
Я очень хорошо помню свои ощущения от чтения классической ныне работы [1] где исследователи Google обучили seq2seq нейросеть генерировать ответы, используя огромную базу субтитров к фильмам. Возможности казались неограниченными:
Ч: Меня зовут Джон, как меня зовут?
Н: Джон
Ч: Сколько ног у собаки?
Н: Четыре
Ч: Какого цвета небо?
Н: Голубого
Ч: Есть ли у кошки хвост?
Н: Да
Ч: Есть ли у кошки крылья?
Н: Нет
Диалоги переведены мной на русский. Ч — человек, Н- нейросеть
Разве не удивительно, что сеть, без всяких правил, на базе очень зашумленных данных умеет правильно отвечать на подобные вопросы (которые не встречаются в самих данных в таких формулировках)? Но вскоре, у такого подхода обнаружился ряд проблем:
- Невозможность обновлять долгосрочную память. Например, “Меня зовут Джон”, будет вскоре забыто, как только пропадет из контекста. Из этого следует невозможность запоминать новые факты и как-то с ними оперировать.
- Невозможность получать информацию из внешних источников
- Невозможность перенести знания на другие тематики. Нужно очень много данных для обучения новой модели.
- Невозможность производить какие-либо действия
- Тенденция давать короткие /частые ответы (например, на любой вопрос отвечать словом “да”)
В результате, большинство практических систем сейчас все еще базируется на заранее заготовленных ответах и ранжировании вариантов (с помощью правил и машинного обучения), а идея синтезировать ответы с нуля, по словам, отошла на второй план. Даже Google Smart Reply теперь использует ранжирование [2], хотя и с помощью нейросетей. Ранжирование же может быть эффективным и без понимания смысла — только за счет синтаксических преобразований и простых правил [7]. В наших опытах с ранжированием, даже если оно осуществляется нейросетью, поверхностный анализ доминирует, и только очень большие нейросети демонстрируют только некоторые зачатки общетематических знаний [8].
Также прагматично работают все популярные чат-боты, виртуальные ассистенты и тому подобные программы. Siri и Cortana кажуться высокоинтеллектуальными системами только за счет того, что каждая тематика, которую они понимают, тщательно настраивается вручную [6], что позволяет добиться высокого качества ответов. Но, с другой стороны, по данным некоторых исследований, при всех огромных усилиях, вложенных компаниями в разработку этих помощников, реально их применяют только 13% пользователей телефонов (при этом когда-либо пробовали, но отказались от использования 46% [11] ). К тому же, это технологии известные, поставленные на поток, и заниматься ими скучно. Хочется чего-то потенциально более интеллектуального, но одновременно, не совсем оторванного от практики.
Много лет назад, при чтении различных фантастических романов, мне понравилась идея “Планирующей машины”
Через мгновение от Планирующей Машины пришел ответ — всего одна буква: «П». Это означало, что Машина приняла сообщение, поняла его и ввела в банк памяти. Приказы последуют.
Зазвенел сигнал телетайпа. Райленд прочел сообщение:
«Действия. Проследовать к поезду 667, путь 6, купе 93».
Рифы космоса. Фредерик Пол и Джек Уильямсон, 1964
Да, в романах, такая машина часто персонаж отрицательный. Но, как удобно было бы иметь подобную планирующую машину в фирме, чтобы она говорила кому и что делать. А также решала разные вопросы самостоятельно.
Можно, конечно, запрограммировать каждую подобную функцию в отдельности. Этим путем идут разработчики интеллектуальных функций в существующих CRM/BPM системах. Но тем самым мы лишим систему гибкости и обречем штат программистов на постоянное дописывание и переписывание этих функций. Можно ли пойти другим путем?
Основным направлением для преодоления вышеописанных недостатков является снабжение нейросети внешней памятью. Память эта бывает в основном двух видов — дифференцируемая, например в [3] и неифференцируемая. Дифференцируемая память предполагает, что механизмы записи и чтения из памяти сами являются нейросетями и обучаются совместно. Для моделирования диалога в основном используется вариант, где обучается только механизм чтения, а механизм записи содержит жестко запрограммированные элементы (например n слотов памяти, и запись идет как в стек) [4]. Такой механизм сложно масштабировать, т.к. чтобы найти элемент в памяти для каждого элемента надо выполнить вычисления с помощью нейросети. Кроме того, содержимое такой памяти невозможно интерпретировать, редактировать вручную, оно может быть не точным, что существенно осложняет использование системы на практике.
В идеале мы хотим, чтобы нейросеть работала с чем-то, напоминающим традиционную базу данных. Поэтому обратили внимание на работы, связанные с вопросно-ответными системами, сопрягаемыми с большими базами знаний. В частности, мне показалась интересной статья [6], где нейросеть генерирует запросы к графовой базе данных на языке LISP на основании вопросов, задаваемых пользователями. Т.е. нейросеть не прямо обращается к данным, а создает небольшую программу, выполнение которой приводит к получению нужного ответа.
Графовое представление знаний в качестве внешней памяти для нейросетей вообще является достаточно популярным решением, поскольку в него с одной стороны легче уложить разнородные знания о мире, а с другой считается, что эта схема напоминает способ хранения информации в головном мозге человека.
Применительно к нашей задаче, получается следующая схема:
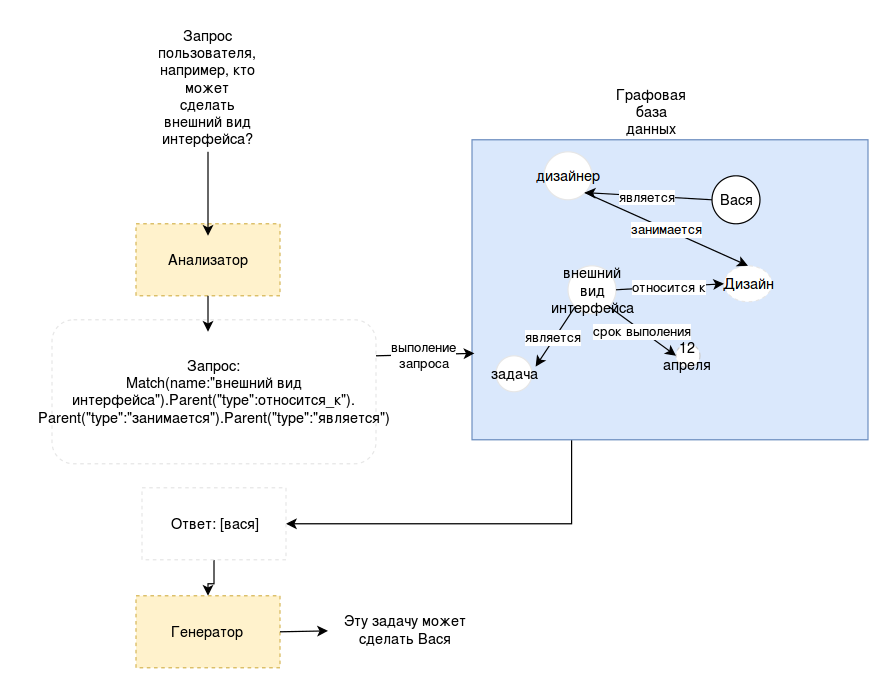
Конечно, мы имеем дело с более сложной проблемой. Во-первых, чтобы система работала, нейросеть должна уметь не только извлекать информацию, но и записывать новые сведения. Очевидно, что одну и ту информацию можно записать совершенно разными способами и, если мы хотим, чтобы система была гибкой, то не можем фиксировать все виды соотношений заранее. А значит, что программа должны будет сама выбирать правильный способ записи информации, и уметь потом достать то, что записала.
Кроме того, на практике возникнут и другие вопросы:
- Скорость работы. Достаточно ли эффективен такой механизм? Программисты тратят достаточно большие усилия, чтобы спроектировать эффективную структуру базы данных. Что будет, если данные будет организовывать нейросеть?
- Что случится, после нескольких месяцев/лет работы? Существует риск накопления неверной, бессмысленной и плохо организованной информации, которая замусорит систему и сделает работу невозможной.
- Безопасность. Не всем можно сообщать все, и не всем позволено изменять данные. Не вся сообщаемая системе информация может быть достоверной.
- Отсутствие обучающей выборки — где брать данные для обучения нейросети?
- Другие подводные камни
Ясно, что ответить на все вопросы сразу не получится, поэтому самым правильным подходом является постепенная реализация.
На первом этапе понадобиться графовая база данных и какой-то язык для выполнения запросов к ней. Существует довольно много реализаций графовых баз и несколько популярных языков, таких как SPARQL, Cypher и другие. Ясно, что структура языка будет сильно влиять на способность нейросети генерировать запросы на нем, поэтому мы решили сделать собственную надстройку над существующими движками графовых баз данных, включающую специальный язык, который можно будет в дальнейшим оптимизировать. Чтобы упростить разработку, изначально язык был реализован с помощью классов Python и представлял собой фактически подмножество Python
Пример (очень простой):
| Текст | Запрос |
| На склад поступило три подушки | MatchOne({«type»:«склад»}).Add(«name»:«подушки»,«количество»:«3») |
| есть ли на складе подушки ? | MatchOne({«type»:«склад»}).child({«имя»:«подушки»}).NotEmpty( ) |
Обратите внимание, язык описывает как-бы процесс навигации по графу. Есть другой способ посмотреть на тоже самое: представьте, что каждый узел в графе это отдельный нейрон. На вход ему приходит некоторая информация — вектор активации входных нейронов и вектор истории предыдущих активаций. Нейрон работает как классификатор — он выбирает, по какому пути (из имеющихся соединений) пойдет процесс дальше. Это гораздо больше похоже на процесс, который реально может происходить в мозге человека [9,10], по крайней мере на некоторые из существующих теорий работы памяти.
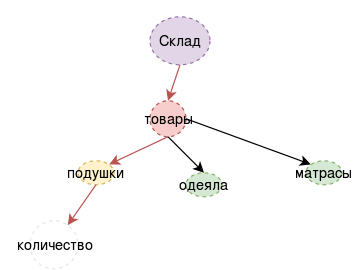
В примерах запросов использована модельная тематика товаров на складе. Для начала мы сделали некоторую выборку диалогов вручную, и прописали для них соответствующие запросы. Целью было убедиться, что язык запросов и схема в целом охватывает достаточное разнообразие случаев. Но, очень быстро, стало понятно, что ограниченный модельный мир не позволяет проверить все аспекты подхода. В действительности, работ в которых предложены системы, работающие на модельных ситуациях очень много, но непонятно, как это все транслировать в практику. Да и сочинять запросы вручную не очень продуктивное занятие.
Поэтому, мы решили реализовать всю схему в модельной системе, заменив, временно, нейросеть, на систему правил. Такой подход вполне разумен, поскольку позволяет отладить работу важных компонентов, не утонув сразу в сложностях проблемы в целом, и при этом избежать “игрушечных” модельных задач.
В качестве предмета приложения мы выбрали систему управления проектами (с прицелом на получение когда-нибудь “планирующей машины”). Как выглядел процесс внедрения с точки зрения использования системы, можно прочитать в предыдущей статье (эмпирически, мы узнали кое-что интересное о том, насколько полезен голосовой интерфейс и как правильно организовывать работу над проектами, но это сейчас не основная тема повествования).
Что касается главной схемы вещей, то приобретенный опыт оказался весьма важным. Главные изменения коснулись организации поиска и введению краткосрочной памяти.
Для процесса диалога (что известно давно) очень важен контекст беседы. В использовании нашей системы контекст оказался абсолютно необходимым. Схема с одним большим хранилищем данных возлагает отслеживание полностью на “анализатор”. Для правил эта задача была непосильной, и, для нейросетей, как известно из других исследований, она тоже сложна. Явное представление краткосрочной внешней памяти является сейчас распространенным подходом в диалоговых системах на базе нейросетей [4], и к тому же позволяет показывать содержимое рабочего контекста пользователю, что весьма важно. Поэтому в схеме появился дополнительный блок, хранящий узлы графа, к которым происходило недавнее обращение (либо недавно созданные).
Далее, на практике большинство узлов получало длинные названия (например, названия задач). Сопоставление задач по точному соответствию перестало быть эффективным, поэтому каждый узел графа был снабжен векторным представлением (для начала попробовали сумку слов и сумму word2vec векторов названия). Это позволило с одной стороны встроить в язык команды поиска по нечеткому совпадению, и с другой приблизило нас к структурам данных, которые используются в дифференцируемой внешней памяти. Это вид структуры ключ-значение, где ключ являются вектором, а значение — произвольного вида данные. Вектора значений могут быть обучаемыми, и также могут быть частью механизма адресации в нейронной модели внимания.
В целом, полученный набор компонентов оказался жизнеспособным и пригодным к применению в других проектах. Так что, дальше мы начали работать над заменой анализатора на правилах (который сильно ограничен в возможностях) на нейронную сеть, тем более, что определенный набор диалогов был накоплен в процессе внедрения версии на правилах. Однако, данная тема, похоже уже не укладывается в рамки одной статьи, так как текст уже получился довольно длинный, а про нейросеть придется написать еще как-минимум столько же. Поэтому, продолжение будет в нашем блоге одной из следующих статей, если, поднятая тема вызовет у читателей интерес.
- Vinyals, Oriol, and Quoc Le. «A neural conversational model.» arXiv preprint arXiv:1506.05869 (2015).
- Henderson, Matthew, et al. «Efficient Natural Language Response Suggestion for Smart Reply.» arXiv preprint arXiv:1705.00652 (2017).
- Kumar, Ankit, et al. «Ask me anything: Dynamic memory networks for natural language processing.» International Conference on Machine Learning. 2016.
- Chen, Yun-Nung, et al. «End-to-End Memory Networks with Knowledge Carryover for Multi-Turn Spoken Language Understanding.» INTERSPEECH. 2016.
- Liang, C., Berant, J., Le, Q., Forbus, K. D., & Lao, N.(2016). Neural symbolic machines: Learning semantic parsers on freebase with weak supervision. arXiv preprintarX iv:1611.0 0 020.
- Sarikaya, Ruhi, et al. «An overview of end-to-end language understanding and dialog management for personal digital assistants.» Spoken Language Technology Workshop (SLT), 2016 IEEE. IEEE, 2016.
- Ameixa, David, et al. «Luke, I am your father: dealing with out-of-domain requests by using movies subtitles.» International Conference on Intelligent Virtual Agents. Springer, Cham, 2014.
- Tarasov, D. S., and E. D. Izotova. «Common Sense Knowledge in Large Scale Neural Conversational Models.» International Conference on Neuroinformatics. Springer, Cham, 2017.
- Fuster,Joaquin M… «Network memory.» Trends in neurosciences 20.10 (1997): 451-459.
- Fuster, Joaquin M. «Cortex and memory: emergence of a new paradigm.» Cortex 21.11 (2009).
- Liao, S.-H. (2015). Awareness and Usage of Speech Technology. Masters thesis, Dept. Computer Science, University of Sheffield
Комментарии (24)
Sdima1357
12.10.2017 00:04«Техника со временем дойдет до такого совершенства, что человек сможет обойтись без самого себя.» С.Е.Лец

Alex_ME
12.10.2017 01:04+1Мои дилетантские рассуждения: чтобы уметь нормально "разговаривать", необходимо иметь понятийный аппарат. На мой взгляд как-то так:
- Различные понятия как-то кластеризуются в близкие и связанные по смыслу, связанные отношениями. Таких примеров много можно найти. Пример.
- Но этого недостаточно для полноценного понимания предметной области (в общем случае — объектов и явлений окружающего мира). Необходимо введение абстрактных понятий и отношений "абстракция — конкретная реализация".
- И аналогичные п.1 связи и кластеризация между абстракциями.
- И супер-абстракции абстракций, абстракции абстракций абстракций...

ServPonomarev
12.10.2017 07:59Если сеть умеет обращаться к внешнему хранилищу данных, то её легко дообучить на работу с онтологиями. А онтологии как раз и дадут сети понятийный аппарат. Разумеется, если сеть будет в состоянии этим аппаратом воспользоваться.

napa3um
12.10.2017 12:05«Теория фреймов для представления знаний», Марвин Минский. Вы переизобрели фреймы, являющиеся фундаментом самообучающихся экспертных систем уже как пол века (так же вам наверняка будет полезно взглянуть на язык программирования Prolog). Хотелось бы взглянуть на демонстрацию работы вашей системы, т.к. именно конкретные реализации и интересны («дьявол в мелочах»), а сама концепция не нова. И да, у Гугла примерно такое же «смысловое» ранжирование, они балансируют между автоматикой и ручным управлением.

Durham Автор
12.10.2017 17:24лет 12 назад делал на Prolog довольно объемное приложение. Была такая вещь, Visual Prolog 6.0. Не претендую на изобретение графовых баз данных, впрочем, в тексте есть ссылки на источники и существующие продукты. Я занимаюсь практическим вопросом, как собрать все вместе, и научить общаться с человеком, чтобы структура данных подстраивалась по мере необходимости, и работало это в реальной задаче.
napa3um
12.10.2017 17:46+1Да, уже пол века с разным успехом этим занимается куча людей, я лишь этим вас хотел удивить :). И не в изобретении графовых СУБД я вас «обвинил», они лишь инструмент, на котором вы, по сути, пытаетесь реализовать фреймовую модель хранения знаний. Просто теперь у вас есть возможность не переизобретать свой велосипед, а ознакомиться с проработанной концепцией Минского, в которой он уже наверняка порешал многие вопросы, с которыми вы боретесь (и с которыми ещё даже не столкнулись). У вас будет надёжная теоретическая основа, к которой вы уже сможете прикрутить свои более конкретизированные способы согласования фреймов, адекватные вашей реальной задаче (прикрутить, например, нейросетевые классификаторы, что вы, по сути, и пытаетесь сделать). Но, конечно, это IMHO, у вас свой путь :).
Alex_ME
12.10.2017 21:23Спасибо за литературу. На новизну я, разумеется, не претендовал и был более чем уверен, что такое есть. Про Prolog знаю, но никогда не доводилось с ним работать. Да и по поводу "дьявола в мелочах" полностью согласен.

anprs
12.10.2017 14:08Мои дилетантские рассуждения: на одну область знаний одна обученная сеть и на всех одна сеть-классификатор, которая решает какой сети (сетям) адресовать данный конкретный вопрос
napa3um
12.10.2017 15:19Так и делают. Вообще, искусственная нейросеть выглядит для обывателя как некая гомогенная каша нейронов, волшебным образом решающая задачи, однако на самом-самом деле нейросети — это просто некое семейство алгоритмов для решения вполне определённых математических операций (классификация, фильтрация, генерация, свёртка, т.п.), и без «ручного» дизайна архитектуры решения (включающей и способ обучения) под конкретную задачу не обойтись. Т.е., правильнее говорить о конкретной модели решения той или иной конкретной задачи, спроектированной человеком, в которой некоторые параметры подбираются статистически на базе обучающей выборки, и именно в этих местах в модель внедряют ту или иную нейросеть (классификатор или фильтратор, например), коэфициенты которой и подбираются в ходе обучения. Когда говорят «нейросеть от Гугла выиграла чемпиона в Го», то имеют ввиду целый каскад нейросетей с разными свойствами и способами обучения, являющиеся частями определённой созданной человеком модели «решателя Го». Т.е., это как сказать, что в Формуле-1 победил поршень двигателя внутреннего сгорания (если бы в информационном пространстве Формулы был хайп вокруг слова «поршень», как в теме ИТ хайп вокруг слова «нейросеть»)
Durham Автор
12.10.2017 17:26Это обычное решение. Но проблема в том, что всю иерархию классификаторов и тематических решателей приходиться собирать вручную, и это долго и нужен большой штат сотрудников.
LorDCA
15.10.2017 13:10Наверное вот это www.lucida.ai, очень сократит вам время. Там несколько сотен уже прописаных паттернов. И не проблема научить русскому языку.
Но если хотите продолжить копать в сторону строительства графов, то переходите к использованию datastax или janusGraph. Все остальные графовые базы очень медленные. Та же Neo4J, которая вроде по рейтингам показывает неплохие результаты, на кластере из 3 серверов выдает не более 1700 запросов в секунду.
Но мне кажется семантика это тупик. Во первых вы устанете подготавливать базу и связи. А во вторых вам придется подготовить еще диких размеров датасет для тренировки нс. Собственно ссылка на люсиду выше.
Да и не понятен алгоритм по которым сеть будет создавать новые правила.Durham Автор
15.10.2017 13:11Никак не могу понять. Пишешь статью, объясняешь, что нечто работает и работает хорошо. Сразу появляется много комментаторов, которые говорят, что нет, это невозможно. И предлагающих использовать XYZ вместо описанного. Ну в чем тут логика?
Мне не нужны шаблоны, ни сотни, ни тысячи, я от них как раз хочу избавится, о чем и идет речь в статье. Тем более зачем мне учить нечто говорить на русском с помощью паттернов, когда у меня есть решение, которое работает прекрасно без них? И наконец, я не готовлю ни базу ни связи, в статье идет речь о том, что связи формируются сами в процессе диалога.
И еще, разработанный язык обращений делает основную систему независимой от конкретной графовой базы данных, так что если какой-то выбранный движок окажется непригодным, или перестанет поддерживаться, очень легко перенести все на другой.LorDCA
15.10.2017 17:44Это очень легко понять как раз. Каждый на своей волне и любую входящую информацию расматривает с позиции знакомых ему паттернов.
Мне просто не ясно, у вас по тексту и нейросеть и графы и fuzzy logic. И совсем не ясно как это работает. Мне так видится, что согласно описаному вами, придется как минимум создавать словарик частей речи.
А на компанию товарищей выше можете не обращать внимания, они и в моей статье нагадили выше некуда.third112
15.10.2017 17:58А на компанию товарищей выше можете не обращать внимания, они и в моей статье нагадили выше некуда.
Скажите пожалуйста: в какой статье Вам нагадили?LorDCA
15.10.2017 18:04Тут.
third112
15.10.2017 18:15Большое спасибо. Моих комментариев там нет, поэтому продолжаю надеется, что уважаемый автор статьи ответит на мои вопросы выше.
LorDCA
15.10.2017 18:28Я не думаю что кто то сможет дать четкий ответ по времени подобных проектов или по конкретным обьемам. Я сужу по своему проекту, только за этот год было переписано с нуля 6 версий модели. Каждая версия докидывала неочевидных деталей. И максимум что удалось пока достичь, это обобщение одной обьемной книги примерно за 3 часа.
third112
15.10.2017 18:33Хотя бы нечеткий. Или удел подобных проектов чистый энтузиазм пока финансирование не кончится?
LorDCA
15.10.2017 18:51Мне сложно судить. Я сам себя финансирую и моему проекту уже больше 5 лет. Если рассматривать подобные проекты с точки зрения моей модели, то процесс не быстрый. Нужно обобщить очень большой обьем информации. Да и многие детали все равно выясняются только при попытках реализации.
third112
15.10.2017 18:56Можно ли сказать, что Вы потратили 5 человеко-лет или были перерывы на другие работы?
LorDCA
15.10.2017 19:09Конкретно на структуру способную создавать новые паттерны на основе имеющегося опыта наверное года два.
third112
15.10.2017 19:32В моем исходном вопросе цитата, где называются трудозатраты в десятки человеко-лет. Конечно, с 1977 г. прогресс ушел далеко вперед, но все же работа выглядит очень затратной по времени. Не опасаетесь ли Вы, что раньше завершения Вас обгонит, нпр., Гугл, который сейчас может потратить пару сотен или м.б. тысяч человеко-лет и закончить работу через год?
third112
Большое спасибо за интересную статью с переднего края работ по созданию ИИ.
Но не нашел ответа на вынесенный в заголовок вопрос.
В связи с этим вспоминается, что Вейценбаум позиционировал свою знаменитую Элизу (1966), как всего лишь имитатор ИИ. Но, просматривая старые журналы, нашел статью примерно 1960 г. (точной ссылки не у меня, к сожалению, не сохранилось) в нашем солидном научном журнале, где авторы утверждали, что к концу текущей пятилетки сделают программу, которая будет писать стихи не хуже Пушкина. Еще вспоминается следующая цитата:
Позвольте спросить: за сколько лет Вы рассчитываете закончить работу и сколько человеко-лет на это потратить?