

В действительности частота ошибок динамической памяти с произвольным доступом (DRAM) на порядки выше, чем сообщают отчеты. В недавнем крупномасштабном исследовании ошибок памяти DRAM в полевых условиях на основе данных, собранных в течение более двух лет, около трети всех машин и более 8% модулей DIMM фиксировали по крайней мере одну исправимую ошибку в год (DRAM errors in the wild: a large-scale field study). На некоторых платформах почти в 50% систем возникали исправимые ошибки (отчет IBID), и в среднем только около 1,3% систем были подвержены непоправимым ошибкам, а для некоторых платформ этот показатель составлял 2-4%.
В стандартных офисных ПК ошибки памяти редко отрицательно влияют на результат работы стандартного прикладного программного обеспечения. Однако в системах старшего класса при интенсивных вычислениях в мире финансов, исследованиях в области добычи нефти и газа, в задачах медицинской визуализации, медиапроизводстве (рендеринге и редактировании) и пр. целостность данных является важнейшей составляющей общей архитектуры системы. В таких высокопроизводительных системах замена памяти занимает одно из первых мест в ремонте из-за отказавших компонентов, при этом ошибки памяти — одна из наиболее распространенных проблем с оборудованием, которые могут привести к сбоям системы (отчет IBID).

Таким образом, способность обнаруживать ошибки DIMM, сообщать о них и предотвращать сбои в высокопроизводительных рабочих станциях становится необходимостью.
Учитывая высокий спрос на экстремальную производительность оперативной памяти, Dell запатентовала инновационную, эксклюзивную технологию, применяемую в рабочих станциях Dell Precision, которая помогает маркировать и выводить из работы непригодную память. Эта уникальная функция Dell помогает сократить время простоя системы, упростить работу службы поддержки ИТ и снизить общие расходы на обслуживание, увеличивая долговечность памяти и повышая продуктивность работы пользователей.
Рассмотрим основные концепции технологии надежной памяти Dell Reliable Memory Technology PRO (RMT PRO), некоторые из основных причин ошибок памяти и то, как RMT PRO помогает устранять эти ошибки.
Оперативная память
Вместе с новыми достижениями в технологиях процессоров, увеличением скорости шины и усовершенствованиями в общей архитектуре, компьютерные системы становятся более сложными, и оперативной памяти также приходится идти в ногу с этими изменениями.

По существу (очень упрощенно), чипы DRAM представляют собой массив элементов с состояниями «включен/выключен», которые сохраняют это состояние (1 или 0) при наличии питания. Когда питание выключено, они возвращаются в нулевое состояние. Несколько чипов собрано вместе в подсистеме памяти и размещено на печатной плате — модуле DIMM (dual in-line memory module).
В большинстве рабочих станций, таких как Dell Precision, используется тип DIMM, известный как DDR4 SDRAM – синхронное динамическое запоминающее устройство с произвольной выборкой. По существу, по сравнению с более ранними версиями типов памяти (например, DDR3), DDR4 работает быстрее, имеет большую пропускную способность и более высокую плотность памяти, требует меньшего напряжения питания.
Ошибки памяти
Ошибки памяти могут быть вызваны большим количеством факторов, в результате чего один бит DRAM автоматически переходит в противоположное состояние (например, из 1 в 0, когда во время этого цикла памяти должен оставаться в 1). На ошибки могут влиять такие факторы, как перегрев, возраст памяти, дефекты и т. д. Как показали исследования, в первые 10 месяцев эксплуатации DIMM уровень ошибок резко возрастает.
Эти типы ошибок называются исправимыми ошибками: они случайным образом повреждают биты, но не оставляют физических повреждений и могут быть исправлены с помощью обновления состояния памяти.
Однако во многих случаях возникают некорректируемые ошибки. Это повторяемая ошибка бита из-за физического дефекта или другой аномалии модуля DIMM, либо когда внутри одного блока памяти случаются сразу две ошибки. Неисправимая ошибка памяти может привести к сбою системы (потребуется перезагрузка) или приложения (код Stop Error на системном уровне, дамп ядра или «синий экран смерти» — BSoD). Часто исправимые ошибки предупреждают о приближающихся неисправимых ошибках. В исследованиях около 65-80% некорректируемых ошибок в том же месяце предшествовала исправимая ошибка.
Обработка ошибок
Сегодня многие ПК класса рабочей станции включают в себя алгоритмы проверки четности памяти, которые, попросту говоря, гарантируют, что каждый раз, когда считывается байт данных, отправленные данные совпадают с полученными данными.

Более сложные системы используют другие методы коррекции ошибок и их обнаружения. Наиболее распространенный вариант — память с исправлением ошибок (error-correcting code, ECC). Она применяется в серверах и рабочих станциях, таких как рабочие станции Dell Precision. По сути, память ECC включает в себя дополнительные биты и встроенный контроллер памяти, который проверяет четность памяти, а в случае однобитовой ошибки логика памяти ECC может исправить ошибку и вывести исправленные данные, чтобы система продолжала работать.
ECC отлично справляется с исправлением изолированных ошибок памяти и обеспечивает стабильную работу системы. Тем не менее, память ECC не дает решения при множественных ошибках в одном блоке памяти. В этих случаях произойдет порча данных. В подобной ситуации может помочь Dell Reliable Memory Technology PRO.
Преимущества технологии RMT PRO
При физическом повреждении пластины жесткого диска сбойный сектор будет помечен как непригодный для использования системой ПК. Однако в большинстве компьютеров, включая рабочие станции с памятью ECC, неисправимая ошибка или несколько исправимых ошибок в одном блоке памяти на модуле DIMM могут привести к сбою системы. Пользователь, как правило, вынужден сообщать о такой ошибке своей службе поддержки, которая, в свою очередь, должна запустить некую программу диагностики для обнаружения ошибки. Нередко однократный отказ может потребовать замены всего модуля DIMM.
Результат – увеличение простоев, снижение производительности, потеря времени ИТ-персонала, необходимость замены DIMM и возможное повреждение ключевых файлов приложений.

На выручку приходит технология Dell Reliable Memory Technology PRO (RMT PRO).
Похожая по своей концепции на технологию исправления ошибок жесткого диска, RMT PRO обнаруживает неисправимые ошибки и многобитовые исправимые ошибки в модуле DIMM и устраняет проблему. Вместо дорогостоящих простоев, запуск диагностики, вскрытия системы и замены неисправного модуля DIMM технология RMT PRO при перезагрузке:
- Помечает дефектную часть отдельного модуля DIMM.
- Сообщает о дефекте и местоположении сбойного участка DIMM в BIOS.
- Удаляет эти плохие ячейки и небольшое количество соседних ячеек из пула используемой системной памяти.
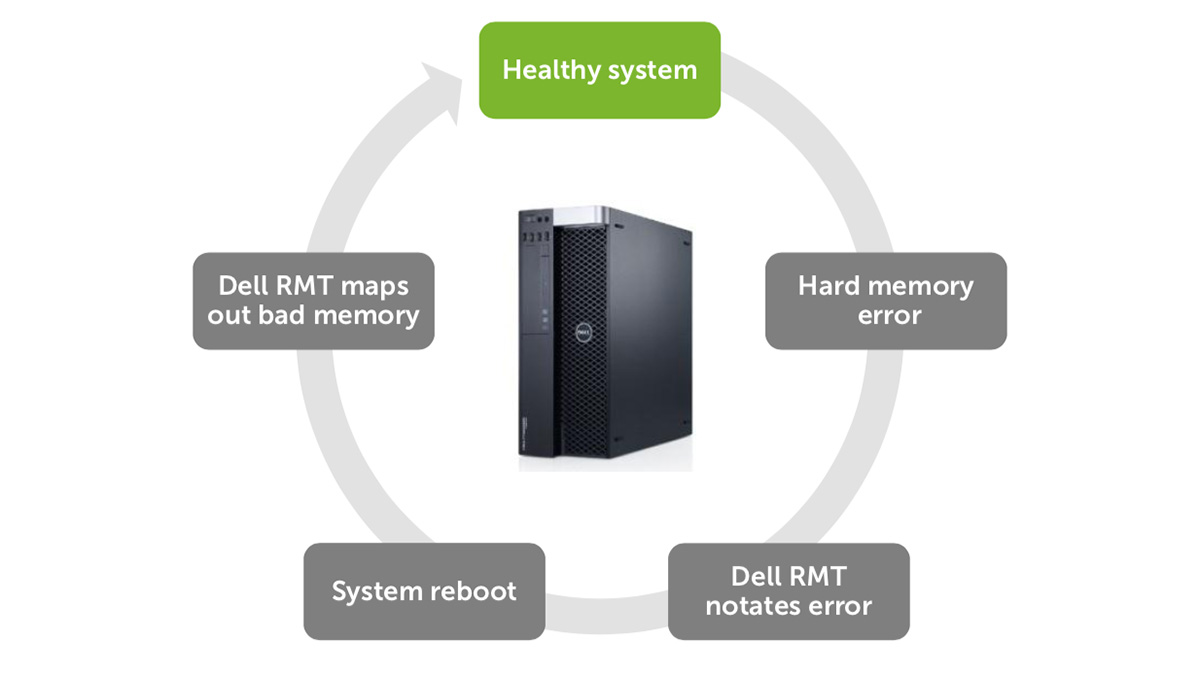
После простой перезагрузки рабочей станции RMT PRO делает дефектную область невидимой для операционной системы. Приложения и критические системные функции будут «обходить» отмеченную область и продолжат работать без необходимости замены оборудования. Все будет так, как если бы плохая память никогда не существовала. Тем самым обеспечивается бесперебойная работа, уменьшается количество системных сбоев и ошибок приложений.
RMT PRO может сократить расходы на аппаратные средства – модули памяти. Поскольку память может ухудшаться при интенсивном использовании или чрезмерном нагревании (обычно из-за высокой нагрузки), число физических ошибок может возрастать. Несмотря на «плохую память» информация остается на DIMM. Кроме того, если требуется замена DIMM, RMT PRO будет отображать в BIOS, какие именно модули DIMM вызывают ошибки, ускоряя процесс устранения неисправностей и замену DIMM, что помогает сократить время простоя и снизить общую стоимость сервиса. Таким образом, технология RMT PRO увеличивает жизненный цикл оперативной памяти и помогает экономить средства.

Выводы
Хотя некоторые схемы обнаружения ошибок, такие как память ECC, могут отлавливать ошибки памяти, многие из этих алгоритмов позволяют обрабатывать только исправимые ошибки. Когда возникают физические дефекты или неисправимые ошибки в DIMM, Dell RMT PRO обеспечивает дополнительный уровень обнаружения и коррекции дефектной памяти.
Путем сопоставления и удаления поврежденных секторов технология RMT PRO делает так, чтобы приложения с интенсивными вычислениями получали доступ только к пригодной для использования памяти. Это может привести к значительной экономии как времени, так и денег из-за сокращения сроков замены оборудования и модулей DIMM, уменьшения простоев техники. Когда целостность данных имеет решающее значение, технология RMT PRO дает необходимый уровень уверенности, обеспечивая доступную память для максимального увеличения производительности и надежности рабочей станции.
Комментарии (9)

amarao
22.11.2017 18:17+1Ребята, научитесь писать по-человечески. multibit ECC отлично детектит битые ячейки. Вы путаете стоимость обслуживания (замены) памяти с обнаружением отказов. Ваша технология не умеет ничего, чтобы не умело ECC с точки зрения обнаружения отказов, то есть вся фича — это проприетарная, эксклюзивная и патентованная реализация давно существующей BadRam. help.ubuntu.com/community/BadRAM

vesper-bot
23.11.2017 10:13BadRAM софтовая штука, и не может работать, если сбойная память пришлась на сегмент слишком низких адресов, так что ядро не доходит до загрузки BadRAM-модуля, как нарывается на сбойную память. По описанию, эта штука работает на более низком уровне, помечая какие-то регионы «занятыми» на уровне BIOS/UEFI, а по факту они сбойные. То есть при этой технологии BadRAM уже ничего не поймает, мало того, если поймает, то будет двойная реакция (хотя хуже не будет, просто на обоих уровнях один и тот же сегмент адресов окажется выключенным).
amarao
23.11.2017 15:13А дальше вопрос: если мы говорим о небольшом числе сбоев, какова вероятность, что они прийдутся на «низкие адреса»? Чем больше память, тем меньше вероятность.
То есть мы имеем маргинальные преимущества по сравнению с софтовым решением. При этом софтовое решение универсальное и открытое, а аппаратное — vendor lock, проприетарное, эксклюзивное, патентованное и иным образом ограничивающее в возможностях применения.
vesper-bot
То есть придумали помечать сегменты модулей памяти как bad sectors на винтах? А где у них FAT, т.е. таблица сбойных секторов, таблица перемещенных секторов (если есть), и что делать, если сбойный блок попал на эту таблицу?
workless
Относительно накопителей.
remap, badblock это не file system
Как например вы будите тестировать ремапы и бэд-ы на новом неформатированном диске?
Например с помощью Victoria, mhdd
Думаю для этого есть сервисная область\сервисная память
Наверное и на памяти есть что-то такое. Там же необязательно хранить много данных. Если уж 1000 ячеек вылетело — память лучше поменять.
Alexeyslav
нет, памяти запасной нет. Но добавить функционал «не использовать адреса XXXX-YYYY» можно программно. Был бы только механизм обнаружения таких ячеек.
В отличие от винчестера, реализация «ремапа» оперативной памяти довольно ресурсоёмка в железе т.к. всё должно работать на высоких скоростях.
vesper-bot
Спасибо за информацию.
a5b
Для повышения выхода годных могут делать небольшое количество "запасных строк" на каждую группу банков в чипах (DDR4 и LPDDR4), например
https://www.micron.com/~/media/documents/products/technical-note/dram/tn_4040_ddr4_point_to_point_design_guide.pdf
https://www.google.com/patents/WO2017030564A1?cl=en "Newer memories, such as double data ram version 4 (DDR4) include so-called post-package repair (PPR) capabilities. PPR capabilities enable a compatible memory controller to remap accesses from a faulty row of a memory module to a spare row of the memory module that is not faulty."
https://www.micron.com/products/datasheets/%7B3D323C4D-6BC7-4193-908D-E99AD746AA4E%7D?page=12
https://www.skhynix.com/static/filedata/fileDownload.do?seq=253 стр 169 "DDR4 supports Fail Row address repair as optional feature for 4Gb and required for 8Gb and above. Supporting PPR is identified via Datasheet and SPD in Module so should refer to DRAM manufacturer’s Datasheet. PPR provides simple and easy repair method in the system and Fail Row address can be repaired by the electrical programming of Electrical-fuse scheme." стр 172 "Soft Post Package Repair (sPPR) is a way to quickly, but temporarily, repair a row element in a Bank Group on a DDR4 DRAM
device, contrasted to hard Post Package Repair which takes longer but is permanent repair of a row element."
vesper-bot
Помнится, сбойные кластеры в файловой системе помечались, пока ещё не было на винтах логики remap. Я об этом.