. Я покажу, что доступ к памяти это не O(1), а O(vN). Этот результат справедлив и в теории, и на практике. Давайте начнем с практики.
Измеряем
Давайте сначала определимся с определениями. Нотация “О” большое применима ко многим вещам, от использования памяти до запущенных инструкций. В рамках этой статьи мы O(f(N)) будет означать, что f(N) — это верхняя граница (худший случай) по времени, которое необходимо для получения доступа к N байтов памяти (или, соответственно, N одинаковых по размеру элементов). Я использую Big O для анализа времени, но не операций, и это важно. Мы увидим, что центральный процессор подолгу ждет медленную память. Лично меня не волнует, что делает процессор пока ждет. Меня волнует лишь время, как долго выполняется та или иная задача, поэтому я ограничиваюсь определением выше.
Еще одно замечание: RAM в заголовке означает произвольный доступ (random memory accesses) в целом, а не какой-то конкретный тип памяти. Я рассматриваю время доступа к информации в памяти, будь это кэш, DRAM или swap.
Вот простая программа, которая проходит по связному списку размером N. Размеры — от 64 элементов до 420 миллионов элементов. Каждый узел списка содержит 64-битный указатель и 64 бит данных. Узлы перемешаны в памяти, поэтому каждый доступ к памяти — произвольный. Я измеряю проход по списку несколько раз, а потом отмечаю на графике время, которое понадобилось для доступа к элементу. Мы должны получить плоский график вида O(1). Вот что получается в реальности:
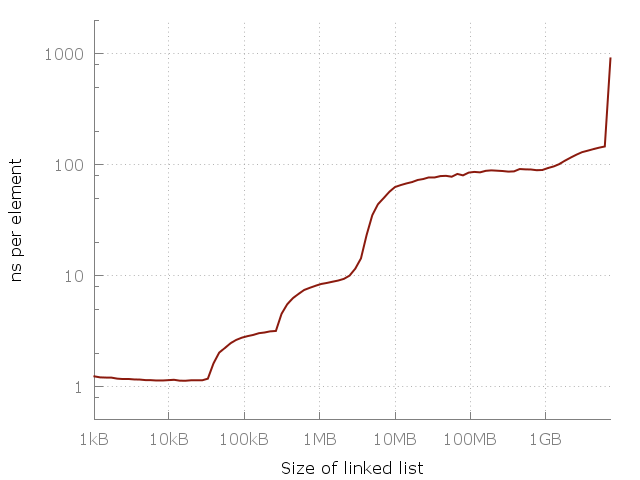
Сложность доступа к элементу в связном списке. Доступ к произвольному элементу в 100-мегабайтном списке примерно в 100 раз медленнее, чем доступ к элементу в 10-килобайтном списке.
Заметьте, что это в этом графике используется логарифмическая шкала на обоих осях, так что разница на самом деле громадная. От примерно одной наносекунды на элемент мы дошли до целой микросекунды! Но почему? Ответ, конечно, это кэш. Системная память (RAM) на самом деле довольно медленная, и для компенсации умные компьютерные проектировщики добавить иерархию более быстрых, более близких и более дорогих кэшей для ускорения операций. В моем компьютере есть три уровня кэшей: L1, L2, L3 размером 32 кб, 256 кб и 4 мб, соответственно. У меня 8 гигабайт оперативной памяти, но когда я запускал этот эксперимент, у меня было только 6 свободных гигабайт, так что в последних запускал был своппинг на диск (SSD). Вот тот же график, но с указанием размеров кэшей.
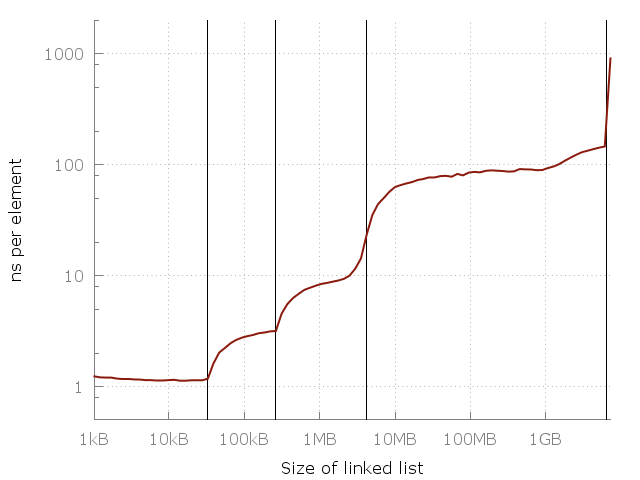
Вертикальные линии указывают на L1 = 32 кб, L2 = 256 кб, L3 = 4 мб и 6 гигабайт свободной памяти.
На этом графике видна важность кэшей. Каждый слой кэша в несколько раз быстрее предыдущего. Это реальность современной архитектуры центрального процессора, будь это смартфон, лаптоп или мэйнфрейм. Но где здесь общий паттерн? Можно ли поместить на этот график простое уравнение? Оказывается, можем!
Посмотрим внимательнее, и заметим, что между 1 мегабайтом и 100 мегабайтами примерно 10-кратное замедление. И такое же между 100 мегабайтами и 10 гигабайтами. Похоже, что каждое 100-кратное увеличение использованной памяти дает 10-кратное замедление. Давайте добавим это на график.
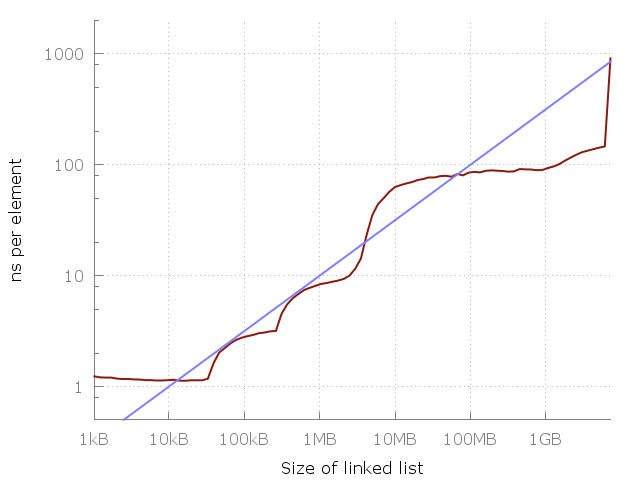
Голубая линия это O(vN).
Голубая линия это график указывает на O(vN) стоимость каждого доступа к памяти. Кажется, отлично подходит, да? Конечно, это моя конкретная машина, и на вашей картина может выглядеть иначе. Тем не менее, уравнение очень легко запомнить, так что, может быть, его стоит использовать как грубое правило.
Вы, наверное, спрашиваете, а что там дальше, правее графика? Продолжается ли повышение или график становится плоским? Ну, он становится плоским на некоторое время, пока на SSD есть достаточно свободного места, после чего программе придется переключиться на HDD, потом на дисковый сервер, потом на далекий дата-центр, и так далее. Каждый скачок создаст новый плоский участок, но общая тенденция на повышение, думаю, продолжится. Я не продолжал свой эксперимент из-за нехватки времени и отсутствия доступа к большому дата-центру.
“Но эмпирический метод нельзя использовать для определения границ Big-O”, — скажете вы. Конечно! Может быть, есть теоретическая граница у задержки при доступе к памяти?
Круглая библиотека
Позвольте описать мысленный эксперимент. Допустим, вы — библиотекарь, работающий в круглой библиотеке. Ваш стол — в центре. Время, необходимое вам для получения любой книги, ограничено расстоянием, которое нужно пройти. И в худшем случае это радиус, потому что нужно дойти до самого края библиотеки.
Допустим, ваша сестра работает в другой подобной библиотеке, но у нее (у библиотеки, не сестры :), — прим. пер.) радиус в два раза больше. Иногда ей нужно пройти в два раза больше. Но у ее библиотеки площадь в 4 раза больше, чем у вашей, и в ней помещается в 4 раза больше книг. Количество книг пропорционально квадрату радиуса: N? r?. И так как время T доступа к книге пропорционально радиусу, то N? T? или T?vN или T=O(vN).
Это грубая аналогия с центральным процессором, которому нужно получить данные из свой библиотеки — оперативной памяти. Конечно, скорость “библиотекаря” важна, но тут мы ограничены скоростью света. Например, за один цикл 3-гигагерцового процессора свет преодолевает расстояние 10 см. Так что для похода туда и обратно, любая мгновенно доступная память должна быть не дальше 5 сантиметров от процессора.
Хорошо, сколько информации мы можем разместить в рамках определенного расстояния r от процессора? Выше мы говорили о круглой плоской библиотеке, но что, если она будет сферической? Количество памяти, которая поместится в сферу, будет пропорциональна кубу радиуса — r?. В реальности компьютеры достаточно плоские. Это отчасти вопрос форм-фактора и отчасти вопрос охлаждения. Возможно, когда-нибудь мы научимся строить и охлаждать трехмерные блоки памяти, но пока практическое ограничение количества информации N в пределах радиуса r будет N ? r?. Это справедливо и для совсем далеких хранилищ, вроде дата-центров (которые распределены по двумерной поверхности планеты).
Но можно ли, теоретически, улучшить картину? Для этого нужно немного узнать про черные дыры и квантовую физику!
Теоретическая граница
Количество информации, которую можно поместить в сфере радиусом r, можно вычислить с помощью границы Бекенштейна. Это количество прямо пропорционально радусу и массе: N ? r·m. Насколько массивна может быть сфера? Ну, что является самым плотным во вселенной? Черная дыра! Оказывается, что масса черной дыры пропорциональна радиусу: m ? r. То есть количество информации, которую можно поместить в сфере радиусом r это N ? r?. Мы пришли к выводу, что количество информации ограничено площадью сферы, а не объемом!
Вкратце: если попытаться засунуть очень большой кэш L1 в процессор, то он в конце концов схлопнется в черную дыру, что помешает вернуть результат вычисления пользователю.
Получается, что N ? r? это не только практическая, но и теоретическая граница! То есть законы физики устанавливают лимит на скорость доступа к памяти: чтобы получить N битов данных, нужно передавать сообщение на расстояние, пропорциональное O(vN). Иными словами, каждое 100-кратное увеличение задачи ведет за собой 10-кратное увеличение времени доступа к одному элементу. И именно это показал наш эксперимент!
Немного истории
В прошлом процессоры были намного медленнее памяти. В среднем, поиск по памяти был быстрее самого вычисления. Распространенной практикой было хранить в памяти таблицы для синусов и логарифмов. Но времена изменились. Производительность процессоров росла намного быстрее скорости памяти. Современные процессоры большую часть своего времени просто ждут память. Именно поэтому существует столько уровней кэша. Я считаю, что эта тенденция будет сохраняться еще долгое время, поэтому важно переосмыслить старые истины.
Вы можете сказать, что вся суть Big-O в абстракции. Она необходима, чтобы отвязаться от таких деталей архитектуры как задержка памяти. Это верно, но я утверждаю, что O(1) это неправильная абстракция. В частности, Big-O нужно для абстракции константных множителей, но доступ к памяти это не константная операция. Ни в теории, ни в практике.
В прошлом любой доступ к памяти в компьютерах был одинаково дорогим, поэтому O(1). Но это больше не так, и уже достаточно давно. Я считаю, что пора думать об этом иначе, забыть про доступ к памяти за O(1) и заменить его на O(vN).
Последствия
Стоимость обращения к памяти зависит от размера, который запрашивается — O(vN), где N это размер памяти, к котором происходит обращение при каждом запросе. Значит, если обращение происходит к одному и тому же списку или таблице, то следующее утверждение верно:
Проход по связному списку это O(NvN) операция. Двоичный поиск это O(vN). Получение из ассоциативного массива это O(vN). На самом деле, любой произвольный поиск в любой базе данных это в лучшем случае O(vN).
Стоит заметить, что действия, производимые между операциями, имеют значение. Если ваша программа работает с памятью размером N, то любой произвольный запрос к памяти будет O(vN). Так что проход по списку размером K будет стоить O(KvN). При повторном проходе (сразу, без обращения к другой памяти) стоимость будет O(KvK). Отсюда важный вывод: если вам нужно обращаться к одному и тому же участку памяти несколько раз, то минимизируйте промежутки между обращениями.
Если же вы делаете проход по массиву размером K, то стоимость будет O(vN + K), потому что только первое обращение будет произвольным. Повторный проход будет O(K). Отсюда другой важный вывод: если планируете делать проход, то используйте массив.
Существует одна большая проблема: многие языки не поддерживают настоящие массивы. Языки вроде Java и многие скриптовые языки хранят все объекты в динамической памяти, и массив там это на самом деле массив указателей. Если вы делаете проход по такому массиву, то производительность будет не лучше, чем при проходе по связному списку. Проход по массиву объектов в Java стоит O(KvN). Это можно компенсировать созданием объектов в правильном порядке, тогда распределитель памяти, надеюсь, разместит их в памяти по порядку. Но если вам нужно создавать объекты в разное время или перемешивать их, то ничего не получится.
Вывод
Методы обращения к памяти — это очень важно. Нужно всегда стараться обращаться к памяти предсказуемым способом, и минимизировать произвольные обращения к памяти. Здесь нет ничего нового, конечно, но это стоит повторить. Надеюсь, вы возьмете на вооружение новый инструмент для размышлений о кэше: обращение к памяти стоит O(vN). В следующий раз, когда будете оценивать сложность, вспомните об этой идее.
Комментарии (94)

Akon32
07.09.2016 12:57+2А кэш очищался перед каждым прогоном теста?
Если нет — в первом прогоне (или даже в генерации данных) было обращение к памяти, а во втором и следующих прогонах измерялась скорость повторного доступа к кэшу. То есть, не было случайного паттерна доступа и проявлялось ускорение за счёт кэширования (пологие участки на графиках).
LoadRunner
07.09.2016 13:00+4Так об этом и речь. Кэш же не очищается при работе программы, когда идёт обращение к одному и тому же участку памяти:
Отсюда важный вывод: если вам нужно обращаться к одному и тому же участку памяти несколько раз, то минимизируйте промежутки между обращениями.
Akon32
07.09.2016 13:12+1Обращение к одному и тому же участку — это не произвольный доступ. Даже если это не один блок памяти, а множество участков, расположенных не подряд, как в связном списке.
В статье почему-то говорится о произвольном доступе, хотя тесты проводятся много итераций для одного и того же списка (я посмотрел код автора на гитхабе). Естественно, список кэшируется (полностью или нет). И это влияет на результаты тестов. Если для каждой итерации брать разные списки (расположенные в некэшированных участках памяти) — полагаю, результаты будут другими.LoadRunner
07.09.2016 13:20+2Так там и формула корректируется в зависимости от ситуации. Пусть она корректная лишь при определённых характеристиках процессора и памяти. Но дать оценку времени выполнения программы можно вполне точно, если учитывать все нюансы (размеры массивов, порядок обращений к тем или иным его участкам или же ко всему и всё такое прочее). И скорректировать под себя её тоже можно.
Akon32
10.09.2016 17:00Не сразу заметил, что под временем доступа O(vN) имеется в виду среднее время доступа к объёму памяти N (именно это, а не что-то другое, замеряет автор своими тестами), а не худшее время одиночного чтения.
В рамках этой статьи мы O(f(N)) будет означать, что f(N) — это верхняя граница (худший случай) по времени, которое необходимо для получения доступа к N байтов памяти (или, соответственно, N одинаковых по размеру элементов).
Так — да, почти сходится. Вместо O(N) из-за кэша получается что-то вроде O(vN), когда есть повторные обращения. Но не вместо O(1), не вместо единичного чтения! И замеряется не худший случай, а средний.
Аналогия с хождением по библиотеке странная. Когда контроллер памяти выставляет 32 бита адреса, он сразу (через фиксированное число тактов) получает доступ к любому из 2^32 байт информации. Если 64 бита — к любому из 2^64 байт. Никто никуда не ходит! Латентность не растёт пропорционально корню количества данных.
Аналогия с чёрной дырой ещё страннее. При современных (невысоких) плотностях и объёмах наверняка можно хранить информацию на узлах в трёхмерной структуре в количестве, пропорциональном объёму структуры, а не площади.
Очень спорная статья, с неверной методикой замеров и странными размышлениями. Неудивительно, что столько людей посчитали её юмором.
chersanya
11.09.2016 10:07+4Латентность не растёт пропорционально корню количества данных.
Как раз основная мысль статьи — что в зависимости от размера памяти, используемой программой, меняется и латентность доступа к ней. Если программа активно использует 10 кб памяти — то все данные будут в самом быстром кеше, и время произвольного доступа допустим 1 нс. Если же программа активно использует 1 Гб памяти, то (в случае случайного обращения к ним) задержка при каждом обращении будет уже 100 нс.
Если это не «Латентность растёт пропорционально корню количества данных.» — тогда что?
Вместо O(N) из-за кэша получается что-то вроде O(vN), когда есть повторные обращения. Но не вместо O(1), не вместо единичного чтения!
Вот именно что sqrt(N) — это время единичного чтения! Видимо действительно статья написана не очень хорошо, раз столько людей не понимают, что имеет в виду автор.
А уж как получить sqrt(N) вместо N для обхода всех элементов (всего), это я вообще не понял у вас. Всё равно нужно как минимум O(N) операций, как ни крути.
prostoVania
11.09.2016 19:18-3Если провести аналогию… Трудно понять что изображено на схеме электрической принципиальной если закончил юридический и никогда этих схем не видел. А тут нужно еще и пронстранственное мышление и воображение. Я думаю данная теория имеет право на жизнь неменьше чем общая теория относительности (которую на практике на 100 процентов тестами не покрыл, но в которую почему-то все свято верят — потому что так в школе учили))))). Хотя Эйнштейн в преклонном возрасте признался что эта теория — лишь частный случай и работает не всегда. Как вариант, данная статья может просто указывать на несовершенство инструмента, которым мы производим вычисления(компьютер).
chersanya
12.09.2016 07:49+4Про ОТО в школе — это вы сииильно загнули, она полностью изучается далеко не во всех вузах/факультетах, даже относительно профильных :) Ну и вообще, естественно-научные теории строго доказать (как теоремы в математике) в принципе нельзя. Даже более того — мы знаем, что ОТО не верна в общем случае, как и остальные используемые теории — но это никак не мешает использовать их.

mwizard
07.09.2016 13:05-9Отличный шуточный пост посреди недели, спасибо! Можно с серьезным лицом показывать коллегам и встревоженно спрашивать "о б-ги, как же нам жить дальше?".
По сути поста — плохая аналогия подобна котенку с дверцей. Если всю мякотку свести к одному практическому примеру, то вы утверждаете, что компьютер с 64 ГБ памяти тратит на получение 1 байта в восемь раз больше времени, чем компьютер с 1 ГБ памяти. Ну конечно же так и есть! Даже поспорить не с чем. Пока библиотекарь дойдет до границы чипа, пока найдет нужный байт в каталоге байтов… А там и обед уже, а потом и короткий день.
Ну и да, глупый вопрос не по теме — с чего вы вообще взяли, что доступ к произвольному элементу связного списка — это O(1)?
P.S. У вас все [ссылки] отвалились.
khim
07.09.2016 14:46+3Спасибо за выставление себя круглым (или квадратным?) идиотом.
Если всю мякотку свести к одному практическому примеру, то вы утверждаете, что компьютер с 64 ГБ памяти тратит на получение 1 байта в восемь раз больше времени, чем компьютер с 1 ГБ памяти.
Вы вообще разницу междуNиO(N)понимаете?
Возьмите сотню компьютеров с 1 ГБ памяти и соответствуюших им компьтеров с 64 ГБ памяти разных поколений, устредните — и, скорее всего, примерно 8 раз разницу и получите. Потому что в совсем старых системах у вас 1ГБ памяти будет стоять на каком-нибудь Pentium3, а 64 ГБ — это будет NUMA-монстр с дикими задержками и там разница будет раз в сто. Сегодня 1ГБ — это будет настольный комп, а 64 ГБ — это будет Xeon и с регистровой памятью и разница может быть раза в два. Завтра — это всё попадёт на «плоский участок» и разницы не будет, а послезавтра — 1ГБ попадуют в кеш L3 и мы снова получим разницу в два порядка.
Это как раз ваши аналогии подобны котёнку с дверцей…
QuakeMan
07.09.2016 17:57+1Мне вот тоже не понятно, почему не взят например массив?
Мне как то довелось выяснять что быстрее обращается к элементу, deque или vector. Совершенно разные O.

napa3um
07.09.2016 13:36+38Big-O — это математическая абстракция для анализа поведения функций, а не физическая величина, учитывающая неидеальность проецирования этих функций на физическую реальности. Если вы пытаетесь проанализировать с помощью big-O информационную систему или её часть, в рамках которой данные перемещаются между L1 и файлом подкачки, то берите за скорость операции с памятью именно файл подкачки, а не L1. Это не диск портит оценку big-O, это кэш её улучшает. И это не повод менять определение для O.
mayorovp
07.09.2016 13:59+3А определение для O никто и не меняет. Просто автор предложил новую модель абстрактного вычислительного устройства чтобы можно было лучше оценивать какой из алгоритмов быстрее.
Кстати, моделей и до этого было несколько. В той же теории алгоритмов принято время на сложение двух чисел и объем занимаемой числами памяти считать равным O(log M), где M — само число; на практике же обычно принимают их за O(1), а не ограниченность типов данных закрывают глаза (хотя с точки зрения математики понятие O и ограниченность сверху несовместимы).
А уж при переходе к модели Машины Тьюринга и вовсе вся асимптотика настолько меняется, что вопрос «какой алгоритм быстрее» даже не ставится.napa3um
07.09.2016 14:17+1При анализе АЛУ процессора оценка сложения действительно может получиться O(log M). Я же о том и говорю — важно понимать границы исследуемой системы, чтобы сформулировать граничные условия (и представлять, что вообще вкладывается в слово «операция» на рассматриваемом масштабе). «На практике же обычно принимают их за O(1)» — потому что ваша практика, подозреваю, лежит за пределами проектирования архитектур процессоров. Похоже, что вы тоже за big-O видите какой-то физический, а не математический смысл. Big-O не получится измерить секундомером, линейкой или весами, это чисто умозрительная, математическая характеристика поведения функции.
mayorovp
07.09.2016 14:44Зачем сразу анализ АЛУ? Когда требуется работать с большими числами — используется так называемая «длинная арифметика», где все эти множители и всплывают.
А вот в при построении архитектуры процессора понятие «О большое» используют очень ограниченно либо вовсе не используют — потому что, во-первых, борьба идет за каждый такт — а во-вторых, ограничения сверху довольно низкие.
32 разряда для процессора — это 32 разряда, а для прикладной программы — 4 миллиона допустимых значений.

RPG18
07.09.2016 14:19+1А определение для O никто и не меняет.
Emil Ernerfeldt просто забыл в определение константу ;) Если мы возьмем константу равной доступа к SSD, то оценка сверху не измениться.
Просто автор предложил новую модель абстрактного вычислительного устройства чтобы можно было лучше оценивать какой из алгоритмов быстрее.
Ничего он не предложил, т.к. этот метод не работает для произвольной программы:
Но если вам нужно создавать объекты в разное время или перемешивать их, то ничего не получится.

Bronx
13.09.2016 12:13+1> Если мы возьмем константу равной доступа к SSD, то оценка сверху не измениться.
Вот только сама эта константа будет меняться при переходе к всё более ёмким SSD, из-за растущих накладных расходов на хранение и извлечение данных. И эти расходы асимтотически приближаются к sqrt(N) при N стремящимся к бесконечности и плотности записи стремящейся к теоретическому пределу. Так что пофиксить проблему простым повышением константы не удастся, за неимением таковой константы.

Alexey2005
07.09.2016 14:11+2Самое лучшее описание особенностей работы памяти с точки зрения программиста из всех, что мне попадались — у Криса Касперски в старой книжке «Техника оптимизации программ: эффективное использование памяти».
RomanArzumanyan
07.09.2016 14:19Вопрос автору — время доступа к какой памяти вы оцениваете: кэш L1/L2/L3/L4/RAM? Последовательный доступ с одного и того же физического ядра процессора, или разных? Последовательный или параллельный доступ cо стороны нескольких ядер? (дальше идёт уже откровенная дичь про UMA/NUMA, шаблон доступа к памяти, организацию безконфликтного доступа — это уже слишком сложно для эксперимента)
Если вы оцениваете время доступа к некой определённой памяти, то стоит исключить из экспериментов обращения к прочим. После того, как это не получится сделать за разумное время, попробуйте составить математическую модель происходящего — ну, хотя бы полином, каждый член которого будет соответствовать уровню иерархии памяти — было бы интересно.

AlexanderG
07.09.2016 14:23+8О(1) это правильная оценка в рамках своей области определения. А менять размеры данных на шесть порядков и «открывать» нелинейность…
beTrue
07.09.2016 14:26Автор, увлекательный пост, читается на одном дыхание.
Подскажите, плиз, как для двоичного поиска получили сложность O(vN) из классической логарифмической, можно формулу, не понятно.
Спасибо.janatem
07.09.2016 14:34Там не утверждается, что для двоичного поиска сложность будет O(vN). Но ее несложно вывести: требуется O(log N) операций доступа к памяти, каждое обращение стоит O(vN), так что итоговая сложность O(vN log N).
chersanya
07.09.2016 17:32+3На самом деле как раз корень из н получится. Ведь только на первом шаге двоичного поиска доступ идёт случайный по всему массиву, а в дальнейшем рабочий участок уменьшается в 2 раза, и через несколько шагов влезет уже в предыдущий кэш — поэтому правильнее взять сумму sqrt(n) + sqrt(n/2) + sqrt(n/4) +… + sqrt(2) + sqrt(1) = O(sqrt(n)), как несложно убедиться.

LynXzp
09.09.2016 18:16Забавно, но в общем случае не значительно по времени. (Если 90км ехать со скоростью 1км/ч, 9 — 10 км/ч, 0.9 — 100км/ч, средняя скорость все равно будет 1.1 км/ч)
chersanya
10.09.2016 06:47+1Какая-то странная аналогия… Я как-то даже совсем не понял, что именно не значительно? Домножение на логарифм или суммирование ряда?
LynXzp
10.09.2016 13:15Согласен, прошу прощения, просто сумма не понравилась, пересчитал и получилось так жеСложность получается:
O(vN) + O(vN/2) + O(vN/4) +… (всего log(N) членов) = ??? (Сложность доступа к первому элементу + сложность доступа ко второму+...)
Смущает то что сложность при бинарном поиске:
O(1)+O(1)+O(1)+...(всего log(N) членов) = O(log(N) (Сложность доступа к первому элементу + сложность доступа ко второму+..., классическая формула)
Поэтому решаю первую формулу:
O(vN + vN/2 + vN/4 +… ) = O(vN*(1+v1/2+v1/4+...) = (тут я не знал как упростить ряд, но взял калькуляpython получил что ряд сходится к ~3.41, и достигает 3.41 уже при 20 членах.
Поэтому сложность = O(3.41*vN)
А при учете сложности алгоритма константный умножитель не учитывается, получается O(vN)
janatem
07.09.2016 14:28-3поиск элемента в хеш-таблице это O(1)
Это неверно, даже если считать не время, а обращения к памяти. При фиксированной мощности хеш-функции p с ростом количества хранимых элементов N вероятность коллизии будет расти как N/p, то есть линейно по N (и это при удачной хеш-функции, а реально могут быть перекосы). Традиционные реализации хеш-таблиц подразумевают использование списков при коллизиях, так что получаем скорость доступа вообще O(N) в классических терминах.
На самом деле применение хеш-таблиц оправдано для случаев, когда коллизии редки, то есть N не должно быть больше p, но тогда и O-анализ обессмысливается.

Shoonoise
07.09.2016 14:32+2Кажется, что вы тоже не очень понимаете, что означает нотация большое О.
janatem
07.09.2016 14:41-1Я-то как раз понимаю, это мое профильное образование. Просто его часто используют слишком вульгарно, мне даже доводилось видеть такие таблицы:
чего-то там: O(1000)
чего-то сям: O(10^5)
(Имелось в виду, что некоторая величина имела значение порядка 10^3, 10^5, что вообще никакого отношения к O-нотации не имеет.)

wataru
07.09.2016 14:53+6Если ограничить load factor константой, и при ее превышении увеличивать таблицу и перехешировать все элементы, то сложность остается O(1) для поиска, O(1) для удаления и (амортизационно, в среднем) O(1) для добавления.
janatem
07.09.2016 15:52-2Перестройка массива — это уже усовершенствование классической хеш-таблицы, в каком-то смысле получается другая структура данных.
mayorovp
07.09.2016 15:57Не знаю что такое «классическая хеш-таблица», но доработка эта настолько простая, что отдельного наименования не заслуживает.

deniskreshikhin
07.09.2016 15:21-4Так O(1) это для идеальной хеш-функции. К тому же O это характеристика функции сложности, а не сама функция сложности. Т.е. если сложность f(n) = k только при n < p, то это не отменяет что f(n) = O(1).
janatem
07.09.2016 15:56+2если сложность f(n) = k только при n < p, то это не отменяет что f(n) = O(1)
Для конечных случаев О-анализ обессмысливается, поскольку всегда можно написать, что f = O(1). Имеет место оценка f(n) <= C, где C = max f, максимум всегда существует на конечном множестве.
deniskreshikhin
07.09.2016 18:20-2Не обязательно обессмысливается. Если функция аналитическая, то у нее всегда есть естественное продолжение за границей определения.
Допустим, у меня есть какой-то уникальный алгоритм сортировки целых чисел, который дает при
N=1...1000000конкретную сложностьA * N * logN + B, а приN > 1000000ужеN*N.
Могу ли я сказать, что на участке
1...1000000сложность выражаеся формулойA*N*logN + B? Да могу.
Могу ли я сказать, что функция выражаемая формулойA*N*logN+BимеетO(N*logN)? Да могу.
Что это дает? Зная O-оценку можно представить что лежит в основе алгоритма, а так же сравнить с другими алгоритмами. Т.к. каждый подход дает свой характерный вклад в O. Именно в этом суть O-нотации для оценки алгоритмической сложности. (Не количественное, а качественное сравнение)
Как пример, Timsort, если для сортировки малых массивов используется
N*Nалгоритм, а для большихN*logN, то это же не значит что при малыхNалгоритм является O(1)? Т.к. значение имеет качественная сторона вопроса. Алгоритм со сложностьюN*Nиспользуемый на конечном промежутке не становится алгоритмом со сложностью O(1).
chabapok
07.09.2016 14:30А почему комментаторы решили, что это юмор? Помоему, он серьезно. Поэтому, тут печально вообще все.
Вопрос к автору. У вас осталась программа, которой вы меряли производительность? Интересно, чтобы вы модифицировали ее определенным образом (если осталась — я опишу каким) — и потом провели снова замеры. Но к sqrt(n) это уже не относится. Просто интересно проверить одну штуку.
Так же, было б полезно залить на гитхаб ее.
redmanmale
07.09.2016 14:35+4Автор вам вряд ли ответит, так же, как всем вышеспросившим. Это перевод.
А тестовая программа есть на гитхабе: https://github.com/emilk/ram_bench
Bronx
13.09.2016 12:20+1> А почему комментаторы решили, что это юмор?
Это математики, решили, что физики опять шутят.
wataru
07.09.2016 15:19У автора ошибка в рассуждениях. Если график строить и дальше вправо, то он так и останется горизонтальным, на уровне 1 микросекунды. После HDD никаких новых уровней ухудшения производительности памяти не будет, и раз О-большое меряет поведение только при больших значениях, то оно так и будет константой.
deniskreshikhin
07.09.2016 15:23+2Он же написал "O(1) это неправильная абстракция". Вы просто неправильной абстракцией пользуетесь, поэтому вам кажется что там все так и будет, а если обратитесь к черным дырам и квантовой теории, то многое сможете осознать.
khim
07.09.2016 21:45После HDD никаких новых уровней ухудшения производительности памяти не будет
О как. Вот прямо даже так? А сколько эксабайт было в системах, с которыми вы работали, нельзя спросить? И как вы их упихали на несколько HDD?
За HDD сначала идёт стойка (из 40 машин примерно), потом кластер, потом датацентр, потом региональная коллекция датацентров, потом глобальная коллекция датацентров…
На каждом шаге идёт увеличение задержек и снижение ширины канала доступа, увы. Так где всё кончается — кончается и график. Никакого осмысленного горизонтального участка (на двойной логарифмической шкале!) там нету.
arheops
07.09.2016 22:47+2А вы точно внимательно прочитали? Дальше автор рассказывает о храниении данных в сетевых хранилищах, в разных датцентрах(поскольку в этом место закончилося) и так далее.

potan
07.09.2016 17:04С переходом на более медленные уровни памяти ее плотность растет, а энергопотребление (и тепловыделение) на хранимый бит падает. Так что «емкость от расстояния» в теории может расти быстрее, чем квадрат и даже куб.
usarskyy
07.09.2016 17:57Ваша статья это продолжение для https://habrahabr.ru/post/308818/? Там автор (ИМХО) уже достаточно ясно все написал.

rimidalvv
07.09.2016 17:57А кто нибудь может объяснить вот это следствие?
Ну, что является самым плотным во вселенной? Черная дыра! [Оказывается], что масса черной дыры пропорциональна радиусу: m ? r. То есть количество информации, которую можно поместить в сфере радиусом r это N ? r?
О чем это вообще? Как вообще количество информации может описываться расстоянием? Заранее спасибо за разъяснение.mayorovp
07.09.2016 18:32+4Максимальное количество информации, которое можно сохранить в некотором объекте, совпадает с его энтропией и является логарифмом числа возможных различимых состояний этого объекта.
Любую информационную систему может поглотить черная дыра — и, согласно второму закону термодинамики, суммарная энтропия от этого не увеличится. Отсюда следствие — энтропия любой информационной системы не может превышать энтропию черной дыры тех же размеров.
Черная дыра может хранить информацию только на горизонте событий — поэтому ее энтропия пропорциональна площади горизонта событий, то есть квадрату радиуса.
Следовательно, максимальное теоретически достижимое количество информации, которую может хранить информационная система, ограничено значением, пропорциональным квадрату радиуса описанной вокруг системы сферы.
Разумеется, этот предел глубоко теоретический и еще долго будет оставаться таковым.
Как-то так. Не самая знакомая для меня область — мог что-то напутать.
deniskreshikhin
07.09.2016 20:13Любую информационную систему может поглотить черная дыра — и, согласно второму закону термодинамики, суммарная энтропия от этого не увеличится. Отсюда следствие — энтропия любой информационной системы не может превышать энтропию черной дыры тех же размеров.
Мне кажется это не совсем так, ведь в единицу пространства можно напихать сколь угодно много безмассовых частиц, например фотонов. Энтропия такой системы будет зависеть от количества этих частиц и их энергии, при этом нет никаких ограничений на то что бы их было не сколь угодно много. В черную дыру они не превратятся, т.к. массы не имеют.
mayorovp
07.09.2016 21:06+3Для образования ЧД подойдет любая форма энергии, в том числе безмассовая.
khim
07.09.2016 21:52+2Вы тут смешали в кучу довольно много понятий. На самом деле всё проще: никаких базмассовых частиц в природе просто не существует. У фотона есть масса — рассчитывается по всем известной формуле. Чего у фотона нет — так это массы покоя. Соотвественно сконцентрировав много фотонов в одном месте вы соберёте там же и кучу массы (удивительным образом у группы фотонов масса покоя вполне может быть), что и создаст вам там чёрную дыру.
Вы так дойдёте до того, что скажите, что два звездолёта утетающих в разные стороны от Земли со скоростью 0.9c удаляются друг от друга со скоростью 1.8c, ага. Не надо так.MichaelBorisov
13.09.2016 22:14+1никаких базмассовых частиц в природе просто не существует
Современное определение массы имеет в виду только массу покоя. Хотя это и не опровергает вас в отношении возможности образования черной дыры из фотонов.
deniskreshikhin
07.09.2016 22:33Да, верно, полистал уравнения в вики, черную дыру можно собрать из любой энергии.
prostoVania
15.09.2016 17:24+1Всё… пошел собирать черную дыру… Если не вернусь — считайте что собрал)))

Mingun
07.09.2016 18:57На самом деле это он про голографический принцип. У Леонарда Сасскинда в его «Битве при чёрной дыре» это хорошо объяснено. Голографический принцип утверждает, что всё находящееся внутри некоторой области пространства, можно описать посредством битов информации, расположенных на её границе. Дальше я привожу цитату из книги, глава 18, «Мир как голограмма»:
Самая массивная вещь, которую можно запихнуть в нашу область, — это чёрная дыра, горизонт которой совпадает с границей. Вещи не должны быть массивнее её, в противном случае они не поместятся внутри границы, но существует ли какой-то предел, ограничивающий число битов информации в этих вещах? Нас интересует определение максимального числа битов, которое можно запихнуть внутрь сферы.
Теперь представьте себе материальную сферическую оболочку — уже не воображаемую границу, а сделанную из настоящего вещества, — окружающую всю рассматриваемую систему. Эта оболочка, будучи сделанной из реальной материи, имеет собственную массу. Из чего бы она ни состояла, её можно сжимать внешним давлением или гравитационным притяжением находящегося внутри вещества, пока она идеально не совпадёт с границей области.
Исходные вещи, которые были у нас с самого начала, содержат некоторое количество энтропии — скрытой информации, — значение которой мы уточнять не будем. Однако нет сомнений в том, что окончательная энтропия — это энтропия чёрной дыры, то есть её площадь, выраженная в планковских единицах.
Для завершения доказательства остается лишь напомнить, что второе начало термодинамики требует, чтобы энтропия всегда возрастала. Поэтому энтропия чёрной дыры должна быть больше, чем у любых исходных вещей. Сводя всё воедино, получаем доказательство удивительного факта: максимальное число битов информации, которое может при каких угодно условиях поместиться в области пространства, равно числу планковских пикселов, которые можно уместить на площади её границы. Неявно это означает, что существует «граничное описание» всего, что происходит внутри области пространства; поверхность границы — это двумерная голограмма трёхмерной внутренней области. Для меня это самый лучший тип доказательства: пара фундаментальных принципов, мысленный эксперимент и далеко идущие выводы.rimidalvv
07.09.2016 19:38Спасибо. Это многое объясняет в статье. Но для меня остается открытым вопрос О(1), О(N)… О(...). Просто в моем понимании есть константа времени обращения к объекту. Хоть это радиус, хоть это 1 минута/час/месяц. И если до любого объекта это время постоянное, то это О(1). Если надо перед этим сделать дополнительные действия то сложность увеличивается. И не понятно как увязали максимальное количество информации на минимальном расстоянии с этим О. Как я понял, если простым языком, то О перестанет быть О(1) когда количество информации настолько уплотнится, что потребуется идти дольше чем время этой константы. И увели тему в кэш, что он конечен, поэтому за следующими данными надо идти дальше. Ради этого надо было писать статью? Вплетать сюда черные дыры и максимальные плотности?
Или я что то упускаю?mayorovp
07.09.2016 19:45+2Для того, чтобы обратиться к ячейке информации — надо послать к ней сигнал и получить ответ. При постоянной скорости распространения сигнала время доступа пропорционально расстоянию. А среднее расстояние зависит от объема памяти.
Чем больше в компьютере памяти — тем больше время доступа к ней. Значит, время доступа не является константой.

ptyrss
07.09.2016 17:58-5Статья конечно интересная, но мне показалось что автор сознательно выбрал логарифмическую шкалу. При использовании обычной шкалы ситуация становится совсем не настолько страшной, http://joxi.ru/bmovQbxFMK1Bwr т.е. можно с точки зрения алгоритмов считать что доступ к памяти имеет сложность O(1) пока память собственно есть. Первоначальные 4Mb скоростного доступа можно считать бонусом. Если начать учитывать их, то это уже не асимптотика а попытка точно вычислить время работы программы, что полезно в конкретных задачах (например программисты микроконтроллеров, там свой мир) но в общей теории алгоритмов почти бесполезно.
Если вам нужно стабильно использовать больше памяти чем есть на устройстве, то может стоит задуматься о покупке лишней планки? Опять же, использование памяти в таких объёмах обычно следствие решения специфических задач (например big data) которые имеют свою теорию, свои алгоритмы и так далее.
Поэтому моё мнение: утверждение что сложность бинарного поиска O(log N * sqrt N) — казуистика и отражает реальную ситуацию в весьма ограничем количестве случаев.
DaylightIsBurning
07.09.2016 18:29Я правильно понимаю, что вся статья сводится к мысли, что из-за наличия многих уровней «кешей», в среднем для диапазона объемов 1..10^12 Байт задержка растёт пропорционально корню? Неужели автор статьи полагает что это кому-то из специалистов непонятно?
vsb
07.09.2016 19:00-5Скорость обращения к памяти действительно O(1). Выкиньте все кеши из вашей модели и всё. Всё, что делает кеш — некоторые обращения делает быстрее других. Для анализа сложности алгоритма наличие кеша несущественно, от его наличия или отсутствия сложность (т.е. класс эквивалентности) не изменится. Реальная скорость на некоторых данных изменится, может быть даже на порядок. Но O(F) останется тем же самым.
khim
07.09.2016 21:58-1Выключите кеш в BIOS'е, запустите комп и, если терпения хватит расскажите на Хабре как на вас не влияют эти дурацкие кеши. Если повезёт — за пару часов управитесь.
Вы правы в том, что если рассуждать о скорости работы разных математических компроютеров — то O(1) может быть неплохой точкой отсчёта.
Но вопрос: как потом это всё к реальному-то компьютеру приложить? Человеку ведь все эти O(1) и O(N) не нужны как бы совсем, ему нужно чтобы 60 кадров в секунду картинка обновлялась и компьютер «не тупил».vsb
08.09.2016 01:39Как это приложить к реальному компьютеру это тема отдельного разговора. Если вкратце — всё, что вам даёт O-нотация это понимание масштабируемости алгоритма, т.е. зависимости его производительности от размера входных данных. А конкретные приложения к реальному компьютеру делаются в первую очередь тестированием и профилированием применительно к конкретному оборудованию.
khim
08.09.2016 16:25+1Как это приложить к реальному компьютеру это тема отдельного разговора.
Но computer science, не приложенный к компьютеру — это мастурбация какая-то!
А конкретные приложения к реальному компьютеру делаются в первую очередь тестированием и профилированием применительно к конкретному оборудованию.
С этого момента — поподробнее. Давайте исключим код, который затачивается под конкретное железо (PlayStation4 или там суперкомпьютер какой — неважно).
Рассмотрим обычный такой код, который пишется сегодня и будет использоваться, в том числе, и в 2030м году (это, собственно, подавляющее большинство создаваемого кода: мало кто бросается переписывать всё с нуля при выходе очередного творения от Intel'а или там ARM'а). Как тут «профилированием применительно к конкретному оборудованию» обойтись?
Disasm
07.09.2016 19:22-4Тут действительно очень сильно не хватает тега "юмор".
Нельзя же считать размер памяти произвольным. Как минимум рано или поздно исчерпается адресное пространство, после чего любой описанный в статье алгоритм будет работать за O(1).
А вообще с таким же успехом можно утверждать, что модуль моего pgp-ключа можно разложить на множители за O(1), а также, что операция сложения выполняется не за O(1), а за O(log(N)), где N это размер машинного слова.
Куда интереснее было бы увидеть рассуждения касательно схемной сложности для обеспечения доступа к произвольной ячейке памяти.
alex_blank
08.09.2016 09:41+4> Как минимум рано или поздно исчерпается адресное пространство, после чего любой описанный в статье алгоритм будет работать за O(1).
Вы не поняли месседжа статьи, речь там о том, что мы проводим O-анализ в контексте совершенно другой модели памяти в принципе: это бесконечная иерархия кэшей (L1 > L2 > L3 > RAM > SSD > дисковый сервер > удаленный датацентр >… > сфера Дайсона > и так до бесконечности, все более и более удаленные физически области). То есть, в этой модели «адресное пространство» никогда не исчерпается. И говорить про O(1), который наступит при достаточном "zoom out" здесь уже нельзя. В этой модели нельзя «отзумиться до предела» — увидев ровную линию на графике. Провести O-анализ здесь можно исходя из физики пространства, в котором информация хранится, рассмотрев предельный случай — черную дыру. Именно это автор и делает в статье ;)

PsyHaSTe
12.09.2016 17:36-2Количество атомов во вселенной конечно, сама вселенная тоже, так что предел где-то все равно есть.
alex_blank
13.09.2016 18:41+1Откуда дровишки? Вы Вселенную с так называемой «видимой Вселенной» не перепутали, случаем? :)
PsyHaSTe
13.09.2016 21:12-1Для видимой вселенной это значение вообще точно известно (~2^80).
Вообще это логично учитывая современные представления (большой взрыв + инфляция). Тот же объем не может быть бесконечным, т.к. расширение вселенной не могло достигать бесконечных величин, а хотя значение инфляции было велико, оно все же было конечным.PsyHaSTe
14.09.2016 00:57+2Окей, предположим. что вселенная истинно бесконечна (т.к. сейчас нет 100% доказательств этого или противного). Но не нужно забывать, что вселенная ускоренно расширяется, и вот это как раз известный факт. А это значит, что сигнал до некоторой достаточно удаленной точки никогда не дойдет, т.к. когда он не долетит до неё какой-то жалкой планковской длины, скорость расширения самого пространства превысит скорость света.
Таким образом область, докуда может дойти сигнал (а ведь он ещё должен вернуться) конечен, даже если вселенная истинно бесконечна.

Mugik
07.09.2016 21:44-3Запомните первокурсники и второкурсники, если не хотите совершать вот такие же вот открытия, то не прогуливайте пары мат. анализа в университете :)
G-M-A-X
07.09.2016 21:45+2Вообще-то время обращения к памяти при наличии кешей никто и не принимает за O(1). Это вообще несравнимые понятия.
Все отдают себе отчет, что есть разные тайминги доступа к разным уровням.
Время обращения к памяти — не строго монотонная функция!
А также данные и обращения к ним стараются выстроить так, чтобы они шли последовательно. Даже если не будет кеша, мы поимеем выгоду.
Вообще странная статья, будто автор недавно открыл кеширование. :)
Кстати, работа допустим с 1МБ данных не гарантирует, что они будут закешированы и доступны за 10 нс.
Что вообще переводчик думает о статье freetonik?
Blast
07.09.2016 22:47+2При определенных условиях такая оценка действительно будет справедлива. В частности, если у нас есть бесконечное количество кэшей, размер и латентность которых возрастают примерно с той же скоростью, что в статье. Другой вопрос, что условия эти притянуты за уши чуть более, чем полностью. Хотя если автор обосновывает предел чёрными дырами, у него наверное очень другой взгляд на это)
prostoVania
08.09.2016 14:36Так все таки какой тип списка использовался для тестов vector или linkedlist. Предлагаю в пост добавить ссылку на оригинальную статью. Уж больно похожа зависимость рандомного доступа на O(n). А ведь для linkedlist'ов она именно ~ O(n).
chersanya
08.09.2016 15:22Эм, а как именно график в статье похож на линейную зависимость? Грубо говоря, по оси х значение выросло в 10000000 раз, по оси у — в 1000 раз. Намного ближе к корню, чем к линейной.
Ну и линейная зависимость соответсвует наклону графика в два раза больше, чем у синей линии — это явно далеко от истины.prostoVania
08.09.2016 16:07Прошу прощения пока читал забыл про логарифмическую шкалу. Может правильнее тогда записать O(f(n)n), где f(n)>>1 и определяется в зависимости от железа…
mayorovp
08.09.2016 16:41Это не даст возможности сравнить разные алгоритмы.
prostoVania
08.09.2016 17:19-1Я думаю за f(n) можно было бы принять некоторую среднюю величину, которая в информатике принята как O(1) для операций с linkedlist'ом (например время добавления элемента в начало списка) и сделать это для того количества операций, которое рассмотрено в статье. А потом уже…
santa324
09.09.2016 20:54Оценка не совсем верная, это не совсем O(sqr(N)). Такое время доступа только к самой медленной части памяти. И хотя ее больше всего, но алгоритм может использовать «в основном» небольшой объем памяти.
Например, если частота обращения к «отдаленным» областям памяти убывает экспоненциально с ростом «удаленности» данных, тогда для алгоритма асимптотическая оценка времени доступа к памяти совсем другая будет.mayorovp
09.09.2016 21:57Это учтено вот тут:
Стоит заметить, что действия, производимые между операциями, имеют значение. Если ваша программа работает с памятью размером N, то любой произвольный запрос к памяти будет O(vN). Так что проход по списку размером K будет стоить O(KvN). При повторном проходе (сразу, без обращения к другой памяти) стоимость будет O(KvK). Отсюда важный вывод: если вам нужно обращаться к одному и тому же участку памяти несколько раз, то минимизируйте промежутки между обращениями.
anatolix
13.09.2016 02:00-2Тут на статье написано перевод, и при этом нет ссылки на оригинальную статью(или я ее не нашел). Поэтому вопрос и претензию к результатам измерения я выскажу переводчику.
А сколько у автора статьи памяти на его ноутбуке?
Мне сдается, что у него 8Gb и вот эта вертикальная палка на 8Gb в конце вызвана тем, что у него кончилась память и он попал в swap на SSD диске. Потому как для кэша процессора 8Gb как-то много, а вот для объема памяти на ноуте в самый раз. Да и порядок замедления примерно соотвествует разницей между RAM и SSD диском вокнутым в SATA(не PCI-E).
Если эта теория верна, то скорее всего эта вертикальная палка не отражает реально скорость RAM, а отражает скорость SSD, и если запустить тест на 256Gb сервере там будет ровная полка, на которую супер теорию про доступ к памяти за O(sqrt(N)) ну никак не натянуть.
Поэтому предлагаю залинковать оригинал и посмотреть не первое апреля ли там дата, чтобы понять шутник автор, или идиот :)anatolix
13.09.2016 02:06-2upd: решил поискать в статье слово SSD(до этого все написал на график посмотрев), теперь не знаю кем считать автора, который в заголовке статьи пишет про RAM, а в конце честно пишет, что RAM закончился и мы померяли SSD. Он либо тролль 30+ уровня, либо таки идиот.
mayorovp
13.09.2016 06:10+2Еще одно замечание: RAM в заголовке означает произвольный доступ (random memory accesses) в целом, а не какой-то конкретный тип памяти. Я рассматриваю время доступа к информации в памяти, будь это кэш, DRAM или swap.

featalion
13.09.2016 17:33-1Если говорить об обращении к определенной памяти (L1, L2, L3, RAM), то никакой зависимости квадратного корня из N нет. Будет лишь ограничение этого самого N в данном типе памяти. Хотя автор, как я понял, принимает любую доступную память в этой вселенной как RAM, поэтому в примерах есть даже дата-центры.

deniskreshikhin
Странно, почему нет "юмор" в тегах?