
Пока все ждут новостей, появится и заберёт ли свой выигрыш житель Воронежа, сорвавший рекордный джекпот в 506 млн. рублей, мы расскажем вам о технической части решения, которое позволило одной из крупнейших компаний по продаже лотерейных билетов в России увеличить объём продаж в 3 раза.

Только представьте, у компании есть более 40 тыс. подразделений практически во всех населенных пунктах России. В какой-то момент ребята упёрлись в потолок масштабируемости и поняли, что пора что-то менять и использовать новые технологические решения.
После этого, совместно с нами, было разработано решение на базе сервисов Azure и СУБД Microsoft SQL Server. Вместе с ним отпала необходимость устанавливать специализированное ПО для обработки данных, а ошибки стали выявляяться на самой ранней стадии. В итоге число отделений, работающих с лотерейными билетами, увеличилось с 8 до 22 тыс., а объём продаж билетов вырос в три раза.
Передаём слово Павлу, автору статьи.
Сегодня всё большее распространение получают облачные сервисы. Думаю, многие задаются вопросом «Чем же они так хороши?» Я для себя отвечаю так: «В первую очередь своей масштабируемостью, качественной инфраструктурой и обилием сервисов.» Но иногда дело не обходится без нюансов, знание о которых поможет сохранить время и деньги. В этой статье речь пойдет как раз о некоторых из них, которые следует учесть при разработке в связке Entity Framework + Azure SQL.
С точки зрения разработчика это почти то же самое, что и современный Microsoft SQL Server. Важнейшим отличием является наличие искусственных ограничений в производительности, от которых зависит цена «облачной» СУБД.
В расчете этого параметра участвует конечно же и CPU, и количество операций ввода/вывода с диском и с логом, правда точный состав формулы неизвестен. И самое главное — за разумные деньги DTU не так много. А много DTU стоят совсем уж неприличных денег. Очевидно, что их надо экономить и не тратить понапрасну. Причем, кроме чисто финансовых соображений, есть и еще одно, очень важное: СУБД довольно плохо масштабируется.
«Как же так?» — спросите вы. — «Мы же в облака и идем за тем, чтобы платить только за использованные ресурсы и иметь возможность быстро масштабировать наше решение. Я же могу в любой момент мышкой щелкнуть и увеличить число доступных DTU в пять раз».
Можете, но учтите при этом то, как внутри платформы происходит переход на другую категорию производительности.
А происходит это так:
Процесс восстановления и синхронизации занимает ненулевое время, практика показывает, что на каждые 50 Гб базы данных уровня Standard требуется около 1 часа, причем это для БД без какой-либо нагрузки. Это значит, что, если ваша БД весит 150 Гб и утром после рекламной кампании вы имеете 100% загрузку БД и все тормозит — повысить число DTU вам удастся в лучшем случае к обеду. Разумеется ваш бизнес департамент за это время красочно объяснит вам, где он видел ваши волшебные облака, а также спросит, где же их хваленая масштабируемость и устойчивость.
Итоговый вывод прост: нам всегда нужен запас по производительности, а переключение уровня производительности нужно делать заранее.
Разобравшись с вопросом зачем нам экономить ресурсы БД попробуем ответить на вопрос «Как?».
В первую очередь отметим, что современный подход к проектированию почти полностью исключает использование хранимых процедур. Нет, никто не запрещает, но этот подход не должен быть основным. В эпоху классических двухзвенных приложений активное использование хранимых процедур на сервере СУБД было хорошим тоном. Но ведь тогда это было средством реализовать тот самый сервер приложений, который сегодня реализуется вашим ASP.NET приложением. Ну и разумеется, перенося логику на СУБД, мы опять быстро упираемся в проблемы масштабирования, что называется “смотри пункт первый”.
Итак, у нас есть веб-приложение на базе ASP.NET + Entity Framework и LINQ to SQL для написания запросов. Удобно — аж жуть. Про базу данных можно забыть… Ага, вот тут-то и есть главная опасность. К сожалению, про базу данных можно забыть только в простых случаях. А в сложных и высоконагруженных…. Вот конкретный пример. Допустим нам надо вытащить несколько записей по условию:
Всё здорово, просто и понятно. Будет выполнен простейший запрос, эквивалентный:
Теперь представим себе, что в дальнейшем коде нам из 20 полей этой таблицы нужно использовать всего три — пусть это будет Amount, ClientID, AccountID. А вытаскиваем мы всегда все 20. При приличных нагрузках быстро выясняется, что выборка всех полей создаёт большое количество обращений к диску, даже если у вас есть индекс по Amount, а если нет — то тем более производится полный скан всей таблицы. Все подобные случаи решаются с двух сторон — со стороны приложения вы выбираете только те поля, которые вам совершенно необходимы:
И если, как в нашем примере, таких полей существенно меньше чем полей в таблице всего, создается индекс со включенными полями:
Если вы посмотрите план запроса — все данные берутся из индекса, обращений к диску почти не происходит. DTU расходуется крайне экономно.
Самое интересное, что платформа сама подскажет вам запросы, которые требуют доработки по описанному сценарию. На рабочей БД вам необходимо внимательно следить за рекомендациями по индексам, которые дает платформа. Рекомендации эти собраны в пункте меню Perfomance Recommendations:
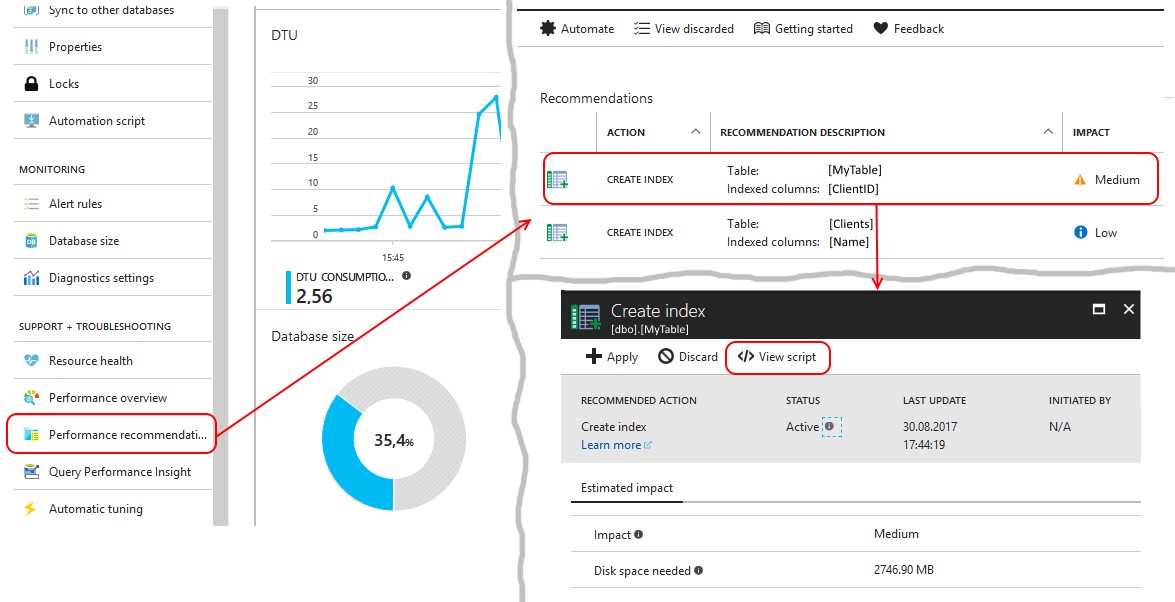
Необходимо посмотреть запрос на создание индекса, который предлагает система. И если предлагается создать индекс, где в INCLUDE перечислены все поля таблицы за исключением ключевых — то это как раз вышеописанный случай!
Дешевизна дискового хранилища породила всеобщую тенденцию к денормализации данных в СУБД. Отсюда стали появляться и NoSQL базы, работа с которыми требует специфичного подхода, но дает большой выигрыш в скорости. В какой то степени сходный принцип приходится нынче применять и для обычных реляционых СУБД.
Как бы ни был красив ваш 6-этажный join, его выполнение достаточно трудная задача для сервера. Заставить сервер «перелопатить» половину базы данных, чтобы выдать две цифры — задача достойная, но резко ограничивающая вас в масштабировании. Практика показывает, что зачастую проще сделать два простых запроса к СУБД и затем склеить результат в памяти, нежели насиловать сервер одним сложным запросом. Более того, проще и быстрее простым запросом получить 5-7 тысяч строк и провести доработку силами сервера приложений, чем наворотить запрос, который выдаст три строки, но при этом сожрёт все доступные ресурсы. За счёт этого мы переносим часть логической нагрузки на сервер приложений, масштабирование которого требует 2 минуты и происходит зачастую автоматически. А про сложности с масштабированием СУБД всё уже сказано выше.
Допустим мы пытаемся выбрать некую статистику общей сумме заказов наших клиентов, где каждый заказ был от 10 тысяч. Выдать нужно общую сумму, количество таких заказов и наименование клиента. Операции хранятся в некой таблице
Посмотрим во что его превращает Entity Framework:
Запрос вроде и не сложный, но большое количество таких «несложных» запросов будут генерировать весьма немалую нагрузку. А если их много, то список клиентов логично держать в кэше. И тогда код выборки мог бы быть таким:
Который Entity Framework превращает в куда более простой запрос:
И после этого уже в памяти мы достраиваем выборку данными клиентов:
Даже при наличии «правильного» индекса:
План запроса для второго случая имеет вдвое меньший Estimated Subtree Cost. Картинки планов запросов соответственно:
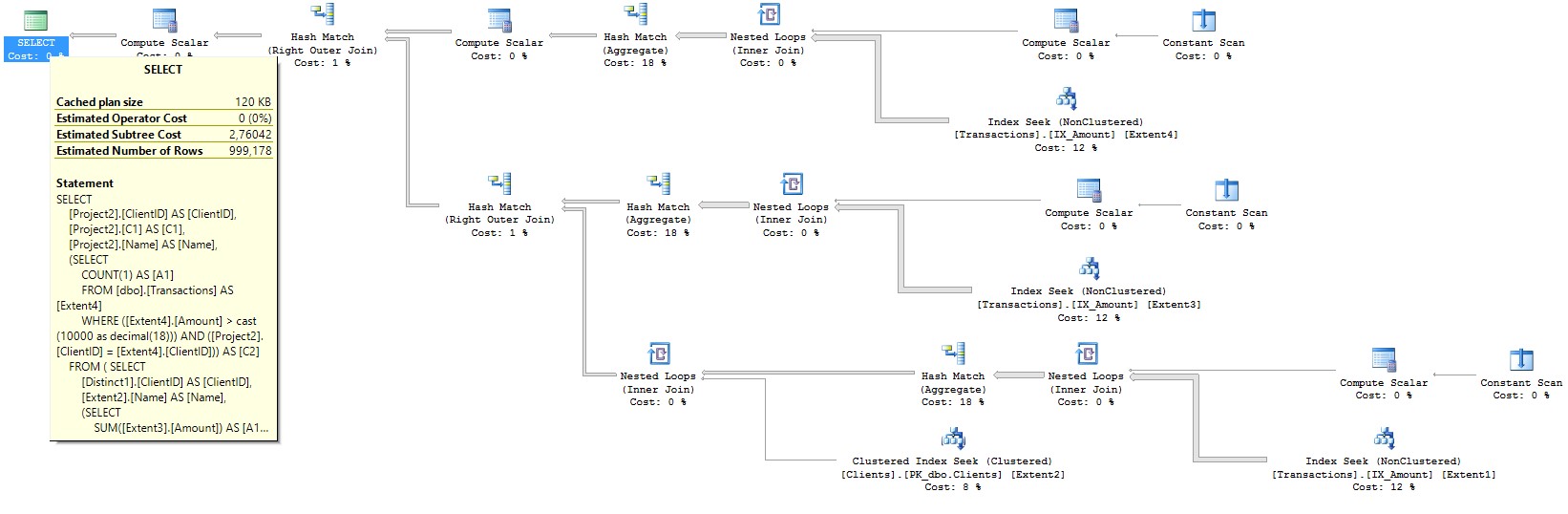
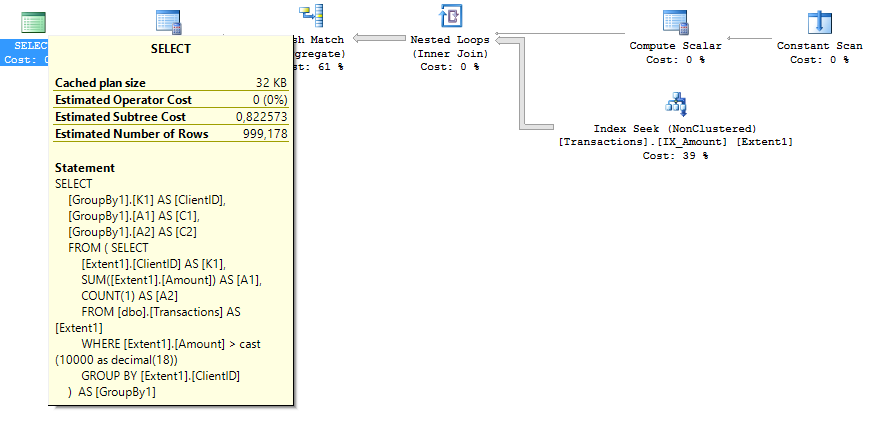
Описанные подходы позволяют увеличить скорость системы в 10-40 раз, пропорционально уменьшив требуемый уровень производительности Azure SQL.
 Павел Кутаков — более 15 лет опыта в качестве разработчика и архитектора программных систем в различных областях бизнеса. В списке проектов банковская информационная система, работающая по всему миру от США до Папуа-Новой Гвинеи, а также интегрированная среда разработки для СУБД Firebird. В настоящее время руководит разработкой специализированных транзакционных сервисов национального оператора лотерей.
Павел Кутаков — более 15 лет опыта в качестве разработчика и архитектора программных систем в различных областях бизнеса. В списке проектов банковская информационная система, работающая по всему миру от США до Папуа-Новой Гвинеи, а также интегрированная среда разработки для СУБД Firebird. В настоящее время руководит разработкой специализированных транзакционных сервисов национального оператора лотерей.
Напоминаем, что Azure можно попробовать бесплатно.
Цикл статей «Digital Transformation»
Технологические статьи:
1. Начало.
2. Лотерея в облаке.
3. Loading…
Серия интервью с Дмитрием Завалишиным на канале DZ Online:
1. Александр Ложечкин из Microsoft: Нужны ли разработчики в будущем?
Введение
Только представьте, у компании есть более 40 тыс. подразделений практически во всех населенных пунктах России. В какой-то момент ребята упёрлись в потолок масштабируемости и поняли, что пора что-то менять и использовать новые технологические решения.
После этого, совместно с нами, было разработано решение на базе сервисов Azure и СУБД Microsoft SQL Server. Вместе с ним отпала необходимость устанавливать специализированное ПО для обработки данных, а ошибки стали выявляяться на самой ранней стадии. В итоге число отделений, работающих с лотерейными билетами, увеличилось с 8 до 22 тыс., а объём продаж билетов вырос в три раза.
Передаём слово Павлу, автору статьи.
Сегодня всё большее распространение получают облачные сервисы. Думаю, многие задаются вопросом «Чем же они так хороши?» Я для себя отвечаю так: «В первую очередь своей масштабируемостью, качественной инфраструктурой и обилием сервисов.» Но иногда дело не обходится без нюансов, знание о которых поможет сохранить время и деньги. В этой статье речь пойдет как раз о некоторых из них, которые следует учесть при разработке в связке Entity Framework + Azure SQL.
Начнем с Azure SQL
С точки зрения разработчика это почти то же самое, что и современный Microsoft SQL Server. Важнейшим отличием является наличие искусственных ограничений в производительности, от которых зависит цена «облачной» СУБД.
- В on-premise сервере вы ограничены мощностью CPU, скоростью HDD и объемом оперативной памяти и, как правило, всё это куплено с хорошим запасом.
- В облачной версии вы не знаете сколько аппаратных ресурсов у вас есть, взамен этого у вас есть некоторая расчетная величина производительности, называемая DTU (Data Transfer Unit).
В расчете этого параметра участвует конечно же и CPU, и количество операций ввода/вывода с диском и с логом, правда точный состав формулы неизвестен. И самое главное — за разумные деньги DTU не так много. А много DTU стоят совсем уж неприличных денег. Очевидно, что их надо экономить и не тратить понапрасну. Причем, кроме чисто финансовых соображений, есть и еще одно, очень важное: СУБД довольно плохо масштабируется.
«Как же так?» — спросите вы. — «Мы же в облака и идем за тем, чтобы платить только за использованные ресурсы и иметь возможность быстро масштабировать наше решение. Я же могу в любой момент мышкой щелкнуть и увеличить число доступных DTU в пять раз».
Можете, но учтите при этом то, как внутри платформы происходит переход на другую категорию производительности.
А происходит это так:
- делается восстановление базы из бэкапа;
- настраивается репликация между базами;
- когда базы синхронизированы происходит переключение (естественно с небольшим разрывом в доступности, заявляется что это время не превышает 30 секунд).
Процесс восстановления и синхронизации занимает ненулевое время, практика показывает, что на каждые 50 Гб базы данных уровня Standard требуется около 1 часа, причем это для БД без какой-либо нагрузки. Это значит, что, если ваша БД весит 150 Гб и утром после рекламной кампании вы имеете 100% загрузку БД и все тормозит — повысить число DTU вам удастся в лучшем случае к обеду. Разумеется ваш бизнес департамент за это время красочно объяснит вам, где он видел ваши волшебные облака, а также спросит, где же их хваленая масштабируемость и устойчивость.
Итоговый вывод прост: нам всегда нужен запас по производительности, а переключение уровня производительности нужно делать заранее.
Разобравшись с вопросом зачем нам экономить ресурсы БД попробуем ответить на вопрос «Как?».
Подход первый — берём только нужное
В первую очередь отметим, что современный подход к проектированию почти полностью исключает использование хранимых процедур. Нет, никто не запрещает, но этот подход не должен быть основным. В эпоху классических двухзвенных приложений активное использование хранимых процедур на сервере СУБД было хорошим тоном. Но ведь тогда это было средством реализовать тот самый сервер приложений, который сегодня реализуется вашим ASP.NET приложением. Ну и разумеется, перенося логику на СУБД, мы опять быстро упираемся в проблемы масштабирования, что называется “смотри пункт первый”.
Итак, у нас есть веб-приложение на базе ASP.NET + Entity Framework и LINQ to SQL для написания запросов. Удобно — аж жуть. Про базу данных можно забыть… Ага, вот тут-то и есть главная опасность. К сожалению, про базу данных можно забыть только в простых случаях. А в сложных и высоконагруженных…. Вот конкретный пример. Допустим нам надо вытащить несколько записей по условию:
myContext.MyTable.Where(x=>x.Amount>100).ToList();Всё здорово, просто и понятно. Будет выполнен простейший запрос, эквивалентный:
Select * from MyTable where amount>100Теперь представим себе, что в дальнейшем коде нам из 20 полей этой таблицы нужно использовать всего три — пусть это будет Amount, ClientID, AccountID. А вытаскиваем мы всегда все 20. При приличных нагрузках быстро выясняется, что выборка всех полей создаёт большое количество обращений к диску, даже если у вас есть индекс по Amount, а если нет — то тем более производится полный скан всей таблицы. Все подобные случаи решаются с двух сторон — со стороны приложения вы выбираете только те поля, которые вам совершенно необходимы:
myContext.MyTable.Where(x=>x.Amount>100)
.Select(x=>new MyTableViewModel{
ClientID = x.ClientID,
AccountId = x.AccountID,
Amount = x.Amount
})
.ToList();И если, как в нашем примере, таких полей существенно меньше чем полей в таблице всего, создается индекс со включенными полями:
create index IX_AmountEx on MyTable(Amount) include(AccountID, ClientID)Если вы посмотрите план запроса — все данные берутся из индекса, обращений к диску почти не происходит. DTU расходуется крайне экономно.
Самое интересное, что платформа сама подскажет вам запросы, которые требуют доработки по описанному сценарию. На рабочей БД вам необходимо внимательно следить за рекомендациями по индексам, которые дает платформа. Рекомендации эти собраны в пункте меню Perfomance Recommendations:
Необходимо посмотреть запрос на создание индекса, который предлагает система. И если предлагается создать индекс, где в INCLUDE перечислены все поля таблицы за исключением ключевых — то это как раз вышеописанный случай!
Подход второй — будь проще
Дешевизна дискового хранилища породила всеобщую тенденцию к денормализации данных в СУБД. Отсюда стали появляться и NoSQL базы, работа с которыми требует специфичного подхода, но дает большой выигрыш в скорости. В какой то степени сходный принцип приходится нынче применять и для обычных реляционых СУБД.
Как бы ни был красив ваш 6-этажный join, его выполнение достаточно трудная задача для сервера. Заставить сервер «перелопатить» половину базы данных, чтобы выдать две цифры — задача достойная, но резко ограничивающая вас в масштабировании. Практика показывает, что зачастую проще сделать два простых запроса к СУБД и затем склеить результат в памяти, нежели насиловать сервер одним сложным запросом. Более того, проще и быстрее простым запросом получить 5-7 тысяч строк и провести доработку силами сервера приложений, чем наворотить запрос, который выдаст три строки, но при этом сожрёт все доступные ресурсы. За счёт этого мы переносим часть логической нагрузки на сервер приложений, масштабирование которого требует 2 минуты и происходит зачастую автоматически. А про сложности с масштабированием СУБД всё уже сказано выше.
Пример
Допустим мы пытаемся выбрать некую статистику общей сумме заказов наших клиентов, где каждый заказ был от 10 тысяч. Выдать нужно общую сумму, количество таких заказов и наименование клиента. Операции хранятся в некой таблице
Transactions, а клиенты, соответственно, в Clients. Типичный запрос выглядит так: from t in dc.Transactions
where t.Amount>10000m
group t by t.ClientID into tg
join cli in dc.Clients on tg.Key equals cli.ID into resTable
from xx in resTable
select new
{
Amount = tg.Sum(x => x.Amount),
ClientID = tg.Key,
ClientName = xx.Name,
ItemCount = tg.Count()
};Посмотрим во что его превращает Entity Framework:
SELECT
[Project2].[ClientID] AS [ClientID],
[Project2].[C1] AS [C1],
[Project2].[Name] AS [Name],
(SELECT
COUNT(1) AS [A1]
FROM [dbo].[Transactions] AS [Extent4]
WHERE ([Extent4].[Amount] > cast(10000 as decimal(18))) AND ([Project2].[ClientID] = [Extent4].[ClientID])) AS [C2]
FROM ( SELECT
[Distinct1].[ClientID] AS [ClientID],
[Extent2].[Name] AS [Name],
(SELECT
SUM([Extent3].[Amount]) AS [A1]
FROM [dbo].[Transactions] AS [Extent3]
WHERE ([Extent3].[Amount] > cast(10000 as decimal(18))) AND ([Distinct1].[ClientID] = [Extent3].[ClientID])) AS [C1]
FROM (SELECT DISTINCT
[Extent1].[ClientID] AS [ClientID]
FROM [dbo].[Transactions] AS [Extent1]
WHERE [Extent1].[Amount] > cast(10000 as decimal(18)) ) AS [Distinct1]
INNER JOIN [dbo].[Clients] AS [Extent2] ON [Distinct1].[ClientID] = [Extent2].[ID]
) AS [Project2]Запрос вроде и не сложный, но большое количество таких «несложных» запросов будут генерировать весьма немалую нагрузку. А если их много, то список клиентов логично держать в кэше. И тогда код выборки мог бы быть таким:
var groupedTransactions= (from t in dc.Transactions
where t.Amount > 10000m
group t by t.ClientID into tg
select new
{
Amount = tg.Sum(x => x.Amount),
ClientID = tg.Key,
ItemCount = tg.Count()
}).ToList();Который Entity Framework превращает в куда более простой запрос:
SELECT
[GroupBy1].[K1] AS [ClientID],
[GroupBy1].[A1] AS [C1],
[GroupBy1].[A2] AS [C2]
FROM ( SELECT
[Extent1].[ClientID] AS [K1],
SUM([Extent1].[Amount]) AS [A1],
COUNT(1) AS [A2]
FROM [dbo].[Transactions] AS [Extent1]
WHERE [Extent1].[Amount] > cast(10000 as decimal(18))
GROUP BY [Extent1].[ClientID]
) AS [GroupBy1]И после этого уже в памяти мы достраиваем выборку данными клиентов:
from tdata in groupedTransactions
join client in clientCache on tdata.ClientID equals client.ID
select new
{
Amount = tdata.Amount,
ItemCount = tdata.ItemCount,
ClientID = tdata.ClientID,
ClientName = client.Name
};Даже при наличии «правильного» индекса:
сreate index IX_Amount on Transactions (Amount) include(ClientID)План запроса для второго случая имеет вдвое меньший Estimated Subtree Cost. Картинки планов запросов соответственно:
Резюме
- При работе с Azure SQL необходимо очень рационально расходовать DTU, чтобы не нарваться на заоблачные цены. При этом запас по производительности должен быть, так как изменение предельной производительности вашей БД может занимать несколько часов.
- Для этого аккуратно пишем запросы, чтобы требовать только нужные данные. Активно используем индексы с INCLUDE полями.
- Упрощаем запросы, финальное соединение данных проводим на стороне сервера приложений — он дешевле и масштабируется быстрее.
Описанные подходы позволяют увеличить скорость системы в 10-40 раз, пропорционально уменьшив требуемый уровень производительности Azure SQL.
Об авторе
Павел Кутаков — более 15 лет опыта в качестве разработчика и архитектора программных систем в различных областях бизнеса. В списке проектов банковская информационная система, работающая по всему миру от США до Папуа-Новой Гвинеи, а также интегрированная среда разработки для СУБД Firebird. В настоящее время руководит разработкой специализированных транзакционных сервисов национального оператора лотерей.Напоминаем, что Azure можно попробовать бесплатно.
Комментарии (4)

mickvav
17.11.2017 09:18Отличная техническая статья для блога Microsoft, многое говорит об отношении —
взамен этого у вас есть некоторая расчетная величина производительности, называемая DTU (Data Transfer Unit).
В расчете этого параметра участвует конечно же и CPU, и количество операций ввода/вывода с диском и с логом, правда точный состав формулы неизвестен.
То есть «Платите нам деньги за то, не знаю что. Сколько? А сколько скажем, столько и платите». Супер вообще.

stasus
17.11.2017 16:33+1Есть вполне понятное определение, что такое DTU docs.microsoft.com/en-us/azure/sql-database/sql-database-what-is-a-dtu
+ есть калькулятор, который может его посчтиать для вашего конкретного воклоада dtucalculator.azurewebsites.net
Так что вы немного преувеличиваете.
algotrader2013
Логики предложения в статье так и не увидел.
С одной стороны
С другой
ЕМПИН, под капотом Azure SQL тот же MSSQL сервер на вполне обычном серверном железе (если не low-end даже, судя по статье cdn2.hubspot.net/hubfs/2334522/reports/Azure%20%20performance%20report%201-2017-ENG.pdf).
То есть, могу сделать вывод, что лотерейщики сделали 2 изменения одновременно (оптимизировали запросы и индексы, и переехали на Azure), и смасштабировались не благодаря, а вопреки прозводительности Azure SQL; видимо, оптимизации таки оказались очень значительными, что и подтверждает фраза
stasus
Масштабирование в основном за счёт масштабирование фронтенда на базе App Services.
До переноса в Azure, там был MySQL, так что там было всё нескольок сложнее, чем простая оптимизациия запросов и индексов. Там было разделение данных, выделение статики и т.д.