

Давайте разбираться
По ходу текста я буду ссылаться на вторую публикацию и некоторые комментарии к ней. Тронуло за живое. Но для начала давайте точно условимся что под чем понимается по ходу данного текста.
Введем определение. Пусть
Из этого определения сразу имеется несколько следствий:
1. Если для всех
Проще говоря, при умножении O-выражения на константу символ Бахмана эту константу «съедает». Это означает, что знак равенства в выражении, включающем в себя O-оценку, нельзя интерпретировать как классическое «равенство» значений и к таким выражениям нельзя применять математические операции без дополнительных уточнений. В противном случае мы бы получили странные вещи по типу следующей:
2. Если
Переводя с математического на русский и взяв для простоты в качестве
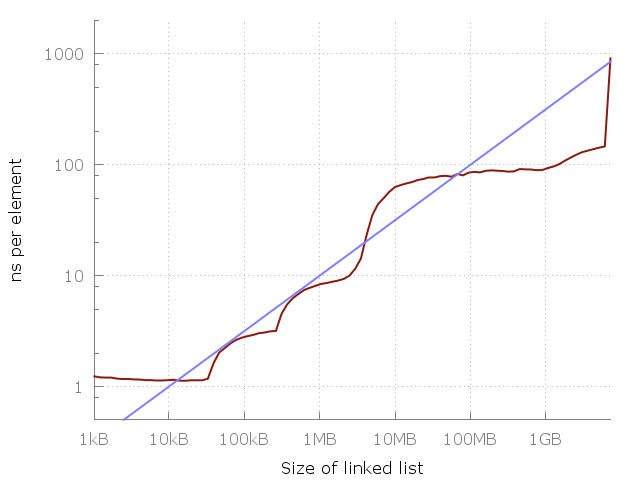
Голубая линия это O(vN).
Вернемся к случаю оценки сложности алгоритма и посмотрим на картинку, приводимую автором цитируемой публикации. Наблюдая рост времени выполнения, делается вывод о несостоятельности оценки O(1). Но интервал, на котором анализируется поведение программы, конечен. Значит по факту утверждается, что оценка O(1) на нем плоха.
Чтож… спасибо, Кэп.
Более того, дальше делается попытка угадать! мажорирующую функцию просто по виду кривой, дескать, «гля как похоже». Не проводя никакого анализа самого алгоритма с учетом тех особенностей, на которых пытаются акцентировать внимание и не вводя никакой модели памяти! А почему, собственно, там корень квадратный, а не кубический? Или не логарифм какой-нибудь залетный? Ну, право слово, предложили бы хоть пару-тройку вариантов, зачем же сразу «внимание, правильный ответ»?
Здесь стоит оговориться. Я, естественно, не веду к неверности выводов о том, что при переходе к «более далекому» от процессора накопителю время доступа падает. Но время получения порции данных при произвольном доступе к памяти даже на самом медленном уровне иерархии есть величина постоянная или хотя бы ограниченная. Из чего и следует оценка O(1). А если она не ограниченная и зависит от размерности данных — значит доступ к памяти не произвольный. Ну тупо по определению. Давайте не забывать, что мы имеет дело с идеализированными алгоритмическими конструкциями. Поэтому когда говорится, что «дальше за HDD пойдут датацентры»… Господа, ну какой же это произвольный доступ, какие массивы и хэш-таблицы? Это называется мухлёж под столом: вы втихаря меняете условия задачи, приводите ответ к предыдущей и кричите: «Ахтунг! Неправильно-то как!». У меня это вызывает приступ тяжелого недоумения. Ведь если за словом array, vector или <какой-то-тип>* ваш компилятор скрывает, скажем, кусок распределенной по узлам кластера памяти — то это по структуре может быть что угодно, но не массив в терминах книг Вирта и Кнута, и применять к ним написанные в этих книгах результаты формального анализа в высшей степени бестолковая идея. И не меньшая шизофрения — на полном серьезе говорить об общности оценки, придуманной глядя на график с результатами произвольного теста.
Ошибочность приводимого суждения заключается в том, что O-оценка сложности делается на основании эксперимента. Чтобы это подчеркнуть, введем еще одно «свойство» O-нотации, применимое к оценкам алгоритмической сложности:
3. O-оценка может быть получена только из анализа структуры алгоритма, но не из результатов эксперимента. По результатам эксперимента можно получить статистические оценки, экспертные оценки, прикидочные оценки и, наконец, инженерное и эстетическое удовольствие — но не асимптотические оценки.
Последнее является следствием того, что сам смысл подобных оценок — это получить представление о поведении алгоритма при достаточно больших размерностях данных, причем насколько больших обычно не уточняется. Это не единственная и далеко не всегда главная, но представляющая интерес характеристика алгоритма. Во времена Дейкстры и Хоара достаточно большими можно было считать порядки размерности 3-6, в наше время 10-100 (по моим не претендующим на глубину анализа оценкам). Иными словами, ставя вопрос о получении асимптотических оценок функции сложности алгоритма, удобно модифицировать определение O-нотации таким образом:
Пусть
То есть при анализе алгоритмической сложности мы фактически рассматриваем мажоранты функции сложности на всех ограниченных слева и не ограниченных справа интервалах. Значит таких О-оценок может быть указано сколь угодно много и все такие оценки могут оказаться практически полезными. Некоторые из них будут точными для малых N, но быстро уходить в бесконечность. Другие будут расти медленно, но станут справедливы начиная с такого N, до которого нам на наших убогих компьютерах как пешком до Луны. Так что если допустить, что за оценкой времени доступа к памяти
Классический пример некорректного сравнения асимптотических оценок — алгоритмы умножения квадратных матриц. Если делать выбор между алгоритмами только на основании сравнения оценок, то берем алгоритм Уильямс и не паримся. Можно лишь пожелать творческих успехов решившему применить его к матрицам характерных для инженерных задач размерностей. Но с другой стороны, мы знаем, что начиная с некоторой размерности задачи алгоритм Штрассена и различные его модификации будут работать быстрее тривиального, и это дает нам пространство для маневра при выборе подходов к решению задачи.
Как из умности получаются глупости
Грешить на неточность O-оценок — значит полностью не понимать смысл этих оценок, и если это так — то никто не заставляет их использовать. Вполне можно и зачастую оправдано предпочитать им статистические оценки, полученные в результате тестов на специфических именно для вашей области наборах данных. Неграмотное использование такого тонкого инструмента, как асимптотический анализ, приводит к перегибам и вообще удивительным штукам. Например, используя O-нотацию, можно ""«доказать»"" несостоятельность идеи параллельного программирования.
Допустим, что наш алгоритм, которому скармливается порция данных размерности N и который при последовательном выполнении имеет сложность
Подведем итоги
В качестве вывода можно предоставить следующие подкупающие новизной утверждения:
- Нельзя утверждать, что один алгоритм эффективнее другого на основании простого сопоставления их O-оценок. Такое утверждение всегда требует пояснений.
- Нельзя из результатов замеров производительности делать вывод о правильности или неправильности таких оценок — спрятанная константа обычно неизвестна и может быть достаточно большой.
- Можно (а иногда нужно) рассуждать об алгоритмах и структурах данных вообще не используя такие оценки. Для этого достаточно просто сказать, какие конкретно их свойства вас интересуют.
- Но лучше все-таки принимать конкретные инженерные решения, учитывая в том числе и такие характеристики употребляемых алгоритмов.
За утверждением о неточности, неправильности или непрактичности асимптотических оценок часто скрыто нежелание провести нормальный предварительный анализ поставленной проблемы и попытка опираться на название, но не суть тех абстракций, с которыми имеют дело. Говоря об асимптотической сложности алгоритма, грамотный специалист понимает, что речь идет об идеализированных конструкциях, держит в уме степень корректности проецирования их на реальное «железо» и никогда, от слова «вообще», не принимает инженерных решений опираясь только и исключительно на нее. O-оценки более полезны при разработке новых алгоритмов и поиске принципиальных решений сложных задач и намного менее полезны при написании и отладке конкретных программ под конкретное железо. Но если вы их неправильно интерпретировали и получили совсем не то, что обещало вам ваше понимание прочитанного в умных книжках — согласитесь, это не проблема тех, кто эти оценки доказательно получил.
Комментарии (53)

popolznev
15.09.2016 08:06Тогда из f(s)=O(g(s)) следует, что найдется такое положительное число A, что для всех s справедливо |f(s)|<A|g(s)|.
Вернее написать не "следует, что", а "по определению означает, что".
MarazmDed
15.09.2016 18:16В определение закралась небольшая ошибочка. Дело в том, что приведенное определение соответствует термину o() а не O(). Поэтому у вас легко получилось, что O(1) = O(N). Для o() это верно, а для O() — нет. O() «подпирает» функцию с двух сторон, поэтому речь идет об асимптотически одинаковом поведении функций. Поэтому они и используются в анализе алгоритмов.

alexkolzov
15.09.2016 18:39+2Это где у меня получилось, что О(1) = О(N)? Я ж вроде как четко написал, что асимптотические оценки проверять на равенство нельзя, потому что такое «равенство» по определению не может быть симметричным. Но при этом возможно одновременно, что f(x) = O(1) и f(x) = O(N).
Термину o («o»-малое) соответствует определение
Не понимаю, что Вы имеете ввиду под фразой «подпирает с двух сторон». f(x) = O(g(x)) обозначает именно ограниченность сверху на некотором односторонне ограниченном интервале. Для ограниченности снизу обычно используют символ, определение то же самое, что и у О-большого, только знак неравенства меняется на противоположный. А если
и
, то пишут
popolznev
15.09.2016 20:03+2у вас легко получилось, что O(1) = O(N). Для o() это верно, а для O() — нет.
Для О большого это тоже верно (с учетом того, что на самом деле это не равенство, а включение — но ведь это и для о малого так). Загляните в любой учебник матанализа.
GarryC
15.09.2016 09:36+2Я могу ошибаться, но на критикуемом рисунке вообще не дана функция, удовлетворяющая критерию Бахмана, поскольку она явно меньше целевой функции в некоторых интервалах области опеределения и, скорее всего, за ее пределами. Там дана скорее аппроксимирующая функция, которая никак оценкой сверху не является.
alexkolzov
15.09.2016 10:06+3Формально можно подобрать константу и функция станет строго больше экспериментальной кривой. Но в силу конечности промежутка это верно для совершенно любой монотонно неубывающей функции. Так что не ошибаетесь, на рисунке показан полный бред.

Sing
15.09.2016 10:59Нельзя утверждать, что один алгоритм эффективнее другого на основании простого сопоставления их O-оценок. Такое утверждение всегда требует пояснений.
Нет, можно. Да, в общем случае, но вполне себе можно.
Другой вопрос — про ограниченный набор данных, специфические задачи и прочую конкретику. Но это уже не просто «один алгоритм эффективнее другого».
RPG18
15.09.2016 11:51Нет, можно. Да, в общем случае, но вполне себе можно.
Дьявол кроется в деталях. В данном случае реализация алгоритма влияет на пресловутую константу в О-нотации. Поэтому нужно делать прототипы, производить измерения.
Sing
15.09.2016 12:50В данном случае реализация алгоритма влияет на пресловутую константу в О-нотации.
Первое, О-нотация исключает константы.
Второе, без констант два алгоритма одного класса будут одинаковы в Big-O, и простое сопоставление ни к чему не приведёт.RPG18
15.09.2016 13:14Первое, О-нотация исключает константы.
Смотрите, что написано в первой картинке.
Второе, без констант два алгоритма одного класса будут одинаковы в Big-O, и простое сопоставление ни к чему не приведёт.
Тогда как вы можете утверждать:
Да, в общем случае, но вполне себе можно.
Если мы да же не может утверждать, что быстрая сортировка эффективней сортировки слиянием. Или же сортировка 5 элементов пузырьком не эффективней быстрой сортировки?
Sing
15.09.2016 14:33Смотрите, что написано в первой картинке.
Бред написан в первой картинке.
Если мы да же не может утверждать, что быстрая сортировка эффективней сортировки слиянием.
Эти сортировки одного класса и в рамках Big-O они равны.
Я могу утверждать, что в общем случае быстрая сортировка быстрее пузырьковой, так как они разного класса.
Или же сортировка 5 элементов пузырьком не эффективней быстрой сортировки?
Вы же даже процитировали меня, где я пишу «в общем случае». Разве сортировка 5 элементов — это общий случай?
В частных случаях Big-O может не давать ответа на вопрос, какой алгоритм лучше, тут нужны измерения. Но Big-O говорит о том, что мало смысла проводить сравнения с, например, пузырьковой сортировкой по умолчанию.

SirEdvin
15.09.2016 15:44Нет, можно. Да, в общем случае, но вполне себе можно.
Нельзя. Самым простым примером в данном случае будут алгоритмы умножение матриц. Алгоритм Штрассена имеет оценку в O (n^2.81), а новый алгоритм Копперсмита — Винограда имеет оценку в O(n^2.3727).
Но на практике используется алгоритм Штрассена или его модификация из-за того, что алгоритм Копперсмита — Винограда дает прирост только на безумно больших матрицах. Привет от спрятанной константы.
Sing
15.09.2016 16:03Изначально речь о том, что
Нельзя утверждать, что один алгоритм эффективнее другого на основании простого сопоставления их O-оценок.
А не о применимости в реальной жизни. И я уточнил, что это «в общем случае». Вы второй человек который пишет в ответ про реальную жизнь.
В реальной жизни очень много переменных, которые придётся учитывать и сделать это точно слишком сложно (если вообще возможно), проще измерять. По измерениям, на реальных матрицах эффективнее алгоритм Штрассена? Используйте его. Но это не значит что он сразу стал эффективнее, напротив.alexkolzov
15.09.2016 18:48Вы таким образом подменяете общее понятие «вычислительной эффективности» более узким «асимптотическая вычислительная сложность». Но тогда, как Вам указали выше, вы не сможете сделать различие между алгоритмами с одинаковой O-асимптотикой.
Sing
16.09.2016 10:45Во-первых, как я уже предложил ниже, давайте придём к общему пониманию понятия «вычислительной эффективности». Что вы понимали под ним в статье?
Во-вторых, на мой взгляд, асимптотическая сложность — это главный (и если мы говорим об аналитике, то единственный) критерий вычислительной эффективности алгоритма. Следовательно, алгоритм с лучшей асимптотикой будет эффективнее.
как Вам указали выше, вы не сможете сделать различие между алгоритмами с одинаковой O-асимптотикой.
На уровне анализа — не сможете, конечно. Эта разница проявится только во время измерений. И результаты могут вас удивить.
popolznev
15.09.2016 20:05А какой смысл вы вкладываете в слова "общий случай"? Если он на самом деле общий, то он должен включать все частные. А у вас что-то странное получается.
Sing
16.09.2016 10:24Да, общий случай — это такой случай, который включает все частные. То есть, и те матрицы, с которыми реально работают инженеры, и малюсенькие, и огромные, которые, возможно, никогда и не понадобятся. Или понадобятся через тысячи лет.
И вот в общем случае алгоритм с лучшей асимптотикой эффективнее.
alexkolzov
15.09.2016 18:41Перечитайте, пожалуйста, пример про алгоритмы перемножения матриц. Это не виртуальный, а вполне практически значимый пример.
Sing
15.09.2016 19:02+1Конечно, реальный. И пример правильный. Неправильный только вывод.
Ваш вывод
Нельзя утверждать, что один алгоритм эффективнее другого на основании простого сопоставления их O-оценок.
на мой взгляд, неверен.
Один алгоритм может быть эффективнее на ограниченном наборе значений n. Но это как сравнивать O(n) и O(log n). Можно найти пару конкретных вариантов, когда O(n) будет быстрее, но это не делает сам алгоритм эффективнее.
Человек, который, как у вас в примере, имеет именно такой случай и конкретные задачи должен это понимать.
PS. Кстати, на ограниченном наборе значений, как вы сами ловко подметили, у неё O(1), так что асимптотика теряет свой смысл.alexkolzov
15.09.2016 19:26Нет, не теряет. Из O(1) следует только ограниченность, но не следует, что невозможно подобрать мажорирующую функцию, которая будет точнее описывать поведение исследуемой функции.
Повторюсь, Вы просто подменяете понятия, называя «эффективностью алгоритма» его «асимптотическую сложность», в то время как это понятие включает в себя в том числе и поведение вычислимой функции на наборах данных конечной и даже конкретно фиксированной размерности.Sing
16.09.2016 00:49Из O(1) следует только ограниченность, но не следует, что невозможно подобрать мажорирующую функцию, которая будет точнее описывать поведение исследуемой функции.
А зачем вообще, по-вашему, подбирать мажорирующую функцию, если у нас уже есть исследуемая? Какой в этом смысл?
Повторюсь, Вы просто подменяете понятия, называя «эффективностью алгоритма» его «асимптотическую сложность», в то время как это понятие включает в себя в том числе и поведение вычислимой функции на наборах данных конечной и даже конкретно фиксированной размерности.
Пожалуйста, приведите определение понятия «эффективность алгоритма», чтобы впредь избежать подмены, в которой вы меня обвиняете. Учитывая, что в статье определения нет, то со ссылкой на литературу. Вполне возможно, что мы под эффективностью алгоритма понимаем разные вещи.alexkolzov
16.09.2016 22:11А у Вас нет исследуемой. У Вас есть некоторые приближенные сведения о ее поведении.
Вы задали интересный вопрос, мне показалось, что он достоин очень подробного ответа.
Самое, наверное, общее и неформальное определение сложности (временной) — зависимость времени выполнения алгоритма от входных данных. Но поскольку время есть понятие растяжимое, то его формализовывают. Это возможно только в контексте некоторой модели вычислений. Например, если в качестве отправной точки взять определение, даваемое тезисом Черча-Тьюринга и строгую модель вычислений без типизации, то можно определить понятие сложности таким образом:
Пусть T — некоторое конечное множество атомарных вычислимых частичных операций, называемых элементарными, определенных над термами языка U. Пусть также задана функция. Определим множества
как замыкание T относительно операций суперпозиции, примитивной рекурсии и минимизации, и U* — как множество всех конечных последовательностей из элементов U (то есть замыкание U относительно операции декартового произведения). Элементы U* будем обозначать
. Назовем сложностью вычислимой функции
относительно аргумента
значение функции L(s, a), определенной следующим образом:
1..
2. Если s есть суперпозиция функцийотносительно функции
, то есть
, то
.
3. Определим примитивную рекурсию (рекурсию по одному аргументу) относительно базы, функции перехода h и функции приращения t как функцию f, такую, что:
Тогда если s есть примитивная рекурсия с базой, функцией перехода h и функцией шага по аргументу t, то
. Это сложность попадания в базу.
4. Если s есть минимизация (по последнему аргументу) относительно k-го аргумента функции f, то есть,
— итерирующая функция,
— начальное значение, то
. Здесь G есть замыкание G0 множества
относительно операции композиции, в пересечении с множеством функций, определенных на U и имеющих результатом a (очевидно, такое множество либо пусто, либо содержит единственную функцию g);
.
5. Если s(a) не определена, то.
Надеюсь, выше написанное не привело Вас в ужас. Потому что фактически здесь не написано ничего кроме очевидного: под сложностью мы понимает взвешенную сумму всех выполненных над заданным набором данных элементарных операций, сложность которых мы можем указать априори. Определив способ построения алгоритма из этих операций — например, как здесь путем указания минимально достаточного количества способов их комбинирования — мы имеем возможность конструктивно определить функцию сложности. Также очевидно, что такое определение столь же точно, сколь и бесполезно: для определения сложности алгоритма нужно знать количество операций, требуемых для обработки любого допустимого набора данных. Поэтому для практического анализа пытаются упростить себе жизнь, рассматривая не поведение алгоритма на множестве допустимых аргументов, а зависимость количества операций от некоторых простых характеристик этих самых аргументов. Самой общей, обезличенной и, наверное, самой удобной такой характеристикой является размерность входных данных, и тогда в рассмотрение вводится функция зависимости количества требуемых операций от размерности. Вполне понятно, что даже при таком упрощении построить подобную зависимость бывает весьма сложно и даже если это удастся, то просто в силу имевшей место подмены она даст лишь приближенное понятие о том, как в действительности изменяется поведение алгоритма при разных наборах данных.
Поэтому любая оценка O(f(N)), где под N понимают размерность данных, не является достаточной и дающей хоть сколь нибудь полное описание поведения алгоритма характеристикой.
Далее, любой достаточно сложный алгоритм имеет в своей структуре некоторое количество других алгоритмов, решающих определенные подзадачи. Их сложность также зависит от размерности данных и характер этой зависимости оказывает влияние на общую сложность. Цена решения, функции сложности некоторых подзадач могут оказаться по значению большими уже при малых размерностях, но медленно растущими — и это значит, что при достаточно больших размерностях их вклад в общую картину станет малым или даже незначительным, но на малых размерностях они могут почти полностью определять суммарную сложность. Поэтому имеет смысл рассматривать поведение функций сложности как во вполне конкретном интервале операционных размерностей, так и ее асимптотическое поведение — это позволяет увидеть, какие эффекты будут угасать, а какие наоборот окажутся доминирующими. Это фактически и есть асимптотическая оценка: мы подменяем функцию сложности такой, что начиная с определенного момента она точно не будет недооценивать реальную сложность алгоритма при условии, что все данные одинаковой размерности считаются неразличимыми, и при этом не будет уж совсем сильно нам врать. При этом совсем уж точная такая оценка и не нужна, ведь оцениваемая величина сама по себе лишь приблизительно описывает то, что нас в действительности интересует. Хотя бы по этому исходя только лишь из асимптотических оценок нельзя делать выводы в терминах «лучше — хуже» и «эффективнее — неэффективнее», для таких категорических утверждений они просто не дают достаточной информации.
Но давайте ответим на вопрос: Вас как специалиста-практика именно это интересует? Общая тенденция? Более вероятно, что Вы хотели бы узнать более точно относительно поведения вашего алгоритма в конкретном диапазоне размерностей. Более того, при таком приближении размерность уже перестает быть характеристикой, достаточной для предсказания типичного поведения программы — и тут Вы можете и должны рассматривать еще и другие аспекты. Вам становится важна устойчивость алгоритма, зависимость сложности от распределения входных данных, степень значимости тех или иных параметров и пр.

Regis
16.09.2016 01:00+1Один алгоритм может быть эффективнее на ограниченном наборе значений n.
При этом конкретный набор значений n будет зависеть от так называемых «деталей реализации» и конкретного железа, на котором он будет выполняться.
Поэтому если хотите сравнивать алгоритмы (абстрактные, а не конкретные реализации), то вы можете только сравнивать их оценки (О-большое, О-малое и др.).alexkolzov
16.09.2016 22:13-1Нет, не верно. Дело не в железе, а в сложности структуры самих алгоритмов. Я там, выше, на вопрос коллеги простыню с пояснением накатал.
killik
13.01.2017 14:03+1AGM это просто когда электролит не плескается свободно, а весь находится в мокрой стекловате между пластинами. А картинка у Вас вообще от буферного использования, и то не самый лучший способ. На сегодня самые умные бесперебойники батарею вообще отключают после полной зарядки, и раз в пару недель подзаряжают — дает продление ресурса батареи до полутора раз.
bfDeveloper
15.09.2016 11:35+8Вы конечно правы, теоретически. Но вот на практике знать об асимптотике без возможности проецировать на задачу бессмысленно. Какие применения O нотации в программировании? Отсечь на ранних этапах совсем невозможное (O(e^n) при заведомо известных n > 100500) и оценить масштабируемость работающего решения. И в большинстве случаев масштабируемость оценивается очень хорошо. Линейный поиск на вдвое большем массиве работает вдвое медленней. А перебор всех пар (O(n^2)) — в 4 раза медленней. И это действительно работает и этим активно пользуются. Предложение считать доступ к памяти как O(sqrt(n)) вместо O(1) — всего лишь способ учесть на практике иерархии кэшей, просто эвристика. В любом инженерном деле таких допущений множество, эврситики проще точной теории. У математиков всегда волосы дыбом встают от того, что вытворяют физики и тем более инженеры. «Так нельзя!», зато работает.
При программировании же не асимптотика нужна, а просто прогноз масштабируемости, и с sqrt он будет ближе к правде.Sing
15.09.2016 13:10Какие применения O нотации в программировании?
Нотация помогает по-разному:
С одной стороны, да, это выбор алгоритма. Среди множества можно быстро найти если не оптимальный, то набор лучших и дальше работать с ними.
С другой, это общее понимание подхода к программированию. Если понимать, что O(n^2) масштабируется плохо, и понимать что два вложенных for — это, как правило, как раз такой случай, то программисты, может быть, два раза подумают, прежде чем пихать всюду «for i for j».
Все эти деревья, связные списки и прочие хитрые придумки программистов сложно объяснить и понять без понимания Big-O. А начать ими пользоваться не только потому что «так надо»?
Иногда нахожу мнение, что Big-O это такая волшебная палочка: сверься с ней — и будешь счастлив. А иногда — что это бесполезная фигня с лекций олдскульщиков. На самом деле, эта нотация обладает главным полезным свойством — она простая, но позволяет моментально делать выводы о том или ином подходе, не вдаваясь в детали.
alexkolzov
15.09.2016 19:14+1Простите конечно, но вот такое наукообразие меня раздражает. Это как сказать: у нас деталь неидеально круглой формы, по нормам не проходит, но давайте pi возьмем равным четырем — а инженерный расчет проведем как для круглой. Это же эвристическая оценка!
Если для вас факт перескакивания между уровнями памяти так критически важен — зачем вам вообще O-оценки, если за ними ничего, кроме Вашей персональной хотелки не стоит? Вы же в сущности хотите просто сказать, что если порции данных размера больше, чем некоторый и если в цикл скачет по памяти так, что каждый раз приходится обращаться к новой странице, то получится потеря в производительности, которой хотелось бы избежать. Так зачем делать вид, что за этим стоит какой-то строгий матаппарат?
Вы и так глядя в код и вывод профайлера поймете, где у Вас узкое место и как можно переформулировать алгоритм чтобы это компенсировать. Попробуйте вот так в инженерном деле взять, скажем, коэффициент Пуассона в расчете здания на прочность из головы — и вам оторвут всё отрывающееся.
lookid
15.09.2016 20:50+2Сейчас мы тут наспоримся, а завтра 99% комментариев пойдут писать бизнес логику на джаве и еще год не вспомнят об O-нотации. Скриньте!
MarazmDed
16.09.2016 00:06+2В бизнес-логике это тоже работает. Недоодинэсники начинают велосипедить циклы там, где можно обойтись одним запросом и получить примерно 100кратный прирост производительности. При чем тут О-большое? Понимание этой нотации заставляет призадуматься о подходе к решению задач.
MarazmDed
16.09.2016 00:09Кстати, о бизнес-логике. Подумалось внезапно, что бизнес-логика тоже бывает разной. В одной зеленой конторке бизнес-логика включает в себя, например, нелинейные задачи квадратичного программирования с нелинейными и невыпуклыми ограничениями — Солвер под такую стоит over 180килодолларов.
Saffron
Ну да, в умных книжках абстракный исполнитель в вакууме, а не реальное железо. И для него эти оценки работают. Но смысла от них как от машины тьюринга — одна теория. На практике необходима другая система оценки, оценивающая современную архитектуру. И понимание O большого никак не отменяет необходимости ввести другую систему оценки. Тоже теоретической, тоже модельной, но уже заточенной под наше железо.
Ваше предложение оценивать производительность алгоритмов постфактум, тестами — порочно. Откуда вы будете знать какие вообще алгоритмы реализовывать, чтобы потестить?
alexkolzov
Для написания программ под x86 пользы от машины Тьюринга и впрямь никакой, она не для этого и делалась. А вот для доказательства алгоритмической неразрешимости некоторых задач она очень даже кстати, а сие телодвижение позволит при попадании на такого рода задачу не биться головой об стену в поисках решения, а направить свои ментальные усилия в направлении поиска других подходов к вставшей инженерной проблеме.
Ваше замечание ровно о том, что я написал в конце. Вы хотите иметь не математический инструмент, а дельфийского оракула: Вы к нему с задачей — он Вам алгоритм, ну или хотя бы «посмотри сюда, сравни это — и будет тебе счастье», как в справочнике слесаря-сантехника. Не бывает так, нет здесь серебряной пули и нормальный теоретический анализ алгоритма требует подходить к нему больше, чем с одного бока. Не можете провести такой анализ — используйте экспериментальные методы исследования. Не можете или не хотите делать ни того, ни другого — пользуйтесь эмпирическими рекомендациями в руководствах по языкам программирования. Можете выполнить и то, и другое — вообще золотой специалист.
Saffron
Вы ошибаетесь, я разумеется, хочу иметь инструмент, а не волшебную палочку. Математический инструмент, в рамках которого удобно обсуждать производительность программы. Такой показатель, который позволяет классифицировать производительность алгоритмов, который легко вычислить для простого алгоритма, и к которому легко редуцировать составленный из более простых алгоритмов.
> Для написания программ под x86 пользы от машины Тьюринга и впрямь никакой, она не для этого и делалась. А вот для доказательства алгоритмической неразрешимости некоторых задач она очень даже кстати,
А вы не задумывались, зачем появилась в информатике О-большая нотация, когда уже была абстракция машины Тьюринга? Ведь последнего достаточно для рассуждений о вычислимости? Как оказалось, абстракция машины Тьюринга совершенно не подходит для оценки производительности алгоритмов на актуальном железе. И вот ввели новый инструмент, чисто для того, чтобы найти адекватный способ измерения производительности, подходящий для реального железа того периода.
Время идёт, новое железо уже совсем не похоже на старое. Понемногу, в деталях, оно трансформировалось в нечто, нарушающее все принципы машины фон-Неймана. Пора, соответственно, и математический аппарат подтянуть. Добавить новую, актуальную абстракцию. А старую модель оставить истории и теории, там же, где сейчас находится машина Тьюринга. Кстати, последнее время тьюринг-полноту принято показывать не приведением к оригинальной машине, а вычислением rule 110.
И задача теоретиков от computer science предоставить для практиков новую абстракцию, удобную к современному применению. Вы ведь не называете жалкими недоучками тех программистов, которые опираются (опирались когда это было актуально) на классические алгоритмы и их оценки?
alexkolzov
То, что Вы описали как раз вполне соответствует описанию волшебной палочки. Вы хотите иметь возможность запросто получать простые ответы на сложные вопросы.
Так получилось, что я эти вопросы знаю. Машина Тьюринга в принципе не предназначена для ответа на вопросы о вычислительной сложности, она предназначалась для получения строгого ответа на вопросы «что есть алгоритм?» и какой «класс задач можно решить чисто механически?». О-нотация появилась совсем не в связи с алгоритмами, а с изучением введенных Пуанкаре асимптотических рядов. Просто так получилось, что при анализе вычислительной сложности эта нотация обычно оказывается достаточно удобной. Она позволяет упростить анализ, исключая по мере надобности лишние множители. Это вообще никак не связано с реальным железом, только лишь с удобством вычислений. Так что не надо валить все в кучу.
Машины Тьюринга и архитектура фон Неймана вещи мало связанные и нарушение принципов второй никак не сказывается на первой. Чем стара эта модель, тем что не удовлетворяет вашим потребностям как специалиста-практика? Еще раз повторюсь, ее не для того придумывали. И свою историческую задачу она, вообще говоря выполнила. Для ответа на другие вопросы придумывались другие модели и приемы.
Но вы пытаетесь перевернуть все с ног на голову, ставя вопрос так, что вам нужен новый метод оценки старых алгоритмов. В самом основании этих «старых» алгоритмов лежали базовые упрощения действительности типа линейной модели памяти, и анализ их асимптотического поведения шел рука об руку с процессом их формулировки. Этот процесс не работает так, что вот мы что-то придумали — и давай его анализировать методами асимптотического анализа. Вас не устраивает, как старые алгоритмы ложатся на новое железо? Так садитесь и придумывайте новые. Но зачем же ставить CS-никам не свойственные им задачи потому, что такая их формулировка кажется Вам правильной?
Saffron
> Вы хотите иметь возможность запросто получать простые ответы на сложные вопросы.
Именно. А для чего ещё математика нужна?
> О-нотация появилась совсем не в связи с алгоритмами
Ну да. А теория категорий появилась гораздо раньше хаскеля. Но притащили её в CS как раз любители функционального программирования, приспособив для своих нужд уже имеющуюся математическую абстракцию.
> Чем стара эта модель, тем что не удовлетворяет вашим потребностям как специалиста-практика?
Не учитывает локальность памяти.
> Так садитесь и придумывайте новые.
Там и без меня справляются. Уже лет десять как написали сортировку для видеокарт, например.
Проблема в том, что пора обновлять базовые абстракции и лексику. Язык ведь частично определяет мышление. Если нет термина, то соответствующее явление попадает в слепое пятно. Потому статьи, что вы цитировали, так полезны — заставляют обратить внимание на объективное явление. Дальше уже каждый по мере разумения корректирует свои представления. Говорит «а ведь и правда, есть такое дело», начинает по-новому смотреть на мир. Ну и предлагает остальным прозревшим разработать общую терминологию и общие решения для описанных проблем. Это как паттерны проектирования — полезны тем, что структурируют мысли и дают программистам общий язык.
alexkolzov
Математика дает ответы, когда и если поставлены правильные вопросы. Предлагаете свою постановку — Ваше право. Но на результат не обижайтесь.
Ну так и я об этом, О-нотация была привнесена как удобное средство описания и анализа. Реальное железо тут совсем не при чем, как и машины Тьюринга.
И не должна, потому что с точки зрения алгоритмической полноты это свойство не имеет значение.
А до прочтения этих статей факт того, что память разделена на несколько уровней, был от Вас сокрыт? Просто это не тот вопрос, который требует какого-то перелопачивания теории, поскольку те самые асимптотические оценки остаются, вообще говоря, справедливыми. Авторы процитированных мной статей банально не понимают, что такое асимптотические оценки, пытаются рассуждать о них в привычных для себя категориях и приходят к (первый) выводу, что, пардон, ну их нафиг, лучше доверять тестам, чутью и мануалам на библиотеки языка, и (второй) к какой-то нелепой, высосанной из пальца оценке с наукообразным ее обоснованием. И тут проблема в том, что никто никого не вводил в заблуждения — сами заблудились, воспринимая такие оценки не тем, чем они на самом деле являются, а как нечто монолитное.
Да, фактическое поведение временной сложности изменилось, стало более сложным — но учитывать такого рода нюансы в рамках общего подхода, пытаться на каждый случай делать модели и формулировать подходы — дело гиблое, тут больше на руку сыграет тот же статистический анализ. Такие проблемы не в ведении ученых — они для них пусты, а в зоне Вашей ответственности: оцените потребность программы в памяти, особенности естественной организации данных, характер ожидаемых обращений, а если в состоянии — особенности целевой архитектуры и алгоритмов управления памятью операционной системы. После этого можно прикинуть подходящую оценку сложности того или иного алгоритма, поднять имеющиеся рекомендации к применению функций выбранной библиотеки и принять конкретное инженерное решение. Если Вы хотите, чтобы эту работу сделали за Вас яйцеголовые, предоставив некоторую общую модель — слишком многого хотите.
А базовые абстракции и так обновляются, а точнее пополняются. Появляются модели вычислителей с распределенной памятью, grid-архитектурой и пр. В рамках этих моделей как раз и разрабатываются новые алгоритмы и методы анализа. Насчет языков соглашусь, такая проблема есть, хотя и не стоит пока очень уж остро.
Saffron
> А до прочтения этих статей факт того, что память разделена на несколько уровней, был от Вас сокрыт?
Нет, конечно. Но я не задумывался во всей полноте о последствиях. Привык полагаться на асимптотические оценки.
> Да, фактическое поведение временной сложности изменилось, стало более сложным
Ага. Вместе с этим изменилась целевая функция оптимизации. Что предполагает необходимость замены некоторых классических алгоритмов на другие. И на стандартизацию работы с кешами. Необходимо уже как-то более осознанно подходить к кешированию памяти, доставать её из-под капота. Потому что, пока она пребывает исключительно под капотом компиляторов и шедулеров, её трудно учитывать.
> Тут больше на руку сыграет тот же статистический анализ.
Как вы будете статистически анализировать _алгоритмы_?
alexkolzov
Я вам не скажу за всю Одессу… но вот лично по моему опыту если уж встала реальная потребность в оптимизации какого-либо критичного участка кода, то такие вопросы, как сложность наиболее часто выполняемой в коде операции для различных подходящих под нужды структур, локализация выделяемых участков памяти, возможность выделения памяти в стеке вместо кучи, способ организации коллекций в стандартных библиотеках и прочие детали производства сами всплывают в памяти с пометкой «важно». Иногда приходится вообще отказываться от стандартных решений в плане организации данных. Мной это воспринимается как часть нормальной инженерной работы, которую куда легче и лучше выполнить ручками, нежели рыться в поисках свежей публикации с более адекватной моей задаче моделью вычислительной системы. Ну не учтете вы все нюансы в абстрактной модели.
Вы, видимо, хотите поймать меня за руку на неточности определения. Уточнюсь. Можно использовать результаты статистического анализа программной реализации алгоритма. Или нескольких реализаций. Да хоть всех когда-либо написанных на всех известных человечеству архитектурах, если это позволит принять Вам обоснованное решение по выбору и алгоритма, и его конкретного программного воплощения.
Saffron
Проблема собственно в том, что их надо предварительно реализовать. Если задача действительно важная, вы, конечно, найдёте время реализовать десять разных алгоритмов и прогнать их через тесты. Вопрос заключается в другом, как отобрать эти десять перспективных алгоритмов для реализации и тестирования? По каким параметрам?
alexkolzov
Провести предварительную приблизительную оценку. О-оценка — первый эшелон. Вы знаете характерную размерность данных и, вероятно, только на основании этого сможете сузить круг кандидатов. Далее, у Вас есть описание алгоритмов и думаю, что Вы в состоянии оценить, насколько их особенности сыграют в плюс или в минус в Вашем случае. Потом можете посмотреть документацию на основные реализации выбранных алгоритмов, там часто есть замечания, которые стоит принять к сведению. И если у Вас осталось несколько перспективных кандидатов — лопату в руки и проводим эксперимент. Замеряем то, что для Вас критично — расход памяти, среднее время для характерных размерностей, разброс результатов при характерном же распределении данных и т.п.
dkosolobov
То что вы ищете называется cache-oblivious model: https://en.wikipedia.org/wiki/Cache-oblivious_algorithm
Эта модель, придуманная ещё в середине девяностых, несколько более сложна, чем традиционная RAM, поэтому под неё разработано меньше алгоритмов. Так получается, я полагаю, потому что при решении ещё нерешённой задачи люди сначала предпочитают всесторонне рассмотреть её в близкой (и часто практической), но более простой обычной RAM, а уже потом смотрят на кэш/внешнюю память/параллелизм.
Arlekcangp
Ну не была О-нотация заточена под конкретное железо то никогда. Она была сделано же для того что бы можно было посмотреть как поведет себя алгоритм при изменениях количества и качества входных данных. И с этим неплохо справляется.
С чего вдруг теоретики должны под конкретную платформу предоставлять новые нотации? А универсальной нотации тут очевидно быть не может. Автор совершенно прав — мозгами думать просто надо а не на О-нотацию все валить.
popolznev
Создатели о-символики и не помышляли об алгоритмах.
Arlekcangp
Спасибо. Действительно, как то не подумал что ее применение гораздо шире чем только анализ алгоритмов.
Sergey_Kovalenko
Если не для тех, кто пишет программы, то для кого проводились исследования и строилась теория вычислительной сложности? «Глас народа — ...». Оценки сложности всегда даются по отношению к некоторой конкретной вычислительной модели, и тот факт, что народ негодует по поводу применяемой RAM модели с доступом к памяти за ограниченное константой количество ходов машины имеет на самом деле не только расхождение с реальными машинами но и некоторые противоречия с теорией передачи информации. Вот вам задачка:
Пусть имеются конечный набор типов идеальных логических элементов («транзисторов» или схем, реализующих более сложные функции). Можно ли построить, пусть даже из бесконечного числа таких элементов, универсальную вычислительную машину с бесконечным адресным пространством и равномерно ограниченным временем доступа ко всем ячейкам памяти (конечного объема), если все логические элементы тратят ровно один ход на выполнения реализуемой ими функции, а сигнал между ними передается мгновенно?
Заметьте, что я снял все ограничения физического или экономического характера, тем не менее, бьюсь об заклад, что смогу перенумеровать ячейки памяти любой удовлетворяющей условиям машины так, что доступ к ним из начального состояния будет ограничен снизу по количеству шагов логарифмом их номера в моей нумерации.
alexkolzov
Вот только теорию информации сюда приплетать не надо, ее задачи ортогональны задачам теории алгоритмов и вычислительной сложности. И если мы с Вами начнем еще и ее обсуждать в контексте программистской практики, то сильно рискуем заблудиться в деталях. Вы ж не будите в самом деле в процессе написания прикладной программы с сетевым обменом под винду еще и учитывать особенности передачи сигнала по беспроводному каналу?
Про необходимость ограниченности времени доступа к памяти некоторой константой нигде не говорилось, это бы противоречило допущению бесконечности памяти. Говорилось о том, что вводя такие понятия, как массив или линейный список обычно явно или неявно фиксируются базовые допущения, потом постулируются основные свойства и далее вводятся и параллельно оценивается сложность основных операций. Это значит, что говоря слово «массив» вы уже предполагаете одинаковое время доступа к произвольному элементу и только тогда имеете право опираться на полученные для массива оценки сложности. В случае иерархической организации памяти такие допущения приемлемы, если в среднем большая часть операций проводится на одном из уровней. Если же Вы понимаете, что у вас характер распределения данных и обращения к ним таков, что такие эффекты окажут существенное влияние на общий итог — ну так учтите это, рассмотрите такую организацию данных как другую структуру, свойства которой точнее отражают состояние дел. Так нет же, Вы хотите, чтобы кто-то за вас рассмотрел «массив» в устраивающем именно Вас смысле этого слова. Поймите, это вообще не задача тех, кто занимается исследованием алгоритмов и теорией вычислений, учет нюансов целевой архитектуры — это задача в первую очередь разработчиков операционных систем и компиляторов. Это они озадачены тем, как наиболее эффективно спроецировать алгоритмы, сформулированные в терминах удобной для использования и исследования модели, на реальное железо. Если Вам не нравятся их решения — берите в руки спецификацию на процессор и делайте всё сами. Вот если действующая модель принципиально не ложится на конкретный набор железа хоть сколь-нибудь эффективно как, например, в случае гетерогенных распределенных вычислительных систем — вот тут в игру вступают дядьки в очках на носу и с мелом в руках и вводят в рассмотрение новые модели и методы. А вопросы, на которых Вы пытаетесь заострить внимание, вполне в компетенции инженеров (должны быть, по крайней мере) и для теоретиков большого интереса не представляют.
khdavid
А все-таки время доступа к элементам массива из n элементов в оперативке зависит от n? Sergey_Kovalenko утверждает, что это логарифм, а не константа.
Visseri
Вы действительно считаете, что от статьи Тьюринга и описания его машины не было никакого толку?