

В этом материале я продолжаю делиться полевым опытом работы с системой сбора логов на базе Heka и ElasticSearch.
На этот раз рассказ пойдет про миграцию данных между двумя кластерами ElasticSearch 2.2 и 5.2.2, которая стоила немалых нервов лично мне. Как-никак, предстояло перевезти 24 миллиарда записей, не сломав уже работающую систему.
Прошлая статья закончилась на том, что система работает, логи поступают и складываются в кластер ElasticSearch, доступен их просмотр в реальном времени через Kibana. Но кластер изначально был собран со значительным запасом по памяти как раз на вырост.
Если обратиться к официальной документации ElasticSearch (далее просто ES), то в первую очередь вы увидите строгое предупреждение «Don't cross 32 gb». Превышение грозит проседанием производительности вплоть до моментов полной остановки, пока garbage collector выполняет пересборку в духе «stop the world». Рекомендация производителя по памяти на сервере: 32 ГБ под heap (xms/xmx) и еще 32 ГБ свободного места под кэш. Итого 64 ГБ физической памяти на одну дата-ноду.
Но что делать, если памяти больше? Официальный ответ все в той же документации – ставить несколько экземпляров ES на один хост. Но мне такой подход показался не совсем правильным, так как штатных средств для этого не предусмотрено. Дублировать init-скрипты – это прошлый век, поэтому более интересной выглядела виртуализация кластера с размещением нод в LXD-контейнерах.
LXD (Linux Container Daemon) – так называемый «контейнерный легковизор». В отличии от «тяжелых» гипервизоров не содержит эмуляции аппаратуры, что позволяет сократить накладные расходы на виртуализацию. К тому же имеет продвинутый REST API, гибкую настройку используемых ресурсов, возможности переноса контейнеров между хостами и другие возможности, более характерные для классических систем виртуализации.

Вот такая вырисовывалась структура будущего кластера.
К началу работ под рукой было следующее железо:
Четыре работающих дата-ноды ES в составе старого кластера: Intel Xeon 2x E5-2640 v3; 512 ГБ ОЗУ, 3x16 ТБ RAID-10.
- Два новых пустых сервера аналогичной предыдущему пункту конфигурации.
По задумке, на каждом физическом сервере будет две дата-ноды ES, мастер-нода и клиентская нода. Кроме того, на сервере разместится контейнер-приёмник логов с установленными HAProxy и пулом Heka для обслуживания дата-нод этого физического сервера.
Подготовка нового кластера
В первую очередь нужно освободить одну из дата-нод – этот сервер сразу уходит в новый кластер. Нагрузка на оставшиеся три возрастет на 30%, но они справятся, что подтверждает статистика загрузки за последний месяц. Тем более это ненадолго. Далее привожу свою последовательность действий для штатного вывода дата-ноды из кластера.
Снимем с четвертой дата-ноды нагрузку, запретив размещение на ней новых индексов:
{
"transient": {
"cluster.routing.allocation.exclude._host": "log-data4"
}
}Теперь выключаем автоматическую ребалансировку кластера на время миграции, чтобы не создавать лишней нагрузки на оставшиеся дата-ноды:
{
"transient": {
"cluster.routing.rebalance.enable": "none"
}
}Собираем список индексов с освобождаемой дата-ноды, делим его на три равные части и запускаем перемещение шардов на оставшиеся дата-ноды следующим образом (по каждому индексу и шарду):
PUT _cluster/reroute
{
"commands" : [ {
"move" :
{
"index" : "service-log-2017.04.25", "shard" : 0,
"from_node" : "log-data4", "to_node" : "log-data1"
}
}
}Когда перенос завершится, выключаем освободившуюся ноду и не забываем вернуть ребалансировку обратно:
{
"transient": {
"cluster.routing.rebalance.enable": "all"
}
}Если позволяют сеть и нагрузка на кластер, то для ускорения процесса можно увеличить очередь одновременно перемещаемых шардов (по умолчанию это количество равно двум)
{
"transient": {
"cluster": {
"routing": {
"allocation": {
"cluster_concurrent_rebalance": "10"
}
}
}
}
}Пока старый кластер постепенно приходит в себя, собираем на трёх имеющихся серверах новый на базе ElasticSearch 5.2.2, с отдельными LXD-контейнерами под каждую ноду. Дело это простое и хорошо описанное в документации, поэтому опущу подробности. Если что – спрашивайте в комментариях, расскажу детально.
В ходе настройки нового кластера я распределил память следующим образом:
Мастер-ноды: 4 ГБ
Клиентские ноды: 8 ГБ
Дата-ноды: 32 ГБ
- XMS везде устанавливаем равным XMX.
Такое распределение родилось после осмысления документации, просмотра статистики работы старого кластера и применения здравого смысла.
Синхронизируем кластеры
Итак, у нас есть два кластера:
Старый – три дата-ноды, каждая на железном сервере.
- Новый, с шестью дата-нодами в LXD контейнерах, по две на сервер.
Первое, что делаем, – включаем зеркалирование трафика в оба кластера. На приемных пулах Heka (за подробным описанием отсылаю к предыдущей статье цикла) добавляем ещё одну секцию Output для каждого обрабатываемого сервиса:
[Service1Output_Mirror]
type = "ElasticSearchOutput"
message_matcher = "Logger == 'money-service1''"
server = "http://newcluster.receiver:9200"
encoder = "Service1Encoder"
use_buffering = trueПосле этого трафик пойдет параллельно в оба кластера. Учитывая, что мы храним индексы с оперативными логами компонент не более 21 дня, на этом можно было бы и остановиться. Через 21 день в кластерах будут одинаковые данные, а старый можно отключить и разобрать. Но долго и скучно столько ждать. Поэтому переходим к последнему и самому интересному этапу – миграции данных между кластерами.
Перенос индексов между кластерами
Так как официальной процедуры миграции данных между кластерами ES на момент выполнения проекта не существует, а изобретать «костыли» не хочется – используем Logstash. В отличии от Heka он умеет не только писать данные в ES, но и читать их оттуда.
Судя по комментариям к прошлой статье, у многих сформировалось мнение, что я почему-то не люблю Logstash. Но ведь каждый инструмент предназначен для своих задач, и для миграции между кластерами именно Logstash подошёл как нельзя лучше.
На время миграции полезно увеличить размер буфера памяти под индексы с 10% по умолчанию до 40%, которые выбраны по среднему количеству свободной памяти на работающих дата-нодах ES. Также нужно выключить обновление индексов на каждой дата-ноде, для чего добавляем в конфигурацию дата-нод следующие параметры:
memory.index_buffer_size: 40%
index.refresh_interval: -1По-умолчанию индекс обновляется каждую секунду и создает тем самым лишнюю нагрузку. Поэтому, пока в новый кластер никто из пользователей не смотрит, обновление можно отключить. Заодно я создал шаблон по умолчанию для нового кластера, который будет использоваться при формировании новых индексов:
{
"default": {
"order": 0,
"template": "*",
"settings": {
"index": {
"number_of_shards": "6",
"number_of_replicas": "0"
}
}
}
}С помощью шаблона выключаем на время миграции репликацию, тем самым снизив нагрузку на дисковую систему.
Для Logstash получилась следующая конфигурация:
input {
elasticsearch {
hosts => [ "localhost:9200" ]
index => "index_name"
size => 5000
docinfo => true
query => '{ "query": { "match_all": {} }, "sort": [ "@timestamp" ] }'}
}
output {
elasticsearch { hosts => [ "log-new-data1:9200" ]
index => "%{[@metadata][_index]}"
document_type => "%{[@metadata][_type]}"
document_id => "%{[@metadata][_id]}"}}
}В секции input описываем источник получения данных, указываем системе, что данные нужно забирать пачками (bulk) по 5000 записей, и выбираем все записи, отсортированные по timestamp.
В output нужно указать назначение для пересылки полученных данных. Обратите внимание на описания следующих полей, которые можно получить из старых индексов:
document_type – тип (mapping) документа, который лучше указать при переезде, чтобы имена создаваемых mappings в новом кластере совпадали с именами в старом – они используются в сохранённых запросах и дашбордах.
- document_id – внутренний идентификатор записи в индексе, который представляет собой уникальный 20-символьный хэш. С его явной передачей решаются две задачи: во-первых, облегчаем нагрузку на новый кластер не требуя генерировать id для каждой из миллиардов записей, и во-вторых, в случае прерывания процесса нет необходимости удалять недокачанный индекс, можно просто запустить процесс заново, и ES проигнорирует записи с совпадающим id.
Параметры запуска Logstash:
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/migrate.conf --pipeline.workers 8Ключевыми параметрами, влияющими на скорость миграции, являются размер пачек, которые Logstash будет отправлять в ES, и количество одновременно запускаемых процессов (pipeline.workers) для обработки. Строгих правил, которые определяли бы выбор этих значений, нет – они выбирались экспериментальным путем по следующей методике:
Выбираем небольшой индекс: для тестов использовался индекс с 1 млн многострочных (это важно) записей.
Запускаем миграцию этого индекса с помощью Logstash.
Смотрим на thread_pool на приёмной дата-ноде, обращая внимание на количество «rejected» записей. Рост этого значения однозначно говорит о том, что ES не успевает проиндексировать поступающие данные – тогда количество параллельных процессов Logstash стоит уменьшить.
- Если резкого роста «rejected» записей не происходит – увеличиваем количество bulk/workers и повторяем процесс.
После того как всё было подготовлено, составлены списки индексов на переезд, написаны конфигурации, а также разосланы предупреждения о предстоящих нагрузках в отделы сетевой инфраструктуры и мониторинга, я запустил процесс.
Чтобы не сидеть и не перезапускать процесс logstash, после завершения миграции очередного индекса я сделал с новым файлом конфигурации следующее:
Список индексов на переезд разделил на три примерно равные части.
В /etc/logstash/conf.d/migrate.conf оставил только статическую часть конфигурации:
input { elasticsearch { hosts => [ "localhost:9200" ] size => 5000 docinfo => true query => '{ "query": { "match_all": {} }, "sort": [ "@timestamp" ] }'} } output { elasticsearch { hosts => [ "log-new-data1:9200" ] index => "%{[@metadata][_index]}" document_type => "%{[@metadata][_type]}" document_id => "%{[@metadata][_id]}"}} }
Собрал скрипт, который читает имена индексов из файла и вызывает процесс logstash, динамически подставляя имя индекса и адрес ноды для миграции.
- Всего нужно запустить три экземпляра скрипта, по одному на каждый файл: indices.to.move.0.txt, indices.to.move.1.txt и indices.to.move.2.txt. После этого данные уходят в первую, третью и пятую дата-ноды.
Код одного из экземпляров скрипта:
cat /tmp/indices_to_move.0.txt | while read line
do
echo $line > /tmp/0.txt && /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/migrate.conf --pipeline.workers 8 --config.string "input {elasticsearch { index => \"$line\" }} output { elasticsearch { hosts => [ \"log-new-data1:9200\" ] }}"
done;Для просмотра статуса миграции пришлось «на коленке» собрать ещё один скрипт, и запустить в отдельном процессе screen (через watch -d -n 60):
#!/bin/bash
regex=$(cat /tmp/?.txt)
regex="(($regex))"
regex=$(echo $regex | sed 's/ /)|(/g')
curl -s localhost:9200/_cat/indices?h=index,docs.count,docs.deleted,store.size | grep -P $regex |sort > /tmp/indices.local
curl -s log-new-data1:9200/_cat/indices?h=index,docs.count,docs.deleted,store.size | grep -P$regex | sort > /tmp/indices.remote
echo -e "index\t\t\tcount.source\tcount.dest\tremaining\tdeleted\tsource.gb\tdest.gb"
diff --side-by-side --suppress-common-lines /tmp/indices.local /tmp/indices.remote | awk '{print $1"\t"$2"\t"$7"\t"$2-$7"\t"$8"\t"$4"\t\t"$9}'Процесс миграции занял около недели. И честно скажу – спалось мне эту неделю неспокойно.
После переезда
После переноса индексов осталось сделать совсем немного. В одну прекрасную субботнюю ночь старый кластер был выключен и изменены записи в DNS. Поэтому все пришедшие на работу в понедельник увидели новый розово-голубой интерфейс пятой Kibana. Пока сотрудники привыкали к обновленной цветовой гамме и изучали новые возможности, я продолжил работу.
Из старого кластера взял еще один освободившийся сервер и поставил на него два контейнера с дата-нодами ES под кластер новый. Все остальное железо отправилось в резерв.
Итоговая структура получилась точно такой, какой планировалась на первой схеме:
Три мастер-ноды.
Три клиентские ноды.
Восемь дата-нод (по две на сервер).
- Четыре log-receiver (HAProxy + Heka Pools, по одному на каждый сервер).
Переводим кластер в production режим – возвращаем параметры буферов и интервалы обновления индексов:
memory.index_buffer_size: 10%
index.refresh_interval: 1sКворум кластера (учитывая три мастер-ноды) выставляем равным двум:
discovery.zen.minimum_master_nodes: 2Далее нужно вернуть значения шард, принимая во внимание, что дата-нод у нас уже восемь:
{
"default": {
"order": 0,
"template": "*",
"settings": {
"index": {
"number_of_shards": "8",
"number_of_replicas": "1"
}
}
}
}Наконец, выбираем удачный момент (все сотрудники разошлись по домам) и перезапускаем кластер.
Нашардить, но не смешивать
В этом разделе я хочу обратить особое внимание на снижение общей надёжности системы, которое возникает при размещении нескольких дата-нод ES в одном железном сервере, да и вообще при любой виртуализации.
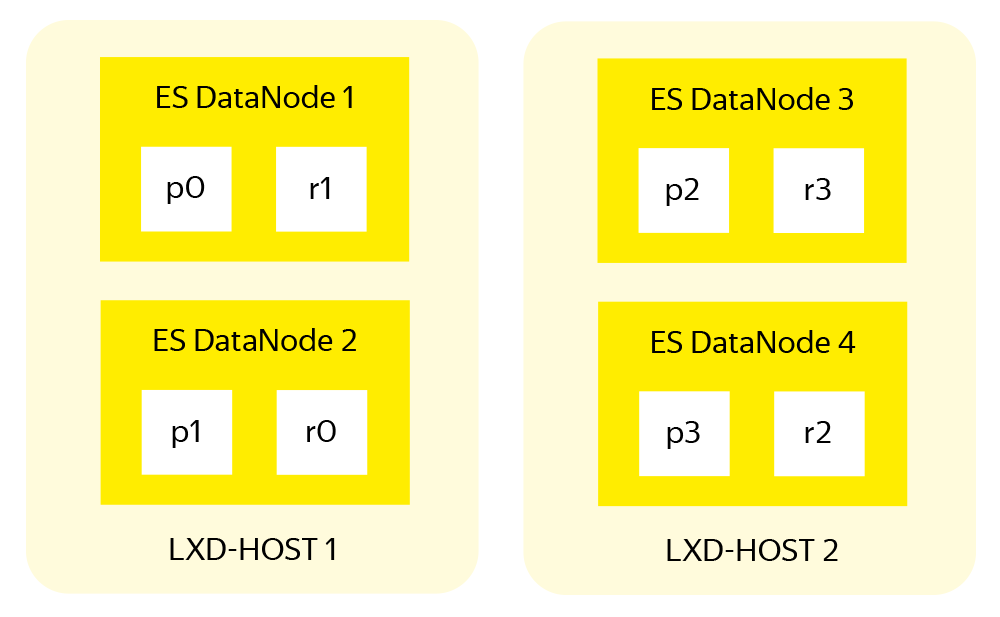
С точки зрения ES кластера – всё хорошо: индекс разбит на шарды по количеству дата-нод, каждый шард имеет реплику, primary и replica шарды хранятся на разных нодах.
Система шардирования и репликации в ES повышают как скорость работы, так и надёжность хранения данных. Но эта система проектировалась с учётом размещения одной ноды ES на одном сервере, когда в случае проблем с оборудованием теряется лишь одна дата-нода ES. В случае с нашим кластером упадут две. Даже с учетом равного разделения индексов между всеми нодами и наличия реплики для каждого шарда, не исключена ситуация когда primary и replica одного и того же шарда оказываются на двух смежных дата-нодах одного физического сервера.
Поэтому разработчики ES предложили инструмент для управления размещением шард в пределах одного кластера – Shard Allocation Awareness (SAA). Этот инструмент позволяет при размещении шард оперировать не дата-нодами, а более глобальными структурами вроде серверов с LXD-контейнерами.
В настройки каждой дата-ноды нужно поместить ES атрибут, описывающий физический сервер, на котором она находится:
node.attr.rack_id: log-lxd-host-NТеперь нужно перезагрузить ноды для применения новых атрибутов, и добавить в конфигурацию кластера следующий код:
{
"persistent": {
"cluster": {
"routing": {
"allocation": {
"awareness": {
"attributes": "rack_id"
}
}
}
}
}
}Причем только в таком порядке, ведь после включения SAA кластер не будет размещать шарды на нодах без указанного атрибута.
Кстати, аналогичный механизм можно использовать для нескольких атрибутов. Например, если кластер расположен в нескольких дата-центрах и вы не хотите туда-сюда перемещать шарды между ними. В этом случае уже знакомые настройки будут выглядеть так:
node.attr.rack_id: log-lxd-hostN
node.attr.dc_id: datacenter_name{
"persistent": {
"cluster": {
"routing": {
"allocation": {
"awareness": {
"attributes": "rack_id, dc_id"
}
}
}
}
}
}Казалось бы, все в этом разделе очевидно. Но именно очевидное и вылетает из головы в первую очередь, так что отдельно проверьте – тогда после переезда не будет мучительно больно.
Следующая статья цикла будет посвящена двум моим самым любимым темам – мониторингу и тюнингу уже построенной системы. Обязательно пишите в комментариях, если что-то из уже написанного или запланированного особенно интересно и вызывает вопросы.
Комментарии (11)

avikez
15.06.2017 16:49+2Хорошая статья. Месяц назад тоже мигрировали с 1.7 на 5.3 (~90 млрд документов) и это было нетривиально.
Официальная документация по миграции все же есть: reinrex-from-remote. Эта процедура показывает очень хорошую производительность. Но есть проблема… Проблема в том, что при ошибках реиндексации(в моем случае конфликтах в типах) невозможно скипнуть документ (опция "conflicts": "proceed" не работает).
Поэтому я так же использовал logstash, правда производительность его оказалась не высока(около 5000док./сек). Я разбил daily индекс на N частей, и каждую часть реиндексировал отдельным экземпляром логстеша. Таким образом удалось достаточно быстро мигрировать документы.
Adel-S
15.06.2017 17:35Помнится над тюнингом logstash я просидел целый день. В итоге он разгонялся в пике до 23-25 тысяч записей в секунду (на каждый запущенный экземпляр), но под него был выделен целый сервер.
Adel-S
15.06.2017 17:42А кстати интересно — по какому принципу делили и как logstash понимал с какой частью ему работать?
avikez
15.06.2017 17:52+1По timestamp. Был общий конфиг (erb темплейт) куда подставлял нужные числа. Делил день на N частей. И на каждый индекс/логстеш генерировал свой конфиг. Запускал через SSHKit.
Понятное дело, что в этих таймфреймах разное количество документов, И общая производительность плавала, но мне это было не критично(я мог потратить на реиндексацию больше времени). Было бы критично, сделал бы селект по количеству документов в индексе, и распределил бы их равномерно по всем логстешам.
avikez
15.06.2017 17:57+2Да, кстати. Сейчас посмотрел в темплейт. Там еще для каждого экземпляра timeframe делится на N input по количеству свободных ядер
input { # We read from the "old" cluster elasticsearch { hosts => [ "localhost:9200" ] size => 1000 index => "logstash-2016.08.19" docinfo => true query => '{ "query": { "range": { "@timestamp": { "gte": "2016-08-19T16:00.000+00:00", "lte": "2016-08-19T16:59.999+00:00" } } } }' } elasticsearch { hosts => [ "localhost:9200" ] size => 1000 index => "logstash-2016.08.19" docinfo => true query => '{ "query": { "range": { "@timestamp": { "gte": "2016-08-19T17:00.000+00:00", "lte": "2016-08-19T17:59.999+00:00" } } } }' } elasticsearch { hosts => [ "localhost:9200" ] size => 1000 index => "logstash-2016.08.19" docinfo => true query => '{ "query": { "range": { "@timestamp": { "gte": "2016-08-19T18:00.000+00:00", "lte": "2016-08-19T18:59.999+00:00" } } } }' } } output { elasticsearch { template => "/mnt/glustersnaps/logstash/config/template/reindex.json" template_name => "logstash-*" template_overwrite => true hosts => ["es1:9200", "es2:9200", "es3:9200", "es4:9200", "es5:9200", "es6:9200"] index => "%{[@metadata][_index]}" } }avikez
15.06.2017 18:02+1ну и сам темплейт для индеков:
{ "template" : "logstash-*", "version" : 50007, "order" : 99, "settings" : { "index.refresh_interval": -1, "number_of_replicas": 0, "number_of_shards": 5, "index.mapping.ignore_malformed": true, "index.merge.scheduler.max_thread_count": 1, "index.routing.allocation.require.box_type": "reindex" } }

alpha_Dog
15.06.2017 17:54Первые две статьи — отличные. Жду с наибольшим интересом третью — про мониторинг. Как раз предстоит поднимать/настраивать систему логгирования.
denis_lx
15.06.2017 22:59Отличная статья, большое спасибо!
Вынес для себя много полезного.
С нетерпением буду ждать третьей части.
Nice1ever
Читается как детективный роман, спасибо автору за изложение :)
Adel-S
Надеюсь, что развязка в финале не разочарует :)