
Чем будем пользоваться:
- расстояние Левенштейна и расстояние Дамерау-Левенштейна: оба представляют собой минимальное количество операций для преобразования одной строки в другую, отличаясь операциями — Левенштейн предложил операции вставки, удаления и замены одного символа, а Дамерау дополнил их операцией транспозиции, т.е. когда два соседних символа меняются местами; для MySQL были предложены следующие имплементации:
- запрос в стиле алгоритма Левенштейна, автор — Gordon Lesti
- пользовательская функция для вычисления расстояния Левенштейна, опубликованная в книге Get It Done With MySQL 5&Up (ред. Peter Brawley и Arthur Fuller), автор — Jason Rust
- пользовательская функция для вычисления расстояния Дамерау-Левенштейна, написанная на основе функции на Си, написанной Линусом Торвальдсом, автор — Diego Torres
- алгоритм Оливера: вычисляет похожесть двух строк
- в PHP представлен функцией similar_text
- метафон (metaphone): алгоритм индексирования слова по фонетическому принципу, работает только с буквами английского алфавита
- в PHP представлен функцией metaphone
- soundex и его PHP функция soundex: алгоритм устарел (был предложен в начале прошлого века), совершенно не похожие друг на друга слова получают одинаковые индексы
- всеми оставшимися алгоритмами, т.к. у PHP нет соответствующих им функций
Алгоритм нечёткого поиска
Очевидно, что нет смысла при каждом поиске вычислять расстояние Левенштейна между введённым словом и каждым словом из словаря в БД, т.к. это займёт много времени. Кстати, несколько лет назад на хабре был описан способ, в котором при каждом поиске весь словарь из БД загонялся в PHP-массив, транслитерировался, и дальше подбирались похожие слова, попеременно используя то функцию levenshtein, то metaphone, то similar_text, то две сразу. Решение предварительной быстрой фильтровки и последующего рафинирования найденных вариантов напрашивается само собой.
Таким образом, суть алгоритма нечёткого поиска может быть сведена к следующему:
- Вычислить метафон поискового запроса.
- Найти все слова в словаре в БД по метафону с расстоянием Левенштейна (или Дамерау-Левенштейна) < 2 символов.
- Если ничего не найдено — юзер сделал слишком много ошибок в слове, прекращаем мучить БД и пишем, что
юзер идёт в банюничего не найдено. - Если найдено 1 слово — возвращаем его.
- Если найдено > 1 слова — рафинируем: находим процент похожести поискового запроса с каждым найденным словом из словаря в БД; находим максимальный процент похожести; возвращаем все слова с этим процентом (на случай, если несколько слов будут иметь одинаковый процент, который окажется максимальным).
При каждом поиске необходимо будет рассчитывать расстояние Левенштейна. Для этого нужно найти самую быструю имплементацию алгоритма для MySQL.
Подготовка БД
Для всех тестов была выбрана база населённых пунктов, 4 года назад вытащенная из Вконтакте. Для тестов использовалась таблица городов, которая содержит более 2,2 миллионов записей, частично переведённых на 13 языков. Были оставлены только колонки с русским переводом, которые содержали много непереведённых названий. Также был сделан индекс по колонке city_id.
Следующим шагом было формирование метафона для каждого названия. Поскольку метафон рассчитывается только со строк, содержащих буквы английского алфавита, каждое название необходимо предварительно преобразовать: кириллицу транслитерировать, а латинские буквы, содержащие диакритические знаки, преобразовать в буквы английского алфавита.
Таким образом, PHP-код для добавления колонки метафонов выглядит следующим образом:
// отменяем ограничения по времени для выполнения скрипта
set_time_limit(0);
ini_set('max_execution_time', 0);
// пишем функцию получения метафона
function mtphn($s){
// определяем набор символов, которые нужно заменить
$from = ['а', 'б', 'в', 'г', 'д', 'е', 'ё', 'ж', 'з', 'и', 'й', 'к', 'л', 'м', 'н', 'о', 'п', 'р', 'с', 'т', 'у', 'ф', 'х', 'ц', 'ч', 'ш', 'щ', 'ъ', 'ы', 'ь', 'э', 'ю', 'я', 'a', 'a', '?', '?', '?', '?', '?', 'a', 'a', '?', '?', '?', '?', '?', 'a', 'a', '?', '?', '?', '?', 'a', '?', '?', 'a', 'a', '?', '?', 'a', '?', '?', '?', 'a', '?', '?', '?', '?', '?', '?', '?', '?', 'b', '?', 'c', 'c', 'c', '?', 'c', '?', 'c', '?', '?', '?', '?', 'd', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', 'd', '?', '?', '?', 'e', 'e', 'e', '?', '?', 'e', '?', '?', '?', '?', '?', '?', 'e', 'e', '?', '?', 'e', '?', '?', 'e', '?', '?', '?', 'e', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', 'g', 'g', 'g', 'g', 'g', '?', '?', '?', 'g', '?', '?', '?', '?', '?', '?', 'h', '?', '?', '?', '?', '?', '?', 'h', '?', '?', '?', 'i', 'i', 'i', 'i', 'i', '?', '?', '?', 'i', '?', '?', 'i', 'i', '?', '?', 'i', '?', '?', '?', '?', 'j', 'j', '?', '?', '?', '?', '?', '?', '?', 'k', 'k', '?', '?', '?', '?', '?', '?', '?', '?', '?', 'l', 'l', '?', 'l', 'l', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', 'l', '?', '?', '?', '?', '?', '?', '?', '?', '?', 'n', 'n', 'n', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', 'n', 'o', 'o', 'o', 'o', '?', '?', '?', '?', '?', 'o', '?', '?', '?', '?', 'o', '?', 'o', '?', 'o', '?', '?', '?', '?', '?', '?', '?', '?', '?', 'o', '?', '?', 'o', 'o', 'o', '?', 'o', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', 'r', 'r', 'r', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', 's', '?', 's', '?', 's', 's', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', 't', 't', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', 't', '?', 't', '?', '?', 'u', 'u', 'u', 'u', '?', 'u', 'u', 'u', 'u', 'u', '?', '?', 'u', '?', 'u', '?', '?', 'u', '?', '?', '?', '?', '?', '?', 'u', '?', 'u', '?', 'u', 'u', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', 'w', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', 'y', 'y', 'y', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', 'z', 'z', '?', '?', '?', 'z', '?', '?', '?', '?', '?', '?', '?', '?', '?' ];
// определяем набор символов, на которые нужно заменить
$to = ['a', 'b', 'v', 'g', 'd', 'e', 'yo', 'zh', 'z', 'i', 'y', 'k', 'l', 'm', 'n', 'o', 'p', 'r', 's', 't', 'u', 'f', 'h', 'ts', 'ch', 'sh', 'shch', '', 'y', '', 'e', 'yu', 'ya', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'b', 'b', 'b', 'b', 'b', 'b', 'b', 'b', 'c', 'c', 'c', 'c', 'c', 'c', 'c', 'c', 'c', 'c', 'c', 'd', 'd', 'd', 'd', 'd', 'd', 'd', 'd', 'd', 'd', 'd', 'd', 'd', 'd', 'd', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'f', 'f', 'f', 'f', 'f', 'g', 'g', 'g', 'g', 'g', 'g', 'g', 'g', 'g', 'g', 'g', 'g', 'g', 'h', 'h', 'h', 'h', 'h', 'h', 'h', 'h', 'h', 'h', 'h', 'h', 'h', 'h', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'i', 'j', 'j', 'j', 'j', 'j', 'j', 'j', 'j', 'k', 'k', 'k', 'k', 'k', 'k', 'k', 'k', 'k', 'k', 'k', 'k', 'l', 'l', 'l', 'l', 'l', 'l', 'l', 'l', 'l', 'l', 'l', 'l', 'l', 'l', 'l', 'l', 'l', 'l', 'm', 'm', 'm', 'm', 'm', 'm', 'm', 'm', 'n', 'n', 'n', 'n', 'n', 'n', 'n', 'n', 'n', 'n', 'n', 'n', 'n', 'n', 'n', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'o', 'p', 'p', 'p', 'p', 'p', 'p', 'p', 'p', 'p', 'q', 'q', 'q', 'q', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 'r', 's', 's', 's', 's', 's', 's', 's', 's', 's', 's', 's', 's', 's', 's', 's', 's', 's', 's', 's', 't', 't', 't', 't', 't', 't', 't', 't', 't', 't', 't', 't', 't', 't', 't', 't', 't', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'u', 'v', 'v', 'v', 'v', 'v', 'w', 'w', 'w', 'w', 'w', 'w', 'w', 'w', 'w', 'x', 'x', 'x', 'x', 'y', 'y', 'y', 'y', 'y', 'y', 'y', 'y', 'y', 'y', 'y', 'y', 'y', 'y', 'z', 'z', 'z', 'z', 'z', 'z', 'z', 'z', 'z', 'z', 'z', 'z', 'z', 'z', 'ss'];
// переводим в нижний регистр и делаем замены
return metaphone( str_replace($from, $to, mb_strtolower($s)) );
}
// устанавливаем соединение с БД
$conn = mysqli_connect('localhost','root','','test') or die(mysqli_error($conn));
// добавляем в таблицу колонку для метафона
mysqli_query($conn, "ALTER TABLE _cities ADD COLUMN metaphone VARCHAR(30) DEFAULT NULL");
// получаем все названия и их id
$q = mysqli_query($conn, "SELECT city_id, title_ru FROM _cities");
while ($row = mysqli_fetch_assoc($q))
// находим метафон и записываем его в таблицу
mysqli_query($conn, "UPDATE _cities
SET metaphone='".mtphn($row['title_ru'])."'
WHERE city_id=".$row['city_id']);
mysqli_close($conn);
// в конце показываем сколько секунд выполнялся скрипт
echo 'Готово. Скрипт выполнялся '.( microtime(true) - $_SERVER["REQUEST_TIME_FLOAT"] ).' сек.';
Для 2 246 813 строк расчёт метафона и его вставка заняли ~38 минут.
Также был сделан индекс по колонке metaphone, т.к. дальнейшие операции поиска будут происходить только в ней.
Выбираем имплементацию расстояния Левенштейна для MySQL
Как было отмечено раннее, на быстроту будут проверяться три имплементации — запрос Лести, функция Раста и функция Торреса.
Для тестов будут использоваться 5 слов (а точнее, их ошибочное написание), 3 из них на кириллице, и 2 на латинице:
| № | Правильное написание | Его метафон | Неправильное написание | Его метафон | Левенштейн метафонов |
| 1. | Александровск-Сахалинский | ALKSNTRFSKSHLNSK | Аликсандравск-саголинзкий | ALKSNTRFSKSKLNSK | 1 |
| 2. | Семикаракорск | SMKRKRSK | Семикораковск | SMKRKFSK | 1 |
| 3. | Чаренцаван | XRNTSFN | Черенцева | XRNTSF | 1 |
| 4. | Bounounbougoula | BNNBKL | Bonunboguva | BNNBKF | 1 |
| 5. | Kampong Tenaki Kawang | KMPNKTNKKWNK | Kampontenaki Kavang | KMPNTNKKFNK | 2 |
Запрос Лести
Первый вариант — самый примитивный из всех трёх: здесь за основу взят принцип расстояния Левенштейна (операции вставки, удаления и замены), который имитируется в SQL-запросе, используя большое количество операторов LIKE. Если строка (слово) состоит из символов (букв), количество операторов LIKE при поиске расстояния Левенштейна в 1 символ будет равно (или при поиске расстояния Левенштейна < 2 символов).
В конце статьи автор предлагает PHP-функцию для автоматизации составления таких SQL-запросов. Эта функция изменена применительно для нашего поиска по метафонам, но принцип оставлен тот же:
// название с ошибками
$input = 'Семикораковск';
// получаем его метафон
$input_m = mtphn($input);
// создаём массив, куда будем генерировать варианты LIKE для SQL-запроса
// и сразу добавляем ему первый вариант
$q_likes = [$input_m . '_'];
// перебираем каждую букву метафона
for ($i = 0, $len = strlen($input_m); $i < $len; $i++)
// каждую букву подвергаем операциям вставки, удаления и замены
for($n = 1; $n < 4; $n++)
$q_likes[] = substr( $input_m, 0, $i )
. ($n & 1 ? '_' : '')
. substr( $input_m, $i + ($n > 1 ? 1 : 0) );
// подключаемся к базе
$conn = mysqli_connect('localhost','root','','test') or die(mysqli_error($conn));
// генерируем запрос + преобразовываем массив в строку для запроса
$q = mysqli_query($conn, "SELECT city_id, title_ru FROM _cities
WHERE metaphone LIKE '".implode("' OR metaphone LIKE '",$q_likes)."'");
// закрываем соединение
mysqli_close($conn);
// создаём массив для результатов
$result = [];
// складываем результаты в массив
while($row = mysqli_fetch_assoc($q))
$result[] = [ $row['city_id'], $row['title_ru'] ];
// можно их распечатать
// echo'<pre>'; print_r($result); echo'</pre>';
echo '<p>Готово. Скрипт выполнялся '.( microtime(true) - $_SERVER["REQUEST_TIME_FLOAT"] ).' сек';
LIKE проверялся с обоими шаблонами поиска, как со знаком подчёркивания, так и со знаком процента.
| № слова | t для LIKE с "_", сек | Найдено | t для LIKE с "%", сек | Найдено |
| 1. | 24.2 | 1 | 24.6 | 1 |
| 2. | 14.1 | 1 | 14.8 | 4 |
| 3. | 11.9 | 188 | 12.3 | 224 |
| 4. | 11.9 | 70 | 12.8 | 87 |
| 5. | 18.1 | 0 | 19.6 | 0 |
Также ожидался резкий всплеск во времени при замене шаблона поиска "_" на "%", но общее время увеличивалось в пределах 2-8%.
Функция Раста
Второй вариант представляет собой пользовательскую функцию levenshtein, которая принимает два параметра — две строки VARCHAR(255), и возвращает число INT — расстояние Левенштейна. Предлагается также вспомогательная функция levenshtein_ratio, которая на основе рассчитанного предыдущей функцией расстояния Левенштейна возвращает процент похожести двух строк (по аналогии с PHP-функцией similar_text). Тестировать будем только первую функцию.
Попробуем найти все слова с расстоянием Левенштейна в 1 символ:
SELECT city_id, title_ru FROM _cities WHERE levenshtein("BNNBKF",metaphone)=1Поиск похожих метафонов для четвёртого названия (у которого самый короткий метафон) дал такие же результаты, как и при поиске с помощью LIKE с шаблоном поиска "_", однако занял ~66 минут, поэтому было решено не продолжать тестировать остальные слова.
Функция Торреса
Третий вариант представляет собой имплементацию функции, написанной на Си Линусом Торвальдсом. Эта функция принимает три параметра — две строки для сравнения, и целое число INT — верхняя граница, т.е. максимальное количество символов, которые будут браться с каждой строки для сравнения.
Установим универсальную верхнюю границу для всех метафонов из нашего теста — 20 символов, и попробуем найти все слова с расстоянием Дамерау-Левенштейна в 1 символ:
SELECT city_id, title_ru FROM _cities WHERE damlevlim("BNNBKF",metaphone,20)=1Результаты:
| № слова | t для ф-ии Торреса, сек | Найдено |
| 1. | 11.24 | 1 |
| 2. | 9.25 | 1 |
| 3. | 9.19 | 173 |
| 4. | 8.3 | 86 |
| 5. | 11.57 | 0 |
| № слова | t для запроса Лести, сек | t для ф-ии Торреса, сек | Запрос Лести, найдено слов | Ф-я Торреса, найдено слов |
| 1. | 24.2 | 11.24 | 1 | 1 |
| 2. | 14.1 | 9.25 | 1 | 1 |
| 3. | 11.9 | 9.19 | 188 | 173 |
| 4. | 11.9 | 8.3 | 70 | 86 |
| 5. | 18.1 | 11.57 | 0 | 0 |
Реализация на PHP
Наиболее точные результаты при рафинировании могут быть получены, если поисковый запрос не будет транслитерироваться, т.е. после получения похожих слов они будут сравниваться с оригиналом. В ходе экспериментов было установлено, что функция similar_text возвращает разные результаты для слов на кириллице и латинице при одинаковом расстоянии Левенштейна. Поэтому для чистоты рассчётов дополнительно будет использована функция utf8_to_extended_ascii, изначально предложенная luciole75w для решения такой же проблемы при использовании PHP-функции levenshtein.
// поисковый запрос
$input = 'Черенцева';
// функция для правильной работы similar_text с UTF-8
function utf8_to_extended_ascii($str, &$map){
$matches = array();
if (!preg_match_all('/[\xC0-\xF7][\x80-\xBF]+/', $str, $matches))
return $str;
foreach ($matches[0] as $mbc)
if (!isset($map[$mbc]))
$map[$mbc] = chr(128 + count($map));
return strtr($str, $map);
}
// функция поиска похожих строк
function damlev($input){
// получаем метафон поискового запроса
$input_m = mtphn($input);
// подключаемся к БД
$conn = mysqli_connect('localhost','root','','test')
or die(mysqli_error($conn));
// находим все строки с разницей Дамерау-Левенштейна 0 или 1
$q = mysqli_query($conn, 'SELECT city_id, title_ru FROM _cities
WHERE damlevlim("'.$input_m.'",metaphone,20)<2');
// закрываем соединение
mysqli_close($conn);
// записываем результаты в массив
while ($row = mysqli_fetch_assoc($q))
$damlev_result[] = [ $row['city_id'], $row['title_ru'] ];
// если результатов больше 1 - рафинируем
if (count($damlev_result) > 1){
// перебираем массив
foreach ($damlev_result as $v)
// вычисляем похожесть каждого результата
// с поисковым запросом и кладём её в массив
similar_text( utf8_to_extended_ascii($input,$charMap),
utf8_to_extended_ascii($v[1],$charMap),
$similar_text_result[] );
// вычисляем максимальную похожесть
$max_similarity = max($similar_text_result);
// вычисляем ключи результатов с максимальной похожестью
$most_similar_strings = array_flip(
array_keys($similar_text_result, $max_similarity) );
// возвращаем результаты с этими ключами
return array_intersect_key($damlev_result,$most_similar_strings);
}
// если результатов нет или он 1 -
// возвращаем пустой массив или массив с 1 результатом
else
return $damlev_result;
}
echo '<p>Ищем название: '.$input;
$output = damlev($input); // получаем массив с похожими названиями
if (count($output) > 0){ // если он не пустой -
foreach ($output as $v) // вывести его содержимое в виде ссылок
$results_list[] = '<a href="search.php?id='.$v[0].'">'
.$v[1].'</a>';
echo '<p>Возможно, Вы ищите: '.implode(', ',$results_list);
}
else // если он пустой - юзер, иди в баню
echo'<p>Ничего не найдено, повторите поиск.';
Результат может выглядеть так:
| Ищем название: Черенцева Возможно, Вы ищите: Чаренцаван, Черенцовка |
Итоги
Самой быстрой оказалась имплементация расстояния Дамерау-Левенштейна, написанная Линусом Торвальдсом на Си и адаптированная Диего Торресом для MySQL в виде пользовательской функции. На втором месте с небольшой разницей во времени идёт примитивная имитация расстояния Левенштейна в виде SQL-запроса с большим количеством операторов LIKE, автор — Гордон Лести. На третьем месте далеко позади осталась пользовательская функция для MySQL от Джейсона Раста.
В заключении хотелось бы добавить, что использовать рассчёт расстояния Левенштейна в MySQL в продакшене необходимо только в случаях, когда строка, с которой нужно сравнивать, — короткая, а таблица со словами, которые подлежат сравнению со строкой — маленькая. В противном случае возможным решением в случае таблицы с большим словарём может быть её разделение на несколько таблиц, например, по первой букве, или по длине слова или его метафона.
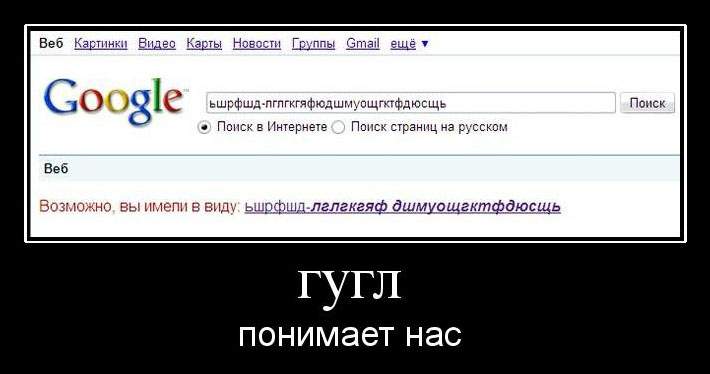
Чаще всего, область применения алгоритмов нечёткого поиска в вебе — поиски названий и имён по имеющемуся словарю, где высока вероятность того, что юзер может сделать опечатку или ошибиться хотя бы на 1 символ. В любом случае, постарайтесь предусмотреть, чтобы предлагаемые вашим скриптом варианты не становились объектом скриншотов:
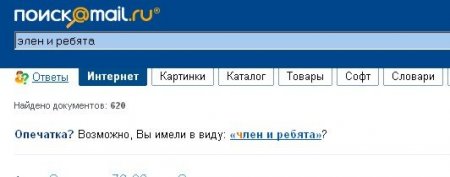
Комментарии (5)

Ilya81
15.11.2017 17:16На счёт транспозиции — я встречал определение, что транспозиция без возможности выполнения дальнейших действий. Хотя, по мне логичнее, что без выполнения других действий, иначе в некоторых случаях оно получится переоценённым:

Но иногда полезно оперировать другими категориями, чем символы (пример выше), использовать частные случаи замены, весовые коэффициенты и т. п…
japan007
15.11.2017 19:04все это будет в сотни раз медленнее существующих решений и в продакшн не годится

Shtucer
15.11.2017 19:12Хорошая ли это идея создавать массивы $from и $to при каждом вызове функции mtphn($s)? В масштабах поставленной задачи, это, конечно, копейки… или нет?
YourChief
15.11.2017 23:21Это решение крайне неэффективно, даже если использовать реализацию пользовательской функции на Си.
В промышленных системах, имеющих поддержку нечёткого поиска, используется автомат Левенштейна (например, поисковые движки на базе Lucene). Он для заданного наперёд расстояния Левенштейна выдаёт результат «истина» или «ложь». Его прелесть в том, что функция сложности этого алгоритма линейная, то есть, упрощённо, он близок по скорости к обычному линейному поиску по набору данных.
Pochemuk
Алгоритмы Левенштейна (как с, так и без Дамерау) и Оливера чувствительны к перестановке слов.
Каковы будут успехи, если задать в качестве поиска строку «Новгород Великий» или «Корея Южная»?