

Введение
При внедрении статического анализатора в существующий процесс разработки, команда может столкнуться с определенными трудностями. Например, очень полезно проверять измененный код перед тем, как он попадет в систему контроля версий. Однако, выполнение статического анализа в этом случае может требовать достаточно продолжительного времени, особенно на проектах с большой кодовой базой. В этой статье мы рассмотрим режим инкрементального анализа в статическом анализаторе PVS-Studio, который позволяет проверять только измененные файлы, что значительно сокращает время, необходимое для анализа кода. Следовательно, разработчики смогут использовать статический анализ так часто, как это необходимо, и минимизировать риски попадания кода, содержащего ошибку, в систему контроля версий. Поводом для написания статьи послужило, во-первых, желание еще раз рассказать о такой полезной функции нашего анализатора, а во-вторых, тот факт, что мы полностью переписали механизм инкрементального анализа и добавили поддержку этого режима в версию нашего анализатора для командной строки.
Сценарии использования статического анализатора
Любой подход к повышению качества программного обеспечения предполагает, что дефекты должны обнаруживаться как можно раньше. В идеальной ситуации, код нужно писать вообще без ошибок, но в наше время эта практика успешно внедрена только в одной корпорации:

Почему же так важно обнаруживать и устранять ошибки как можно раньше? Я не буду здесь говорить о таких банальных вещах как репутационные риски, которые неизбежно возникнут, если ваши пользователи начнут массово обнаруживать дефекты в вашем программном обеспечении. Давайте сосредоточимся именно на экономической составляющей исправления ошибки в коде. У нас нет статистики по средней цене ошибки. Ошибки бывают очень разные, обнаруживаются на разных этапах жизненного цикла программного обеспечения, программное обеспечение может применяться в разных предметных областях, как критичных к ошибкам, так и не очень. Поэтому, хотя средняя по индустрии стоимость исправления дефекта в зависимости от стадии жизненного цикла ПО неизвестна, оценить изменение этой стоимости можно, используя известное правило «1-10-100». Применительно к разработке программного обеспечения, это правило утверждает, что если стоимость устранения дефекта на этапе разработки равна 1 ?, то после передачи этого кода в тестирование составит уже 10 ?, и вырастает до 100? после того, как код с дефектом ушел на продакшен:
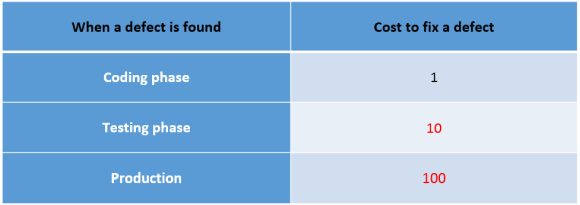
Существует множество причин для такого быстрого роста цены исправления дефекта, например:
- Изменения в одной части кода могут затронуть множество других частей приложения.
- Повторное выполнение уже сделанных задач: изменения в дизайне, кодирование, внесение корректировок в документацию и т.д.
- Доставка исправленной версии пользователям, необходимость убедить пользователей обновиться.
Понимая важность того, что следует устранять ошибки на наиболее ранних этапах жизненного цикла ПО, мы предлагаем нашим клиентам использовать двухуровневую схему проверки кода статическим анализатором. Первый уровень – это проверка кода на компьютере разработчика перед тем, как код будет заложен в систему контроля версий. То есть разработчик пишет какой-то фрагмент кода и сразу инспектирует его статическим анализатором. Для этой задачи у нас есть плагин для Microsoft Visual Studio (поддерживаются все версии с 2010 до 2015 включительно). Плагин позволяет проверить один или несколько файлов исходного кода, один или несколько проектов или все решение целиком.
Второй уровень защиты — это запуск статического анализа во время ночной сборки проекта. Это позволяет убедиться, что новые ошибки не были добавлены в систему контроля версий, или же предпринять необходимые действия, чтобы эти ошибки исправить. Для того, чтобы минимизировать риск проникновения ошибок на более поздние этапы жизненного цикла ПО, мы предлагаем использовать оба уровня выполнения статического анализа: локально на машинах разработчиков и на централизованном сервере непрерывной интеграции.
Такой подход, однако, не лишен недостатков и не гарантирует, что ошибки, которые могут быть обнаружены статическим анализатором, не попадут в систему контроля версий или, в крайнем случае, будут исправлены до того, как билд уйдет в тестирование. Принуждение разработчиков обязательно выполнять вручную статический анализ перед коммитом, наверняка столкнется с сильным сопротивлением. Во-первых, на проектах с большой кодовой базой никто не захочет сидеть и ждать, пока проект будет проверен. Либо же, если разработчик решит сэкономить время и проверить только те файлы, код в которых он изменял, ему придется вести учет измененных файлов, что, естественно, тоже никто не будет делать. Если же мы рассмотрим сборочный сервер, на котором, помимо ночных сборок, также настроена сборка после обнаружения изменений в системе контроля версий, то выполнение статического анализа всей кодовой базы во время многочисленных дневных сборок также неприменимо из-за того, что статический анализ потребует много времени.
Режим инкрементального анализа, позволяющий проверять только последние измененные файлы, помогает решить эти проблемы. Рассмотрим более подробно, какие преимущества может принести режим инкрементального анализа при использовании на компьютерах разработчиков и на сборочном сервере.
Инкрементальный анализ на компьютере разработчика — барьер на пути багов в систему контроля версий
Если команда разработчиков приняла решение использовать статический анализ кода, и анализ выполняется только на сборочном сервере, во время, например, ночных сборок, рано или поздно разработчики начнут статический анализатор воспринимать как врага. Неудивительно, ведь все члены команды будут видеть, какие ошибки допускают их коллеги. Мы стремимся к тому, чтобы все участники проекта воспринимали статический анализатор как друга и как полезный инструмент, который помогает улучшать качество кода. Для того, чтобы ошибки, которые может обнаруживать статический анализатор, не попадали в систему контроля версий и на всеобщее обозрение, статический анализ должен выполняться также и на компьютерах разработчиков, чтобы выявлять возможные проблемы в коде как можно раньше.
Как я уже упоминал, ручной запуск статического анализа на всей кодовой базе может потребовать достаточно продолжительного времени. Если же разработчик будет вынужден запоминать, над какими файлами с исходным кодом он работал, это также будет очень сильно раздражать.
Инкрементальный анализ позволяет и сократить время, которое требуется для выполнения статического анализа, и избавиться от необходимости вручную запускать анализ. Инкрементальный анализ запускается автоматически после сборки проекта или решения. Мы считаем этот триггер наиболее подходящим для запуска анализа. Вполне логично проверить, что проект собирается, перед тем, как внести изменения в систему контроля версий. Таким образом, режим инкрементального анализа позволяет избавиться от раздражающих действий, связанных с необходимостью вручную выполнять статический анализ на компьютере разработчика. Инкрементальный анализ выполняется в фоновом режиме, поэтому разработчик может продолжать работать над кодом, не дожидаясь окончания проверки.
Включить режим послесборочного инкрементального анализа можно в меню PVS-Studio/Incremental Analysis After Build (Modified Files Only), данный пункт активирован в PVS-Studio по умолчанию:
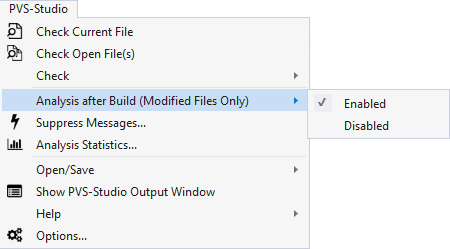
После активации режима инкрементного анализа PVS-Studio станет автоматически в фоновом режиме производить анализ всех затронутых модификациями файлов сразу после окончания сборки проекта. Если PVS-Studio обнаружит такие модификации, инкрементальный анализ будет автоматически запущен, а в области уведомлений Windows появится анимированная иконка PVS-Studio:
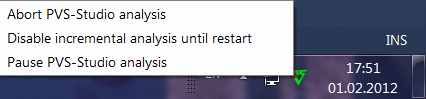
Подробности, связанные с использованием инкрементального анализа, рассмотрены в статье Режим инкрементального анализа PVS-Studio.
Инкрементальный анализ на сервере непрерывной интеграции — дополнительный барьер на пути багов
Практика непрерывной интеграции подразумевает, что проект собирается на сборочном сервере после каждого коммита в систему контроля версий. Как правило, кроме сборки проекта также выполняется существующий набор юнит-тестов. В дополнение к юнит-тестам многие команды, применяющие практику непрерывной интеграции, используют сборочный сервер для обеспечения процессов непрерывного контроля качества. Например, кроме прогона модульных и интеграционных тестов, эти процессы могут включать выполнение статического и динамического анализа, измерение производительности и т.д.
Одним из важных требований к задачам, выполняемым на сервере непрерывной интеграции, является то, что сборка проекта и выполнение всех дополнительных действий должны проходить быстро, чтобы команда могла оперативно отреагировать на обнаруженные проблемы. Выполнение статического анализа на большой кодовой базе после каждого коммита в систему контроля версий противоречит этому требованию, поскольку это может требовать весьма продолжительного времени. Мы были не согласны мириться с таким ограничением, поэтому посмотрели на наш плагин для Visual Studio, в котором уже давно существует режим инкрементального анализа, и спросили себя: а почему бы нам не реализовать такой же режим в модуле для командной строки PVS-Studio_Cmd.exe?
Сказано — сделано, и в нашем модуле для командной строки, который предназначен для интеграции статического анализатора в различные сборочные системы, появился режим инкрементального анализа. Этот режим работает так же, как инкрементальный анализ в плагине.
Таким образом, с добавлением поддержки инкрементального анализа в PVS-Studio_Cmd.exe стало возможно использовать наш статический анализатор в системе непрерывной интеграции во время многочисленных дневных сборок. За счет того, что будут проверены только измененные файлы с момента последнего обновления кода из системы контроля версий, статический анализ будет выполнен очень быстро, и продолжительность сборки проекта практически не увеличится.
Чтобы активировать режим инкрементального анализа в модуле для командной строки PVS-Studio_Cmd.exe, укажите ключ --incremental и задайте один из следующих режимов работы:
- Scan – проанализировать все зависимости для определения того, на каких файлах должен быть выполнен инкрементальный анализ. Непосредственно анализ выполнен не будет.
- Analyze – выполнить инкрементальный анализ. Этот шаг должен выполняться после выполнения шага Scan, и может выполняться как до, так и после сборки решения или проекта. Статический анализ будет выполнен только для измененных файлов с момента последней сборки.
- ScanAndAnalyze — проанализировать все зависимости для определения того, на каких файлах должен быть выполнен инкрементальный анализ, и сразу же выполнить инкрементальный анализ измененных файлов с исходным кодом.
Для получения более подробной информации о режиме инкрементального анализа в модуле для командной строки PVS-Studio_Cmd.exe, обратитесь к статьям Режим инкрементального анализа PVS-Studio и Проверка Visual C++ (.vcxproj) и Visual C# (.csproj) проектов из командной строки с помощью PVS-Studio.
Хочу также отметить, что с функциональностью инкрементального анализа отлично сочетается использование утилиты BlameNotifier, поставляемой в дистрибутиве PVS-Studio. Эта утилита взаимодействует с популярными системами контроля версий (на данный момент поддерживаются Git, Svn и Mercurial), чтобы получить информацию о том, кто из разработчиков закоммитил код, содержащий ошибки, и разослать уведомления этим разработчикам.
Таким образом, мы рекомендуем использовать следующий сценарий применения статического анализатора на сервере непрерывной интеграции:
- для многочисленных дневных сборок выполнять инкрементальный анализ, чтобы контролировать качество кода только модифицированных файлов;
- для ночной сборки целесообразно выполнять полный анализ всей кодовой базы, чтобы иметь полную информацию о дефектах в коде.
Особенности реализации режима инкрементального анализа в PVS-Studio
Как я уже отметил, режим инкрементального анализа в плагине PVS-Studio для Visual Studio существует уже давно. В плагине определение измененных файлов, для которых должен выполняться инкрементальный анализ, было реализовано с помощью COM-оберток Visual Studio. Такой подход абсолютно неприменим для реализации режима инкрементального анализа в версии нашего анализатора для командной строки, поскольку он полностью независим от внутренней инфраструктуры Visual Studio. Поддержка разных реализаций, выполняющих одну и ту же функцию в разных компонентах, — не самая хорошая идея, поэтому мы сразу решили, что плагин для Visual Studio и утилита для командной строки PVS-Studio_Cmd.exe будут использовать общую кодовую базу.
Теоретически, задача по обнаружению модифицированных файлов с момента последней сборки проекта не представляет особой трудности. Для ее решения нам нужно получить время модификации целевого бинарного файла и время модификации всех файлов, участвовавших в построении целевого бинарного файла. Те файлы с исходным кодом, которые были изменены позднее, чем целевой файл, должны быть добавлены в список файлов для инкрементального анализа. Реальный мир, однако, гораздо сложнее. В частности, для проектов, реализованных на C или C++, весьма сложно определить все файлы, участвовавшие в построении целевого файла, например, те заголовочные файлы, которые были подключены напрямую в коде, и отсутствуют в проектном файле. Здесь я хочу отметить, что под Windows и наш плагин для Visual Studio (что очевидно), и версия для командной строки PVS-Studio_Cmd.exe поддерживают только анализ проектов MSBuild. Этот факт существенно упростил нашу задачу. Стоит также упомянуть, что в Linux версии PVS-Studio тоже возможно использование инкрементального анализа — там это работает «из коробки»: при использовании мониторинга компиляции будут анализироваться только собираемые файлы. Соответственно, при инкрементальной сборке запустится инкрементальный анализ; при прямой интеграции в сборочную систему (например, в make файлы) ситуация будет аналогичной.
В MSBuild реализован механизм отслеживания обращений к файловой системе (File Tracking). Для инкрементальной сборки проектов, реализованных на C и C++, соответствия между исходными файлами (например, cpp-файлами, заголовочными файлами) и целевыми файлами записываются в *.tlog-файлы. Например, для задачи CL пути ко всем исходным файлам, прочитанным компилятором, будут записаны в файл CL.read.{ID}.tlog, а пути к целевым файлам будут сохранены в файле CL.write.{ID}.tlog.
Итак, в файлах CL.*.tlog у нас уже есть вся информация об исходных файлах, которые были скомпилированы, и о целевых файлах. Задача постепенно упрощается. Однако, все равно остается задача обойти все исходные и целевые файлы и сравнить даты их модификации. Можно ли упростить еще? Конечно! В пространстве имен Microsoft.Build.Utilities находим классы CanonicalTrackedInputFiles и CanonicalTrackedOutputFiles, которые отвечают за работу с файлами CL.read.*.tlog и CL.write.*.tlog соответственно. Создав экземпляры этих классов и используя метод CanonicalTrackedInputFiles.ComputeSourcesNeedingCompilation, получаем список исходных файлов, требующих компиляции, на основании анализа целевых файлов и графа зависимостей исходных файлов.
Приведем пример кода, позволяющий получить список файлов, на которых должен быть выполнен инкрементальный анализ, с помощью выбранного нами подхода. В этом примере sourceFiles – это коллекция полных нормализованных путей ко всем исходным файлам проекта, tlogDirectoryPath – путь к директории, в которой находятся *.tlog-файлы:
var sourceFileTaskItems =
new ITaskItem[sourceFiles.Count];
for (var index = 0; index < sourceFiles.Count; index++)
sourceFileTaskItems[index] =
new TaskItem(sourceFiles[index]);
var tLogWriteFiles =
GetTaskItemsFromPath("CL.write.*", tlogDirectoryPath);
var tLogReadFiles =
GetTaskItemsFromPath("CL.read.*", tlogDirectoryPath);
var trackedOutputFiles =
new CanonicalTrackedOutputFiles(tLogWriteFiles);
var trackedInputFiles =
new CanonicalTrackedInputFiles(tLogReadFiles,
sourceFileTaskItems, trackedOutputFiles, false, false);
ITaskItem[] sourcesForIncrementalBuild =
trackedInputFiles.ComputeSourcesNeedingCompilation(true);Таким образом, используя стандартные средства MSBuild, мы добились того, что механизм определения файлов для инкрементального анализа идентичен внутреннему механизму MSBuild для инкрементальной сборки, что обеспечивает очень высокую надежность этого подхода.
Заключение
В этой статье мы рассмотрели преимущества, которые приносит использование инкрементального анализа на компьютерах разработчиков и на сборочном сервере. Также мы заглянули под капот и узнали, как, используя возможности MSBuild, определить, для каких файлов нужно выполнять инкрементальный анализ. Предлагаю всем, кого заинтересовали возможности нашего продукта, скачать пробную версию анализатора PVS-Studio и посмотреть, а что же может обнаружиться в ваших проектах. Всем качественного кода!

Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Pavel Kuznetsov. Incremental analysis in PVS-Studio: now on the build server
Прочитали статью и есть вопрос?
Часто к нашим статьям задают одни и те же вопросы. Ответы на них мы собрали здесь: Ответы на вопросы читателей статей про PVS-Studio, версия 2015. Пожалуйста, ознакомьтесь со списком.
Поделиться с друзьями
Комментарии (5)

mickvav
13.02.2017 14:50Так, а почему не повесить на precommit-hook в гите и не научить присылать разработчику письмо с проблемами (и не пускать изменения в основную ветку)?

EvgeniyRyzhkov
13.02.2017 14:54+2Никто не мешает так сделать. Вызов анализа можно прикрутить к хуку. Просто один отдельный файл (без запуска всей сборки) проверить-то нельзя.
olekl
13.02.2017 16:32Думаю, даже для сторонников анализатора такой подход будет слишком жестким и в лучшем случае приведет к сокрытию предупреждений по принципу «отстань от меня»…
EvgeniyRyzhkov
13.02.2017 16:33Согласен. Мы НЕ рекомендуем такую политику использования, так как это слишком агрессивно
lookid