

В прошлый раз я описал в общих чертах использование Akka для игрового сервера.
Сейчас разберем простой, но тем не менее рабочий пример сервера.
Дискляймер
Те, кто шарит в теме, могут найти неточности и упрощения в описании. Так и было задумано. Я хотел показать общие моменты для тех, кто не знает, что это и как это можно использовать. Приведенный пример стоит рассматривать не как готовый к продакшену код. А скорее как рабочий шаблон для экспериментов.
В прошлой статье, уже было в общих чертах описано почему akka это хорошо.
Поэтому сразу приступим к созданию сервера.
Архитектура
У нас стоит задача сделать многопользовательскую игру, ну пусть это будут танчики (ага, свежая идея).
В исходниках, на гитхабе, будут и сервер и клиент. Но здесь мы рассмотрим только сервер.
Сам сервер будет состоять из нескольких сервисов.
Каждый сервис представляет из себя актор, принимающий сообщения. В реальной системе, этот актор, скорее всего, будет супервизором для акторов непосредственно обрабатывающих сообщения. Т.е. сам актор сервиса никакой работы делать не будет.
Он будет только запускать рабочие акторы и следить за их работой, например, перезапускать при необходимости. У нас же ситуация упрощенная. Поэтому всю работу акторы будут делать сами.
Итак, давайте сначала нарисуем, что мы вообще делаем.
Это наш меганавороченный клиент. Фул 3D, между прочим:
А это сервер:
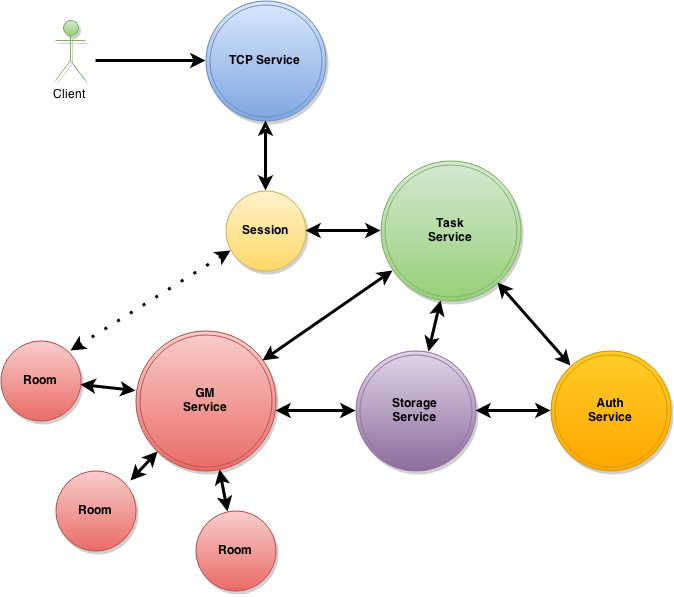
Стрелочками обозначены потоки сообщений между акторами.
1. TCP service – сервис отвечающий за подключение клиентов. У нас вариант с TCP.
2. Session – актор игровой сессии. Отвечает за обмен сообщениями с клиентом.
3. Task service – сервис для выполнения общих задач.
4. Auth service – сервис выполняющий аутентификацию игрока.
5. GM service – сервис игровой механики. Отвечает за управление комнатами и общими игровыми действиями…
6. Room – это акторы, выполняющие роль комнат, в которых и происходит игра.
7. Storage – сервис для работы с хранилищем данных. БД SQL или еще что либо.
Распишем подробнее, что же у нас получилось.
Я буду приводить здесь только кусочки кода. Весь код выложен на гитхаб.
TCP service
Akka, на данный момент, в стандартной поставке поддерживает TCP и UDP подключения. В экспериментальной ветке есть и WebSocket. Мы будем использовать TCP. Сетевой стек в Akka, берет свои корни у Spray и работает более эффективно, чем например Netty. Хотя у Netty, при этом, больше функционала.
Итак, клиент подключается к TCP service. Ему создается актор connection, отвечающий непосредственно за соединение. После установления соединения, мы создаем актор Session, который отвечает за игровую сессию и через connection обменивается сообщениями с клиентом.
При работе с TCP есть некоторые нюансы. TCP это постоянное соединение. И не всегда система может точно сказать, клиент все еще подключен или уже нет.
Поэтому для проверки клиента используют так называемый Heartbeat. Сервер пингует периодически клиент, пустым пакетом, чтобы понять, есть ли еще подключение.
Для этого в Session заводится шедуллер, который в нашем случае пингует клиент каждые 10 сек.
scheduler = context.system.scheduler.schedule(10.seconds, 10.seconds, self, Heartbeat)
Далее, как только связь с клиентом установлена, он посылает серверу команду на аутентификацию. Ее принимает актор Session.
Session перенаправляет сообщение к Task service. Что бы тот разобрался, что это вообще за сообщение и что с ним делать. Оно выглядит так:
case class CommandTask(session: ActorRef, comm: PacketMSG)
Да, забыл пояснить. В качестве транспорта используем Protobuf. Так что здесь PacketMSG это протобафовский объект, наше сообщение от клиента. Session это ссылка на актор сессии игрока.
Task service
Это сервис отвечающий за общие задачи, выполняемые на сервере. В нашем случае он является основным роутером команд от клиента. Но это, естественно, не серебряная пуля. Система сообщений в Akka очень гибкая. И можно довольно хитро настраивать роутинг сообщений встроенными средствами. Но двигаться нужно от простого к сложному. Сразу все возможности не охватишь.
Вообще, Task service в реальном сервере сам ничего делать не будет. Он только запускает дочерние акторы, которые уже и будут выполнять всю работу. Или же сами порождать еще свои дочерние акторы для выполнения конкретных действий. В общем тут уже много вариантов. В нашем случае, Task service определит, что это запрос аутентификации и просто отправит сообщение на Auth service, с задачей проверить, есть ли игрок с заданными параметрами аутентификации.
def handlePacket(task: CommandTask) = {
task.comm.getCmd match {
case Cmd.Auth.code => authService ! Authenticate(task.session, task.comm)
case Cmd.Join.code => gameService ! JoinGame(task.session)
case Cmd.Move.code => gameService ! PlayerMove(task.session, task.comm)
case _ => log.info("Crazy message")
}
}
Auth service
Сервис, отвечающий за аутентификацию. У нас он очень примитивный. Умеет только ходить в БД за пользователем:
override def receive = {
case task: Authenticate => handleAuth(task)
case task: SomePlayer => handleAuthenticated(task)
case task: AuthenticatedFailed => handleFailed(task)
case _ => log.info("unknown message")
}
Если он получает Authenticate, значит, надо сходить в БД проверить:
case class GetPlayerByName(session: ActorRef, comm: PacketMSG)
Если получает SomePlayer, значит, аутентификация успешна и можно сообщить эту радостную новость всем заинтересованным. Игроку и GM.
task.session ! Send(Cmd.AuthResp, login.build().toByteArray)
gameService ! task
А если AuthenticatedFailed, значит, не нашли игрока, и эту печальную новость тоже надо сообщить всем заинтересованным. В данном случае только игроку. Кстати, в реальном сервере такие попытки можно считать и наказывать настырных:
task.session ! Send(Cmd.AuthErr, Array[Byte]())
Собственно, никто не мешает навернуть его по полной, обеспечив самые разные варианты аутентификации.
Storage
Работа с БД в Akka это отдельная тема. Т.к. внутри работа происходит на обычных потоках. То создав много «долгоиграющих» задач акторам, можно подвесить всю систему. Акторы должны быть легковесными. У нас в качестве «БД» используется обычный список. Поэтому ничего не будет тормозить. Но реальная БД заблокирует поток надолго. Поэтому в реальном проекте актору, работающему с БД, выделяется отдельный поток, или пул потоков, чтобы он не тормозил всю систему.
Если игрок нашелся, то в актор Session отправляется сообщение с успешной аутентификацией, который уже упакует его и отправит клиенту
Ну вот мы и зашли в игру.
Далее клиент, посылает сообщение «Начинаем игру». Task service перенаправит сообщение GM service, он создаст комнату и поместит в нее игрока.
Затем оповестит клиента о начале игры.
Но у нас реализация простая, поэтому сразу после подключения первого игрока, сервер автоматом создаст комнату и поместит в нее игрока. Таким образом все подключившиеся, будут в одной комнате.
GM service
Это основной сервис игры. Он знает про всех подключившихся игроках. Знает сколько у него комнат создано и может выступать в роли части системы балансировки нагрузки. У нас сессионная игра, поэтому вся игровая механика рассчитывается в комнатах. Для них создан актор Room.
И здесь есть нюансы. Если игра пошаговая. Ну вроде шашек или карт. То для распределения нагрузки по комнатам, делать в общем-то ничего не надо. Все доступные железячные ресурсы будут утилизированы аккой равномерно.
Если игра, как у нас, реалтаймовая, то можно сделать некоторые оптимизации.
Дело в том, что пока у нас нагрузка небольшая. Мало игроков или механика игры легкая, то расчет игровой механики в общем пуле потоков может и не притормаживать. Но как только нагрузка возрастет, то лаги будут заметны.
Далее я опишу что с этим можно сделать.
А пока мы запустили комнату и в нее добавили игрока. Игра реалтаймовая, поэтому нам надо оповещать игроков об изменения состояния игры регулярно. Ну, допустим, каждые 100мс. Хотя, конечно, это время индивидуально для игр.
Мир в реалтаймовой игре, особенно стрелялки с физикой, рассчитывается детерминированно, т.е. по шагам. Во время шага, мы берем игровой мир, применяем к нему команды игрока полученные к этому моменту, рассчитываем физику, коллизии, попадания, какие-то внутриигровые события, NPC и т. д. Соответственно чем быстрее происходит просчет игровой ситуации, тем больше кадров может выдать сервер. И тем более плавно будет идти игра.
Для этого заводим шедуллер, который каждые 100мс будет присылать нам «Тик».
Событие, означающее, что пришло время пересчитать игровую ситуацию.
scheduler = context.system.scheduler.schedule(100.millisecond, 100.millisecond, self, Tick)
Получается, что каждая комната сама себе будет периодически говорить «пора пересчитать игру».
Результаты пересчета отсылаются всем подключенным игрокам в комнате.
В нашем случае учитываются только перемещения игроков.
players.keySet.map(p => getPoint(move, p))
players.values.map(s => s ! Send(Cmd.Move, move.build().toByteArray))
Собственно говоря, мы создали простой игровой сервер, охватывающий базовые вещи. Подключение, аутентификация, работа с БД, комнаты.
Опытный читатель, взглянув на код, скажет:
— Семен Семеныч, да я тоже самое на простых тредах забабахаю без проблем.
Ну в общем, так и есть. Система сообщений пишется на коленке за пару часов. Подключаем Netty и вперед, заре навстречу. Выделяем каждый сервис в поток, и обмениваемся сообщениями через коллекции.
Зачем использовать какую-то сложную Akka?
А что вообще нам может предложить Akka в данном случае?..
Ну про то, что у нас весь код очень простой, однопоточный. И про другие удобства Akka, я уже писал. Не буду повторяться.
Вообще, простые реализации плохи тем, что не отражают многих проблем реальных приложений. Например в этот сервер можно написать вообще в одном потоке. И до поры до времени он будет работать.
Ну вот, например, комнаты, которые могут (и будут в большинстве случаев) нагружать CPU работой. В обычном варианте, если нам понадобится разделить комнаты по потокам, нам придется об этом думать. Думать и писать код для этого разделения.
Что же мы имеем сейчас?
Комната, это простой класс, актор. Он очень простой. Весь код выполняется в общем пуле потоков. На тесте с парой игроков, у себя локально, это будет мало ощущаться.
Но вот нам надо потестить сервер уже например с 50 игроками. Мы решаем выделить каждую комнату в свой поток. Для этого надо просто указать, что этот актор использует отдельный поток, а не общий пул. Это все, мы не думали о синхронизации, не думали о общих данных. Более того, в Akka есть кластер «из коробки». Это значит, что вынести комнаты на отдельные машины в сети не будет большой проблемой. Код самой комнаты не изменится вообще. Это будет тот же самый актор, только работать он будет на отдельной машине.
У каждого актора есть адрес. И вся работа с ним идет через него. Всей системе вообще все равно где работает этот актор. В общем пуле, в отдельном потоке, на отдельной машине или даже на отдельных машинах. Есть адрес, на который мы отсылаем сообщение, а что расположено за ним, поток, машина или кластер мы уже определяем конфигом. Это дает нам с одной стороны удобную и быструю масштабируемость, ну если вдруг игра попрет и надо будет быстро поднимать сервера с игровой механикой. А с другой стороны удобство разработки. Весь кластер может быть поднят как на одной машине разработчика, так и на кластере. Определятся это будет только конфигом.
Т.е. любой актор или группа акторов в системе, может быть запущен как в общем пуле потоков, так и в отдельном потоке, или в отдельных потоках, или на отдельной машине просто изменением конфига. Сохраняя при этом свой простой однопоточный код.
Для игрового сервера это очень большой плюс. Очень большой пласт работы Akka берет на себя. И при этом практически не ограничивает разработчика. Ведь если нет подходящего диспатчера, роутера или мейлбокса, всегда можно написать свою реализацию. Идеально подходящую для конкретного случая.
Если тема интересна, можно будет сделать продолжение с рефакторингом, приблизив код к более реальному продакшену.
Весь код, включая сервер и клиент, выложен на GitHub.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Комментарии (52)

InfiniteCode
01.06.2015 16:31+2Касательно баз данных в АККА. Можно использовать драйверы, которые полностью асинхронные. Тогда не будет проблем с блокировкой потоков. К примеру для MongoDB это ReactiveMongo.
gurinderu
01.06.2015 17:47На моей памяти только mongo и couchbase имеют асинхронные jdbc драйвера. Может еще какие скажите?

grossws
01.06.2015 17:49А для всяких SQL что-нибудь посоветовать можете? Желательно, работающее поверх jdbc.

alno
01.06.2015 18:14+1Есть postgreql-async и mysql-async, например: github.com/mauricio/postgresql-async
Также, если не хочется работать с ними напрямую, есть поддержка в ScalikeJDBC: github.com/scalikejdbc/scalikejdbc-async

doom369
01.06.2015 20:51Сетевой стек в Akka, берет свои корни у Spray и работает более эффективно, чем например Netty
Голословно. Есть статьи, бенчмарки, какие-то пруфы?
solver Автор
01.06.2015 22:16Ну собственно не хотелось бы разводить тут холивар по поводу бенчмарков.
Каждый измеряет свое, и на своих попугаях.
Мне лично хватило того, что я заменил Netty на Akka.IO в сетевой части TCP сервера и получил трехкратный рост количества обработанных пакетов в сек. И это при том, что Netty тюнилась, а Akka работала «из коробки».
Без тюнинга разница больше.
Но тут я не претендую на истину в последней инстанции. Библиотеки ведь развиваются.
Я для себя выводы сделал.doom369
01.06.2015 22:30Особенно забавно выглядит Ваше заявление, учитывая тот факт что в распределнных акторах юзается нетти =).
solver Автор
01.06.2015 22:43Особенно забавно выглядит ваше заявление, учитывая тот факт, что при приеме сообщений от клиента, не используются распределенные акторы. Может подскажете, как их вообще можно там использовать?
doom369
01.06.2015 23:23Ммм, ну я вообще-то тут пишу в контексте «работает более эффективно, чем например Netty». Сам факт использования в акке нетти, как бы намекает. А по поводу конкретно вашего случая — надо смотреть код. Поэтому если уж пишите что-то пододбное то или давайте факты, или не преподностите это как истину.
solver Автор
02.06.2015 00:11Если уж начинаете читать текст, то читайте до конца. Не вырывая фразы из контекста.
В тексте говорится не в общем смысле быстрее, а конкретно про сетевой стек TCP, который используется в примере. И про истину там ни слова нет.
А сам факт использования нетти, говорит лишь о «так исторически сложилось». Изначально использовали его, потому что не было более эффективного решения. Сейчас оно есть и на него плавно переходят. Сначала в IO отказались, потом и в других местах заменят.
P.S. И заканчивайте уже это занудство… никому оно не нужно, словами баловаться.doom369
02.06.2015 00:31И заканчивайте уже это занудство… никому оно не нужно, словами баловаться.
Вы написали статью, опубликовали, у меня к содержанию статьи вопросы. Вы написали, что цитирую «Сетевой стек в Akka, берет свои корни у Spray и работает более эффективно, чем например Netty». Хочу получить об этом информацию. Так как вы автор статьи и об этом пишите, следовательно я полагаю, что у вас есть определенные источники этой информации, помимо одного Вашего субъективного случая. Иначе, повторю, это утверждение голословно.
Чем конкретно сетевой стек акки лучше нетти?
Я не пытаюсь Вас троллить, я реально хочу узнать.solver Автор
02.06.2015 01:49-3Если бы реально хотели знать, сразу именно так и спросили.
Без вырывания фраз из контекста и попыток притянуть за уши факты.
А по существу, в одном каменте не ответишь.
Смотрите например www.youtube.com/watch?v=rTW9_p6Db_4
Если коротко, Akka более технологична. За счет этого быстрее и удобнее в использовании.
Тут надо просто понимать, что любые тесты субъективны. Невозможно в ситуации постоянно драбатываемой среды, библиотек и подходов написать абсолютно истинный тест.
P.S. Но вы можете считать любы тексты, тесты и доклады голословными, вам никто не запрещает)
Проведите тестирование, напишите статью, может оно кому и надо, измерять этих попугаев.
Doggy
06.06.2015 21:57+1Почитать почему акка перешла на спрей
Вы тоже не правы. Вы бы хоть поинтересовались причинами, по которым акка перешла на спрей. И они вовсе не связаны с производительностью. У нетти никогда не было проблем с производительностью. И ваш прирост в тестах объясняется не переходом на акку(спрей), а совсем другими нюансами.
Вы товарищ не очень владеете вопросом, но больно агрессивно отстаиваете свои ничем не подкрепленные мысли.solver Автор
06.06.2015 22:44-1В вашей ссылке написано именно то о чем я писал, Spray технологичнее Netty.
Поэтому и перешли. Я нигде не писал, что единственной причиной перехода был вопрос производительности. Я нигде и никогда не говорил, что у Netty проблемы с производительностью. И прежде чем так по детски гнуть пальцы, разобрались бы о чем я здесь пишу вообще.
>И ваш прирост в тестах объясняется не переходом на акку(спрей), а совсем другими нюансами.
А вот тут у вас с логикой что-то проскальзывает. Замена библиотеки A на B дает прирост производительности, но этот прирост не обусловлен этой заменой. Не ощущаете странности в вашем высказывании? Может объясните, почему замена библиотеки дает прирост, не обусловленный этой библиотекой?
P.S. Прежде чем тыкать в кого-то пальцем, обвинять, неплохо бы самому разобраться в вопросе, что бы не позориться так.

Rigo
02.06.2015 07:44Очень интересно, спасибо.
Что произойдет, если два юзера подключатся с одинаковыми данными авторизации (один логин)?
У акторов Room и GmService должно быть общее состояние — кто в какой комнате находится. Например, чтобы клиент не мог дважды отправить JoinRoom и оказаться в двух комнатах одновременно. В Akka нет гарантии доставки сообщений, поэтому между Room и GmService может возникнуть рассинхронизация. Как это разруливать?meln1k
02.06.2015 09:55В Akka нет гарантии доставки сообщений, поэтому между Room и GmService может возникнуть рассинхронизация. Как это разруливать?
Можно воспользоваться фичей под названием At-Least-Once Delivery и сделать обработку сообщений идемпотентной. Таким образом мы получим гарантированную доставку.gurinderu
02.06.2015 10:11Правильно я понял: у akka нет гарантии, что event не попадет в mailbox? Но в каких ситуациях? и если нет гарантии, то к примеру в банковской среде использование akka может сыграть злую шутку.
meln1k
02.06.2015 10:40+2Корень проблемы гарантированной достаки в том, что непонятно какие гарантии она должна давать, так как у нас есть несколько вариантов.
- Сообщение отправлено в сеть?
- Сообщение принято другим хостом?
- Сообщение получено мейлбоксом?
- Сообщение начато обрабатываться актором?
- Сообщение успешно обработано актором?
Единственный способ узнать, было ли сообщение обработано или нет — это ввести подтверждение доставки на уровне бизнес-логики. По этой причине разработчики Akka намеренно не стали включать такую дырявую абстракцию, как гарантированная доставка.solver Автор
02.06.2015 11:00Вот на этом моменте, многие путают гарантию доставки с потерей сообщения вообще.
Внутри JVM сообщение не может быть потеряно.
Другое дело, что ссылка актора, которому отправляется сообщение может не существовать на момент отправки. Или у него мейлбокс переполнится. Или еще много моментов из-за которых сообщение не будет обработано. И сообщение попадет в deadLetters.gurinderu
02.06.2015 11:12А если произойдет crash JVM? и оно не успеет попасть в mailbox? Оно останется в mailbox родительского актора?
solver Автор
02.06.2015 11:15Ну сами подумайте. Кто может может что либо гарантировать при crash JVM?
gurinderu
02.06.2015 12:54Ну вообще вполне конктретный вопрос и обычно можно описать логику и для такого варианта.
solver Автор
02.06.2015 13:15Описать логику для креша всего JVM? Как именно это можно сделать?
gurinderu
02.06.2015 14:08Нет. Описать логику, которая позволит в случае крэша проиграть event заного.

Optik
02.06.2015 15:09В момент смерти жвм вы ничего сделать уже не можете. Событие пропадет. Создавайте транзакции для больших гарантий.
gurinderu
02.06.2015 15:20Транзакцию на весь процесс? Да вы видно шутите.
Optik
02.06.2015 18:19+1Что-то у меня ощущение, что говорим на разных языках или вы просто хотите гарантий за даром.
gurinderu
02.06.2015 20:44Никто и не говорит «за даром» мне нужна гарантия, что event посланный одним актором никогда никуда не пропадет)
Optik
02.06.2015 21:33Только один вариант — отвечать Ack-сообщением. Один из базовых принципов в архитектуре Akka — это location transparency, что значит актор может физически находиться где угодно. Можно не заморачиваться если jvm одна (и то с нюансами, актор может быть мертв, а почта в спец-ящике), но для другого инстанса (особенно где-то на другом хосте или вообще в другом дц) нельзя получить гарантию в принципе. Магия пока не доступна. Если вы соседу через забор камень кините, то пока он вас не обматерит, вы не узнаете результат (соседа нет, камень улетел куда-то дальше, соседа вырубило камнем). Смотрите как на аналог UDP в сетевом стеке. Соорудить из UDP TCP можно, обратно нет.
gurinderu
03.06.2015 10:22Мне важна была одна фраза.
A durable mailbox is a mailbox which stores the messages on durable storage. What this means in practice is that if there are pending messages in the actor's mailbox when the node of the actor resides on crashes, then when you restart the node, the actor will be able to continue processing as if nothing had happened; with all pending messages still in its mailbox.
И все)
Вопрос только остается одно, это lifecycle of message in mailboxOptik
03.06.2015 12:51Это специфичная вещь, упоминания о которой в последних доках не вижу вдобавок. Реализовать свой ящик один из вариантов (если хочется аналог редо логов в реляционках).
gurinderu
03.06.2015 14:08Вот тут doc.akka.io/docs/akka/2.1.0/modules/durable-mailbox.html
solver Автор
03.06.2015 14:40Это устаревшая версия.
durable-mailbox при падении приложения теряет то сообщение, которое обратывается в тот момент.
Его заменили на persistence у которого такой проблемы нет.gurinderu
03.06.2015 15:11Возникает тогда вопрос логичный: «Почему он durable и какой с него вообще толк, если он его теряет?» Плюс он хуже же, чем обычный по производительности из-за этого
grossws
03.06.2015 15:24Durable mailbox — это про другое. Оно лишь гарантирует, что сообщение, успешно записанное в mailbox, переживёт перезапуск приложения.
Но сообщение может потеряться не дойдя до mailbox'а, может возникнуть проблема сохранения на надёжное хранилище (и сообщение не попадёт в mailbox).
Это даже не говоря о том, что актор может упасть при обработке этого сообщения и оно будет выкинуто согласно логике работы mailbox'а.gurinderu
03.06.2015 16:43Правильно ли я понимаю, что сообщение убивается из mailbox как только актор начал его обработку, а не как закончил?
solver Автор
03.06.2015 17:14durable-mailbox из старой версии, по умолчанию именно так и работает.
Но тут надо понимать, что это дефолтные установки и все в твоих руках.
Можно заменить обработку, как выше описал meln1k.
Можно вообще сделать свою версию мейлбокса с шахматами и поэтессами.grossws
03.06.2015 18:26Дополню, что такое поведение по умолчанию (удаление сообщения из mailbox'а при обработке) является защитой от ситуации, когда именно это сообщение является причиной смерти актора.
В случае, когда нужно иметь возможность попробовать обработать сообщение повторно при падении актора есть два варианта:
— добавить перед ним супервизор, который попробует послать сообщение повторно (но необходимо самостоятельно сделать защиту от livelock'а, если это сообщение приводит к падению актора),
— использовать peek mailbox (который требует явного подтверждения удачной обработки сообщения (см. doc.akka.io/docs/akka/2.3.11/contrib/peek-mailbox.html, на реализацию можно посмотреть здесь: github.com/akka/akka/blob/v2.3.11/akka-contrib/src/main/scala/akka/contrib/mailbox/PeekMailbox.scala)gurinderu
03.06.2015 19:58Можно же сделать state у message и менять его по прохождению. Если из-за него актор упал, то тогда помечать его как error и удалять, если нет то слать другому актору и как только тот получит сообщение в mailbox удалять его из первого
grossws
03.06.2015 20:12Сообщение должно быть immutable. У него не может быть никакого стейта. Оно могло уйти по цепочке акторов, в другую jvm и т. п.
Кроме того, вы в общем случае не можете определить упал актор от того, что сообщение кривое или от того, что какой-то внешний ресурс не доступен. Если нужны повторные попытки — оно описывается в бизнес-логике (как AtLeastOnceDelivery, как PeekMailbox или ещё как-то).
solver Автор
02.06.2015 10:47Не надо делать для разных акторов общее состояние, это зло.
Состояние описывающее кто в какой комнате находится, должно быть только у GM.
Комнате должно быть все равно, она не решает ничего по поводу подключения игроков.
По поводу гарантий доставки. Тут есть нюансы. Ниже есть интересная статья на эту тему.
Но если пояснять именно про Akka…
Фраза «В Akka нет гарантии доставки сообщений» работает только в общем случае. Т.к. подразумевается, что Akka это распределенная система работающая на неизвестном количестве узлов. А раз в системе присутствует сеть, то понятно, что это слабое звено, которое может сбоить и в этом случае такую ситуацию надо обрабатывать отдельно. Поэтому и говорят, что при использовании Ask Pattern нет гарантий доставки.
В случае, если вы можете разместить акторы в пределах одной JVM, то гарантируется, что сообщение не будет потеряно.
Что, в общем-то, вполне логично.
Если все же акторы разойдутся по разным машинам, то meln1k ниже верно описал подход с At-Least-Once Delivery.
dborovikov
А почему сервисы сделаны в виде акторов, а не просто сервисов? В чем в данном случае профит от их использования? Про разделение комнат аргумент не ясный, так как они бы и так были бы изначально в разных потоках.
solver Автор
А что такое «просто сервис»?
Мы же используем Akka. У нас «все актор».
Ну профит не в том, что можно в поток выделить. А в том, что этот момент очень гибко конфигурируется.
Можно поток, можно пул потоков, можно вообще отдельную машину по сети. Все через конфиг. Без изменения самого актора.
dborovikov
Просто сервис в смысле просто обычный класс с методами. И методы можно вызывать в отдельных потоках, через ExecutorService. Который тоже можно конфигурить во вне.
solver Автор
Ну собственно сейчас так и есть. Каждый сервис это просто класс с методами.
В простых случаях профит не всегда очевиден. Я об этом писал.
Надо просто написать приложение на Akka, что бы понять всю прелесть этого подхода.
Ибо «можно конфигурить во вне» всего лишь один маленький момент из всей Akka.
Как вы будете, например, пул потоков размещать прозрачно на соседней машине в сети?
dborovikov
С распределением акторов по сети понятно, тут уже есть смысл.