
В данной статье я расскажу историю о том, как решал конкурс ML Boot Camp V “Предсказание сердечно-сосудистых заболеваний” и занял в нём второе место.
Постановка задачи и данные
Данные содержали 100 000 пациентов, из которых 70% были в обучающей выборке, 10% для публичного лидерборда (public) и финальных 20% (private), на которых и определялся результат соревнования. Данные представляли собой результат врачебного осмотра пациентов, на основании которого нужно было предсказать, есть ли у пациента сердечно-сосудистое заболевание (ССЗ) или нет (данная информация была доступна для 70% и нужно было предсказать вероятность ССЗ для оставшихся 30%). Другими словами – это классическая задача бинарной классификации. Метрика качества – log loss.
Результат врачебного осмотра состоял из 11 признаков:
- Общие – возраст, пол, рост, вес
- Объективные – верхнее и нижнее давление, уровень холестерола (3 категории: норма, выше нормы) и глюкозы в крови (также 3 категории).
- Субъективные – курение, алкоголь, активный образ жизни (бинарные признаки)
Так как субъективные признаки были основаны на основании ответов пациентов (могут быть недостоверными), организаторы конкурса скрыли 10% каждого из субъективных признаков в тестовых данных. Выборка была сбалансирована. Рост, вес, верхнее и нижнее давление нуждались в чистке, так как содержали опечатки.
Кросс-валидация
Первый важный момент – это правильная кросс-валидация, так как тестовые данные имели пропущенные данные в полях smoke, alco, active. Поэтому, в валидационной выборке 10% данных полей тоже были скрыты. Используя 7 фолдов кросс-валидации (CV) с изменённым валидационным множеством, я рассмотрел несколько различных стратегий улучшения предсказаний на smoke, alco, active:
- Оставить данные в обучении как есть (в валидации 10% пропущенных значений в smoke, alco, active). Данный подход требует алгоритмы, умеющие обрабатывать пропущенные значения (NaN), например — XGBoost.
- Скрыть в обучении 10%, чтобы обучающая выборка больше походила на валидацию. Данный подход также требует алгоритмы, умеющие работать с NaN.
- Предсказать NaN в валидации на трёх обученных классификаторах
- Заменить признаки smoke, alco,active на предсказанные вероятности.
Также была рассмотрена стратегия взвешивания обучающих примеров по близости к валидации\тестовым данным, которая, однако, не давала прироста ввиду одинакового распределения train-test.
Скрытие в обучении почти всегда показывало лучшие результаты CV, причём оптимальная доля скрытых значений в обучении тоже получалась 10%.
Хотелось бы добавить, что если использовать стандартную кросс-валидацию без скрытия значений в валидации, то CV получался лучше, однако завышенным, так как тестовые данные в данном случае не похожи на локальную валидацию.
Корреляция с лидербордом
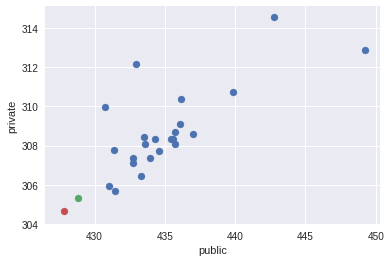
Интересный вопрос, который всегда волнует участников, это корреляция между CV и тестовыми данными. Уже имея полные данные после завершения конкурса (ссылка), я провёл небольшой анализ данной корреляции. Почти для всех сабмитов я записывал в описание результаты CV. Имея также результат на public и private, построим попарные графики сабмитов для значений CV, public, private (Так как все значения logloss начинаются на 0.5, для наглядности я опустил первые цифры, например 370 – это 0.5370, а 427.78 – 0.542778):

Чтобы получить численную оценку корреляции, я выбрал коэффициент Спирмана (другие тоже подойдут, но в данном случае важна именно монотонная зависимость).
| Spearman rho | CV | Public | Private |
|---|---|---|---|
| CV | 1 | 0.723 | 0.915 |
| Public | - | 1 | 0.643 |
| Private | - | - | 1 |
Можно сделать вывод, что введённая в предыдущей секции кросс-валидация хорошо коррелировала с private для моих сабмитов (в течении всего конкурса), когда как корреляция public с CV или private слабая.
Небольшие замечания: не ко всем сабмитам я подписывал результат CV, причём среди данных CV имеются результаты с не самыми лучшими стратегиями для работы с NaN (но подавляющее большинство с лучшей стратегией, описанной в предыдущей секции). Также, на данных графиках не присутствуют два моих финальных сабмита, о которых я расскажу далее. Их я изобразил отдельно в пространстве public-private красной и зелёной точкой.
Модели
В течении данного конкурса я использовал следующие модели с соответствующими библиотеками:
- Regularized Gradient Boosting (библиотека XGBoost) – основная модель, на которую я опирался, так как в моих экспериментах показывала лучшие результаты. Также большинство усреднений было построено только на нескольких xgb.
- Neural Networks (библиотека Keras) – экспериментировал с feed forward networks, autoencoders, но не получалось побить свой baseline от xgb, даже в усреднении.
- Различные sklearn модели, которые участвовали в усреднении с xgb – RF, ExtraTrees, и т.д.
- Стекинг (библиотека brew) – не получалось улучшить baseline усреднения нескольких различных xgb.
Поэксперементировав с различными моделями, и получая лучшие результаты путём смешивания 2-3 xgb (кросс-валидация занимала 3-7 минут), я решил сконцентрироваться больше на чистке данных, преобразовании признаков и тщательном тюнинге 1-5 различных множеств гиперпараметров xgb.
Гиперпараметры я попробовал искать с помощью Байесовской оптимизации (библиотека bayes_opt), но в основном опирался на случайный поиск, который служил инициализацией для Баейсовской оптимизации. Также, помимо банального оптимального количества деревьев, после такого поиска я старался попеременно подтягивать параметры (в основном регуляризационные параметры деревьев min_child_weight и reg_lambda) — метод, который некоторые называют graduate student descent.
Чистка данных I
Первый вариант чистки данных, вариант которого в той или иной мере реализовывали участники, состоял в простом применении правил на обработку выбросов:
- Для давлений вида 12000 и 1200 – разделить на 100 и 10
- Домножить на 10 и 100 для давлений вида 10 и 1
- Вес вида 25 заменить на 125
- Рост вида 70 заменить на 170
- Если верхнее давление меньше нижнего, поменять местами
- Если нижнее давление равно 0, то заменить на верхнее минус 40
- и т.д.
Используя несколько простых правил для очистки, я смог добиться в среднем CV ~0.5375 и public ~0.5435, что показывало совсем средненький результат.
На рисунках изображён последовательный процесс обработки экстремальных значений и выбросов с приходом к очищенным значениям верхнего и нижнего давления на последнем изображении.


В моих экспериментах удаление выбросов не приводило к улучшению CV.
Чистка данных II
Предыдущая чистка данных вполне адекватная, однако, после долгих попыток улучшения моделей я её пересмотрел более тщательно, что позволило значительно улучшить качество. Последующие модели с данной чисткой показали прирост CV до ~0.5370 (с ~0.5375), public до ~0.5431 (с ~0.5435).
Основная идея – к каждому правилу есть исключение. Мой процесс поиска таких исключений был довольно рутинным – для небольшой группы (например, людей с с верхним давлением между 1100 и 2000) я смотрел на значения в train и test. Для большинства, конечно, правило “разделить на 10” срабатывало, но всегда существовали исключения. Данные исключения было проще изменить отдельно для примеров, чем искать общую логику исключений. Например, такие выбивающиеся из общей группы давления, как 1211 и 1620, я заменял на 120 и 160.
В некоторых случаях правильно обработать исключения удавалось, лишь включая информацию с других полей (например, по связке верхнего и нижнего давления). Таким образом, давления вида 1/1099 и 1/2088 заменялись на 110/90 и 120/80, а 14900/90 заменялись на 140/90. Самые сложные случаи были, например, при замене давления 585 на 85, 701 на 170, 401 на 140.
В сложных менее однозначных случаях я проверял, насколько исправления похожи на обучение и тест. Например, случай 13/0 я заменял на 130/80, так как он самый вероятный. Для исключений из обучающей выборки мне также помогало знание поля ССЗ.
Очень важный момент – это различить шум от сигнала, в данном случае – опечатку от настоящих аномальных значений. Например, после чистки у меня осталась небольшая группа людей с давлением вида 150/60 (имеют ССЗ в обучении, их давление вписывается в одну из категорий ССЗ) или ростом около 90 см с небольшим весом.
Добавлю, что основной прирост дала очистка давления, тогда как с ростом и весом было много неоднозначностей (обработка роста-веса тоже основана на поиске исключений с дальнейшим применением общего правила).
Пользуясь выложенным полным датасетом после соревнования, получаем, что данная очистка затронула 1379 объектов в обучении (1.97%), 194 в public (1.94%), 402 в private (2.01%). Конечно, исправления аномальных значений для 2% датасета была не идеальной и можно её сделать лучше, однако даже в этом случае наблюдался самый большой прирост CV. Стоит отметить только, что после чистки или работы с признаками необходимо находить более оптимальные гиперпараметры алгоритмов.
Работа с признаками и их дискретизация
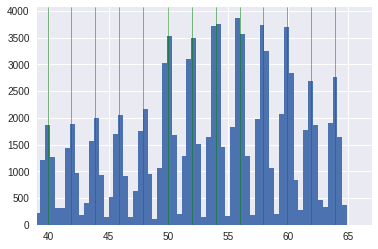
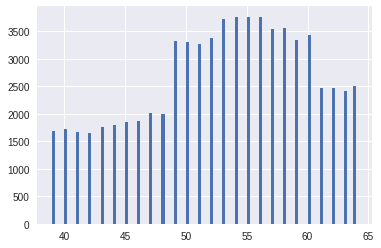
Изначально возраст был поделён на 365.25, чтобы работать с годами. Распределение возраста было периодичным, где пациентов с чётными годами было гораздо больше. Возраст представлял собой гауссовскую смесь с 13 центрами в чётных годах. Если просто округлить по годам, то улучшалось CV в четвёртом знаке на ~1-2 единицы по сравнению с исходным возрастом. На рисунках показан переход от исходного возраста к округлённому до года.

Однако, я также использовал другую дискретизацию с целью улучшения распределения по годам, которую и включил в последнюю простую модель. Вершины распределений в гауссовской смеси были найдены с помощью гауссовского процесса, и «год» определился как половина гауссовского распределения (справа и слева). Таким образом новое распределение по «годам» выглядело более равномерным. На рисунках показан переход от исходного возраста (с найденными вершинами гауссовской смеси) к новому распределнию по «годам»
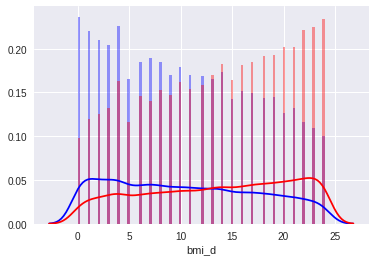
BMI ( индекс массы тела = ) появлялся первым в важности признаков. Добавление исходного BMI улучшало результат, однако, наибольшего улучшения модели достигли после дискретизации его значений. Порог дискретизации был выбран на основании квартилей, а количество определялось на основании cv, визуальной валидации распределений. На рисунках показан переход от исходного BMI к дискретизированному BMI.

Аналогично, к росту и весу была применена дискретизация с малым количеством категорий, а давление и пульс были округлены c точностью до 5.
Поиск новых признаков и их отбор производился вручную. Лишь небольшое количество новых признаков смогли улучшить CV, причём все они показывали относительно небольшой прирост:
- Pulse pressure — разница между верхним и нижним давлением
- Нормальное ли давление (85 <= ap_hi <= 125 & 55 <= ap_lo <= 85)
- Последняя цифра в давлении до округления + перестановка по вероятности ССЗ
- Аналог чётности года (age — (age/2).round()*2) > 0
Итоговую важность признаков (с дискретизацией) для одной модели xgb можно увидеть на графике:
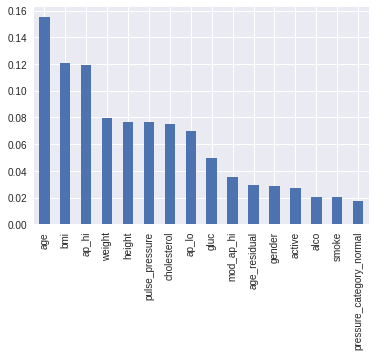
За час до окончания у меня была довольно простая модель из 2 xgb с использованием последней чистки данных и дискретизации признаков. Код доступен на github ( показывал CV 0.5370, public 0.5431, private 0.530569 — тоже 2 место).
Последний час соревнования
Имея усреднения двух или трёх xgb на последней предобработке данных, я решил попробовать усреднить результаты последних моделей с некоторыми предыдущими (различные преобразования и набор признаков, чистка данных, модели) и на удивление, усреднение с весами 8 предыдущих предсказаний дало улучшение на public с 0.5430-31 до 0.54288. Стратегия с весами была зафиксирована сразу — обратно пропорционально округлённой 4й цифре на public (к примеру, у 0.5431 вес 1, 0.5432 — 1/2, 0.5433 — 1/3), что вполне хорошо коррелировало с тем, что модели с последней чисткой данных показывали также лучшие значения CV. Эти 8 предсказаний были получены с помощью одного, двух, трёх (большинство), а также 9 различных моделей xgb. Все, кроме одной, были на основании последней чистки данных, различаясь набором новых признаков, дискретизацией или её отсутствием, гиперпараметрами, а также стратегией с NaN. Далее, с той же схемой весов добавление сабмитов похуже (с весами меньше 1/4) помогло улучшить public до 0.542778 (всего 17 предсказаний, описание можно найти на github).
Конечно же, по-хорошему необходимо было хранить результаты предыдущих кросс-валидаций, чтобы правильно оценить качество такого усреднения. Могло ли быть здесь переобучение? Руководствуясь тем, что более 90% веса в усреднении было у моделей со стабильными CV 0.5370-0.5371, можно было ожидать, что модели послабее могли помочь в экстремальных ошибках лучших простых моделей, однако в целом предсказания мало отличались от лучших моделей. Учитывая также, что public значительно улучшился, я выбрал в качестве финальных именно два этих усреднения, которое и вылилось в лучшую модель, показавшую 2 место с private 0.5304688. Можно заметить, что простое решение, описанное выше, и которое было базой в данном усреднении, показало бы тоже 2 место, однако оно менее стабильно.
Выученные уроки
Финальное усреднение показало, что использование комбинации относительно простых моделей на разных признаках/предобработке может дать лучшие результаты, чем использование множества моделей на одних и тех же данных. К сожалению, в течении конкурса я искал именно одну «идеальную» очистку данных, одно преобразование признаков и т.д.
Также, для себя я заметил, что кроме частых коммитов в git, желательно хранить результаты кросс-валидации предыдущих моделей, чтобы можно было быстро оценить, смешивание каких различных признаков\предобработки\моделей даёт наибольший прирост. Однако же, исключения к правилам бывают, например, если остаётся лишь час до конца конкурса.
Судя по результатам других участников, мне необходимо было продолжить свои эксперименты с включением нейронных сетей, стекингом. Они, однако, присутствовали у меня в финальном сабмите, но лишь косвенно с незначительным весом.
В заключение, выступление автора доступно здесь, а презентация также на github.