
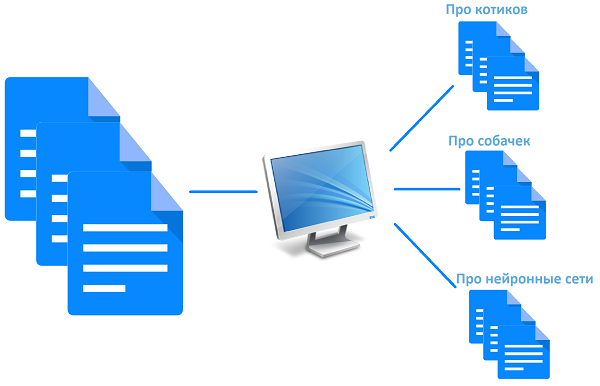
Лена – это наш сотрудник технической поддержки. Одна из ее обязанностей – распределение поступающих на электронную почту обращений между специалистами. Она анализирует обращение и определяет ряд характеристик. Например, «Тип обращения»: ошибка системы, пользователю просто нужна консультация, пользователь хочет какую-то новую функциональность. Определяет «Функциональный модуль системы»: модуль бухгалтерии, модуль паспортизации оборудования и т.д. Проставив все эти характеристики, она перенаправляет обращение соответствующему специалисту.
– Давай я напишу программу, которая это будет делать автоматически! – ответил я.
На этом увлекательный роман заканчиваем и переходим к технической части.
Формализуем задачу
- на вход поступает текст произвольной длины и содержания;
- текст написан человеком, поэтому может содержать опечатки, ошибки, сокращения и вообще быть малопонятным;
- этот текст нужно как-то проанализировать и классифицировать его по нескольким несвязанным между собой характеристикам. В нашем случае нужно было определить суть обращения: сообщение об ошибке, запрос новой функциональности или нужна консультация, а также определить функциональный модуль: расчет з/п, бухгалтерия, управление складом и т.д.;
- может быть присвоено только одно значение для каждой характеристики;
- набор возможных значений для каждой характеристики заранее известен;
- имеется несколько тысяч уже классифицированных обращений.
Формализовав задачу и начав разработку под наши конкретные нужды, я понял, что лучше разрабатывать сразу универсальный инструмент, который не будет жестко завязан на какие-то конкретные характеристики и на число этих характеристик. В результате родился инструмент, умеющий классифицировать текст по произвольным характеристикам.
Готовых решений искать не стал, потому что было время и интерес сделать самостоятельно, параллельно погрузившись в изучение нейронных сетей.
Выбор инструментов
Так как в тот момент я самостоятельно активно изучал язык JAVA, то и писать решил на нем, чтобы теорию подкрепить практикой.
В качестве СУБД использовал SQLite.
Отсюда взял готовую реализацию нейронной сети (Encog Machine Learning Framework). Я решил в качестве классификатора использовать именно нейронную сеть, а не, например, наивный байесовский классификатор, потому что, во-первых, теоретически, нейронная сеть должна быть точнее. Во-вторых, мне просто хотелось поиграться с нейронными сетями.
Для чтения Excel-файла с данными для обучения понадобились некоторые библиотеки Apache POI.
Ну, и для тестов традиционно использовал JUnit 4.
Чуть-чуть теории
Не буду подробно описывать теорию по нейронным сетям, так как ее предостаточно (тут неплохой вводный материал). Вкратце и по-простому: у сети есть входной слой, скрытые слои и выходной слой. Количество нейронов в каждом слое определяется разработчиком заранее и после обучения сети изменению не подлежит: если добавили/убавили хоть один нейрон, то сеть нужно переобучать заново. На каждый нейрон входного слоя подается нормализованное число (чаще всего от 0 до 1). В зависимости от набора этих чисел на входном слое, после определенных вычислений, на каждом выходном нейроне тоже получается число от 0 до 1.
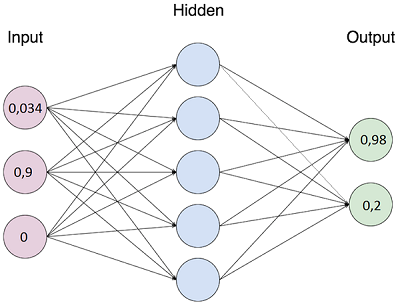
Суть обучения сети состоит в том, что сеть подстраивает свои веса связей, участвующие в вычислениях, таким образом, чтобы при заранее известном наборе чисел на входном слое получить заранее известный набор чисел на выходном слое. Подстраивание весов – процесс итеративный и происходит до тех пор, пока сеть не достигнет заданной точности на обучающей выборке либо пока не достигнет определенного числа итераций. После обучения предполагается, что сеть будет выдавать близкий к эталонному набор чисел на выходном слое, если на входной подали набор чисел, похожий на тот, который был в обучающей выборке.
Переходим к практике
Первой задачей стало придумать, как преобразовать текст к виду, который можно передать на вход нейронной сети. Но для начала нужно было определиться с размером входного слоя сети, так как он должен быть заранее задан. Очевидно, что входной слой должен быть такого размера, чтобы любой текст можно было в этот слой «уместить». Первое, что приходит в голову – размер входного слоя должен быть равен размеру словаря, содержащего слова/фразы, из которых состоят тексты.
Способов построения словаря много. Можно, например, тупо взять все слова русского языка и это будет наш словарь. Но такой подход не годится, потому что размер входного слоя будет настолько огромным, что для создания нейронной сети не хватит ресурсов простой рабочей станции. Для примера представим, что у нас словарь состоит из 100 000 слов, тогда имеем 100 000 нейронов во входном слое; допустим, 80 000 в скрытом слое (ниже описан способ определения размерности скрытого слоя) и 25 в выходном. Тогда просто для хранения весов связей потребуется ~60 Гб оперативки: ((100 000 * 80 000) + (80 000 * 25)) * 64 бита (тип double в JAVA). Во-вторых, такой подход не годится, потому что в текстах может использоваться специфичная терминология, отсутствующая в словарях.
Отсюда напрашивается вывод, что словарь надо строить только из тех слов/фраз, из которых состоят наши анализируемые тексты. Важно понимать, что в этом случае для построения словаря должен быть достаточно большой объем обучающих данных.
Один из способов «выдергивания» слов/фраз (даже точнее сказать, фрагментов) из текста называется построением N-грамм. Наиболее популярными являются униграммы и биграммы. Бывают так же символьные N-граммы – это когда текст дробится не на отдельные слова, а на отрезки символов определенный длины. Трудно заранее сказать, какая из N-грамм окажется эффективнее в конкретной задаче, поэтому нужно экспериментировать.
| Текст | Униграмма | Биграмма | 3-символьная N-грамма |
|---|---|---|---|
| Этот текст должен быть разбит на части | [«этот», «текст», «должен», «быть», «разбит», «на», «части»] | [«этот текст», «текст должен», «должен быть», «быть разбит», «разбит на», «на части»] | [«Это», «т т», «екс», «т д», «олж», «ен », «быт», «ь р», «азб», «ит », «на », «час», «ти»] |
Я решил двигаться от простого к сложному и разработал для начала класс Unigram.
class Unigram implements NGramStrategy {
@Override
public Set<String> getNGram(String text) {
if (text == null) {
text = "";
}
// get all words and digits
String[] words = text.toLowerCase().split("[ \\pP\n\t\r$+<>№=]");
Set<String> uniqueValues = new LinkedHashSet<>(Arrays.asList(words));
uniqueValues.removeIf(s -> s.equals(""));
return uniqueValues;
}
}
В результате, после обработки ~10 000 текстов, я получил словарь размером ~32 000 элементов. Проанализировав по диагонали полученный словарь, я понял, что в нем очень много лишнего, от чего надо бы избавиться. Для этого сделал следующее:
- Убрал все небуквенные символы (числа, знаки препинания, арифметические операции и т.д.), так как никакой смысловой нагрузки они, как правило, не несут.
- Прогнал слова через процедуру стемминга (использовал Стеммер Портера для русского языка). Кстати, полезным побочным эффектом этой процедуры является «унисексация» текстов, то есть «сделал» и «сделала» будут преобразованы в «сдела».
- Сначала я хотел определять и исправлять опечатки и грамматические ошибки. Начитался про Алгоритм Оливера (функция similar_text в PHP) и Расстояние Левенштейна. Но задача решилась гораздо проще, хоть и с погрешностью: я решил, что если элемент N-граммы встречается меньше, чем в 4 текстах из обучающей выборки, то мы этот элемент в словарь не включаем как бесполезный в будущем. Таким образом я избавился от большинства опечаток, слов с грамматическими ошибками, «слепленныхСлов» и просто очень редких слов. Но надо понимать, что если в будущих текстах будут часто встречаться опечатки и грамматические ошибки, точность классификации таких текстов будет ниже и тогда все-таки придется реализовывать механизм исправления опечаток и грамматических ошибок. Важно: такой «финт» с выкидыванием редко-встречающихся слов допустим при большом объеме данных для обучения и построения словаря.
Все это реализовано в классах FilteredUnigram и VocabularyBuilder.
public class FilteredUnigram implements NGramStrategy {
@Override
public Set<String> getNGram(String text) {
// get all significant words
String[] words = clean(text).split("[ \n\t\r$+<>№=]");
// remove endings of words
for (int i = 0; i < words.length; i++) {
words[i] = PorterStemmer.doStem(words[i]);
}
Set<String> uniqueValues = new LinkedHashSet<>(Arrays.asList(words));
uniqueValues.removeIf(s -> s.equals(""));
return uniqueValues;
}
private String clean(String text) {
// remove all digits and punctuation marks
if (text != null) {
return text.toLowerCase().replaceAll("[\\pP\\d]", " ");
} else {
return "";
}
}
}
class VocabularyBuilder {
private final NGramStrategy nGramStrategy;
VocabularyBuilder(NGramStrategy nGramStrategy) {
if (nGramStrategy == null) {
throw new IllegalArgumentException();
}
this.nGramStrategy = nGramStrategy;
}
List<VocabularyWord> getVocabulary(List<ClassifiableText> classifiableTexts) {
if (classifiableTexts == null ||
classifiableTexts.size() == 0) {
throw new IllegalArgumentException();
}
Map<String, Integer> uniqueValues = new HashMap<>();
List<VocabularyWord> vocabulary = new ArrayList<>();
// count frequency of use each word (converted to n-gram) from all Classifiable Texts
//
for (ClassifiableText classifiableText : classifiableTexts) {
for (String word : nGramStrategy.getNGram(classifiableText.getText())) {
if (uniqueValues.containsKey(word)) {
// increase counter
uniqueValues.put(word, uniqueValues.get(word) + 1);
} else {
// add new word
uniqueValues.put(word, 1);
}
}
}
// convert uniqueValues to Vocabulary, excluding infrequent
//
for (Map.Entry<String, Integer> entry : uniqueValues.entrySet()) {
if (entry.getValue() > 3) {
vocabulary.add(new VocabularyWord(entry.getKey()));
}
}
return vocabulary;
}
}
Пример составления словаря:
| Текст | Отфильтрованная униграмма | Словарь |
|---|---|---|
| Необходимо найти последовательность 12 задач | необходим, найт, последовательн, задач | необходим, найт, последовательн, задач, для, произвольн, добав, транспозиц |
| Задачу для произвольных | задач, для, произвольн | |
| Добавить произвольную транспозицию | добав, произвольн, транспозиц |
Для построения Биграмм тоже сразу написал класс, чтобы в итоге после экспериментов остановить выбор на варианте, дающем лучший результат по соотношению размера словаря и точности классификации.
class Bigram implements NGramStrategy {
private NGramStrategy nGramStrategy;
Bigram(NGramStrategy nGramStrategy) {
if (nGramStrategy == null) {
throw new IllegalArgumentException();
}
this.nGramStrategy = nGramStrategy;
}
@Override
public Set<String> getNGram(String text) {
List<String> unigram = new ArrayList<>(nGramStrategy.getNGram(text));
// concatenate words to bigrams
// example: "How are you doing?" => {"how are", "are you", "you doing"}
Set<String> uniqueValues = new LinkedHashSet<>();
for (int i = 0; i < unigram.size() - 1; i++) {
uniqueValues.add(unigram.get(i) + " " + unigram.get(i + 1));
}
return uniqueValues;
}
}
На этом я пока решил остановиться, но возможна и дальнейшая обработка слов для составления словаря. Например, можно определять синонимы и приводить их к единому виду, можно анализировать похожесть слов, можно вообще что-то свое придумать и т.д. Но, как правило, существенного прироста в точности классификации это не дает.
Ладно, идем дальше. Размер входного слоя нейронной сети, который будет равняться количеству элементов в словаре, мы вычислили.
Размер выходного слоя для нашей задачи сделаем равным количеству возможных значений для характеристики. Например, у нас 3 возможных значения для характеристики «Тип обращения»: ошибка системы, помощь пользователю, новая функциональность. Тогда количество нейронов выходного слоя будет равно трем. При обучении сети для каждого значения характеристики нужно заранее определить эталонный уникальный набор чисел, который мы ожидаем получить на выходном слое: 1 0 0 для первого значения, 0 1 0 – для второго, 0 0 1 – для третьего…
Что касается количества и размерности скрытых слоев, то тут какой-то конкретной рекомендации нет. В источниках пишут, что оптимальный размер под каждую конкретную задачу можно вычислить только экспериментальным путем, но для сужающейся сети рекомендуют начинать с одного скрытого слоя, размер которого колеблется в интервале между размерами входного слоя и выходного. Для начала я создал один скрытый слой размером 2/3 от входного слоя, а потом уже экспериментировал с числом скрытых слоев и их размерами. Вот тут можно почитать немного теории и рекомендаций по этому вопросу. Там же рассказывается о том, сколько должно быть данных для обучения.
Итак, сеть мы создали. Теперь нужно определиться с тем, как будем конвертировать текст в цифры, пригодные для «скармливания» нейронной сети. Для этого нам нужно преобразовать текст в вектор текста. Предварительно нужно каждому слову в словаре присвоить уникальный вектор слова, размер которого должен быть равен размеру словаря. После обучения сети менять вектора для слов нельзя. Вот как это выглядит для словаря из 4 слов:
| Слово в словаре | Вектор слова |
|---|---|
| привет | 1 0 0 0 |
| как | 0 1 0 0 |
| дела | 0 0 1 0 |
| тебе | 0 0 0 1 |
Процедура преобразования текста в вектор текста подразумевает под собой сложение векторов используемых в тексте слов: текст «как тебе привет?» будет преобразован в вектор «1 1 0 1». Этот вектор мы уже можем подавать на вход нейронной сети: каждое отдельное число на каждый отдельный нейрон входного слоя (число нейронов как раз равно размеру вектора текста).
private double[] getTextAsVectorOfWords(ClassifiableText classifiableText) {
double[] vector = new double[inputLayerSize];
// convert text to nGram
Set<String> uniqueValues = nGramStrategy.getNGram(classifiableText.getText());
// create vector
//
for (String word : uniqueValues) {
VocabularyWord vw = findWordInVocabulary(word);
if (vw != null) { // word found in vocabulary
vector[vw.getId() - 1] = 1;
}
}
return vector;
}
Тут и тут можно дополнительно почитать про подготовку текста к анализу.
Точность классификации
Поэкспериментировав с разными алгоритмами формирования словаря и с разным количеством и размерностью скрытых слоев, я остановился на таком варианте: используем FilteredUnigram с отсеканием редкоиспользуемых слов для формирования словаря; делаем 2 скрытых слоя размерностью 1/6 от размера словаря – первый слой и 1/4 от размера первого слоя – второй слой.
После обучения на ~20 000 текстов (а это очень мало для сети такого размера) и на прогоне сети по 2 000 эталонных текстов имеем:
| N-грамма | Точность | Размер словаря (без редкоиспользуемых слов) |
|---|---|---|
| Униграмма | 58% | ~25 000 |
| Отфильтрованная униграмма | 73% | ~1 200 |
| Биграмма | 63% | ~8 000 |
| Отфильтрованная биграмма | 69% | ~3 000 |
Это точность для одной характеристики. Если нужна точность для нескольких характеристик, то формулы расчета такие:
- Вероятность угадывания сразу всех характеристик равна произведению вероятностей угадывания каждой характеристики.
- Вероятность угадывания хотя бы одной характеристики равна разности между единицей и произведением вероятностей некорректного определения каждой характеристики.
Пример:
Допустим, точность определения одной характеристики равна 65%, второй характеристики – 73%. Тогда точность определения сразу обеих равна 0,65*0,73 = 0,4745= 47,45%, а точность определения хотя бы одной характеристики равна 1-(1-0,65)*(1-0,73) = 0,9055= 90,55%.
Вполне неплохой результат для инструмента, не требующего предварительной ручной обработки входящих данных.
Есть одно «но»: точность сильно зависит от похожести текстов, которые должны быть отнесены в разные категории: чем менее похожи тексты из категории «Ошибки системы» на тексты из категории «Нужна помощь», тем точнее будет классификация. Поэтому при одних и тех же настройках сети и словаря в разных задачах и на разных текстах могут быть значительные различия в точности.
Итоговая программа
Как уже говорил, я решил писать универсальную программу, не привязанную к числу характеристик, по которым нужно классифицировать текст. Я тут не буду подробно описывать все детали разработки, опишу лишь алгоритм работы программы, а ссылка на исходники будет в конце статьи.
Общий алгоритм работы программы:
- При первом запуске программа запрашивает XLSX-файл с обучающими данными. Файл может состоять из одного или из двух листов. На первом листе данные для обучения, на втором – данные для последующего тестирования точности сети. Структура листов совпадает. В первой колонке должен быть анализируемый текст. В последующих колонках (их может быть сколько угодно) должны содержаться значения характеристик текста. В первой строке должны содержаться названия этих характеристик.
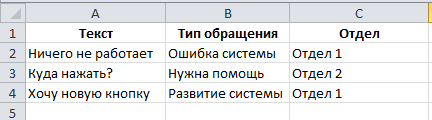
- На основании этого файла строится словарь, определяется перечень характеристик и уникальные значения, допустимые для каждой характеристики. Все это сохраняется в хранилище.
- Создается отдельная нейронная сеть для каждой характеристики.
- Все созданные нейронные сети обучаются и сохраняются.
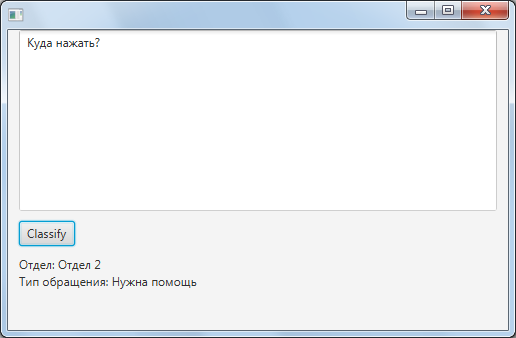
- При последующем запуске все сохраненные обученные нейронные сети подгружаются. Программа готова к анализу текста.
- Полученный текст обрабатывается независимо каждой нейронной сетью, и выдается общий результат в виде значения для каждой характеристики.
В планах:
- Добавить другие типы классификаторов (например, сверточную нейронную сеть и наивный байесовский классификатор);
- Попробовать использовать словарь, состоящий из комбинации униграмм и биграмм.
- Добавить механизм устранения опечаток и грамматических ошибок.
- Добавить словарь синонимов.
- Исключать слишком часто-встречающиеся слова, так как они, как правило, являются информационным шумом.
- Добавить веса к отдельным значимым словам, чтобы их влияние в анализируемом тексте было больше.
- Немного переделать архитектуру, упростив API, чтобы можно было вынести основную функциональность в отдельную библиотеку.
Немного об исходниках
Исходники могут быть полезны в качестве примера использования некоторых паттернов проектирования. Выносить это в отдельную статью нет смысла, но и умалчивать про них, раз уж делюсь опытом, тоже не хочется, поэтому пусть будет в этой статье.
- Паттерн «Стратегия». Интерфейс NGramStrategy и классы, его реализующие.
- Паттерн «Наблюдатель». Классы LogWindow и Classifier, реализующие интерфейсы Observer и Observable.
- Паттерн «Декоратор». Класс Bigram.
- Паттерн «Простая фабрика». Метод getNGramStrategy() интерфейса NGramStrategy.
- Паттерн «Фабричный метод». Метод getNgramStrategy() класса NGramStrategyTest.
- Паттерн «Абстрактная фабрика». Класс JDBCDAOFactory.
- Паттерн (антипаттерн?) «Одиночка». Класс Config. Наверное, это один из немногих случаев, когда использование одиночки оправдано.
- Паттерн «Шаблонный метод». Метод initializeIdeal() класса NGramStrategyTest. Правда, тут не совсем классическое его применение.
- Паттерн «DAO». Интерфейсы CharacteristicDAO, ClassifiableTextDAO и т.д.
Полный исходный код: https://github.com/RusZ/TextClassifier
Конструктивные предложения и критика приветствуются.
P.S.: За Лену не переживайте – это вымышленный персонаж.
Комментарии (26)

kdenisk
03.07.2017 12:49+1Палец вверх за Java. Посмотрите ещё в сторону deeplearning4j и word2vec (в том же deeplearning4j есть реализация). Последний даст прирост и по точности и по скорости, если хватит данных для обучения. И не надо будет словарь синонимов прикручивать. Тем более, что это неэффективно для тематических текстов.
i11
03.07.2017 14:17Я изначально взял в качестве реализации нейронной сети именно deeplearning4j, но только создание сети с несколькими тысячами нейронов во входном и скрытом слоях длилось более получаса на очень неслабой машине. конечно, может быть стоило глубже поковыряться в параметрах, но я решил сменить фреймворк на Encog, у которого из коробки не было проблем со производительностью — на нем и остановился.
Tremere
03.07.2017 14:18Вы сказали что не будете искать готовых решений(к слову, почему?), но тем не менее уже взяли некоторые существующие подходы.
Ну и к тому же, есть уже много хорошо описанных решений на питоне, не пробовали сравнивать качество со своей моделью?i11
03.07.2017 14:31Вы сказали что не будете искать готовых решений(к слову, почему?), но тем не менее уже взяли некоторые существующие подходы.
В том же предложении, где я сказал, что не буду искать готовых решений, объясняется почему я этого не делаю: было время и интерес сделать своими руками — это во-первых. Во-вторых, хотел смахнуть пыль со знаний JAVA, решив конкретную задачу. Реализацию сети взял готовую, потому что хотел сосредоточиться на решении задачи формирования словаря и преобразования текста в вектор.
Ну и к тому же, есть уже много хорошо описанных решений на питоне, не пробовали сравнивать качество со своей моделью?
Под качеством вы понимаете точность классификации? Конкретных сравнений с другими решениями я не проводил, но точность в районе 80% считается очень хорошим показателем в задачах классификации текста. На самом деле, тут от инструмента зависит только скорость и объем используемых ресурсов, но никак не точность.
reforms
03.07.2017 15:39+1Плюс за статью.
Так как критика приветствуется, имею следующее:
посмотрел код в пакете com.irvil.textclassifier.dao.jdbc; Сложилось впечатление, что код написан небрежно, где-то sql ошибки глотаются, где-то на консоль пишутся, con.commit есть, а con.rollback нет (правда может в SQLite jdbc драйвере это поведение по умолчанию), результаты операций не проверяются, с con.setAutoCommit нужно работать аккуратнее и много чего ещё. В общем, если проект будете развивать то рекомендую такие огрехи зачищать сразу.
svboobnov
04.07.2017 22:48+1Позвольте заметить, что вместо SQLite можно использовать H2db. Я пару лет назад её пробовал, и с Java-кодом она работала быстрее, чем SQLite. Возможно это от того, что нет оверхеда Java <-> JNI.
i11
05.07.2017 21:02Да, я про H2 уже думал, у меня это даже записано в TODO. Она действительно должен быть быстрее.
vasja0441
03.07.2017 21:05Попробовал из " но вот тут уже есть форк" попробовать что то — никаких членораздельных результатов увы не получилось. Есть возможность как то дочистить тот самый форк, что бы можно было на данных чуть пообширнее чем 3 строчки это потестить?
i11
03.07.2017 21:09Я добавил поддержку Maven в свой проект, поэтому теперь можно взять за основу его, а не форк. На каком конкретно этапе у вас возникли проблемы и какого они рода?
vasja0441
04.07.2017 15:15С мавином лучшче! Так вот:
1) git clone https://github.com/RusZ/TextClassifier.git
2) ubuntu
3) Java version: 1.8.0_111, vendor: Oracle Corporation
Java home: /usr/lib/jvm/java-8-oracle/jre
4) start MainWindow
…
Storage created. Wait…
Vocabulary is null or empty
'Characteristic 2' characteristic saved. Wait…
'Characteristic 1' characteristic saved. Wait…
Classifiable texts saved. Wait…
java.lang.IllegalArgumentException
…
Есть констольный вариант для «попробовать»? Винду ставить для хеллоуворда ка кто не охота.i11
04.07.2017 20:42У вас слишком маленький объем обучающих данных. Настолько маленький, что не выполняется требование, что униграмма должна встречаться хотя бы в 4 разных текстах — только в этом случае она добавится в словарь. В вашем случае словарь пустой. Вам нужно хотя бы 100-200 обучающих текстов даже для «попробовать».
А зачем вам винда? Скомпилироваться и запуститься должно в любой системе. Если проблема в подготовке XLSX-файла, то тут Google Docs в помощь.vasja0441
05.07.2017 09:30-1А насколько сложно «обучающие данные» включить в уже существующий проект?
Я «загружаю» прилагаемый "/TextClassifier/test_db/test.xlsx", который, как я понял запрашивает оконное приложение при первом старте. Вот в этом то файлике данных и маловато. При моей попытке «набить хотя бы 100-200 текстов» прога тупо зависает на пару часов, и…
… дальше помогает только килл процесса :(
Посему хотелось бы посмотреть сначала на уже работающий вариант, чем самому топтаться по всем Вами уже пройденнным граблям.i11
05.07.2017 20:59Универсальных обучающих данных не существует. Они для каждой отдельной задачи подбираются индивидуально, поэтому заранее включить что-то в проект нельзя.
Файл test_db/test.xlsx используется в JUnit-тестах и служит для тестирования модуля считывания Excel-файла. Его использовать в качестве обучающих данных не нужно.
При моей попытке «набить хотя бы 100-200 текстов» прога тупо зависает на пару часов
Она, скорее всего, не тупо повисла, а начался процесс обучения сети. Каждую эпоху выводится результат в окно с логом. На слабой машине это вполне может длиться часами.
Посему хотелось бы посмотреть сначала на уже работающий вариант, чем самому топтаться по всем Вами уже пройденнным граблям.
Чтобы увидеть работающий вариант, его нужно обучить именно на ваших данных.vasja0441
06.07.2017 11:10-1Налицо паттерн непонимания программистами проблем конечных пользователей.
Аргументы:
— у меня работает!
— у Вас компьютер медленеый, что я могу поделать?
— твой компьютер, ты и разбирайся
— сам дурак :)
ЗЫ
я убил пару часов что бы:
— прочитать
— понять
— скачать\скомпилить\прикрутить мавен с депетденси\
— подождать пока научиться…
— три дня дискуссии в хабре
ЗЫЗЫ
«машина» не медленная :)
Результат:
— кроме как на наборе данных из (!) одного это работает правильно и только в JUnit. Больше позитивных результатов не получилось :(
Вывод
— в корзину. Спасиба за помощь и радушие! :)


gltrinix
04.07.2017 01:58-1А не думали для повышения точности сделать многослойную модель? Например, на первом слое данные проходят через нейронную сеть, наивный байесовский классификатор, логистическую регрессию, k-means с количеством соседей равным и большим в 2 раза исходное количество классов. А на втором слое, какой-нибудь градиентный бустинг по данным предсказанным на первом слое.
i11
04.07.2017 06:06-1Иногда используют комбинацию нескольких классификаторов. Правда, не такую сложную, как вы описали. Но это дает несущественный прирост производительности по сравнение с затраченными усилиями на разработку. Есть смысл с этим заморачиваться, если твоя программа будет соревноваться с другими и 1-2% к точности могут обеспечить победу.
Лучше выбрать какой-то один классификатор и направить силы на увеличение его точности. В многослойной модели, скорее всего, все упрется в бутылочное горлышко — самый неточный слой будет портить общую картину.
sergey-b
04.07.2017 09:16+1Правильно ли я понимаю, что результат классификации зависит только от количества определенных слов в тексте и не зависит от их порядка?
i11
04.07.2017 11:42Результат классификации зависит не от количества, а от наличия в анализируемом тексте слова (точнее сказать, фрагмента) из словаря. Если использовать биграммы (или триграммы) вместо униграмм, то частично будет учитываться и порядок следования («Я люблю вкусное мороженное» --> [«я люблю», «люблю вкусное», «вкусное мороженное»]). Для использования биграмм в конфигурационном файле программы нужно сменить параметр ngram_strategy с filtered_unigram на bigram или filtered_bigram.
rPman
08.07.2017 22:56Есть идея, добавить во входные данные больше информации о тексте. Причем данные о тексте могут быть абсурдно бессмысленными — количество слов/символов, факт наличия определенных знаков препинания (вопрос, воскл.знак, точка, запятая, двоеточие и т.п.), расстояние между знаками препинания (можно разработать несколько метрик — типа мин/макс, и видов — межу точка/вопрос/воскл. — определяет длину предложений, и т.п.), использование 'ё', наличие иностранных слов или только русских и т.п.
Точно помню, при исследовании анализа авторства текстов вылезали такие странные закономерности что диву даешься (не мое, чужой диплом очень очень давно).svboobnov
12.07.2017 11:53Где-то на киберленинке была работа об определении авторства произведения (минимум 1000 знаков нужно).
Т.е. задача такого типа: Есть неизвестный ранее текст. Надо определить: этот текст написан Л. Толстым, или кем-то другим?
Так вот, там предлагались метрики:
- Длина предложения;
- Состав частей речи (т.е., сколько существительных, прилагательных, глаголов и пр..)
- Наличие редких (не используемых в обычной разговорной речи) слов.
Авторы утверждали, что точность такого набора метрик более 90%.
xxxFeLiXxxx
Было бы ещё неплохо pom.xml добавить к проекту, чтобы прямо после чекаута кода можно было собрать проект.
i11
Я не использовал Maven для этого проекта, но вот тут уже есть форк с необходимым вам файлом pom.xml.
P.S.: надо бы и к своему проекту прикрутить Maven. Займусь.
i11
Добавил поддержку Maven. Файл pom.xml доступен на Github.