

Возможно ли с помощью Python обработать миллион запросов в секунду? До недавнего времени это было немыслимо.
Многие компании мигрируют с Python на другие языки программирования для повышения производительности и, соответственно, экономии на стоимости вычислительных ресурсов. На самом деле в этом нет необходимости. Поставленных целей можно добиться и с помощью Python.
Python-сообщество в последнее время уделяет много внимания производительности. С помощью CPython 3.6 за счет новой реализации словарей удалось повысить скорость работы интерпретатора. А благодаря новому соглашению о вызове (calling convention) и словарному кэшу CPython 3.7 должен стать еще быстрее.
Для определенного класса задач хорошо подходит PyPy с его JIT-компиляцией. Также можно использовать NumPy, в котором улучшена поддержка расширений на Си. Ожидается, что в этом году PyPy достигнет совместимости с Python 3.5.
Эти замечательные решения вдохновили меня на создание нового в той области, где Python используется очень активно: в разработке веб- и микросервисов.
Встречайте Japronto!
Japronto — это новый микрофреймворк, заточенный под нужды микросервисов. Он создан, чтобы быть быстрым, масштабируемым и легким. Благодаря asyncio реализованы синхронный и асинхронный режимы. Japronto удивительно быстр — даже быстрее NodeJS и Go.
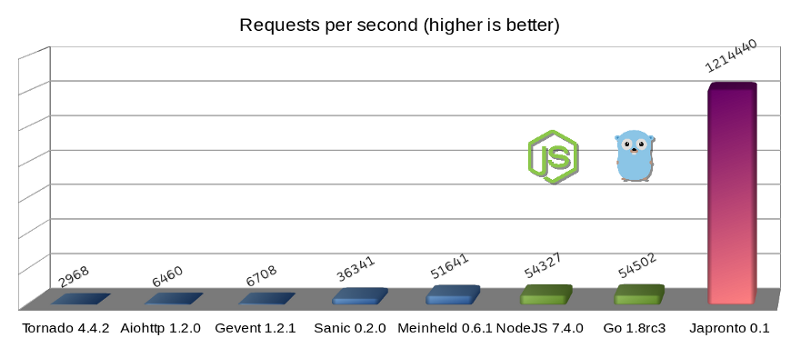
Микрофреймворки Python (синим), Темная сторона силы (зеленым) и Japronto (фиолетовым)
Обновление: Пользователь @heppu подсказал, что хорошо оптимизированный, написанный на Go с использованием stdlib HTTP-сервер может быть на 12% быстрее. Также существует замечательный сервер fasthttp (также Go), который в этом конкретном бенчмарке лишь на 18% медленнее Japronto. Чудесно! Детали можно найти здесь: https://github.com/squeaky-pl/japronto/pull/12 и https://github.com/squeaky-pl/japronto/pull/14.
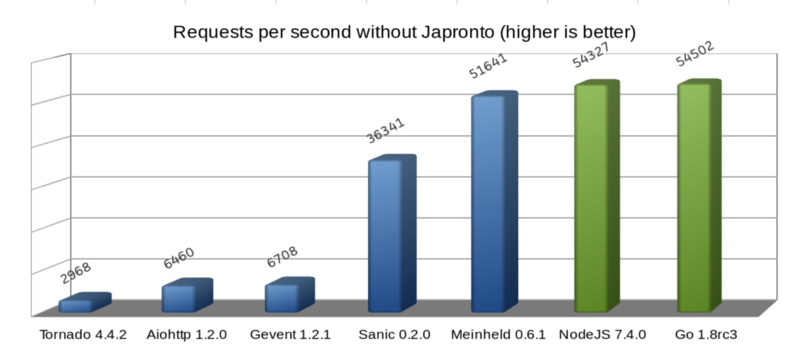
На диаграмме видно, что WSGI-сервер Meinheld идет практически ноздря в ноздрю с NodeJS и Go. Несмотря на то что этот сервер по своей природе является блокирующим, по сравнению с предыдущими четырьмя асинхронными решениями на Python работает он просто замечательно. Поэтому не верьте говорящим, что асинхронные системы всегда быстрее. В большинстве случаев они гораздо лучше параллелятся, но производительность зависит и от многих других параметров.
Для тестирования я использовал простое приложение «Hello world!». Несмотря на незамысловатость, такое решение позволяет легко определить вклад программы/фреймворка в потери производительности.
Результаты были получены на запущенном в регионе Sao Paulo невыделенном инстансе AWS c4.2xlarge с 8 VCPU, HVM-виртуализацией и хранилищем типа magnetic. На машине была установлена Ubuntu 16.04.1 LTS (Xenial Xerus) с ядром Linux 4.4.0–53-generic x86_64. Процессор определялся операционной системой как Xeon CPU E5–2666 v3 @ 2.90GHz CPU. Использовался свежескомпилированный из исходников Python 3.6.
Каждый из тестируемых серверов (включая варианты на Go) использовал только один рабочий процесс. Нагрузочное тестирование проводилось с помощью wrk с одним потоком, сотней соединений и двадцатью четырьмя одновременными (конвейеризованными (pipelined)) запросами на соединение (итого 2400 параллельных запросов).
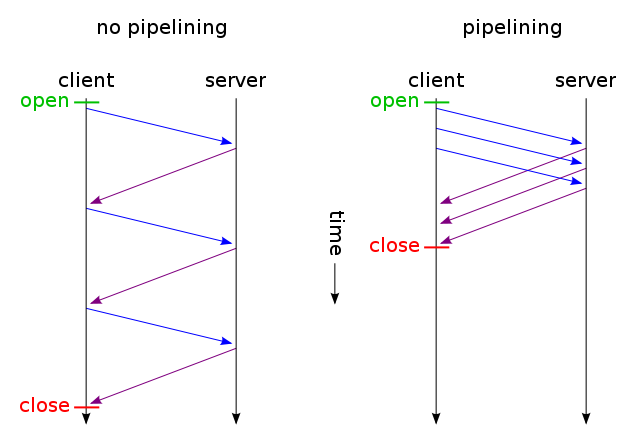
Конвейерная обработка HTTP (изображение взято из Wikipedia)
Конвейерная обработка HTTP (HTTP pipelining) в данном случае является важнейшим элементом системы, поскольку это одна из оптимизаций, которую использует Japronto при обслуживании запросов.
Большинство серверов не используют преимущества HTTP pipelining и обрабатывают запросы от pipelining-клиентов в обычном порядке (Sanic и Meinheld пошли еще дальше: они молча отбрасывают такие запросы, что является нарушением спецификации HTTP 1.1).
При использовании HTTP pipelining клиент в рамках одного TCP-соединения отправляет следующий запрос, не дождавшись ответа на предыдущий. Для корректного сопоставления запросов и ответов сервер отправляет ответы в том же порядке, в каком принял запросы.
Бескомпромиссная борьба за оптимизацию
Когда клиент отправляет много небольших GET-запросов в виде pipeline-цепочки, высока вероятность, что они прибудут на сервер в одном TCP-пакете (благодаря алгоритму Нейгла) и там будут прочитаны (read) единичным системным вызовом.
Выполнение системного вызова и перемещение данных из пространства ядра в пространство пользователя — весьма дорогостоящая операция (скажем, по сравнению с перемещением памяти в рамках одного процесса). Поэтому важно выполнять только необходимый минимум системных вызовов (но не меньше).
После получения и успешного разбора данных Japronto старается максимально быстро выполнить все запросы, выстроить ответы в правильном порядке и записать (write) их все одним системным вызовом. Для «склеивания» запросов можно применить системные вызовы scatter/gather IO, но в Japronto это пока не реализовано.
Следует помнить, что такая схема работает далеко не всегда. Некоторые запросы могут выполняться слишком долго, и их ожидание приведет к безосновательному увеличению сетевой задержки.
Будьте осторожны при настройке эвристик, а также не забывайте о стоимости системных вызовов и ожидаемом времени завершения обработки запросов.
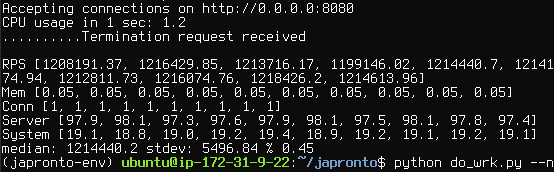
Japronto выдает 1,214,440 RPS на сгруппированных непрерывных данных (медиана, рассчитанная как 50-й перцентиль, с использованием интерполяции).
Помимо задержки записи для pipelining-клиентов, используется несколько других техник.
Japronto практически полностью написан на Си. Парсер, протокол, connection reaper, маршрутизатор, request- и response-объекты реализованы в виде расширений на Си.
Japronto до последнего старается задержать создание аналогов своих внутренних структур на Python. Например, словарь заголовков не создается до тех пор, пока он не будет запрошен в представлении. Все границы токенов уже отмечены заранее, но нормализация ключей заголовков и создание нескольких объектов типа str выполняется только в момент первого обращения к ним.
При разборе статуса (status line), заголовков и разбитого на части (chunks) тела HTTP-сообщения (HTTP message body) Japronto полагается на замечательную Си-библиотеку picohttpparser. Чтобы быстро находить границы HTTP-токенов, picohttpparser напрямую использует встроенные в современные процессоры SSE4.2-инструкции по обработке текста (они уже 10 лет представлены практически во всех x86_64-совместимых процессорах). I/O возложен на uvloop, который является оберткой вокруг libuv. На самом низком уровне используется системный вызов epoll, который обеспечивает асинхронные уведомления о готовности чтения-записи.

Picohttpparser парсит с помощью SSE4.2 и CMPESTRI x86_64
При проектировании высокопроизводительных систем на Python нужно уделять особое внимание тому, чтобы без необходимости не увеличивать нагрузку на сборщик мусора. Japronto старается избежать создания ссылочных циклов (reference cycle) и выполнять как можно меньше операций allocation/deallocation. Это достигается с помощью заблаговременного размещения некоторых объектов в так называемых аренах (arenas). Japronto также пытается использовать объекты Python повторно, вместо того чтобы избавляться от них и создавать новые.
Память выделяется кратно 4 Кб. Внутренние структуры организованы таким образом, чтобы данные, которые часто используются совместно, располагались в памяти недалеко друг от друга. Этим минимизируются промахи кэша.
Также Japronto старается избегать безосновательного копирования между буферами, выполняя многие операции «на месте». Например, URL-декодирование пути происходит еще до сопоставления в процессе-маршрутизаторе.
Open source-разработчики, мне нужна ваша помощь
Я работал над Japronto на протяжении последних трех месяцев. Часто в выходные, а также в рабочие дни. Это стало возможным только потому, что я решил сделать перерыв в работе в качестве наемного программиста и направил все усилия на Japronto.
Думаю, что настало время разделить плоды моего труда с сообществом.
В настоящее время в Japronto реализованы следующие возможности:
- HTTP 1.x с поддержкой сhunked transfer;
- полная поддержка HTTP pipelining;
- Keep-alive-соединения с настраиваемым сборщиком неактивных соединений (connection reaper);
- поддержка синхронного и асинхронного режимов;
- модель с мастером и несколькими рабочими процессами (Master-multiworker model), основанная на ветвлении (forking);
- перезагрузка кода при изменениях;
- простая маршрутизация.
Дальше я бы хотел заняться веб-сокетами и потоковыми HTTP-ответами (streaming HTTP responses) в асинхронном режиме.
Предстоит еще много работы, связанной с документированием и тестированием. Если вы хотите помочь, свяжитесь со мной напрямую в Twitter. Здесь находится репозиторий Japronto на GitHub.
Также, если ваша компания ищет Python-разработчика, помешанного на производительности и разбирающегося в DevOps, я готов это обсудить. Рассматриваю предложения из любых уголков мира.
В заключение
Вышеперечисленные техники не обязательно должны быть Python-специфичными. Может быть, их можно применить в таких языках, как Ruby, JavaScript или даже PHP. Мне было бы интересно этим заняться, но, к сожалению, это невозможно без финансирования.
Я бы хотел поблагодарить Python-сообщество за постоянную работу над улучшением производительности. А именно: Victor Stinner @VictorStinner, INADA Naoki @methane и Yury Selivanov 1st1, а также всю команду PyPy.
Во имя любви к Питону.
Комментарии (29)

ggo
28.03.2017 10:06+12Сможет ли Питон прожевать миллион запросов в секунду?
и
Japronto практически полностью написан на Си. Парсер, протокол, connection reaper, маршрутизатор, request- и response-объекты реализованы в виде расширений на Си.
как-то не коррелируют между собой.
vasiliysenin
28.03.2017 17:35Это же перевод статьи «A million requests per second with Python»

slonopotamus
29.03.2017 09:06+4«Это же перевод» — это такая универсальная отмазка которая оправдывает размещение на сайте любой фигни?

sheknitrtch
28.03.2017 10:27Здорово, что разработчики смогли заставить работать «Hello world» сервер с такой производительностью. Только Я бы сравнил реализации какого-нибудь реального REST-сервиса, реализованного на разных языках программирования.
Вспоминается история проекта Pyston. Разработчики из Dropbox делали свою реализацию Python с JIT-компиляцией. На синтетических тестах Pyston на 95% быстрее чем стандартный CPython. Но на реальном web-сервере прирост составляет всего на 10%. Из-за этого Dropbox больше не финансирует этот проект (к моему величайшему сожалению).
brooth
28.03.2017 11:06+5какого-нибудь реального REST-сервиса
На реальном REST-сервисе можно проверит скорость работы БД, никак не языка.

vedenin1980
28.03.2017 16:45На реальном REST-сервисе можно проверит скорость работы БД, никак не языка.
Не обязательно, кэширование зачастую позволяет на большинство популярных запросов просто отдавать данные из памяти без всяких обращений к БД. Иногда вообще приложение почти не обращается к диску почти все беря из памяти.

raacer
04.04.2017 14:02+2Зачем тогда нужны все эти оптимизации, если запросы к БД будут выполняться в тыщу раз дольше? Тут и проверять нечего, для классического веб-приложения такой движок бесполезен. Может быть для какого-то микросервиса на основе redis или memcached еще имеет смысл…

youlose
28.03.2017 11:49+3Затея-то интересная, но добавьте к тесту конкатенацию строки из питона (не просто вывести hello world, а прибавить что-то) и количество обрабатываемых запросов сразу упадёт процентов на 15. Что говорит о том что передача ответа, скорее всего вряд ли может являться «бутылочным горлышком», сайты и сервисы же делают не для того чтобы статичные строки передавать, а выполнять какую-то логику.
vedenin1980
28.03.2017 16:43сайты и сервисы же делают не для того чтобы статичные строки передавать, а выполнять какую-то логику.
Зачастую запросы к сайтам и сервисам можно закэшировать в виде простой строкой в хэш-таблице, лежащей в памяти и в 99% случаях отдавать уже её. Например, главная страница во многих ресурсах для всех пользователей одна и та же и статична достаточно долго, кто мешает хранить её в памяти?
mayorovp
28.03.2017 18:14Обычно эту задачу выполняет CDN или обратный прокси. Зачем делать то же самое уже на языке Python?
vedenin1980
28.03.2017 20:37+1Потому что CDN или обратный прокси не могут управлять кэшем интеллектуально, например мы хотим чтобы если не было новых постов в форуме отдать статическую версию из памяти, а если были то обновить кэш из базы. Вообще уровней кешей в среднем веб приложении может быть очень много — кеш прокси, кеш баз данных, кеш HTML страниц и т.п.
mayorovp
28.03.2017 21:35Ну, в nginx есть модуль для инвалидации кэша по запросу.
vedenin1980
29.03.2017 00:10+2Ну, в nginx есть модуль для инвалидации кэша по запросу.
Он сможет убрать из кэша всех сотрудников одного отдела, если отделу администратор поменял название в веб админке, при этом не трогая кэши всех остальных сотрудников? Ну или предположим что мы строим сложную HTML страницу, собирая данные из десятков таблиц (да ещё и разных хранилищь/баз данных), и знаем что нам нужно обновить только одну сущность из базы, а остальные можно взять из кэша. Можно ли это сделать на уровне прокси?
Я не спорю, что-то можно сделать на уровне проксей и т.п., но далеко не все что можно сделать с помощью кэшей на беке.


recompileme
28.03.2017 11:59+1Я верно что понял HTTP Pipelining отключен, например в хроме, фаерфоксе и ее не рекомендуют использовать?
https://www.chromium.org/developers/design-documents/network-stack/http-pipelining
http://kb.mozillazine.org/Network.http.pipelining
В связи с этим — интересно было бы увидеть более приближенные к реальности результаты тестов, без Pipelining.
san9s
28.03.2017 12:09+1Ну тут как бы это, надо проводить какие-то честные сравнения чтоль. А то питон бафнули, библиотеку на сях написали (почти целиком), а потом скоростью меряемся.
Код примераpackage main import . "fmt" import "github.com/valyala/fasthttp" func HandleFastHTTP(ctx *fasthttp.RequestCtx) { Fprintf(ctx, "Hello, world! Requested path is %q.", ctx.Path()) } func main() { fasthttp.ListenAndServe(":8000", HandleFastHTTP) }
servancho
29.03.2017 02:35Ссылка на оригинал статьи:
https://medium.freecodecamp.com/million-requests-per-second-with-python-95c137af319YourChief
29.03.2017 03:42+2В переводных статьях эта ссылка даётся самим автором и видна под рейтингом поста, справа от зелёных стрелочек.

berezuev
03.04.2017 16:30-1Вообще, можно устроить мощный такой холивар, описав ТЗ некоего относительно простого веб-приложения, и предлагая разработчикам разных «религий» написать его на своем языке программирования. Ну и, к нему несколько объективных тестов, соответственно.
mayorovp
04.04.2017 09:24Какой же это будет холивар, если есть объективные критерии сравнения? :-)
fireSparrow
04.04.2017 10:04Будет холивар о том, насколько корректно измерять производительность именно этими тестами.

Tiberiumk
04.04.2017 16:45Было бы круто, только если бы HTTP Pipelining поддерживался современными браузерами…
Взято с Википедии:
Браузеры Mozilla ( Mozilla Firefox, SeaMonkey and Camino) поддерживают pipelining, но эта функция выключена по умолчанию.
Google Chrome убрал поддержку pipelining из-за багов и проблем с «плохими» серверами.
Internet Explorer 11 не поддерживает pipelining
Так что как мне кажется, это будет полезно только для очень нагруженных микросервисов (где разработчики сами могут включить pipelining)
bak
Всё это очень круто, только event-loop написан на C (libuv) и парсер http тоже сишный (picohttpparser). Хотя наверное просто дернуть callback в питоне миллион раз в секунду — уже круто (я сам фанат питона, просто не люблю желтые заголовки).
tumbler
Ну строго говоря CPython тоже на си написан, так можно много до чего договориться. Тут наверно можно поставить вопрос так: а можно ли бизнес-логику на python обернуть производительным асинхронным http-движком с наименьшей долей накладных расходов? Понятно что для hello world доля накладных расходов в 99% это нормально, но для чего-то более сложного хотелось бы иметь пространство для оптимизации своего кода, а не чужого.