

Под катом вы найдете подробное описание задач и их решения с картинками и запросами.
Задачи
Компания X имеет порядка 30 департаментов, в которых порядка 400 внутренних номеров и около 100 000 звонков в месяц.
- Компания X хочет получать аналитику звонков внутренних пользователей как наружу так и между собой. Необходимо получать информацию о количестве телефонных звонков, количестве звонящих пользователей, распределении входящих и исходящих звонков, самых звонящих абонентах внутри/извне.
- Необходимы отчеты, показывающие как сотрудники из различных департаментов взаимодействуют с контрагентами. Зачастую такую задачу тяжело объективно решить на основании опросов, а благодаря анализу телефонных звонков можно получить максимально объективную картину.
- Необходимо оценить интенсивность звонков, для понимания активности работы менеджеров внутри организации.
Компания Y имеет колл-центр на базе Asterisk телефонии с 1 млн звонком в день и хочет получать аналитику о его работе. Больше всего компания Y хочет знать количество конкурентных звонков (занятых time слотов) в определенный квант времени (например в каждый час), с распределением по внешним потокам. Плюс базовые kpi, такие как: средняя продолжительность звонков, средняя продолжительность разговора, процент отвеченных вызовов и прочее.
Решения задач
В данной статье мы не будем рассказывать о том как подключить данные Splunk и как сделать разбор полей (если интересно именно это, напишите нам — и мы сделаем отдельную статью об этом, но на самом деле никакого rocket science там нет). Мы покажем основные запросы, графики и дашборды.
Компания X
Аналитика по всей организации:

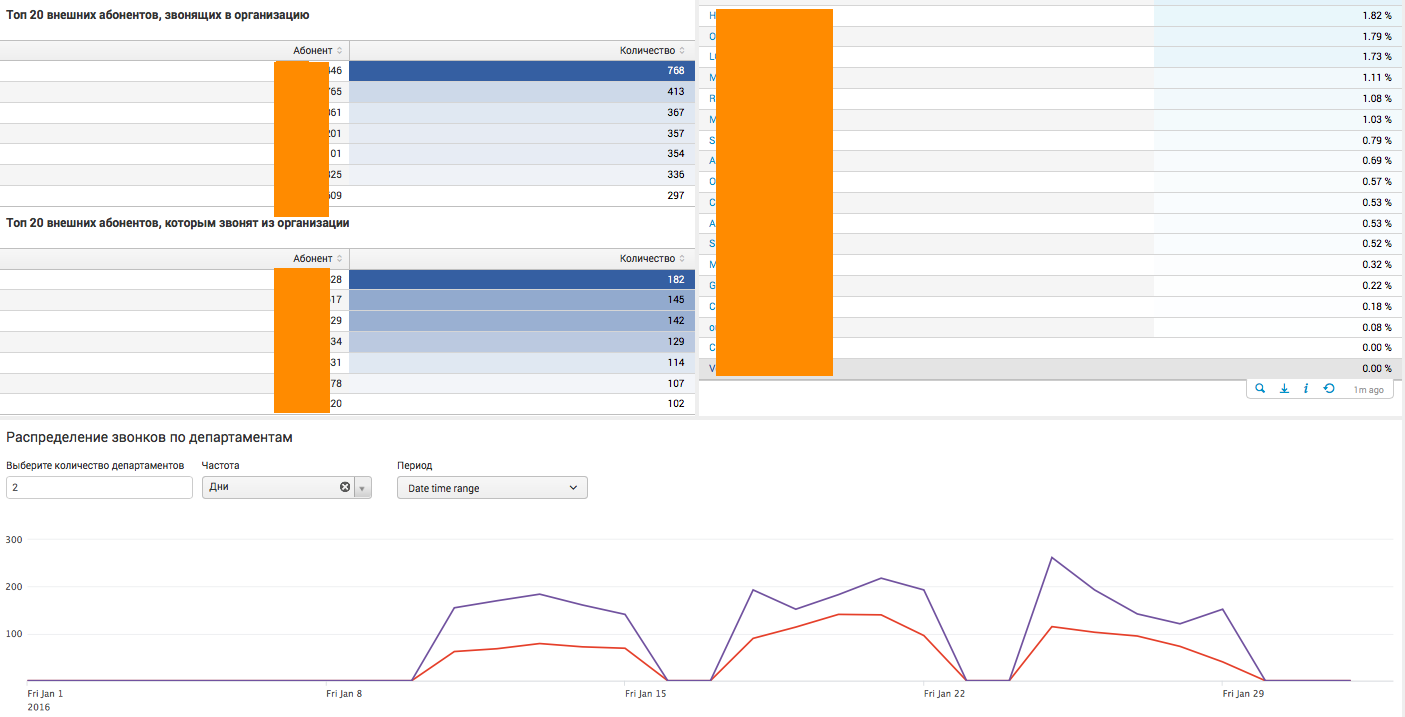
На данном дашборде собрана общая аналитика по всей компании в целом, с различными статистическими показателями. Дашборд живой, то есть имеет различные фильтры, а также может отправить пользователя на следующий уровень детализации. К примеру, при нажатии на определенный департамент или номер телефона, пользователь увидит аналитику в разрезе выбранного сегмента.
Аналитика в рамках отдельного департамента:
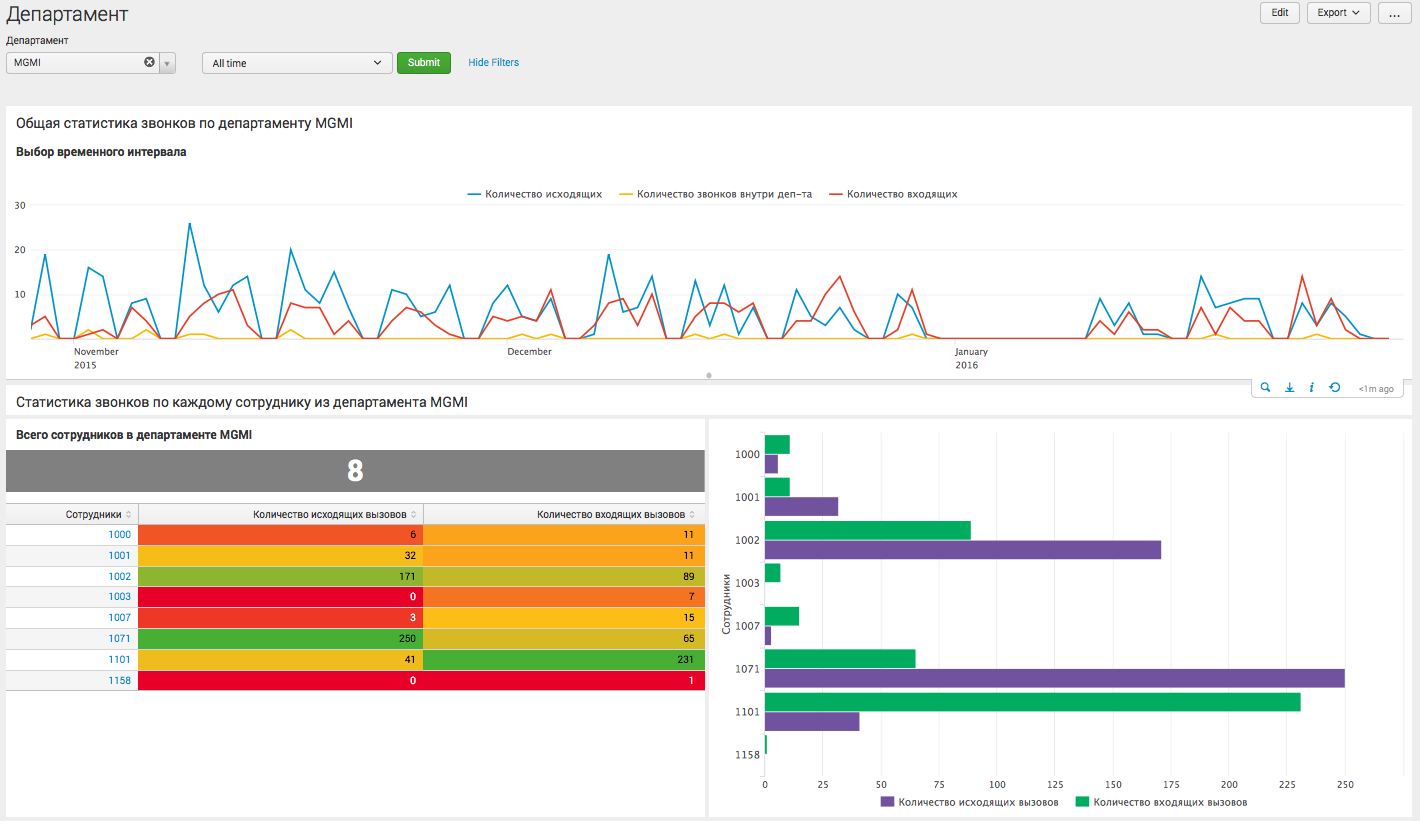
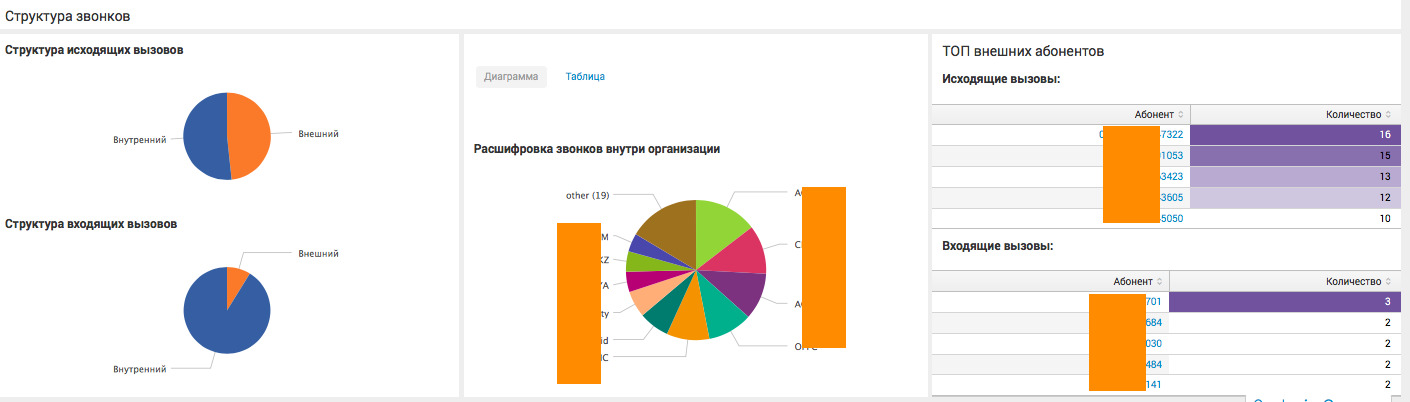
На этом дашборде пользователь видит детализацию по конкретному департаменту компании, и может сделать вывод как о статистике взаимодействия сотрудников данного отдела с другими внутренними департаментами, так и о внешних вызовах.
Аналитика по конкретному пользователю:
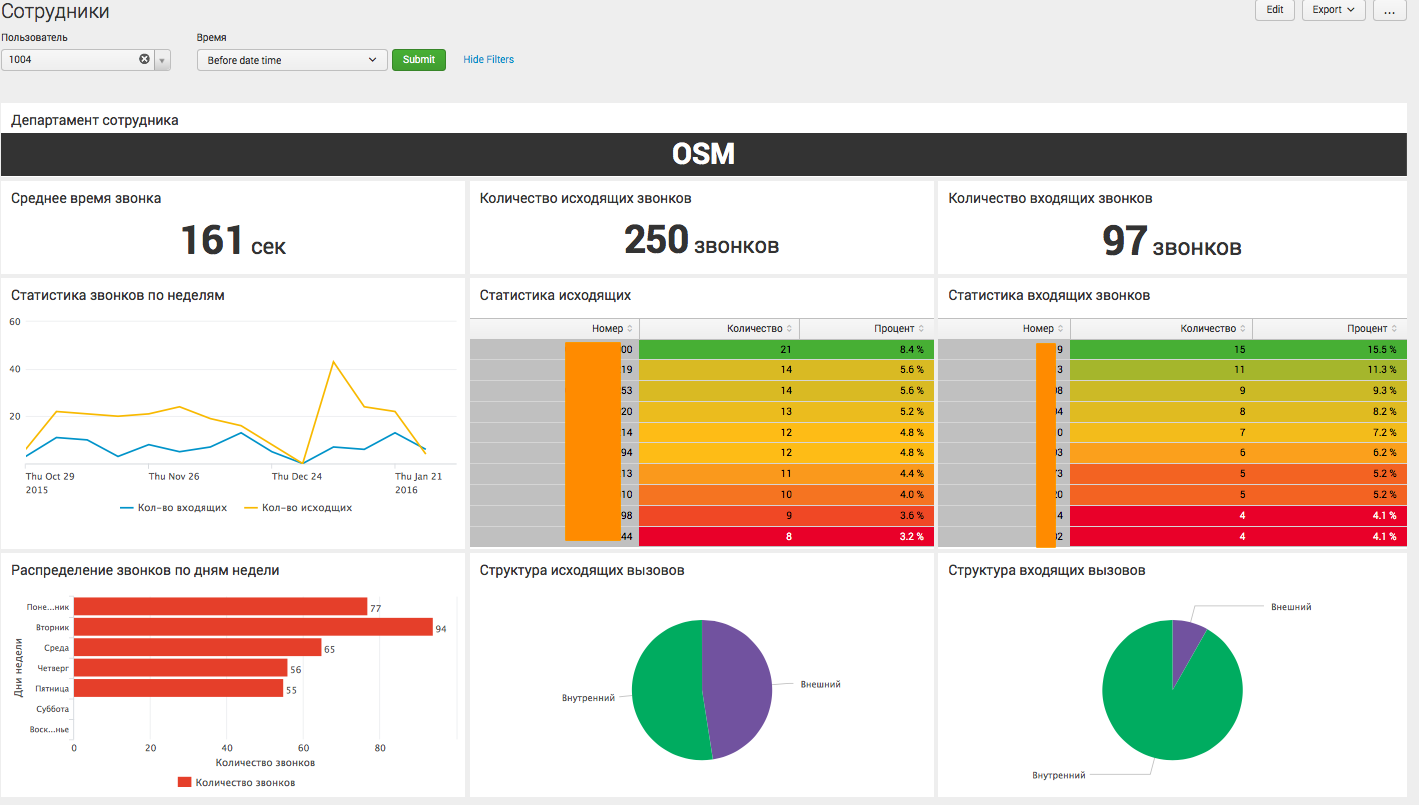
Это последний уровень детализации, где мы видим информацию, касающуюся определенного сотрудника организации, и можем судить о его активности.
Запросы
На самом деле все эти графики построены на достаточно простых запросах, уровень сложности сравним с теми, что мы обсуждали в наших предыдущих статьях. Ниже один из наиболее сложных:
|inputlookup lookup.csv
| where unit = "MGMI"
| table ext
| join ext type=left
[search index=test sourcetype = csv Department = "MGMI" | stats count AS "colorig" by callingPartyNumber| rename callingPartyNumber as ext]
| join ext type=left
[search index=test sourcetype = csv DepartmentDest = "MGMI" | stats count AS "coldest" by originalCalledPartyNumber| rename originalCalledPartyNumber as ext ]
| eval C=if(isnull(colorig), 0,colorig)
| eval D = if(isnull(coldest), 0,coldest)
| table ext C D
|rename ext as "Сотрудники" C as "Количество исходящих вызовов" D as "Количество входящих вызовов"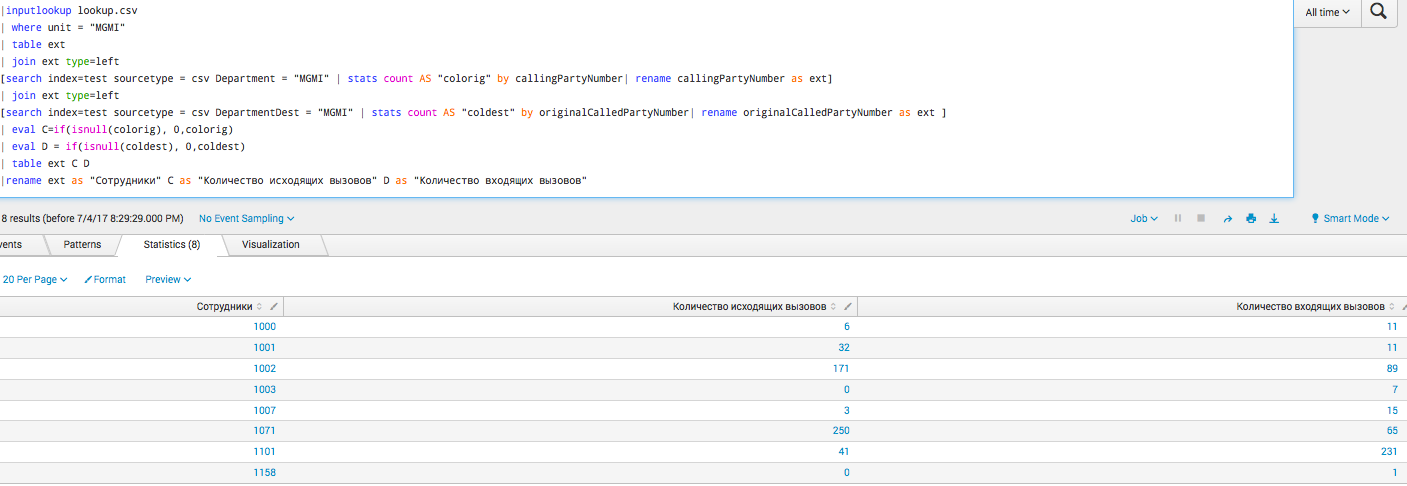
Компания Y
Здесь все намного проще, так как у колл-центра есть только один тип звонков, да и компанию в большей степени интересует только сводная информация. Однако, возможность дороботки и детализации не исключена, например по конкретному сотруднику. Ниже основной дашборд на основе CDR Asteriska:
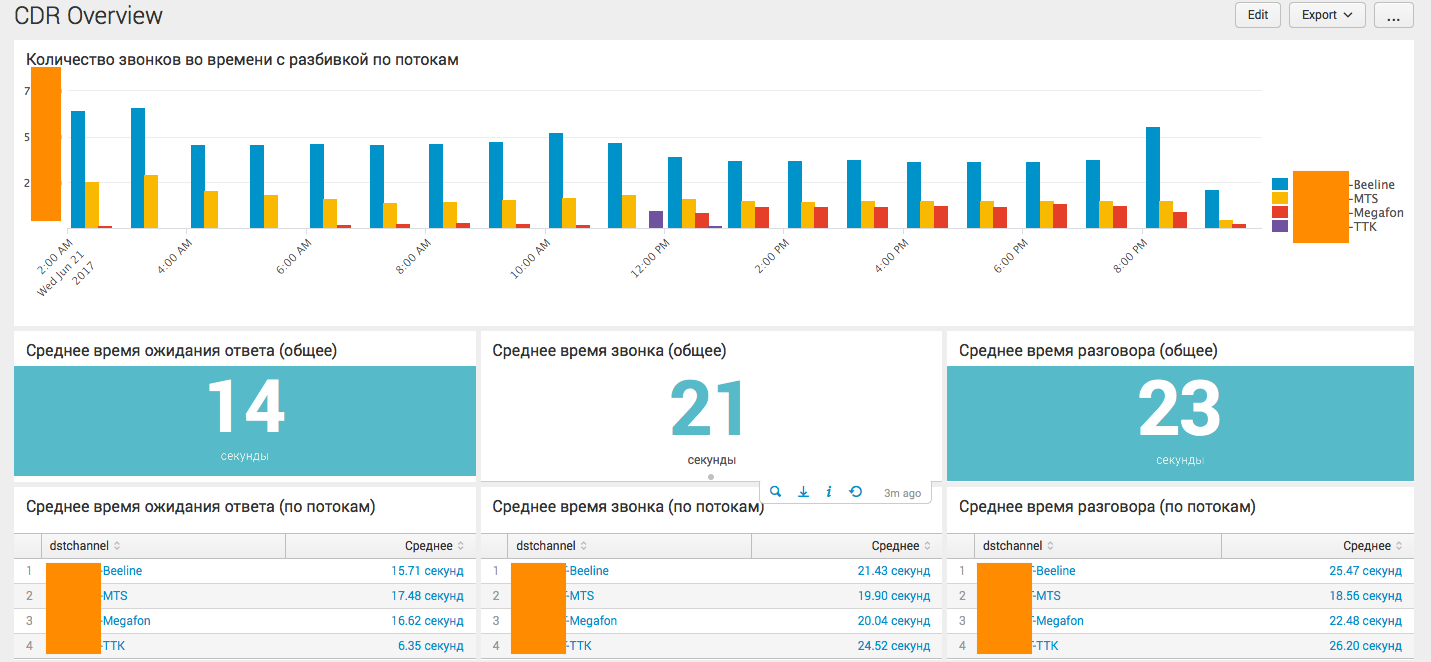

Наиболее интересным является самый нижний график, где решается задача по вычислению конкурентных сессий.
Запросы
Ниже один из наиболее сложных запросов, как раз про конкурентные сессии:
index="aster2" dstchannel="Beeline" | concurrency duration=duration | timechart span=1h max(concurrency) as Beeline
| join _time type=left
[search index="aster2" dstchannel="MTS" | concurrency duration=duration | timechart span=1h max(concurrency) as MTS
| join _time type=left
[search index="aster2" dstchannel="Megafon" | concurrency duration=duration | timechart span=1h max(concurrency) as Megafon
| join _time type=left
[search index="aster2" dstchannel="TTK" | concurrency duration=duration | timechart span=1h max(concurrency) as TTK ]]]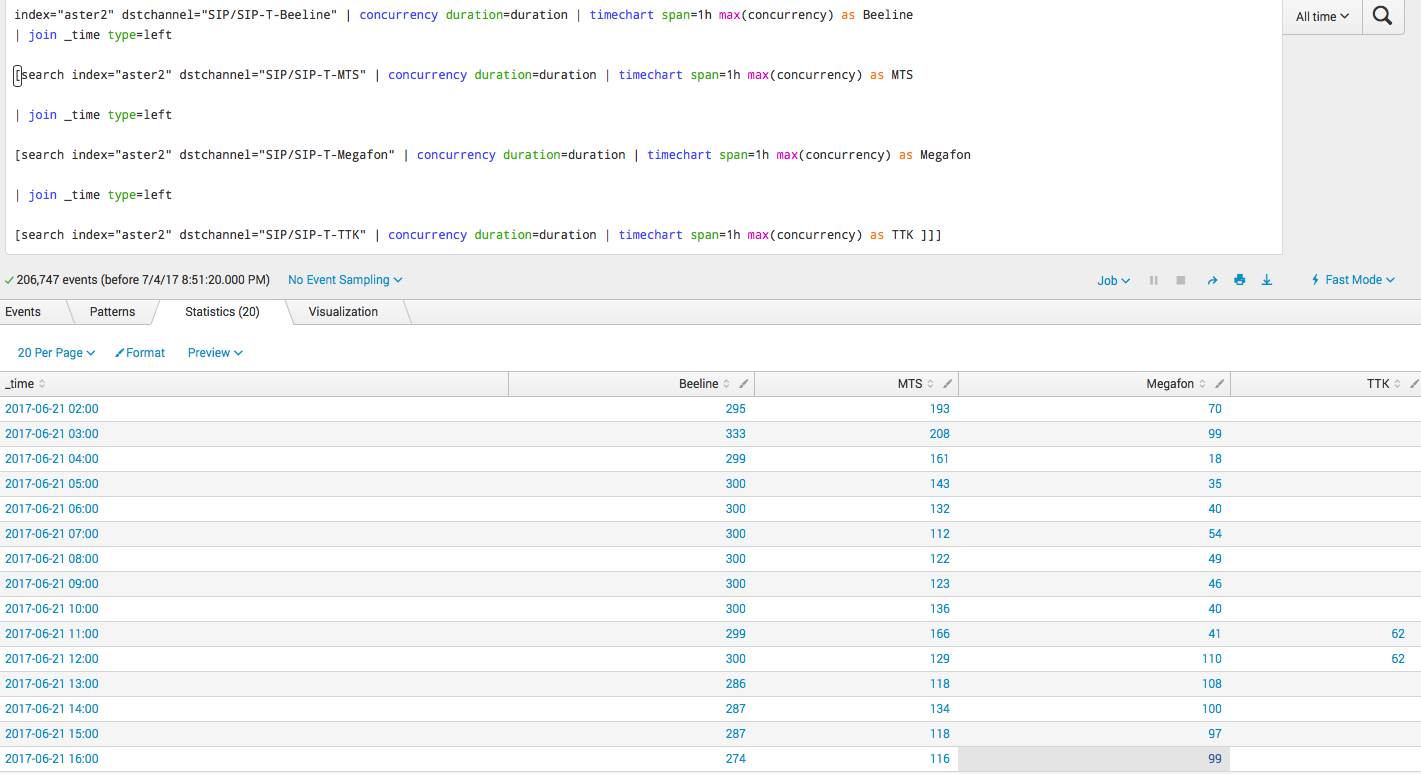
Заключение
Мы рады ответить на все ваши вопросы и комментарии по данной теме. Также, если вас интересует что-то конкретно в этой области, или в области анализа машинных данных в целом — мы готовы доработать существующие решения для вас, под вашу конкретную задачу. Для этого можете написать об этом в комментариях или просто отправить нам запрос через форму на нашем сайте.
Комментарии (11)

Emily_Rose
05.07.2017 11:56Несколько лет назад написали приложение Thirdlane Free Metrics для Splunk, парсит Asterisk queue_log и CDR, к сожалению популярностю не пользуеться, по непонятным мне причинам.

AlexKulakov
05.07.2017 12:08Надо было в названии приложения указать «Asterisk» — тогда бы больше шансов на успех.

Ovoshlook
05.07.2017 13:56Правильно ли я понимаю что Splunk можно прикрутить к любой БД для аналитики данных?
И как на счет встраивоемости дашборда как виджета в существующие проекты?
AlexKulakov
05.07.2017 15:52- Да, правильно. Но помимо БД он нас самом деле может забирать данные практически из любого источника.
Об этом мы писали здесь.
- Да, это тоже можно сделать.
- Да, правильно. Но помимо БД он нас самом деле может забирать данные практически из любого источника.

xmaster83
06.07.2017 09:07+1Ну не знаю, товарищи, лучше для аналитика чем кастомный sql, пока не придумали, сколько систем не ставили всеровно в конце аналитики любят кастомные запросы подходят и озвучивают свои хотелки, и неодна готовая система еще может этого.
AlexKulakov
06.07.2017 10:19Splunk это не коробочное решение с уже зашитой аналитикой, это скорее инструмент для анализа данных. Он как раз и позволяет реализовать все хотелки аналитиков, посредством своего языка запросов SPL. Посмотрите наши предыдущие статьи, они как раз про SPL, и все станет несколько прозрачнее.
И если в данной статье мы говорим про CDR и так или иначе структурированные данные, то сравнение с sql конечно возможно. Но если мы перейдем в пространство неструктурированных данных, то для sql все становиться намного сложнее.

Debug_all
06.07.2017 10:21А как бы Вы оценили плюсы и минусы реализации обозначенной в статье задачи на ELK относительно Splunk?
Одному_моему_другуприснилосьдоводилось делать очень похожее решение как раз на ELK: CDR'ы по SFTP с CUCM грузятся на сервер, разбираются в Logstash и складываются в индексы на Elasticsearch. На Kibana собраны дашборды под возникшие нужды. Большинство визуализаций создается в пару кликов. Дашборды можно генерировать динамически, есть возможность их вставки через iframe в сторонние ресурсы.
Плюс базовый ELK бесплатен без ограничений на объемы информации и количество нод в кластере (в противовес стоимости on-premise железа у Elastic, если мне не изменяет память, есть и SaaS-опции).
AlexKulakov
06.07.2017 10:31Ключевое различие ELK и Splunk в том, что ELK — это open source, а Splunk — это проприетарный продукт. Отсюда растёт ряд следствий и различий и их достаточно много.
Что касается непосредственно этой задачи, то можно сказать следующее: так как в большинстве случаев можно обойтись бесплатной версией Splunk — вопрос о стоимости лицензии не стоит. Остается стоимость внедрения и стоимость обслуживания (наличие специалистов, кто будет работать с системой).
Стоимость внедрения Splunk, даже если мы говорим не про деньги а просто про время, намного ниже. Обучиться базовому функционалу неподготовленному пользователю тоже намного быстрее. Тот функционал, который Вы описываете в ELK, так или иначе доступен, а главное все это находится в одном продукте.

yellowknife
11.07.2017 19:19Мы себе в контору делали аналогичный функционал. Но у нас много разных АТСок, помимо астерисков пришлось иметь дело с РТУ, форматом bis+ и т.д. Поэтому поступили следующим образом. Все АТСки скидывают cdr-ы на ftp. Далее наше решение (рабочее название «СКИТ.АТС») забирает логи, по маске названия файла привязывает их к конкретной АТС и парсит. В остальном те же задачи и та же аналитика.
apilichev
Спасибо за статью. А не подскажите, для этого анализа нужна платная лицензия? На сколько большие логи? Для компании из 100 человек хватит 500Мб в день или какое там ограничение у бесплатной версии Splunk?
AlexKulakov
Да, так как CDR весят не так уж и много — за частую можно поместиться в бесплатную версию.